P4简介
前言
P4C作为一个编译器自然是给P4语言服务的,那么首先先要通过实例搞清P4的语法,然后还得了解P4编译器怎么用,此外还必须对Linux常用的网络方面的命令得熟悉,然后跑起来。总之重点是理解他。
P4 Exercise
P4 准备工作
在进行实例之前,还是先需要继续扩充背景知识,然后这有个教程:P4language官方github教程, 我发现这里有Vagrantfile, 也就是这个教程给我们把环境配置好了,对我自己来说,我更希望在自己的云服务器上部署,而不是使用虚拟机,因为这样会占用本地的资源,,我还得打游戏。。
那就照着Vagrantfile里面的命令在本地安装环境好了,我主要是参考了user-dev这个bash脚本。
这个脚本安装了几样东西,分别是Protobuf,gRPC,Bmv2,Ptf, 我觉得如果还是有必要先搞清楚他们都是干啥的。
- gRPC
gRPC首先它得是一种RPC,RPC(Remote Procedure Call), 说白了就是IPC是远程版本,就是远程调用接口,要在本地调用远程的函数,那么他在思想上和Restful就是不一样的,Rest(Representional State Transfer),重点还是关注数据的抽象。一个是面向函数的,解决跨服务器函数的调用,一个是面向远程资源的,面向数据的。具体的解释可以参考RPC和Restful的区别。 RPC通信也有序列化的需求,这时候需要使用一个中间层,那gPRC就是使用的protocol buffers也就是在安装中碰见的protobuf。推荐去看这里的前面原文以及原文对应的书籍(原文中有,知乎也有电子版)。
- Protobuf
Protobuf通信协议详解:代码演示、详细原理介绍等 - 知乎 (zhihu.com)这篇文章足足够。
- Bmv2
P4编程理论与实践------理论篇-阿里云开发者社区 (aliyun.com)看这个。
这个直接开Tutorial介绍就可以大概了解:
PTF is a Python based dataplane test framework. It is based on unittest, which is included in the standard Python distribution.
P4 原理
在开始具体的Tutorial学习之前,还是得先搞明白P4总体结构。前面我们已经知道了P4程序是用来解决数据平面的问题的,交换机等硬件保证物理上能够联通,P4做的事就是让不同的交换机都能够执行控制平面的协议。我们用软件描述协议,用软件取代了专用的芯片(AISC),就好比我们没有把数据库直接设计成芯片,虽然这样可以保证更好的性能,但是更新换代以及开发的工作就会变得很困难,P4的存在就可以让我们加快网络的更新速度,取而代之的是,肯定是要慢一些,所以一般只用来进行学术上的交流,交换机只要能够和P4打交道就行了。大体上就做了这么个事。
P4的论文:(Programming Protocol-Independent Packet Processors)1312.1719.pdf (arxiv.org)
下图就比较清楚的展示了P4的地位和作用,首先大背景是软件定义网络,其次是用来替代传统openflow,openflow是一个协议,Swtich需要硬件支持openflow,控制器也需要按照openflow的规则填充对应的值,在ASIC电路中,Control Plane就差不多是状态机的地位,Openflow就是ASIC设计的那些使能复位等等功能端口,Dataplane提供具体的时序电路和组合电路。P4现在要推翻这一套,Switch就是CPU,P4就是C语言(看起来也像是C语言改的),编译器编译成汇编,Switch不需要具体知道用的P4的代码是做什么,跑就完事了。这样Switch就不需要看到一个协议就需要更新一下硬件,从ASIC变到CPU了。

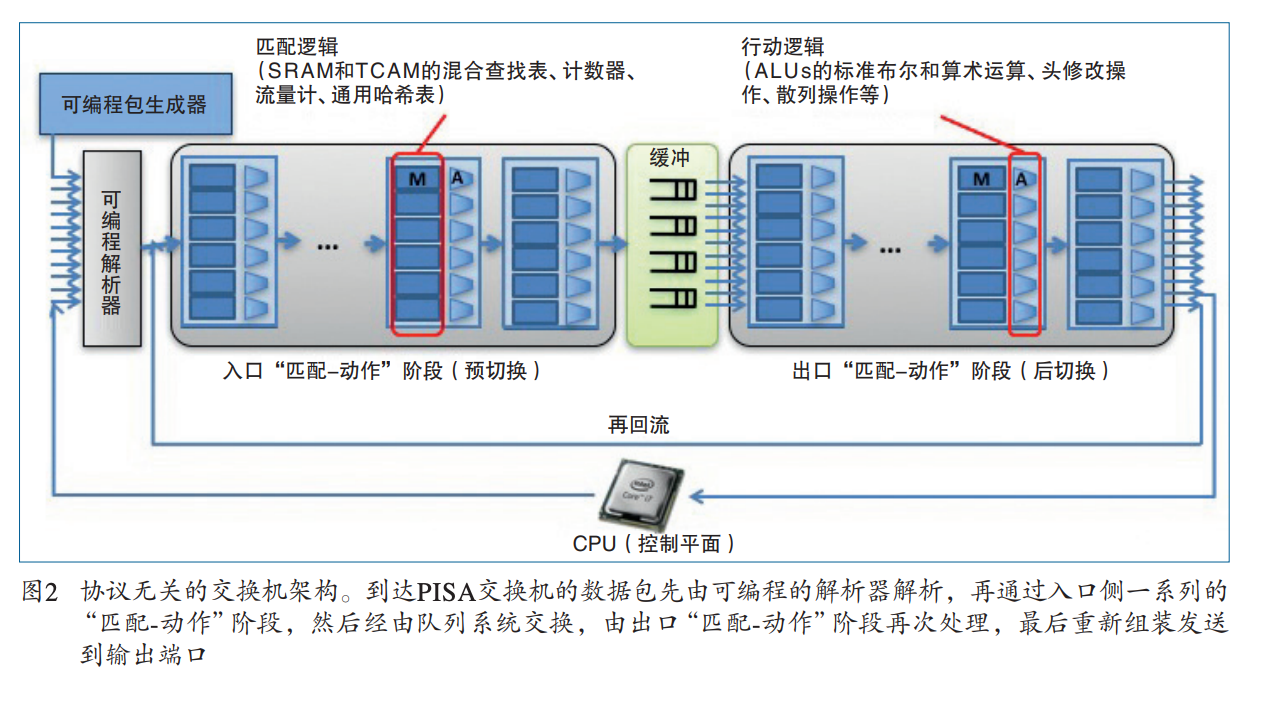
Fig.1 P4 Controll Switch
图2的Forward模型有两个Operation:Configure(配置)和Populate(填充), 配置操作对解析器进行编程,设置匹配+动作阶段的顺序,并指定每个阶段处理的头域。配置决定了哪些协议被支持以及交换机如何处理数据包。填充操作向配置期间指定的匹配+动作表添加(和删除)条目。配置决定了在任何给定时间应用于数据包的策略。 通常都是假设配置和填充是两个不同的阶段。特别是,交换机在配置期间不需要处理数据包。 然而,作者希望在部分或全部重新配置期间,实现数据包的处理,使升级没有停机时间。所以P4的forward模型特意允许并鼓励不中断转发的重新配置。
显然,如果对应功能固定的ASIC交换机,那么P4的配置就意义不大,那么P4编译器的主要工作就是检查芯片是否支持P4。到达的数据包首先由解析器处理。数据包主体被认为是buffer separately的,不可用于匹配。解析器识别并从包头中提取字段,从而定义了交换机所支持的协议。该模型对协议头的含义不做任何假设,只是解析后的表述定义了匹配和操作的字段的集合。提取的头字段然后被传递给match+action表。Match+Action表被分为入口和出口。虽然两者都可以修改数据包头,但入口处的Match+Action决定了出口端口,并决定了数据包被放入的队列。 根据入口处理,数据包可以被转发、复制(用于多播、跨度或控制平面)、丢弃或触发流量控制。出口Match+Action对数据包头进行每个实例的修改--例如,用于多播复制。Action表(Counter, Policers等)可以与流相关联,以跟踪帧到帧的状态。
这一部分内容,可以参考其他作者的说明:P4 学习笔记(一)- 导论 - 知乎 (zhihu.com)
Parser:先看看包里面都有啥,每一个 bit 都是什么; Ingress:一堆 Match-Action 的流水线,看看哪些 bits 组成的 fields 有没有我们想要的,比如目标 IP 是不是 8.8.8.8,是的话就改写一下 header 让包能被转发到它该去的地方; Switching Logic:还要有个地方实现我们想要的逻辑,或者为了高性能,放一个 buffer,存放刚被上一个环节处理完,准备给下一个环节处理的包 1; Egress:又来一堆 Match-Action 的流水线,比如改写源 MAC 地址,同时提供更多对网络包的操作空间; Deparser:最后把我们改写好的 headers 重新写回网络包,然后送它出去。
数据包也包括一些元数据用于描述这个数据包,比如这个包是什么时间进来的,从哪个端口进来的等等。当然,这个元数据并不会改变包本身的一些元数据,例如VNI:网络虚拟化协议GENEVE - 知乎 (zhihu.com)。控制寄存器/信号在P4中被表示为内在的元数据。P4程序也可以存储和操作与每个数据包有关的数据,作为用户定义的元数据。当匹配完成后,数据包也会像Openflow协议一样进到队列当中,也会依据特定的service discipline分配包:QoS队列调度算法 - realJianhao - 博客园 (cnblogs.com)。P4也同样支持ECN:显式拥塞通知-Explicit Congestion Notification(ECN) - 知乎 (zhihu.com)。
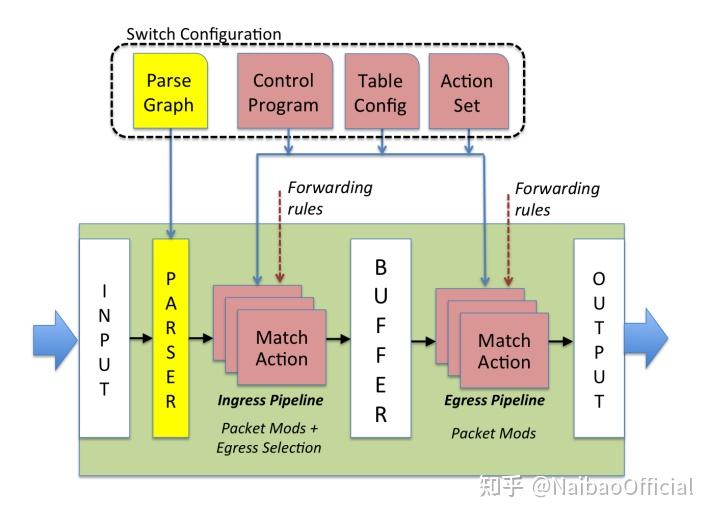
Fig.2 The abstract forwarding model
P4 语法
数据包处理语言必须允许程序员表达(隐含地或明确地)表头字段之间的任何串行依赖关系。依赖关系决定了哪些表可以被并行执行。例如,由于IP路由表和ARP表之间的数据依赖性,需要顺序执行。依赖关系可以通过分析表依赖图(TDG, Table Dependecny Graph)来确定;这些图描述了表之间的字段输入、动作和控制流。
下图就是一个L2/L3交换机的依赖图,TDG节点直接映射到匹配+动作表,并通过依赖性分析来确定每个表在管道中的位置。 不幸的是,大多数程序员不容易接触到TDG;程序员倾向于使用命令式结构而不是图形来考虑数据包处理算法。
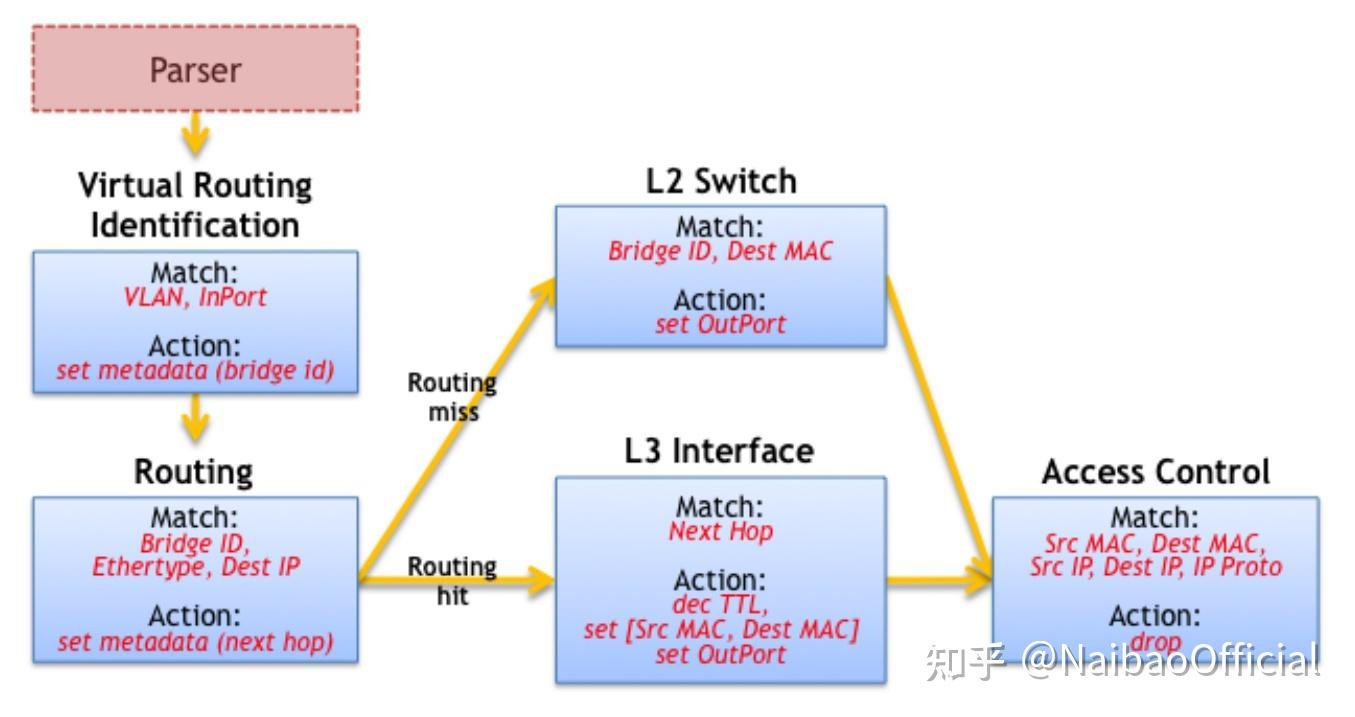
Fig.3. TDG for an L2/L3 switch
那么一般开发流程就变成了2步compilation process,开发者表述包的处理流程,这部分用P4,然后编译器将P4代码编译成TDGs以方便依赖性分析(facilitate dependency analysis),然后将TDG映射到具体的交换机目标。
论文中详细讲解了一个简单的例子,网络中有边缘网络和核心网络,终端(end hosts)都是连接在边缘上(edge devices), 终端和核心通过高带宽互联,整个协议会设计成支持MLPS(MPLS基础 - 知乎),和Portland(译文:PortLand:A Scalable Fault-Tolerant Layer 2 Data Center Network Fabric_portland).
