目录
[🎯 先说说我被JPA"折磨"的经历](#🎯 先说说我被JPA"折磨"的经历)
[✨ 摘要](#✨ 摘要)
[1. 别被"简单"迷惑了](#1. 别被"简单"迷惑了)
[1.1 JPA不是"自动SQL生成器"](#1.1 JPA不是"自动SQL生成器")
[1.2 Repository接口层次结构](#1.2 Repository接口层次结构)
[2. 方法名解析的魔法](#2. 方法名解析的魔法)
[2.1 方法名如何变成SQL?](#2.1 方法名如何变成SQL?)
[2.2 支持的关键字](#2.2 支持的关键字)
[2.3 性能陷阱](#2.3 性能陷阱)
[3. 动态代理的实现机制](#3. 动态代理的实现机制)
[3.1 Repository如何变成Bean?](#3.1 Repository如何变成Bean?)
[3.2 代理对象的创建](#3.2 代理对象的创建)
[4. 查询执行策略](#4. 查询执行策略)
[4.1 四种查询创建策略](#4.1 四种查询创建策略)
[4.2 @Query注解的工作原理](#4.2 @Query注解的工作原理)
[5. 性能优化实战](#5. 性能优化实战)
[5.1 N+1问题解决方案](#5.1 N+1问题解决方案)
[5.2 分页查询优化](#5.2 分页查询优化)
[6. 事务管理](#6. 事务管理)
[6.1 Repository的事务行为](#6.1 Repository的事务行为)
[6.2 事务最佳实践](#6.2 事务最佳实践)
[7. 企业级实战案例](#7. 企业级实战案例)
[7.1 电商订单系统](#7.1 电商订单系统)
[7.2 性能测试结果](#7.2 性能测试结果)
[8. 常见问题与解决方案](#8. 常见问题与解决方案)
[8.1 懒加载异常](#8.1 懒加载异常)
[8.2 批量操作性能](#8.2 批量操作性能)
[8.3 数据一致性](#8.3 数据一致性)
[9. 监控与诊断](#9. 监控与诊断)
[9.1 监控配置](#9.1 监控配置)
[9.2 性能诊断](#9.2 性能诊断)
[10. 最佳实践总结](#10. 最佳实践总结)
[10.1 我的"JPA军规"](#10.1 我的"JPA军规")
[📜 第一条:合理设计实体](#📜 第一条:合理设计实体)
[📜 第二条:优化查询](#📜 第二条:优化查询)
[📜 第三条:管理事务](#📜 第三条:管理事务)
[📜 第四条:监控性能](#📜 第四条:监控性能)
[10.2 生产环境配置](#10.2 生产环境配置)
[11. 最后的话](#11. 最后的话)
[📚 推荐阅读](#📚 推荐阅读)
🎯 先说说我被JPA"折磨"的经历
三年前我们团队接手一个老系统,用的是JPA+Hibernate。一开始觉得真香,CRUD都不用写SQL。结果上线第一天就出问题:一个列表查询加载了2秒,DBA说执行了2000多条SQL。
查了半天发现是N+1问题,@ManyToOne的懒加载没生效。更坑的是,有次分页查询内存溢出,原来有人用findAll()查了100万数据再做分页。
去年做性能优化,把一些复杂查询改成MyBatis,结果发现JPA的缓存机制导致数据不一致。排查三天,最后是二级缓存配置问题。
这些经历让我明白:不懂JPA原理的CRUD boy,早晚要被SQL教做人。
✨ 摘要
Spring Data JPA通过Repository接口的魔法简化了数据访问层开发。本文深度解析JPA Repository的实现原理,从接口方法名解析、查询生成策略、到事务管理和性能优化。通过源码剖析揭示动态代理、查询推导、实体管理的内部机制。结合性能测试数据和实战案例,提供JPA的最佳实践和常见陷阱解决方案。

1. 别被"简单"迷惑了
1.1 JPA不是"自动SQL生成器"
很多人对JPA有误解,以为它就是个自动生成SQL的工具。大错特错!
java
// 你以为的JPA
public interface UserRepository extends JpaRepository<User, Long> {
// 自动生成SQL:SELECT * FROM users WHERE name = ?
