文章目录
- 前言
- 一、问题本质:Kafka消费模型与Offset核心作用
- 二、核心原因拆解:从消费端到服务端的全场景分析
-
- (一)消费端Offset提交异常(最常见,占比80%+)
-
- [1. 提交时机错误:先提交Offset,后处理消息](#1. 提交时机错误:先提交Offset,后处理消息)
- [2. 自动提交Offset:提交与业务处理不同步](#2. 自动提交Offset:提交与业务处理不同步)
- [3. 手动提交失败:异常未捕获或重试机制缺失](#3. 手动提交失败:异常未捕获或重试机制缺失)
- [4. 消费超时触发重平衡:Offset未及时提交](#4. 消费超时触发重平衡:Offset未及时提交)
- (二)消费端自身异常(高频场景,占比15%)
-
- [1. 消费者进程崩溃/被终止](#1. 消费者进程崩溃/被终止)
- [2. 消费者主动重启(发布部署场景)](#2. 消费者主动重启(发布部署场景))
- [3. 消费线程异常(未捕获异常导致线程崩溃)](#3. 消费线程异常(未捕获异常导致线程崩溃))
- (三)服务端/中间件机制触发(占比5%,易被忽略)
-
- [1. 分区重平衡(Rebalance)触发重复消费](#1. 分区重平衡(Rebalance)触发重复消费)
- [2. 生产者重试机制导致消息重复发送](#2. 生产者重试机制导致消息重复发送)
- [3. Offset重置导致从头消费](#3. Offset重置导致从头消费)
- [4. 下游系统异常导致的业务重复](#4. 下游系统异常导致的业务重复)
- 三、兜底方案:消费端幂等处理
-
- (一)基于数据库主键/唯一索引(推荐,最简单)
- [(二)基于消息唯一ID(Message ID)](#(二)基于消息唯一ID(Message ID))
- (三)基于业务状态机(适用于有状态业务)
- 四、落地建议
-
- (一)配置优化(核心参数)
-
- [1. 消费者配置](#1. 消费者配置)
- [2. 生产者配置](#2. 生产者配置)
- (二)代码层面优化
- (三)运维层面优化
- 五、总结
前言
在分布式消息中间件领域,Kafka凭借高吞吐、低延迟、高可靠性的特性,成为企业级架构中的核心组件。但在实际生产环境中,重复消费问题却频繁困扰开发者------消息被多次消费不仅会导致业务数据不一致(如重复入库、重复计费),还可能引发下游系统过载。本文将从"问题本质"出发,逐层拆解重复消费的核心原因,提供可落地的解决方案,并结合生产实践给出建议,帮你彻底攻克这一难题。
一、问题本质:Kafka消费模型与Offset核心作用
要理解重复消费,首先需明确Kafka的消费核心机制------Offset(偏移量)。Kafka为每个Topic的每个分区维护了一个Offset,用于记录消费者当前消费到的位置。正常消费流程如下:
-
消费者从Broker拉取(poll)一批消息;
-
消费者执行业务逻辑,确认消息处理成功;
-
消费者向Broker提交Offset,告知"该位置之前的消息已消费完成";
-
下次消费时,从已提交的Offset后续位置拉取消息。
由此可见,重复消费的本质的是"消息处理状态"与"Offset提交状态"不一致------要么消息处理成功但Offset未提交,要么Offset提交成功但消息处理失败,导致消费者重启/重连后,从旧Offset重新拉取消息。所有重复消费场景,都可归为三大类:消费端Offset提交异常、消费端自身异常、服务端/中间件机制触发。
二、核心原因拆解:从消费端到服务端的全场景分析
(一)消费端Offset提交异常(最常见,占比80%+)
Offset提交是消费流程的核心环节,任何提交逻辑的异常,都会直接导致重复消费。以下是4种高频场景及底层原理。
1. 提交时机错误:先提交Offset,后处理消息
这是新手最易踩的坑,本质是消费逻辑顺序倒置,流程如下:
-
消费者拉取消息后,立即调用commitSync/commitAsync提交Offset;
-
执行业务逻辑(如数据库入库、调用第三方接口);
-
若业务处理中发生异常(如数据库宕机、接口超时、代码报错),消息实际未处理成功,但Offset已提交;
-
消费者重启或分区重平衡后,从已提交的 Offset 继续消费,导致未处理成功的消息被永久跳过。
错误代码示例:
java
// 错误逻辑:先提交,后处理
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
// 先提交Offset
consumer.commitSync();
// 后处理消息,异常则消息未处理但Offset已提交
handleMessage(records);
}解决方案:严格遵循"先处理消息,确认成功后再提交Offset"的原则,将提交操作放在业务处理成功后的逻辑中。
正确代码示例:
java
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
try {
// 先处理消息,确保无异常
handleMessage(records);
// 处理成功后,再提交Offset
consumer.commitSync();
} catch (Exception e) {
log.error("消息处理失败,不提交Offset", e);
// 不提交Offset,下次poll会重复拉取该批次消息
}
}2. 自动提交Offset:提交与业务处理不同步
下面是Kafka自动提交的内部机制时序图:
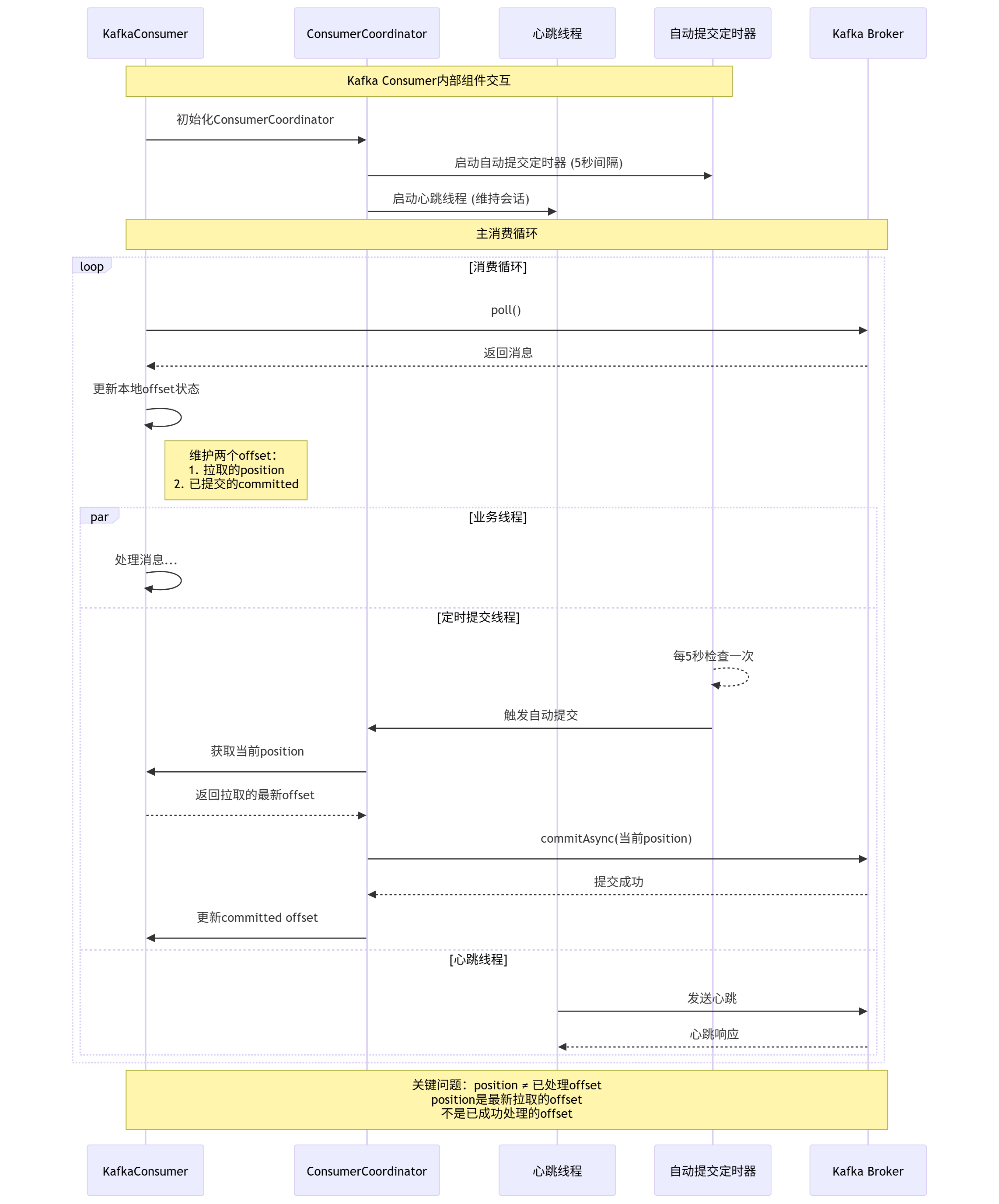
Kafka默认开启自动提交(enable.auto.commit=true),自动提交的触发机制是:每间隔 auto.commit.interval.ms(默认5秒),提交一次最近一次poll的Offset。这种方式存在两个致命问题:
-
问题1:消息未处理完,Offset自动提交失败( 崩溃发生在提交间隔内 ) :消费者拉取消息后,还在处理中,还未自动提交。若此时消费者崩溃/重启,未处理完的消息会被重复拉取。
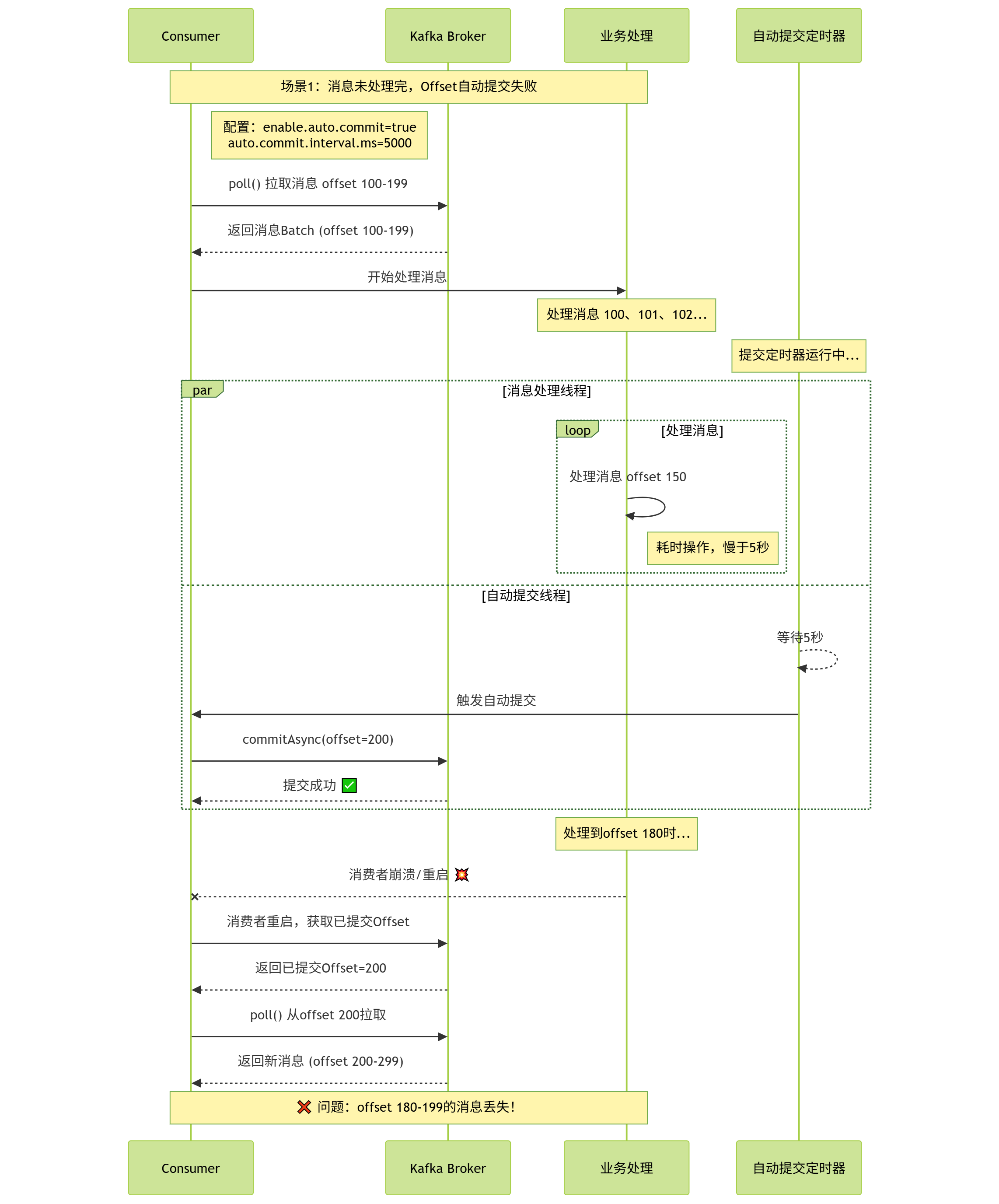
-
问题2:批量消息部分失败,Offset整体提交 :自动提交是批量提交,若一批消息中部分处理失败、部分成功,Offset仍会提交,导致失败的消息丢失。
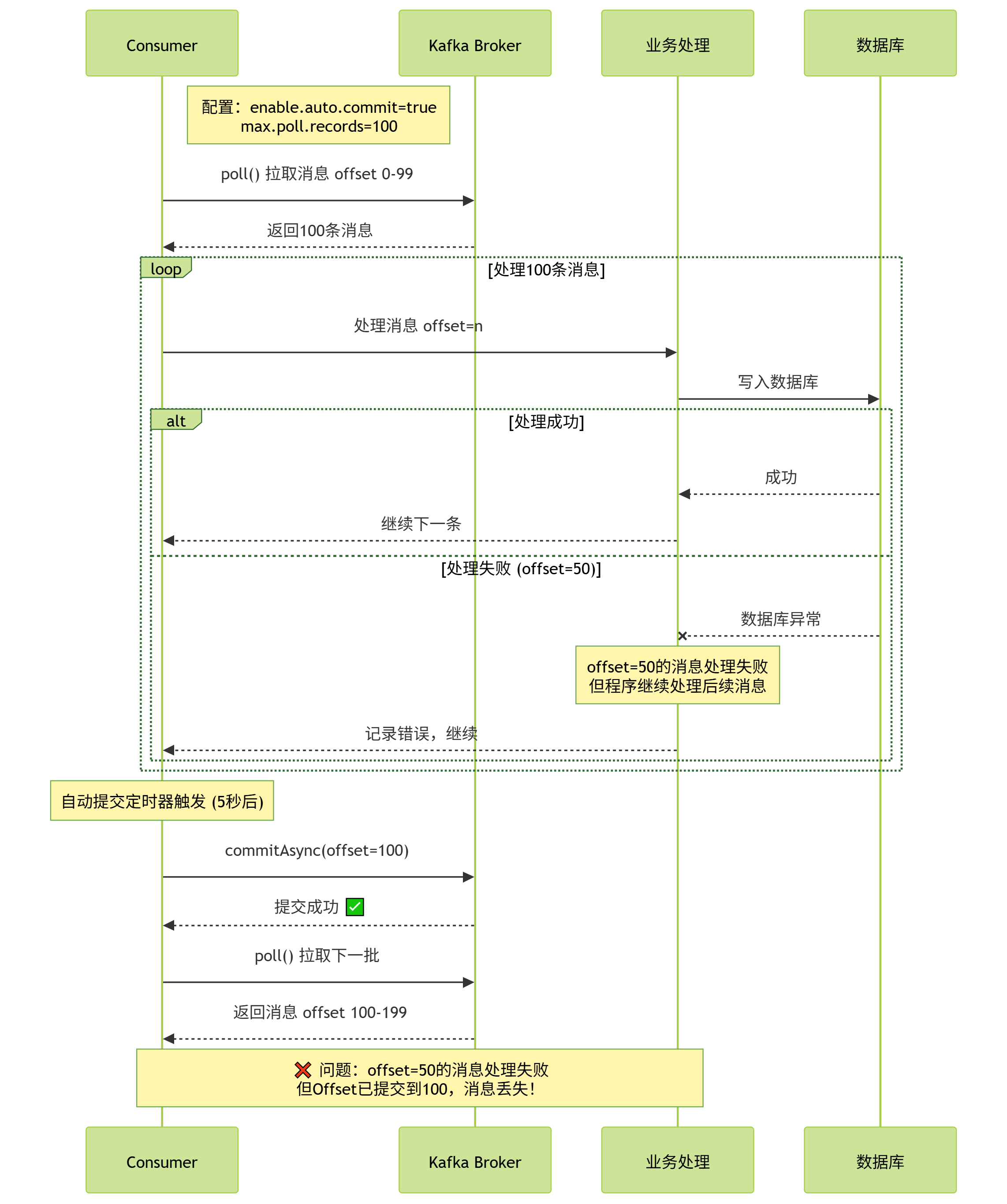
典型场景 :auto.commit.interval.ms=5s,消费者拉取100条消息,处理到第50条时,5秒时间到,Offset被自动提交(提交到100)。此时消费者突然崩溃,重启后从Offset=100开始消费,导致第51-100条未处理的消息丢失。
解决方案:生产环境强制关闭自动提交,改为手动提交。这是解决此类问题的根本方案。
properties
# 消费者核心配置
enable.auto.commit=false # 关闭自动提交若因业务场景限制必须使用自动提交,需配合幂等处理(后文详细说明),兜底重复消费带来的业务影响。
3. 手动提交失败:异常未捕获或重试机制缺失
即使改为手动提交,也可能因网络、Broker状态等问题导致提交失败,常见原因包括:
-
网络抖动:提交Offset的请求超时,Broker未收到提交请求;
-
Broker异常:Leader节点挂了,Offset提交请求被拒绝或无响应;
-
代码缺陷:未捕获提交异常,误以为提交成功,实际Offset未更新。
提交失败的直接后果是:消费者认为Offset已提交,下次从新位置消费,但Broker记录的仍是旧Offset,导致旧Offset到新位置的消息被重复拉取。
解决方案:手动提交必须捕获异常,并实现合理的重试机制(避免死循环),同时区分"提交异常"和"业务处理异常"。