考虑一个L2网络部署的例子,在边缘有顶部机架(ToR)交换机,由一个两层的核心连接。我们将假设终端主机的数量在增长,核心的L2表已经溢出了。MPLS是简化核心的一个选择,但实现一个具有多个标签的标签分配协议是一项艰巨的任务。PortLand看起来很有趣,但需要重写MAC地址--可能会破坏现有的网络调试工具,而且需要新的代理来响应ARP请求。 P4让我们可以在对网络架构进行最小改动的情况下表达一个自定义的解决方案。
上文中提到的TOR可以参考以下两个资料,如有需要。
了解接入层、汇聚层、核心层交换机 - 知乎 (zhihu.com)
从EOR与TOR架构谈EOR与TOR交换机 - 知乎 (zhihu.com)
论文中的例子称为mTag:它结合了PortLand的分层路由和简单的类似MPLS的Tag。通过核心的路由是由四个单字节字段组成的32位Tag来编码的。32位Tag可以携带 "源路由 "或目的地定位器(像PortLand的Pseudo MAC)。每个核心交换机只需要检查标签的一个字节,并根据该信息进行切换。 在我们的例子中,标签是由第一个ToR交换机添加的,尽管它也可以由终端主机网卡添加。 mTag的例子比较简单,使我们的注意力集中在P4语言上。整个交换机的P4程序在实践中会复杂很多倍。
P4在概念上有以下核心组件:
- Headers: Headers定义描述了一系列字段的顺序和结构。它包括对字段宽度和字段值的限制的说明。有点类似与C的Struct。Header的定义可以参考其他协议中的来,例如以太网:

Fig.4. UDP+以太网协议的数据包
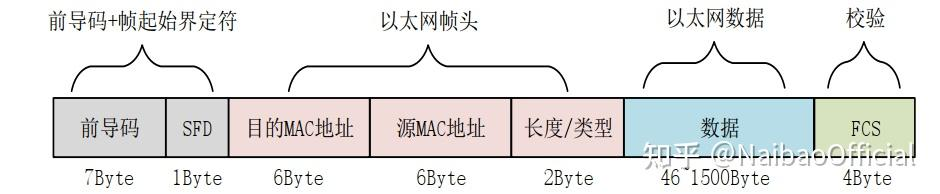
Fig.5 MAC层的帧结构
Fig.5 就包括以太网帧头的定义,因为以太网是使用MAC地址进行转发的,所以目的地址和源地址都是MAC地址。这在P4中的写法如下:
header ethernet {
fields {
dst_addr : 48; // width in bits
src_addr : 48;
ethertype : 16;
}
} 论文中还举了VLAN的例子,VLAN就是虚拟的局域网,说白了就是给局域网分组,那么自然也需要多加几个比特提供相应的信息(这是根据信息论的必然结果),那么,VLAN的帧头结构如下所示:
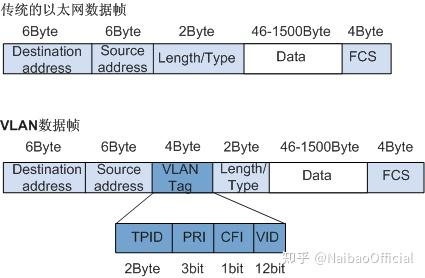
Fig.6 VLAN的帧头结构
对应P4代码如下,这看起来跟C/C++没啥区别。
headervlan{
fields{
pcp:3;
cfi:1;
vid:12;
ethertype:16;
}}那么文中的mtag结构因为是自己定义的,所以这里就直接列出来了,我暂时也搞不清具体是怎么运作的。
/* 可以在不改变现有声明的情况下添加mTag头。字段名表示核心有两层聚合。 * 每个核心交换机都被编入规则,以检查这些字节中的一个,由其在层次结构 * 中的位置和移动方向(向上或向下)决定。 */headermTag{
fields{
up1:8;
up2:8;
down1:8;
down2:8;
ethertype:16;
}}- Parsers: 解析器的定义规定了如何识别数据包内的头和有效的头序列。P4假设下层的交换机可以实现一个状态机,这个状态机可以完成数据包头的遍历,在遍历的同时提取需要的值。然后将提取出来的值送给Match+Action模块。 P4将这个状态机直接描述为从一个头到下一个头的转换集合。每个转换都可以由当前头中的值触发。例如,我们对mTag状态机的描述如下:
// Parser后面就是状态的名称,这里虽然是结构体的语法,但是确实jmp的实现// case后面我猜测就是根据跳转到对应状态,并按照header进行解析// 因为Parsers和Headers的name是能对应上的parserstart{
ethernet;// 下一个状态就是ethernet}parserethernet{
switch(ethertype){//根据ethertype的值跳转 case0x8100:vlan;
case0x9100:vlan;
case0x800:ipv4;
// Other cases }}parservlan{
switch(ethertype){
case0xaaaa:mTag;
case0x800:ipv4;
// Other cases }}parsermTag{
switch(ethertype){
case0x800:
// Other cases }}解析从开始状态开始,一直进行到达到一个明确的停止状态或遇到一个未处理的情况(可能被标记为错误)。当 达到一个新的头的状态时,状态机使用其规范提取头并继续确定其下一个转换。提取的头被转发到Pinpline的Match+Action表中。mTag的解析器非常简单:它只有四个状态。 实际网络中的解析器需要更多的状态。
Tables: Match+Action是执行数据包处理的机制。P4程序定义了一个表可以Match的字段和可以执行的Action。 在mTag例子中,边缘交换机在L2的destination和VLAN ID上进行匹配,并选择一个mTag来添加到头中。开发者定义了一个表来匹配这些字段并应用一个动作来添加mTag头(见下文)。reads属性声明了要匹配的字段,由匹配类型限定(exact,ternary, etc)。actions属性列出了可能被表应用于数据包的actions, 下面就会说到Action。max_size属性指定了该表应该支持多少个条目。Table的规格允许编译器决定它需要多少内存,以及实现表的内存类型(例如,TCAM或SRAM)。 这里稍微啰嗦一下,SRAM就是用的双稳态触发器(核心器件是一个6管的SR锁存器),一般被用在Cache中,因为全是晶体管,所以成本还是很高的。我们常用的内存是DRAM,D就是Dynamic,相对的S就是Static,这个D不是代表用D触发器,而是用电容动态表示1和0,所以内存一般比较大,没法做在CPU里,但是成本低,稍微慢一点。TCAM(Ternary Content AddressableMemory)是三态的CAM寻址器。一般用来做路由表的存储器。
tablemTag_table{
reads{
ethernet.dst_addr:exact;
vlan.vid:exact;
}
actions{
// At runtime, entries are programmed with params // for the mTag action. See below. add_mTag;
}
max_size:20000;}/* 为了完整性讨论,这里一次性将控制程序需要的Table先列出,并给与简单定义 */tablesource_check{
// Verify mtag only on ports to the core reads{
mtag:valid;// Was mtag parsed? metadata.ingress_port:exact;
}
actions{// Each table entry specifies *one* action // If inappropriate mTag, send to CPU fault_to_cpu;
// If mtag found, strip and record in metadata strip_mtag;
// Otherwise, allow the packet to continue pass;
}
max_size:64;// One rule per port}tablelocal_switching{
// Reads destination and checks if local // If miss occurs, goto mtag table.}tableegress_check{
// Verify egress is resolved // Do not retag packets received with tag // Reads egress and whether packet was mTagged}可以看出,Table也只是描述了对应的准则,具体的表项还没有添加。
- Actions: P4支持从较简单的、与协议无关的基元构建复杂的动作。这些复杂的动作可以在match+action表中使用。 P4定义了一个原始行动的集合,从中可以建立更复杂的Action,每一个P4程序都声明了一组由Action Primitives组成的Action Functions。这些Action Functions简化了Table的规格和数量。P4假设每一个Action Function中的Action Primitives都是并行执行的(Switch不支持并行运算的话可以模拟语义)。 上面提到的添加mTag动作是这样实现的:
actionadd_mTag(up1,up2,down1,down2,egr_spec){
add_header(mTag);
// Copy VLAN ethertype to mTag copy_field(mTag.ethertype,vlan.ethertype);
// Set VLAN’s ethertype to signal mTag set_field(vlan.ethertype,0xaaaa);
set_field(mTag.up1,up1);
set_field(mTag.up2,up2);
set_field(mTag.down1,down1);
set_field(mTag.down2,down2);
// Set the destination egress port as well set_field(metadata.egress_spec,egr_spec);}如果一个动作需要参数(例如,mTag的up1值),则在运行时从匹配表中提供。 在这个例子中,交换机在VLAN标签之后插入mTag,将VLAN标签的ethertype复制到mTag中以表示后面的内容,并将VLAN标签的ethertype设置为0xaaaa以示mTag。未显示的是将mTag从数据包中剥离的反向动作规范和在边缘交换机中应用该动作的Table。
P4的primitive actions包括(这部分还是看英文原文比较好): •set_field: Set a specific field in a header to a value. Masked sets are supported. •copy_field:Copy one field to another. •add_header:Set a specific header instance (and all its fields) as valid. •remove_header:Delete ("pop") a header (and all its fields) from a packet. •increment:Increment or decrement the value in a field. •checksum:Calculate a checksum over some set of header fields (e.g., an IPv4 checksum).
- Control Programs: 控制程序决定了应用于数据包的Match + Actions的顺序。一个简单的命令式程序描述了Match + Actions之间的控制流。一旦表和动作被定义,剩下的唯一任务就是指定从一个表到下一个表的控制流。控制流通过函数、条件和表的引用的集合被指定为一个程序。
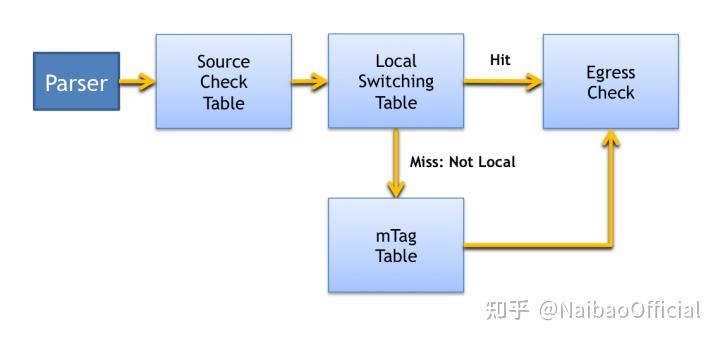
Fig.7. Control Flow for m_tag example
图7显示了边缘交换机上mTag实现所需的控制流程的图形表示。 在解析之后,源检查表验证了收到的数据包和入口端口之间的一致性。例如,mTags应该只出现在连接到核心交换机的端口上。source_check还从数据包中剥离(strip_mtag这个action论文中并没有给出) mTags,记录数据包的元数据中是否有mTag。Pipeline中稍后的表可以在这个元数据上进行匹配,以避免对数据包进行重新标记。 然后执行local_switching。如果该表 "miss",则表明该数据包不是以本地连接的主机为目的地的。在这种情况下,mTag Table将应用于该数据包。本地和核心转发控制都可以由egress_check表处理,该表通过向SDN控制栈发送通知来处理未知目的地的情况。 这个数据包处理Pipeline的命令式表示如下:
controlmain(){
// Verify mTag state and port are consistent table(source_check);
// If no error from source_check, continue if(!defined(metadata.ingress_error)){
// Attempt to switch to end hosts table(local_switching);
if(!defined(metadata.egress_spec)){
// Not a known local host; try mtagging table(mTag_table);
}
// Check for unknown egress state or // bad retagging with mTag. table(egress_check);
}}P4 编译
编辑就是将上面的P4语言代码编译成各个软硬件交换机都支持的程序。可以看到,编译器会编译出来两个程序,一个是Dataplane Runtime,一个是API。
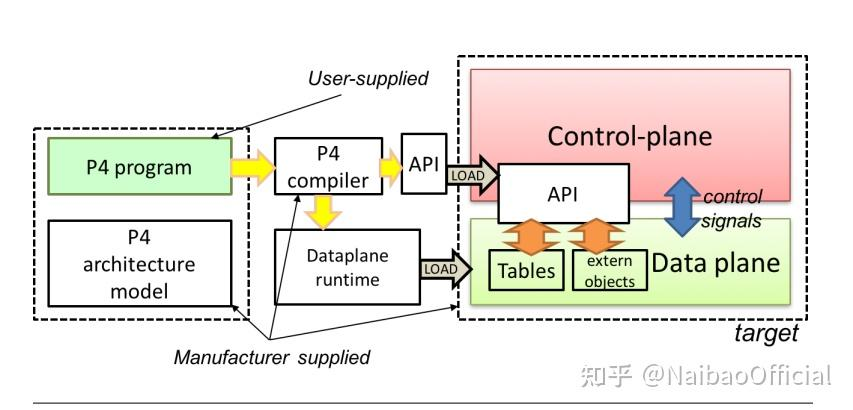
Fig.8. . Programming a target with P4
Parsers阶段的代码就会被转换成状态机。vlan和mTag的解释器转换后如下表所示。每一个状态下都会根据匹配的值进行状态跳转

Table 1: State Machine
对于Control程序,上面的写法没有精确的指出表之间的依赖关系以及可能的并发情况,因此,编译器会尽力优化这个过程。最后编译器会生成交换机识别的目标文件。交换机target有很多,比如软件交换机,多核软件交换机,NPU,fix function交换机,或者RMT(Reconfigurable match table) Pipeline交换机。【开源】手把手教你写支持RMT架构的P4语言后端编译器!-面包板社区 (eet-china.com)
RMT论文的摘要:In Software Defined Networking (SDN) the control plane is physically separate from the forwarding plane. Control software programs the forwarding plane (e.g., switches and routers) using an open interface, such as OpenFlow. This paper aims to overcomes two limitations in current switching chips and the OpenFlow protocol: i) current hardware switches are quite rigid, allowing ``Match-Action'' processing on only a fixed set of fields, and ii) the OpenFlow specification only defines a limited repertoire of packet processing actions. We propose the RMT (reconfigurable match tables) model, a new RISC-inspired pipelined architecture for switching chips, and we identify the essential minimal set of action primitives to specify how headers are processed in hardware. RMT allows the forwarding plane to be changed in the field without modifying hardware. As in OpenFlow, the programmer can specify multiple match tables of arbitrary width and depth, subject only to an overall resource limit, with each table configurable for matching on arbitrary fields. However, RMT allows the programmer to modify allheader fields much more comprehensively than in OpenFlow. Our paper describes the design of a 64 port by 10 Gb/s switch chip implementing the RMT model. Our concrete design demonstrates, contrary to concerns within the community, that flexible OpenFlow hardware switch implementations are feasible at almost no additional cost or power.
正如前面所提到的两阶段编译一样,首先先转化成TDG(前面提到过)并对其进行分析以确定表之间的依赖关系。然后,一个特定目标的后端将这个图映射到switch的特定资源上,论文详细论述了针对各个交换机target编译器所作的工作,这里就不列举了。
到此为止,我们就对P4的工作流程有了大致的了解,我没还是没有一个成功的示例让他跑起来,接下来就进一个示例,我的工作重点在p4 runtime,所以会多看几个tutorial。
Basic Forwarding
tutorials/exercises/basic at master · p4lang/tutorials (github.com)README文件中说明了大体情况,以及如果我们跟着教程继续完成编写会发生什么,但是basic蕴含的文件是特别的多的,更让我好奇的是,p4是怎么和mininet集成的,makefile是如何完成编译的。P4 tutorials 实例分析---basic - 知乎 (zhihu.com)这边文章对Basic教程的内容做了比较详尽的说明。下面我将按照我自己的思路自己分析
basic下的makefile比较简单:
我们要执行的target是run:也就是make run
BMV2_SWITCH_EXE= simple_switch_grpcTOPO= pod-topo/topology.json
include../../utils/Makefile大头在../../utils/Makefile里面, 我们使用make run -n就可以查看具体执行了哪些动作。
lighthouse@VM-0-5-ubuntu:~/downloads/tutorials/exercises/basic$ make run -n
mkdir -p build pcaps logs# p4runtime-file是描述控制平面的API文件# basename从文件名序列“NAMES…”中取出各个文件名的前缀部分,即*.p4.p4info.txt# $@ 传给脚本的所有参数的列表# P4编译过程中需要一个p4.p4info.txt, 这部分是P4 Runtime的东西:# P4Info:元数据,指定了可以通过P4Runtime访问的P4实体。这些实体与P4源代码中的实例化对象有一对一的对应关系。# 这个文件也是解析出来的,因为build文件夹需要创建。
p4c-bm2-ss --p4v 16 --p4runtime-files build /basic.p4.p4info.txt -o build /basic.json basic.p4
sudo python3 ../../utils/run_exercise.py -t pod-topo/topology.json -j build /basic.json -b simple_switch_grpc可以看到首先编译了basic.p4,编译的输出在build/basic.json以及Runtime的basic.p4.p4info.txt,然后将basic.json导入到python的run_exercise.py, 并进行相应的操作。
我们这里先分析第一步,也就是编译的过程,先解释一下P4 Runtime(以下内容来自chatgpt):
P4 Runtime File是一个文本格式的文件,用于描述P4程序中定义的控制平面接口,包括所有可用的表格、计数器、计时器和通知等。 在P4程序中,数据平面和控制平面是分开定义和处理的。P4程序通过定义数据平面的行为来控制如何处理数据包,而控制平面则定义了P4程序的控制接口,即如何与P4程序进行交互。 P4 Runtime File就是用于定义P4程序控制平面接口的文件。它是一种文本格式文件,使用P4 Runtime API中的protobuf格式进行编码。P4 Runtime File中包含了所有可用的表格、计数器、计时器和通知等,以及它们的属性、键、操作等信息。通过解析P4 Runtime File,控制平面就可以了解P4程序中所有可用的控制接口,并使用P4 Runtime API向数据平面发送控制指令。 在实际应用中,P4 Runtime File通常是由P4程序的设计者手动编写的,或者通过自动生成工具从P4程序的源代码中生成。控制平面可以根据P4 Runtime File的内容,使用P4 Runtime API向数据平面发送控制指令,并与P4程序进行交互。 总之,P4 Runtime File是一个文本格式文件,用于描述P4程序中定义的控制平面接口,包括所有可用的表格、计数器、计时器和通知等。控制平面可以根据P4 Runtime File中的内容,使用P4 Runtime API向数据平面发送控制指令,并与P4程序进行交互。 P4 Runtime API与网络设备的交互通常通过GRPC协议进行。GRPC是一种高性能的远程过程调用(RPC)框架,可以在客户端和服务器之间传输二进制数据,并使用protobuf协议进行序列化和反序列化。 在P4 Runtime API中,客户端应用程序可以使用P4 Runtime API提供的GRPC客户端来向网络设备发送控制指令,例如设置转发表、读取状态信息等。网络设备也必须运行一个P4 Runtime代理,该代理会接收GRPC请求并将其转换为对数据平面的配置或控制指令。 具体地说,当P4程序被加载到网络设备上并启动时,P4 Runtime代理会与网络设备建立一个GRPC服务器,并开始监听来自客户端应用程序的GRPC请求。当客户端应用程序向代理发送请求时,请求将通过GRPC协议传输到P4 Runtime代理,并被转换为P4程序的控制指令。代理将执行这些指令,并将结果通过GRPC协议返回给客户端应用程序。 总之,P4 Runtime API通过GRPC协议提供了一种灵活而高效的方式,让客户端应用程序能够与P4程序运行的网络设备进行交互和控制。 当使用P4编写程序定义网络设备数据平面处理功能时,需要将P4程序编译成二进制文件,然后将该文件加载到网络设备中。然而,当需要动态地配置和控制网络设备时,需要使用P4 Runtime API与网络设备进行交互。P4 Runtime API提供了一组用于配置和控制P4程序的标准接口,这些接口可用于向网络设备发送控制指令,以及从网络设备读取状态和统计信息。 以下是一些常用的P4 Runtime API接口及其作用: -
