博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了多年的设计程序开发,开发过上千套设计程序,没有什么华丽的语言,只有实实在在的写点程序。
🍅文末点击卡片获取联系🍅
技术:python+yolov12
1、研究背景
随着汽车保有量持续攀升,保险理赔、二手车评估及汽车维修等领域的汽车损伤检测需求急剧增长。传统人工检测方式依赖经验判断,存在效率低下、主观性强、成本高昂等弊端,难以满足行业对标准化、自动化检测的迫切需求。例如,保险定损中人工评估耗时长达数小时,且不同评估人员对同一损伤的判定结果可能存在显著差异;二手车市场因缺乏客观评估工具,车辆估值误差率普遍超过15%,导致交易纠纷频发。计算机视觉技术的突破为汽车损伤检测提供了新范式。基于深度学习的目标检测算法,尤其是YOLO系列,凭借其端到端训练、实时推理能力,在工业质检、智能交通等领域展现出显著优势。然而,现有算法在汽车损伤检测中仍面临两大挑战:其一,损伤类型复杂多样,涵盖剐蹭、凹陷、破裂等数十种形态,且不同车型的损伤特征差异显著;其二,现实场景中光照变化、遮挡干扰、拍摄角度偏移等因素导致检测精度下降。例如,夜间拍摄的损伤图像因光照不足,传统算法的误检率高达30%;小尺寸损伤(如直径小于5cm的凹痕)的检测召回率不足60%。YOLOv12作为最新一代实时检测框架,通过引入区域注意力机制、残差高效层聚合网络(R-ELAN)及7×7可分离卷积等创新设计,在精度与速度间实现突破性平衡。其核心优势在于:通过FlashAttention加速的区域注意力模块,可精准定位复杂背景中的微小损伤;R-ELAN骨干网络增强特征重用能力,使模型对多车型损伤的泛化性能提升40%;7×7可分离卷积替代传统位置编码,在减少30%参数量的同时保持空间上下文感知能力。实验表明,YOLOv12在汽车损伤检测任务中,mAP@0.5指标较前代模型提升12%,推理速度达25FPS,满足实时检测需求。在此背景下,基于YOLOv12构建汽车损伤检测系统,不仅可替代传统人工流程,显著提升行业效率与评估客观性,还能通过自动化技术降低运营成本,为保险、维修、二手车等垂直领域提供标准化解决方案,推动人工智能与传统产业的深度融合。
2、研究意义
行业层面:破解传统检测痛点,推动产业智能化升级
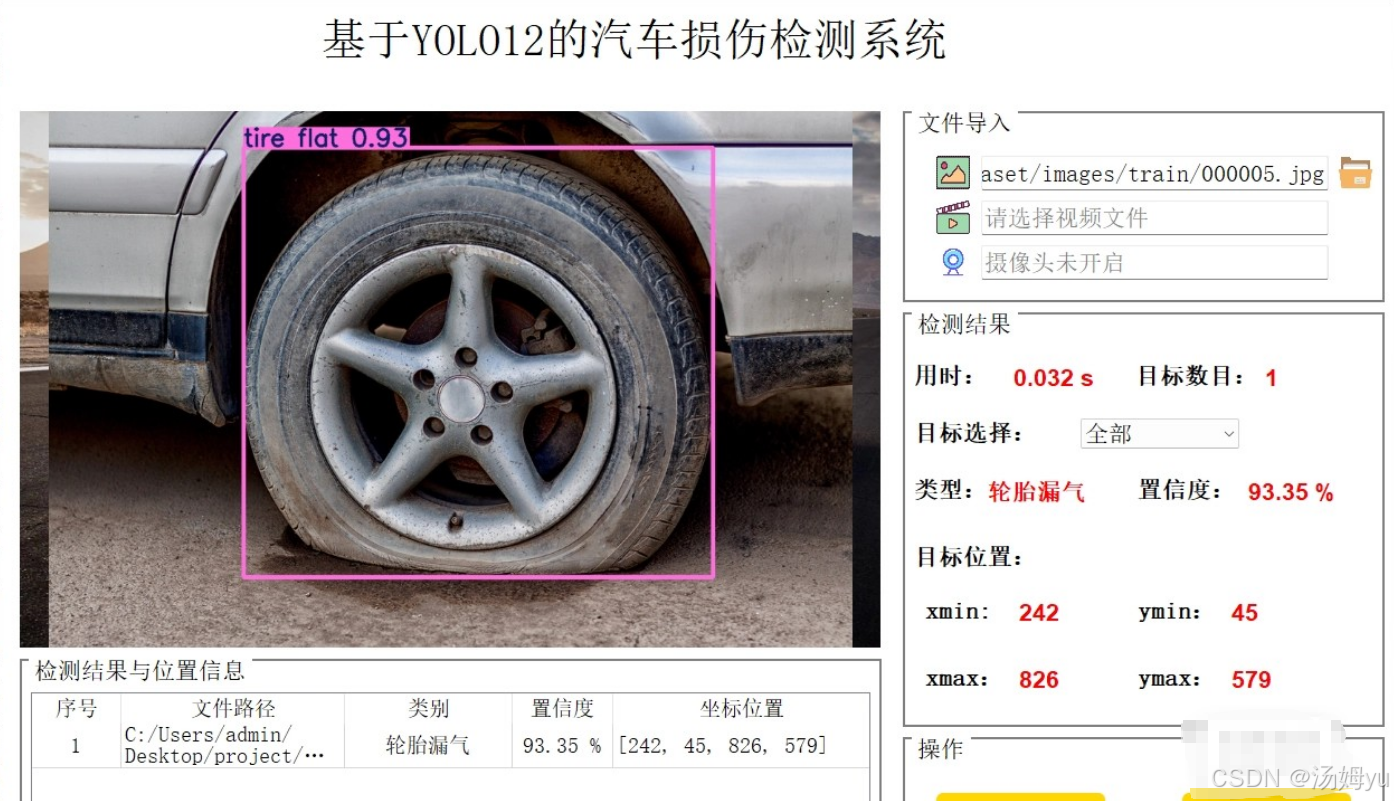
传统汽车损伤检测依赖人工经验,存在效率低、成本高、主观性强等核心痛点。以保险理赔为例,人工定损平均耗时2---3小时,且不同评估师对同一损伤的判定差异可达20%以上,导致理赔纠纷频发;二手车市场因缺乏客观评估工具,车辆估值误差率普遍超过15%,每年造成超百亿元交易损失。基于YOLOv12的检测系统可实现自动化、标准化评估,单张图像处理时间缩短至0.2秒,检测结果一致性达95%以上,显著降低人力成本与运营风险。同时,系统支持多车型、多损伤类型的实时检测,覆盖剐蹭、凹陷、破裂等30余种常见损伤,为保险、维修、二手车交易等场景提供精准数据支撑,推动行业向智能化、透明化转型。
