今天刷Java技术博文时,看到结构化并发的相关知识,突然好奇"结构化并发"这个名字的由来。带着这份好奇,我百度google了一下,总算把来龙去脉理清楚了,今天就分享给大家~
"结构化"的源头------结构化编程
要弄明白"结构化并发",得先回到它的"老祖宗"------结构化编程。咱们程序员天天写代码,其实早就被结构化编程"驯化"了,只是平时没特意留意。

早在上世纪50年代,编程还是"野蛮生长"的状态。那时候的程序员全靠goto语句跳转代码,就像在迷宫里乱闯:想从A处跳到B处?加一句goto B;想跳过C处代码?再加一句goto D。最后写出来的代码,跳转逻辑缠成一团,被业界戏称为"面条代码 "------就像一碗没拌开的杂酱面,根根面条缠在一起,想挑出一根完整的都难。后来有人统计,那时候超过30%的调试时间,都花在理清goto跳转逻辑上。
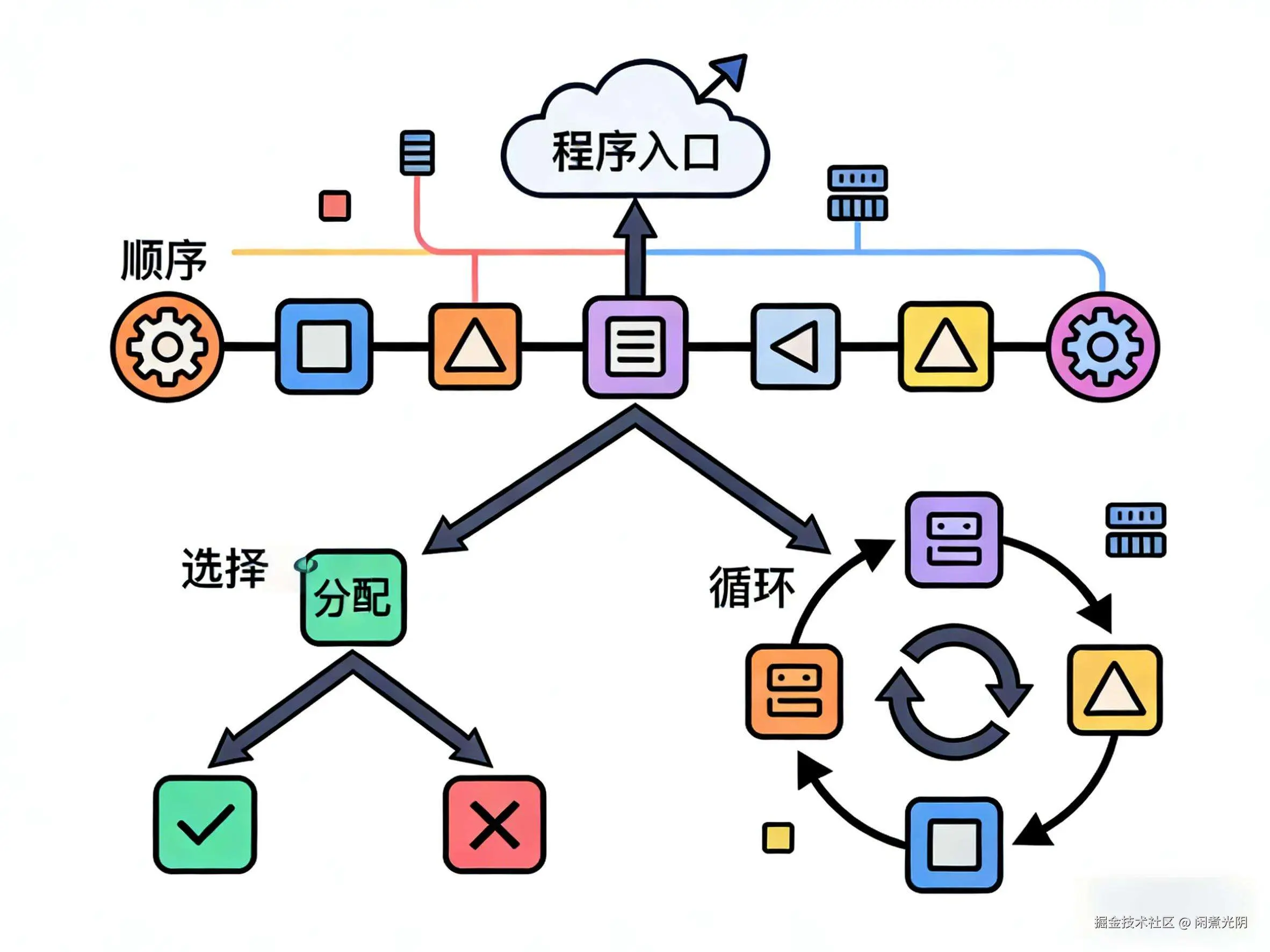
直到1968年,计算机科学家迪杰斯特拉(Edsger Dijkstra)发表了一篇影响深远的短文《Go To Statement Considered Harmful》(《GOTO语句有害论》),直接点燃了"结构化编程革命"。他提出:不用goto也能实现所有程序逻辑,只要用"顺序、选择(if/else)、循环(for/while)"三种基础结构就行 。 
这就像咱们整理房间:以前东西随便放,找的时候翻遍全屋(对应goto乱跳转);现在用抽屉、柜子分类收纳(对应三种控制结构),每个东西都有固定位置,拿取、整理都清晰。咱们现在写的代码,其实都在遵循这个逻辑,比如这段最基础的Java代码:
java
// 结构化编程典型示例
public class StructuredCode {
public static void main(String[] args) {
// 顺序结构:按顺序执行
int a = 10;
int b = 20;
// 选择结构:if/else 有明确分支边界
if (a + b > 25) {
System.out.println("总和大于25");
} else {
System.out.println("总和不大于25");
}
// 循环结构:for循环有明确循环边界
for (int i = 0; i < 3; i++) {
System.out.println("循环第" + (i+1) + "次");
}
}