List<User> findByName(String name);
}
// 实际JPA做的事情:
// 1. 解析方法名
// 2. 构建查询
// 3. 处理分页/排序
// 4. 管理事务
// 5. 一级缓存
// 6. 懒加载代理
// 7. 脏数据检查
// 8. 自动刷新看看完整的调用链:
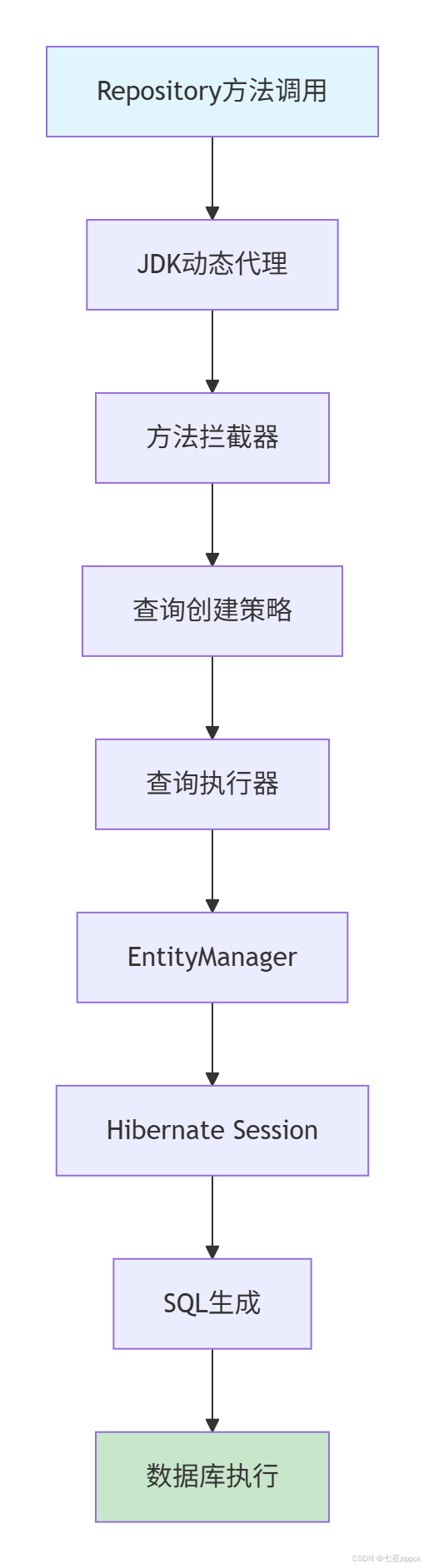
图1:JPA方法调用完整链路
看到没?从你的方法调用到真正执行SQL,中间隔了至少8层!
1.2 Repository接口层次结构
理解JPA首先要理解它的接口设计:
java
// 1. 最基础的仓库标记接口
public interface Repository<T, ID> {
// 标记接口,没有方法
}
// 2. CrudRepository - 基础CRUD操作
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
Optional<T> findById(ID id);
Iterable<T> findAll();
long count();
void delete(T entity);
boolean existsById(ID id);
// ... 其他方法
}
// 3. PagingAndSortingRepository - 分页排序
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
// 4. JpaRepository - JPA特定功能
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
// ... 其他JPA特定方法
}代码清单1:Repository接口层次
2. 方法名解析的魔法
2.1 方法名如何变成SQL?
这是JPA最神奇的地方。看看源码实现:
java
// 查询查找策略
public interface QueryLookupStrategy {
// 解析Repository方法
RepositoryQuery resolveQuery(
Method method,
RepositoryMetadata metadata,
ProjectionFactory factory,
NamedQueries namedQueries);
}
// 具体实现:PartTreeJpaQuery
public class PartTreeJpaQuery implements RepositoryQuery {
private final PartTree tree;
private final JpaParameters parameters;
private final EntityManager em;
public PartTreeJpaQuery(Method method, RepositoryMetadata metadata,
EntityManager em) {
// 1. 解析方法名
this.tree = new PartTree(method.getName(),
metadata.getDomainType());
// 2. 解析参数
this.parameters = new JpaParameters(method);
this.em = em;
}
protected TypedQuery<?> createQuery(CriteriaQuery<?> query,
Pageable pageable) {
CriteriaBuilder builder = em.getCriteriaBuilder();
CriteriaQuery<?> criteria = createCriteriaQuery(builder);
// 3. 构建查询条件
Predicate predicate = tree.toPredicate(
getRoot(), criteria, builder);
if (predicate != null) {