java
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
if (records.isEmpty()) continue;
try {
handleMessage(records);
// 捕获提交异常,进行重试
retryCommit(consumer, records);
} catch (Exception e) {
log.error("消息处理失败,不提交Offset", e);
}
}
// 重试提交方法
private void retryCommit(KafkaConsumer<String, String> consumer, ConsumerRecords<String, String> records) {
int retryCount = 0;
int maxRetry = 3;
while (retryCount < maxRetry) {
try {
consumer.commitSync();
log.info("Offset提交成功");
break;
} catch (CommitFailedException e) {
retryCount++;
log.error("Offset提交失败,第{}次重试", retryCount, e);
if (retryCount == maxRetry) {
// 重试失败,记录日志并告警,避免死循环
log.error("Offset提交重试失败,放弃重试", e);
throw e;
}
// 重试间隔,避免频繁重试
TimeUnit.MILLISECONDS.sleep(100 * retryCount);
}
}
}4. 消费超时触发重平衡:Offset未及时提交
Kafka消费者存在两大核心机制:心跳机制与消费超时机制,对应三个关键配置参数,直接影响Offset提交和重平衡触发:
-
session.timeout.ms(默认10秒):消费者与Coordinator(消费组协调者)的心跳超时时间。若超时未发送心跳,Coordinator认为消费者已挂,触发分区重平衡。 -
heartbeat.interval.ms(默认3秒):消费者向Coordinator发送心跳的间隔时间,建议设置为session.timeout.ms的1/3,确保Coordinator及时感知消费者存活。 -
max.poll.interval.ms(默认5分钟):消费者两次poll操作的最大间隔时间。若超过该时间未调用poll,Coordinator认为消费者消费能力不足,将其踢出消费组,触发重平衡。
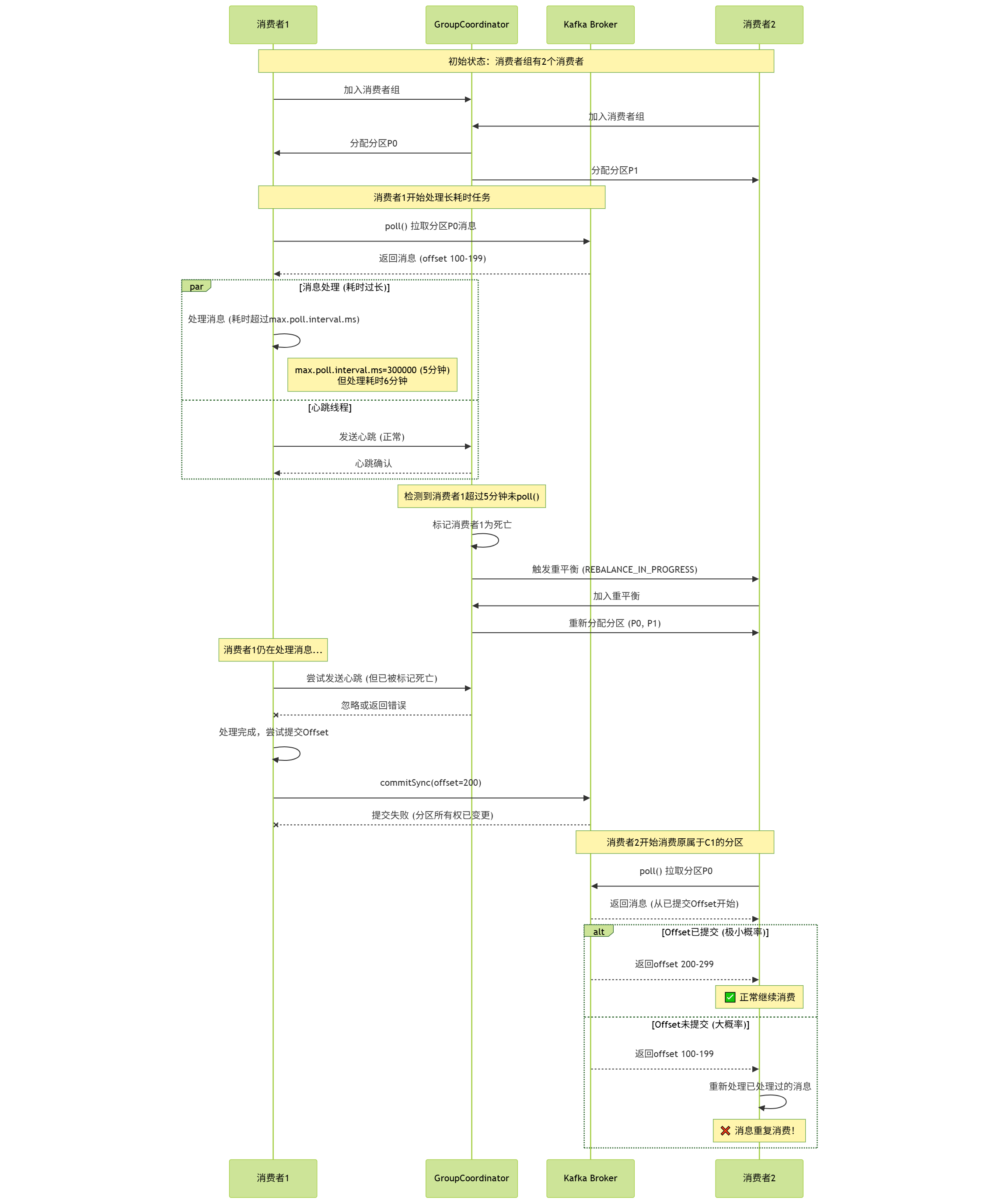
异常流程:若业务处理耗时过长(如批量处理10万条数据,耗时超过5分钟),会触发max.poll.interval.ms超时:
-
当前消费者被踢出消费组,其负责的分区被分配给消费组内其他消费者;
-
当前消费者仍在处理消息,未提交Offset;
-
新消费者拉取该分区时,从Broker记录的旧Offset开始消费,导致重复消费。
异常流程时序图:
解决方案:通过配置优化,减少超时触发的重平衡,同时控制单次消费耗时。
properties
# 消费者配置优化
max.poll.interval.ms=1800000 # 30分钟,根据业务最大处理耗时调整
max.poll.records=500 # 减少单次poll拉取的消息数,默认500,避免处理耗时过长
heartbeat.interval.ms=1000 # 1秒发送一次心跳,加快存活感知
session.timeout.ms=30000 # 30秒,与heartbeat.interval.ms匹配补充:若业务处理确实无法缩短耗时(如大数据量批处理),可拆分消费逻辑,采用"分片处理+异步回调"的方式,避免阻塞poll操作。