}这段代码里,每个逻辑块都有明确的"入口"和"出口":if块执行完才会走后续代码,for循环跑完才会结束程序,没有任何无规则的跳转。这就是结构化编程的核心:用"代码块结构"约束"执行流程",让逻辑变得可预测、可追溯。
简单总结下结构化编程的三个关键特点:
- 有明确的块级边界,内层块执行完才进外层块;
- 错误会自然向外层传导,比如if块里抛异常,能直接被外层try-catch捕获;
- 外层逻辑管控内层逻辑,没有"无主逻辑"。
结构化并发=把"结构化思想"搬进并发场景
搞懂了结构化编程,再看"结构化并发"就简单了------它本质就是把结构化编程的"收纳逻辑",从"顺序代码"搬到了"并发任务"里。

咱们先回想下传统并发编程的"痛点"。以前用线程池写并发,就像给一群小朋友分配任务,你喊他们去做事,转头就不知道谁做完了、谁跑丢了(对应"野线程")。比如这段传统并发代码:
java
// 传统非结构化并发:容易出现"野线程"
public class UnstructuredConcurrency {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(2);
// 提交子任务1
executor.submit(() -> {
try {
Thread.sleep(1000);
System.out.println("子任务1完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// 提交子任务2
executor.submit(() -> {
try {
Thread.sleep(2000);
System.out.println("子任务2完成");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// 主线程直接结束,不管子任务是否完成
executor.shutdownNow();
System.out.println("主线程结束");
}
}这段代码里,主线程提交完子任务就直接 shutdown 线程池,很可能子任务还没执行完就被强制中断,甚至出现子任务执行到一半没人管的"孤儿线程 "------就像你提前下班,把没做完事的小朋友丢在原地,后续怎么清理资源、怎么处理异常都成了难题。这就是非结构化并发的问题:并发任务没有明确的"归属"和"边界",管控混乱。

而结构化并发,就是给并发任务加上"收纳盒"------让父任务像"家长"一样,管着所有子任务,必须等所有子任务都完成(或者处理完异常),父任务才会结束。这和结构化编程里"内层块跑完才进外层块"的逻辑完全一致!