p4runtime.SetForwardingPipelineConfig(): 用于设置网络设备的转发管道配置。例如,设置使用哪个P4程序、如何分配流表空间、如何配置计数器等。 -p4runtime.WriteTableEntry(): 用于向流表中添加、修改或删除一个规则。例如,设置如何匹配流量、如何动作等。 -p4runtime.ReadTableEntry(): 用于读取流表中的一条规则。例如,读取特定的流表项或读取整个流表。 -p4runtime.PacketIn(): 用于将数据包发送到P4程序进行处理。例如,从数据包中提取头部信息、匹配流表项、执行动作等。 -p4runtime.PacketOut(): 用于将处理后的数据包发送回网络中。例如,将转发或修改后的数据包发送到正确的端口。 -p4runtime.ReadCounters(): 用于读取计数器的值。例如,读取特定的计数器或读取整个计数器数组。 以上是一些常用的P4 Runtime API接口,具体接口及其使用方式可以根据具体的P4程序和网络设备进行调整。
然后我又问了一下,控制平面是怎么使用P4 runtime file的:
- 解析P4 Runtime File:控制平面首先需要解析P4 Runtime File,以了解P4程序中定义的所有控制平面接口及其属性、键和操作等信息。P4 Runtime File使用protobuf格式编码,因此控制平面需要使用protobuf库或类似的库来解析它。 2. 创建P4 Runtime Session:控制平面使用P4 Runtime API与数据平面进行交互,因此需要创建P4 Runtime Session。P4 Runtime Session是与数据平面建立的会话,用于发送控制指令、读取状态信息和处理事件通知等。 3. 发送控制指令:控制平面可以使用P4 Runtime API向数据平面发送控制指令,例如设置转发表、配置计数器、读取状态信息等。控制平面可以根据P4 Runtime File中定义的控制平面接口,构造控制指令,并使用P4 Runtime API将其发送到数据平面。 4. 处理事件通知:P4程序可以生成事件通知,以向控制平面报告某些事件的发生,例如某个计数器达到某个阈值、某个计时器到期等。控制平面可以使用P4 Runtime API注册对这些事件的监听器,并在事件发生时处理它们。
生成的p4.p4info.txt格式上采用的protobuf的可序列化和反序列化格式,P4 Runtime使用protobuf格式来描述P4程序中的各个组件,例如pkg_info、tables、actions和type_info,并将它们序列化为二进制格式的P4 Runtime消息。
pkg_info:指定了该P4程序使用的编程模型,这里是v1model。tables:定义了一个名为MyIngress.ipv4_lpm(别名为ipv4_lpm)的表格,该表格使用LPM(最长前缀匹配)方式匹配IPv4目的地址,可以执行三种不同的动作(NoAction、drop和ipv4_forward),表格大小为1024。actions:定义了三个动作,分别是NoAction、drop和ipv4_forward。其中,NoAction不执行任何操作,drop将数据包丢弃,ipv4_forward根据参数指定的目标地址和端口号将数据包转发到指定的目的地。type_info:未定义任何自定义数据类型,因此为空。
第二步就是去查看一下../../utils/run_exercise.py,在代码中这些文件是怎么被使用的,为了方便,命令这里粘贴到这里:
sudo python3 ../../utils/run_exercise.py -t pod-topo/topology.json -j build/basic.json -b simple_switch_grpc首先看了一下run_exercise.py的main函数,先通过get_args()获取命令行参数:
defget_args():
cwd=os.getcwd()
default_logs=os.path.join(cwd,'logs')
default_pcaps=os.path.join(cwd,'pcaps')
parser=argparse.ArgumentParser()
parser.add_argument('-q','--quiet',help='Suppress log messages.',
action='store_true',required=False,default=False)
# topo就先不看了,这部分应该是tutorial中关于mininet的东西
parser.add_argument('-t','--topo',help='Path to topology json',
type=str,required=False,default='./topology.json')
parser.add_argument('-l','--log-dir',type=str,required=False,default=default_logs)
parser.add_argument('-p','--pcap-dir',type=str,required=False,default=default_pcaps)
# p4编译出来的basic.json被用在这里
parser.add_argument('-j','--switch_json',type=str,required=False)
parser.add_argument('-b','--behavioral-exe',help='Path to behavioral executable',
type=str,required=False,default='simple_switch')继续看一下switch_json的调用的地方:
# Main函数中 exercise=ExerciseRunner(args.topo,args.log_dir,args.pcap_dir,
args.switch_json,args.behavioral_exe,args.quiet)# -- 在这里执行到了下面的create_network函数exercise.run_exercise()
# ExerciseRunner中# -- switch_json : string // json of the compiled p4 example# -- 被复制给了ExerciseRunner的self成员。defcreate_network(self):
# 调用了configureP4Swich
defaultSwitchClass=configureP4Switch( #注意这个
sw_path=self.bmv2_exe,
# 这里赋值给了json_path
json_path=self.switch_json,
log_console=True,
pcap_dump=self.pcap_dir)
# configureP4Switch函数# -- 这里要判断另一个参数,也就是命令行中的-b参数,-b simple_switch_grpc,会传到这个函数defconfigureP4Switch(**switch_args):
""" Helper class that is called by mininet to initialize the virtual P4 switches. The purpose is to ensure each switch's thrift server is using a unique port. """
# 判断 switch_args 的是否包含 "sw_path" 这个键,并且该键对应的值中是否包含字符串 "grpc"
if"sw_path"inswitch_argsand'grpc'inswitch_args['sw_path']:
# If grpc appears in the BMv2 switch target, we assume will start P4Runtime
# BMv2交换机作为数据面设备,负责对网络数据包进行处理和转发,
# 而gRPC作为控制面与数据面之间的通信框架,用于控制器向BMv2交换机发送流表等配置信息,
# 以实现对数据面设备的控制和管理。因此,BMv2交换机和gRPC框架之间存在紧密的关系。
# 这里就是继承了P4RuntimeSwitch
classConfiguredP4RuntimeSwitch(P4RuntimeSwitch):
def__init__(self,*opts,**kwargs):
kwargs.update(switch_args)
P4RuntimeSwitch.__init__(self,*opts,**kwargs)
defdescribe(self):
print("%s -> gRPC port: %d"%(self.name,self.grpc_port))
returnConfiguredP4RuntimeSwitch
else:
# 省略原文
pass
returnConfiguredP4Switch那么接下来就该看P4RuntimeSwitch了, 里面大概就是设定了GRpc的端口和Device_id之类的变量。这个类最初也是从Mininet的Switch类中继承出来的
这个是switch类的定义
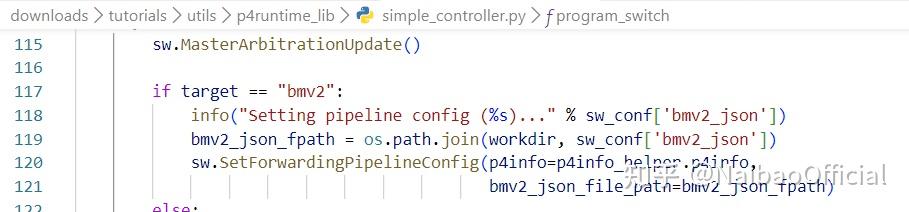
basic.json最后调用SetForwardingPipelineConfig被解析
然后拿来给Mininet用,这基本上串起来了。下面看一看basic.p4答案和原版的变化,理解一下, 详尽的语言标准文档在:P4-16-v1.2.3.pdf
diff -urN basic.p4 ./solution/basic.p4 > ./solution/ans_diff.patch
# Result:--- basic.p4 2023-03-06 01:30:55.656308057 +0800+++ ./solution/basic.p4 2023-03-06 01:30:55.660308058 +0800@@ -52,11 +52,23 @@ inout standard_metadata_t standard_metadata) {
state start {- /* TODO: add parser logic */+ transition parse_ethernet; //增加了一个状态+ }++ state parse_ethernet { /* 标准文档中有介绍extract用法 */+ packet.extract(hdr.ethernet);+ transition select(hdr.ethernet.etherType) { //根据etherType条件跳转+ TYPE_IPV4: parse_ipv4;+ default: accept;+ }+ }++ state parse_ipv4 {+ packet.extract(hdr.ipv4); transition accept; // 代表接受,完成。
}-}+}
/*************************************************************************
************ C H E C K S U M V E R I F I C A T I O N *************@@ -79,7 +91,10 @@ }
action ipv4_forward(macAddr_t dstAddr, egressSpec_t port) {- /* TODO: fill out code in action body */+ standard_metadata.egress_spec = port; //这个port从数据包中传参+ hdr.ethernet.srcAddr = hdr.ethernet.dstAddr;+ hdr.ethernet.dstAddr = dstAddr;+ hdr.ipv4.ttl = hdr.ipv4.ttl - 1; }
table ipv4_lpm {@@ -92,14 +107,13 @@ NoAction;
}
size = 1024;- default_action = NoAction();+ default_action = drop(); }
apply {- /* TODO: fix ingress control logic- * - ipv4_lpm should be applied only when IPv4 header is valid- */- ipv4_lpm.apply();+ if (hdr.ipv4.isValid()) {+ ipv4_lpm.apply();+ } }
}
@@ -117,10 +131,10 @@ ************* C H E C K S U M C O M P U T A T I O N **************
*************************************************************************/
-control MyComputeChecksum(inout headers hdr, inout metadata meta) {+control MyComputeChecksum(inout headers hdr, inout metadata meta) { apply {
update_checksum(- hdr.ipv4.isValid(),+ hdr.ipv4.isValid(), { hdr.ipv4.version,
hdr.ipv4.ihl,
hdr.ipv4.diffserv,@@ -137,14 +151,14 @@ }
}
- /*************************************************************************
*********************** D E P A R S E R *******************************
*************************************************************************/
control MyDeparser(packet_out packet, in headers hdr) {
apply {- /* TODO: add deparser logic */+ packet.emit(hdr.ethernet);+ packet.emit(hdr.ipv4); }
}编译后的basic.json也会有相对应的变化。
DPDK
DPDK的入门程序我选择的是《深入浅出DPDK》里面的Helloworld, 其源码如下:
#include<stdio.h>#include<string.h>#include<stdint.h>#include<errno.h>#include<sys/queue.h>//以上头开发环境glibc的相关头文件#include<rte_memory.h>#include<rte_memzone.h>#include<rte_launch.h>#include<rte_eal.h>#include<rte_per_lcore.h>#include<rte_lcore.h>#include<rte_debug.h>staticintlcore_hello(__attribute__((unused))void*arg){
unsignedlcore_id;
lcore_id=rte_lcore_id();//获取逻辑核编号,并输出逻辑核id,返回,线程退出。 printf("hello from core %u\n",lcore_id);
return0;}
intmain(intargc,char**argv){
intret;
unsignedlcore_id;
/* 相关初始化工作,如命令含参数处理,自动检测环境相关条件。以及相关库平台初始化工作*/
ret=rte_eal_init(argc,argv);
if(ret<0)
rte_panic("Cannot init EAL\n");
/* 每个从逻辑核调用回调函数lcore_hello输出相关信息。 */
/*给出RTE_LCORE_FOREACH_SLAVE宏定义 #define RTE_LCORE_FOREACH_SLAVE(i) \ for (i = rte_get_next_lcore(-1, 1, 0); \ i<RTE_MAX_LCORE; \ i = rte_get_next_lcore(i, 1, 0)) */
RTE_LCORE_FOREACH_WORKER(lcore_id)
{
rte_eal_remote_launch(lcore_hello,NULL,lcore_id);
}
/* 再次调用主逻辑核输出相关信息。 */
lcore_hello(NULL);
/* 等待所有从逻辑核调用返回,相当于主线程阻塞等待。*/
rte_eal_mp_wait_lcore();
return0;}其对应的输出结果如下:
EAL: Detected CPU lcores: 2
EAL: Detected NUMA nodes: 1
EAL: Detected shared linkage of DPDK
EAL: Multi-process socket /var/run/dpdk/rte/mp_socket
EAL: Selected IOVA mode 'PA'
EAL: VFIO support initialized
EAL: Probe PCI driver: net_virtio (1af4:1000) device: 0000:00:05.0 (socket -1)
eth_virtio_pci_init(): Failed to init PCI device
EAL: Requested device 0000:00:05.0 cannot be used
TELEMETRY: No legacy callbacks, legacy socket not created
hello from core 1
hello from core 0下面就用GDB跟踪调试一下这个代码:
函数:rte_eal_init(argc, argv)
(74条消息) DPDK lcore学习笔记_rtoax的博客-CSDN博客,此博客中有此函数的主要调度的总结梳理,以及大体模块的介绍。
首先看ret =rte_eal_init(argc, argv);里面干的第一件事,就是重置内部环境,里面有个结构体internal_config,其定义在[DPDK_HOME]/lib/eal/common/eal_internal_cfg.h中,有些变量涉及操作系统的内核机制,所以不过多展开,我自己是通过chatgpt理解的。
之后就是处理输入程序的命令行参数了,参数分为EAL commandline和App commanline两种, 具体调用函数形式如下:
inteal_save_args(intargc,char**argv){
inti,j;
// 调用两次,分别处理EAL和APP的命令参数 rte_telemetry_register_cmd(EAL_PARAM_REQ,handle_eal_info_request,
"Returns EAL commandline parameters used. Takes no parameters");
rte_telemetry_register_cmd(EAL_APP_PARAM_REQ,handle_eal_info_request,
"Returns app commandline parameters used. Takes no parameters");这里第二个参数是一个函数指针,用于具体处理命令行,其定义如下:
/** * This telemetry callback is used when registering a telemetry command. * It handles getting and formatting information to be returned to telemetry * when requested. * * @param cmd * The cmd that was requested by the client. * @param params * Contains data required by the callback function. * @param info * The information to be returned to the caller. * * @return * Length of buffer used on success. * @return * Negative integer on error. */typedefint(*telemetry_cb)(constchar*cmd,constchar*params,
structrte_tel_data*info);rte_telemetry_register_cmd代码中会用到一个静态变量num_callbacks,这个变量没有显式赋值,但是在main函数运行时,这个变量就被赋值成4了。就算我断点打在__start处也是也一样,目前没有想明白。
Breakpoint1,main(argc=1,argv=0x7fffffffe628)athelloworld.c:2525 {(gdb)pnum_callbacks$1=4这里主要用自旋锁调用了realloc函数扩展了callbacks数组,这个callbacks数组记录了每个调用register_cmd的入参:
structcmd_callback{
charcmd[MAX_CMD_LEN];
telemetry_cbfn;
charhelp[RTE_TEL_MAX_STRING_LEN];};将argc个argv复制给eal_args字符串数组。同样也对eal_app_args进行处理。
再处理完命令行参数后,DPDK先对CPU进行了初始化:rte_eal_cpu_init(),主要操作的目录是/sys/devices/system/cpu,其简单介绍如下
/sys/devices/system/cpu目录是 Linux 系统中的一个虚拟文件系统,用于显示和操作 CPU 相关的信息。在这个目录下,每个目录名都代表一个逻辑处理器(或核心),而目录中的文件则记录了与逻辑处理器相关的信息。
在/sys/devices/system/cpu目录下可以找到很多与 CPU 相关的文件和子目录,例如:
/sys/devices/system/cpu/cpu*/topology目录用于显示逻辑处理器的拓扑结构信息,比如逻辑处理器的 ID、所属的物理 CPU 和 NUMA 节点等;/sys/devices/system/cpu/cpu*/cpufreq目录用于显示和设置 CPU 频率相关的信息,比如 CPU 的最小、最大和当前频率等;/sys/devices/system/cpu/cpu*/cache目录用于显示 CPU 缓存的相关信息,比如缓存的大小、类型、行大小等;/sys/devices/system/cpu/online文件用于控制哪些逻辑处理器是在线的;/sys/devices/system/cpu/offline文件用于控制哪些逻辑处理器是离线的;/sys/devices/system/cpu/kernel_max文件用于显示系统支持的最大逻辑处理器数目
函数中首先获取了当前结构体rte_config, 这个结构体都是关于逻辑处理器的,其定义如下:
/** * Structure storing internal configuration (per-lcore) */structlcore_config{
pthread_tthread_id; /**< pthread identifier */// 用于表示当前逻辑核心所在的线程intpipe_main2worker[2]; /**< communication pipe with main */// 0是主到副的读端,1是写端intpipe_worker2main[2]; /**< communication pipe with main */