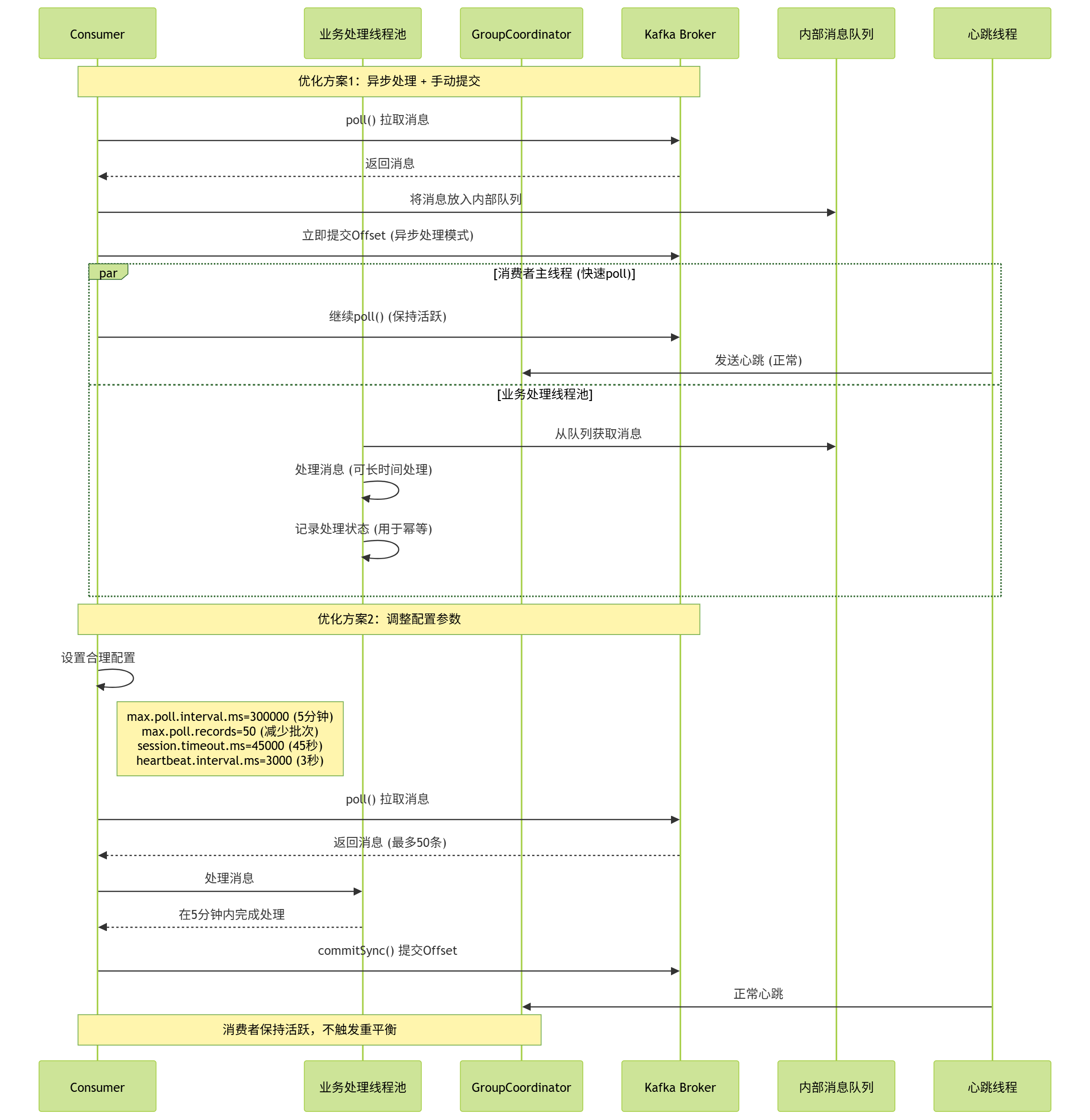
(二)消费端自身异常(高频场景,占比15%)
消费端自身异常导致的重复消费,本质仍是Offset未提交或提交未生效,常见于进程、服务器、线程层面的异常。
1. 消费者进程崩溃/被终止
典型场景:
-
消费进程因OOM、代码Bug(如死循环、空指针)导致崩溃;
-
运维误杀进程、服务器宕机、容器(Docker/K8s)重启;
-
资源限制导致进程被系统Kill(如CPU、内存使用率过高)。
核心原因:消息拉取后,处于"处理中"状态或"处理完成但未提交Offset"状态,进程突然终止,导致Offset未同步到Broker。重启后从旧Offset拉取,重复消费。
解决方案:
-
核心优化:坚持"先处理后提交"原则,配合幂等处理兜底;
-
进程监控:使用K8s的Liveness/Readiness探针、Prometheus+Grafana监控进程状态,快速发现崩溃并告警;
-
资源保障:为消费进程分配足够的CPU、内存资源,避免被系统Kill。
2. 消费者主动重启(发布部署场景)
日常发布部署时,消费进程会被主动重启,若重启流程不规范,极易导致重复消费:
异常流程:重启指令下发 → 消费进程被强制终止 → 此时正处理一批消息,已处理完成但未提交Offset → 重启后从旧Offset拉取,导致该批次消息重复消费。
解决方案:实现"优雅停机",确保重启前处理完当前批次消息并提交Offset。
java
public class KafkaConsumerService {
private KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
public void start() {
// 注册关闭钩子,实现优雅停机
Runtime.getRuntime().addShutdownHook(new Thread(this::shutdown));
consumer.subscribe(Collections.singletonList("test-topic"));
while (isRunning) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
try {
handleMessage(records);
consumer.commitSync();
} catch (Exception e) {
log.error("消息处理失败", e);
}
}
}
private void shutdown() {
log.info("开始优雅停机,停止拉取消息");
isRunning = false;
try {
// 唤醒poll阻塞,避免线程卡死
consumer.wakeup();
// 等待当前批次消息处理完成
TimeUnit.SECONDS.sleep(5);
// 最后一次提交Offset
consumer.commitSync();
log.info("Offset提交完成,关闭消费者");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
consumer.close();
}
}
}补充:生产环境建议采用灰度发布,分批重启消费者实例,避免全量重启导致大量分区重平衡和重复消费。
3. 消费线程异常(未捕获异常导致线程崩溃)
若消费逻辑运行在独立线程中,且未捕获所有异常(尤其是RuntimeException),会导致线程崩溃,进而引发重复消费:
异常流程:线程处理消息时抛空指针异常 → 未捕获异常,线程崩溃 → 当前批次消息未处理完,Offset未提交 → 线程池重新创建消费线程 → 新线程从旧Offset拉取,重复消费。
解决方案:
-
消费逻辑统一捕获所有异常(包括Throwable),不允许线程崩溃;
