目录
[2 使用公开数据集进行深度学习遥感地物分类](#2 使用公开数据集进行深度学习遥感地物分类)
[2.3.2 UNET代码实现](#2.3.2 UNET代码实现)
2 使用公开数据集进行深度学习遥感地物分类
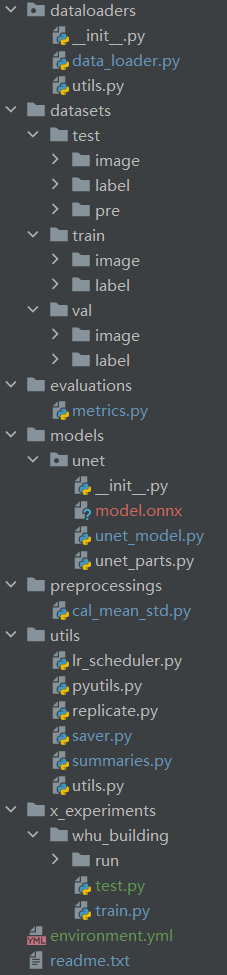
2.1代码整体介绍
readme中对各个路径的内容进行了简易的介绍。
preprocessings 数据预处理工具
datasets 数据存放位置
dataloaders 数据的dataloader
models 模型
evaluations 评价指标类
utils 用来储存实验过程的常用工具与函数
environment.yml conda环境配置文件,供大家配置环境参考
================================================================
前边都是常用工具代码,不太常改,x_experiments是进行实验经常需要修改的
x_experiments 实验代码、记录、与结果详细目录如下
2.2问题定义与数据收集
2.2.1问题定义
在模型,损失函数或者训练方法等方面进行创新来提高遥感地物分类的精度,或者精简模型,使用更小的模型达到较好的效果。
2.2.2数据收集
收集公开的、大家进行精度对比的公开数据集,公开的地物分类有很多,既有多分类语义分割数据集数据集,也有专门针对一种地物分类的语义分割数据集数据集,如水体,建筑,耕地,道路等等,大家可以自行检索下载,他们都有着相似的数据组织方式,此处以WHU 建筑物数据集中的航空影像数据集为例来进行介绍与演示。
WHU 建筑物数据集由航空数据集和卫星数据集组成。其中的航空影像数据集,来自新西兰土地信息服务网站,地面分辨率降采样为0.3 m,选取的克赖斯特彻奇内大约有2.2万栋独立建筑。共8189块512×512像素的图像,并将样本分为3个部分:一个训练集(4736幅),一个验证集(1036幅)和一个测试集(2416幅)。
数据原始下载地址:http://study.rsgis.whu.edu.cn/pages/download/ 之前可以下载,但是不知道什么时候失效了,但是本教程配套数据中提供了该数据,供大家学习使用。
数据来源于以下研究:
J i S, Wei S, Lu M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data SetJ. IEEE Transactions on Geoscience and Remote Sensing, 2018 (99): 1-13.
目录结构如下
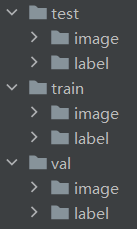
以目录的形式将数据划分为训练、测试和验证数据集,各个子目录内image与label中有着数量一致,名称一一对应的图像和标签数据,如下

image

label
2.3数据预处理
公开的数据集往往不需要过多是预处理,主要需要将数据加载到Dataset类,在训练时供DataLoader批量加载使用。
2.3.1Dataset与DataLoader是什么
PyTorch 的 Dataset 类是用于表示数据集的一个抽象基类。它定义了如何从数据源加载和访问数据。Dataset 类是 PyTorch 数据处理管道中的一个重要组成部分,通常与 DataLoader 类一起使用,以实现高效的数据加载和批处理。
Dataset 主要功能
- 数据加载 :
Dataset类提供了一种标准化的方式来加载数据。你可以自定义数据加载逻辑,包括读取文件、预处理数据等。 - 数据访问:通过索引访问数据,使得数据可以被逐个或批量地访问。
- 数据预处理:可以在数据加载时进行预处理操作,如图像缩放、归一化等。
要使用 Dataset 类,你需要继承它并实现两个主要的方法:
__len__:返回数据集的大小(即数据样本的数量)。__getitem__:根据给定的索引返回一个数据样本。
Dataset 类通常与 DataLoader 类一起使用,以实现批量加载、数据打乱、多线程加载等功能。
2.3.2构建RSDataset与RSDataLoader
构建RSDataset来加载WHU 建筑物数据集,代码如下:
import numpy as np
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import os
import cv2
def get_filename(path, filetype):
# 获取指定路径下指定文件类型的文件名列表
name = []
final_name = []
for root, dirs, files in os.walk(path):
for i in files:
if filetype in i[-4:]:
name.append(i.replace(filetype, ''))
final_name = [item + filetype for item in name]
return final_name
class RSDataset(Dataset):
# 定义自定义数据集类
def __init__(self, image_folder, label_folder):
self.image_folder = image_folder # 图像文件夹路径
self.label_folder = label_folder # 标签文件夹路径
# 获取图像和标签文件名列表
self.filenames = get_filename(self.image_folder, filetype='tif')
self.images_path = [self.image_folder + i for i in self.filenames]
self.labels_path = [self.label_folder + i for i in self.filenames]
def __len__(self):
# 返回数据集的长度,即图像文件的数量
return len(self.images_path)
def __getitem__(self, idx):