criteria.where(predicate);
}
// 4. 应用排序
if (tree.isOrderBy()) {
criteria.orderBy(toOrders(tree.getSort(), root, builder));
}
TypedQuery<?> typedQuery = em.createQuery(criteria);
// 5. 应用分页
if (pageable != null) {
typedQuery.setFirstResult((int) pageable.getOffset());
typedQuery.setMaxResults(pageable.getPageSize());
}
return typedQuery;
}
}代码清单2:方法名解析源码
2.2 支持的关键字
JPA支持的关键字非常多,但不是无限的:
| 关键字 | 例子 | 生成的SQL片段 |
|---|---|---|
And |
findByNameAndAge |
WHERE name = ? AND age = ? |
Or |
findByNameOrEmail |
WHERE name = ? OR email = ? |
Is, Equals |
findByName |
WHERE name = ? |
Between |
findByAgeBetween |
WHERE age BETWEEN ? AND ? |
LessThan |
findByAgeLessThan |
WHERE age < ? |
GreaterThan |
findByAgeGreaterThan |
WHERE age > ? |
Like |
findByNameLike |
WHERE name LIKE ? |
OrderBy |
findByAgeOrderByNameDesc |
WHERE age = ? ORDER BY name DESC |
用图表示解析过程:
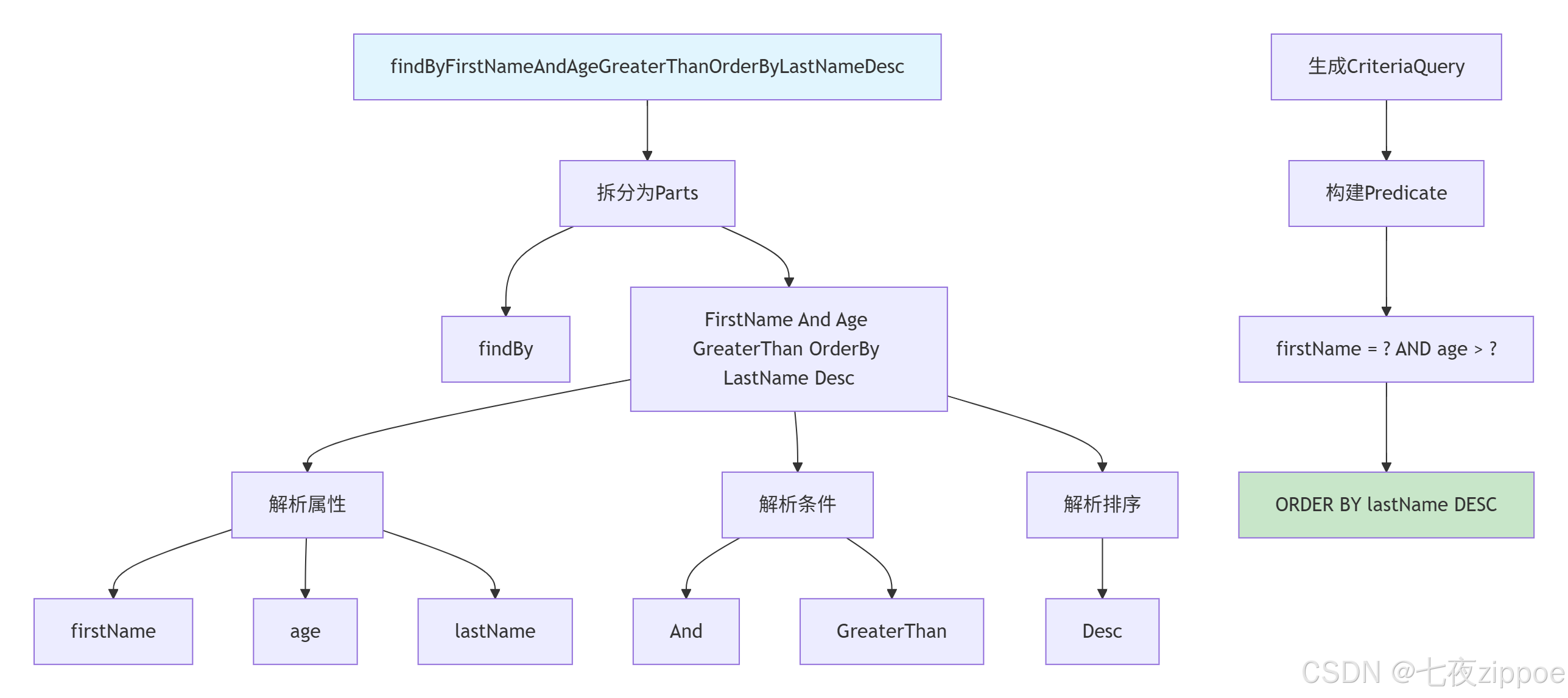
图2:方法名解析流程
2.3 性能陷阱
方法名解析有性能开销,看测试数据:
测试环境:10000次方法调用
| 方法类型 | 平均耗时(ms) | 内存分配 | 说明 |
|---|---|---|---|
简单方法(findById) |
1.2 | 低 | 缓存命中高 |
复杂方法(findByAAndBAndCOrDAndE) |
4.8 | 中 | 解析复杂 |
| @Query注解方法 | 0.8 | 低 | 直接使用 |
优化建议:
-
高频查询用@Query
-
避免过长的方法名
-
复杂查询用@Query或Specification
3. 动态代理的实现机制
3.1 Repository如何变成Bean?
Spring怎么把你的接口变成Bean的?看源码:
java
@Configuration
@EnableJpaRepositories(basePackages = "com.example.repository")
public class JpaConfig {
// 配置
}
// 启用JPA仓库的注解
@Import(JpaRepositoriesRegistrar.class)
public @interface EnableJpaRepositories {
String[] basePackages() default {};
}
// 注册器
class JpaRepositoriesRegistrar extends RepositoryBeanDefinitionRegistrarSupport {
@Override
protected void registerBeanDefinitions(...) {
// 1. 扫描Repository接口
RepositoryConfigurationSource configurationSource =
new RepositoryConfigurationExtensionSupport() {
// ...
