一、可观测性的"最后一公里"难题
在可观测性领域,指标、日志与链路数据因其不同的数据特性与访问模式,通常采用异构存储架构:
- 时序数据库(如 Prometheus、InfluxDB)承载指标数据;
- 日志存储(如 Elasticsearch、Loki)处理日志流;
- 分布式追踪系统(如 Jaeger、Tempo、Skwalking)管理链路数据。
这种基于数据特性的存储分层设计虽能优化各自场景的性能与成本,但也导致了跨数据类型关联分析的固有障碍。
当前货拉拉的 Monitor 系统已实现三种基础关联能力:
(1)通过应用名称+指标类型+标签组合实现框架指标与链路的关联检索;
(2)依托 ClickHouse 日志引擎原生指标能力支撑中间件(如 Kong)的指标-日志关联;
(3)基于预设保留字段完成业务 订单与链路的定向检索。
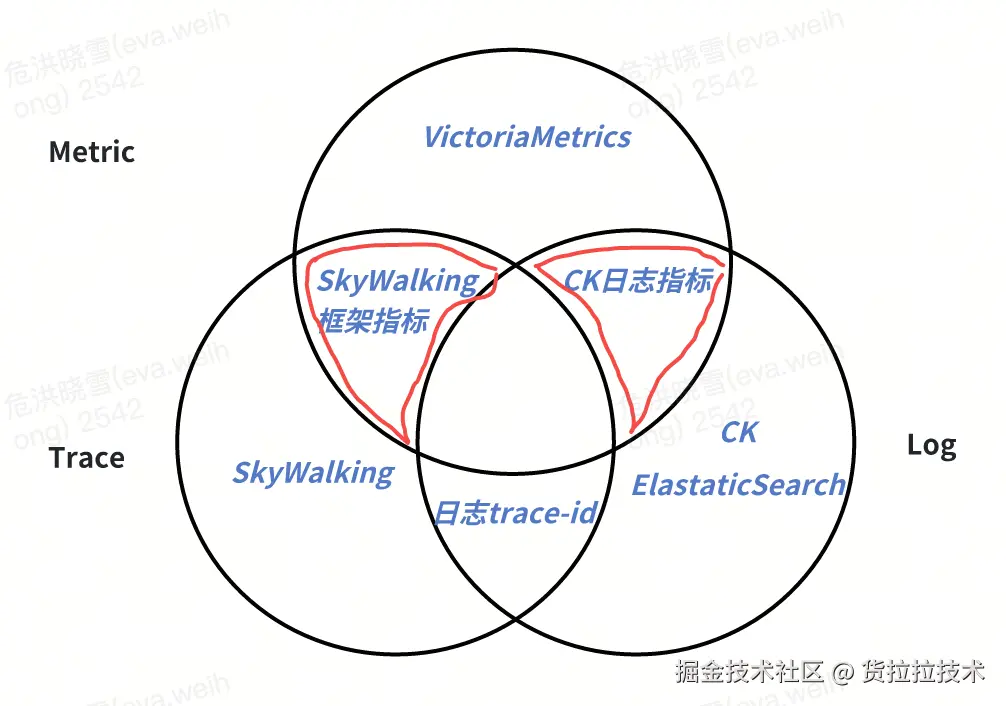 然而,架构评估表明,在指标-链路、指标-日志的核心融合路径上,现有方案的完成度仍存在显著提升空间。
然而,架构评估表明,在指标-链路、指标-日志的核心融合路径上,现有方案的完成度仍存在显著提升空间。
| 数据维度 | 构建形式 | 数据流 | 完成度 |
|---|---|---|---|
| 指标 & 日志 | 双向跳转 | 在 ck 日志指标的看板中,可以根据点击曲线查看到日志的细节;在分析日志时,可以进行 top、时间线图、饼图等分析; | 用户需要先使用 ck 日志才能具备这个能力,对绝大多数 vm 指标不适用; |
| 指标 & 链路 | 基于约定的指标单向跳转到链路 | 在应用指标上,用户可以通过点击曲线展开相关指标类型、时间的 trace 数据; | 适配框架指标、定制化的订单数据,对业务指标不适用; |
| 链路 & 日志 | 基于约定的双向跳转 | 查看链路时根据 trace-id 搜索相关日志;查看日志根据 trace-id 跳转到链路数据; | 暂没有更深入的可观测需求 |
当用户面对指标异常时,仍需在多个子系统中手动拼接上下文,这不仅延长了 MTTR,更暴露了当前可观测体系在数据融合维度的深层缺陷:缺乏一种轻量级、标准化的端到端关联机制。Exemplar 技术正是针对这一问题的核心解法------它通过在指标数据中内嵌结构化上下文标识(如 TraceID、关键业务标签),构建从聚合指标到原始观测数据的可追溯路径,从而在保持存储架构优势的同时,实现跨数据类型的无缝融合。下文将详细探讨该技术的实践路径。
二、对行业主流方案的探索与思考
OpenTelemetry Exemplar 方案
OpenTelemetry 作为可观测性领域的开源标准,其 Exemplar 机制通过在指标数据中嵌入 TraceID 和 SpanID 等上下文信息,实现指标与分布式追踪的关联。技术实现上,Exemplar 作为指标样本点的附加属性,支持单个时间序列存储多个 Exemplar 样本,通过 Exemplar Reservoir 机制进行采样和存储管理。该方案的优势在于标准化程度高,与 CNCF 生态深度集成。
Grafana Exemplar 实践
Grafana 在可视化层面对 Exemplar 进行了深度整合。在指标图表中,包含 Exemplar 的数据点会以高亮标记(如星形图标)显示,用户点击后可直接跳转至关联的 Trace 详情。该方案依赖后端存储系统(如 Prometheus 2.27+、Mimir)对 Exemplar 的原生支持,通过 Explore 功能提供分析能力,而非独立页面。

Dynatrace OneAgent 方案
Dynatrace 通过 OneAgent 代理实现了全栈自动化的数据关联能力。OneAgent 能够自动为日志记录添加 TraceID 和 SpanID 等上下文标识,实现日志与追踪的自动关联。该方案的核心特点是通过统一代理架构收集事件、日志、指标和追踪数据,并将它们统一呈现在单一工作负载相关的视图中。
行业方案的局限性
我们通过对 OpenTelemetry、Grafana、Dynatrace OneAgent 等主流方案的深入分析,现有 Exemplar 实现存在三个根本性局限,制约了其在复杂业务场景中的价值发挥:
定位局限:增强属性而非独立维度
