个人主页:strive_debug
Bjarne Stroustrup与C++的诞生
C++之父的背景与动机
Bjarne Stroustrup(本贾尼·斯特劳斯特卢普)在开发C++时的核心驱动力源于他对当时主流编程语言(特别是C语言)局限性的深刻认识:
Stroustrup观察到的三大不足:
-
表达能力的局限
- C语言缺乏高级抽象机制(如类、模板)
- "Simula-like"特性需求日益增长但无法实现
-
可维护性挑战
- C程序规模增大时代码组织困难
- UNIX内核开发经验暴露了模块化不足的问题
-
可扩展性瓶颈
- ADT(抽象数据类型)实现笨拙且低效
- Bell实验室网络交换机项目需要更强大的类型系统
发展史:

C++参考⽂档:
https://legacy.cplusplus.com/reference/
https://zh.cppreference.com/w/cpp
http://https://en.cppreference.com/w/
C++学习资源与第一个程序指南
C++学习文档资源对比
📚三大主流参考文档
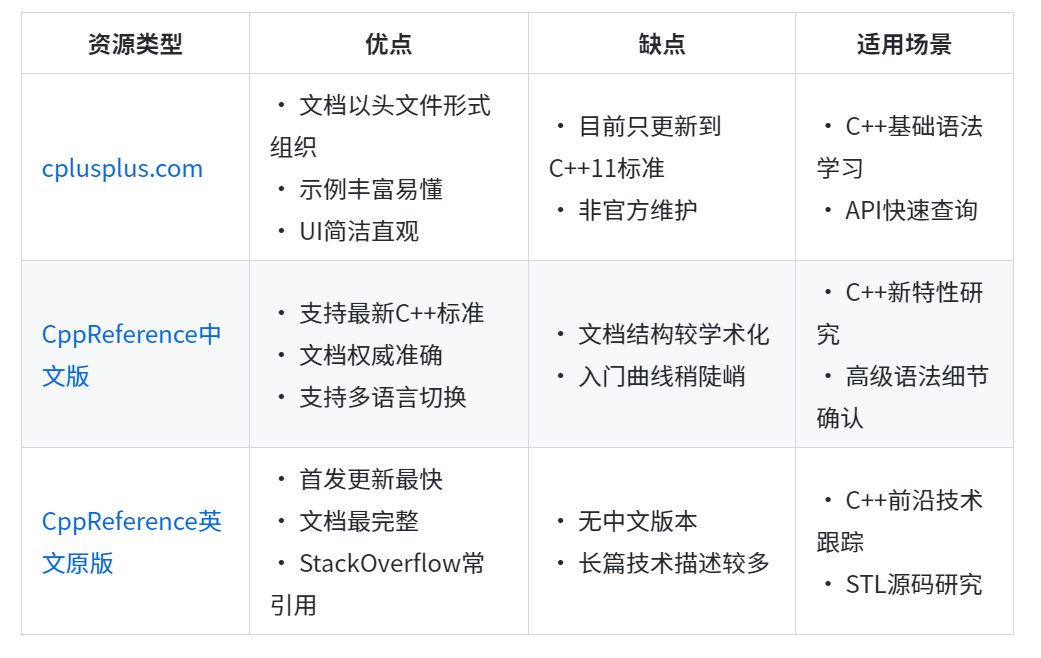
> 💡 **建议策略**:初学者从cplusplus.com入门 → cppreference查阅细节 → StackOverflow解决具体问题
C++第一个程序实现
C与C++的兼容性说明
- **语法兼容性**
C++兼容C语言99%语法特性(除VLA等少数特性)
C语言程序可直接保存为`.cpp`文件编译运行
- **编译工具差异**
Windows (VS):`.c`文件 → C编译器 / `.cpp` → C++编译器
Linux:需明确使用`gcc`(C)或`g++`(C++)命令
> 🌟 **最佳实践建议**:即使是简单测试程序也建议使用`.cpp`扩展名和C++标准写法(如cout/cin),以培养规范的C++编码习惯
cpp
// test.cpp
#include<stdio.h>
int main()
{
printf("hello world\n");
return 0;
}当然C++有⼀套⾃⼰的输⼊输出,严格说C++版本的hello world应该是这样写的。
cpp
// test.cpp
#include<iostream>
using namespace std;
int main()
{
cout << "hello world\n" << endl;
return 0;
}C++命名空间详解
namespace的核心价值
在C/C++开发中面临的核心问题:
**全局作用域污染**:变量、函数、类名都存在于全局作用域
**命名冲突风险**:大型项目中名称冲突概率极高
namespace的设计初衷正是为了解决这些问题。
namespace的本质特性
- **作用域隔离机制**
cpp
namespace A {
int x = 10; // A域中的x
}
int x = 20; // 全局域中的x- **可包含内容**
- ✅变量、✅函数、✅类型(类/结构体)、✅嵌套命名空间
- **作用域类型对比**
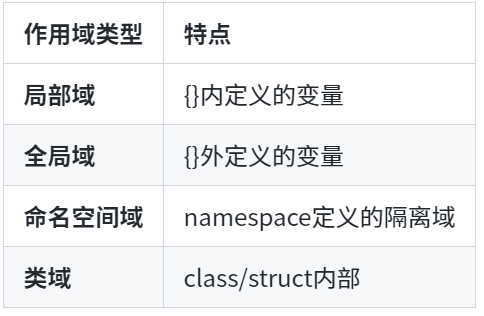
namespace的关键特性
- **只能定义在全局**
cpp
// ✅正确 - 全局定义
namespace N1 { /*...*/ }
void func() {
// ❌错误 -不能在函数内定义namespace
// namespace N2 { /*...*/ }
}- **支持嵌套定义**
cpp
//2. 命名空间可以嵌套
namespace uint
{
namespace king
{
int rand = 1;
int Add(int left, int right)
{
return left + right;
}
}
namespace qun
{
int rand = 2;
int Add(int left, int right)
{
return (left + right)*10;