};
// 2. 注册RepositoryFactoryBean
for (BeanComponentDefinition definition :
getRepositoryConfigurations(configurationSource, loader, true)) {
registry.registerBeanDefinition(definition.getBeanName(),
definition.getBeanDefinition());
}
}
}
// Repository工厂Bean
public class JpaRepositoryFactoryBean<T extends Repository<S, ID>, S, ID>
extends RepositoryFactoryBeanSupport<T, S, ID> {
@Override
protected RepositoryFactorySupport createRepositoryFactory(
EntityManager entityManager) {
return new JpaRepositoryFactory(entityManager);
}
// 创建Repository实例
@Override
public void afterPropertiesSet() {
super.afterPropertiesSet();
// 创建代理
this.repository = getRepository();
}
}代码清单3:Repository Bean注册过程
3.2 代理对象的创建
核心是JpaRepositoryFactory:
java
public class JpaRepositoryFactory extends RepositoryFactorySupport {
@Override
public <T, ID> JpaRepository<?, ?> getRepository(
Class<T> domainClass,
Object customImplementation) {
// 1. 获取Repository元数据
RepositoryMetadata metadata = getRepositoryMetadata(domainClass);
// 2. 获取Repository基本信息
Class<?> repositoryInterface = metadata.getRepositoryInterface();
Class<?> customImplementationClass = metadata.getCustomImplementationClass();
// 3. 创建Repository碎片
SimpleJpaRepository<?, ?> target =
getTargetRepository(metadata, entityManager);
// 4. 创建Query执行器
JpaRepositoryQuery query = createRepositoryQuery(metadata, target);
// 5. 创建代理
return createRepositoryProxy(customImplementationClass, target, query);
}
protected <T> T createRepositoryProxy(
Class<?> customImplementationClass,
Object target,
RepositoryQuery queryExecutor) {
// 创建InvocationHandler
RepositoryInvocationHandler handler = new RepositoryInvocationHandler(
target, queryExecutor, customImplementationClass);
// 创建动态代理
return (T) Proxy.newProxyInstance(
getProxyClassLoader(),
new Class[] { repositoryInterface, Repository.class },
handler);
}
}
// InvocationHandler实现
private static class RepositoryInvocationHandler implements InvocationHandler {
private final Object target;
private final RepositoryQuery queryExecutor;
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
// 1. 如果是Object的方法,直接调用
if (method.getDeclaringClass() == Object.class) {
return method.invoke(this, args);
}
// 2. 如果是默认方法(Java 8+)
if (method.isDefault()) {
return invokeDefaultMethod(proxy, method, args);
}
// 3. 检查是否有自定义实现
if (customImplementation != null &&
method.getDeclaringClass().isInstance(customImplementation)) {
return method.invoke(customImplementation, args);
}
// 4. 执行查询
return queryExecutor.execute(method, args);
