目录
一.日志打印宏
我们日志宏的代码都存放到这个log.hpp
封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
例如: 17.22.58 log.cpp:12打开文件失败
那么具体怎么实现呢?
那么还记得
您可以把__FILE__和__LINE__理解为两个"魔法标记",它们的作用是在编译时,由编译器自动填入当前代码所在的位置信息。
它们的具体含义如下:
- FILE
- 它是什么:它是一个字符串常量。
- 它代表什么:它代表了**当前源代码文件的完整路径名或文件名。**编译器在处理这行代码时,会将它替换成当前源文件的名字。例如,如果你的文件叫做 main.c,那么 FILE 就会被替换为 "main.c"。在某些编译环境中,它可能会包含完整的文件路径,如 "D:/project/src/main.c"。
- LINE
- 它是什么:它是一个整数常量。
- 它代表什么:它代表了**当前代码在源文件中的行号。**编译器会将它替换成一个数字,这个数字就是这行代码(即 LINE 这行本身)在文件中的具体行数。如果你把这段代码移动到文件的第50行,那么 LINE 的值在下次编译时就会变成50。
cpp
#include<iostream>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
printf("[%s:%d] Hello World!\n",__FILE__,__LINE__);
}
可以看到。还是很不错的
但是还有一个系统事件呢!这个怎么搞?
我们需要学习一些新的东西
1. time() 函数 - 获取时间戳
cpp
time_t t = time(nullptr);作用:
- time() 函数返回从 1970年1月1日00:00:00 UTC(Unix纪元)到当前时间的秒数
- 这个秒数被称为 "时间戳" 或 "Unix时间戳"
- time_t 是一个整数类型(通常是 long int),用于存储这个秒数
参数:
- nullptr(或 NULL)表示我们不需要将时间戳存储到额外的地方
- 如果传入一个 time_t 类型变量的地址,函数也会把时间戳写入那个地址
类比:
想象一个从1970年1月1日开始计时的巨大秒表,time() 就是按下秒表查看当前累积秒数的按钮。
2. localtime() 函数 - 转换成本地时间结构
cpp
struct tm* ptm = localtime(&t);作用:
- 将 time() 得到的秒数(时间戳)转换成本地时间的各个组成部分
- 返回一个指向 tm 结构体的指针,这个结构体包含了年、月、日、时、分、秒等各个字段
tm 结构体包含的字段:
- tm_sec - 秒 (0-59)
- tm_min - 分 (0-59)
- tm_hour - 时 (0-23)
- tm_mday - 一个月中的第几天 (1-31)
- tm_mon - 月 (0-11,0代表1月)
- tm_year - 年(从1900年开始的年数,2023年就是123)
- tm_wday - 一周中的第几天 (0-6,0代表周日)
- tm_yday - 一年中的第几天 (0-365)
- tm_isdst - 夏令时标志
重要注意事项:
- localtime() 返回的是指向静态内存区域的指针,这意味着:
- 每次调用 localtime() 都会覆盖上次的结果
- 不需要手动释放这个指针指向的内存
如果需要保存结果,应该复制结构体的内容,而不是直接保存指针
3. strftime() 函数 - 格式化时间字符串
cpp
strftime(time_str, 31, "%H:%M:%S", ptm);作用:
将 tm 结构体中的时间信息按照指定的格式字符串格式化成可读的字符串
参数详解:
- time_str:目标字符数组,用于存放格式化后的字符串
- 31:最多写入的字符数(包括结尾的空字符\0)
- "%H:%M:%S":格式控制字符串
ptm:指向 tm 结构体的指针
常用格式说明符:
- %H:24小时制的小时 (00-23)
- %I:12小时制的小时 (01-12)
- %M:分钟 (00-59)
- %S:秒 (00-59)
- %p:AM/PM 指示符
- %Y:4位数的年份
- %y:2位数的年份
- %m:月份 (01-12)
- %d:日 (01-31)
- %A:完整的星期几名称
- %a:缩写的星期几名称
- %B:完整的月份名称
- %b或%h:缩写的月份名称
示例格式:
- "%Y-%m-%d %H:%M:%S" → "2023-12-25 14:30:45"
- "%a %b %d %H:%M:%S %Y" → "Mon Dec 25 14:30:45 2023"
我们就能写出下面这个
cpp
#include<iostream>
#include<ctime>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
time_t t=time(nullptr);
struct tm* ptm=localtime(&t);
char time_str[32];
strftime(time_str,31,"%H:%M:%S",ptm);
printf("[%s][%s:%d] Hello World!\n",time_str,__FILE__,__LINE__);
}
但是我们不能每次调用的时候都写这么多代码吧
那么我们就需要将它封装成宏函数
此外,我们还需要了解一些宏函数相关的知识
在 C/C++ 中,宏函数必须定义在一行内,或者通过反斜杠(\)进行换行连接。
cpp
// ✅ 正确的多行写法(使用反斜杠续行)
#define COMPLEX_MACRO(a, b, c) do { \
int result = (a) + (b); \
if (result > (c)) { \
printf("Too big: %d\n", result); \
} else { \
printf("OK: %d\n", result); \
} \
} while(0)
// 这样子写也行,但是可读性极其差劲
#define COMPLEX_MACRO_ONE_LINE(a, b, c) do { int result = (a) + (b); if (result > (c)) { printf("Too big: %d\n", result); } else { printf("OK: %d\n", result); } } while(0)C99标准引入了不定参数宏,允许宏接受可变数量的参数。语法类似于可变参数函数,使用 ... 表示可变参数部分,并在替换部分使用 VA_ARGS 来引用这些参数。
cpp
#define PRINT(...) printf(__VA_ARGS__)
int main() {
PRINT("Hello, %s!\n", "world");
PRINT("Number: %d\n", 42);
return 0;
}注意:在C语言中,字符串常量相邻会自动连接成一个字符串
因为format是一个字符串参数,在预处理时,它会被替换成用户传入的字符串,然后与周围的字符串连接,形成一个完整的格式字符串。
cpp