}
}
}
int main()
{
printf("%d\n", unit::king::rand);
printf("%d\n", unit::qun::rand);
printf("%d\n", unit::king::Add(1, 2));
printf("%d\n", unit::qun::Add(1, 2));
return 0;
}- **多文件共享特性**
cpp
// file1.h
namespace MyLib {
void init();
}
// file2.cpp
namespace MyLib {
void init() { /*实现*/ }
}
//int main 函数调用的时候MyLib::写使用的函数,他会去自己寻找MyLib中的对应函数
//这两个MyLib的函数是不一样的,一样的就多余了,体现的是不一样的函数作用
//多⽂件中可以定义同名namespace,他们会默认合并到⼀起,就像同⼀个namespace⼀样下面的我还没理解到,等理解到我会为大家插入链接:
namespace的实际应用场景
- **第三方库隔离**
cpp
namespace boost { /*...*/ }
namespace Qt { /*...*/ }- **模块化开发**
cpp
namespace NetworkModule {
class Socket;
void connect();
}
namespace DatabaseModule {
class Connection;
void query();
}- **版本控制**
cpp
namespace MyLib_v1 { /*旧版接口*/ }
namespace MyLib_v2 { /*新版接口*/ }namespace的特殊用法
匿名命名空间
cpp
namespace {
//仅在当前文件可见(类似static)
int internalVar = 42;
}别名定义
cpp
namespace very_long_namespace_name {
/*...*/
}
namespace vl = very_long_namespace_name; //创建别名最佳实践建议:在大型项目中优先使用命名空间组织代码结构,避免将非必要内容暴露到全局作用域
cpp
#include <stdio.h>
#include <stdlib.h>
// 1. 正常的命名空间定义
// king是命名空间的名字,⼀般开发中是⽤项⽬名字做命名空间名。
namespace king
{
// 命名空间中可以定义变量/函数/类型
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
int main()
{
// 这⾥默认是访问的是全局的rand函数指针
printf("%p\n", rand);
// 这⾥指定king命名空间中的rand
printf("%d\n", king::rand);
return 0;
}C++命名空间使用指南
命名空间的基本概念
当编译器查找变量/函数的声明或定义时:
默认查找范围:局部作用域 → 全局作用域
不会自动查找:命名空间内的定义
三种访问命名空间成员的方式
- 指定命名空间访问(项目推荐)
cpp
std::cout << "Hello World" << std::endl;**优点**:
明确标识来源命名空间
避免命名冲突风险
- using声明引入特定成员(推荐常用无冲突成员)
cpp
using std::cout;
using std::endl;
cout << "Hello World" << endl;**适用场景**:
频繁使用的命名空间成员
**确认不会引起命名冲突**的情况
- using指令展开整个命名空间(仅推荐练习使用)
cpp
using namespace std;
cout << "Hello World" << endl;**风险提示**:
**极易引起命名冲突**
**项目开发中严格禁止使用**
最佳实践建议:

项目开发推荐写法
cpp
// ✅项目开发推荐写法