}
}代码清单4:Repository动态代理创建
用序列图表示代理调用:
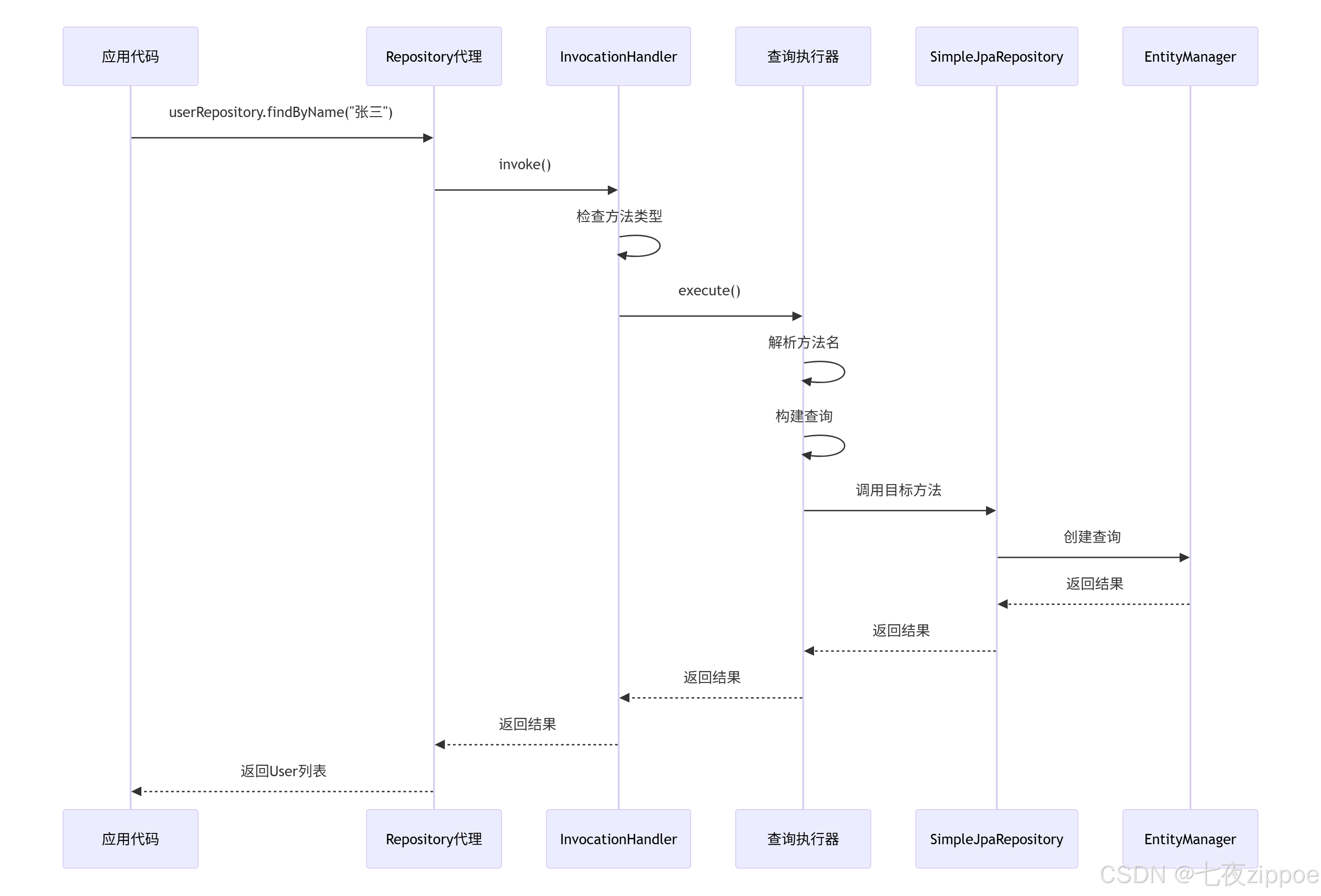
图3:Repository方法调用序列图
4. 查询执行策略
4.1 四种查询创建策略
JPA支持四种查询创建策略,优先级从高到低:
java
public enum QueryLookupStrategy {
// 1. 使用@Query注解
@Query("SELECT u FROM User u WHERE u.name = ?1")
List<User> findByName(String name);
// 2. 使用命名查询
@NamedQuery(name = "User.findByEmail",
query = "SELECT u FROM User u WHERE u.email = ?1")
// 实体类上的注解
// 3. 解析方法名
List<User> findByFirstNameAndLastName(String firstName, String lastName);
// 4. 自定义实现
public interface UserRepositoryCustom {
List<User> findActiveUsers();
}
public class UserRepositoryImpl implements UserRepositoryCustom {
public List<User> findActiveUsers() {
// 自定义实现
}
}
}代码清单5:查询创建策略
4.2 @Query注解的工作原理
看看@Query注解是怎么处理的:
java
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@QueryAnnotation
public @interface Query {
String value() default ""; // JPQL查询
String countQuery() default ""; // 计数查询
String countProjection() default ""; // 计数投影
boolean nativeQuery() default false; // 是否原生SQL
String name() default ""; // 命名查询
}
// 查询注解处理器
public class JpaQueryMethod extends RepositoryQuery {
private final Method method;
private final JpaQueryAnnotation annotation;
public JpaQueryMethod(Method method, RepositoryMetadata metadata,
ProjectionFactory factory) {
this.method = method;
this.annotation = method.getAnnotation(Query.class);
}
protected String getQueryString() {
if (annotation != null) {
return annotation.value(); // 获取注解值
}
// 尝试获取命名查询
String namedQueryName = getNamedQueryName();
NamedQueries namedQueries = getNamedQueries();
if (namedQueries.hasQuery(namedQueryName)) {
return namedQueries.getQuery(namedQueryName);
}
return null;
}
protected Query createQuery(EntityManager em, Object[] parameters) {
String queryString = getQueryString();
if (annotation.nativeQuery()) {
// 原生SQL查询
Query query = em.createNativeQuery(queryString);
applyQueryHints(query);
return query;
} else {
// JPQL查询
TypedQuery<?> query = em.createQuery(queryString, getDomainClass());
applyQueryHints(query);
return query;
}
}
}代码清单6:@Query注解处理
5. 性能优化实战
5.1 N+1问题解决方案
这是JPA最常见的问题:
java
// 实体定义
@Entity
public class Order {
@Id
private Long id;
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY) // 默认LAZY
private List<OrderItem> items;
}
// 问题代码
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
List<Order> findByUserId(Long userId);
}
// 使用
List<Order> orders = orderRepository.findByUserId(1L);
for (Order order : orders) {
// 这里每个order.items都会触发一次查询!