#define LOG(format, ...) printf("[%s:%d] " format "\n", __FILE__, __LINE__, __VA_ARGS__)
// 使用示例
int x = 42;
LOG("Value: %d", x);
cpp
// 宏展开后的代码:
printf("[%s:%d] " "Value: %d" "\n", __FILE__, __LINE__, x);
// 编译器会处理为:
printf("[%s:%d] Value: %d\n", __FILE__, __LINE__, x);现在我们就去封装我们的日志打印宏
cpp
#define INF 0
#define DBG 1
#define ERR 2
#define LOG_LEVEL DBG
#define LOG(level, format, ...) do{\
if (level < LOG_LEVEL) break;\
time_t t = time(NULL);\
struct tm *ltm = localtime(&t);\
char tmp[32] = {0};\
strftime(tmp, 31, "%H:%M:%S", ltm);\
fprintf(stdout, "[%p %s %s:%d] " format "\n", (void*)pthread_self(), tmp, __FILE__, __LINE__, __VA_ARGS__);\
}while(0)但是现在还有一个问题。
如果说我传递的是只是两个参数进去
cpp
LOG(DEBUG_LEVEL,"hello World");那么宏函数的不定参数就会报错啊。
上面的LOG宏定义中,format 和 ... 是分开的,这样调用时就需要至少两个参数(level和format),然后可变参数至少一个(因为__VA_ARGS__至少需要一个参数)。
- 使用C99标准中的__VA_ARGS__,并确保在调用时至少提供一个参数(但这样就不能完全省略可变参数)。
- 使用##VA_ARGS(GCC扩展),这样当可变参数为空时,就没有一点问题。
如果你希望允许可变参数为空,则需要使用**##VA_ARGS**。
cpp
#define INF 0
#define DBG 1
#define ERR 2
#define LOG_LEVEL DBG
#define LOG(level, format, ...) do{\
if (level < LOG_LEVEL) break;\
time_t t = time(NULL);\
struct tm *ltm = localtime(&t);\
char tmp[32] = {0};\
strftime(tmp, 31, "%H:%M:%S", ltm);\
fprintf(stdout, "[%p %s %s:%d] " format "\n", (void*)pthread_self(), tmp, __FILE__, __LINE__, ##__VA_ARGS__);\
}while(0)这样子编译就不会报错了。
同时,我们为了使用方便,我们根据日志等价将这个日志打印宏封装好了三个接口
cpp
#pragma once
#include <iostream>
#define INF 0
#define DBG 1
#define ERR 2
#define LOG_LEVEL DBG
#define LOG(level, format, ...) do{\
if (level < LOG_LEVEL) break;\
time_t t = time(NULL);\
struct tm *ltm = localtime(&t);\
char tmp[32] = {0};\
strftime(tmp, 31, "%H:%M:%S", ltm);\
fprintf(stdout, "[%p %s %s:%d] " format "\n", (void*)pthread_self(), tmp, __FILE__, __LINE__, ##__VA_ARGS__);\
}while(0)
#define INF_LOG(format, ...) LOG(INF, format, ##__VA_ARGS__)
#define DBG_LOG(format, ...) LOG(DBG, format, ##__VA_ARGS__)
#define ERR_LOG(format, ...) LOG(ERR, format, ##__VA_ARGS__)测试代码
cpp
// 最简单的使用方式
int main() {
// 使用简化宏,只需要传递一个字符串(两个参数:宏本身+字符串)
DBG_LOG("这是一个简单的调试消息");
INF_LOG("这是一个信息消息");
ERR_LOG("这是一个错误消息");
// 带参数的用法
int x = 10, y = 20;
DBG_LOG("x = %d, y = %d", x, y);
return 0;
}
注意:最前面这一坨是线程ID.
二.Buffer模块设计
1.1.功能回顾
Buffer模块实现了一个高效的用户态缓冲区,作为通信连接的接收与发送数据的中转站。其核心设计目标是通过减少系统调用的次数来提升I/O效率,同时解决TCP流式传输中常见的"粘包"与"半包"问题。
Buffer模块内部维护了一块预分配的连续内存空间,通过精心设计的读写指针机制来管理数据的存储与读取。这种结构不仅使得数据的追加和移除操作非常高效,还避免了频繁的内存分配与释放带来的性能开销。
接收数据(读操作)处理流程
当从socket读取数据时,并不直接将数据交给上层应用处理,而是先将数据存入Buffer的接收缓冲区中。
这样的设计带来了显著的优势:即使一次读取的数据量不足以构成一个完整的应用层数据包,这些数据也可以安全地暂存在Buffer中,等待后续数据的到达。
智能数据包重组机制:Buffer模块与协议解析器紧密配合,能够智能处理数据包的边界问题。
其工作流程如下:
-
数据暂存 :每次socket可读事件触发时,都会将新到达的数据追加到Buffer接收缓冲区的末尾。
-
完整性检查:上层应用可以随时检查Buffer中是否包含完整的数据包。这通常通过协议定义的特定方式实现(如长度字段、分隔符或自定义的验证逻辑)。
-
数据提取:当检测到至少一个完整数据包时,Buffer会将这个完整的数据包从缓冲区中提取出来,交付给上层应用处理,同时从缓冲区中移除已处理的数据。
-
等待拼接:如果当前缓冲区中的数据不足以构成完整数据包,Buffer会保留这些"半包"数据,等待下一次数据到达。新数据会被追加到现有数据之后,然后再次尝试完整性检查,形成新旧数据的无缝拼接。
这种机制确保了无论数据包如何被TCP流分割,应用层都能获得完整、正确的消息单元,极大地简化了上层协议的实现复杂度。
发送数据(写操作)优化策略
在数据发送方面,Buffer模块同样扮演着关键角色。如果直接将数据通过send系统调用发送,当内核发送缓冲区已满时,调用线程可能会被阻塞,直到缓冲区有足够的空间。这种阻塞行为会严重影响服务器的并发性能和响应能力。
Buffer模块通过发送缓冲区提供了优雅的解决方案:
-
异步发送队列 :**当上层应用需要发送数据时,并不直接调用
send,而是将数据先写入Buffer的发送缓冲区。**这个缓冲区充当了一个待发送数据的队列。 -