#include <iostream>
int main() {
std::cout << "Professional code" << std::endl;
return 0;
}
// 🚨仅限练习使用的写法(不推荐用于项目)
#include <iostream>
using namespace std;
int main() {
cout << "Practice code" << endl;
return 0;
}记住:良好的命名空间使用习惯是编写可维护C++代码的重要基础!
三种写法:
cpp
// 指定命名空间访问
int main()
{
printf("%d\n", N::a);
return 0;
}
// using将命名空间中某个成员展开
using N::b;
int main()
{
printf("%d\n", N::a);
printf("%d\n", b);
return 0;
}
// 展开命名空间中全部成员
using namespace N;
int main()
{
printf("%d\n", a);
printf("%d\n", b);
return 0;
}C++输⼊&输出
基本概念
<iostream>(Input/Output Stream)是 C++ 标准库中的输入输出流库,定义了标准输入输出对象。
主要组件
标准输入输出对象
-`std::cin`
属于 `istream` 类对象,处理窄字符(`char` 类型)的标准输入流
- `std::cout`
属于 `ostream` 类对象,处理窄字符的标准输出流操作符与函数
`<<`
流插入运算符(输出)`>>`
流提取运算符(输入)`std::endl` (推荐使用)
插入换行符并刷新缓冲区
cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
int main()
{
int a = 0;
double b = 0.1;
char c = 'x';
cout << a << " " << b << " " << c << endl;
std::cout << a << " " << b << " " << c << std::endl;
scanf("%d%lf", &a, &b);
printf("%d %lf\n", a, b);
// 可以⾃动识别变量的类型
cin >> a;
cin >> b >> c;
cout << a << endl;
cout << b << " " << c << endl;
return 0;
}
#include<iostream>
using namespace std;
int main()
{
// 在io需求⽐较⾼的地⽅,如部分⼤量输⼊的竞赛题中,加上以下3⾏代码
// 可以提⾼C++IO效率
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}C++ I/O 优势
- **类型安全** - 自动识别变量类型(通过函数重载实现)
- **扩展性强** - 完美支持自定义类型的输入输出
- **使用简便** - 无需手动指定格式说明符
命名空间注意事项
- C++ 标准库组件位于 `std` 命名空间
- 推荐用法:
cpp
std::cout << "Hello" << std::endl;- 练习时可使用:
cpp
using namespace std;- 项目开发中不建议使用 `using namespace std`
兼容性说明
在包含 `<iostream>` 后:
- VS 系列编译器可同时使用 `printf/scanf`
- 其他编译器可能需要显式包含 `<cstdio>`
缺省参数
基本概念
缺省参数(又称默认参数)是在函数声明或定义时为参数指定的默认值。调用函数时:
未提供实参:使用形参的缺省值
提供实参:使用指定的实参值
分类与规则
- 全缺省参数
cpp
void func(int a = 10, int b = 20, int c = 30) {
// ...
