EXPLAIN:用实体摘要为RAG"开外挂",让文档问答又快又准
一句话总结:EXPLAIN通过自动提取文档中的关键实体并生成摘要,用这些"知识浓缩胶囊"替换低相关性的文档片段,在保持低推理成本的同时大幅提升RAG问答的准确性和全面性。
📖 论文信息
- 标题:EXPLAIN: Enhancing Retrieval-Augmented Generation with Entity Summary
- 作者:Yaozhen Liang, Xiao Liu, Jiajun Yu (浙江大学), Zhouhua Fang, Qunsheng Zou, Linghan Zheng, Yong Li, Zhiwei Liu (蚂蚁集团), Haishuai Wang (浙江大学)
- 发表:ACL 2025 Industry Track
- 机构:浙江大学 & 蚂蚁集团
🎯 研究背景:RAG面临的核心挑战
从一个实际问题说起
假设你在使用企业内部的文档问答系统,问了一个问题:"MISSA模型的作者是谁,它主要解决什么问题?"
传统RAG系统会这样处理:
- 把你的问题转成向量
- 在文档库中找到语义最相似的几个片段
- 把这些片段喂给大模型生成答案
问题来了:关于"MISSA"的信息可能分散在文档的不同位置------第一段介绍了它是什么,第三段提到了作者,第七段讲了应用场景。如果检索只返回了其中一两个片段,答案必然不完整。
这就是RAG系统面临的信息碎片化问题------文档被切成小块后,一个实体的完整信息被打散了。
RAG vs 长上下文:成本与效果的两难
| 方法 | 优势 | 劣势 |
|---|---|---|
| RAG(检索增强生成) | Token消耗少,推理成本低 | 检索片段有限,可能丢失关键信息 |
| 长上下文(Long Context) | 信息完整,准确率高 | Token消耗大,推理成本高昂 |
论文中的实验数据很直观:RAG平均消耗约4200 tokens,而长上下文方案需要10000+ tokens。在企业级应用中,这意味着2.5倍以上的API成本差异。
但有趣的是,论文实验发现长上下文在某些场景下反而表现更差(HotpotQA上47.75 vs RAG的56.70)。原因是当文档中包含大量干扰信息时,大模型反而会被误导。
EXPLAIN要解决的核心问题是:如何在保持RAG低成本优势的同时,弥补信息碎片化带来的准确率损失?
传统RAG的三个痛点
-
信息碎片化:文档被切成小块后,实体的完整信息分散在多个片段中。比如一篇介绍GPT-4的文章,可能第一段讲架构、第三段讲训练数据、第五段讲性能评测------单独检索任何一个片段都不完整。
-
检索盲区:向量检索基于语义相似度,但有些重要信息虽然与问题相关,却在语义上不直接匹配。比如问"谁发明了Transformer",但文档中写的是"Vaswani等人在2017年提出了Attention is All You Need"------如果没有检索到这个片段,就会漏掉关键信息。
-
上下文污染:检索到的片段中往往包含大量无关信息。研究表明,RAG检索到的片段中,真正与答案相关的内容可能只占30%左右,其余都是"噪声"。

图1:EXPLAIN方法的整体框架。整个流程分为两个阶段:离线阶段 (左侧)完成实体提取与摘要生成,在线阶段(右侧)进行摘要检索与增强RAG。以"MISSA"实体为例,系统首先从文档片段中提取实体,生成结构化摘要(如"MISSA refers to Multiple Intents and Semantic Slots Annotation Neural Network..."),然后在问答时将高相关性的实体摘要与文档片段混合排序,用摘要替换低分片段,最终输入LLM生成答案。
🧠 核心方法:EXPLAIN的四步流程
EXPLAIN的全称是 EXtracting, Pre-summarizing, Linking and enhAcINg RAG,即"提取、预摘要、链接、增强RAG"。
第一步:实体提取(Entity Extraction)
目标:从文档中提取所有可能有用的实体名词。
为什么不用传统NER?