-
异常消息记录详细日志(含消息内容、Offset),并触发告警,便于排查;
-
使用线程池管理消费线程,设置核心线程数和最大线程数,避免线程耗尽。
java
// 线程池消费示例
ExecutorService consumerExecutor = Executors.newFixedThreadPool(5);
for (int i = 0; i < 5; i++) {
consumerExecutor.submit(() -> {
while (isRunning) {
try {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
handleMessage(records);
consumer.commitSync();
} catch (Throwable t) { // 捕获所有异常,避免线程崩溃
log.error("消费线程异常,继续运行", t);
}
}
});
}(三)服务端/中间件机制触发(占比5%,易被忽略)
这类原因不依赖消费端逻辑,是Kafka服务端或上下游中间件的机制导致消息重发,进而引发重复消费。
1. 分区重平衡(Rebalance)触发重复消费
分区重平衡是消费组内分区重新分配的机制,目的是确保消费组内的消费者公平分配分区。但重平衡过程中,极易导致重复消费,触发重平衡的场景包括:
-
消费组内新增/减少消费者(如扩容、缩容);
-
消费者心跳超时、poll超时(前文已提及);
-
Topic分区数量变化(手动增加分区);
-
消费组订阅的Topic发生变化。
异常流程:
-
消费者A负责Topic的分区0,拉取消息后正在处理,未提交Offset;
-
因心跳超时,Coordinator触发重平衡,分区0被分配给消费者B;
-
消费者B拉取分区0时,从Broker记录的旧Offset开始消费,导致消费者A未处理完的消息被重复消费。
解决方案:优化重平衡机制,减少重平衡触发频率,同时在重平衡时提交Offset。
-
优化配置:前文提到的心跳、poll超时参数优化,减少不必要的重平衡;
-
重平衡监听器:监听重平衡事件,在分区被释放前提交Offset,减少重复消费范围。
java
consumer.subscribe(Collections.singletonList("test-topic"), new ConsumerRebalanceListener() {
// 分区被分配给当前消费者前触发
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
log.info("分区分配成功,分区列表:{}", partitions);
// 可选:重置Offset到最近提交位置
consumer.seekToCommitted(partitions);
}
// 分区被从当前消费者收回前触发
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
log.info("分区即将被收回,提交当前Offset:{}", partitions);
// 释放分区前,提交一次Offset
consumer.commitSync();
}
});2. 生产者重试机制导致消息重复发送
重复消费不一定是消费端问题,也可能是生产者重复发送消息,导致Broker存储多条相同消息,消费端自然会重复消费。
异常流程:
-
生产者发送消息到Broker,Broker已接收并写入磁盘,但因网络抖动,生产者未收到Broker的ACK响应;
-
生产者认为消息发送失败,触发重试(默认重试次数为2147483647,无限重试);
-
Broker再次接收该消息,写入磁盘,导致Topic中存在多条相同消息;
-
消费端消费时,会多次消费到相同消息。
解决方案:生产者开启幂等性和事务,避免重复发送。
-