}- 半缺省参数
cpp
void func(int a, int b = 20, int c = 30) { // ✅正确:从右向左连续缺省
// ...
}
// void func(int a = 10, int b, int c = 30); // ❌错误:不能间隔缺省重要规则:
**半缺省必须从右向左连续缺省 **
**调用时必须从左向右依次传参**(不能跳过中间参数)
cpp
// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
// 半缺省
void Func2(int a, int b = 10, int c = 20)
int main()
{
Func1();
Func1(1);
Func1(1,2);
Func1(1,2,3);
Func2(100);
Func2(100, 200);
Func2(100, 200, 300);
return 0;
}声明与定义分离时的规则
当函数声明与定义分离时:
只能在函数声明中 指定缺省参数
定义中不能重复指定
cpp
// ✅正确示例:
// test.h
void func(int a = 10);
// test.cpp
void func(int a) { /*...*/ }
// ❌错误示例:
// test.h
void func(int a = 10);
// test.cpp
void func(int a = 10) { /*...*/ } // 重复指定缺省值使用建议
**将缺省参数放在头文件声明中**
**避免在复杂函数中使用过多缺省参数**
**注意缺省参数的求值时机**(每次调用都会重新求值)
函数重载
基本概念
函数重载(Function Overloading)是C++的重要特性之一:
- ✅允许在同一作用域内定义多个同名函数
- ✅要求各函数的形参列表必须不同(参数个数或类型)
- ❌仅返回值不同不构成重载
与C语言的对比
| C语言 | C++ | |
|---|---|---|
| 同名函数处理 | 直接报错 | 允许重载 |
| 多态支持程度 | 无 | 编译时多态 |
| 调用匹配方式 | 仅按名称 | 名称+参数类型 |
cpp
// C语言示例(报错)
void print(int a) {}
void print(float a) {} // ❌重复定义错误
// C++示例(合法)
void print(int a) {} // #1
void print(float a) {} // #2 ✅合法重载 重载规则详解
参数数量不同构成重载
cpp
2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}参数类型不同构成重载
cpp
// 1、参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}参数类型顺序不同
cpp
3、参数类型顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}不构成重载的情况
cpp
// 返回值不同不能作为重载条件,因为调⽤时也⽆法区分
//void fxx()
//{}
//
//int fxx()
//{
// return 0;
//} 最佳实践建议
-
保持语义一致性
重载函数应执行相似操作(如各种类型的print)
-
避免过度重载
超过5个重载建议改用类方法
-
注意隐式转换影响
void calc(short s) {}
void calc(long l) {}calc(10); //可能产生歧义(int→short/long)
扩展阅读:《Effective C++》条款26:尽可能延后变量定义式的出现时间
C++引用
引用的基本概念
引用(Reference)是C++特有的重要特性:
- ✅为已存在的变量创建别名(不分配新内存)
- ✅与原变量共享同一内存地址(如同人的绰号)
- ❗符号复用:使用
&表示引用(与取地址符相同)
引用语法规范
基本格式:
类型& refName = originalVar; 经典示例:
int main() {
int value = 42;
int& refValue = value; // refValue是value的别名
refValue = 100; // value的值也被修改为100
cout << value; // Output:100
return EXIT_SUCCESS;
}*引用的实际用法
代替指针,实际上就是通过给传过来的参数取别名,来直接引用那片空间,直接进行交换等操作
cpp
void Swap(int& rx, int& ry)
{
int tmp = rx;
rx = ry;
ry = tmp;
}
int main()
{
int x = 0, y = 1;
cout << x <<" " << y << endl;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}优点:函数调用的时候不用再加&.