事件驱动发送:Buffer模块与EventLoop的事件监控机制协同工作。当数据被写入发送缓冲区后,会启用对应socket的写事件监控。只有当socket真正可写(内核发送缓冲区有空闲空间)时,才会触发写回调函数。
-
智能发送调度 :在写事件回调中,Buffer会尝试将发送缓冲区中的数据通过
send系统调用发送出去。如果一次无法发送全部数据,剩余数据会保留在发送缓冲区中,等待下一次可写事件的到来。 -
流量控制:Buffer模块还能与TCP的拥塞控制机制良好配合。当网络拥塞导致发送缓慢时,Buffer会自动暂存待发送数据,避免应用层频繁尝试发送而浪费CPU资源。
1.2.设计
缓冲区设计思想:
内存管理:
缓冲区使用一块连续的内存空间来存储数据。这块内存空间是动态分配的,可以根据需要自动扩容。我们这里使用vector<char>来充当这块连续的内存空间。
空间划分:
通过两个关键位置指针来管理缓冲区:
-
读取位置指针:标记当前可以从哪个位置开始读取数据
-
写入位置指针:标记当前可以在哪个位置开始写入新数据
这两个指针将缓冲区划分为三个逻辑区域:已读取区域(可被覆盖)、待读取区域(有效数据)、空闲区域(可写入新数据)。
- a. 已读区域:从内存起始位置到读位置之前(不包括读位置)的区域,这部分数据已经被读取,可以被后续写入覆盖。
- b. 未读区域:从读位置到写位置之间的区域,这部分数据已经写入但尚未被读取。
- c. 空闲区域:从写位置到内存空间末尾的区域,这部分空间尚未使用。

- 写入操作流程
当需要向缓冲区写入数据时,系统会按照以下逻辑执行:
第一步:确定写入起始点
系统总是从写入位置指针所指向的位置开始写入新数据,这保证了数据的顺序性。
第二步:空间检查与处理
写入前必须确保有足够的空闲空间,系统会进行智能的空间管理:
-
情况一:如果写入位置指针后面的空闲空间足够,直接在该区域写入
-
情况二:如果后面空间不足,但前面有可回收空间(已被读取的数据空间),系统会将现有的有效数据整体移动到缓冲区起始位置,腾出连续的大块空间
-
情况三:如果总空闲空间不足,系统会自动扩容,增加缓冲区总容量
第三步:更新指针位置
数据成功写入后,写入位置指针会相应向后移动,指向下一次写入的起始位置。
- 读取操作流程
当从缓冲区读取数据时,遵循以下规则:
第一步:可读性验证
系统首先检查是否有数据可读,可读数据量为写入位置指针减去读取位置指针的差值。只有当这个值大于0时才允许读取操作。
第二步:数据读取
从读取位置指针指向的位置开始,按照请求的数据量进行读取。系统会确保读取的数据是连续且完整的。
第三步:指针更新
数据成功读取后,读取位置指针会向后移动,标记这些数据已被消费,相应的空间可被后续写入操作重用。
3.操作总览
这是一个环形缓冲区类的完整功能描述列表:
-
初始化函数:创建缓冲区对象时,将读写位置指针都设置为起始位置,并为内部存储区域分配默认大小的空间。
-
获取起始地址函数:返回缓冲区内部存储区域的第一个位置的地址。
-
获取写入位置地址函数:返回缓冲区中下一个数据写入操作应该开始的位置的地址。
-
获取读取位置地址函数:返回缓冲区中下一个数据读取操作应该开始的位置的地址。
-
计算尾部空闲空间函数:计算从当前写入位置到缓冲区末尾之间的空闲空间大小。
-
计算头部空闲空间函数:计算从缓冲区起始位置到当前读取位置之间的空闲空间大小。
-
计算可读数据大小函数:计算缓冲区中已经写入但尚未被读取的数据总量。
-
移动读取位置函数:将读取位置指针向后移动指定长度,表示已经读取了相应长度的数据。
-
移动写入位置函数:将写入位置指针向后移动指定长度,表示已经写入了相应长度的数据。
-
确保写入空间函数:检查缓冲区是否有足够空间写入指定长度的数据,如果空间不足则进行数据移动或缓冲区扩容操作。
-
写入数据函数:将外部数据拷贝到缓冲区的当前写入位置,但不更新写入位置指针。
-
写入数据并更新位置函数:将外部数据拷贝到缓冲区,然后自动更新写入位置指针。
-
写入字符串函数:将字符串数据拷贝到缓冲区的当前写入位置,但不更新写入位置指针。
-
写入字符串并更新位置函数:将字符串数据拷贝到缓冲区,然后自动更新写入位置指针。
-
写入另一缓冲区数据函数:将另一个缓冲区中可读取的数据拷贝到当前缓冲区,但不更新写入位置指针。
-
写入另一缓冲区数据并更新位置函数:将另一个缓冲区中可读取的数据拷贝到当前缓冲区,然后自动更新写入位置指针。
-
读取数据函数:将缓冲区中指定长度的数据拷贝到外部缓冲区,但不更新读取位置指针。
-
读取数据并更新位置函数:将缓冲区中指定长度的数据拷贝到外部缓冲区,然后自动更新读取位置指针。
-
以字符串形式读取数据函数:将缓冲区中指定长度的数据转换为字符串返回,但不更新读取位置指针。
-
以字符串形式读取并更新位置函数:将缓冲区中指定长度的数据转换为字符串返回,然后自动更新读取位置指针。
-
查找换行符函数:在缓冲区的可读数据范围内搜索换行符的位置。
-
获取一行数据函数:从当前读取位置开始,读取直到第一个换行符(包括换行符)的所有数据,但不更新读取位置指针。
-
获取一行并更新位置函数:从当前读取位置开始,读取直到第一个换行符(包括换行符)的所有数据,然后自动更新读取位置指针。
-
清空缓冲区函数:将读写位置指针都重置为起始位置,逻辑上清空所有数据,但保留已分配的内存空间。
按照需求,我们很快就能写出下面这个框架
cpp
// 定义缓冲区的默认大小
#define BUFFER_DEFAULT_SIZE 1024
// 这是一个环形缓冲区实现类,用于高效管理数据读写操作
class Buffer {
private:
std::vector<char> _buffer; // 使用vector进行动态内存空间管理,存储实际数据
uint64_t _reader_idx; // 读偏移,表示下一个读取操作应该开始的位置
uint64_t _writer_idx; // 写偏移,表示下一个写入操作应该开始的位置
public:
// 构造函数:初始化读写偏移为0,并预分配默认大小的缓冲区空间
Buffer();
// 获取缓冲区的起始地址:返回内部vector的第一个元素的地址
char *Begin();
// 获取当前写入起始地址:缓冲区起始地址 + 写偏移量
char *WritePosition();
// 获取当前读取起始地址:缓冲区起始地址 + 读偏移量
char *ReadPosition();
// 获取缓冲区末尾空闲空间大小:计算写偏移之后到缓冲区末尾的空闲空间
uint64_t TailIdleSize();
// 获取缓冲区起始空闲空间大小:计算缓冲区起始位置到读偏移之间的空闲空间
uint64_t HeadIdleSize();
// 获取可读数据大小:计算写偏移减去读偏移,即已写入但尚未读取的数据量
uint64_t ReadAbleSize();
// 将读偏移向后移动指定长度:表示已读取指定长度的数据,更新读位置
void MoveReadOffset(uint64_t len);
// 将写偏移向后移动指定长度:表示已写入指定长度的数据,更新写位置
void MoveWriteOffset(uint64_t len);
// 确保可写空间足够:检查是否有足够空间写入指定长度的数据,不够则处理
void EnsureWriteSpace(uint64_t len);
// 写入数据:将外部数据拷贝到缓冲区,但不更新写偏移
