实验2:函数调用栈帧机制(重点难点)
函数调用的核心是"栈帧的创建与销毁",栈帧是函数运行的独立内存空间,用于存储局部变量、参数、返回地址等。本实验通过多参数函数调用,拆解栈帧结构与参数传递规则。
bash
#include <stdio.h>
// 多参数函数:计算a + b * c - d
int calc(int a, int b, int c, int d) {
int temp = b * c; // 局部变量
int result = a + temp - d;
return result;
}
int main() {
int x = 5, y = 3, z = 4, w = 6;
int res = calc(x, y, z, w);
printf("calc(%d, %d, %d, %d) = %d\n", x, y, z, w, res);
return 0;
}
===================
0:000> uf main
basic_functions_stack!main [C:\Users\wanni\Desktop\Asm64\basic_functions_stack.c @ 10]:
10 00007ff7`8a8972a0 4883ec38 sub rsp,38h
13 00007ff7`8a8972a4 c74424280b000000 mov dword ptr [rsp+28h],0Bh
13 00007ff7`8a8972ac 488d0d6ddc0700 lea rcx,[basic_functions_stack!`string' (00007ff7`8a914f20)]
13 00007ff7`8a8972b3 ba05000000 mov edx,5
13 00007ff7`8a8972b8 c744242006000000 mov dword ptr [rsp+20h],6
13 00007ff7`8a8972c0 41b904000000 mov r9d,4
13 00007ff7`8a8972c6 41b803000000 mov r8d,3
13 00007ff7`8a8972cc e865b7ffff call basic_functions_stack!ILT+6705(printf) (00007ff7`8a892a36)
14 00007ff7`8a8972d1 33c0 xor eax,eax
15 00007ff7`8a8972d3 4883c438 add rsp,38h
15 00007ff7`8a8972d7 c3 ret
bash
一、什么是栈帧(Stack Frame)?
栈帧是每个函数在被调用时,在栈上分配的一块私有内存区域,用于:
存放 函数参数(部分或全部)
存放 局部变量
保存 返回地址(caller 的下一条指令地址)
保存 被调用者需保护的寄存器(callee-saved registers)
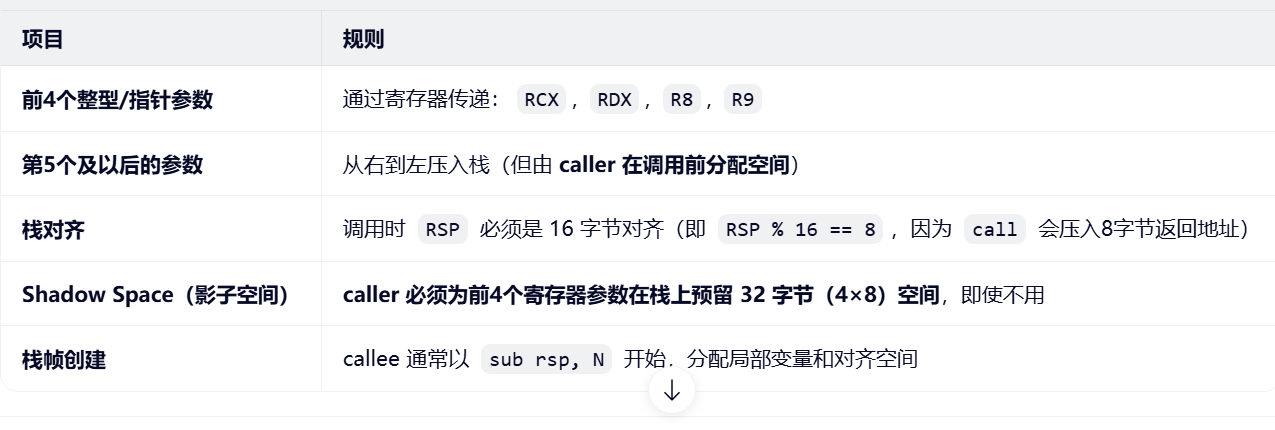
栈帧由 调用者(caller) 和 被调用者(callee) 共同协作建立和清理。二、x64 调用约定的关键规则(Windows)
在 Windows x64 平台上,微软采用如下调用约定:
bash
三、分析你的 main 函数反汇编
asm
basic_functions_stack!main [C:\Users\wanni\Desktop\Asm64\basic_functions_stack.c @ 10]:
10 00007ff7`8a8972a0 4883ec38 sub rsp,38h ; 分配 0x38 = 56 字节栈空间
13 00007ff7`8a8972a4 c74424280b000000 mov dword ptr [rsp+28h],0Bh ; 第5个参数?实际是局部变量或额外参数
13 00007ff7`8a8972ac 488d0d6ddc0700 lea rcx,[string] ; 第1个参数:字符串地址 → RCX
13 00007ff7`8a8972b3 ba05000000 mov edx,5 ; 第2个参数:5 → EDX (RDX)
13 00007ff7`8a8972b8 c744242006000000 mov dword ptr [rsp+20h],6 ; 放到 rsp+20h
13 00007ff7`8a8972c0 41b904000000 mov r9d,4 ; 第4个参数 → R9D
13 00007ff7`8a8972c6 41b803000000 mov r8d,3 ; 第3个参数 → R8D
13 00007ff7`8a8972cc e865b7ffff call printf ; 调用 printf
14 00007ff7`8a8972d1 33c0 xor eax,eax ; return 0;
15 00007ff7`8a8972d3 4883c438 add rsp,38h ; 恢复栈指针(销毁栈帧)
15 00007ff7`8a8972d7 c3 ret ; 返回
对应的 C 代码(推测):
int main() {
printf("...", 3, 4, 5, 6, 11); // 共6个参数?
return 0;
}
注意:printf 是变参函数,其参数传递仍遵循 x64 规则。
四、栈帧结构详解(以 main 为例)
执行 sub rsp, 38h 后,栈布局如下(从高地址 → 低地址):
High Address
│
├── [RSP + 20h] ← Shadow Space for R9 (d = 6)
├── [RSP + 18h] ← Shadow Space for R8 (c = 4)
├── [RSP + 10h] ← Shadow Space for RDX (b = 3)
├── [RSP + 08h] ← Shadow Space for RCX (a = 5)
├── [RSP + 00h] ← Return Address (由 CALL 自动压入)
│
├── [RSP - 08h] ← 局部变量 temp(编译器分配)
├── [RSP - 10h] ← padding / 其他局部
│
Low Address ← RSP(当前栈顶)
注意:Shadow Space 虽由 caller 分配,但 callee 可自由使用(例如 spill 寄存器值)。
============================
RSP + 0x38 → caller 的栈帧(返回地址等)
RSP + 0x30 → Shadow Space for R9 (第4个参数影子区)
RSP + 0x28 → Shadow Space for R8 + 可能存放第5/6个参数(如 0xB = 11)
RSP + 0x20 → Shadow Space for RDX → 这里存了 6
RSP + 0x18 → Shadow Space for RCX
RSP + 0x10 → 局部变量 / 对齐填充
RSP + 0x08 → ...