通过引用和缺省参数可以更加的省事
cpp
void STInit(ST& rs, int n = 4)
{
rs.a = (STDataType*)malloc(n * sizeof(STDataType));
rs.top = 0;
rs.capacity = n;
}引用特性深度解析
内存模型分析:
原变量value 引用refValue
┌─────────┐ ┌─────────┐
│ 0x100 │◄─────┤ 0x100 │
├─────────┤ ├─────────┤
│ 100 │ │ │
└─────────┘ └─────────┘ 关键限制条件:
必须初始化
int& badRef; // ❌错误:未初始化引用 不能改变绑定
int a=1, b=2;
int& r=a;
r=b; // ✅赋值操作而非重新绑定
// a的值变为2,r仍绑定a 不能有空引用
int* ptr = nullptr;
int& ref = *ptr; // ❌危险行为!运行时错误 引用vs指针对比表
| 引用 | 指针 | |
|---|---|---|
| 内存开销 | 无额外开销 | 需要存储地址 |
| 初始化要求 | 必须初始化 | 可延迟初始化 |
| 可变性 | 永久绑定 | 可重新指向 |
| null检查 | 永远非空 | 可能为空 |
| 访问方式 | 自动解引用 | 需显式解引用 |
实际应用场景
这里还没有了解到,等了解到了为大家弹链接:
函数参数传递(避免拷贝)
void processBigData(BigData& data) {
//修改会影响原数据但无拷贝开销
}
BigData dataset;
processBigData(dataset);函数返回值优化
vector<int>& getCache() {
static vector<int> cache;
return cache; //避免返回时拷贝整个vector
}
auto& cache = getCache(); //直接操作原缓存 常见误区警示
-
返回局部变量引用
int& dangerousFunc() {
int local =10;
return local; // ❌局部变量销毁后引用无效!
}auto& ref = dangerousFunc(); //崩溃风险!
-
混淆引用与指针操作符
int x=5;
int* ptr=&x; // &取地址操作符
int& ref=x; // &引用声明符cout<<*ptr; // 解引用操作符
cout<<ref; //自动解引用无需 -
误用const引用
const int& r=42; // ✅合法:延长临时量生命周期
double d=3.14;
const int& cr=d; // ❗实际生成临时int变量绑定!d=4.14; // cr的值仍为3!
运行
设计哲学思考:虽然符号复用确实可能造成初学者的困惑(如&的多义性),但保持语言简洁性也是重要的设计考量。《The Design and Evolution of C++》中详细讨论了这类权衡决策
const引用的基本特性
const引用(常引用)是C++中重要的安全机制:
基本规则:
- 可以绑定到const对象或普通对象上
- 权限只能缩小不能放大("只读锁"原则)
- 临时对象自动具有const属性
语法形式:
const Type& refName = expression;权限控制原理
权限传递方向:
普通对象 ──允许─► const引用 (权限缩小)
const对象 ──禁止─►普通引用 (权限放大)
cpp
int main()
{
const int a = 10;
// 编译报错:error C2440: "初始化": ⽆法从"const int"转换为"int &"