void Write(const void *data, uint64_t len);
// 写入数据并移动写偏移:写入数据后自动更新写偏移
void WriteAndPush(const void *data, uint64_t len);
// 写入字符串:将字符串数据拷贝到缓冲区,但不更新写偏移
void WriteString(const std::string &data);
// 写入字符串并移动写偏移:写入字符串后自动更新写偏移
void WriteStringAndPush(const std::string &data);
// 写入另一个缓冲区的数据:将另一个缓冲区的可读数据拷贝到当前缓冲区
void WriteBuffer(Buffer &data);
// 写入另一个缓冲区的数据并移动写偏移:写入后自动更新写偏移
void WriteBufferAndPush(Buffer &data);
// 读取数据:将缓冲区的数据拷贝到外部缓冲区,但不更新读偏移
void Read(void *buf, uint64_t len);
// 读取数据并移动读偏移:读取数据后自动更新读偏移
void ReadAndPop(void *buf, uint64_t len);
// 以字符串形式读取指定长度的数据:读取数据并转换为字符串,不更新读偏移
std::string ReadAsString(uint64_t len);
// 以字符串形式读取数据并移动读偏移:读取后自动更新读偏移
std::string ReadAsStringAndPop(uint64_t len);
// 查找CRLF位置:在可读数据中搜索换行符,用于按行读取
char *FindCRLF();
/*
通常获取一行数据,这种情况针对是按行读取
*/
// 获取一行数据:从当前读取位置读取到第一个换行符(包含换行符)
std::string GetLine();
// 获取一行数据并移动读偏移:读取一行后自动更新读偏移
std::string GetLineAndPop();
// 清空缓冲区:重置读写偏移,逻辑上清空但保留内存空间
void Clear();
};三.Buffer代码实现
3.1.代码总览
我们把代码放到这个buffer.hpp里面
cpp
#pragma once
#include"log.hpp"
#include <iostream>
#include <vector>
#include <string>
#include <cassert>
#include <cstring>
#include <ctime>
#include <functional>
#include <unordered_map>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <memory>
#include <typeinfo>
#include <fcntl.h>
#include <signal.h>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/socket.h>
#include <sys/epoll.h>
#include <sys/eventfd.h>
#include <sys/timerfd.h>
// 定义缓冲区的默认大小
#define BUFFER_DEFAULT_SIZE 1024
// 这是一个环形缓冲区实现类,用于高效管理数据读写操作
class Buffer
{
private:
std::vector<char> _buffer; // 使用vector进行动态内存空间管理,存储实际数据
uint64_t _reader_idx; // 读偏移,表示下一个读取操作应该开始的位置
uint64_t _writer_idx; // 写偏移,表示下一个写入操作应该开始的位置
public:
// 构造函数:初始化读写偏移为0,并预分配默认大小的缓冲区空间
Buffer() : _reader_idx(0), _writer_idx(0), _buffer(BUFFER_DEFAULT_SIZE) {}
// 获取缓冲区的起始地址:返回内部vector的第一个元素的地址
char *Begin()
{
// _buffer.begin() 返回一个迭代器(iterator),指向vector的第一个元素。
// *_buffer.begin() 解引用这个迭代器,得到第一个元素的引用(即char&)。
// &*_buffer.begin() 取得这个引用的地址,即得到指向第一个元素的指针(char*)。
return &*_buffer.begin();
}
// 获取当前写入起始地址:缓冲区起始地址 + 写偏移量
char *WritePosition()
{
return Begin() + _writer_idx;
}
// 获取当前读取起始地址:缓冲区起始地址 + 读偏移量
char *ReadPosition()
{
return Begin() + _reader_idx;
}
// 获取缓冲区末尾空闲空间大小:计算写偏移之后到缓冲区末尾的空闲空间
uint64_t TailIdleSize()
{
return _buffer.size() - _writer_idx;
}
// 获取缓冲区起始空闲空间大小:计算缓冲区起始位置到读偏移之间的空闲空间
uint64_t HeadIdleSize()
{
return _reader_idx;
}
// 获取可读数据大小:计算写偏移减去读偏移,即已写入但尚未读取的数据量
uint64_t ReadAbleSize()
{
return _writer_idx - _reader_idx;
}
// 将读偏移向后移动指定长度:表示已读取指定长度的数据,更新读位置
void MoveReadOffset(uint64_t len)
{
if (len == 0)
return; // 如果移动长度为0,直接返回不执行任何操作
// 向后移动的大小,必须小于或等于可读数据大小,否则越界
assert(len <= ReadAbleSize());
_reader_idx += len; // 更新读偏移
}
// 将写偏移向后移动指定长度:表示已写入指定长度的数据,更新写位置
void MoveWriteOffset(uint64_t len)
{
// 向后移动的大小,必须小于或等于尾部空闲空间大小,否则越界
assert(len <= TailIdleSize());
_writer_idx += len; // 更新写偏移
}
// 确保可写空间足够:检查是否有足够空间写入指定长度的数据,不够则处理
void EnsureWriteSpace(uint64_t len)
{
// 如果尾部空闲空间大小足够,直接返回,不需要额外操作
if (TailIdleSize() >= len)
{
return;
}
// 尾部空闲空间不够,判断加上起始位置的空闲空间大小是否足够
if (len <= TailIdleSize() + HeadIdleSize())
{
// 总体空闲空间足够,将数据移动到起始位置以腾出连续空间
uint64_t rsz = ReadAbleSize(); // 保存当前可读数据大小
// 把可读数据拷贝到起始位置,覆盖已被读取的区域