当前行业方案普遍将 Exemplar 定位为指标的增强属性,而非独立的观测维度。OpenTelemetry 规范中 Exemplar 作为指标样本点的附加字段存在,Grafana 的实现必须依附于指标图表进行交互,Dynatrace 虽实现自动关联但仍将 Exemplar 视为上下文补充。这种设计导致:
- 分析路径单一:只能从指标异常触发 Exemplar 查询,无法反向从 Exemplar 数据发现指标趋势;
- 查询能力受限:缺乏对 Exemplar 数据本身的聚合、过滤、统计等日志式分析能力;
- 价值挖掘不足:Exemplar 中蕴含的业务上下文(如订单 ID、用户特征)难以作为独立维度进行分析;
架构局限:存储耦合与使用门槛
现有方案在存储架构上存在显著缺陷:
- 存储强耦合:OpenTelemetry 的 Exemplar 必须存储在兼容 Prometheus remote write 的时序数据库中,与指标数据绑定,无法独立扩展
- 查询体验割裂:Grafana 虽提供 Trace 跳转,但 Exemplar 数据本身无法在 Explore 等通用分析界面中独立使用
- 接入成本高:现有的 Opentelemetry、Prometheus SDK 难以直接让用户接入 exemplar 。
价值局限:场景覆盖不足
行业方案未能充分释放 Exemplar 的潜力:
- 被动关联为主:仅在指标异常时提供上下文,无法主动发现业务模式(如特定用户群的性能退化)
- 日志能力缺失:Exemplar 虽本质是结构化日志,但现有方案未提供日志检索、字段提取、模式发现等基础能力
我们的思考:Exemplar 作为独立观测维度
基于上述局限,我们提出 Exemplar as a Dimension 的核心理念:
-
双重身份:Exemplar 既是指标与链路/日志的关联桥梁,也是可独立分析的结构化日志流(即在指标->链路的映射关系之上,建立指标->日志的映射关系)
-
降维使用:在异构存储背景下,Exemplar 可作为结构化日志使用,降低接入门槛------无需完整部署日志系统,即可获得关键业务上下文
-
场景扩展:支持从 Exemplar 数据反向聚合生成指标(如统计特定业务场景的错误率),实现观测维度的自由切换
三、货拉拉 Exemplar 架构
技术选型
我们选择 VictoriaLogs(以下简称 VLog)作为 Exemplar 的专用存储引擎,基于货拉拉实际业务场景重构内部组件,构建了从数据写入到查询分析的完整链路。这一选型主要基于三点核心考量:
-
Schemaless:VictoriaLogs 自动索引所有出现的字段,业务团队无需预先定义日志结构,新业务字段可立即用于查询,较 Ck 日志使用门槛大幅降低;
-
VictoriaMetrics 生态协同:货拉拉已在全球多个 Region 完成指标系统向 VictoriaMetrics 的迁移。VLog 作为同源产品,共享一致的运维体系,团队无需新增运维技能栈。其简化的 LogQL 语法(与 PromQL 风格统一)大幅降低查询使用门槛;
-
性能出色:实测,单位相同日志量下,综合成本大约为 ElasticSearch 的 1/10。
文本传输协议
我们借鉴了 OpenMetrics 的行协议,以实现对 Prometheus 行协议的前向兼容。
| Opentelemetry | 货拉拉 Exemplar 行协议 | |
|---|---|---|
| 核心数据结构 | - Exemplars 必须由一个 LabelSet 和一个值组成,并且可以有一个时间戳 |
- 每个 exemplar 如果附加到 TimeSeries,必须包含一个值,可能包含时间戳 | - 必须包含值(counter 中 IncrOnce 对应为 1,histogram 中对应为 observce 的值)
- 必须包含时间戳( 最高支持 ns) | | Trace 上下文标识 | OpenMetrics Exemplars 必须使用
trace_id和span_id键分别表示 trace 和 span ID |trace_id和segment_id键分别表示 skwalking 中的 trace 和 segment ID | | 格式兼容性 | 使用#注释跟随在 series 行后 | 使用# Exemplar独立行跟随在具体的 series 行后,多个 Exemplar 使用多个独立的行 |
