
当下,中国产业界正面临一场深刻的"数据风暴"。在智慧工厂里,数以万计的传感器每分每秒记录着设备的温度、振动与能耗;在繁华的都市中,数十万辆网联车实时回传着位置与轨迹......
这类按时间顺序产生的数据,被称为时序数据,正以前所未有的速度和规模产生,成为企业数字化转型中增长最快、价值密度最高的数字资产之一,然而传统的数据基础设施却无力应对。
市场需求的激增催生了众多时序数据库产品。然而,许多企业发现,无论是流行的开源方案还是新兴的国产专有产品,往往在关键维度存在"短板效应":有的在简单查询上表现迅捷,但无法支持跨设备、跨维度的复杂关联分析;有的写入吞吐量惊人,却因不支持标准SQL或ACID事务,导致开发与运维成本陡增;更常见的是,多数产品功能单一,仅能处理时序数据,无法与企业的地理信息(GIS)、文档图谱等既有数据资产融合,形成新的"数据孤岛"。
金仓数据库

以融合引擎重塑产品能力边界
面对市场的复合型需求,金仓数据库选择了一条差异化突围路径:不做功能单一的专用时序数据库, 而是基于其成熟稳定的企业级数据库内核,深度集成时序处理能力,构建了一个同时精通关系型事务与海量时序处理的融合数据平台。
这一设计的精妙之处在于,它让企业能够以最小的成本和风险,将现有数据库平滑升级为一个同时精通关系型事务与海量时序处理的融合平台。
对于华东某大型水务集团而言,这意味着无需颠覆沿用多年的核心业务系统,仅通过启用插件,就在数天内让原有系统具备了每秒处理百万级传感器数据的能力,且原有的财务、客户数据与实时监测数据得以在同一平台内无缝关联分析。这种"增强模式"而非"替代模式",大幅降低了企业采纳时序技术的门槛和风险。
双维对比

定义时序数据库新标准
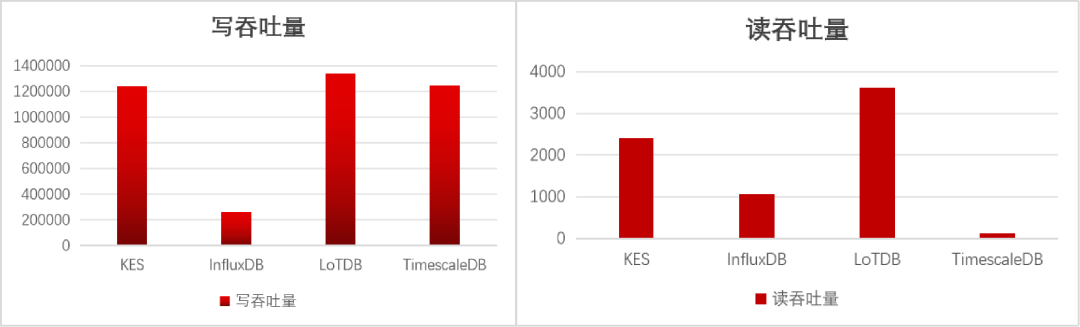
产品理念的差异,最终在性能与综合能力的硬核对比中,转化为了显著优势。在与主流时序数据库InfluxDB的同台实测中,金仓时序数据库时序能力展现出了清晰的场景化优势。
在模拟真实工业场景的TSBS基准测试中,面对"查询过去24小时内某类设备温度超过阈值且振动异常的记录"此类复杂查询,金仓时序数据库的响应速度达到InfluxDB的20倍以上。 在最为核心的写入吞吐量上,金仓单机可实现每秒千万级指标点的稳定写入,已跻身业界第一梯队。更重要的是存储效率,金仓时序数据库采用针对时序数据优化的压缩算法,在多个工业现场实测中实现了平均1:4的压缩比,部分场景下甚至高达1:40,这意味着可将存储硬件成本直接降低80%。
如果说卓越的性能是"硬实力",那么完整的产品能力则是金仓时序数据库区别于一众竞品的"软实力"。这构成了其最鲜明的护城河:
**➢ 完整的SQL与事务支持:**金仓时序数据库提供对标准SQL和ACID事务的完整支持,这使得开发人员能够使用熟悉的工具和范式,安全、便捷地实现复杂的业务逻辑,彻底避免了因使用专用查询语言或弱事务模型而带来的开发与运维复杂性。
**➢ 真正的多模融合分析:**金仓时序数据库的时序引擎与内置的GIS空间引擎、文档模型、向量计算组件原生融合。在智慧交通管理中,一条标准的SQL查询即可完成"检索过去一周内,所有在重点区域停留超时且车速模式异常的车辆"这样的时空-时序联合分析,而这在需要多个异构数据库协同的旧架构中,将是极其繁琐的过程。
**➢ 企业级生态与管控:**金仓时序数据库时序能力继承自其企业级数据库的全套生态,包括可视化的管理工具、细粒度的权限管控、与Oracle/MySQL高度兼容的语法,以及丰富的第三方工具连接性。相比之下,许多开源时序产品在企业级管控、安全审计和运维便利性上存在明显短板。
应用深化

在关键行业中验证产品价值
技术优势最终需要在场景中兑现价值。金仓时序数据库的产品力已在多个关键行业的严苛场景中得到验证:
在国家电网的数字化实践中,基于金仓时序数据库构建的用电信息采集系统,不仅要实时处理全省数千万智能电表产生的洪流数据,更需支撑精准的反窃电分析。得益于金仓时序数据库对复杂SQL和混合负载的强大支持,分析人员能直接在库内将实时电流波形数据与用户历史档案、地理信息进行即时关联与模型计算,将异常识别从"天级"缩短至"秒级",每年挽回的经济损失高达数亿元。
在高端制造领域,沪硅产业的半导体硅片生产线引入了金仓时序数据库。生产线上的蚀刻机、光刻机每毫秒都会产生海量传感数据。金仓时序数据库一方面确保了海量数据的高效写入与压缩存储,另一方面,其"时序+关系+向量"的融合能力,允许工程师在SQL中直接调用AI模型,对时序频谱进行在线故障预测,成功将预测性维护的预警窗口从小时级提前至分钟级,多次避免了重大生产中断。

定义新一代数据基座
产业的数字化转型,本质是数据驱动决策能力的升级。金仓时序数据库通过其创新的融合架构证明,卓越的时序处理能力并非必须通过牺牲数据体系的统一性、事务的严谨性或生态的丰富性来换取。它为企业提供了一条兼具性能领先、平滑演进与长期可持续性的路径:在无需推翻重建的前提下,将一个成熟的企业级数据库,升级为一个面向工业互联网时代、能够自如驾驭混合数据模型的强大基座。
在国产化替代与产业智能化交汇的历史节点,这种既能攻坚克难、又能与现有生态深度融合的产品力,或许正是破解当前产业数据困境的关键答案。

K宝推荐阅读



 供稿:数据库产品研发中心
供稿:数据库产品研发中心
编辑:格格
审核:日尧