std::copy(ReadPosition(), ReadPosition() + rsz, Begin());
_reader_idx = 0; // 将读偏移归0,因为数据现在从起始位置开始
_writer_idx = rsz; // 将写偏移设置为可读数据大小
}
else
{
// 总体空间不够,则需要扩容,不移动数据,直接扩展缓冲区大小
DBG_LOG("RESIZE %ld", _writer_idx + len); // 记录调试信息
_buffer.resize(_writer_idx + len); // 调整缓冲区大小为所需大小
}
}
// 写入数据:将外部数据拷贝到缓冲区,但不更新写偏移
void Write(const void *data, uint64_t len)
{
// 1. 保证有足够空间,2. 拷贝数据进去
if (len == 0)
return; // 如果数据长度为0,直接返回
EnsureWriteSpace(len); // 确保缓冲区有足够空间
const char *d = (const char *)data; // 将数据指针转换为char*类型
std::copy(d, d + len, WritePosition()); // 拷贝数据到写入位置
}
// 写入数据并移动写偏移:写入数据后自动更新写偏移
void WriteAndPush(const void *data, uint64_t len)
{
Write(data, len); // 先写入数据
MoveWriteOffset(len); // 然后移动写偏移
}
// 写入string字符串:将字符串数据拷贝到缓冲区,但不更新写偏移
void WriteString(const std::string &data)
{
return Write(data.c_str(), data.size()); // 将string转换为字符数组并写入
}
// 写入string字符串并移动写偏移:写入字符串后自动更新写偏移
void WriteStringAndPush(const std::string &data)
{
WriteString(data); // 写入字符串
MoveWriteOffset(data.size()); // 根据字符串长度移动写偏移
}
// 写入另一个缓冲区Buffer的数据:将另一个缓冲区的可读数据拷贝到当前缓冲区
void WriteBuffer(Buffer &data)
{
return Write(data.ReadPosition(), data.ReadAbleSize()); // 写入可读数据
}
// 写入另一个缓冲区Buffer的数据并移动写偏移:写入后自动更新写偏移
void WriteBufferAndPush(Buffer &data)
{
WriteBuffer(data); // 写入缓冲区数据
MoveWriteOffset(data.ReadAbleSize()); // 根据写入的数据量移动写偏移
}
// 读取数据:将缓冲区的数据拷贝到外部缓冲区,但不更新读偏移
void Read(void *buf, uint64_t len)
{
// 要求要获取的数据大小必须小于或等于可读数据大小
assert(len <= ReadAbleSize());
std::copy(ReadPosition(), ReadPosition() + len, (char *)buf); // 拷贝数据到目标缓冲区buf
}
// 读取数据并移动读偏移:读取数据后自动更新读偏移
void ReadAndPop(void *buf, uint64_t len)
{
Read(buf, len); // 先读取数据
MoveReadOffset(len); // 然后移动读偏移
}
// 以字符串string形式读取指定长度的数据:读取数据并转换为字符串,不更新读偏移
std::string ReadAsString(uint64_t len)
{
// 要求要获取的数据大小必须小于或等于可读数据大小
assert(len <= ReadAbleSize());
std::string str; // 创建字符串对象
str.resize(len); // 预分配字符串空间
Read(&str[0], len); // 读取数据到字符串中
return str; // 返回字符串
}
// 以字符串string形式读取数据并移动读偏移:读取后自动更新读偏移
std::string ReadAsStringAndPop(uint64_t len)
{
assert(len <= ReadAbleSize()); // 检查长度是否合法
std::string str = ReadAsString(len); // 读取数据为字符串
MoveReadOffset(len); // 移动读偏移
return str; // 返回字符串
}
// 查找CRLF位置:在可读数据中搜索换行符,用于按行读取
char *FindCRLF()
{
// 从读取位置开始查找换行符,搜索范围为可读数据大小
char *res = (char *)memchr(ReadPosition(), '\n', ReadAbleSize());
return res; // 返回找到的位置,如果没有找到返回NULL
}
//通常获取一行数据,这种情况针对是按行读取
// 获取一行数据:从当前读取位置读取到第一个换行符(包含换行符)
std::string GetLine()
{
char *pos = FindCRLF(); // 查找换行符位置
if (pos == NULL)
{
return ""; // 未找到换行符,返回空字符串
}
// +1是为了把换行字符也取出来,计算从当前位置到换行符的长度
return ReadAsString(pos - ReadPosition() + 1);
}
// 获取一行数据并移动读偏移:读取一行后自动更新读偏移
std::string GetLineAndPop()
{
std::string str = GetLine(); // 获取一行数据
MoveReadOffset(str.size()); // 根据读取的数据长度移动读偏移
return str; // 返回读取的行
}
// 清空缓冲区:重置读写偏移,逻辑上清空但保留内存空间
void Clear()
{
// 只需要将偏移量归0即可,实际数据留在内存中但会被后续写入覆盖
_reader_idx = 0;
_writer_idx = 0;
}
};3.2.代码实现细节
3.2.1.细节一
cpp
// 获取缓冲区的起始地址:返回内部vector的第一个元素的地址
char *Begin()
{
return &*_buffer.begin();
}这是一个经典的获取vector内部数据指针的写法。
让我们分解一下:
- _buffer.begin() 返回一个迭代器(iterator),指向vector的第一个元素。
- *_buffer.begin() 解引用这个迭代器,得到第一个元素的引用(即char&)。
- &*_buffer.begin() 取得这个引用的地址,即得到指向第一个元素的指针(char*)。
为什么不能直接使用 _buffer.data() 呢?