开启幂等性:通过
enable.idempotence=true,确保生产者向同一分区发送的消息仅被写入一次。幂等性依赖acks=all(所有副本确认)和生产者ID(PID),Broker会通过PID和消息序列号去重。 -
开启事务:适用于多分区、多Topic发送场景,确保消息要么全部发送成功,要么全部失败,避免部分重复。
properties
# 生产者核心配置
enable.idempotence=true # 开启幂等性
acks=all # 幂等性依赖acks=all
retries=3 # 合理设置重试次数,避免无限重试
transactional.id=producer-transaction-1 # 事务ID,确保事务唯一性3. Offset重置导致从头消费
消费者Offset被重置为最早位置(earliest),会导致全量消息重复消费,触发场景包括:
-
新消费组首次消费Topic,且
auto.offset.reset=earliest(默认值为latest,从最新消息开始消费); -
消费组的Offset过期被删除:Kafka默认保存Offset的时间为7天(
retention.ms=604800000),若消费者长时间未消费,Offset被删除,触发重置; -
手动执行Offset重置命令(如通过kafka-consumer-groups.sh脚本)。
解决方案:
-
新消费组配置
auto.offset.reset=latest,避免从头消费; -
合理设置Offset过期时间,根据业务消费频率调整
retention.ms; -
禁止手动误操作Offset重置,操作前需备份Offset。
properties
# 消费者配置
auto.offset.reset=latest # 无Offset时,从最新消息开始消费
# 调整Topic的Offset过期时间为30天(通过脚本)
kafka-configs.sh --zookeeper localhost:2181 --alter --entity-type topics --entity-name test-topic --add-config retention.ms=25920000004. 下游系统异常导致的业务重复
这类场景容易被误认为是Kafka重复消费,但本质是业务层面的问题:消息仅被消费一次,但因下游系统异常,导致业务数据重复。
典型场景:
-
消费端处理消息成功,Offset已提交,但调用下游接口(如支付接口)时,接口执行成功但返回超时,消费端误以为失败,触发重试(或下游系统重试),导致业务重复;
-
业务逻辑未做幂等,即使只消费一次消息,也会因代码逻辑问题产生重复数据(如重复入库)。
解决方案:优化业务逻辑,确保下游接口幂等,同时消费端做好业务幂等兜底。
三、兜底方案:消费端幂等处理
无论如何优化Offset提交、减少重平衡,都无法100%避免重复消费------网络抖动、硬件故障、Broker异常等不可抗因素始终存在。因此,消费端必须做幂等处理,这是解决重复消费的终极方案,确保重复消费不影响业务结果。
幂等性定义:同一操作执行多次,结果与执行一次一致。以下是3种常用的幂等实现方案,按优先级排序。
(一)基于数据库主键/唯一索引(推荐,最简单)
原理:利用数据库的唯一约束,确保重复消息对应的业务数据无法重复插入/更新。适用于需要入库的业务场景(如订单、日志)。
实现步骤:
-
为业务表添加唯一索引(如订单号、消息ID);
-
消费消息时,执行插入/更新操作,重复消息会触发唯一约束冲突,直接忽略。
sql
-- 1. 为订单表添加订单号唯一索引
ALTER TABLE t_order ADD UNIQUE INDEX uk_order_no (order_no);
-- 2. 入库SQL(重复则更新或忽略)
-- 方案1:重复则更新
INSERT INTO t_order (order_no, amount, status)