# 读取图像和标签文件
image = cv2.imread(self.images_path[idx]) / 1.0 #转换格式int-》float
label = cv2.imread(self.labels_path[idx], 0)/255 #0是背景,255是建筑,/255后就是0是背景,1是建筑
# image标准化
image = np.transpose(image, (2, 0, 1))
mean = [110.9934057 , 113.53421436, 105.33440688]
std = [52.11187492, 49.05592545, 51.32822532]
for i in range(image.shape[0]):
image[i] = (image[i] - mean[i]) / std[i]
# 转换为PyTorch张量
image = torch.from_numpy(image).float()
label = torch.from_numpy(label).long()
# 返回图像和标签
return image, label
if __name__ == "__main__":
image_path=r'../datasets/train/image/'
label_path=r'../datasets/train/label/'
dataset = RSDataset(image_path, label_path)
rsdata_loader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=8, pin_memory=True, drop_last=True)
print(len(rsdata_loader.dataset))输出为:4736,为data/train/image或data/train/label中图片的数量
2.4选择合适的模型架构
这里我们选用UNet做为主要模型,模型代码来源于网络,供学习参考。
2.3.1UNET模型介绍
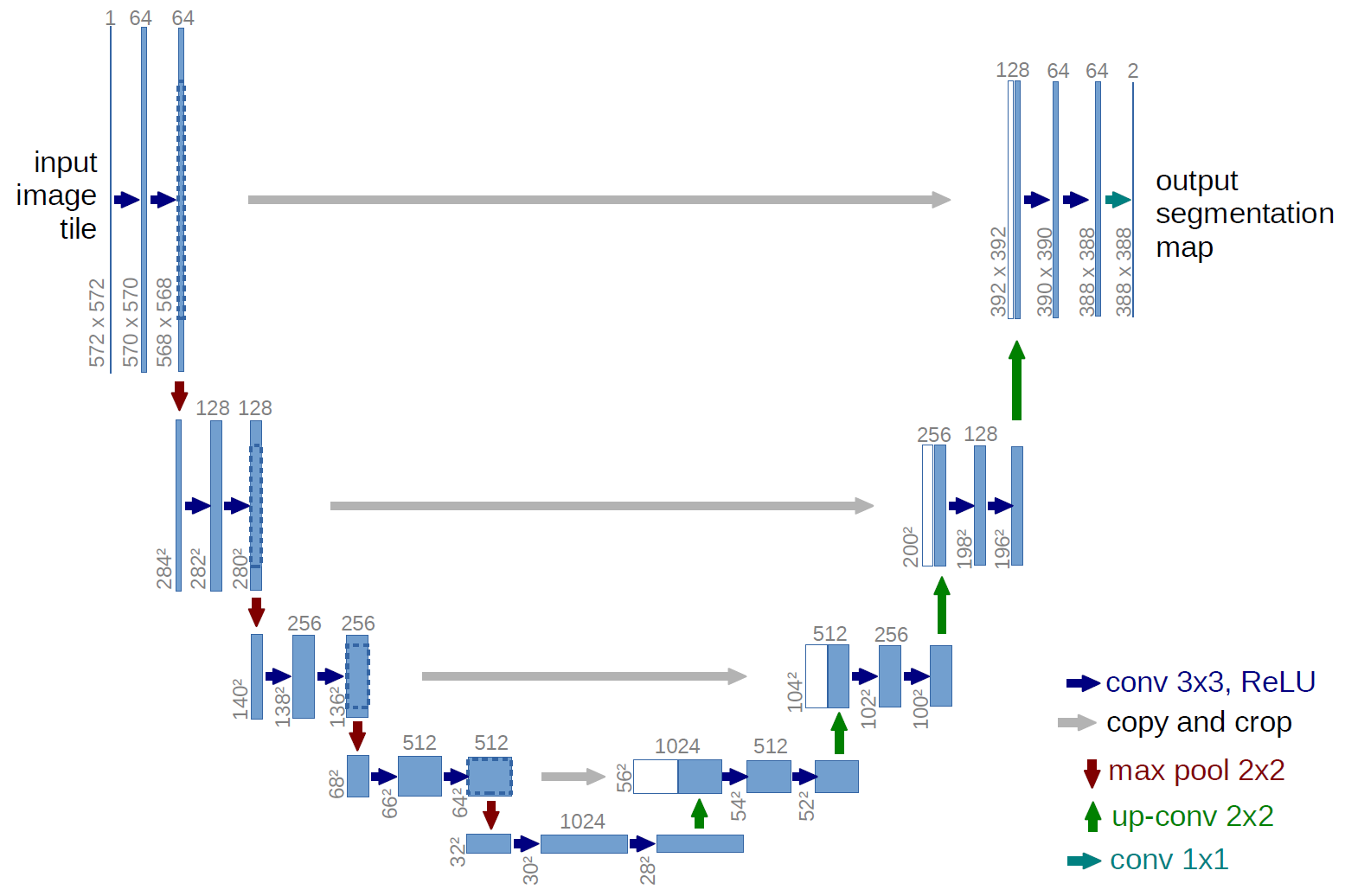
UNET是一种卷积神经网络(CNN)架构,最初被设计用于生物医学图像分割任务。它采用了一种独特的"U"形结构,使得网络能够精确地定位图像中的目标对象,并对其进行分割。
UNET的工作原理基于编码器(下采样)和解码器(上采样)的结构。编码器通过卷积层和池化层逐渐减小图像的尺寸,同时提取特征;解码器则通过转置卷积层(或上采样)逐步恢复图像尺寸,并合并来自编码器的特征,以生成最终的分割图像。
下图为UNET模型的示意图,图中的特征大小由输入图片,卷积步长以及是否采用padding等决定,此处仅做示意作用,具体模型请参考代码与详细模型结构图。
2.3.2 UNET代码实现
""" Parts of the U-Net model """
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
""" Full assembly of the parts to form the complete network """
import torch.nn.functional as F
from models.unet.unet_parts import *
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64) # (convolution => [BN] => ReLU) * 2
self.down1 = Down(64, 128) # Downscaling with maxpool(2) then double conv
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc1 = OutConv(64, 32)
self.outc2 = OutConv(32, 16)
self.outc3 = OutConv(16, 8)
self.outc4 = OutConv(8, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc1(x)
logits = self.outc2(logits)
logits = self.outc3(logits)
logits = self.outc4(logits)
return logits
if __name__ == "__main__":
model = UNet(n_channels=3, n_classes=2)
# 创建一个示例网络
import netron
import onnx
print(model)
model.eval()
input = torch.rand(1, 3, 256, 256)
output = model(input)
print(output.size())
torch.onnx.export(model=model, args=input, f='model.onnx', input_names=['image'], output_names=['feature_map'])
onnx.save(onnx.shape_inference.infer_shapes(onnx.load("model.onnx")), "model.onnx")
netron.start("model.onnx")输出的网络结构为:
UNet(
(inc): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(down1): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down2): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down3): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down4): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(up1): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up2): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up3): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up4): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(outc1): OutConv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