在C++11及以后,vector提供了data()成员函数,它返回指向底层数组的指针。所以,在C++11中,我们可以直接使用_buffer.data()来获取指针。
但是,注意:这里的代码可能是在C++11之前编写的,或者为了兼容没有data()方法的旧版本。另外,即使有data(),使用迭代器的方式也是通用的。
另外,注意:_buffer是std::vector<char>类型,它的元素是char,所以begin()返回的是std::vector<char>::iterator,解引用后得到char,然后取地址得到char*。
但是,这里有一个潜在的问题:如果vector为空,_buffer.begin()返回的迭代器等于end(),那么解引用它是未定义行为。因此,在调用Begin()之前,必须确保缓冲区不为空。然而,在构造函数中,我们使用_buffer(BUFFER_DEFAULT_SIZE)进行了初始化,所以缓冲区大小至少为BUFFER_DEFAULT_SIZE(非零),因此这里调用是安全的。
3.2.2.细节二
cpp
// 获取当前写入起始地址:缓冲区起始地址 + 写偏移量
char *WritePosition()
{
return Begin() + _writer_idx;
}我们知道Begin()返回的是char*,而这个_writer_idx又是一个uint_64,两者相加等于啥??
这就需要去复习一下指针运算了!!
cpp
// 假设在内存中的布局(每个int占4字节):
// 地址: 0x1000 0x1004 0x1008 0x100C 0x1010
// 数据: numbers[0] numbers[1] numbers[2] numbers[3] numbers[4]
// 值: 10 20 30 40 50
int *p = numbers; // p = 0x1000
// 指针加1不是加1个字节!
p = p + 1; // p 现在指向 0x1004,不是 0x1001!
// 实际上:0x1000 + 1 * sizeof(int) = 0x1000 + 4 = 0x1004我们看个例子就明白了
cpp
char chars[5]; // 每个char占1字节
int ints[5]; // 每个int通常占4字节
double doubles[5]; // 每个double通常占8字节
char *pc = chars;
int *pi = ints;
double *pd = doubles;
pc = pc + 1; // 地址加 1 字节
pi = pi + 1; // 地址加 4 字节
pd = pd + 1; // 地址加 8 字节char类型的特点:char 在C/C++中定义为1字节。这是标准规定的。
指针算术的自动缩放:
- 当对 char* 指针加一个整数 N 时,编译器会自动计算:新地址 = 原地址 + N × sizeof(char)
- 因为 sizeof(char) = 1,所以实际计算简化为:新地址 = 原地址 + N
所以Begin() + _writer_idx;返回的就是真实的地址
3.2.3.细节三
cpp
std::copy(first, last, d_first);这是·一个专门用于复制数据的
- first: 源范围的起始位置(迭代器)
- last: 源范围的结束位置(迭代器)
- d_first: 目标范围的起始位置(迭代器)
也就是说将[first,last)的数据复制到d_first位置上去
注意范围是半开区间 [first, last)
- 包含first指向的元素
- 不包含last指向的元素
- 所以实际复制的是从first到last-1的元素
示例1
cpp
#include <algorithm>
#include <vector>
#include <iostream>
int main() {
std::vector<int> src = {1, 2, 3, 4, 5, 6, 7, 8};
std::vector<int> dst(4); // 预先分配空间
// 复制src中的前4个元素到dst
std::copy(src.begin(), src.begin() + 4, dst.begin());
// 输出结果
for (int val : dst) {
std::cout << val << " "; // 输出: 1 2 3 4
}
return 0;
}
示例2
cpp
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
std::vector<int> result(10, 0); // 10个元素,都初始化为0
// 从第3个位置开始复制(索引2)
std::copy(data.begin(), data.end(), result.begin() + 2);
std::cout << "复制后的结果:";
for (int num : result) {
std::cout << num << " "; // 输出:0 0 1 2 3 4 5 0 0 0
}
return 0;
}
3.2.4.细节四
cpp
// 查找CRLF位置:在可读数据中搜索换行符,用于按行读取
char *FindCRLF()
{
// 从读取位置开始查找换行符,搜索范围为可读数据大小
char *res = (char *)memchr(ReadPosition(), '\n', ReadAbleSize());
return res; // 返回找到的位置,如果没有找到返回NULL
}我们注意到这里使用了memchr函数
memchr 是 C 标准库中的一个函数,用于在内存块中搜索特定字符。它位于 <cstring> 头文件中(C++中)或 <string.h>(C中)。
函数原型:
cpp
void* memchr(const void* ptr, int ch, size_t count);参数:
- ptr:指向要搜索的内存块的指针。
- ch:要搜索的字符(以 int 形式传递,但会被转换为 unsigned char)。
- count:要搜索的字节数。
返回值:
- 如果找到字符,则返回指向该字符的指针。
- 如果未找到,则返回空指针(nullptr)。
工作原理:
memchr 从 ptr 开始的位置,逐字节地搜索,直到找到字符 ch 或搜索完 count 个字节。
注意:
- 搜索是以字节为单位,因此通常用于搜索内存块中的某个字节值。
- 字符 ch 会被转换为 unsigned char,因此即使传入负数,也会被当作 0~255 的范围。
示例1
cpp
#include <iostream>
#include <cstring>
int main() {
const char* str = "Hello, World!";
char target = 'W';
// 搜索字符 'W'
const char* result = static_cast<const char*>(memchr(str, target, strlen(str)));
if (result != nullptr) {
std::cout << "找到字符 '" << target << "' 在位置: " << (result - str) << std::endl;
std::cout << "从该位置开始的字符串: " << result << std::endl; // 输出: World!