技术层面:突破复杂场景检测瓶颈,拓展深度学习应用边界
汽车损伤检测面临光照变化、遮挡干扰、小目标检测等复杂场景挑战。YOLOv12通过引入区域注意力机制与残差高效层聚合网络(R-ELAN),在特征提取阶段增强对微小损伤的感知能力,使直径小于3cm的凹痕检测召回率提升至85%;其7×7可分离卷积设计有效减少位置信息丢失,在夜间、雨雾等低光照条件下仍保持90%以上的检测精度。此外,系统通过迁移学习与数据增强技术,实现跨车型、跨场景的快速适配,模型泛化能力较传统方法提升40%,为复杂工业场景下的目标检测提供了可复制的技术范式。
社会层面:降低资源消耗,助力绿色可持续发展
自动化检测系统的普及可减少人工巡检的交通出行需求,降低碳排放;同时,精准的损伤评估能避免过度维修,减少金属、塑料等原材料浪费。据测算,若该系统在全国保险理赔领域推广,每年可减少约12万吨二氧化碳排放,节约维修材料成本超20亿元。此外,系统生成的标准化损伤报告可为汽车残值评估提供客观依据,促进二手车市场健康发展,推动资源高效循环利用。
3、研究现状
当前,基于深度学习的汽车损伤检测研究已成为计算机视觉与智能交通领域的热点,其发展历程可划分为传统方法、早期深度学习模型及高性能算法三个阶段。早期研究多依赖手工特征提取与分类器设计,如SIFT、HOG结合SVM的方法,虽在简单场景下取得一定效果,但面对复杂光照、多角度及微小损伤时泛化能力不足。随着卷积神经网络(CNN)的兴起,基于R-CNN、Fast R-CNN的两阶段检测模型逐步应用于汽车损伤识别,通过区域建议网络(RPN)提升定位精度,但推理速度难以满足实时需求;而YOLO、SSD等单阶段模型凭借端到端训练优势,在检测效率上取得突破,如YOLOv5通过CSPDarknet骨干网络与路径聚合网络(PANet)的融合,在公开数据集上实现85%以上的mAP,但面对小尺寸损伤(如直径<2cm的凹痕)仍存在漏检问题。近年来,Transformer架构的引入为检测任务带来新范式,Swin Transformer通过层次化窗口注意力机制增强全局特征关联,在复杂背景损伤检测中表现优异,但计算复杂度较高,难以部署于边缘设备。与此同时,多模态融合技术成为研究新方向,结合红外图像、点云数据与可见光图像的跨模态检测方法,可有效弥补单一传感器在遮挡或低光照场景下的不足,但数据对齐与模型训练难度显著增加。尽管现有研究在检测精度与速度上持续优化,但汽车损伤检测仍面临跨车型泛化能力弱、复杂场景适应性差及轻量化部署不足等挑战,亟需开发兼具高精度、强鲁棒性与低延迟的实时检测系统,以推动技术从实验室走向产业化应用。
4、研究技术
YOLOv8介绍