// 这⾥的引⽤是对a访问权限的放⼤
//int& ra = a;
// 这样才可以
const int& ra = a;
// 编译报错:error C3892: "ra": 不能给常量赋值
//ra++;
// 这⾥的引⽤是对b访问权限的缩⼩
int b = 20;
const int& rb = b;
// 编译报错:error C3892: "rb": 不能给常量赋值
//rb++;
return 0;
}典型示例:
int x =10;
const int& cr1=x; // ✅允许:权限缩小
const int y=20;
int& r=y; // ❌错误:试图放大权限
const int& cr2=y; // ✅正确:权限匹配 临时对象与const引用
临时对象的本质:
编译器自动生成的未具名存储空间(具有自动const属性)
实常性 指的就是借助临时空间存储再给到变量,也就是存在临时对象(被const修饰)
正确写法:
cpp
int a=5;
int& rb=a*3; // ❌临时对象具有常性
//a*3的结果先存储在临时对象中,而用int& rb是对这个临时对象进行了引用
//说白了就是临时对象是被const修饰的空间,不能被修改
//本质就是权限的放大
double d=12.34;
int& rd=d; // ❌类型转换产生临时int
//错误类型和上面一样
const int& crb=a*3; // ✅匹配临时对象的常性
const int& crd=d; // ✅合法绑定转换后的临时int
//等效于:
const int temp=static_cast<int>(d);
const int& crd=temp; 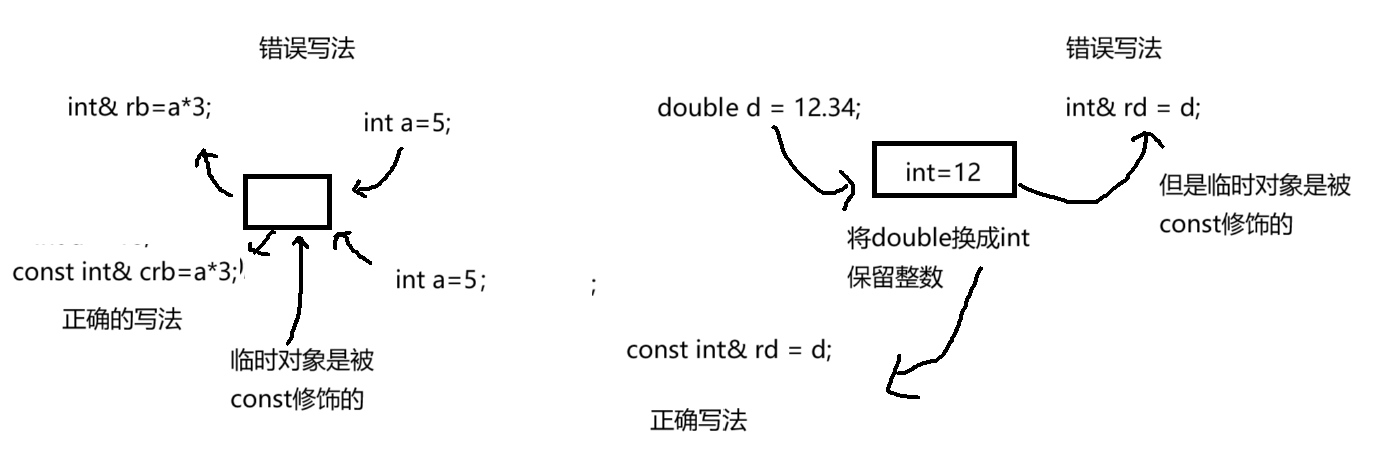
底层机制解析
临时对象的生命周期延长:
当const引用绑定到临时对象时:
表达式求值 →生成临时对象 → const引用绑定 →延长生命周期至引用作用域结束 内存模型示例:
原始表达式: const int& r = x + y;
编译器行为:
1. tmp = x + y; //生成临时变量tmp (const属性)
2. const int& r=tmp; //绑定到常引用
tmp的生命周期延长至r的作用域结束!以下博主还没了解到,等了解的时候会为大家讲解,当然有大佬可以提前为大家讲解也是相当不错的。
实际应用场景
安全传递大对象:
void process(const vector<int>& data){
//保证不会意外修改调用方数据
}
vector<int> bigData(1000000);
process(bigData); //无拷贝开销且安全
process({1,2,3}); //✅可接受临时vector 优化性能技巧:
string concat(const string& s1, const string& s2){
return s1+s2; //利用返回值优化(RVO)
}
const string& result=concat("hello","world");//延长临时string生命周期 常见误区警示
误用非const引用绑定右值
string&& rvRef=getString(); //移动语义专用语法 ✔️
string& badRef=getString();// ❌非常引用不能绑右值! 忽略隐式转换产生的临时对象
class MyInt{
public:
operator int() const{return value;}
private:
int value=42;
};
MyInt mi;
int& ri=mi; // ❌实际产生临时int!