RSP + 0x00 → 当前栈顶(16字节对齐)
Shadow Space(0x00 ~ 0x1F,共32字节):必须由 caller(即 main)分配,供 callee(printf)使用。
额外参数(第5、6个):由于 x64 只用寄存器传前4个,第5个开始放栈上。这里:
[rsp+20h] = 6 → 第5个参数
[rsp+28h] = 0Bh (11) → 第6个参数
所以 printf 实际收到:
RCX = 字符串地址
RDX = 5
R8 = 3
R9 = 4
[rsp+20h] = 6
[rsp+28h] = 11
注意:参数顺序在 C 中是从左到右,但第5+个参数在栈上是 从右到左压入,不过由于是 caller 直接写内存,这里直接按偏移赋值。
结合 Intel 手册解释函数调用机制
✅ 1. CALL 指令的行为(Intel SDM Vol. 2A, Section 3.2)
Operation (64-bit mode, near call):
text
RSP ← RSP − 8
Memory[RSP] ← RIP (address of next instruction after CALL)
RIP ← target address (calc)
在 main 中执行 call calc 时:
CPU 自动将 返回地址(即 printf 前那条指令的地址)压入栈顶;
RSP 减 8;
程序跳转到 calc 入口。
👉 这就是栈帧中"返回地址"字段的来源------由硬件自动完成,无需软件干预。
✅ 2. RET 指令的行为(Intel SDM Vol. 2A)
Operation:
text
RIP ← Memory[RSP]
RSP ← RSP + 8
在 calc 结尾执行 ret:
从当前 RSP 处读取返回地址;
RSP 加 8,恢复到 call 之前的值;
控制流跳回 main。
👉 这完成了栈帧的"逻辑销毁"------返回地址被消费,控制权交还。
✅ 3. 栈指针(RSP)的操作与栈帧分配
calc 开头:sub rsp, 18h
分配 24 字节栈空间,用于:
局部变量 temp(4 字节)
可能的 padding(为 16 字节对齐)
callee 保存寄存器空间(本例未用)
结尾:add rsp, 18h
手动释放栈帧(x64 中 callee 负责清理自己的局部空间)
🔔 注意:CALL/RET 只管理 返回地址,局部变量空间必须由软件显式分配/释放。
这体现了:栈帧 = 硬件管理的返回地址 + 软件管理的局部存储
✅ 4. 栈对齐要求(Intel SDM Vol. 1, Section 3.4.1 & 14.4)
"The stack pointer should be aligned on a 16-byte boundary prior to calling a function."
在 main 调用 calc 前:
假设进入 main 时 RSP % 16 == 8(因 CRT 启动代码已对齐);
sub rsp, 28h(40 字节)→ 40 % 16 = 8,所以 RSP 变为 (8 - 8) % 16 = 0?
实际需考虑 CALL 压栈的影响。
更准确地说:
调用者(main)必须确保:在执行 call 指令前,RSP % 16 == 8
因为 call 会压入 8 字节,使被调用者入口处 RSP % 16 == 0
这样 calc 内部才能安全使用 movaps、pxor 等要求 16 字节对齐的 SIMD 指令(即使本例未用)
⚠️ 若违反对齐,某些 SSE 指令会触发 #GP(General Protection Fault)
✅ 5. 控制流转移机制