lcore_function_t*volatilef;/**< function to call */// 当前逻辑核心执行的函数void*volatilearg; /**< argument of function */
volatileintret; /**< return value of function */
volatileenumrte_lcore_state_tstate;/**< lcore state */// 可能的取值有WAIT, RUNNING, FINISHEDunsignedintsocket_id; /**< physical socket id for this lcore */
unsignedintcore_id; /**< core number on socket for this lcore */
intcore_index; /**< relative index, starting from 0 */// 可以唯一的区分lcoreuint8_tcore_role; /**< role of core eg: OFF, RTE, SERVICE *//* OFF: 没有被DPDK使用 * RTE: 这个core被用来进行DPDK数据包处理 * SERVICE: 用于DPDK本身的程序服务,例如定时器,缓存清除等,这个核心通常与RTE角色翻开,以免影响数据包性能 */
rte_cpuset_tcpuset; /**< cpu set which the lcore affinity to */};/* internal configuration (per-core) */structlcore_configlcore_config[RTE_MAX_LCORE];这里需要说明的是CPU的socket说的是插槽,插槽分为Socket,Slot两种,可以用下面命令查看
cat /sys/devices/system/cpu/cpu0/topology/physical_package_idcpu_set_t的定义:
/* Size definition for CPU sets. */#define __CPU_SETSIZE 1024#define __NCPUBITS (8 * sizeof (__cpu_mask))/* Type for array elements in 'cpu_set_t'. */typedef__CPU_MASK_TYPE__cpu_mask;
/* Data structure to describe CPU mask. */typedefstruct{
__cpu_mask__bits[__CPU_SETSIZE/__NCPUBITS];}cpu_set_t;可以看到cpu_set_t这个结构体本质上是一个数组,在x86_64架构中,__CPU_MASK_TYPE是unsigned long int类型,那就可以算出来__bits的长度有128位(1024/8,sizeof(__cpu_mask)约掉)。这个也就是上面RTE_MAX_LCORE的取值128。
接下来就是函数就是通过循环128次,给lcore_config进行设置,因为每个用户的CPU硬件不一样,所以里面肯定需要判断,并不真的需要128个lcore。
for(lcore_id=0;lcore_id<RTE_MAX_LCORE;lcore_id++){
lcore_config[lcore_id].core_index=count;
/* init cpuset for per lcore config */
CPU_ZERO(&lcore_config[lcore_id].cpuset);// clear set
/* find socket first */
socket_id=eal_cpu_socket_id(lcore_id);// 调用这个函数获取socket id lcore_to_socket_id[lcore_id]=socket_id;
if(eal_cpu_detected(lcore_id)==0){// 检测lcore_id的cpu是否真实存在,就是到sys/cpu的目录中检测。 config->lcore_role[lcore_id]=ROLE_OFF;
lcore_config[lcore_id].core_index=-1;
continue;
}
/* By default, lcore 1:1 map to cpu id */
CPU_SET(lcore_id,&lcore_config[lcore_id].cpuset); // 到这里就是检测成功,一个lcore占用一个核心
/* By default, each detected core is enabled */
/* 打断插入一下enum enum rte_lcore_role_t { ROLE_RTE, ROLE_OFF, ROLE_SERVICE, ROLE_NON_EAL, }; */
config->lcore_role[lcore_id]=ROLE_RTE;
lcore_config[lcore_id].core_role=ROLE_RTE;
lcore_config[lcore_id].core_id=eal_cpu_core_id(lcore_id);
lcore_config[lcore_id].socket_id=socket_id;
RTE_LOG(DEBUG,EAL,"Detected lcore %u as "
"core %u on socket %u\n",
lcore_id,lcore_config[lcore_id].core_id,
lcore_config[lcore_id].socket_id);
count++;
}完成CPU的设置后就是处理命令行参数了:
/* Parse the argument given in the command line of the application */staticinteal_parse_args(intargc,char**argv){}在此之后就会调用插件库,跟踪库,然后初始化中断:
(74条消息) DPDK初始化分析(二)_rte_mp_handle_whenloce的博客-CSDN博客
intrte_eal_intr_init(void){
intret=0;
TAILQ_INIT(&intr_sources);//生成一个链表,用来记录if(pipe(intr_pipe.pipefd)<0){//采用epll机制处理rte_errno=errno;
return-1;
}
ret=rte_ctrl_thread_create(&intr_thread,"eal-intr-thread",NULL,
eal_intr_thread_main,NULL);
if(ret!=0){
rte_errno=-ret;
RTE_LOG(ERR,EAL,"Failed to create thread for interrupt handling\n");}
returnret;}这里大体上有三个比较重要的地方,分别是IO多路复用的Epoll,中断机制以及多线程启动。
这三部分内容设计的比较多。因此将放到下一篇笔记。
总结
这篇博客的内容比较长,当然,涉及的知识面也相对较多,有个地方总结还是很不错的。本篇基本上探明了P4开发流程和对DPDK进行了基本的探讨,下周将继续研究DPDK,并对P4和DPDK的结合体
参考
- ^Maglev: A Fast and Reliable Software Network Load Balancerhttps://www.usenix.org/conference/nsdi16/technical-sessions/presentation/eisenbud
P4编程理论与实践
SDN的概念
SDN(Software Defined Network,软件定义网络)。 相对于传统网络,软件定义网络实现了控制平面 与数据平面的分离,同时(至少在逻辑上)构建了一个集中的控制平面。人们可以在这个单一的控制平面上,实现对全网各个网元设备的监控,管理,编程。
● 数据平面:维护一个由一系列流表组成的(pipeline,流水线)。当数据包经过交换机时,首先会走的是数据平面,即去匹配这些表。根据匹配到的相应的规则(action),如output, drop。从不同的端口转发或者丢弃。但是FIB的信息是如何添加的呢?为什么FIB会知道数据包该从哪个端口转发呢?这就需要控制平面去管理它。 ● 控制平面:不管是分布式的控制平面,还是集中式的控制平面。控制平面可以理解为网元设备的操作系统。他可以写一些程序,里面含有特定的算法,向数据平面添加相应的转发规则。也就是说,控制平面相当于网元设备的大脑,当数据平面不知道如何转发一个数据包时,会向大脑询问,大脑根据自己对网络拓扑的"认知",向数据平面返回指定的规则,数据平面记录这条规则,在之后的转发过程中,就不再询问自己的大脑(速率较慢),而是根据"肌肉记忆"直接转发。
OpenFlow
OpenFlow的诞生和历史不做赘述。OpenFlow在SDN中扮演怎样一个地位呢?我们先来看一张图片:
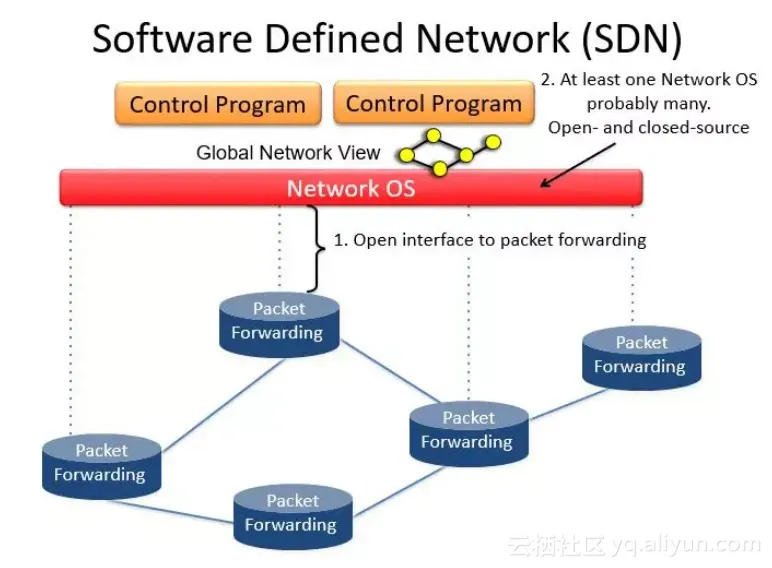
我们知道,SDN的一个重要概念就是控制平面和数据平面的分离,以及集中式的控制平面,这个集中的控制平面就是我们所说的控制器。那么控制平面与数据平面分离之后,如何像往常一样管理数据平面呢?因此,在分离后的控制平面和数据平面之间,只能通过一个特定的协议进行交互,这个协议就是我们的OpenFlow协议。也就是上图所示的1. Open interface to packet forwarding.
所以, OpenFlow协议有如下特点:
● 定义了用于控制器和数据平面(各个OpenFlow交换机)交互的报文格式。 ● OpenFlow必须是一个 target-independent 的协议,所谓target-independent就是与 特定的交换机无关,能够提供一种抽象,从而可以以统一的接口管理网络中所有的设备,从而实现一个逻辑集中的控制平面。 ● OpenFlow作为一种南向协议,其与其他南向接口的对比如下。

这张图放的有点早了,但是可以看到OpenFlow虽然实现了Target-independent,但是没有实现Protocol-independent。 这个是OpenFlow的最主要的缺陷之一,这也是引入P4的最主要的原因。什么是Protocol-independent呢?请继续看。
OpenFlow的缺陷
OpenFlow虽然为SDN奠定了基础。但是在进行应用开发的时候有一个很大的局限,就是OpenFlow没有真正做到协议不相关。也就是说,OpenFlow只能依据现有的协议来定义流表项。打个比方,就好像OpenFlow给了我们几个固定形状的积木,让我们自行组装,却不能让我们自己定义积木的形状。 这就是OpenFlow的局限所在!
举个例子:
OpenFlow 1.0 的时候有12个字段,这些字段分别就是我们熟悉的,IP地址,MAC地址,等等。但是很快发现,单单这12个字段不能满足现实网络世界中各种需求(在网络中的协议有很多种)。所以到OpenFlow1.3的时候字段增加到40个,现在OpenFlow1.5甚至更多。
这样带来的麻烦有很多,一是匹配效率和空间占用的问题。二是特定的OpenFlow交换机生产出来后,无法支持新的协议字段,只能在现有协议上进行开发。最终只能面临淘汰。
如果我们可以自定义协议字段的类型,甚至实现自定义动作的类型,那么我们就不需要反复修正协议本身,SDN的架构也将更加灵活。这个自定义协议字段类型 ,自定义动作类型就是我们所说的数据面编程。
数据面编程思想
数据面编程就是我们自己定义匹配字段,自己定义动作类型,从而自己定义流表,进而形成流水线(pipline)。基于这种初衷,P4应运而生。
什么是P4
P4(P rogrammingP rotocol-IndependentP acketProcessors)是一种数据面的高级编程语言。他可以克服OpenFlow的局限。通过P4语言,我们可以定义我们想要的数据面。进而再通过南向协议添加流表项。
P4 与 OpenFlow 的关联与区别
**P4虽然弥补了OpenFlow的不足,但是P4和OpenFlow的定位是截然不同的!**OpenFlow提供了一种控制器和数据面的动态交互的协议。是一种南向协议。而P4只是一个数据面的编程语言。
通过P4,我们可以定义各种各样形状的积木,而通过南向协议,我们可以组装这些积木来实现特定的功能。也就是说,写好P4代码并不是全部,我们还需要写相应的控制面代码才能使网络正常工作。
与OpenFlow对应的是P4 Runtime。 还记的上面的那张图吗,为了实现协议无关。P4的设计者们还提供了一个南向协议------P4 runtime。 P4 runtime与OpenFlow功能类似,但是P4 runtime可以充分利用P4协议无关的特性,"与P4更搭配!"。
P4中的那些事
P4是一种高级数据面编程语言,既然是高级语言,那么其设计本身就有着很高的抽象程度。我们先来看一种图:
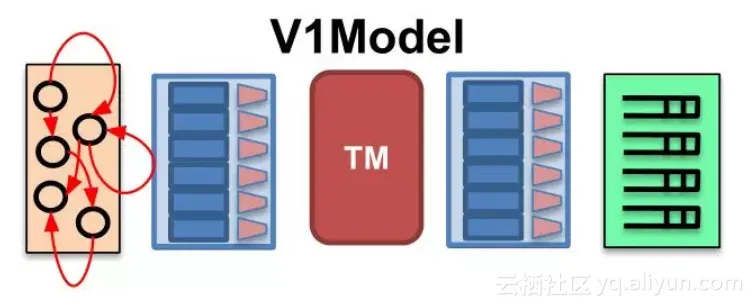
这是P4中提供的最简单最易理解的编程结构,V1Model。可以看到它由5个模块组成,他们的名字分别是(从左到右):
● Parser: 解析器, 解析并且提取数据包头的各个字段。
● Ingress: Ingress处理,在这里定义Ingress流水线。
● TM: Traffic manager,有一些队列,用于流量控制(一些队列相关的metadata在此更新)。
● Egress: Egress, 在这里定义Egress流水线。
● Deparser:用于重组数据包,因为数据包在处理过程中经历了分解和处理。所以最后转发的时候需要重组一下。
P4为我们提供了上述抽象,我们就可以把所有的交换机理解为上述的模型,然后按照上述模型进行开发就可以了。所以,按照上述模型,P4语言的代码结构通常为这样:
在开始搭建环境和写P4代码前
p4 的github仓库是学习P4编程的重要基地,我们着重了解一下几个子仓库:
● behavioral-model 简称BMv2. 是一款支持P4的软件交换机。其设计初衷是完全支持P4语言,从而用于功能性试验和学习,而性能不是第一目标(与OVS不同)。BMv2可以和Mininet集成。BMv2提供两种控制接口,一种是基于thirft的CLI接口(命令行),另一种是基于gRPC和protobuf的P4 runtime。显然,一种是分布式控制平面,一种是集中式控制平面。
● tutorials 是我们学习P4编程最重要的教程。里面含有一些交互式的学习材料和一个搭建好环境的虚拟机。建议大家使用搭建好环境的虚拟机学习,本人尝试过自己搭建环境,尽管最后成功了,但是中间遇到了各种报错,特别还有国内网络原因,访问github特别慢,整体搭建好还是是比较吃力的。可以直接访问我的ftp服务器下载虚拟机镜像 。
● p4c是P4的编译器,它是一个比较综合的编译器,支持多个版本的p4代码,同时支持多种输出格式。有二进制形式的,也有用于BMv2的json格式。
上述几个仓库是学习过程中需要用到的,当然还有一些其他仓库。
P4 & DPDK
前言
本周先来从P4和DPDK的example下手,先理解其基本的运作方式。
P4C作为一个编译器自然是给P4语言服务的,那么首先先要通过实例搞清P4的语法,然后还得了解P4编译器怎么用,此外还必须对Linux常用的网络方面的命令得熟悉,然后跑起来。总之重点是理解他。
DPDK准备先跑一下Hello World,然后GDB大概跟一下。
P4 Exercise
P4 准备工作
在进行实例之前,还是先需要继续扩充背景知识,然后这有个教程:P4language官方github教程, 我发现这里有Vagrantfile, 也就是这个教程给我们把环境配置好了,对我自己来说,我更希望在自己的云服务器上部署,而不是使用虚拟机,因为这样会占用本地的资源,,我还得打游戏。。
那就照着Vagrantfile里面的命令在本地安装环境好了,我主要是参考了user-dev这个bash脚本。
这个脚本安装了几样东西,分别是Protobuf,gRPC,Bmv2,Ptf, 我觉得如果还是有必要先搞清楚他们都是干啥的。
- gRPC
gPRC和Restful干的事情差不多, Restful可以理解成为前端和后端通信的桥梁,前端要干什么,告诉RestAPI,然后RestAPI帮你问服务器,服务器也通过RestAPI把客户端需要的消息传送回去。这其中的过程可以简单地用Request和Response来描述。
gRPC首先它得是一种RPC,RPC(Remote Procedure Call), 说白了就是IPC是远程版本,就是远程调用接口,要在本地调用远程的函数,那么他在思想上和Restful就是不一样的,Rest(Representional State Transfer),重点还是关注数据的抽象。一个是面向函数的,解决跨服务器函数的调用,一个是面向远程资源的,面向数据的。具体的解释可以参考RPC和Restful的区别。 RPC通信也有序列化的需求,这时候需要使用一个中间层,那gPRC就是使用的protocol buffers也就是在安装中碰见的protobuf。推荐去看这里的前面原文以及原文对应的书籍(原文中有,知乎也有电子版)。
- Protobuf
Protobuf通信协议详解:代码演示、详细原理介绍等 - 知乎 (zhihu.com)这篇文章足足够。
- Bmv2
P4编程理论与实践------理论篇-阿里云开发者社区 (aliyun.com)看这个。
这个直接开Tutorial介绍就可以大概了解:
PTF is a Python based dataplane test framework. It is based on unittest, which is included in the standard Python distribution.
P4 原理
在开始具体的Tutorial学习之前,还是得先搞明白P4总体结构。前面我们已经知道了P4程序是用来解决数据平面的问题的,交换机等硬件保证物理上能够联通,P4做的事就是让不同的交换机都能够执行控制平面的协议。我们用软件描述协议,用软件取代了专用的芯片(AISC),就好比我们没有把数据库直接设计成芯片,虽然这样可以保证更好的性能,但是更新换代以及开发的工作就会变得很困难,P4的存在就可以让我们加快网络的更新速度,取而代之的是,肯定是要慢一些,所以一般只用来进行学术上的交流,交换机只要能够和P4打交道就行了。大体上就做了这么个事。
P4的论文:(Programming Protocol-Independent Packet Processors)1312.1719.pdf (arxiv.org)
下图就比较清楚的展示了P4的地位和作用,首先大背景是软件定义网络,其次是用来替代传统openflow,openflow是一个协议,Swtich需要硬件支持openflow,控制器也需要按照openflow的规则填充对应的值,在ASIC电路中,Control Plane就差不多是状态机的地位,Openflow就是ASIC设计的那些使能复位等等功能端口,Dataplane提供具体的时序电路和组合电路。P4现在要推翻这一套,Switch就是CPU,P4就是C语言(看起来也像是C语言改的),编译器编译成汇编,Switch不需要具体知道用的P4的代码是做什么,跑就完事了。这样Switch就不需要看到一个协议就需要更新一下硬件,从ASIC变到CPU了。

Fig.1 P4 Controll Switch
图2的Forward模型有两个Operation:Configure(配置)和Populate(填充), 配置操作对解析器进行编程,设置匹配+动作阶段的顺序,并指定每个阶段处理的头域。配置决定了哪些协议被支持以及交换机如何处理数据包。填充操作向配置期间指定的匹配+动作表添加(和删除)条目。配置决定了在任何给定时间应用于数据包的策略。 通常都是假设配置和填充是两个不同的阶段。特别是,交换机在配置期间不需要处理数据包。 然而,作者希望在部分或全部重新配置期间,实现数据包的处理,使升级没有停机时间。所以P4的forward模型特意允许并鼓励不中断转发的重新配置。
显然,如果对应功能固定的ASIC交换机,那么P4的配置就意义不大,那么P4编译器的主要工作就是检查芯片是否支持P4。到达的数据包首先由解析器处理。数据包主体被认为是buffer separately的,不可用于匹配。解析器识别并从包头中提取字段,从而定义了交换机所支持的协议。该模型对协议头的含义不做任何假设,只是解析后的表述定义了匹配和操作的字段的集合。提取的头字段然后被传递给match+action表。Match+Action表被分为入口和出口。虽然两者都可以修改数据包头,但入口处的Match+Action决定了出口端口,并决定了数据包被放入的队列。 根据入口处理,数据包可以被转发、复制(用于多播、跨度或控制平面)、丢弃或触发流量控制。出口Match+Action对数据包头进行每个实例的修改--例如,用于多播复制。Action表(Counter, Policers等)可以与流相关联,以跟踪帧到帧的状态。
这一部分内容,可以参考其他作者的说明:P4 学习笔记(一)- 导论 - 知乎 (zhihu.com)
Parser:先看看包里面都有啥,每一个 bit 都是什么; Ingress:一堆 Match-Action 的流水线,看看哪些 bits 组成的 fields 有没有我们想要的,比如目标 IP 是不是 8.8.8.8,是的话就改写一下 header 让包能被转发到它该去的地方; Switching Logic:还要有个地方实现我们想要的逻辑,或者为了高性能,放一个 buffer,存放刚被上一个环节处理完,准备给下一个环节处理的包 1; Egress:又来一堆 Match-Action 的流水线,比如改写源 MAC 地址,同时提供更多对网络包的操作空间; Deparser:最后把我们改写好的 headers 重新写回网络包,然后送它出去。
数据包也包括一些元数据用于描述这个数据包,比如这个包是什么时间进来的,从哪个端口进来的等等。当然,这个元数据并不会改变包本身的一些元数据,例如VNI:网络虚拟化协议GENEVE - 知乎 (zhihu.com)。控制寄存器/信号在P4中被表示为内在的元数据。P4程序也可以存储和操作与每个数据包有关的数据,作为用户定义的元数据。当匹配完成后,数据包也会像Openflow协议一样进到队列当中,也会依据特定的service discipline分配包:QoS队列调度算法 - realJianhao - 博客园 (cnblogs.com)。P4也同样支持ECN:显式拥塞通知-Explicit Congestion Notification(ECN) - 知乎 (zhihu.com)。

Fig.2 The abstract forwarding model
P4 语法
数据包处理语言必须允许程序员表达(隐含地或明确地)表头字段之间的任何串行依赖关系。依赖关系决定了哪些表可以被并行执行。例如,由于IP路由表和ARP表之间的数据依赖性,需要顺序执行。依赖关系可以通过分析表依赖图(TDG, Table Dependecny Graph)来确定;这些图描述了表之间的字段输入、动作和控制流。
下图就是一个L2/L3交换机的依赖图,TDG节点直接映射到匹配+动作表,并通过依赖性分析来确定每个表在管道中的位置。 不幸的是,大多数程序员不容易接触到TDG;程序员倾向于使用命令式结构而不是图形来考虑数据包处理算法。
Fig.3. TDG for an L2/L3 switch
那么一般开发流程就变成了2步compilation process,开发者表述包的处理流程,这部分用P4,然后编译器将P4代码编译成TDGs以方便依赖性分析(facilitate dependency analysis),然后将TDG映射到具体的交换机目标。
论文中详细讲解了一个简单的例子,网络中有边缘网络和核心网络,终端(end hosts)都是连接在边缘上(edge devices), 终端和核心通过高带宽互联,整个协议会设计成支持MLPS(MPLS基础 - 知乎),和Portland(译文:PortLand:A Scalable Fault-Tolerant Layer 2 Data Center Network Fabric_portland).
