f t \[ x ] = t f \[ x ] ft\[x]=tf\[x] ft\[x]=tf\[x]
-> 卷积操作满足同变性
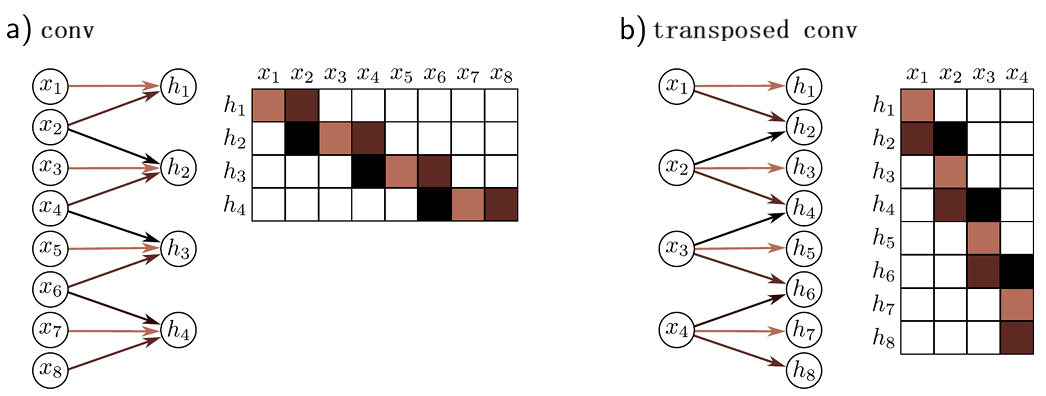
一维卷积(convolution 1d)
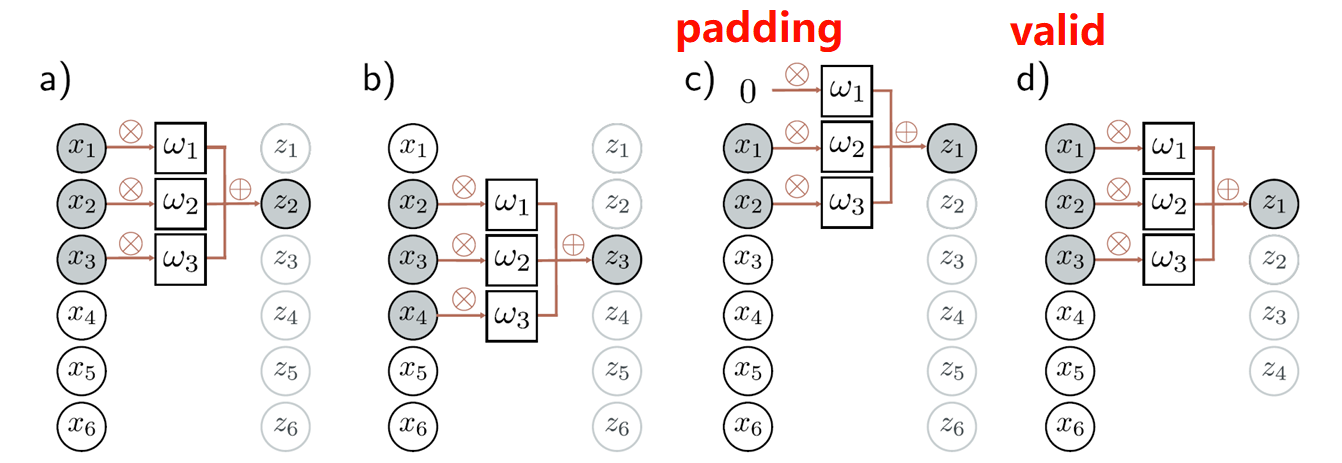
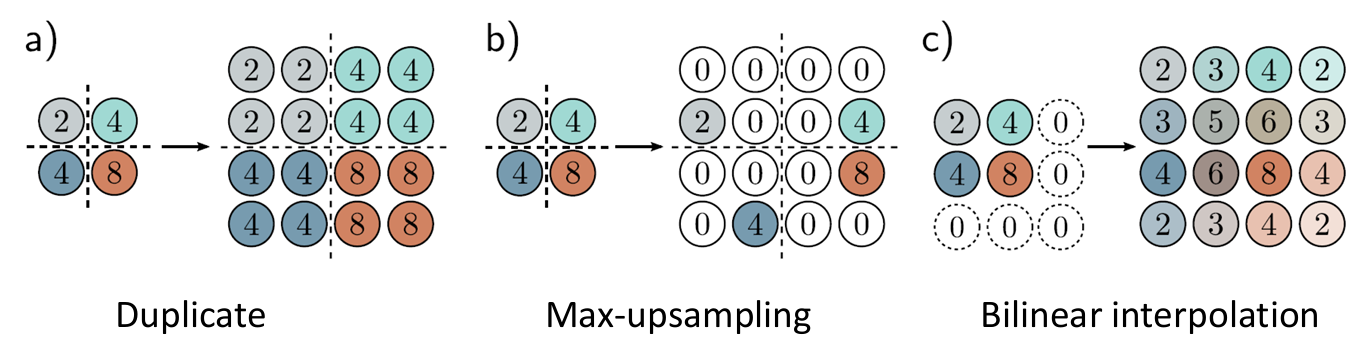
1. Padding 与 Valid 模式
Padding 模式 :在输入数据的两侧填充元素 ,使卷积后输出尺寸与输入尺寸一致
Valid 模式 :不进行填充,仅对输入数据的有效区域进行卷积,输出尺寸小于输入尺寸