)
(outc2): OutConv(
(conv): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1))
)
(outc3): OutConv(
(conv): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1))
)
(outc4): OutConv(
(conv): Conv2d(8, 2, kernel_size=(1, 1), stride=(1, 1))
)
)
此图是模型的具体结构,并模拟了输入一张256*256大小的RGB 3通道图像,输出二分类结果的数据流。
2.5模型训练评估
模型的训练与评估一般是交叉进行的,用训练集训练一轮或者多轮,用验证集进行一次评估。边训练边评估,可以实时监测模型的效果与训练过程,防止过拟合,并不断调整超参数,使得模型优化到理想的效果。
在训练前,还需要设置一些超参数,如学习率、lr调度器模式、损失函数的动量、训练的epoch数、训练输入的batch大小等等,具体设置见代码。
import os
import torch
import argparse
from dataloaders import data_loader
from torch.utils.data import DataLoader
from models.unet.unet_model import UNet
from evaluations.metrics import Evaluator2C
from utils.lr_scheduler import LR_Scheduler
from utils.saver import Saver
from utils.summaries import TensorboardSummary
from utils.replicate import patch_replication_callback
from utils.utils import AverageMeter
from tqdm import tqdm
import time
import torch.nn as nn
torch.backends.cudnn.benchmark = True
class Trainer(object):
def __init__(self, args):
# 实验记录
self.args = args
self.saver = Saver(args) # 创建模型保存文件夹
self.saver.save_experiment_config() # 保存args参数
self.summary = TensorboardSummary(self.saver.experiment_dir) # 在保存路径下建立tensorboard可视化日志
self.writer = self.summary.create_summary() # 定义SummaryWriter
# 训练集
self.train_dataset = data_loader.RSDataset(args.input_dir_train, args.label_dir_train)
self.train_loader = DataLoader(self.train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=8,pin_memory=True, drop_last=True)
# 验证集
self.val_dataset = data_loader.RSDataset(args.input_dir_val, args.label_dir_val)
self.val_loader = DataLoader(self.val_dataset, batch_size=args.batch_size,shuffle=False, num_workers=8, pin_memory=True, drop_last=False)
# 定义网络
self.model = UNet(n_channels=3, n_classes=2)
train_params = self.model.parameters()
# 定义优化器
self.optimizer = torch.optim.SGD(train_params, momentum=args.momentum,weight_decay=args.weight_decay, nesterov=args.nesterov,lr= self.args.lr)
# 定义损失函数
self.critersion = nn.CrossEntropyLoss().cuda()
# 定义评价指标
self.evaluator = Evaluator2C()
# 学习率衰减函数
self.scheduler = LR_Scheduler(args.lr_scheduler, args.lr, args.epochs, len(self.train_loader))
# 是否使用GPU
if args.cuda:
self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)
patch_replication_callback(self.model)
self.model = self.model.cuda()
# 混合梯度下降
self.scaler = torch.cuda.amp.GradScaler()
# 加载预训练模型
self.best_pred = 0.0
if args.resume is not None:
if not os.path.isfile(args.resume):
raise RuntimeError("=> no checkpoint found at '{}'" .format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
if args.cuda:
self.model.load_state_dict(checkpoint['state_dict'])
else:
self.model.load_state_dict(checkpoint['state_dict'],)
if not args.ft:
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.best_pred = checkpoint['best_pred']
print("=> loaded checkpoint '{}' (epoch {})".format(args.resume, checkpoint['epoch']))
if args.ft:
args.start_epoch = 0
# 请见xy 用户:geedownload
# 或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
def main():
# 创建一个参数解析器
parser = argparse.ArgumentParser(description="WHU建筑数据实验")
# 优化器参数
parser.add_argument('--lr', type=float, default=0.001, metavar='LR',
help='学习率 (默认: auto)')
parser.add_argument('--lr-scheduler', type=str, default='poly',
choices=['poly', 'step', 'cos'],
help='lr调度器模式: (默认: poly)')
parser.add_argument('--momentum', type=float, default=0.9,
metavar='M', help='动量 (默认: 0.9)')
parser.add_argument('--weight-decay', type=float, default=5e-4,
metavar='M', help='权重衰减 (默认: 5e-4)')
parser.add_argument('--nesterov', action='store_true', default=False,
help='是否使用Nesterov (默认: False)')
# 随机种子,GPU,参数保存
parser.add_argument('--no-cuda', action='store_true', default=False,
help='禁用CUDA训练')
parser.add_argument('--gpu-ids', type=str, default='0',
help='使用哪个GPU进行训练,必须是整数列表 (默认=0)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='随机种子 (默认: 1)')
parser.add_argument('--ft', action='store_true', default=False, # False
help='在不同的数据集上进行微调')
# 训练参数配置
parser.add_argument('--epochs', type=int, default=100, metavar='N',
help='训练的epoch数 (默认: auto)')
parser.add_argument('--start_epoch', type=int, default=0,
metavar='N', help='开始epochs (默认:0)')
parser.add_argument('--batch-size', type=int, default=20,
metavar='N', help='训练输入的batch大小 (默认: auto)')
parser.add_argument('--resume', type=str, default=None,
help='如果需要,将模型权重文件的路径放入其中')
parser.add_argument('--expname', type=str, default='WHU_building',
help='设置检查点名称')
parser.add_argument("--input_dir_train", default=r'../../datasets/train/image/', type=str)
parser.add_argument("--label_dir_train", default=r'../../datasets/train/label/', type=str)
parser.add_argument("--input_dir_val", default=r'../../datasets/val/image/', type=str)
parser.add_argument("--label_dir_val", default=r'../../datasets/val/label/', type=str)
# 解析参数
args = parser.parse_args()
# 检查CUDA是否可用
args.cuda = not args.no_cuda and torch.cuda.is_available()
# 如果使用CUDA,解析GPU ID
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
# 设置随机种子
torch.manual_seed(args.seed)
# 创建训练器
trainer = Trainer(args)
# 打印参数
print(args)
# 打印开始和总epoch数
print('Starting Epoch:', trainer.args.start_epoch)