传统的命名实体识别(NER)只能识别预定义的类型:人名、地名、组织名等。但在实际文档问答中,用户可能问到任何专业术语、产品名称、技术概念。比如"MISSA"、"Transformer"、"BGE-M3"这些在传统NER看来都不是"实体"。
EXPLAIN采用了更通用的策略:直接提取名词短语。
技术实现:
- 使用spaCy的
en_core_web_sm(英文)和zh_core_web_sm(中文)进行句法分析 - 提取完整的名词短语(noun chunks)作为实体
- 建立双向索引:
Context2Entity(ci) = Ei:每个文档片段包含哪些实体Entity2Context(ej) = {ck}:每个实体出现在哪些片段中
python
# 伪代码示例
import spacy
nlp = spacy.load("en_core_web_sm")
def extract_entities(document_chunks):
context2entity = {}
entity2context = {}
for chunk in document_chunks:
doc = nlp(chunk)
# 提取所有名词短语
entities = [nc.text for nc in doc.noun_chunks]
context2entity[chunk] = entities
for entity in entities:
if entity not in entity2context:
entity2context[entity] = []
entity2context[entity].append(chunk)
return context2entity, entity2context这个设计的精妙之处:虽然名词短语提取会引入一些噪声(比如"the system"、"this method"这类无意义的短语),但消融实验表明,这种"宁可多提、不可漏提"的策略反而效果更好。原因是:
- 噪声实体的摘要在检索时自然会被低分过滤掉
- 但漏提的重要实体则永远无法被检索到
第二步:实体链接(Entity Linking)
问题:同一个实体在文档中可能以不同形式出现。
比如:
- "GPT-4"、"GPT4"、"gpt-4"、"GPT 4"
- "Large Language Model"、"LLM"、"大语言模型"
如果不做链接,这些会被当作不同实体,导致信息分散。
解决方案:基于n-gram Jaccard相似度的实体链接。
核心公式:
J(e1,e2)=∣N(e1,n)∩N(e2,n)∣∣N(e1,n)∪N(e2,n)∣J(e_1, e_2) = \frac{|N(e_1, n) \cap N(e_2, n)|}{|N(e_1, n) \cup N(e_2, n)|}J(e1,e2)=∣N(e1,n)∪N(e2,n)∣∣N(e1,n)∩N(e2,n)∣
其中 N(e,n)N(e, n)N(e,n) 表示从实体名称提取的n-gram集合。
直观理解:把两个实体名称都拆成字符级别的n-gram,看它们的重叠程度。比如"GPT-4"和"GPT4"的2-gram集合高度重叠,Jaccard相似度会很高。
算法实现:使用Union-Find(并查集)数据结构高效合并相似实体。
算法:基于Jaccard相似度的实体链接
输入:实体名称列表,相似度阈值T=0.7
输出:链接后的实体组
1. 初始化:每个实体为独立的组
2. 初始化Union-Find数据结构
3. for 每对实体 (ei, ej):
4. 计算 J(ei, ej)
5. if J(ei, ej) > T:
6. UF.Union(ei, ej)
7. 返回 Union-Find 形成的组实际效果:在阈值T=0.7时,实体链接减少了约5.86%的实体数量。虽然数量减少不多,但主要价值在于:
- 合并后的实体能聚合更多上下文信息
- 减少了下游摘要生成的计算开销
第三步:实体摘要生成(Entity Summarization)
这是EXPLAIN最核心的创新!
对于每个实体(或链接后的实体组),收集所有包含它的文档片段,然后用LLM生成结构化摘要。
关键设计:生成多个独立的摘要项,而非一个聚合摘要
这是论文中最重要的设计决策之一。Prompt设计如下:
你的主要任务是总结给定术语在提供的上下文中的用法和意义。
对于摘要中的每一项:
1. 首先用引号引用原文中最相关的句子
2. 然后提供简洁的摘要解释该术语的用法或意义
3. 确保每个摘要项都是独立完整的,可以单独理解
4. 使用'\n'分隔不同的摘要项
上下文信息如下:<CONTEXT>
请总结术语'<ENTITY NAME>'的用法和意义。为什么要生成多个独立摘要项?