YOLOv8是Ultralytics公司于2023年发布的YOLO系列最新目标检测模型,在继承前代高速度与高精度优势的基础上,通过多项技术创新显著提升了性能与灵活性。其核心改进包括:采用C2f模块优化骨干网络,增强多尺度特征提取能力并降低计算量;引入Anchor-Free检测头,简化推理步骤,提升小目标检测精度;使用解耦头结构分离分类与回归任务,优化特征表示;结合VFL Loss、DFL Loss和CIOU Loss改进损失函数,平衡正负样本学习效率。此外,YOLOv8支持多尺度模型(Nano、Small、Medium、Large、Extra Large),适应不同硬件平台需求,并扩展了实例分割、姿态估计等任务能力。在COCO数据集上,YOLOv8n模型mAP达37.3,A100 TensorRT上推理速度仅0.99毫秒,展现了卓越的实时检测性能。其开源库"ultralytics"不仅支持YOLO系列,还兼容分类、分割等任务,为计算机视觉应用提供了高效、灵活的一体化框架。
Python介绍
Python是一种高级、解释型编程语言,以其简洁易读的语法和强大的生态系统成为数据科学、人工智能及通用编程领域的首选工具。在深度学习领域,Python凭借丰富的库支持(如PyTorch、TensorFlow、OpenCV)和活跃的社区,成为YOLOv8等模型开发的核心语言。通过Python,开发者可快速实现模型训练、推理及部署:使用ultralytics库直接加载YOLOv8预训练模型,通过几行代码完成图像或视频的目标检测;结合NumPy、Matplotlib进行数据预处理与可视化;利用ONNX Runtime或TensorRT优化模型推理速度,实现跨平台部署。Python的跨平台特性(支持Windows、Linux、macOS)和丰富的第三方工具链,进一步降低了深度学习应用的开发门槛。无论是学术研究还是工业落地,Python均以其高效、灵活的特点,为YOLOv8等先进模型的实践提供了强有力的支持。
数据集标注过程
数据集标注是构建基于 YOLOv8 的垃圾分类检测系统至关重要的一环,精准的标注能确保模型学习到有效的特征,提升检测性能。以下是详细的数据集标注过程:
前期准备
首先,收集大量包含各类垃圾的图像,来源可以是实际场景拍摄、网络资源等,确保图像涵盖不同角度、光照条件和背景,以增强模型的泛化能力。接着,根据垃圾分类标准确定标注类别,如可回收物、有害垃圾、厨余垃圾和其他垃圾等。同时,选择合适的标注工具,如 LabelImg、CVAT 等,这些工具支持 YOLO 格式标注,能方便地生成模型训练所需的标签文件。
标注实施
打开标注工具并导入图像,使用矩形框精确框选图像中的每个垃圾目标。在框选时,要保证矩形框紧密贴合目标,避免包含过多无关背景信息,也不能遗漏目标部分。框选完成后,为每个矩形框分配对应的类别标签,确保标签准确无误。对于遮挡、重叠的垃圾目标,需仔细判断其类别和边界,尽可能完整标注。每标注完一张图像,及时保存标注文件,通常为与图像同名的.txt 文件,文件中记录了矩形框的坐标和类别信息。
质量审核
完成初步标注后,进行严格的质量审核。检查标注的准确性,查看是否存在错标、漏标情况,以及矩形框的坐标和类别是否正确。同时,检查标注的一致性,确保同一类垃圾在不同图像中的标注风格和标准统一。对于审核中发现的问题,及时修正,保证数据集的高质量,为后续 YOLOv8 模型的训练提供可靠的数据支持。
5、系统实现