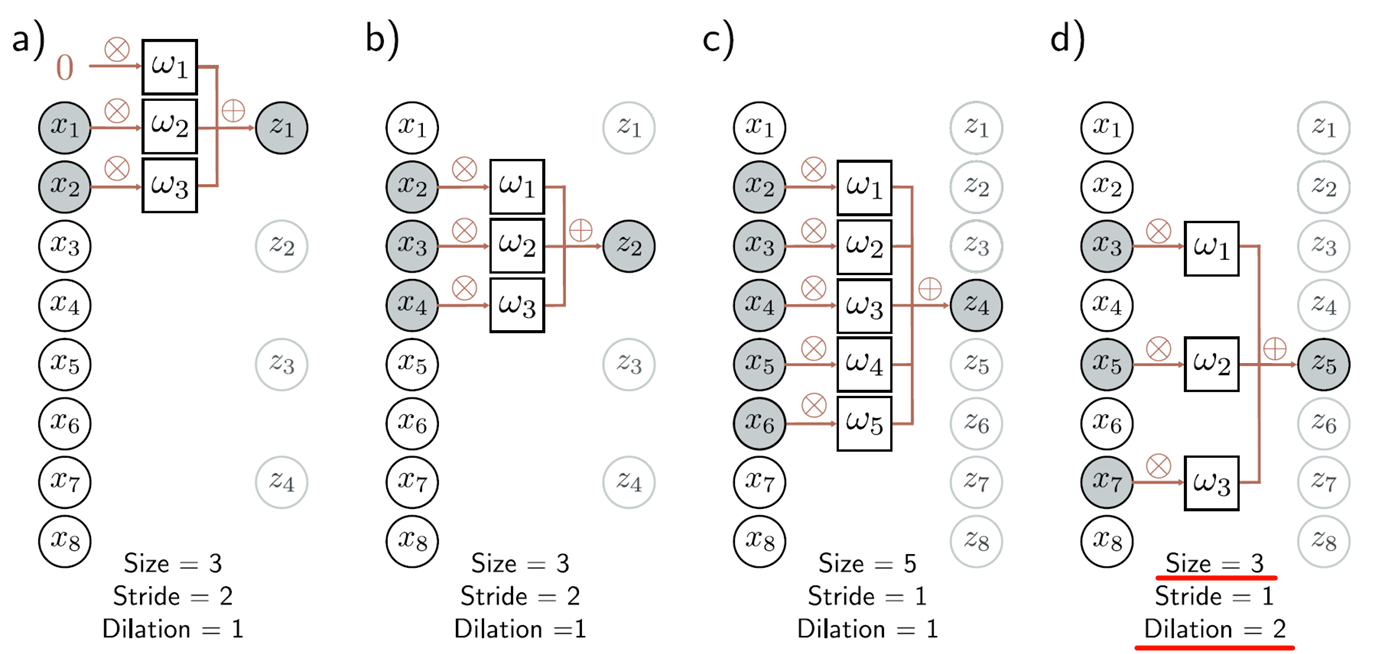
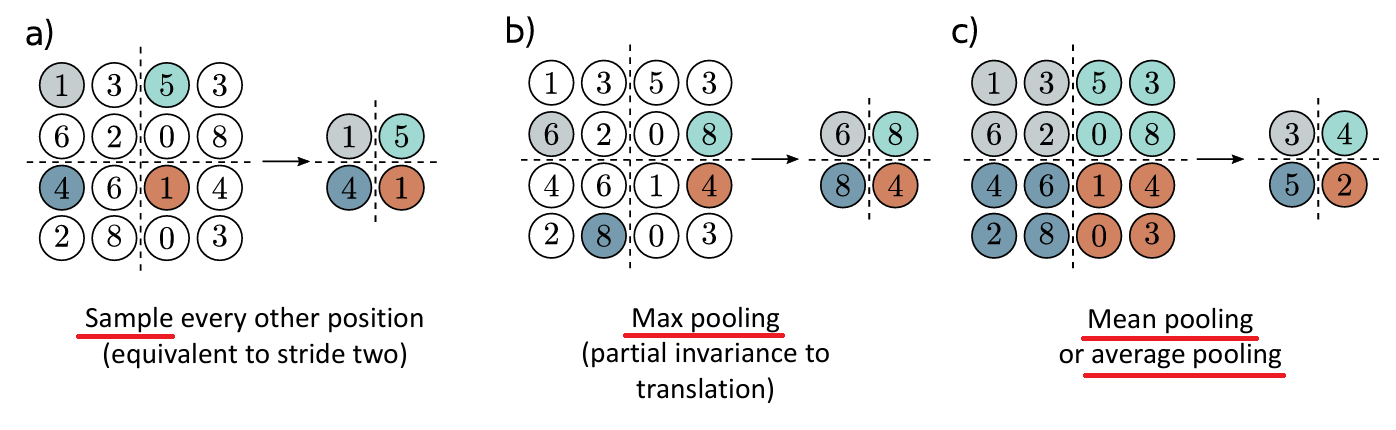
步长: stride
卷积核大小: kernel size
膨胀/空洞: dilated
Dilation=2代表每2个元素取1个 size按实际取到的元素个数来算
2. 卷积层计算流程
卷积层通过以下步骤计算输出:
对输入进行卷积运算,加上偏置项 β \beta β,然后将每个结果通过激活函数 a ⋅ a\\cdot a⋅ 传递
卷积网络: 3 weights, 1 bias
h i = a β + ω 1 x i − 1 + ω 2 x i + ω 3 x i + 1 = a β + ∑ j = 1 3 ω