print('Total Epoches:', trainer.args.epochs)
# 遍历每个epoch
for epoch in range(trainer.args.start_epoch, trainer.args.epochs):
# 训练
trainer.training(epoch)
# 验证
trainer.validation(epoch)
# 关闭writer
trainer.writer.close()
if __name__ == "__main__":
main()本代码训练10轮,保存模型一轮,输出与模型保存在run对应的目录下。
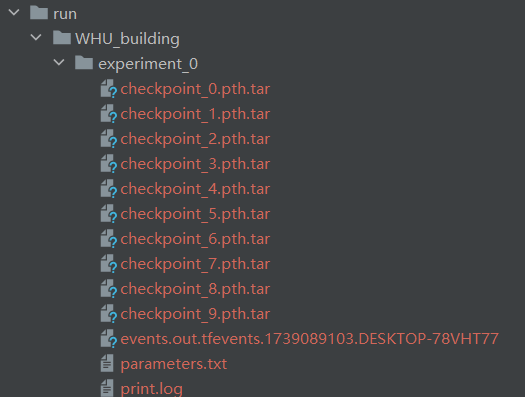
其中print.log中存放了训练过程中的输出。
Using poly LR Scheduler!
Namespace(batch_size=20, cuda=True, epochs=100, expname='WHU_building', ft=False, gpu_ids=[0], input_dir_train='../../datasets/train/image/', input_dir_val='../../datasets/val/image/', label_dir_train='../../datasets/train/label/', label_dir_val='../../datasets/val/label/', lr=0.001, lr_scheduler='poly', momentum=0.9, nesterov=False, no_cuda=False, resume=None, seed=1, start_epoch=0, weight_decay=0.0005)
Starting Epoch: 0
Total Epoches: 100
=>Epoches 0, learning rate = 0.001000, previous best = 0.000000
[Epoch: 0, numImages: 4720, time: 0.51]
Loss: 83.447334
Validation:
[Epoch: 0]
accuracy:0.9617,precision:0.7751, recall:0.8631, f1_score:0.8167
=>Epoches 1, learning rate = 0.000991, previous best = 0.000000
[Epoch: 1, numImages: 4720, time: 0.46]
Loss: 35.857325
Validation:
[Epoch: 1]
accuracy:0.9706,precision:0.8747, recall:0.8603, f1_score:0.8674
=>Epoches 2, learning rate = 0.000982, previous best = 0.000000
[Epoch: 2, numImages: 4720, time: 0.46]
Loss: 29.618076
Validation:
[Epoch: 2]
accuracy:0.9715,precision:0.8493, recall:0.8868, f1_score:0.8676
=>Epoches 3, learning rate = 0.000973, previous best = 0.000000
[Epoch: 3, numImages: 4720, time: 0.46]
Loss: 26.464764
Validation:
[Epoch: 3]
accuracy:0.9736,precision:0.8814, recall:0.8790, f1_score:0.8802
=>Epoches 4, learning rate = 0.000964, previous best = 0.000000
[Epoch: 4, numImages: 4720, time: 0.46]
Loss: 24.401384
Validation:
[Epoch: 4]
accuracy:0.9731,precision:0.9151, recall:0.8516, f1_score:0.8822
=>Epoches 5, learning rate = 0.000955, previous best = 0.000000
[Epoch: 5, numImages: 4720, time: 0.46]
Loss: 23.149246
Validation:
[Epoch: 5]
accuracy:0.9739,precision:0.8446, recall:0.9115, f1_score:0.8768
=>Epoches 6, learning rate = 0.000946, previous best = 0.000000
[Epoch: 6, numImages: 4720, time: 0.46]
Loss: 22.006196
Validation:
[Epoch: 6]
accuracy:0.9754,precision:0.9194, recall:0.8657, f1_score:0.8917
=>Epoches 7, learning rate = 0.000937, previous best = 0.000000
[Epoch: 7, numImages: 4720, time: 0.46]
Loss: 21.275964
Validation:
[Epoch: 7]
accuracy:0.9764,precision:0.9237, recall:0.8696, f1_score:0.8959
=>Epoches 8, learning rate = 0.000928, previous best = 0.000000
[Epoch: 8, numImages: 4720, time: 0.46]
Loss: 20.501293
Validation:
[Epoch: 8]
accuracy:0.9785,precision:0.8993, recall:0.9046, f1_score:0.9020
