引言
作为一个 Java 和 Go 后端开发者,深刻理解 IO 多路复用是掌握高性能网络编程(如 Netty)的基石。
简单来说,IO 多路复用是一种允许单个线程同时监视多个文件描述符(FD, File Descriptor)的技术。一旦某个 FD 就绪(读/写就绪),内核会通知应用程序进行处理。
如果没有它,处理 10,000 个并发连接可能需要 10,000 个线程(资源消耗巨大)或者使用非阻塞 IO 轮询(空转烧 CPU)。
下面我将从底层原理对比 select、poll 和 epoll进行说明。
Select:早期的探索
select 是最早期的 IO 多路复用实现。
-
工作原理:
- 用户进程将需要监视的
fd_set(一个位图 bitmap)拷贝到内核空间。 - 内核遍历一遍所有的 socket,如果有数据,就标记为可读/可写。
- 内核将
fd_set拷贝回用户空间。 - 用户进程再次遍历
fd_set,找到被标记的 socket 进行处理。
- 用户进程将需要监视的
-
缺点:
- 性能开销大: 每次调用都要把 FD 集合在用户态和内核态之间拷贝;内核和用户态都需要遍历整个 FD 集合(时间复杂度 O(n))。
- 连接数限制: 默认限制为 1024 个连接(由
FD_SETSIZE宏定义,虽然可以改,但效率会急剧下降)。
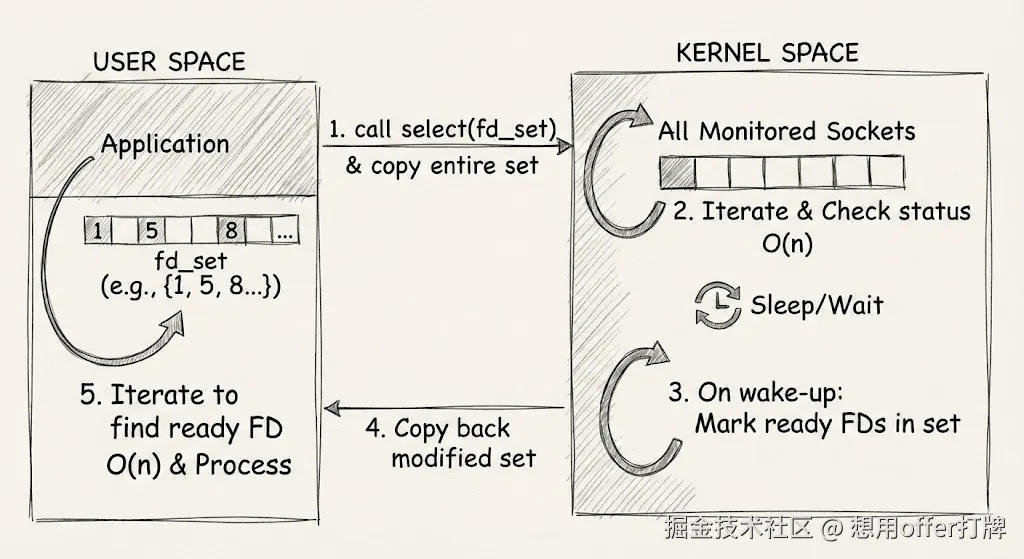
总的原因就是每次调用都需要拷贝fd_set,而且需要进行线性循环。来个形象的比喻就是服务员需要挨个问客人你点好单了吗,不用想都是效率十分低下。
这张图展示了 select 低效的原因:每次调用都需要在用户态和内核态之间拷贝整个文件描述符集合 (fd_set),并且内核和用户程序都需要进行 O(n) 的线性遍历。
Poll:Select 的链表版
poll 和 select 本质区别不大。
-
工作原理:
- 它使用
pollfd结构体的链表(或数组)而不是 bitmap 来传递 FD。
- 它使用
-
改进点:
- 没有最大连接数限制(受限于系统内存和文件描述符限制)。
-
缺点:
- 性能依然是瓶颈: 它和
select一样,内核需要线性遍历所有 FD 来检查状态,用户态也需要遍历所有 FD 来查找谁就绪了。随着连接数增加,性能线性下降
- 性能依然是瓶颈: 它和
最大的性能瓶颈并没有解决,所以这个我们并不需要太了解。
Epoll:Linux 的杀手锏
epoll是为了解决 C10K 问题而生的,它是目前 Linux 下高性能网络编程的核心。
-
核心设计(三个函数):
epoll_create:在内核创建一个 epoll 对象(内部结构是一棵红黑树 和一个双向链表)。epoll_ctl:向红黑树中添加、删除或修改感兴趣的 FD。这也是 O(logn) 的效率,比线性扫描快得多。epoll_wait:等待事件。
-
工作原理(Callback 机制):
epoll不再轮询。它为每个 FD 注册一个回调函数。- 当网卡接收到数据,中断程序会调用回调函数,将该 FD 添加到就绪链表(Ready List)中。
epoll_wait实际上只是在检查这个就绪链表是否为空。- 用户进程只需要处理就绪链表中的 FD,不需要遍历所有连接。
-
优点:
- 效率极高: 时间复杂度为 O(1)(严格来说是 O(k),k 为活跃连接数)。性能不会随总连接数增加而下降,只与"活跃"连接数有关。
