这是一个专为判断苹果是否变质或新鲜而构建的图像分类模型。
python
import tensorflow as tf
ds_train=tf.keras.preprocessing.image_dataset_from_directory(
'/Apple',
labels="inferred",
label_mode='binary',
interpolation='nearest',
batch_size=64,
image_size=[128,128],
shuffle=False
)
def convert_to_int(image,label):
image=tf.image.convert_image_dtype(image,dtype=tf.float32)
return image,label
ds_train=(
ds_train.
map(convert_to_int).
cache()
)
model=tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=32,kernel_size=5,input_shape=[128,128,3],activation='relu',padding='same'),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Conv2D(filters=64,kernel_size=5,activation='relu',padding='same'),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Conv2D(filters=128,kernel_size=5,activation='relu',padding='same'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=8,activation='relu'),
tf.keras.layers.Dense(units=1,activation='sigmoid')]
)
model.summary()
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['binary_accuracy'])
history=model.fit(ds_train,epochs=9)2025-12-28 06:59:40.835848: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:467] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1766905181.010572 24 cuda_dnn.cc:8579] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1766905181.067789 24 cuda_blas.cc:1407] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
W0000 00:00:1766905181.526749 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1766905181.526780 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1766905181.526782 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
W0000 00:00:1766905181.526785 24 computation_placer.cc:177] computation placer already registered. Please check linkage and avoid linking the same target more than once.
Found 170 files belonging to 2 classes.
I0000 00:00:1766905195.483352 24 gpu_device.cc:2019] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 15513 MB memory: -> device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0
/usr/local/lib/python3.12/dist-packages/keras/src/layers/convolutional/base_conv.py:113: UserWarning: Do not pass an `input_shape`/`input_dim` argument to a layer. When using Sequential models, prefer using an `Input(shape)` object as the first layer in the model instead.
super().__init__(activity_regularizer=activity_regularizer, **kwargs)
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ conv2d (Conv2D) │ (None, 128, 128, 32) │ 2,432 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 64, 64, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_1 (Conv2D) │ (None, 64, 64, 64) │ 51,264 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_1 (MaxPooling2D) │ (None, 32, 32, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_2 (Conv2D) │ (None, 32, 32, 128) │ 204,928 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten (Flatten) │ (None, 131072) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 8) │ 1,048,584 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 1) │ 9 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 1,307,217 (4.99 MB)
Trainable params: 1,307,217 (4.99 MB)
Non-trainable params: 0 (0.00 B)
Epoch 1/9
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1766905198.685538 70 service.cc:152] XLA service 0x7fcc28087d90 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1766905198.685575 70 service.cc:160] StreamExecutor device (0): Tesla P100-PCIE-16GB, Compute Capability 6.0
I0000 00:00:1766905199.133224 70 cuda_dnn.cc:529] Loaded cuDNN version 91002
[1m1/3[0m [32m━━━━━━[0m[37m━━━━━━━━━━━━━━[0m [1m13s[0m 7s/step - binary_accuracy: 1.0000 - loss: 0.6743
I0000 00:00:1766905203.877915 70 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m10s[0m 2s/step - binary_accuracy: 0.8226 - loss: 1.4248
Epoch 2/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - binary_accuracy: 0.1774 - loss: 0.9172
Epoch 3/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - binary_accuracy: 0.2682 - loss: 0.8156
Epoch 4/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - binary_accuracy: 0.8226 - loss: 0.5356
Epoch 5/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - binary_accuracy: 0.8226 - loss: 0.5897
Epoch 6/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - binary_accuracy: 0.8226 - loss: 0.5844
Epoch 7/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 24ms/step - binary_accuracy: 0.8256 - loss: 0.4883
Epoch 8/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 24ms/step - binary_accuracy: 0.8746 - loss: 0.3659
Epoch 9/9
[1m3/3[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 25ms/step - binary_accuracy: 0.9491 - loss: 0.2893
python
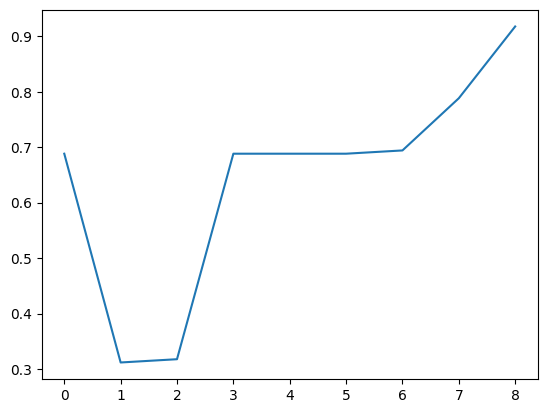
import matplotlib.pyplot as plt
plt.plot(history.history['binary_accuracy'])[<matplotlib.lines.Line2D at 0x7fcccc53ac60>]