消融实验给出了明确答案:
| 摘要策略 | HotpotQA F1 | 2WikiMQA F1 |
|---|---|---|
| 独立摘要项(默认) | 60.33 | 62.78 |
| 聚合成单个摘要 | 51.67 | 59.49 |
聚合摘要会导致性能大幅下降!原因是:
- 聚合摘要把所有信息混在一起,检索时要么全部命中、要么全部错过
- 独立摘要项可以精准匹配------问题只需要实体的某个方面时,只检索到那个摘要项即可
一个具体例子:
对于实体"MISSA",可能生成以下独立摘要项:
1. "MISSA refers to Multiple Intents and Semantic Slots Annotation Neural Network" - MISSA是一个用于多意图和语义槽标注的神经网络模型。
2. "MISSA was proposed by Zhang et al. in 2021" - MISSA由Zhang等人在2021年提出。
3. "MISSA achieves state-of-the-art performance on intent detection tasks" - MISSA在意图检测任务上达到了最先进的性能。当用户问"MISSA是什么"时,第1条摘要会被高分检索到;问"MISSA的作者是谁"时,第2条会被检索到。这种细粒度匹配是EXPLAIN性能提升的关键。
第四步:摘要增强检索(Entity Summary Enhanced RAG)
在线推理阶段的核心流程:
-
双路检索:同时从两个索引库检索
- 文档片段索引(传统RAG)
- 实体摘要索引(EXPLAIN新增)
-
统一重排序:用Reranker对所有候选项(片段+摘要)按与问题的相关性统一排序