j x i + j − 2 \begin{aligned} h_i &= \mathrm{a}\left\\beta + \\omega_1 x_{i-1} + \\omega_2 x_i + \\omega_3 x_{i+1}\\right \\ &= \mathrm{a}\left\\beta + \\sum_{j=1}\^{3} \\omega_j x_{i+j-2}\\right \end{aligned} hi=aβ+ω1xi−1+ω2xi+ω3xi+1=aβ+j=1∑3ωjxi+j−2
全连接网络: D 2 D^2 D2 weights, D D D biases
h i = a β i + ∑ j = 1 D ω i j x j h_i = \mathrm{a}\left\\beta_i + \\sum_{j=1}\^{D} \\omega_{ij} x_j\\right hi=aβi+j=1∑Dωijxj
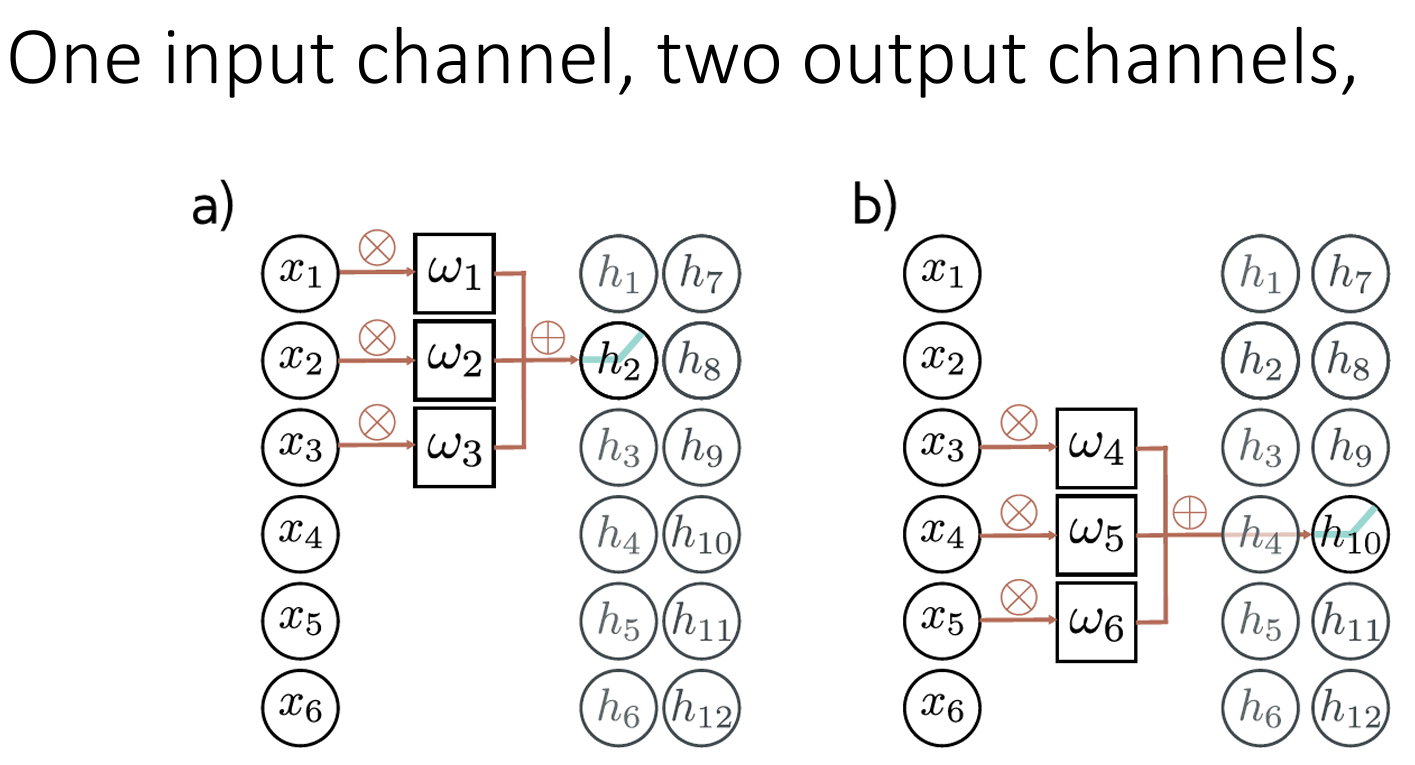
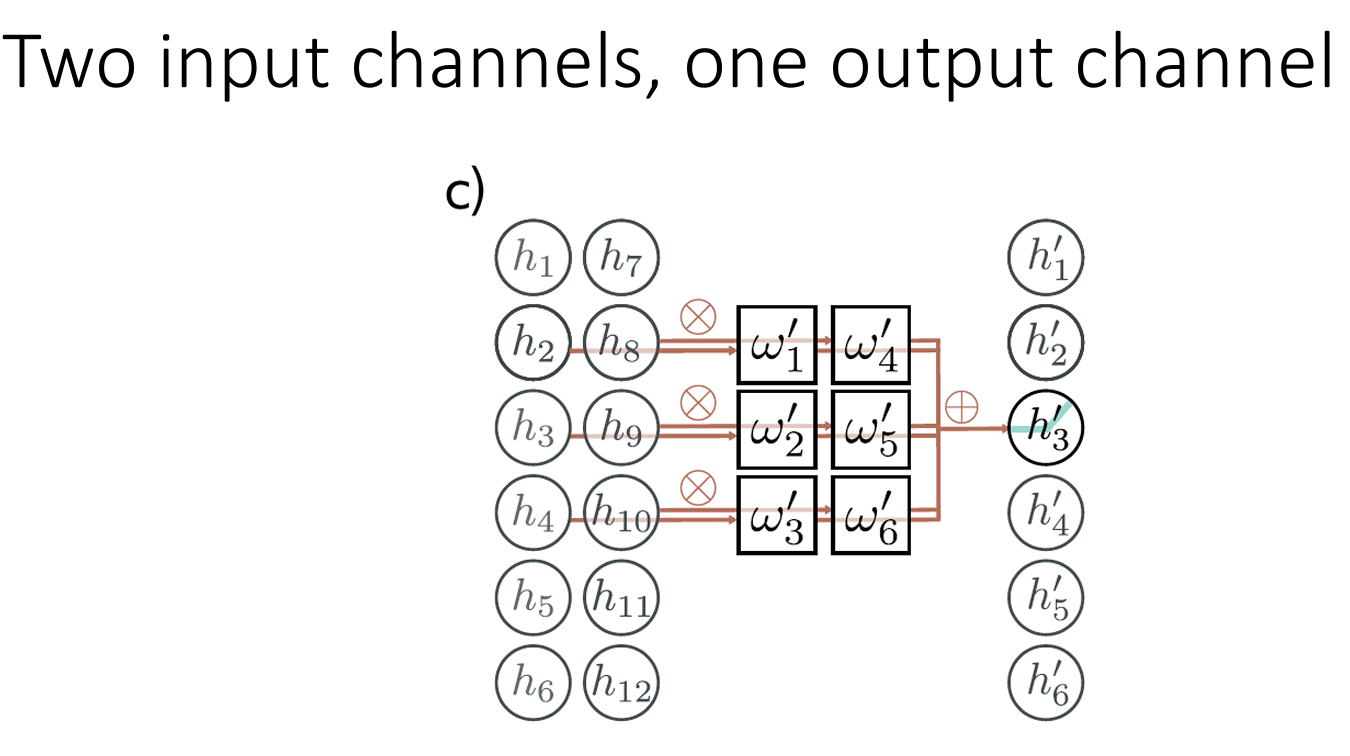
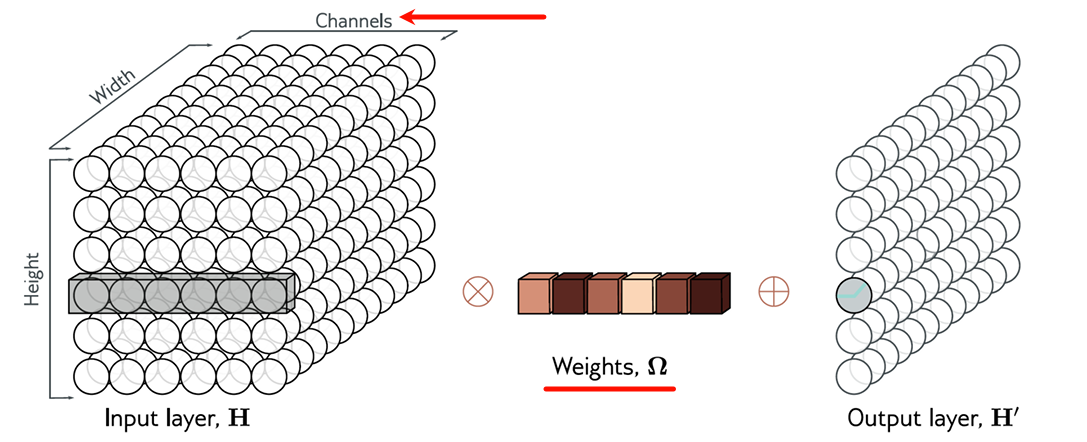
3. 通道(channels)
单一卷积会导致信息丢失(邻近输入平均、ReLU 剪切负值)
通常并行计算多个卷积,每个卷积生成一组隐藏变量,称为特征图 或通道
通道与卷积核的关系:
卷积核的个数 → \to → 输出通道数 C o C_o Co