const int& cri=mi; // ✅正确方式 滥用const_cast去除常性
const int x=10;
const int& cr=x;
int& r=const_cast<int&>(cr); //语法允许但...
r=20; //❌未定义行为!可能崩溃! 设计哲学思考:临时对象的常性是C++的重要安全机制。《Effective Modern C++》条款24专门讨论了右值引用、移动语义与临时对象的交互关系
C++指针与引用深度对比分析
兄弟关系比喻解析
指针和引用确实如同性格迥异的兄弟:
| "哥哥"指针 | "弟弟"引用 | |
|---|---|---|
| 性格特点 | 自由奔放、功能强大但容易惹祸 | 乖巧可靠、安全稳定但缺乏灵活性 |
| 诞生顺序 | 从C语言继承而来 | 由Stroustrup专为C++设计 |
| 适用场景 | 需要动态内存管理或重定向的场景 | 需要安全别名且绑定不变的场景 |
核心差异对照表
基础特性对比:
| 指针 | 引用 | |
|---|---|---|
| 内存占用 | 额外存储地址(4/8字节) | 无额外存储(纯别名) |
| 初始化要求 | 可延迟初始化 | 必须立即初始化 |
| 可变性 | 可改变指向 | 永久绑定 |
| null处理 | 可设为nullptr | 永远非空 |
| 访问方式 | 需显式解引用(*ptr) | 自动解引用 |
操作差异示例:
代码演示:
int main() {
int val =10;
/*-----指针操作-----*/
int* ptr = &val; //显式取地址
*ptr =20; //显式解引用修改
ptr = nullptr; //可改变指向
/*-----引用操作-----*/
int& ref = val; //必须初始化绑定
ref =30; //直接操作原变量
//ref = otherVal; ❌无法重新绑定
cout<<"val:"<<val<<" ref:"<<ref<<endl;
}sizeof行为差异:
32位系统示例:
sizeof(ptr) →4字节 (地址大小)
sizeof(ref) →4字节 (int大小)
64位系统示例:
sizeof(ptr) →8字节 (地址大小)
sizeof(ref) →4字节 (int大小)安全隐患对比
指针典型风险:
空指针问题:
int* p = nullptr;
*p =42; ❌运行时崩溃!野指针问题:
int* wildPtr;
*wildPtr=10; ❌未定义行为!
delete ptr; ❗ptr变成野指针!悬垂指针问题:
int* func(){
int local=10;
return &local; ❌返回局部变量地址!
}func作为局部域,出了函数就被销毁了,返回的是一个地址
相互转换关系
指针转引用(安全):
int x=10;
int* ptr=&x;
int& ref=*ptr; ✔️合法转换!引用转指针(需注意):
int& ref=x;
int* ptr=&ref; ✔️等价于取x地址!非常量引用转常量指针:
const int* cptr=&ref;// ✔️权限缩小安全!现代C+的最佳实践建议
1.优先选择引用的情况 :
-函数参数传递(避免拷贝)
-返回值优化(RVO场景)
2.必须使用指针的情况 :
-需要处理nullptr的特殊状态时
-需要动态内存管理(new/delete)时
3.混合使用策略:
void smartProcess(const BigObj* ptr){
if(ptr){ ✔️先检查空指针
const BigObj& ref=*ptr;//再转安全引用使用
ref.method();
}
}4.结合智能指针使用:
unique_ptr<int> smartPtr=make_unique<int>(42);
int& ref=*smartPtr; ✔️配合现代内存管理!📚扩展阅读:《Effective Modern C+》条款18讲智能指针与引用的配合使用,《A Tour of C+》第7章详细讨论指针与引用的设计哲学