考虑一个L2网络部署的例子,在边缘有顶部机架(ToR)交换机,由一个两层的核心连接。我们将假设终端主机的数量在增长,核心的L2表已经溢出了。MPLS是简化核心的一个选择,但实现一个具有多个标签的标签分配协议是一项艰巨的任务。PortLand看起来很有趣,但需要重写MAC地址--可能会破坏现有的网络调试工具,而且需要新的代理来响应ARP请求。 P4让我们可以在对网络架构进行最小改动的情况下表达一个自定义的解决方案。
上文中提到的TOR可以参考以下两个资料,如有需要。
了解接入层、汇聚层、核心层交换机 - 知乎 (zhihu.com)
从EOR与TOR架构谈EOR与TOR交换机 - 知乎 (zhihu.com)
论文中的例子称为mTag:它结合了PortLand的分层路由和简单的类似MPLS的Tag。通过核心的路由是由四个单字节字段组成的32位Tag来编码的。32位Tag可以携带 "源路由 "或目的地定位器(像PortLand的Pseudo MAC)。每个核心交换机只需要检查标签的一个字节,并根据该信息进行切换。 在我们的例子中,标签是由第一个ToR交换机添加的,尽管它也可以由终端主机网卡添加。 mTag的例子比较简单,使我们的注意力集中在P4语言上。整个交换机的P4程序在实践中会复杂很多倍。
P4在概念上有以下核心组件:
- Headers: Headers定义描述了一系列字段的顺序和结构。它包括对字段宽度和字段值的限制的说明。有点类似与C的Struct。Header的定义可以参考其他协议中的来,例如以太网:

Fig.4. UDP+以太网协议的数据包
Fig.5 MAC层的帧结构
Fig.5 就包括以太网帧头的定义,因为以太网是使用MAC地址进行转发的,所以目的地址和源地址都是MAC地址。这在P4中的写法如下:
header ethernet {
fields {
dst_addr : 48; // width in bits
src_addr : 48;
ethertype : 16;
}
} 论文中还举了VLAN的例子,VLAN就是虚拟的局域网,说白了就是给局域网分组,那么自然也需要多加几个比特提供相应的信息(这是根据信息论的必然结果),那么,VLAN的帧头结构如下所示:
Fig.6 VLAN的帧头结构
对应P4代码如下,这看起来跟C/C++没啥区别。
headervlan{
fields{
pcp:3;
cfi:1;
vid:12;
ethertype:16;
}}那么文中的mtag结构因为是自己定义的,所以这里就直接列出来了,我暂时也搞不清具体是怎么运作的。
/* 可以在不改变现有声明的情况下添加mTag头。字段名表示核心有两层聚合。 * 每个核心交换机都被编入规则,以检查这些字节中的一个,由其在层次结构 * 中的位置和移动方向(向上或向下)决定。 */headermTag{
fields{
up1:8;
up2:8;
down1:8;
down2:8;
ethertype:16;
}}- Parsers: 解析器的定义规定了如何识别数据包内的头和有效的头序列。P4假设下层的交换机可以实现一个状态机,这个状态机可以完成数据包头的遍历,在遍历的同时提取需要的值。然后将提取出来的值送给Match+Action模块。 P4将这个状态机直接描述为从一个头到下一个头的转换集合。每个转换都可以由当前头中的值触发。例如,我们对mTag状态机的描述如下:
// Parser后面就是状态的名称,这里虽然是结构体的语法,但是确实jmp的实现// case后面我猜测就是根据跳转到对应状态,并按照header进行解析// 因为Parsers和Headers的name是能对应上的parserstart{
ethernet;// 下一个状态就是ethernet}parserethernet{
switch(ethertype){//根据ethertype的值跳转 case0x8100:vlan;
case0x9100:vlan;
case0x800:ipv4;
// Other cases }}parservlan{
switch(ethertype){
case0xaaaa:mTag;
case0x800:ipv4;
// Other cases }}parsermTag{
switch(ethertype){
case0x800:
// Other cases }}解析从开始状态开始,一直进行到达到一个明确的停止状态或遇到一个未处理的情况(可能被标记为错误)。当 达到一个新的头的状态时,状态机使用其规范提取头并继续确定其下一个转换。提取的头被转发到Pinpline的Match+Action表中。mTag的解析器非常简单:它只有四个状态。 实际网络中的解析器需要更多的状态。
Tables: Match+Action是执行数据包处理的机制。P4程序定义了一个表可以Match的字段和可以执行的Action。 在mTag例子中,边缘交换机在L2的destination和VLAN ID上进行匹配,并选择一个mTag来添加到头中。开发者定义了一个表来匹配这些字段并应用一个动作来添加mTag头(见下文)。reads属性声明了要匹配的字段,由匹配类型限定(exact,ternary, etc)。actions属性列出了可能被表应用于数据包的actions, 下面就会说到Action。max_size属性指定了该表应该支持多少个条目。Table的规格允许编译器决定它需要多少内存,以及实现表的内存类型(例如,TCAM或SRAM)。 这里稍微啰嗦一下,SRAM就是用的双稳态触发器(核心器件是一个6管的SR锁存器),一般被用在Cache中,因为全是晶体管,所以成本还是很高的。我们常用的内存是DRAM,D就是Dynamic,相对的S就是Static,这个D不是代表用D触发器,而是用电容动态表示1和0,所以内存一般比较大,没法做在CPU里,但是成本低,稍微慢一点。TCAM(Ternary Content AddressableMemory)是三态的CAM寻址器。一般用来做路由表的存储器。
tablemTag_table{
reads{
ethernet.dst_addr:exact;
vlan.vid:exact;
}
actions{
// At runtime, entries are programmed with params // for the mTag action. See below. add_mTag;
}
max_size:20000;}/* 为了完整性讨论,这里一次性将控制程序需要的Table先列出,并给与简单定义 */tablesource_check{
// Verify mtag only on ports to the core reads{
mtag:valid;// Was mtag parsed? metadata.ingress_port:exact;
}
actions{// Each table entry specifies *one* action // If inappropriate mTag, send to CPU fault_to_cpu;
// If mtag found, strip and record in metadata strip_mtag;
// Otherwise, allow the packet to continue pass;
}
max_size:64;// One rule per port}tablelocal_switching{
// Reads destination and checks if local // If miss occurs, goto mtag table.}tableegress_check{
// Verify egress is resolved // Do not retag packets received with tag // Reads egress and whether packet was mTagged}可以看出,Table也只是描述了对应的准则,具体的表项还没有添加。
- Actions: P4支持从较简单的、与协议无关的基元构建复杂的动作。这些复杂的动作可以在match+action表中使用。 P4定义了一个原始行动的集合,从中可以建立更复杂的Action,每一个P4程序都声明了一组由Action Primitives组成的Action Functions。这些Action Functions简化了Table的规格和数量。P4假设每一个Action Function中的Action Primitives都是并行执行的(Switch不支持并行运算的话可以模拟语义)。 上面提到的添加mTag动作是这样实现的:
actionadd_mTag(up1,up2,down1,down2,egr_spec){
add_header(mTag);
// Copy VLAN ethertype to mTag copy_field(mTag.ethertype,vlan.ethertype);
// Set VLAN’s ethertype to signal mTag set_field(vlan.ethertype,0xaaaa);
set_field(mTag.up1,up1);
set_field(mTag.up2,up2);
set_field(mTag.down1,down1);
set_field(mTag.down2,down2);
// Set the destination egress port as well set_field(metadata.egress_spec,egr_spec);}如果一个动作需要参数(例如,mTag的up1值),则在运行时从匹配表中提供。 在这个例子中,交换机在VLAN标签之后插入mTag,将VLAN标签的ethertype复制到mTag中以表示后面的内容,并将VLAN标签的ethertype设置为0xaaaa以示mTag。未显示的是将mTag从数据包中剥离的反向动作规范和在边缘交换机中应用该动作的Table。
P4的primitive actions包括(这部分还是看英文原文比较好): •set_field: Set a specific field in a header to a value. Masked sets are supported. •copy_field:Copy one field to another. •add_header:Set a specific header instance (and all its fields) as valid. •remove_header:Delete ("pop") a header (and all its fields) from a packet. •increment:Increment or decrement the value in a field. •checksum:Calculate a checksum over some set of header fields (e.g., an IPv4 checksum).
- Control Programs: 控制程序决定了应用于数据包的Match + Actions的顺序。一个简单的命令式程序描述了Match + Actions之间的控制流。一旦表和动作被定义,剩下的唯一任务就是指定从一个表到下一个表的控制流。控制流通过函数、条件和表的引用的集合被指定为一个程序。
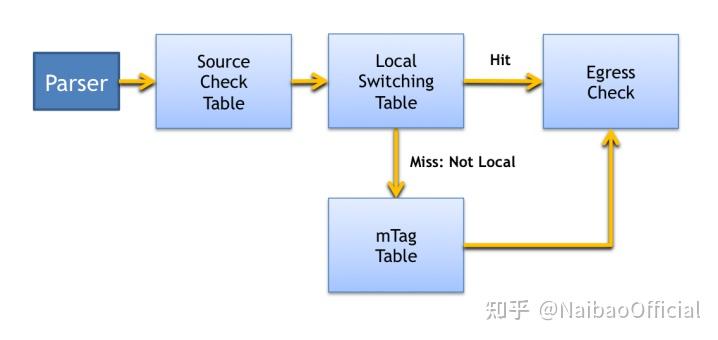
Fig.7. Control Flow for m_tag example
图7显示了边缘交换机上mTag实现所需的控制流程的图形表示。 在解析之后,源检查表验证了收到的数据包和入口端口之间的一致性。例如,mTags应该只出现在连接到核心交换机的端口上。source_check还从数据包中剥离(strip_mtag这个action论文中并没有给出) mTags,记录数据包的元数据中是否有mTag。Pipeline中稍后的表可以在这个元数据上进行匹配,以避免对数据包进行重新标记。 然后执行local_switching。如果该表 "miss",则表明该数据包不是以本地连接的主机为目的地的。在这种情况下,mTag Table将应用于该数据包。本地和核心转发控制都可以由egress_check表处理,该表通过向SDN控制栈发送通知来处理未知目的地的情况。 这个数据包处理Pipeline的命令式表示如下:
controlmain(){
// Verify mTag state and port are consistent table(source_check);
// If no error from source_check, continue if(!defined(metadata.ingress_error)){
// Attempt to switch to end hosts table(local_switching);
if(!defined(metadata.egress_spec)){
// Not a known local host; try mtagging table(mTag_table);
}
// Check for unknown egress state or // bad retagging with mTag. table(egress_check);
}}P4 编译
编辑就是将上面的P4语言代码编译成各个软硬件交换机都支持的程序。可以看到,编译器会编译出来两个程序,一个是Dataplane Runtime,一个是API。
Fig.8. . Programming a target with P4
Parsers阶段的代码就会被转换成状态机。vlan和mTag的解释器转换后如下表所示。每一个状态下都会根据匹配的值进行状态跳转

Table 1: State Machine
对于Control程序,上面的写法没有精确的指出表之间的依赖关系以及可能的并发情况,因此,编译器会尽力优化这个过程。最后编译器会生成交换机识别的目标文件。交换机target有很多,比如软件交换机,多核软件交换机,NPU,fix function交换机,或者RMT(Reconfigurable match table) Pipeline交换机。【开源】手把手教你写支持RMT架构的P4语言后端编译器!-面包板社区 (eet-china.com)
RMT论文的摘要:In Software Defined Networking (SDN) the control plane is physically separate from the forwarding plane. Control software programs the forwarding plane (e.g., switches and routers) using an open interface, such as OpenFlow. This paper aims to overcomes two limitations in current switching chips and the OpenFlow protocol: i) current hardware switches are quite rigid, allowing ``Match-Action'' processing on only a fixed set of fields, and ii) the OpenFlow specification only defines a limited repertoire of packet processing actions. We propose the RMT (reconfigurable match tables) model, a new RISC-inspired pipelined architecture for switching chips, and we identify the essential minimal set of action primitives to specify how headers are processed in hardware. RMT allows the forwarding plane to be changed in the field without modifying hardware. As in OpenFlow, the programmer can specify multiple match tables of arbitrary width and depth, subject only to an overall resource limit, with each table configurable for matching on arbitrary fields. However, RMT allows the programmer to modify allheader fields much more comprehensively than in OpenFlow. Our paper describes the design of a 64 port by 10 Gb/s switch chip implementing the RMT model. Our concrete design demonstrates, contrary to concerns within the community, that flexible OpenFlow hardware switch implementations are feasible at almost no additional cost or power.