call calc:改变控制流,跳转到新函数
ret:恢复控制流,回到调用点
整个过程通过 栈上的返回地址链 实现嵌套调用(如 main → calc → printf)
Intel 手册强调:这种机制支持任意深度的函数嵌套和递归,因为每次 call 都压入独立返回地址。
五、栈帧的"创建"与"销毁"
创建:
sub rsp, 38h:分配栈空间(含 shadow space + 局部变量 + 对齐)
初始化参数(寄存器 + 栈上)
销毁:
add rsp, 38h:释放栈空间(恢复 RSP)
ret:弹出返回地址,跳回调用者(此处是 CRT 启动代码)
这体现了"谁分配,谁释放"原则:main 自己分配的栈空间,自己回收。
六、实验意义总结
本实验通过一个多参数 printf 调用,清晰展示了:
x64 参数传递机制:前4个用寄存器,后续用栈;
Shadow Space 的强制存在:即使不用,也必须预留;
栈帧的生命周期:函数入口分配,出口释放;
栈对齐的重要性:确保 SIMD 指令和系统调用正常工作;
调试器如何揭示底层行为:通过 uf main 反汇编,看到高级语言背后的机器逻辑。
✅ 结论:
函数调用的本质确实是 栈帧的创建与销毁。每一次调用都是一次"上下文隔离"的过程,而栈帧就是这个隔离容器。理解它,就理解了程序运行时的内存组织核心机制。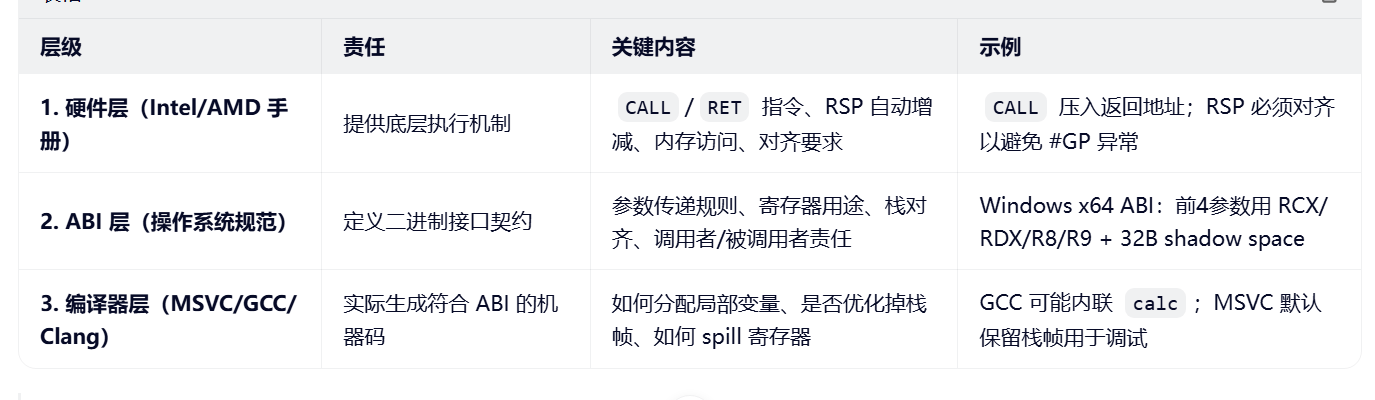
bash
二、ABI 是栈帧结构的"宪法"
✅ ABI(Application Binary Interface) 是连接编译器、链接器、操作系统和 CPU 的桥梁。它明确规定:
1. 参数如何传递
Windows x64 ABI(Microsoft):
整型/指针:RCX, RDX, R8, R9
浮点:XMM0--XMM3
第5+个参数:从右到左压栈(由 caller 分配空间)
强制 32 字节 shadow space(即使函数只用1个参数)
System V ABI(Linux/macOS):
整型:RDI, RSI, RDX, RCX, R8, R9
无 shadow space
第7+个参数才上栈
🔸 同一段 C 代码,在 Windows 和 Linux 下汇编完全不同!
2. 寄存器分类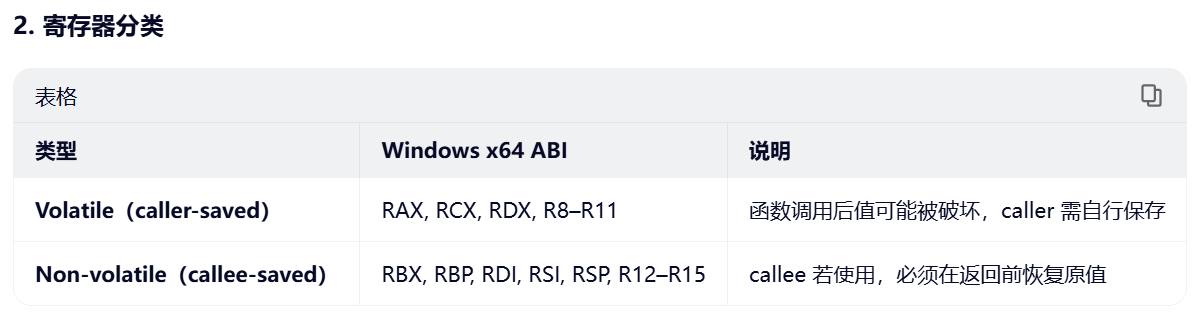
bash
→ 这决定了哪些寄存器需要在栈帧中保存。
3. 栈对齐要求
调用时刻:RSP % 16 == 8(因为 CALL 会 -8,使被调用者入口处 RSP % 16 == 0)
违反 → 某些 SSE 指令崩溃(如 movaps)
4. 返回值传递
整型/指针:RAX
大结构体:caller 分配内存,传隐藏指针作为第一个参数(RCX)
三、编译器:ABI 的忠实执行者(或优化者)
编译器读取 ABI 规范,生成符合要求的代码,但也会进行优化:
示例:你的 calc 函数在不同场景下的实现
场景1:Debug 模式(保留栈帧)
asm
编辑
calc:
push rbp
mov rbp, rsp
sub rsp, 20h ; 为 temp 和对齐分配空间
mov dword ptr [rbp-4], edx ; temp = b
imul eax, edx, r8d
mov dword ptr [rbp-4], eax
add eax, ecx
sub eax, r9d
mov rsp, rbp
pop rbp
ret
→ 完整栈帧,便于调试。
场景2:Release 模式(优化掉栈帧)
asm
编辑
calc:
imul eax, edx, r8d ; b * c
add eax, ecx ; + a
sub eax, r9d ; - d
ret ; 无栈操作!