VALUES ('ORDER_001', 100, 0)
ON DUPLICATE KEY UPDATE amount=VALUES(amount), status=VALUES(status);
-- 方案2:重复则忽略
INSERT IGNORE INTO t_order (order_no, amount, status)
VALUES ('ORDER_001', 100, 0);优点:实现简单,无需额外代码,依赖数据库原生能力;缺点:仅适用于数据库存储的业务场景。
(二)基于消息唯一ID(Message ID)
原理:生产者发送消息时,携带全局唯一的消息ID(如UUID、雪花算法ID);消费端维护一个"已处理消息ID"集合,消费前先校验该ID是否已处理,未处理则消费,处理后记录ID。适用于无数据库存储的业务场景(如缓存更新、接口调用)。
实现步骤:
-
生产者发送消息时,在消息头或消息体中添加唯一ID;
-
消费端接收消息后,提取唯一ID;
-
查询缓存/数据库,判断该ID是否已处理:
-
已处理:直接忽略消息;
-
未处理:执行业务逻辑,处理成功后记录该ID(存入缓存,设置过期时间;或存入数据库)。
-
java
// 生产者:添加唯一消息ID
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key", "message");
// 雪花算法生成唯一ID
String msgId = SnowflakeIdGenerator.generateId();
record.headers().add("msgId", msgId.getBytes());
producer.send(record);
// 消费端:校验消息ID是否已处理
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
// 提取消息ID
String msgId = new String(record.headers().lastHeader("msgId").value());
// 从Redis查询是否已处理
Boolean isProcessed = redisTemplate.opsForValue().get(msgId) != null;
if (isProcessed) {
log.info("消息已处理,忽略重复消息:{}", msgId);
continue;
}
// 未处理,执行业务逻辑
try {
handleMessage(record);
// 处理成功,记录到Redis,设置过期时间(与Offset过期时间一致)
redisTemplate.opsForValue().set(msgId, "processed", 30, TimeUnit.DAYS);
} catch (Exception e) {
log.error("消息处理失败", e);
}
}
consumer.commitSync();
}优点:通用性强,不依赖业务字段;缺点:需维护额外的缓存/数据库,增加系统复杂度。
(三)基于业务状态机(适用于有状态业务)
原理:业务数据存在明确的状态流转(如订单:待支付→支付中→支付成功→已完成),重复消费时,通过判断当前业务状态,决定是否执行后续逻辑。适用于有状态的业务场景(如订单、流程审批)。
实现示例:
java
// 订单状态枚举
public enum OrderStatus {
PENDING_PAY(0, "待支付"),
PAYING(1, "支付中"),
PAY_SUCCESS(2, "支付成功"),
PAY_FAILED(3, "支付失败");
private int code;
private String desc;
// 构造方法、getter省略
}
// 消费端处理逻辑