-
智能替换:用高相关性的实体摘要替换低相关性的文档片段
-
参数控制:
maxEntSumm:最大检索的实体摘要数量maxChunkRepl:最多可替换的文档片段数量
为什么是"替换"而非"追加"?
这是一个很巧妙的设计。如果只是追加摘要,会增加上下文长度和Token消耗。而替换策略:
- 用高信息密度的摘要(平均35 tokens)替换低相关性的片段(平均110 tokens)
- 不仅提供了更精准的信息,还减少了Token消耗
🧪 实验评估
数据集
| 数据集 | 类型 | 语言 | 评估指标 | 特点 |
|---|---|---|---|---|
| HotpotQA | 多跳问答 | 英文 | F1 | 需要跨文档推理,2跳问题 |
| 2WikiMQA | 多跳问答 | 英文 | F1 | 更复杂的2-5跳问题 |
| QuALITY | 阅读理解 | 英文 | EM | 长文档多选题 |
| Internal QA | 企业问答 | 中文 | ROUGE-L | 蚂蚁集团真实HR/金融场景 |
主要结果
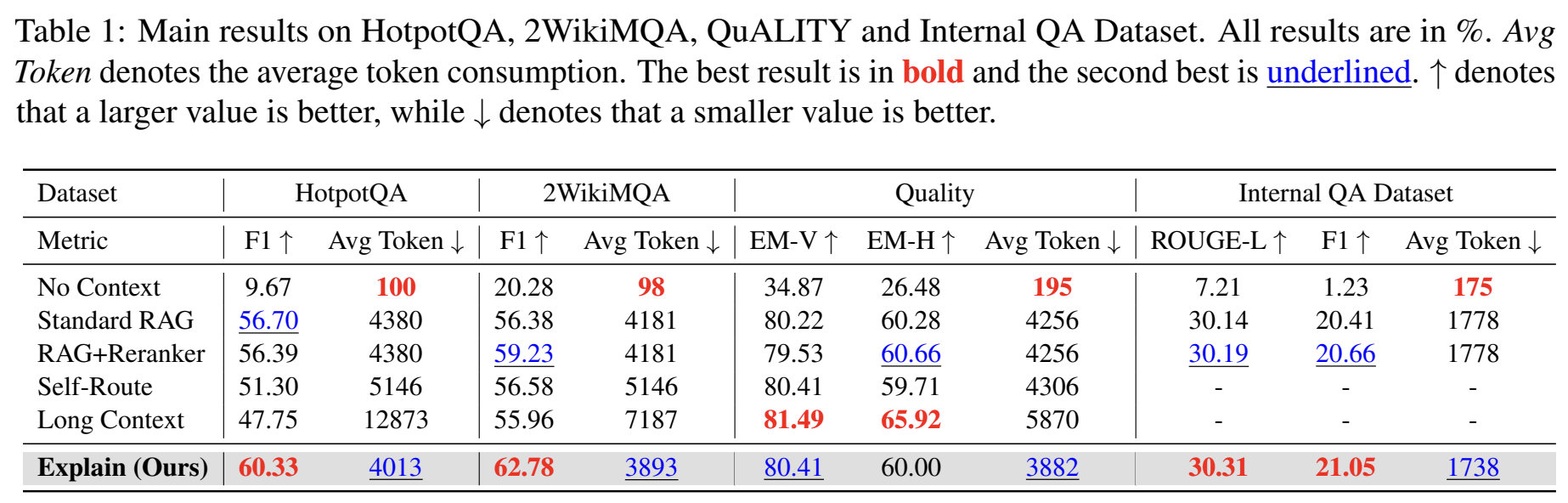
表1:EXPLAIN在HotpotQA、2WikiMQA、QuALITY和Internal QA Dataset上的主要实验结果。Avg Token表示平均Token消耗,↑表示越大越好,↓表示越小越好。最佳结果加粗,次佳结果下划线标注。
从上表可以清晰看到各方法的性能对比:
| 方法 | HotpotQA F1 | 2WikiMQA F1 | QuALITY EM-V | Internal ROUGE-L | 平均Token |
|---|---|---|---|---|---|