→ 没有 sub rsp,没有局部变量存储,因为寄存器足够。
💡 即便如此,ABI 仍被遵守:参数仍在正确寄存器,返回值在 RAX,栈对齐依然满足。
四、Intel 手册:提供"舞台",不规定"剧本"
Intel 手册确保:
CALL 一定会压返回地址
RSP 是隐式操作数
内存访问支持任意偏移(如 [rsp+20h])
对齐不当会触发异常
但它不会说:
"你应该把第一个参数放 RCX"
"必须预留 32 字节 shadow space"
"局部变量要放在 [rbp-4]"
这些全是 ABI 的"剧本"。五、完整流程:main 调用 calc 的栈帧生命周期

✅ 整个过程是硬件、ABI、编译器精密配合的结果。
六、总结:为什么必须三者结合?
| 仅看 Intel 手册 | ❌ 不知道参数放哪、栈怎么布局 |
| 仅看 ABI 文档 | ❌ 不知道 CALL 如何压栈、RSP 如何变化 |
| 仅看编译器输出 | ❌ 不理解为何这样生成、能否跨平台 |
🔑 只有三者结合,才能真正掌握:
函数调用时 CPU 做了什么
操作系统 要求我们怎么做
编译器 实际上怎么做的
而这,正是逆向工程、性能调优、系统编程、安全分析的根基。
分析递归或异常(如 SEH)对栈帧的影响
bash
func4 函数的C语言等价代码:
c
// func4的C语言版本
int func4(int a, int b, int c) { // a=edi, b=esi, c=edx
int t = c - b; // t = edx - esi
int sign = t >> 31; // 取符号位 (t < 0 ? -1 : 0)
t = (t + sign) >> 1; // t = (t + sign) / 2
int mid = t + b; // mid = (c - b)/2 + b = (b + c)/2
if (mid <= a) {
if (mid >= a) {
return 0;
} else {
// mid < a
return 2 * func4(a, mid + 1, c) + 1;
}
} else {
// mid > a
return 2 * func4(a, b, mid - 1);
}
}
逐行分析汇编:
text
400fce: sub $0x8,%rsp ; 栈空间
400fd2: mov %edx,%eax ; eax = c
400fd4: sub %esi,%eax ; eax = c - b
400fd6: mov %eax,%ecx ; ecx = c - b
400fd8: shr $0x1f,%ecx ; ecx = (c-b) >> 31 (符号位)
400fdb: add %ecx,%eax ; eax = (c-b) + sign
400fdd: sar %eax ; eax = ((c-b) + sign) / 2
400fdf: lea (%rax,%rsi,1),%ecx ; ecx = (c-b)/2 + b = (b+c)/2 = mid
; 比较 mid 和 a
400fe2: cmp %edi,%ecx ; 比较 mid 和 a
400fe4: jle 400ff2 ; 如果 mid <= a, 跳转
; mid > a 的情况
400fe6: lea -0x1(%rcx),%edx ; c = mid - 1
400fe9: callq 400fce <func4> ; 递归调用
400fee: add %eax,%eax ; 结果 * 2
400ff0: jmp 401007 ; 返回
; mid <= a 的情况
400ff2: mov $0x0,%eax ; eax = 0
400ff7: cmp %edi,%ecx ; 再次比较 mid 和 a
400ff9: jge 401007 ; 如果 mid >= a, 返回0