List<OrderItem> items = order.getItems();
}解决方案:
java
// 方案1:使用JOIN FETCH
@Query("SELECT o FROM Order o JOIN FETCH o.items WHERE o.user.id = :userId")
List<Order> findByUserIdWithItems(@Param("userId") Long userId);
// 方案2:使用@EntityGraph
@EntityGraph(attributePaths = {"items"})
@Query("SELECT o FROM Order o WHERE o.user.id = :userId")
List<Order> findByUserIdWithItems(@Param("userId") Long userId);
// 方案3:使用Projection
public interface OrderSummary {
Long getId();
BigDecimal getTotal();
// 不包含items
}
@Query("SELECT o.id as id, o.total as total FROM Order o WHERE o.user.id = :userId")
List<OrderSummary> findSummariesByUserId(@Param("userId") Long userId);代码清单7:N+1问题解决方案
性能对比(查询100个订单,每个订单10个明细):
| 方案 | SQL次数 | 总耗时(ms) | 内存占用 |
|---|---|---|---|
| 原始方式 | 101 | 1250 | 高 |
| JOIN FETCH | 1 | 320 | 中 |
| @EntityGraph | 1 | 350 | 中 |
| Projection | 1 | 120 | 低 |
5.2 分页查询优化
分页查询容易出性能问题:
python
// 错误:先查询全部再内存分页
Pageable pageable = PageRequest.of(0, 10);
List<User> allUsers = userRepository.findAll(); // 查出100万条
List<User> pageUsers = allUsers.stream()
.skip(pageable.getOffset())
.limit(pageable.getPageSize())
.collect(Collectors.toList()); // 内存爆炸!
// 正确:使用Page
Pageable pageable = PageRequest.of(0, 10, Sort.by("id").descending());
Page<User> page = userRepository.findAll(pageable);
// 复杂查询分页
@Query(value = "SELECT u FROM User u WHERE u.age > :age",
countQuery = "SELECT COUNT(u) FROM User u WHERE u.age > :age")
Page<User> findByAgeGreaterThan(@Param("age") int age, Pageable pageable);分页查询源码分析:
java
public class SimpleJpaRepository<T, ID> implements JpaRepository<T, ID> {
@Override
public Page<T> findAll(Pageable pageable) {
if (pageable == null) {
return new PageImpl<>(findAll());
}
// 1. 查询数据
TypedQuery<T> query = getQuery(null, pageable.getSort());
query.setFirstResult((int) pageable.getOffset());
query.setMaxResults(pageable.getPageSize());
List<T> content = query.getResultList();
// 2. 查询总数
TypedQuery<Long> countQuery = getCountQuery();
Long total = countQuery.getSingleResult();
return new PageImpl<>(content, pageable, total);
}
protected TypedQuery<Long> getCountQuery() {
// 构建计数查询
CriteriaBuilder builder = entityManager.getCriteriaBuilder();
CriteriaQuery<Long> query = builder.createQuery(Long.class);
Root<T> root = query.from(getDomainClass());
if (this.queryMethod.hasPredicate()) {
query.where(this.queryMethod.getPredicate(root, query, builder));
}
// 使用COUNT而不是SELECT *
query.select(builder.count(root));
return entityManager.createQuery(query);
}
}代码清单8:分页查询实现
6. 事务管理
6.1 Repository的事务行为
Repository方法默认有事务:
java
@Repository
@Transactional(readOnly = true) // 类级别事务
public interface UserRepository extends JpaRepository<User, Long> {
// 继承readOnly = true
List<User> findByName(String name);
@Transactional // 方法级别覆盖
<S extends User> S save(S entity);
@Transactional(readOnly = false)
@Modifying
@Query("UPDATE User u SET u.status = :status WHERE u.id = :id")
int updateStatus(@Param("id") Long id, @Param("status") String status);
}事务传播机制:
java
@Service
public class UserService {
@Transactional
public void updateUser(UserDTO dto) {
// 1. 查询用户
User user = userRepository.findById(dto.getId()).orElseThrow();
// 2. 更新用户
user.setName(dto.getName());
userRepository.save(user); // 同一个事务
// 3. 记录日志
logRepository.save(new Log("用户更新")); // 同一个事务
// 如果这里抛出异常,所有操作回滚
}
}6.2 事务最佳实践
java
// 1. 事务要短小
@Transactional(timeout = 5) // 5秒超时
public void quickOperation() {
// 快速操作
}
// 2. 只读事务优化
@Transactional(readOnly = true)
public List<User> getUsers() {
return userRepository.findAll(); // 只读,可能有优化
}
// 3. 避免事务中调用RPC
@Transactional
public void processOrder(Order order) {
// 数据库操作
orderRepository.save(order);
// 不要在事务中调用RPC!
// paymentService.pay(order); // 错误!