| No Context | 9.67 | 20.28 | 34.87 | 7.21 | ~100 |
| Standard RAG | 56.70 | 56.38 | 80.22 | 30.14 | ~4200 |
| RAG+Reranker | 56.39 | 59.23 | 79.53 | 30.19 | ~4200 |
| Long Context | 47.75 | 55.96 | 81.49 | - | ~10000 |
| EXPLAIN | 60.33 | 62.78 | 80.41 | 30.31 | ~3900 |
关键发现:
-
多跳问答显著提升 :在HotpotQA和2WikiMQA上,EXPLAIN比RAG+Reranker分别提升3.94和3.55个F1点。这说明实体摘要对于需要整合多处信息的问题特别有效。
-
Token消耗反而更低:EXPLAIN平均减少约135 tokens(从4200降到3900),同时提升准确率。这是"替换"策略带来的额外收益。
-
长上下文的意外表现:Long Context在HotpotQA上只有47.75,远低于RAG方案。原因是HotpotQA数据集中包含大量干扰文档,长上下文把这些噪声也全部输入了模型。
效率-准确率权衡分析
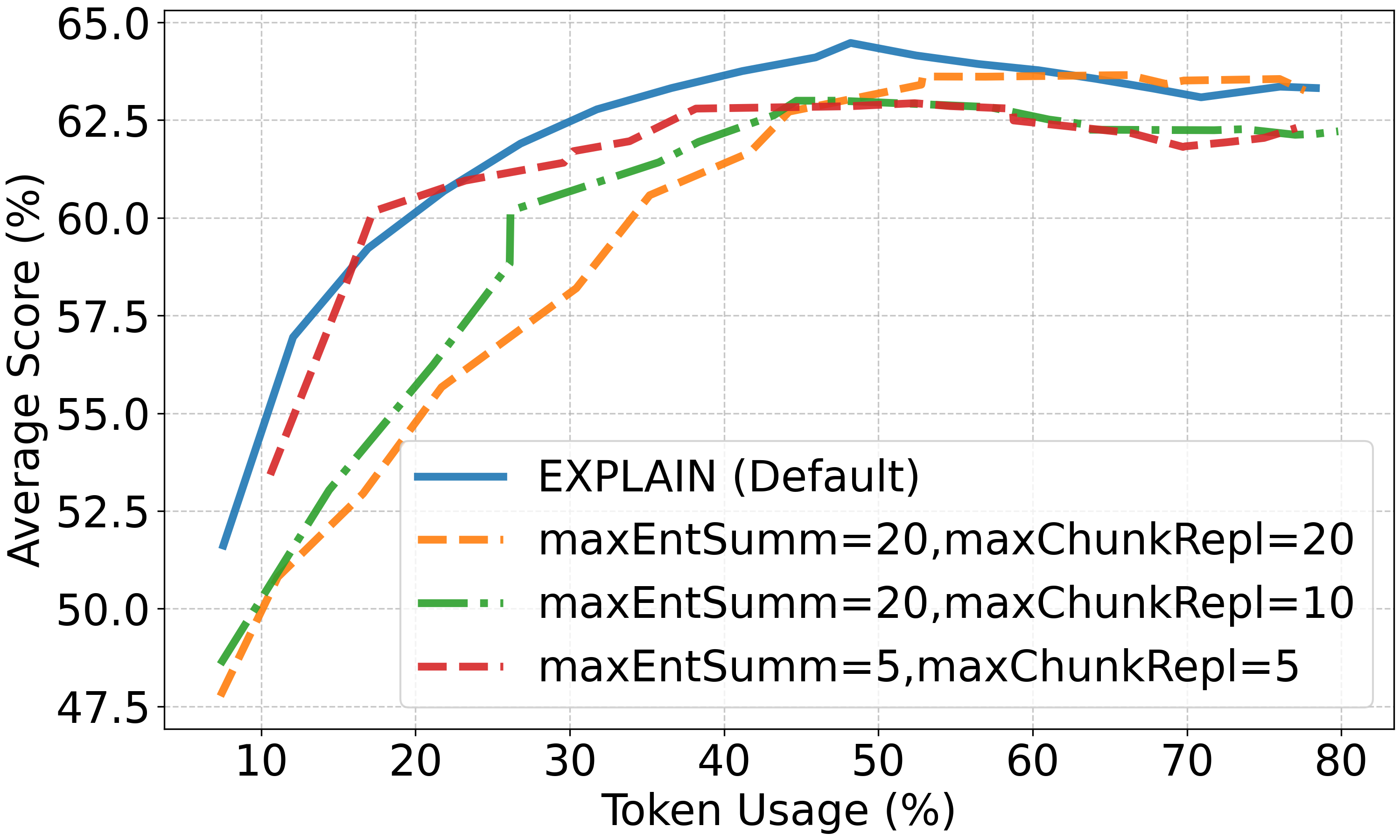
图2:Token消耗(%)与平均得分(%)的关系。在HotpotQA、2WikiMQA和Quality数据集上,固定实体摘要数量为10,通过增加文档片段数量来增加Token消耗。可以看到在相同Token消耗下,EXPLAIN始终优于RAG+Reranker基线。