咱们用Java Project Loom(结构化并发的Java实现)写一段对应代码,感受下这种"结构化":
java
// 结构化并发:父任务管控子任务,边界清晰
public class StructuredConcurrency {
public static void main(String[] args) throws Exception {
// 结构化并发核心:用StructuredTaskScope创建"任务作用域"(相当于"收纳盒")
try (StructuredTaskScope<Void> scope = new StructuredTaskScope.ShutdownOnFailure()) {
// 提交子任务1:归属于scope这个"收纳盒"
scope.fork(() -> {
Thread.sleep(1000);
System.out.println("子任务1完成");
return null;
});
// 提交子任务2:同样归属于scope
scope.fork(() -> {
Thread.sleep(2000);
System.out.println("子任务2完成");
return null;
});
// 父任务等待所有子任务完成(相当于"家长等所有小朋友做完事")
scope.join();
// 处理异常:子任务异常会自动传导给父任务
scope.throwIfFailed();
}
// 所有子任务完成+异常处理完,父任务才结束
System.out.println("主线程结束");
}
}这段代码里,StructuredTaskScope就是结构化编程里的"代码块",所有子任务都被"装"在这个作用域里:父任务必须等scope.join()执行完(也就是所有子任务完成),才会继续往下走;如果任何一个子任务抛异常,会直接传导给父任务,通过scope.throwIfFailed()统一处理------这和结构化编程里"内层异常向外层传导"的逻辑一模一样!
这里给大家做个通俗的类比,一下子就能分清两者的关系:
- 结构化编程:就像你按步骤煮一碗面,必须等水烧开(内层块),才能下面条(外层后续逻辑),如果水烧糊了(异常),会直接影响后续煮面步骤;
- 结构化并发:就像你请朋友来家里吃饭,要做三道菜(三个子任务),必须等所有菜都做好(所有子任务完成),才能喊朋友开吃(父任务继续),如果其中一道菜炒糊了(子任务异常),你得先处理好(父任务统一处理异常),再决定要不要继续开饭。
回到最初的问题:"结构化并发"名字的由来
看到这里,大家应该能猜到名字的由来的:"结构化并发"的"结构化",直接借用了"结构化编程"的核心思想------用"结构"约束"行为"。
结构化编程用"代码块结构"约束"顺序执行流程",解决了"面条代码"的混乱问题;结构化并发则用"父子任务的作用域结构"约束"并发任务生命周期",解决了"野线程、资源泄漏"的混乱问题。两者的核心逻辑完全同源,都是"内层归外层管控、内层完成外层才继续、异常逐层传导"。
这里还有个小彩蛋:Java里实现结构化并发的Project Loom,名字也藏着巧思。"Loom"是"织布机"的意思,而结构化并发的核心载体是"纤程(Fiber)"------"纤维(Fiber)"通过"织布机(Loom)"编织成布匹,就像分散的并发任务通过结构化机制,被编织成逻辑清晰、可管控的并发体系。这个名字是Java语言架构师Brian Goetz提议的,他在2018年JavaOne演讲里提到:"We wanted a name that evokes weaving threads together. Loom is a weaving machine, and fibers are what you weave. So Project Loom felt natural."(我们想要一个能唤起"编织线程"意象的名字,织布机是编织工具,纤程是编织的材料,所以Project Loom这个名字很自然。)
最后总结:这个名字背后的价值
其实"结构化并发"的命名,不只是简单的"借词",更体现了软件设计的核心思路------用成熟的思想解决新场景的问题。
结构化编程让顺序代码从"混乱"走向"有序",奠定了现代编程的基础;结构化并发则让并发编程从"难管控"走向"可预测",降低了并发开发的门槛 。对于咱们程序员来说,理解这个名字的由来,不只是多知道一个"编程冷知识",更能帮我们抓住结构化并发的核心逻辑------本质就是用写顺序代码的思维写并发,不用再天天担心线程跑丢、资源没清理的问题。
不知道大家平时写并发代码时,有没有遇到过"野线程"的坑?如果之前对结构化并发没概念,看完这篇是不是觉得清晰多了?欢迎在评论区交流~