单个卷积核的层数 → \to → 输入通道数 C i C_i Ci
参数量计算:
核大小为 K K K,输入通道 C i C_i Ci,输出通道 C o C_o Co,卷积核参数维度为:
Ω ∈ R C i × C o × K \Omega \in \mathbb{R}^{C_{i}\times C_{o}\times K} Ω∈RCi×Co×K
两个卷积核:
一个卷积核, 但是有两层:
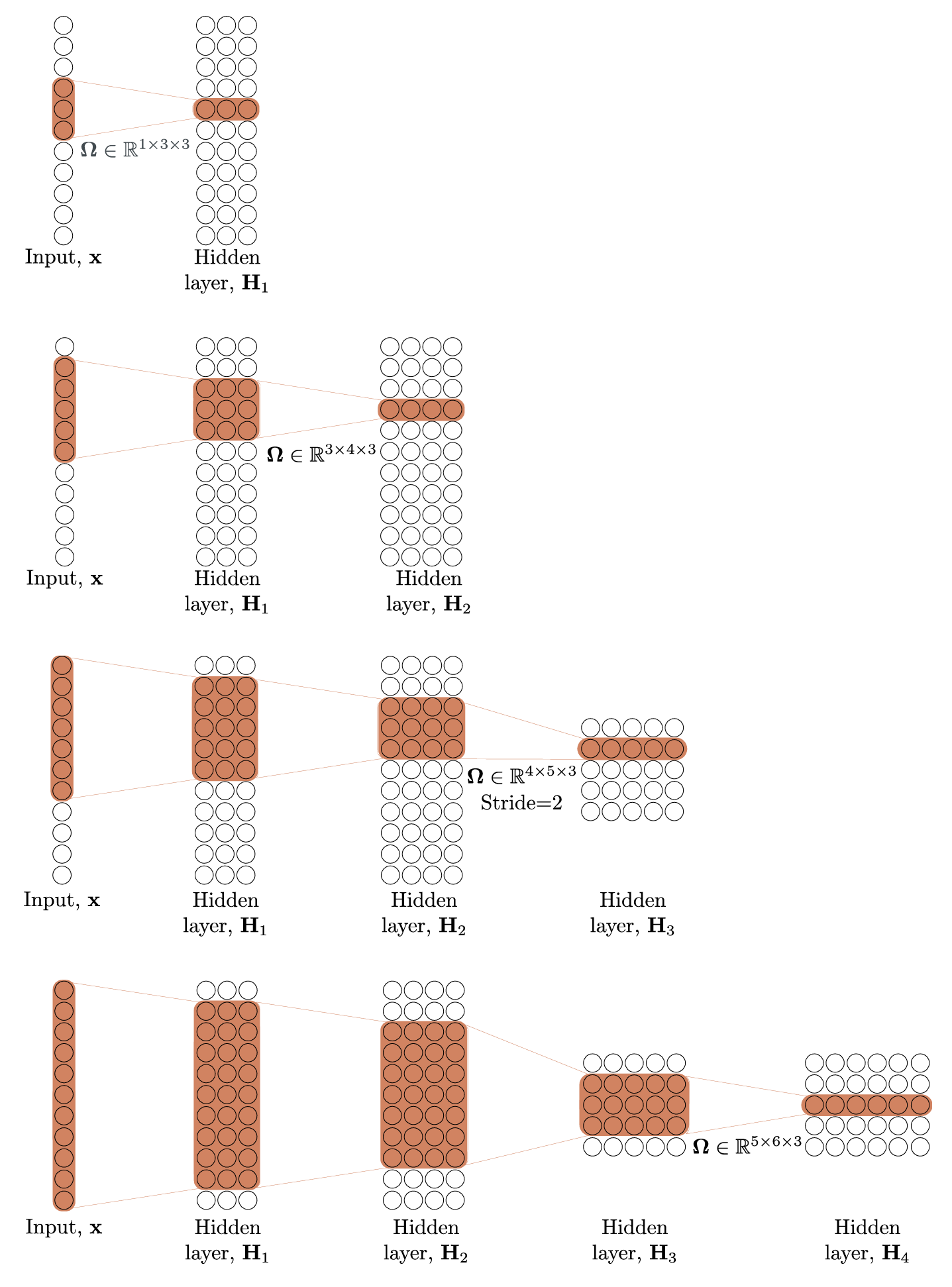
4. 感受野(Receptive fields)
感受野指输出特征图上的一个像素点,对应输入图像上的区域大小
例:H1 每个单元感受野为 3,H2 为 5,H3 为 7,H4 为 11
规律:卷积层数越多,感受野越大 → 这是卷积网络设计多层结构的核心原因
二维卷积(convolution 2d)
适用场景: 图像数据、金融时间序列、音频、文本等
参数量计算:
核大小为 K × K K\times K K×K,输入通道 C i C_i Ci,输出通道 C o C_o Co,卷积核与偏置参数维度为:
ω ∈ R C i × C o × K × K β ∈ R C o \boldsymbol{\omega} \in \mathbb{R}^{C_{i} \times C_{o} \times K \times K} \qquad \beta \in \mathbb{R}^{C_{o}} ω∈RCi×Co×K×Kβ∈RCo