} else {
std::cout << "未找到字符 '" << target << "'" << std::endl;
}
return 0;
}
实例2
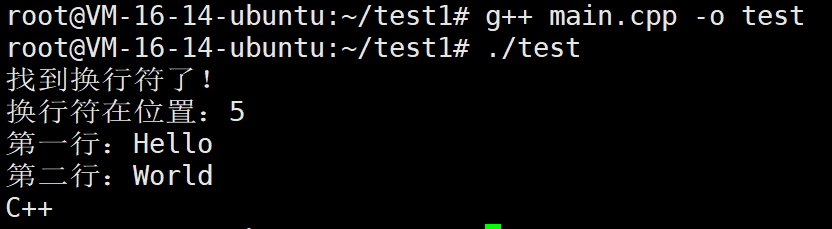
cpp
#include <iostream>
#include <cstring>
int main() {
const char* text = "Hello\nWorld\nC++";
// 找第一个换行符
const char* pos = static_cast<const char*>(memchr(text, '\n', strlen(text)));
if (pos != nullptr) {
std::cout << "找到换行符了!\n";
std::cout << "换行符在位置:" << (pos - text) << "\n";
// 显示第一行
std::cout << "第一行:";
for (int i = 0; text[i] != '\n'; i++) {
std::cout << text[i];
}
std::cout << "\n";
// 显示第二行
std::cout << "第二行:" << (pos + 1) << "\n";
} else {
std::cout << "没有换行符\n";
}
return 0;
}
3.2.5.细节五
cpp
// 以字符串string形式读取指定长度的数据:读取数据并转换为字符串,不更新读偏移
std::string ReadAsString(uint64_t len)
{
// 要求要获取的数据大小必须小于或等于可读数据大小
assert(len <= ReadAbleSize());
std::string str; // 创建字符串对象
str.resize(len); // 预分配字符串空间
Read(&str[0], len); // 读取数据到字符串中
return str; // 返回字符串
}我们这里为什么使用
cpp
Read(&str[0], len); // 读取数据到字符串中这里为什么使用&str0来表示数组地址
- std::string 本质上是一个字符数组的封装
- 在内存中,它存储一个 char 数组(就像 char str\[\])
- 通过 str0 可以访问第一个字符
- &str0 获取这个字符的地址(也就是整个字符串缓冲区的起始地址)
为什么不直接传递str进去?
- str 是一个 std::string 对象,不是字符指针
- Read() 函数需要一个指向内存缓冲区的指针(地址)
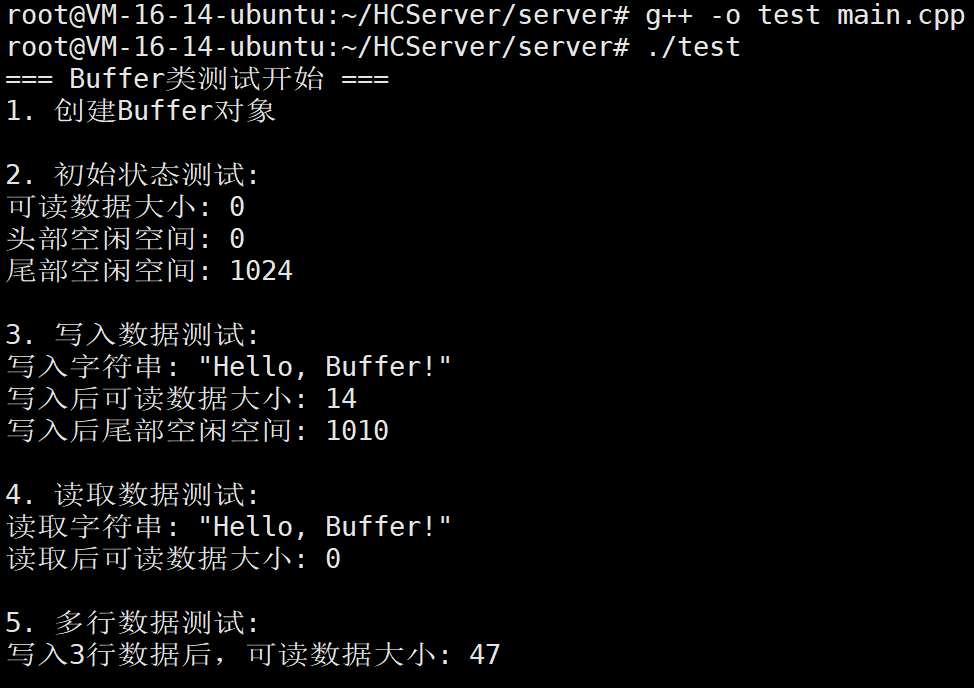
3.3.代码测试
cpp
#include <iostream>
#include "Buffer.hpp"
int main() {
std::cout << "=== Buffer类测试开始 ===" << std::endl;
// 1. 创建Buffer对象
Buffer buf;
std::cout << "1. 创建Buffer对象" << std::endl;
// 2. 测试基本属性
std::cout << "\n2. 初始状态测试:" << std::endl;
std::cout << "可读数据大小: " << buf.ReadAbleSize() << std::endl;
std::cout << "头部空闲空间: " << buf.HeadIdleSize() << std::endl;
std::cout << "尾部空闲空间: " << buf.TailIdleSize() << std::endl;
// 3. 测试写入数据
std::cout << "\n3. 写入数据测试:" << std::endl;
std::string test_str = "Hello, Buffer!";
buf.WriteStringAndPush(test_str);
std::cout << "写入字符串: \"" << test_str << "\"" << std::endl;
std::cout << "写入后可读数据大小: " << buf.ReadAbleSize() << std::endl;
std::cout << "写入后尾部空闲空间: " << buf.TailIdleSize() << std::endl;
// 4. 测试读取数据
std::cout << "\n4. 读取数据测试:" << std::endl;
std::string read_str = buf.ReadAsStringAndPop(test_str.size());