; mid < a 的情况
400ffb: lea 0x1(%rcx),%esi ; b = mid + 1
400ffe: callq 400fce <func4> ; 递归调用
401003: lea 0x1(%rax,%rax,1),%eax ; eax = 2*result + 1
401007: add $0x8,%rsp ; 恢复栈
40100b: retq ; 返回
bash
func4 是一个典型的递归函数,实现的是二分查找的变种,并返回一个与路径相关的整数值(类似"决策树编码")。它完美展示了 递归对栈帧的动态影响。
我们将结合:
✅ Intel 手册(硬件):CALL/RET 如何操作栈
✅ System V ABI(Linux x64 软件约定):参数传递、寄存器使用
✅ GCC 编译器行为:如何为递归函数分配栈帧
来深入分析 递归调用对栈帧的影响。
(注:本例无 SEH,因为 SEH 是 Windows 特有;Linux 使用 DWARF 异常处理,但 func4 无异常,故聚焦递归)
一、func4 的功能简析(辅助理解栈行为)
c
编辑
int func4(int a, int b, int c) {
int mid = (b + c) / 2; // 向下取整(通过符号位修正)
if (mid == a) return 0;
else if (mid < a) return 2 * func4(a, mid+1, c) + 1;
else return 2 * func4(a, b, mid-1);
}
这是一个 尾递归?不!是普通递归(调用后还要做 *2 或 *2+1)
每次递归缩小 [b, c] 区间
最深递归深度 ≈ log₂(c - b)
二、单次调用的栈帧结构(非递归视角)
汇编开头/结尾:
asm
编辑
sub $0x8, %rsp ; 分配 8 字节
...
add $0x8, %rsp ; 释放 8 字节
retq
为什么只分配 8 字节?
函数很小,局部变量 t, sign, mid 全用寄存器(%eax, %ecx)
唯一需要栈的原因:对齐要求
🔸 System V ABI 要求:函数入口处 %rsp % 16 == 8
因为 call 会压入 8 字节,使被调用者入口处 RSP % 16 == 0
但 GCC 发现内部要调用其他函数(call func4),所以必须保持 16 字节对齐
→ sub $0x8 使 RSP % 16 == 8,满足下一次 call 前的要求
✅ 所以这 8 字节 不是用于局部变量,而是用于栈对齐!
三、递归调用时的栈帧累积(核心!)
假设调用链:
text
编辑
func4(5, 0, 14)
└─ func4(5, 8, 14)
└─ func4(5, 8, 10)
└─ func4(5, 8, 8) → mid=8 > 5 → func4(5,8,7) → base case?
每次 call func4 发生时: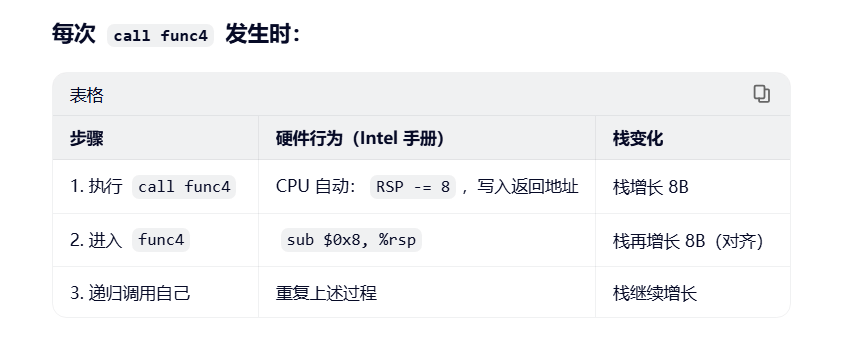
bash
栈内存布局(递归深度=3 时):
text
编辑
High Address
│
├── [RSP+10h] → 返回地址(第3层 → 第2层)
├── [RSP+08h] → 对齐空间(第3层)
├── [RSP+00h] → ← 当前 RSP(第3层入口)
│
├── [RSP-08h] → 返回地址(第2层 → 第1层)
├── [RSP-10h] → 对齐空间(第2层)
│
├── [RSP-18h] → 返回地址(第1层 → caller)
├── [RSP-20h] → 对齐空间(第1层)
│
Low Address
💡 每层递归消耗 16 字节栈空间(8B 返回地址 + 8B 对齐)
四、Intel 手册如何支撑递归?