正如前面所提到的两阶段编译一样,首先先转化成TDG(前面提到过)并对其进行分析以确定表之间的依赖关系。然后,一个特定目标的后端将这个图映射到switch的特定资源上,论文详细论述了针对各个交换机target编译器所作的工作,这里就不列举了。
到此为止,我们就对P4的工作流程有了大致的了解,我没还是没有一个成功的示例让他跑起来,接下来就进一个示例,我的工作重点在p4 runtime,所以会多看几个tutorial。
Basic Forwarding
tutorials/exercises/basic at master · p4lang/tutorials (github.com)README文件中说明了大体情况,以及如果我们跟着教程继续完成编写会发生什么,但是basic蕴含的文件是特别的多的,更让我好奇的是,p4是怎么和mininet集成的,makefile是如何完成编译的。P4 tutorials 实例分析---basic - 知乎 (zhihu.com)这边文章对Basic教程的内容做了比较详尽的说明。下面我将按照我自己的思路自己分析
basic下的makefile比较简单:
我们要执行的target是run:也就是make run
BMV2_SWITCH_EXE= simple_switch_grpcTOPO= pod-topo/topology.json
include../../utils/Makefile大头在../../utils/Makefile里面, 我们使用make run -n就可以查看具体执行了哪些动作。
lighthouse@VM-0-5-ubuntu:~/downloads/tutorials/exercises/basic$ make run -n
mkdir -p build pcaps logs# p4runtime-file是描述控制平面的API文件# basename从文件名序列“NAMES…”中取出各个文件名的前缀部分,即*.p4.p4info.txt# $@ 传给脚本的所有参数的列表# P4编译过程中需要一个p4.p4info.txt, 这部分是P4 Runtime的东西:# P4Info:元数据,指定了可以通过P4Runtime访问的P4实体。这些实体与P4源代码中的实例化对象有一对一的对应关系。# 这个文件也是解析出来的,因为build文件夹需要创建。
p4c-bm2-ss --p4v 16 --p4runtime-files build /basic.p4.p4info.txt -o build /basic.json basic.p4
sudo python3 ../../utils/run_exercise.py -t pod-topo/topology.json -j build /basic.json -b simple_switch_grpc可以看到首先编译了basic.p4,编译的输出在build/basic.json以及Runtime的basic.p4.p4info.txt,然后将basic.json导入到python的run_exercise.py, 并进行相应的操作。
我们这里先分析第一步,也就是编译的过程,先解释一下P4 Runtime(以下内容来自chatgpt):
P4 Runtime File是一个文本格式的文件,用于描述P4程序中定义的控制平面接口,包括所有可用的表格、计数器、计时器和通知等。 在P4程序中,数据平面和控制平面是分开定义和处理的。P4程序通过定义数据平面的行为来控制如何处理数据包,而控制平面则定义了P4程序的控制接口,即如何与P4程序进行交互。 P4 Runtime File就是用于定义P4程序控制平面接口的文件。它是一种文本格式文件,使用P4 Runtime API中的protobuf格式进行编码。P4 Runtime File中包含了所有可用的表格、计数器、计时器和通知等,以及它们的属性、键、操作等信息。通过解析P4 Runtime File,控制平面就可以了解P4程序中所有可用的控制接口,并使用P4 Runtime API向数据平面发送控制指令。 在实际应用中,P4 Runtime File通常是由P4程序的设计者手动编写的,或者通过自动生成工具从P4程序的源代码中生成。控制平面可以根据P4 Runtime File的内容,使用P4 Runtime API向数据平面发送控制指令,并与P4程序进行交互。 总之,P4 Runtime File是一个文本格式文件,用于描述P4程序中定义的控制平面接口,包括所有可用的表格、计数器、计时器和通知等。控制平面可以根据P4 Runtime File中的内容,使用P4 Runtime API向数据平面发送控制指令,并与P4程序进行交互。 P4 Runtime API与网络设备的交互通常通过GRPC协议进行。GRPC是一种高性能的远程过程调用(RPC)框架,可以在客户端和服务器之间传输二进制数据,并使用protobuf协议进行序列化和反序列化。 在P4 Runtime API中,客户端应用程序可以使用P4 Runtime API提供的GRPC客户端来向网络设备发送控制指令,例如设置转发表、读取状态信息等。网络设备也必须运行一个P4 Runtime代理,该代理会接收GRPC请求并将其转换为对数据平面的配置或控制指令。 具体地说,当P4程序被加载到网络设备上并启动时,P4 Runtime代理会与网络设备建立一个GRPC服务器,并开始监听来自客户端应用程序的GRPC请求。当客户端应用程序向代理发送请求时,请求将通过GRPC协议传输到P4 Runtime代理,并被转换为P4程序的控制指令。代理将执行这些指令,并将结果通过GRPC协议返回给客户端应用程序。 总之,P4 Runtime API通过GRPC协议提供了一种灵活而高效的方式,让客户端应用程序能够与P4程序运行的网络设备进行交互和控制。 当使用P4编写程序定义网络设备数据平面处理功能时,需要将P4程序编译成二进制文件,然后将该文件加载到网络设备中。然而,当需要动态地配置和控制网络设备时,需要使用P4 Runtime API与网络设备进行交互。P4 Runtime API提供了一组用于配置和控制P4程序的标准接口,这些接口可用于向网络设备发送控制指令,以及从网络设备读取状态和统计信息。 以下是一些常用的P4 Runtime API接口及其作用: -
p4runtime.SetForwardingPipelineConfig(): 用于设置网络设备的转发管道配置。例如,设置使用哪个P4程序、如何分配流表空间、如何配置计数器等。 -p4runtime.WriteTableEntry(): 用于向流表中添加、修改或删除一个规则。例如,设置如何匹配流量、如何动作等。 -p4runtime.ReadTableEntry(): 用于读取流表中的一条规则。例如,读取特定的流表项或读取整个流表。 -p4runtime.PacketIn(): 用于将数据包发送到P4程序进行处理。例如,从数据包中提取头部信息、匹配流表项、执行动作等。 -p4runtime.PacketOut(): 用于将处理后的数据包发送回网络中。例如,将转发或修改后的数据包发送到正确的端口。 -p4runtime.ReadCounters(): 用于读取计数器的值。例如,读取特定的计数器或读取整个计数器数组。 以上是一些常用的P4 Runtime API接口,具体接口及其使用方式可以根据具体的P4程序和网络设备进行调整。
然后我又问了一下,控制平面是怎么使用P4 runtime file的:
- 解析P4 Runtime File:控制平面首先需要解析P4 Runtime File,以了解P4程序中定义的所有控制平面接口及其属性、键和操作等信息。P4 Runtime File使用protobuf格式编码,因此控制平面需要使用protobuf库或类似的库来解析它。 2. 创建P4 Runtime Session:控制平面使用P4 Runtime API与数据平面进行交互,因此需要创建P4 Runtime Session。P4 Runtime Session是与数据平面建立的会话,用于发送控制指令、读取状态信息和处理事件通知等。 3. 发送控制指令:控制平面可以使用P4 Runtime API向数据平面发送控制指令,例如设置转发表、配置计数器、读取状态信息等。控制平面可以根据P4 Runtime File中定义的控制平面接口,构造控制指令,并使用P4 Runtime API将其发送到数据平面。 4. 处理事件通知:P4程序可以生成事件通知,以向控制平面报告某些事件的发生,例如某个计数器达到某个阈值、某个计时器到期等。控制平面可以使用P4 Runtime API注册对这些事件的监听器,并在事件发生时处理它们。
生成的p4.p4info.txt格式上采用的protobuf的可序列化和反序列化格式,P4 Runtime使用protobuf格式来描述P4程序中的各个组件,例如pkg_info、tables、actions和type_info,并将它们序列化为二进制格式的P4 Runtime消息。
pkg_info:指定了该P4程序使用的编程模型,这里是v1model。tables:定义了一个名为MyIngress.ipv4_lpm(别名为ipv4_lpm)的表格,该表格使用LPM(最长前缀匹配)方式匹配IPv4目的地址,可以执行三种不同的动作(NoAction、drop和ipv4_forward),表格大小为1024。actions:定义了三个动作,分别是NoAction、drop和ipv4_forward。其中,NoAction不执行任何操作,drop将数据包丢弃,ipv4_forward根据参数指定的目标地址和端口号将数据包转发到指定的目的地。type_info:未定义任何自定义数据类型,因此为空。
第二步就是去查看一下../../utils/run_exercise.py,在代码中这些文件是怎么被使用的,为了方便,命令这里粘贴到这里:
sudo python3 ../../utils/run_exercise.py -t pod-topo/topology.json -j build/basic.json -b simple_switch_grpc首先看了一下run_exercise.py的main函数,先通过get_args()获取命令行参数:
defget_args():
cwd=os.getcwd()
default_logs=os.path.join(cwd,'logs')
default_pcaps=os.path.join(cwd,'pcaps')
parser=argparse.ArgumentParser()
parser.add_argument('-q','--quiet',help='Suppress log messages.',
action='store_true',required=False,default=False)
# topo就先不看了,这部分应该是tutorial中关于mininet的东西
parser.add_argument('-t','--topo',help='Path to topology json',
type=str,required=False,default='./topology.json')
parser.add_argument('-l','--log-dir',type=str,required=False,default=default_logs)
parser.add_argument('-p','--pcap-dir',type=str,required=False,default=default_pcaps)
# p4编译出来的basic.json被用在这里
parser.add_argument('-j','--switch_json',type=str,required=False)
parser.add_argument('-b','--behavioral-exe',help='Path to behavioral executable',
type=str,required=False,default='simple_switch')继续看一下switch_json的调用的地方:
# Main函数中 exercise=ExerciseRunner(args.topo,args.log_dir,args.pcap_dir,
args.switch_json,args.behavioral_exe,args.quiet)# -- 在这里执行到了下面的create_network函数exercise.run_exercise()
# ExerciseRunner中# -- switch_json : string // json of the compiled p4 example# -- 被复制给了ExerciseRunner的self成员。defcreate_network(self):
# 调用了configureP4Swich
defaultSwitchClass=configureP4Switch( #注意这个
sw_path=self.bmv2_exe,
# 这里赋值给了json_path
json_path=self.switch_json,
log_console=True,
pcap_dump=self.pcap_dir)
# configureP4Switch函数# -- 这里要判断另一个参数,也就是命令行中的-b参数,-b simple_switch_grpc,会传到这个函数defconfigureP4Switch(**switch_args):
""" Helper class that is called by mininet to initialize the virtual P4 switches. The purpose is to ensure each switch's thrift server is using a unique port. """
# 判断 switch_args 的是否包含 "sw_path" 这个键,并且该键对应的值中是否包含字符串 "grpc"
if"sw_path"inswitch_argsand'grpc'inswitch_args['sw_path']:
# If grpc appears in the BMv2 switch target, we assume will start P4Runtime
# BMv2交换机作为数据面设备,负责对网络数据包进行处理和转发,
# 而gRPC作为控制面与数据面之间的通信框架,用于控制器向BMv2交换机发送流表等配置信息,
# 以实现对数据面设备的控制和管理。因此,BMv2交换机和gRPC框架之间存在紧密的关系。
# 这里就是继承了P4RuntimeSwitch
classConfiguredP4RuntimeSwitch(P4RuntimeSwitch):
def__init__(self,*opts,**kwargs):
kwargs.update(switch_args)
P4RuntimeSwitch.__init__(self,*opts,**kwargs)
defdescribe(self):
print("%s -> gRPC port: %d"%(self.name,self.grpc_port))
returnConfiguredP4RuntimeSwitch
else:
# 省略原文
pass
returnConfiguredP4Switch那么接下来就该看P4RuntimeSwitch了, 里面大概就是设定了GRpc的端口和Device_id之类的变量。这个类最初也是从Mininet的Switch类中继承出来的
这个是switch类的定义
basic.json最后调用SetForwardingPipelineConfig被解析
然后拿来给Mininet用,这基本上串起来了。下面看一看basic.p4答案和原版的变化,理解一下, 详尽的语言标准文档在:P4-16-v1.2.3.pdf
diff -urN basic.p4 ./solution/basic.p4 > ./solution/ans_diff.patch
# Result:--- basic.p4 2023-03-06 01:30:55.656308057 +0800+++ ./solution/basic.p4 2023-03-06 01:30:55.660308058 +0800@@ -52,11 +52,23 @@ inout standard_metadata_t standard_metadata) {
state start {- /* TODO: add parser logic */+ transition parse_ethernet; //增加了一个状态+ }++ state parse_ethernet { /* 标准文档中有介绍extract用法 */+ packet.extract(hdr.ethernet);+ transition select(hdr.ethernet.etherType) { //根据etherType条件跳转+ TYPE_IPV4: parse_ipv4;+ default: accept;+ }+ }++ state parse_ipv4 {+ packet.extract(hdr.ipv4); transition accept; // 代表接受,完成。
}-}+}
/*************************************************************************
************ C H E C K S U M V E R I F I C A T I O N *************@@ -79,7 +91,10 @@ }
action ipv4_forward(macAddr_t dstAddr, egressSpec_t port) {- /* TODO: fill out code in action body */+ standard_metadata.egress_spec = port; //这个port从数据包中传参+ hdr.ethernet.srcAddr = hdr.ethernet.dstAddr;+ hdr.ethernet.dstAddr = dstAddr;+ hdr.ipv4.ttl = hdr.ipv4.ttl - 1; }
table ipv4_lpm {@@ -92,14 +107,13 @@ NoAction;
}
size = 1024;- default_action = NoAction();+ default_action = drop(); }
apply {- /* TODO: fix ingress control logic- * - ipv4_lpm should be applied only when IPv4 header is valid- */- ipv4_lpm.apply();+ if (hdr.ipv4.isValid()) {+ ipv4_lpm.apply();+ } }
}
@@ -117,10 +131,10 @@ ************* C H E C K S U M C O M P U T A T I O N **************
*************************************************************************/
-control MyComputeChecksum(inout headers hdr, inout metadata meta) {+control MyComputeChecksum(inout headers hdr, inout metadata meta) { apply {
update_checksum(- hdr.ipv4.isValid(),+ hdr.ipv4.isValid(), { hdr.ipv4.version,
hdr.ipv4.ihl,
hdr.ipv4.diffserv,@@ -137,14 +151,14 @@ }
}
- /*************************************************************************
*********************** D E P A R S E R *******************************
*************************************************************************/
control MyDeparser(packet_out packet, in headers hdr) {
apply {- /* TODO: add deparser logic */+ packet.emit(hdr.ethernet);+ packet.emit(hdr.ipv4); }
}编译后的basic.json也会有相对应的变化。
DPDK
DPDK的入门程序我选择的是《深入浅出DPDK》里面的Helloworld, 其源码如下:
#include<stdio.h>#include<string.h>#include<stdint.h>#include<errno.h>#include<sys/queue.h>//以上头开发环境glibc的相关头文件#include<rte_memory.h>#include<rte_memzone.h>#include<rte_launch.h>#include<rte_eal.h>#include<rte_per_lcore.h>#include<rte_lcore.h>#include<rte_debug.h>staticintlcore_hello(__attribute__((unused))void*arg){
unsignedlcore_id;
lcore_id=rte_lcore_id();//获取逻辑核编号,并输出逻辑核id,返回,线程退出。 printf("hello from core %u\n",lcore_id);
return0;}
intmain(intargc,char**argv){
intret;
unsignedlcore_id;
/* 相关初始化工作,如命令含参数处理,自动检测环境相关条件。以及相关库平台初始化工作*/
ret=rte_eal_init(argc,argv);
if(ret<0)
rte_panic("Cannot init EAL\n");
/* 每个从逻辑核调用回调函数lcore_hello输出相关信息。 */
/*给出RTE_LCORE_FOREACH_SLAVE宏定义 #define RTE_LCORE_FOREACH_SLAVE(i) \ for (i = rte_get_next_lcore(-1, 1, 0); \ i<RTE_MAX_LCORE; \ i = rte_get_next_lcore(i, 1, 0)) */
RTE_LCORE_FOREACH_WORKER(lcore_id)
{
rte_eal_remote_launch(lcore_hello,NULL,lcore_id);
}
/* 再次调用主逻辑核输出相关信息。 */
lcore_hello(NULL);
/* 等待所有从逻辑核调用返回,相当于主线程阻塞等待。*/
rte_eal_mp_wait_lcore();
return0;}其对应的输出结果如下:
EAL: Detected CPU lcores: 2
EAL: Detected NUMA nodes: 1
EAL: Detected shared linkage of DPDK
EAL: Multi-process socket /var/run/dpdk/rte/mp_socket
EAL: Selected IOVA mode 'PA'
EAL: VFIO support initialized
EAL: Probe PCI driver: net_virtio (1af4:1000) device: 0000:00:05.0 (socket -1)
eth_virtio_pci_init(): Failed to init PCI device
EAL: Requested device 0000:00:05.0 cannot be used
TELEMETRY: No legacy callbacks, legacy socket not created
hello from core 1
hello from core 0下面就用GDB跟踪调试一下这个代码:
函数:rte_eal_init(argc, argv)
(74条消息) DPDK lcore学习笔记_rtoax的博客-CSDN博客,此博客中有此函数的主要调度的总结梳理,以及大体模块的介绍。
首先看ret =rte_eal_init(argc, argv);里面干的第一件事,就是重置内部环境,里面有个结构体internal_config,其定义在[DPDK_HOME]/lib/eal/common/eal_internal_cfg.h中,有些变量涉及操作系统的内核机制,所以不过多展开,我自己是通过chatgpt理解的。
之后就是处理输入程序的命令行参数了,参数分为EAL commandline和App commanline两种, 具体调用函数形式如下:
inteal_save_args(intargc,char**argv){
inti,j;
// 调用两次,分别处理EAL和APP的命令参数 rte_telemetry_register_cmd(EAL_PARAM_REQ,handle_eal_info_request,
"Returns EAL commandline parameters used. Takes no parameters");