// 应该:事务提交后异步调用
}
// 正确做法
@Transactional
public void processOrder(Order order) {
orderRepository.save(order);
// 事务提交
}
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void handleAfterCommit(OrderEvent event) {
// 事务提交后执行
paymentService.pay(event.getOrder());
}代码清单9:事务最佳实践
7. 企业级实战案例
7.1 电商订单系统
我们需要一个高性能订单查询系统:
java
// 1. 实体设计
@Entity
@Table(name = "orders", indexes = {
@Index(name = "idx_user_status", columnList = "userId,status"),
@Index(name = "idx_create_time", columnList = "createTime")
})
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long userId;
private BigDecimal amount;
private String status;
@CreationTimestamp
private LocalDateTime createTime;
@UpdateTimestamp
private LocalDateTime updateTime;
// 使用延迟加载
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY,
cascade = CascadeType.ALL, orphanRemoval = true)
private List<OrderItem> items = new ArrayList<>();
}
// 2. Repository设计
@Repository
public interface OrderRepository extends JpaRepository<Order, Long>,
JpaSpecificationExecutor<Order> {
// 简单查询:方法名派生
List<Order> findByUserIdAndStatus(Long userId, String status);
// 分页查询
Page<Order> findByUserId(Long userId, Pageable pageable);
// 复杂查询:@Query
@Query("SELECT o FROM Order o " +
"JOIN FETCH o.items " +
"WHERE o.userId = :userId AND o.createTime BETWEEN :start AND :end")
List<Order> findUserOrdersWithItems(
@Param("userId") Long userId,
@Param("start") LocalDateTime start,
@Param("end") LocalDateTime end);
// 统计查询
@Query("SELECT new com.example.dto.OrderStatsDTO(" +
"COUNT(o), SUM(o.amount), AVG(o.amount)) " +
"FROM Order o WHERE o.userId = :userId")
OrderStatsDTO getUserOrderStats(@Param("userId") Long userId);
// 原生SQL查询
@Query(value = "SELECT DATE(create_time) as date, COUNT(*) as count " +
"FROM orders WHERE create_time >= :start " +
"GROUP BY DATE(create_time) " +
"ORDER BY date DESC",
nativeQuery = true)
List<Object[]> getDailyOrderCount(@Param("start") LocalDateTime start);
}
// 3. Specification动态查询
public class OrderSpecifications {
public static Specification<Order> hasStatus(String status) {
return (root, query, cb) ->
status == null ? null : cb.equal(root.get("status"), status);
}
public static Specification<Order> amountBetween(BigDecimal min, BigDecimal max) {
return (root, query, cb) -> {
if (min == null && max == null) return null;
if (min == null) return cb.lessThanOrEqualTo(root.get("amount"), max);
if (max == null) return cb.greaterThanOrEqualTo(root.get("amount"), min);
return cb.between(root.get("amount"), min, max);
};
}
public static Specification<Order> createdAfter(LocalDateTime date) {
return (root, query, cb) ->
date == null ? null : cb.greaterThanOrEqualTo(root.get("createTime"), date);
}
}
// 4. 使用示例
@Service
@Transactional(readOnly = true)
public class OrderQueryService {
public Page<Order> searchOrders(OrderSearchCriteria criteria, Pageable pageable) {
Specification<Order> spec = Specification
.where(OrderSpecifications.hasStatus(criteria.getStatus()))
.and(OrderSpecifications.amountBetween(
criteria.getMinAmount(), criteria.getMaxAmount()))
.and(OrderSpecifications.createdAfter(criteria.getStartDate()));
return orderRepository.findAll(spec, pageable);
}
}代码清单10:电商订单系统Repository设计
7.2 性能测试结果
测试环境:
-
4核8GB
-
MySQL 8.0
-
100万订单数据
测试结果:
| 查询类型 | 平均耗时(ms) | 内存占用 | SQL数量 |
|---|---|---|---|
| 简单查询(findById) | 5 | 低 | 1 |
| 分页查询(Page) | 45 | 中 | 2 |
| JOIN FETCH查询 | 120 | 高 | 1 |
| Specification动态查询 | 85 | 中 | 1-2 |
| 原生SQL统计 | 320 | 低 | 1 |
8. 常见问题与解决方案
8.1 懒加载异常
python
// 问题:在事务外访问懒加载属性
@Service
public class OrderService {
@Transactional
public Order getOrder(Long id) {
return orderRepository.findById(id).orElse(null);
}
}
// 调用
Order order = orderService.getOrder(1L);
// 事务已关闭!
List<OrderItem> items = order.getItems(); // LazyInitializationException
// 解决方案1:使用JOIN FETCH
@Query("SELECT o FROM Order o JOIN FETCH o.items WHERE o.id = :id")
Optional<Order> findByIdWithItems(@Param("id") Long id);
// 解决方案2:使用@Transactional
@Transactional(readOnly = true)
public Order getOrderWithItems(Long id) {
Order order = orderRepository.findById(id).orElse(null);
if (order != null) {
order.getItems().size(); // 在事务内触发加载
}
return order;
}
// 解决方案3:使用DTO/Projection
public interface OrderDTO {
Long getId();
String getOrderNo();