- 内存拷贝少: 使用了 mmap(内存映射)技术或高效的内存管理,减少了复制开销(注:现代实现主要是避免了像 select 那样每次调用都重复传入整个 FD 集合)。
-
两种触发模式:
- LT (Level Triggered - 水平触发): 默认模式。只要缓冲区还有数据,内核就会一直通知你。
- ET (Edge Triggered - 边缘触发): 高速模式。只有数据状态发生变化(从无到有)时通知一次。如果你不读完,内核不会再通知,这要求程序必须一次性把数据读完。Go 和 Nginx 使用的是 ET 模式的变种或思想来追求极致性能。
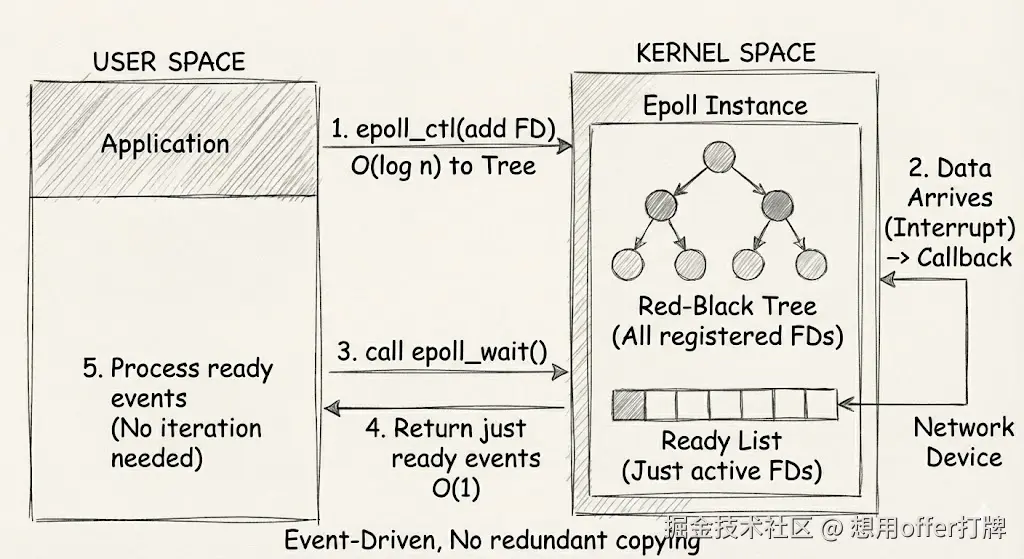
不好理解?来个比喻:服务员再也不用去挨个问是否点好单,而是由大堂经理将需要订单的顾客名单给服务员去通知后厨
这张图展示了 epoll 高效的原因:它使用红黑树来管理所有的文件描述符(只需注册一次),并采用事件驱动的机制。当网络设备有数据到达时,通过回调函数直接将就绪的 FD 加入到"就绪链表"中,应用程序只需要处理这个链表即可,无需遍历所有连接
Java和Go有什么需要了解的小知识?
作为后端开发,了解这些对你理解语言底层至关重要:
-
Java (NIO / Netty):
- Java 的
java.nio.channels.Selector是一个抽象层。 - 在 Linux 上,JDK 会自动映射到底层的
epoll。 - Netty 的核心 EventLoop 也就是在一个线程中不断轮询这个
Selector(即epoll_wait),实现了高性能的 Reactor 模型。
- Java 的
-
Go (Goroutine & Netpoller):
- Go 的网络编程看起来是同步阻塞的(比如
conn.Read()),但底层完全是异步非阻塞的。 - Go Runtime 包含了一个 Netpoller(网络轮询器)。
- 在 Linux 下,Netpoller 封装了
epoll。当你调用conn.Read()且没有数据时,Go 调度器会将该 Goroutine 挂起(Gopark),并将 FD 注册到epoll中。 - 当
epoll通知数据就绪,Go 调度器再唤醒该 Goroutine。
- Go 的网络编程看起来是同步阻塞的(比如
这就是 Go 高并发的核心秘密:用同步的代码逻辑,享受了 epoll 的异步性能。
总结
这就是全部内容,下面是一个小结表格。
| 特性 | Select | Poll | Epoll |
|---|---|---|---|
| 底层数据结构 | Bitmap (数组) | 链表 / 数组 | 红黑树 (存储FD) + 双向链表 (存储就绪FD) |
| 时间复杂度 | O(n) | O(n) | O(1) (与活跃数有关) |
| 最大连接数 | 1024 (默认) | 无限制 | 无限制 (受系统内存限制) |
| IO效率 | 随连接数增加而显著下降 | 随连接数增加而显著下降 | 不随总连接数线性下降 |
| 数据拷贝 | 每次调用都需要拷贝全部 FD | 每次调用都需要拷贝全部 FD | FD 仅在注册时拷贝一次 |
如果觉得我讲的好,就给我点赞+收藏+关注吧,这是我更新的最大动力❤️