rte_telemetry_register_cmd(EAL_APP_PARAM_REQ,handle_eal_info_request,
"Returns app commandline parameters used. Takes no parameters");这里第二个参数是一个函数指针,用于具体处理命令行,其定义如下:
/** * This telemetry callback is used when registering a telemetry command. * It handles getting and formatting information to be returned to telemetry * when requested. * * @param cmd * The cmd that was requested by the client. * @param params * Contains data required by the callback function. * @param info * The information to be returned to the caller. * * @return * Length of buffer used on success. * @return * Negative integer on error. */typedefint(*telemetry_cb)(constchar*cmd,constchar*params,
structrte_tel_data*info);rte_telemetry_register_cmd代码中会用到一个静态变量num_callbacks,这个变量没有显式赋值,但是在main函数运行时,这个变量就被赋值成4了。就算我断点打在__start处也是也一样,目前没有想明白。
Breakpoint1,main(argc=1,argv=0x7fffffffe628)athelloworld.c:2525 {(gdb)pnum_callbacks$1=4这里主要用自旋锁调用了realloc函数扩展了callbacks数组,这个callbacks数组记录了每个调用register_cmd的入参:
structcmd_callback{
charcmd[MAX_CMD_LEN];
telemetry_cbfn;
charhelp[RTE_TEL_MAX_STRING_LEN];};将argc个argv复制给eal_args字符串数组。同样也对eal_app_args进行处理。
再处理完命令行参数后,DPDK先对CPU进行了初始化:rte_eal_cpu_init(),主要操作的目录是/sys/devices/system/cpu,其简单介绍如下
/sys/devices/system/cpu目录是 Linux 系统中的一个虚拟文件系统,用于显示和操作 CPU 相关的信息。在这个目录下,每个目录名都代表一个逻辑处理器(或核心),而目录中的文件则记录了与逻辑处理器相关的信息。
在/sys/devices/system/cpu目录下可以找到很多与 CPU 相关的文件和子目录,例如:
/sys/devices/system/cpu/cpu*/topology目录用于显示逻辑处理器的拓扑结构信息,比如逻辑处理器的 ID、所属的物理 CPU 和 NUMA 节点等;/sys/devices/system/cpu/cpu*/cpufreq目录用于显示和设置 CPU 频率相关的信息,比如 CPU 的最小、最大和当前频率等;/sys/devices/system/cpu/cpu*/cache目录用于显示 CPU 缓存的相关信息,比如缓存的大小、类型、行大小等;/sys/devices/system/cpu/online文件用于控制哪些逻辑处理器是在线的;/sys/devices/system/cpu/offline文件用于控制哪些逻辑处理器是离线的;/sys/devices/system/cpu/kernel_max文件用于显示系统支持的最大逻辑处理器数目
函数中首先获取了当前结构体rte_config, 这个结构体都是关于逻辑处理器的,其定义如下:
/** * Structure storing internal configuration (per-lcore) */structlcore_config{
pthread_tthread_id; /**< pthread identifier */// 用于表示当前逻辑核心所在的线程intpipe_main2worker[2]; /**< communication pipe with main */// 0是主到副的读端,1是写端intpipe_worker2main[2]; /**< communication pipe with main */
lcore_function_t*volatilef;/**< function to call */// 当前逻辑核心执行的函数void*volatilearg; /**< argument of function */
volatileintret; /**< return value of function */
volatileenumrte_lcore_state_tstate;/**< lcore state */// 可能的取值有WAIT, RUNNING, FINISHEDunsignedintsocket_id; /**< physical socket id for this lcore */
unsignedintcore_id; /**< core number on socket for this lcore */
intcore_index; /**< relative index, starting from 0 */// 可以唯一的区分lcoreuint8_tcore_role; /**< role of core eg: OFF, RTE, SERVICE *//* OFF: 没有被DPDK使用 * RTE: 这个core被用来进行DPDK数据包处理 * SERVICE: 用于DPDK本身的程序服务,例如定时器,缓存清除等,这个核心通常与RTE角色翻开,以免影响数据包性能 */
rte_cpuset_tcpuset; /**< cpu set which the lcore affinity to */};/* internal configuration (per-core) */structlcore_configlcore_config[RTE_MAX_LCORE];这里需要说明的是CPU的socket说的是插槽,插槽分为Socket,Slot两种,可以用下面命令查看
cat /sys/devices/system/cpu/cpu0/topology/physical_package_idcpu_set_t的定义:
/* Size definition for CPU sets. */#define __CPU_SETSIZE 1024#define __NCPUBITS (8 * sizeof (__cpu_mask))/* Type for array elements in 'cpu_set_t'. */typedef__CPU_MASK_TYPE__cpu_mask;
/* Data structure to describe CPU mask. */typedefstruct{
__cpu_mask__bits[__CPU_SETSIZE/__NCPUBITS];}cpu_set_t;可以看到cpu_set_t这个结构体本质上是一个数组,在x86_64架构中,__CPU_MASK_TYPE是unsigned long int类型,那就可以算出来__bits的长度有128位(1024/8,sizeof(__cpu_mask)约掉)。这个也就是上面RTE_MAX_LCORE的取值128。
接下来就是函数就是通过循环128次,给lcore_config进行设置,因为每个用户的CPU硬件不一样,所以里面肯定需要判断,并不真的需要128个lcore。
for(lcore_id=0;lcore_id<RTE_MAX_LCORE;lcore_id++){
lcore_config[lcore_id].core_index=count;
/* init cpuset for per lcore config */
CPU_ZERO(&lcore_config[lcore_id].cpuset);// clear set
/* find socket first */
socket_id=eal_cpu_socket_id(lcore_id);// 调用这个函数获取socket id lcore_to_socket_id[lcore_id]=socket_id;
if(eal_cpu_detected(lcore_id)==0){// 检测lcore_id的cpu是否真实存在,就是到sys/cpu的目录中检测。 config->lcore_role[lcore_id]=ROLE_OFF;
lcore_config[lcore_id].core_index=-1;
continue;
}
/* By default, lcore 1:1 map to cpu id */
CPU_SET(lcore_id,&lcore_config[lcore_id].cpuset); // 到这里就是检测成功,一个lcore占用一个核心
/* By default, each detected core is enabled */
/* 打断插入一下enum enum rte_lcore_role_t { ROLE_RTE, ROLE_OFF, ROLE_SERVICE, ROLE_NON_EAL, }; */
config->lcore_role[lcore_id]=ROLE_RTE;
lcore_config[lcore_id].core_role=ROLE_RTE;
lcore_config[lcore_id].core_id=eal_cpu_core_id(lcore_id);
lcore_config[lcore_id].socket_id=socket_id;
RTE_LOG(DEBUG,EAL,"Detected lcore %u as "
"core %u on socket %u\n",
lcore_id,lcore_config[lcore_id].core_id,
lcore_config[lcore_id].socket_id);
count++;
}完成CPU的设置后就是处理命令行参数了:
/* Parse the argument given in the command line of the application */staticinteal_parse_args(intargc,char**argv){}在此之后就会调用插件库,跟踪库,然后初始化中断:
(74条消息) DPDK初始化分析(二)_rte_mp_handle_whenloce的博客-CSDN博客
intrte_eal_intr_init(void){
intret=0;
TAILQ_INIT(&intr_sources);//生成一个链表,用来记录if(pipe(intr_pipe.pipefd)<0){//采用epll机制处理rte_errno=errno;
return-1;
}
ret=rte_ctrl_thread_create(&intr_thread,"eal-intr-thread",NULL,
eal_intr_thread_main,NULL);
if(ret!=0){
rte_errno=-ret;
RTE_LOG(ERR,EAL,"Failed to create thread for interrupt handling\n");}
returnret;}这里大体上有三个比较重要的地方,分别是IO多路复用的Epoll,中断机制以及多线程启动。
这三部分内容设计的比较多。因此将放到下一篇笔记。
总结
这篇博客的内容比较长,当然,涉及的知识面也相对较多,有个地方总结还是很不错的。本篇基本上探明了P4开发流程和对DPDK进行了基本的探讨,下周将继续研究DPDK,并对P4和DPDK的结合体
参考
- ^Maglev: A Fast and Reliable Software Network Load Balancerhttps://www.usenix.org/conference/nsdi16/technical-sessions/presentation/eisenbud
P4 tutorials 实例分析
https://zhuanlan.zhihu.com/c_1317790033336836096
环境
OS:Ubuntu16.04
behavioral-model:1.13.0
p4c:1.2.0
mininet:2.3.0d6
tutorials:p4lang/tutorials
P4编程环境安装完成的目录结构如下:
├── behavioral-model
├── grpc
├── mininet
├── p4c
├── PI
├── protobuf
└── tutorials实例分析主要操作是tutorials目录,结构如下:
├── exercises
├── LICENSE
├── p4-cheat-sheet.pdf
├── P4_tutorial.pdf
├── Learning tracker
├── utils
└── vm其中P4_tutorial.pdf 为P4语言教程可以打开学习一下,exercises目录存放的是P4程序学习示例,utils里面存放了一些用于调用各个组件(mininet, bmv2, PI, p4c)的脚本,有了这些脚本,我们可以专注于p4代码的开发,控制面的编写,以及拓扑的构建,而不需要去关心去了解bmv2的启动命令,p4c的调用选项等等。具体如何使用,也是非常的简单,我们进入一个具体的例子查看:
root@ubuntu:~/P4/tutorials/exercises/basic# tree -L 1
.
├── basic.p4
├── build
├── logs
├── Makefile
├── pcaps
├── pod-topo
├── README.md
├── receive.py
├── send.py
├── solution
└── triangle-topo
6 directories, 5 files具体操作通过查看README.md文件下面步骤进行
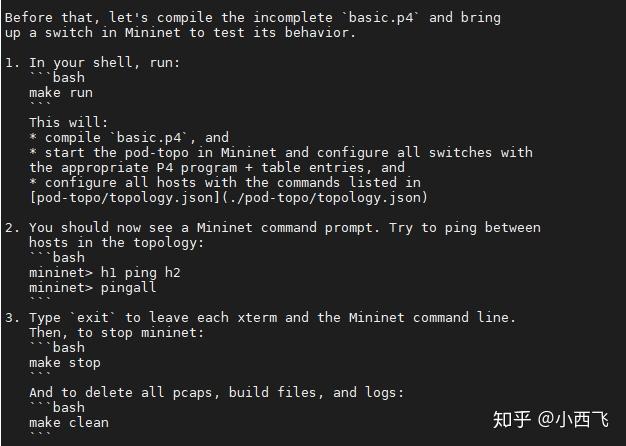
可以看到,通过make命令执行Makefile文件,我们可以调用utils下Makefile文件并执行下面的脚本,让我们的p4代码跑起来:

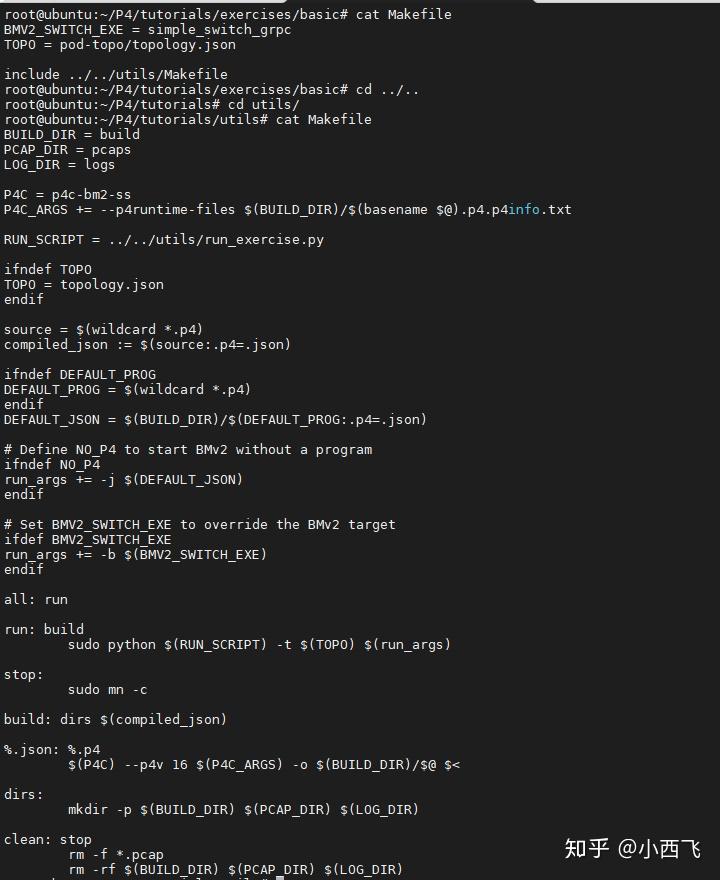
调用make run,我们可以运行当前目录下(以basic目录为例)的代码,它将执行以下几个步骤:
- 编译basic.p4 代码,生成basic.json;
- 解析topology.json, 并且构建相应的mininet仿真拓扑,按照该拓扑启动一台或者多台BMv2交换机,以及一些host;
- 启动BMv2的同时会将p4代码编译产生的json文件导入;
- 启动BMv2后会解析 sN-runtime.json 文件,将其载入交换机sN流表之中;
- 进入mininet命令行,同时开始记录log以及搜集pcap文件;
可以从下面执行过程看到以上描述的几个步骤:
root@ubuntu:~/P4/tutorials/exercises/basic# make run
mkdir -p build pcaps logs
p4c-bm2-ss --p4v 16 --p4runtime-files build/basic.p4.p4info.txt -o build/basic.json basic.p4
sudo python ../../utils/run_exercise.py -t pod-topo/topology.json -j build/basic.json -b simple_switch_grpc
Reading topology file.
Building mininet topology.
Configuring switch s3 using P4Runtime with file pod-topo/s3-runtime.json
- Using P4Info file build/basic.p4.p4info.txt...
- Connecting to P4Runtime server on 127.0.0.1:50053 (bmv2)...
- Setting pipeline config (build/basic.json)...
- Inserting 5 table entries...
- MyIngress.ipv4_lpm: (default action) => MyIngress.drop()
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.1.1', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:01:00, port=1)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.2.2', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:01:00, port=1)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.3.3', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:02:00, port=2)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.4.4', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:02:00, port=2)
Configuring switch s2 using P4Runtime with file pod-topo/s2-runtime.json
- Using P4Info file build/basic.p4.p4info.txt...
- Connecting to P4Runtime server on 127.0.0.1:50052 (bmv2)...
- Setting pipeline config (build/basic.json)...
- Inserting 5 table entries...
- MyIngress.ipv4_lpm: (default action) => MyIngress.drop()
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.1.1', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:03:00, port=4)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.2.2', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:04:00, port=3)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.3.3', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:03:33, port=1)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.4.4', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:04:44, port=2)
Configuring switch s1 using P4Runtime with file pod-topo/s1-runtime.json
- Using P4Info file build/basic.p4.p4info.txt...
- Connecting to P4Runtime server on 127.0.0.1:50051 (bmv2)...
- Setting pipeline config (build/basic.json)...
- Inserting 5 table entries...
- MyIngress.ipv4_lpm: (default action) => MyIngress.drop()
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.1.1', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:01:11, port=1)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.2.2', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:02:22, port=2)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.3.3', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:03:00, port=3)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.4.4', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:04:00, port=4)
Configuring switch s4 using P4Runtime with file pod-topo/s4-runtime.json
- Using P4Info file build/basic.p4.p4info.txt...
- Connecting to P4Runtime server on 127.0.0.1:50054 (bmv2)...
- Setting pipeline config (build/basic.json)...
- Inserting 5 table entries...
- MyIngress.ipv4_lpm: (default action) => MyIngress.drop()
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.1.1', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:01:00, port=2)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.2.2', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:01:00, port=2)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.3.3', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:02:00, port=1)
- MyIngress.ipv4_lpm: hdr.ipv4.dstAddr=['10.0.4.4', 32] => MyIngress.ipv4_forward(dstAddr=08:00:00:00:02:00, port=1)
s1 -> gRPC port: 50051
s2 -> gRPC port: 50052
s3 -> gRPC port: 50053
s4 -> gRPC port: 50054
**********
h1
default interface: eth0 10.0.1.1 08:00:00:00:01:11
**********
**********
h2
default interface: eth0 10.0.2.2 08:00:00:00:02:22
**********
**********
h3
default interface: eth0 10.0.3.3 08:00:00:00:03:33
**********
**********
h4
default interface: eth0 10.0.4.4 08:00:00:00:04:44
**********
Starting mininet CLI
======================================================================
Welcome to the BMV2 Mininet CLI!
======================================================================
Your P4 program is installed into the BMV2 software switch
and your initial runtime configuration is loaded. You can interact
with the network using the mininet CLI below.