这个实验设计很有价值:固定实体摘要数量为10,逐步增加文档片段数量,观察Token消耗与准确率的关系。
核心结论 :在相同Token消耗下,EXPLAIN始终比RAG+Reranker高出1-2%的准确率。这证明了实体摘要的信息密度优势------同样的Token预算,摘要能提供更多有用信息。
消融实验:每个设计决策都有依据
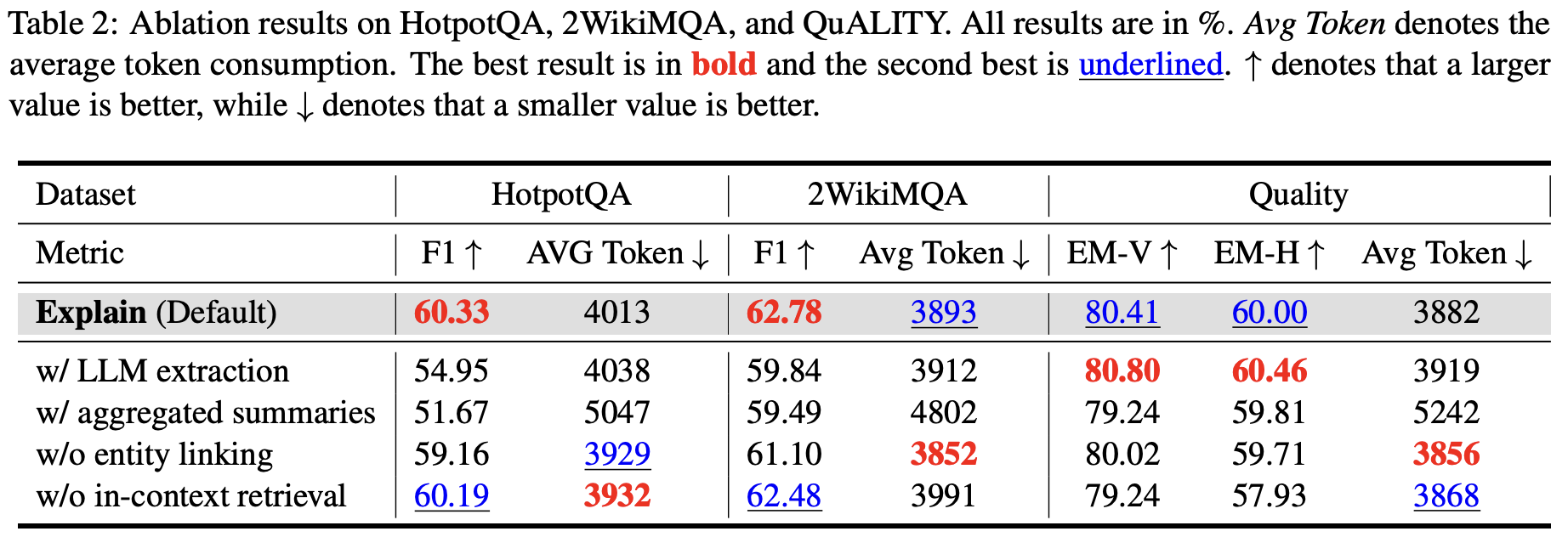
表2:EXPLAIN各组件的消融实验结果。分别测试了LLM提取 vs SpaCy提取、聚合摘要 vs 独立摘要、有无实体链接、上下文内检索 vs 全文档检索的影响。
| 变体 | HotpotQA F1 | 2WikiMQA F1 | QuALITY EM-V |
|---|---|---|---|
| EXPLAIN (Default) | 60.33 | 62.78 | 80.41 |
| w/ LLM extraction | 54.95 | 59.84 | 80.80 |
| w/ aggregated summaries | 51.67 | 59.49 | 79.24 |
| w/o entity linking | 59.16 | 61.10 | 80.02 |
| w/o in-context retrieval | 60.19 | 62.48 | 79.24 |
关键洞察:
-
SpaCy vs LLM提取:SpaCy提取的实体多11.16%,生成的摘要多20.26%。虽然SpaCy会引入噪声,但"宁多勿漏"的策略综合效果更好。而且SpaCy的速度比LLM快几个数量级,适合大规模文档处理。
-
聚合摘要有害 :把一个实体的所有摘要合并成一条,HotpotQA上性能从60.33暴跌到51.67。细粒度检索是关键!