=>Epoches 9, learning rate = 0.000919, previous best = 0.000000
[Epoch: 9, numImages: 4720, time: 0.46]
Loss: 19.773310
Validation:
[Epoch: 9]
accuracy:0.9729,precision:0.8273, recall:0.9186, f1_score:0.8706
=>Epoches 10, learning rate = 0.000910, previous best = 0.000000
[Epoch: 10, numImages: 4720, time: 0.46]
Loss: 19.785136
Validation:
[Epoch: 10]
accuracy:0.9790,precision:0.8792, recall:0.9263, f1_score:0.90212.6模型测试
由于训练集和验证集都参与了模型的训练,需要使用从未参与过训练与优化的测试集进行精度验证,该精度才能较为真实的代表模型的效果。
我们选择验证精度最优的模型或者训练次数最多的模型进行测试,代码如下
import os
import torch
import numpy as np
from PIL import Image
from models.unet.unet_model import UNet
import cv2
from evaluations.metrics import Evaluator2C
from utils.replicate import patch_replication_callback
# 获取指定路径下指定文件类型的文件名列表
def get_filename(path, filetype):
name = []
final_name = []
for root, dirs, files in os.walk(path):
for i in files:
if filetype in i[-4:]:
name.append(i.replace(filetype, ''))
final_name = [item + filetype for item in name]
return final_name
def main():
# 加载权重文件路径
weights_path = "./run/WHU_building/experiment_0/checkpoint_9.pth.tar"
# 加载测试图像文件夹路径
image_folder = "../../datasets/test/image/"
# 加载测试标签文件夹路径
label_folder = "../../datasets/test/label/"
# 加载预测结果保存文件夹路径
pre_folder = "../../datasets/test/pre/"
# 检查路径是否存在
assert os.path.exists(weights_path), f"weights {weights_path} not found."
assert os.path.exists(image_folder), f"image {image_folder} not found."
assert os.path.exists(label_folder), f"image {label_folder} not found."
assert os.path.exists(pre_folder), f"image {pre_folder} not found."
# 获取文件名列表
filenames = get_filename(image_folder, filetype='tif')
# 获取图像路径列表
images_path = [image_folder + i for i in filenames]
# 获取标签路径列表
labels_path = [label_folder + i for i in filenames]
# 获取预测结果保存路径列表
pre_path = [pre_folder + i for i in filenames]
# 创建模型
model = UNet(n_channels=3, n_classes=2)
# 将模型设置为多GPU模式
model = torch.nn.DataParallel(model, device_ids=[0])
# 将模型复制到所有GPU上
patch_replication_callback(model)
# 将模型移动到GPU上
model = model.cuda()
# 加载权重
checkpoint = torch.load(weights_path)
model.load_state_dict(checkpoint['state_dict'])
# 将模型设置为评估模式
model.eval()
# 创建评估器
evaluator = Evaluator2C()
# 在不计算梯度的情况下进行预测
# 请见xy 用户:geedownload
# 或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
# 计算评估指标
accuracy, precision, recall, f1_score = evaluator.cal()
# 打印评估指标
print("accuracy:{:.4f},precision:{:.4f}, recall:{:.4f}, f1_score:{:.4f}".format(accuracy, precision, recall,f1_score))
if __name__ == '__main__':
main()此处我们使用了迭代次数最多的模型,对测试集进行预测并计算精度,精度指标如下。
accuracy:0.9815,precision:0.9219, recall:0.9125, f1_score:0.9171
预测的结果与真实图像对比如下,pre为预测结果 ,label为标签


结果还是比较好的。
请见xy 用户:geedownload
或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例