To inspect or change the switch configuration, connect to
its CLI from your host operating system using this command:
simple_switch_CLI --thrift-port <switch thrift port>
To view a switch log, run this command from your host OS:
tail -f /root/P4/tutorials/exercises/basic/logs/<switchname>.log
To view the switch output pcap, check the pcap files in /root/P4/tutorials/exercises/basic/pcaps:
for example run: sudo tcpdump -xxx -r s1-eth1.pcap
To view the P4Runtime requests sent to the switch, check the
corresponding txt file in /root/P4/tutorials/exercises/basic/logs:
for example run: cat /root/P4/tutorials/exercises/basic/logs/s1-p4runtime-requests.txt
mininet>新版本的tutorials中,载入静态流表项时采用了runtime方法,而非之前的CLI方法,我们查看一下s1-runtime.json:
root@ubuntu:~/P4/tutorials/exercises/basic/pod-topo# cat s1-runtime.json
{
"target": "bmv2",
"p4info": "build/basic.p4.p4info.txt",
"bmv2_json": "build/basic.json",
"table_entries": [
{
"table": "MyIngress.ipv4_lpm",
"default_action": true,
"action_name": "MyIngress.drop",
"action_params": { }
},
{
"table": "MyIngress.ipv4_lpm",
"match": {
"hdr.ipv4.dstAddr": ["10.0.1.1", 32]
},
"action_name": "MyIngress.ipv4_forward",
"action_params": {
"dstAddr": "08:00:00:00:01:11",
"port": 1
}
},
{
"table": "MyIngress.ipv4_lpm",
"match": {
"hdr.ipv4.dstAddr": ["10.0.2.2", 32]
},
"action_name": "MyIngress.ipv4_forward",
"action_params": {
"dstAddr": "08:00:00:00:02:22",
"port": 2
}
},
{
"table": "MyIngress.ipv4_lpm",
"match": {
"hdr.ipv4.dstAddr": ["10.0.3.3", 32]
},
"action_name": "MyIngress.ipv4_forward",
"action_params": {
"dstAddr": "08:00:00:00:03:00",
"port": 3
}
},
{
"table": "MyIngress.ipv4_lpm",
"match": {
"hdr.ipv4.dstAddr": ["10.0.4.4", 32]
},
"action_name": "MyIngress.ipv4_forward",
"action_params": {
"dstAddr": "08:00:00:00:04:00",
"port": 4
}
}
]
}这是一个json文件,可以看到,其作用是定义一个个具体的流表项,标明了流表项所处的位置,匹配域,匹配模式,动作名,以及动作参数。这些字段都依赖于我们P4代码中所自定义的流表,匹配域和动作。
mininet> net
h1 eth0:s1-eth1
h2 eth0:s1-eth2
h3 eth0:s2-eth1
h4 eth0:s2-eth2
s1 lo: s1-eth1:eth0 s1-eth2:eth0 s1-eth3:s3-eth1 s1-eth4:s4-eth2
s2 lo: s2-eth1:eth0 s2-eth2:eth0 s2-eth3:s4-eth1 s2-eth4:s3-eth2
s3 lo: s3-eth1:s1-eth3 s3-eth2:s2-eth4
s4 lo: s4-eth1:s2-eth3 s4-eth2:s1-eth4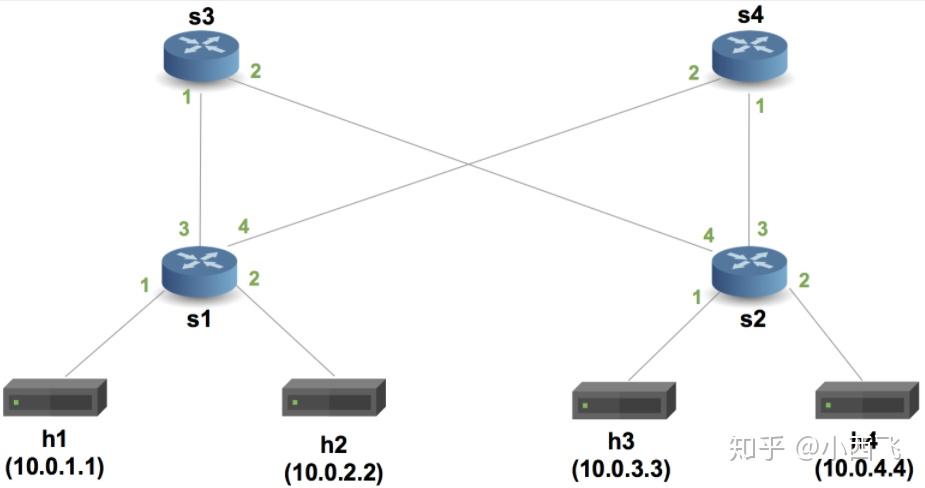
接下来我们开始解读basic.p4代码,basic目录下的只有TODO部分没有具体实现,代码的具体实现在basic/solution目录下面。make run时需要把文件复制到basic目录运行。
P4是一种高级数据面编程语言,既然是高级语言,那么其设计本身就有着很高的抽象程度。我们先来看一种图:
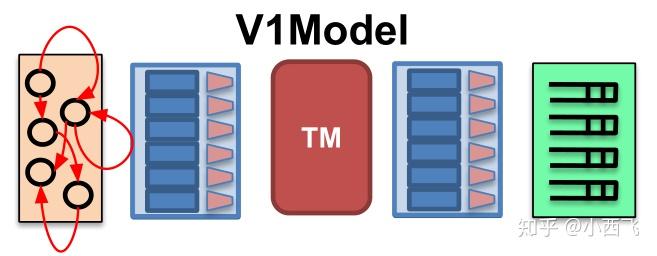
这是P4中提供的最简单最易理解的编程结构,V1Model。可以看到它由5个模块组成,他们的名字分别是(从左到右):
- Parser: 解析器, 解析并且提取数据包头的各个字段。
- Ingress: Ingress处理,在这里定义Ingress流水线。
- TM: Traffic manager,有一些队列,用于流量控制(一些队列相关的metadata在此更新)。
- Egress: Egress, 在这里定义Egress流水线。
- Deparser:用于重组数据包,因为数据包在处理过程中经历了分解和处理。所以最后转发的时候需要重组一下。
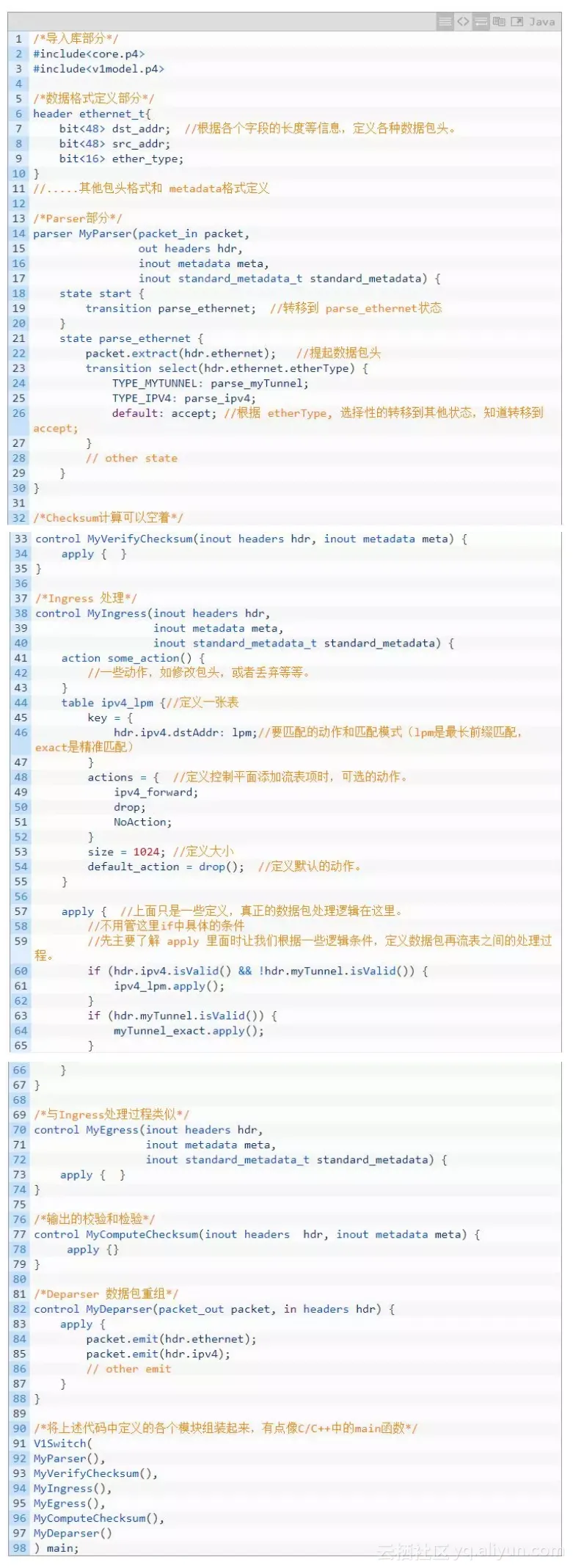
P4为我们提供了上述抽象,我们就可以把所有的交换机理解为上述的模型,然后按照上述模型进行开发就可以了。所以,按照上述模型,分析basic用例的代码结构:
/* -*- P4_16 -*- */
#include <core.p4>
#include <v1model.p4>
const bit<16> TYPE_IPV4 = 0x800;
/*************************************************************************
*********************** H E A D E R S ***********************************
*************************************************************************/
/*数据格式定义部分*/
typedef bit<9> egressSpec_t; //根据各个字段的长度等信息,定义各种数据包头。
typedef bit<48> macAddr_t; //根据各个字段的长度等信息,定义各种数据包头。
typedef bit<32> ip4Addr_t; //根据各个字段的长度等信息,定义各种数据包头。
header ethernet_t {
macAddr_t dstAddr;
macAddr_t srcAddr;
bit<16> etherType;
}
header ipv4_t {
bit<4> version;
bit<4> ihl;
bit<8> diffserv;
bit<16> totalLen;
bit<16> identification;
bit<3> flags;
bit<13> fragOffset;
bit<8> ttl;
bit<8> protocol;
bit<16> hdrChecksum;
ip4Addr_t srcAddr;
ip4Addr_t dstAddr;
}
struct metadata {
/* empty */
}
struct headers {
ethernet_t ethernet;
ipv4_t ipv4;
}
/*************************************************************************
*********************** P A R S E R ***********************************
*************************************************************************/
parser MyParser(packet_in packet,
out headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
state start {
transition parse_ethernet; //转移到 parse_ethernet状态
}
state parse_ethernet {
packet.extract(hdr.ethernet); //根据定义结构提取以太包头
transition select(hdr.ethernet.etherType) { //根据etherType, 选择转移到其他状态,直到转移到accept;
TYPE_IPV4: parse_ipv4; //如果是0x0800,则转移到parse_ipv4状态
default: accept; //默认是接受,进入下一步处理
}
}
state parse_ipv4 {
packet.extract(hdr.ipv4); //提取ip包头
transition accept;
}
}
/*************************************************************************
************ C H E C K S U M V E R I F I C A T I O N *************
*************************************************************************/
control MyVerifyChecksum(inout headers hdr, inout metadata meta) {
apply { }
}
/*************************************************************************
************** I N G R E S S P R O C E S S I N G *******************
*************************************************************************/
control MyIngress(inout headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
action drop() {
mark_to_drop(standard_metadata); //内置函数,将当前数据包标记为即将丢弃数据包
}
action ipv4_forward(macAddr_t dstAddr, egressSpec_t port) {
standard_metadata.egress_spec = port; //将输出的端口从参数中取出,参数是由控制面配置
hdr.ethernet.srcAddr = hdr.ethernet.dstAddr; //原始数据包的源地址改为目的地址
hdr.ethernet.dstAddr = dstAddr; //目的地址改为控制面传入的新地址
hdr.ipv4.ttl = hdr.ipv4.ttl - 1; //ttl要减去1
}
table ipv4_lpm { //定义一张表
key = { //流表匹配域关键字
hdr.ipv4.dstAddr: lpm; //匹配模式(lpm是最长前缀匹配,exact是精准匹配,ternary是三元匹配)
}
actions = { //流表动作集合
ipv4_forward; //转发数据,需要自定义
drop; //丢弃动作
NoAction; //空动作
}
size = 1024; //流表可以容纳最大流表项
default_action = drop(); //默认动作
}
apply {
if (hdr.ipv4.isValid()) {
ipv4_lpm.apply();
}
}
}
/*************************************************************************
**************** E G R E S S P R O C E S S I N G *******************
*************************************************************************/
control MyEgress(inout headers hdr,
inout metadata meta,
inout standard_metadata_t standard_metadata) {
apply { }
}
/*************************************************************************
************* C H E C K S U M C O M P U T A T I O N **************
*************************************************************************/
control MyComputeChecksum(inout headers hdr, inout metadata meta) {
apply {
update_checksum(
hdr.ipv4.isValid(),
{ hdr.ipv4.version,
hdr.ipv4.ihl,
hdr.ipv4.diffserv,
hdr.ipv4.totalLen,
hdr.ipv4.identification,
hdr.ipv4.flags,
hdr.ipv4.fragOffset,
hdr.ipv4.ttl,
hdr.ipv4.protocol,
hdr.ipv4.srcAddr,
hdr.ipv4.dstAddr },
hdr.ipv4.hdrChecksum,
HashAlgorithm.csum16);
}
}
/*************************************************************************
*********************** D E P A R S E R *******************************
*************************************************************************/
control MyDeparser(packet_out packet, in headers hdr) {
apply { //注意封包的先后顺序
packet.emit(hdr.ethernet);
packet.emit(hdr.ipv4);
}
}
/*************************************************************************
*********************** S W I T C H *******************************
*************************************************************************/
/*将上述代码中定义的各个模块组装起来,有点像C/C++中的main函数*/
V1Switch(
MyParser(), //解析数据包,提取包头
MyVerifyChecksum(), //校验和验证
MyIngress(), //输入处理
MyEgress(), //输出处理
MyComputeChecksum(), //计算新的校验和
MyDeparser() //逆解析器
) main;上例中几个模块是用函数来封装的。
parser解析数据包:parser是一个有限状态机。从 start 状态开始,每一个状态便解析一种协议,然后根据低层协议的类型字段,选择解析高一层协议的状态,然后transition到该状态解析上层协议,最后transition到accept;
Ingress:Ingress中,要实现一个转发功能,因此需要定义一个用于转发的流表;
Checksum 和 Deparser:这两个部分都有高度抽象的内置函数直接完成;
控制面代码在pod-topo目录下面s1-runtime.json、s2-runtime.json、s3-runtime.json、s4-runtime.json,定义好了每个交接机的流表项。
测试
- 根据README.md的步骤进行测试结果如下截图
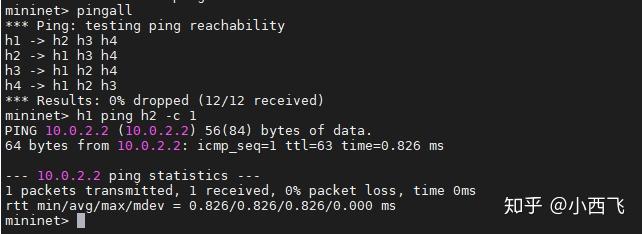
根据测试结果看丢包率为0,说明转发功能实现了。
2.连接到交换机查看流表
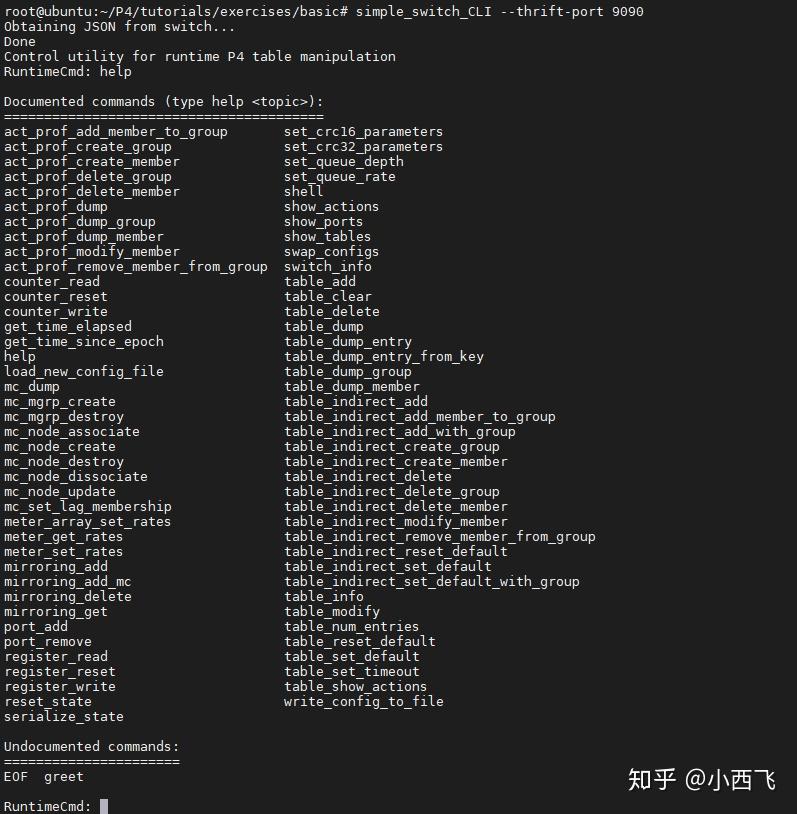
通过simple_switch_CLI --thrift-port 9090命令可以连接到s1交换机进行操作。--thrift-port默认端口是9090,后面依此类推。可以通这help查看所有操作命令。
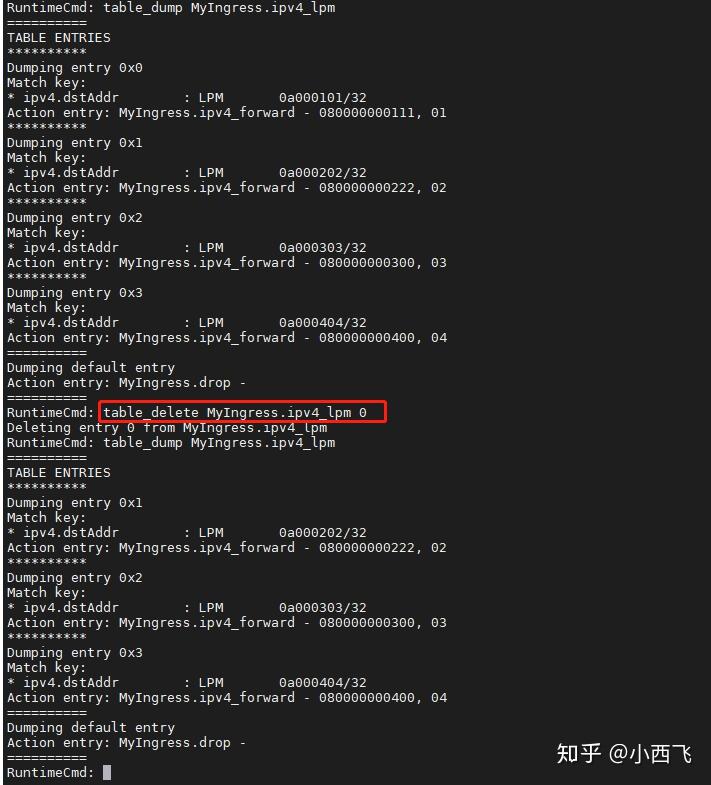
3.在s1上删除10.0.1.1对应的流表(命令:table_delete MyIngress.ipv4_lpm 0)进行测试
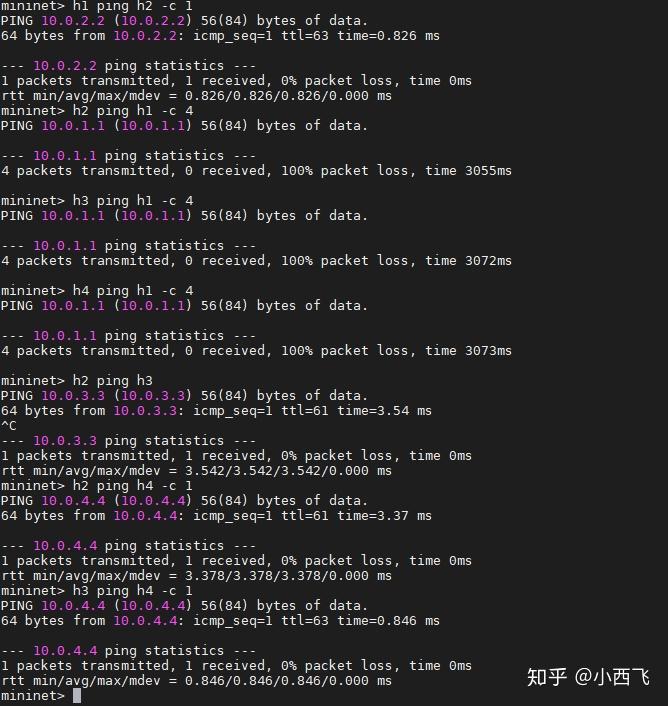
从测试结查可以看出删除到h1的流表项后,到h1都不通,h2, h3, h4三台主机之间是可以互相ping通。
至此所有分析都完成。