std::cout << "读取字符串: \"" << read_str << "\"" << std::endl;
std::cout << "读取后可读数据大小: " << buf.ReadAbleSize() << std::endl;
// 5. 测试多行数据
std::cout << "\n5. 多行数据测试:" << std::endl;
std::string line1 = "这是第一行\n";
std::string line2 = "这是第二行\n";
std::string line3 = "这是第三行";
buf.WriteStringAndPush(line1);
buf.WriteStringAndPush(line2);
buf.WriteStringAndPush(line3);
std::cout << "写入3行数据后,可读数据大小: " << buf.ReadAbleSize() << std::endl;
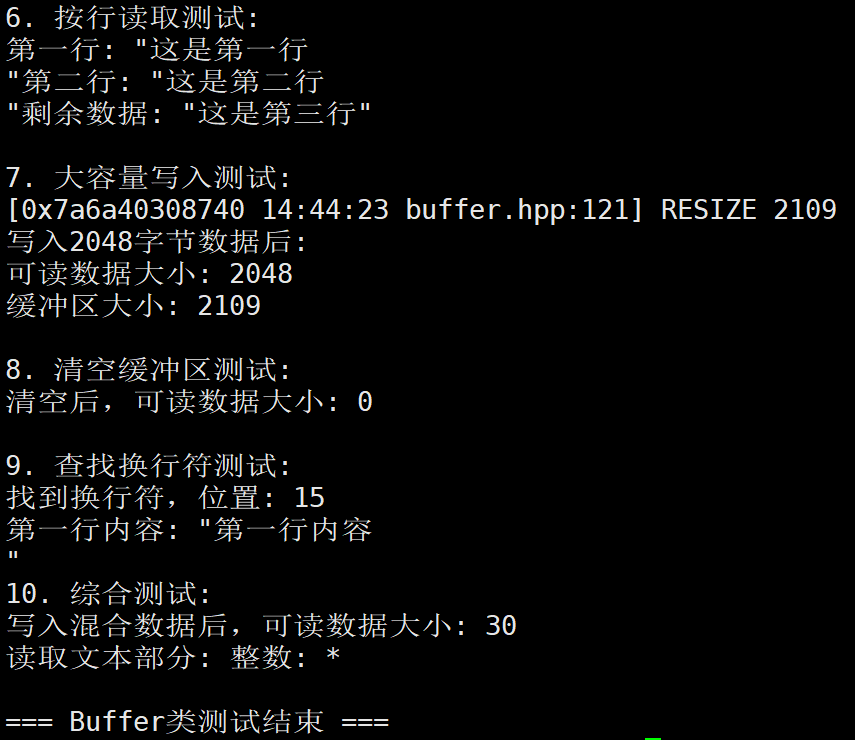
// 6. 测试按行读取
std::cout << "\n6. 按行读取测试:" << std::endl;
std::cout << "第一行: \"" << buf.GetLineAndPop() << "\"";
std::cout << "第二行: \"" << buf.GetLineAndPop() << "\"";
std::cout << "剩余数据: \"" << buf.ReadAsStringAndPop(buf.ReadAbleSize()) << "\"" << std::endl;
// 7. 测试大容量写入和缓冲区自动调整
std::cout << "\n7. 大容量写入测试:" << std::endl;
std::string large_data(2048, 'X'); // 创建2048个'X'的字符串
buf.WriteStringAndPush(large_data);
std::cout << "写入2048字节数据后:" << std::endl;
std::cout << "可读数据大小: " << buf.ReadAbleSize() << std::endl;
std::cout << "缓冲区大小: " << buf.ReadAbleSize() + buf.HeadIdleSize() + buf.TailIdleSize() << std::endl;
// 8. 测试清空缓冲区
std::cout << "\n8. 清空缓冲区测试:" << std::endl;
buf.Clear();
std::cout << "清空后,可读数据大小: " << buf.ReadAbleSize() << std::endl;
// 9. 测试查找功能
std::cout << "\n9. 查找换行符测试:" << std::endl;
std::string text = "第一行内容\n第二行内容\n";
buf.WriteStringAndPush(text);
char* crlf_pos = buf.FindCRLF();
if (crlf_pos) {
std::cout << "找到换行符,位置: " << (crlf_pos - buf.ReadPosition()) << std::endl;
std::cout << "第一行内容: \"" << buf.GetLineAndPop() << "\"";
} else {
std::cout << "未找到换行符" << std::endl;
}
// 10. 综合测试
std::cout << "\n10. 综合测试:" << std::endl;
buf.Clear();
// 写入不同类型的数据
buf.WriteStringAndPush("整数: ");
int num = 42;
buf.WriteAndPush(&num, sizeof(num));
buf.WriteStringAndPush(",浮点数: ");
float pi = 3.14f;
buf.WriteAndPush(&pi, sizeof(pi));
std::cout << "写入混合数据后,可读数据大小: " << buf.ReadAbleSize() << std::endl;
// 读取并显示
std::string str_part = buf.ReadAsStringAndPop(13); // "整数: " + 4字节整数
std::cout << "读取文本部分: " << str_part << std::endl;
std::cout << "\n=== Buffer类测试结束 ===" << std::endl;
return 0;
}