1. CALL 指令(Vol. 2A)
"Pushes the return address onto the stack and transfers control."
每次递归调用都压入独立的返回地址
形成 返回地址链,确保 ret 能逐层返回
2. RET 指令
"Pops the return address and jumps to it."
从当前栈顶弹出地址,跳转
自动恢复上一层的 RIP
3. 栈指针连续性
RSP 始终指向当前函数的栈顶
递归深度增加 → RSP 不断减小(向低地址增长)
✅ 递归的本质:利用栈的 LIFO 特性保存多层上下文
五、ABI 与编译器在递归中的角色
System V ABI 规定:
参数通过 %rdi, %rsi, %rdx 传递 → 每次递归调用前重新设置
调用者(即 func4 自己)负责清理参数(但参数在寄存器,无需清理)
必须保持栈 16 字节对齐 → 所以每层 sub $0x8
GCC 行为:
没有优化成尾递归(因为 *2 和 +1 在调用后执行)
每层独立栈帧(即使无局部变量,也保留对齐空间)
若开启 -O2,可能内联或优化,但本例保留递归结构
六、潜在风险:栈溢出(Stack Overflow)
每层递归消耗 ~16 字节
默认栈大小(Linux)通常为 8MB
最大递归深度 ≈ 8MB / 16B ≈ 524,288 层
但在 func4 中:
区间 [b, c] 每次至少缩小 1
最大深度 ≈ c - b(最坏线性),但实际是二分 → 深度 ≈ log₂(15) ≈ 4~5 层
✅ 所以安全。但若写成:
c
编辑
int bad(int n) { return bad(n-1); } // 无限递归
→ 很快触发 Segmentation Fault(栈溢出)
🔔 栈溢出不是由 CPU 检测,而是由 OS 的 栈保护页(guard page) 触发 SIGSEGV
七、与异常处理(如 SEH)的对比说明
虽然 func4 没有异常,但可简要对比: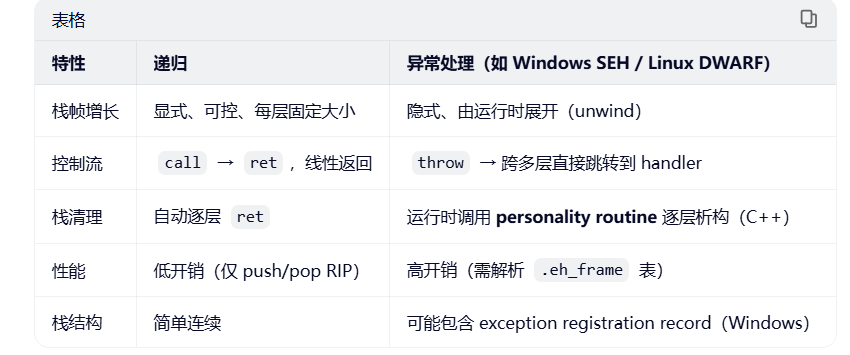
bash
八、总结:递归对栈帧的核心影响
栈帧动态累积:每层递归创建独立栈帧(含返回地址 + 对齐空间)
硬件自动管理返回地址:CALL/RET 构建调用链
ABI 强制对齐:即使无局部变量,也需 sub rsp, N 满足 16 字节对齐
编译器保留结构:因非尾递归,无法优化为循环
深度决定栈消耗:二分递归深度浅,安全;线性递归易栈溢出
✅ 最终结论:
func4 是理解 递归与栈帧关系 的绝佳例子------它展示了:
每一次递归调用,都是在栈上叠加一个新的上下文盒子;
而每一次返回,都是将这个盒子优雅地拆除。
这正是冯·诺依曼架构"用栈实现递归"的精妙体现。