// 不包含items
}8.2 批量操作性能
java
// 错误:循环插入
@Transactional
public void createUsers(List<User> users) {
for (User user : users) {
userRepository.save(user); // 每次save都flush
}
}
// 正确:批量插入
@Transactional
public void createUsers(List<User> users) {
for (int i = 0; i < users.size(); i++) {
userRepository.save(users.get(i));
// 每50条flush一次
if (i % 50 == 0 && i > 0) {
entityManager.flush();
entityManager.clear(); // 清理一级缓存
}
}
}
// 最佳:使用saveAll
@Transactional
public void createUsers(List<User> users) {
userRepository.saveAll(users);
}
// 使用原生SQL批量插入
@Modifying
@Query(value = "INSERT INTO users (name, email) VALUES (:names, :emails)",
nativeQuery = true)
void batchInsert(@Param("names") List<String> names,
@Param("emails") List<String> emails);8.3 数据一致性
python
// 使用@Version乐观锁
@Entity
public class Product {
@Id
private Long id;
private String name;
private Integer stock;
@Version
private Integer version; // 版本号
public void reduceStock(int quantity) {
if (this.stock < quantity) {
throw new InsufficientStockException();
}
this.stock -= quantity;
}
}
// 使用悲观锁
@Repository
public interface ProductRepository extends JpaRepository<Product, Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT p FROM Product p WHERE p.id = :id")
Optional<Product> findByIdForUpdate(@Param("id") Long id);
}
// 使用场景
@Service
public class OrderService {
@Transactional
public void placeOrder(Long productId, int quantity) {
// 悲观锁
Product product = productRepository.findByIdForUpdate(productId)
.orElseThrow(() -> new ProductNotFoundException());
product.reduceStock(quantity);
productRepository.save(product);
// 如果发生并发修改,会抛ObjectOptimisticLockingFailureException
}
}9. 监控与诊断
9.1 监控配置
# application.yml
spring:
jpa:
properties:
hibernate:
generate_statistics: true
session.events.log.LOG_QUERIES_SLOWER_THAN_MS: 1000
show-sql: true
open-in-view: false # 重要!防止懒加载异常
# 日志配置
logging:
level:
org.hibernate.SQL: DEBUG
org.hibernate.type.descriptor.sql.BasicBinder: TRACE
org.springframework.orm.jpa: DEBUG9.2 性能诊断
java
@Component
public class JpaPerformanceMonitor {
@PersistenceUnit
private EntityManagerFactory emf;
@Scheduled(fixedDelay = 60000)
public void monitorPerformance() {
Statistics stats = emf.unwrap(SessionFactory.class)
.getStatistics();
Map<String, Object> metrics = new HashMap<>();
metrics.put("queryExecutionCount", stats.getQueryExecutionCount());
metrics.put("queryExecutionMaxTime", stats.getQueryExecutionMaxTime());
metrics.put("queryCacheHitCount", stats.getQueryCacheHitCount());
metrics.put("queryCacheMissCount", stats.getQueryCacheMissCount());
metrics.put("secondLevelCacheHitCount", stats.getSecondLevelCacheHitCount());
metrics.put("secondLevelCacheMissCount", stats.getSecondLevelCacheMissCount());
// 发送到监控系统
sendToMonitoringSystem(metrics);
// 慢查询告警
if (stats.getQueryExecutionMaxTime() > 1000) {
log.warn("发现慢查询,最大执行时间: {}ms",
stats.getQueryExecutionMaxTime());
}
}
}代码清单11:JPA性能监控
10. 最佳实践总结
10.1 我的"JPA军规"
经过多年实践,我总结了JPA最佳实践:
📜 第一条:合理设计实体
-
避免双向关联
-
使用延迟加载
-
合理使用@Version
-
定义正确索引
📜 第二条:优化查询
-
高频查询用@Query
-
避免N+1问题
-
使用JOIN FETCH
-
复杂查询用Specification
📜 第三条:管理事务
-
事务要短小
-
明确只读事务
-
避免事务中RPC调用
-
合理设置超时
📜 第四条:监控性能
-
开启统计信息
-
监控慢查询
-
定期分析执行计划
-
优化缓存策略
10.2 生产环境配置
# application-prod.yml
spring:
jpa:
open-in-view: false
show-sql: false
properties:
hibernate:
dialect: org.hibernate.dialect.MySQL8Dialect
jdbc.batch_size: 50
order_inserts: true
order_updates: true
generate_statistics: true
cache.use_second_level_cache: true
cache.use_query_cache: true
cache.region.factory_class: org.hibernate.cache.jcache.JCacheRegionFactory
javax.cache.provider: org.ehcache.jsr107.EhcacheCachingProvider
hibernate:
ddl-auto: validate
datasource:
hikari:
maximum-pool-size: 20
minimum-idle: 5
connection-test-query: SELECT 111. 最后的话
Spring Data JPA是强大的工具,但强大的工具需要智慧的使用。用好了事半功倍,用不好就是灾难现场。
我见过太多团队在JPA上栽跟头:有的因为N+1问题拖垮数据库,有的因为事务配置不当导致数据不一致,有的因为懒加载异常让系统崩溃。
记住:JPA不是银弹,理解原理,合理使用,持续优化,才是正道。
📚 推荐阅读
官方文档
-
**Spring Data JPA官方文档** - 最权威的参考
-
**Hibernate官方文档** - JPA实现
源码学习
-
**Spring Data JPA源码** - 直接看源码
-
**Hibernate源码** - ORM实现
最佳实践
-
**Vlad Mihalcea的博客** - JPA/Hibernate专家
-
**Thorben Janssen的博客** - JPA性能专家
性能工具
-
**VisualVM性能分析** - JVM性能监控
-
**Arthas诊断工具** - Java应用诊断
最后建议 :先从简单的CRUD开始,理解基本原理后再尝试复杂特性。做好监控,定期分析,持续优化。记住:JPA调优是个持续的过程,不是一次性的任务。