其格式如下:
lua
# TYPE foo_request_duration_seconds histogram
foo_request_duration_seconds_bucket{app="foo-service",env="prod",instance="10.0.0.1",method="GET",status="200",le="0.005"} 0
foo_request_duration_seconds_bucket{app="foo-service",env="prod",instance="10.0.0.1",method="GET",status="200",le="0.01"} 2
foo_request_duration_seconds_bucket{app="foo-service",env="prod",instance="10.0.0.1",method="GET",status="200",le="0.025"} 5
# Exemplar {trace_id="abc123def4567890",segment_id="xyz789",user_id="user-123",endpoint="/api/v1/query",client_ip="192.168.1.100",} 0.008456 1700000000123456789
# Exemplar {trace_id="def456ghi7890123",segment_id="uvw456",user_id="user-456",endpoint="/api/v1/query_range",client_ip="192.168.1.101",} 0.018723 1700000000234567890
# TYPE foo_database_query_seconds histogram
foo_database_query_seconds_bucket{service="foo-db",env="prod",query_type="select",database="main",le="0.05"} 3
foo_database_query_seconds_bucket{service="foo-db",env="prod",query_type="select",database="main",le="0.1"} 8
# Exemplar {trace_id="ghi789jkl0123456",segment_id="rst123",query_id="query-789",table="users",client_app="web-frontend",} 0.042158 1700000000345678901
# Exemplar {trace_id="jkl012mno3456789",segment_id="opq789",query_id="query-012",table="orders",client_app="mobile-app",} 0.087634 1700000000456789012-
SDK 数据上报
针对 Exemplar 数据的高吞吐、不可聚合的特性,我们摒弃了 Prometheus 传统的 pull 模型,在 sdk 中新增了一条面向 exemplar 数据的数据流通道,采用 push 机制向后端 collector 发送数据。
由于不同应用场景产生的 Exemplar 日志类型差异显著------单条日志大小可能从几百字节到几十 KB 不等,简单的定时 flush 或基于固定行数的 flush 策略均难以平衡实时性与资源消耗。因此,我们需要设计一套精细的自适应 push 策略,能够根据日志体积、业务重要性和系统负载动态调整推送节奏。
-
Cache Size 驱动:SDK 内置滑动窗口缓存,当 Exemplar 数据量达到阈值(默认 10MB)或时间窗口到期(默认 10 秒)时,自动批量推送数据;
-
反压保护:当后端处理异常时,SDK 自动重试,极端情况下,丢弃以保证服务的稳定性;
-
数据压缩:采用 gzip 压缩替代原始文本格式,降低网络带宽的占用;