private void handleOrderMessage(ConsumerRecord<String, String> record) {
Order order = JSON.parseObject(record.value(), Order.class);
// 判断订单当前状态
if (order.getStatus() >= OrderStatus.PAY_SUCCESS.getCode()) {
log.info("订单已完成支付,忽略重复消息:{}", order.getOrderNo());
return;
}
// 未支付,执行支付逻辑
payService.processPayment(order);
}优点:贴合业务逻辑,无需额外存储;缺点:仅适用于有明确状态流转的业务。
四、落地建议
结合前文分析,总结一套生产环境可直接落地的优化方案,从配置、代码、运维三个层面杜绝重复消费。
(一)配置优化(核心参数)
1. 消费者配置
properties
# 基础配置
enable.auto.commit=false # 关闭自动提交,手动提交
auto.offset.reset=latest # 无Offset时从最新消息开始消费
# 超时与心跳配置
max.poll.interval.ms=1800000 # 30分钟,根据业务耗时调整
max.poll.records=500 # 单次拉取消息数,避免处理耗时过长
session.timeout.ms=30000 # 30秒,与心跳间隔匹配
heartbeat.interval.ms=1000 # 1秒发送一次心跳
# 其他优化
fetch.min.bytes=1024 # 拉取最小字节数,减少空轮询
fetch.max.wait.ms=500 # 拉取最大等待时间,平衡延迟与吞吐2. 生产者配置
properties
# 可靠性配置
acks=all # 所有副本确认,确保消息不丢失
enable.idempotence=true # 开启幂等性,避免重复发送
retries=3 # 合理重试次数,避免无限重试
# 事务配置(可选,多分区/多Topic场景)
transactional.id=producer-transaction-id # 唯一事务ID
transaction.timeout.ms=60000 # 事务超时时间
# 性能优化
batch.size=16384 # 批量发送大小,16KB
linger.ms=5 # 等待5ms批量发送,平衡吞吐与延迟(二)代码层面优化
-
严格遵循"先处理后提交"原则,手动提交Offset并捕获异常;
-
实现优雅停机,重启前处理完当前批次消息并提交Offset;
-
消费线程统一捕获所有异常,避免线程崩溃;
-
生产者开启幂等性/事务,避免重复发送;
-
消费端必做幂等处理,根据业务场景选择合适的幂等方案。
(三)运维层面优化
-
监控消费组状态:监控Offset滞后量(Consumer Lag)、重平衡次数、消费异常日志,及时发现问题;
-
合理设置Offset过期时间,避免Offset被删除;
-
灰度发布消费者,分批重启,减少重平衡影响;
-
禁止手动误操作Offset重置,操作前备份Offset;
-
保障网络稳定性,减少因网络抖动导致的提交失败、生产者重试。
五、总结
Kafka重复消费的核心根源是"Offset提交与消息处理状态不一致",所有场景均可追溯到消费端Offset提交异常、消费端自身异常、服务端/中间件机制触发三类原因。解决重复消费需从"预防"和"兜底"两方面入手:
-
预防:通过配置优化、代码规范(先处理后提交、优雅停机)、生产者幂等性,减少重复消费的触发;
-
兜底:消费端必须实现幂等处理,这是应对不可抗因素的终极方案。
在生产实践中,需结合业务场景选择合适的解决方案,同时通过完善的监控告警体系,提前发现并排查问题,确保Kafka消费的可靠性和业务数据的一致性。