一、引言
随着大型语言模型(LLM)在具身智能等领域的广泛应用,接下来就该思考如何在有限硬件资源下部署这些模型,量化是其中必不可少的步骤。
模型量化(Model Quantization)作为一种有效的模型压缩技术,通过将模型中的浮点数参数转换为低比特宽度的整数表示,显著减少了模型的存储和计算需求,同时尽量保持模型的性能。量化的基础知识相信大家都不会陌生,例如必然要介绍两种量化方式:PTQ/QAT。
QAT 是一种深度融合量化需求与模型训练流程的技术,核心是在模型训练阶段主动嵌入 "伪量化算子"------ 不实际将参数转换为低比特,而是模拟量化过程中的数值截断误差与舍入误差,让模型在学习任务知识的同时,同步适应量化带来的精度损耗。训练中,伪量化算子会实时统计各层输入输出的数据分布(如激活值的极值、权重的方差),动态优化量化参数(如缩放因子、零点),确保量化逻辑与模型参数更新形成配合。这种 "边训练边适配量化" 的特性,能让大语言模型(LLM)在低精度表示(如 4bit、2bit)下,依然保留接近原始浮点模型的性能。
PTQ 是在 LLM 完全训练完成后执行的量化方案,无需修改模型训练流程,仅需使用少量校准数据(通常 100-1000 条代表性样本)统计模型权重与激活值的分布特征,即可确定量化参数并完成低比特转换。其核心优势在于 "轻量高效":无需重新训练模型,量化过程仅需数分钟至数小时,无需大规模计算资源;同时无需改动 LLM 架构,可直接适配各类推理框架,兼顾易用性与部署效率。不过,PTQ 的精度天花板相对较低,目前在 4bit 及以下量化时易出现明显精度损失,更适合对精度要求不高、追求快速部署的场景。
本文重点不是上述两种量化方式,而是将重点介绍四种主流的大模型量化方法:GPTQ、SmoothQuant、AWQ 和旋转量化,下面来分别看一下。
二、GPTQ
GPTQ(Gradient-based Post-training Quantization)是一种后训练量化方法,其核心思想是利用梯度信息来指导量化过程,从而最小化量化带来的性能损失。论文中仅进行权重量化,权重被量化为 int4 类型,激活值为 float16。
GPTQ(GPT Quantization)是一种基于最优量化误差最小化的单轮权重量化方法,其核心创新点在于:
- 顺序压缩算法:按重要性对模型层进行排序,优先量化对输出影响较小的层
- 误差补偿机制:通过梯度下降优化量化参数,减少精度损失
- 分组量化策略:将权重矩阵分为小组(Group Size)独立量化,平衡压缩率与精度
工作流程图如下:

GPTQ 通过优化量化误差的目标函数,使得量化后的模型输出尽可能接近原始模型的输出。其优化目标可以表示为:
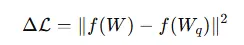
其中,f(⋅) 为模型的前向传播函数,W 为原始浮点权重,Wq 为量化后的权重。
GPTQ 已被广泛应用于 HuggingFace 等平台,具有完善的工具链和生态支持。但 GPTQ 主要针对模型的权重进行量化,对激活值的处理相对有限,且在量化过程中需要计算梯度信息,会增加额外的计算开销。
三、SmoothQuant
SmoothQuant 是一种训练后量化方法,旨在解决激活值量化困难的问题。核心理念在于平衡激活值和权重的量化难度。在大模型量化中,激活值通常包含大量离群点,这些离群点会显著拉伸量化范围,增加量化误差。SmoothQuant 提出了一种基于平滑因子的逐通道缩放变换方法,对每个通道的激活值进行缩放以平滑其分布,同时对权重施加反向缩放,确保模型计算的等价性。
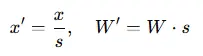
其中,s 为平滑因子,x 为激活值,W 为权重,x′ 和 W′ 分别为经过平滑处理后的激活值和权重。通过这种方式,SmoothQuant 将激活值的量化难度转移到权重上,从而实现更高效的量化。
SmoothQuant 可以同时对权重和激活值进行 8 位量化,减少模型的存储需求,通过将激活值的异常值减少,SmoothQuant 可以提高推理的效率,但平滑因子 s 的选择对量化效果有较大影响,且不同的模型可能需要不同的平滑因子,需要通过实验进行调优。
四、AWQ
AWQ(Activation-aware Weight Quantization)是一种自适应权重量化方法,旨在根据激活值的重要性来指导权重的量化过程。其核心思想是识别出对模型输出影响较大的激活值,并根据这些激活值的重要性来调整权重的量化精度。具体而言,AWQ 通过计算激活值的方差来评估其重要性,然后根据重要性为权重分配不同的量化精度:
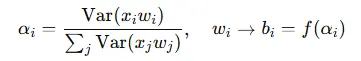
其中,
αi
为第 i 个权重的激活感知度,b_i 为其对应的量化比特数。
AWQ 方法源于"权重对于 LLM 的性能并不同等重要"的观察,存在约(0.1%-1%)显著权重对大模型性能影响太大,通过跳过这 1% 的重要权重不进行量化,可以大大减少量化误差。根据激活值的重要性动态调整权重的量化精度,这需要计算激活值的方差,实现相对复杂。
五、SpinQuant
旋转量化(SpinQuant)是一种通过旋转矩阵变换数据空间来实现量化的方法。其核心思想是通过引入旋转矩阵 RRR 将数据映射到新的空间,然后在新的空间中进行量化,从而使得量化误差在数据空间中更加均匀地分布,减少量化误差对模型性能的影响。具体而言,旋转量化的过程可以表示为:

其中,w 为原始权重,w′ 为经过旋转变换后的权重,w'_q 为量化后的权重,w_q 为最终的量化权重。
通过旋转变换数据空间,可以使得量化误差在数据空间中更加均匀地分布,适应不同的模型结构和数据分布,减少量化误差。这个过程需要计算旋转矩阵,并进行矩阵变换,会引入一些计算开销。