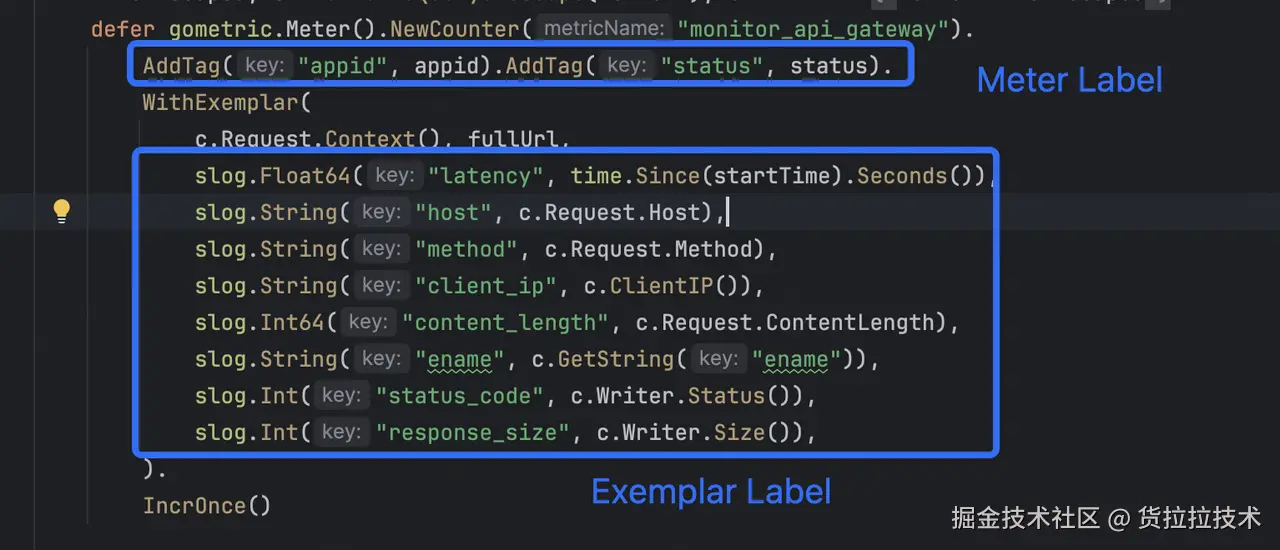
在 golang 中,我们通过扩展既有的 Meter 接口,实现了 Exemplar 数据的标准化上报。该机制将 Exemplar 标签与数值精准附着到对应的指标时间序列上,其调用规范如下:
- 上下文参数 :首个参数必须为
context.Context,用于自动捕获分布式追踪上下文(如 SkyWalking 的 TraceID/SegmentID); - 业务 标识参数:第二个参数为关键业务标识字符串(如完整 URL、SQL 、请求入参等等),作为 Exemplar 的核心描述内容;
- 结构化标签集合 :后续参数为可变数量的
slog标签,通过slog.String()/slog.Int64()等方法定义业务维度标签;
在 Java SpringBoot Actuator 中,默认是集成Micrometer作为指标数据上报的标准 API。我们通过扩展 PrometheusMeterRegistry、Counter、Timer 默认实现,在指标数据记录 Value 的同时,实现 Exemplar 数据的上报。具体使用规范如下:
-
使用**
LalaMetricRegistry**#XXbuilder构建- 默认携带
trace_id、segment_id链路信息; - 构建可直接放在方法体重复执行,同一个 Meter (Name+Tag 区分)只会创建一次;
- Counter 类型按照规范:指标名称,默认会自动添加"_total"后缀(名称已有则不会重复添加),如不需要可添加
.withoutTotalSuffix()方法
- 默认携带
-
Exemplar 扩展信息类型支持长文本(
withExemplarMsg方法)、KV 键值对(withExemplarTag)类型,如 KV 键值对,推荐使用内置ExemplarTag构建输入; -
支持通过 Endpoint 查看 Exemplar 统计信息和待上报文本内容,需显示配置开启 exemplar、exemplar-data 两个端点;
-
使用示例:
less
@GetMapping("/exemplar")
public String exemplarTest() {
//Histogram 方式1 计时开始位置
Timer.Sample sample = Timer.start();//开始计时位置
// Counter 计数器构建,直接放在方法体中,无需提前创建,
// 注意 指标名称,默认会自动添加"_total"后缀,如不需要可添加.withoutTotalSuffix()
LalaMetricRegistry.counterBuilder("exemplar_counter_test")
.withoutTotalSuffix() // 如显示指定,则不会添加 _total 后缀,建议都加上(防止名称有差异)
.tag("city_id", "13333")//这是指标的label,必须保证收敛
.tags("business_type", "driver")
.register()
.withExemplarTag( "userId" , "uid123445" ) //这是exemplar的扩展信息
.withExemplarTag(ExemplarTag. int_ ( "cost_amount" , 3000 ))
.increment();
//Histogram 方式1 终止计时,自定义Bucket 支持serviceLevelObjectives 配置
sample.stop(LalaMetricRegistry.timerBuilder("exemplar_timer_test")
.tag("city_id", "1333")//这是指标的label,必须保证收敛
.serviceLevelObjectives(Duration.ofMillis(3L), Duration.ofMillis(6L), Duration.ofMillis(10L), Duration.ofMillis(15L), Duration.ofMillis(25L), Duration.ofMillis(50L), Duration.ofMillis(100L), Duration.ofMillis(1000L))