-
实体链接影响有限:移除实体链接后性能下降约1个点,主要作用是减少计算开销。
-
上下文内检索:论文中的"in-context retrieval"是指只从已检索到的片段中提取实体进行摘要检索,而非从全文档检索。这个设计在QuALITY上有明显收益。
🏭 生产部署:蚂蚁集团的真实验证
EXPLAIN已于2024年9月在蚂蚁集团内部部署,用于HR和金融咨询场景。这是论文最有说服力的部分------学术实验和生产环境往往有很大差距。
在线A/B测试结果
实验设置:
- 892个真实用户查询
- 3名公司志愿者盲评
- 对比RAG+Reranker基线
| 评估维度 | EXPLAIN胜 | 平局 | 基线胜 |
|---|---|---|---|
| 准确性 | 13.79% | 57.29% | 28.92% |
| 全面性 | 30.04% | 53.70% | 16.26% |
| 幻觉率 | 2.5% | - | 1.8% |
关键发现:
-
全面性大幅领先:EXPLAIN在回答的全面性上显著优于基线(30.04% vs 16.26%)。这正是实体摘要的核心价值------把分散的信息聚合起来。
-
准确性略有差距:这是一个有趣的发现。作者分析原因是EXPLAIN倾向于先提供实体定义再回答问题,在严格的准确性评估中可能被扣分(因为"多说了")。
-
幻觉率相当:2.5% vs 1.8%,差异不显著。这说明实体摘要步骤没有引入额外的幻觉风险。
作者的反思:HR和金融查询通常需要更详细、更有上下文的答案。EXPLAIN提供的额外实体信息虽然增强了全面性,但可能使核心答案不够直接。这提示我们在不同场景下可能需要调整摘要的使用策略。
💡 技术洞察:为什么EXPLAIN有效?
1. 解决了RAG的信息碎片化问题
传统RAG的文档切分策略(如固定长度切分、递归切分)都面临一个根本矛盾:
- 切片太小:语义不完整,上下文丢失
- 切片太大:检索粒度粗,引入过多噪声
EXPLAIN的实体摘要提供了一个新的检索粒度------以实体为中心聚合信息。这不是替代文档切分,而是作为补充。
2. 信息密度的提升
| 类型 | 平均长度 | 信息密度 |
|---|---|---|
| 文档片段 | ~110 tokens | 包含大量背景、过渡句 |
| 实体摘要 | ~35 tokens | 高度浓缩的关键信息 |
同样的Token预算,摘要能提供3倍的"有效信息量"。
3. 与GraphRAG的对比
GraphRAG是另一种实体增强RAG的方案,它构建完整的知识图谱来增强检索。对比:
| 维度 | EXPLAIN | GraphRAG |
|---|---|---|
| 构建成本 | 低(只需实体提取+摘要生成) | 高(需要关系抽取、图谱构建) |
| 维护成本 | 低(摘要独立、易于更新) | 高(图谱结构复杂) |
| 推理能力 | 有限(不支持多跳图推理) | 强(支持路径推理) |
| 适用场景 | 通用文档问答 | 关系密集型知识库 |
EXPLAIN的定位是轻量级增强方案,适合快速部署和迭代。
4. 离线-在线分离的工程价值
- 离线阶段:实体提取、链接、摘要生成(计算密集但只需执行一次)
- 在线阶段:摘要检索和替换(轻量级,不增加推理延迟)
这种架构设计使得EXPLAIN可以即插即用------不需要修改底层LLM,不需要重新训练模型,只需要在RAG pipeline中增加一个摘要索引和替换逻辑。
⚠️ 局限性与改进方向
当前局限
-
离线处理成本:实体摘要生成需要调用LLM,对大规模文档库有一定成本。论文使用LLaMA3.1-8B生成摘要,但对于TB级文档库仍是不小的开销。
-
参数敏感性 :
maxEntSumm和maxChunkRepl需要针对不同场景调优。论文给出的参考值:- 多跳QA:maxChunkRepl=5
- 长文档阅读:maxChunkRepl=7
- 企业内部QA:maxChunkRepl=2
-
实体噪声:SpaCy提取的名词短语可能包含无意义的实体(如"the system"、"this method")。虽然这些噪声在检索时会被自然过滤,但会增加摘要生成的成本。
-
跨实体关系缺失:EXPLAIN只处理单个实体的摘要,不涉及实体间的关系。对于"A和B有什么关系"这类问题,效果可能有限。
未来改进方向
-
自适应参数选择:根据问题类型(事实型、比较型、推理型)动态调整摘要和片段的比例。
-
增量更新:当文档库变化时,只更新受影响实体的摘要,而非全量重建。
-
实体关系摘要:扩展到实体对的关系摘要,增强对关系型问题的回答能力。
-
多模态扩展:将实体摘要思想扩展到图表、图像等多模态内容。
🔬 复现指南
核心组件选择
| 组件 | 论文使用 | 推荐替代 |
|---|---|---|
| 实体提取 | spaCy (en_core_web_sm) | 效率优先,噪声可接受 |
| 向量检索 | BGE-M3 | 多语言支持,效果好 |
| 重排序 | BGE-reranker-v2 | 与BGE-M3配合 |
| 摘要生成 | LLaMA3.1-8B | Qwen2.5-7B(中文场景) |
关键参数设置
python
# 推荐的默认参数
config = {
"chunk_size": 128, # 文档片段最大token数
"jaccard_threshold": 0.7, # 实体链接阈值
"n_gram": 3, # Jaccard计算的n-gram大小
"top_k_retrieval": 40, # 初始检索数量
"max_ent_summ": 10, # 最大实体摘要数
"max_chunk_repl": 5, # 最大替换片段数(多跳QA场景)
}实践建议
-
先跑基线:在你的数据集上先跑通标准RAG+Reranker,建立性能基线。
-
小规模验证:选择100-200个样本进行实体摘要实验,观察效果和成本。
-
参数搜索 :
maxChunkRepl对不同任务敏感,建议在验证集上搜索2, 5, 7, 10。 -
监控指标:
- 准确率/F1(核心指标)
- Token消耗(成本指标)
- 摘要命中率(诊断指标:有多少问题用到了摘要)
-
渐进式部署:先在低风险场景(如内部知识库问答)验证,再推广到客户facing场景。
📚 相关工作对比
| 方法 | 核心思想 | 与EXPLAIN的区别 |
|---|---|---|
| RECOMP | 抽取式/生成式压缩检索结果 | EXPLAIN是预生成摘要,RECOMP是在线压缩 |
| RAPTOR | 递归摘要构建树结构 | EXPLAIN以实体为中心,RAPTOR以文档层次为中心 |
| GraphRAG | 知识图谱增强 | EXPLAIN更轻量,不需要构建完整图谱 |
| OP-RAG | 保序检索,保留原文顺序 | EXPLAIN是内容增强,OP-RAG是顺序优化 |
| ChainRAG | 渐进式检索和重写 | EXPLAIN是离线预处理,ChainRAG是在线迭代 |
📝 总结
EXPLAIN是一个设计精巧、工程友好的RAG增强方法。它的核心贡献在于:
-
提出实体摘要增强RAG的新范式:通过预生成实体摘要,解决了RAG的信息碎片化问题。
-
细粒度摘要设计:每个摘要项独立检索,避免信息污染,这是性能提升的关键。
-
生产环境验证:在蚂蚁集团的真实部署证明了方法的实用价值,特别是在全面性指标上的显著提升。
-
即插即用的架构:不需要修改底层模型,可以与现有RAG系统无缝集成。
对于正在构建企业级文档问答系统的团队,EXPLAIN提供了一个值得尝试的技术方案------用相对低的实现成本,换取显著的效果提升。
🔗 参考资料
- 论文原文:EXPLAIN: Enhancing Retrieval-Augmented Generation with Entity Summary (ACL 2025)
- GraphRAG: From Local to Global: A Graph RAG Approach to Query-Focused Summarization
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- OP-RAG: Order-Preserve RAG for Long Context
- ChainRAG: 南京大学提出的渐进式检索和重写方法
- BGE-M3: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings
如果觉得有帮助,别忘了点赞、在看、转发三连哦~ 👍