.register()
.withExemplarMsg( "自定义文本内容" ) //有长度限制,1024
.withExemplarTag( "orderId" , "did123456" )
.withExemplarTag( "payId" , "pid123456" ) );
// Histogram 方式2
LalaMetricRegistry.timerBuilder("exemplar_timer_test3")
.tags("city_id", "13555")
.serviceLevelObjectives(BucketConfigs.getInstance().getDurations(HllBucketType.API))
.register()
.withExemplarMsg( "plain text" )
.withExemplarTag( "userId" , "123456" )
.record(Duration.ofMillis(15)); //记录耗时
return "SUCCESS";
}- 两种 Label 的对比:
| 特性 | Meter Labels | Exemplar Labels |
|---|---|---|
| 存储机制 | 每个唯一组合生成独立时间序列 | 附加在样本上的键值对,不影响时间序列 |
| 基数限制 | 严格限制(具备采集防御) | 无限制(Victoria-Logs全采样) |
| 查询场景 | 聚合分析(如sum by(appid)) | 单点详情追溯(点击曲线查看日志) |
| 资源消耗 | 高(序列数直接影响性能) | 低(仅存储样本时的附加信息) |
| 保留策略 | 半年 | 7天 |
Exemplar-Collector
Exemplar-Collector 是一个轻量化的数据接收处理组件,作为 VictoriaMetrics 指标体系与 VictoriaLogs 日志系统的桥梁,它承担两个核心职责:
数据写入处理
-
relabeling :接收应用 SDK 推送的 Exemplar 数据,流式解析文本协议,混合 series labels 与 exemplar labels,使用
internal/insert接口进行数据写入;丢弃无用标签如job、instance等; -
元数据记录:记录应用(appid)与指标(metric)的关联关系到 MySQL,用于后续查询优化,如 histogram 复合指标的支持,智能关联等;
数据查询 处理
-
统一查询接口:提供直方图分布、时间序列、饼图、TopN 统计等预置分析模式,屏蔽底层存储差异;
-
语法兼容层:自动将 PromQL 指标查询转换为 LogsQL 日志查询,使业务团队点击 promethues 图表便能转换到 exemplar 查询;
-
智能关联:根据指标与应用的元数据映射,为存量的图表自动注入 Exemplar 跳转能力,实现"指标→Trace/日志"一键穿透;
四、可视化交互
可视化交互是释放 Exemplar 价值的核心环节。依托货拉拉全自研的 Lala-Monitor 监控系统(集成指标、日志、链路、告警的统一可观测平台),我们突破了 Grafana 等通用工具的交互限制,构建了深度优化的 Exemplar 分析界面。
我们的交互设计围绕 Exemplar 的结构化日志特性展开,实现四大核心能力:
-
智能关联:自动关联图表与 Exemplar,同时支持业务人员手动指定 logsql 进行关联;
-
Drill-down:从指标→Exemplar 日志→trace 的无缝穿透;
-
日志分析:提供完整的日志检索页面,支持类似 ES 的全文检索、字段过滤和模式发现,可直接分析 Exemplar 结构化日志内容;
-
多维统计图表: 基于 Exemplar 数据自动生成时序统计图、排行榜、饼图及柱状图,直观展示业务维度分布(如错误类型占比、慢请求地域分布);
智能关联
当业务指标启用 Exemplar 功能后,Lala-Monitor 会在对应图表上自动添加 Exemplar 标识。此时,用户可直接点击指标曲线上的数据点,查看关联的 Exemplar 日志。
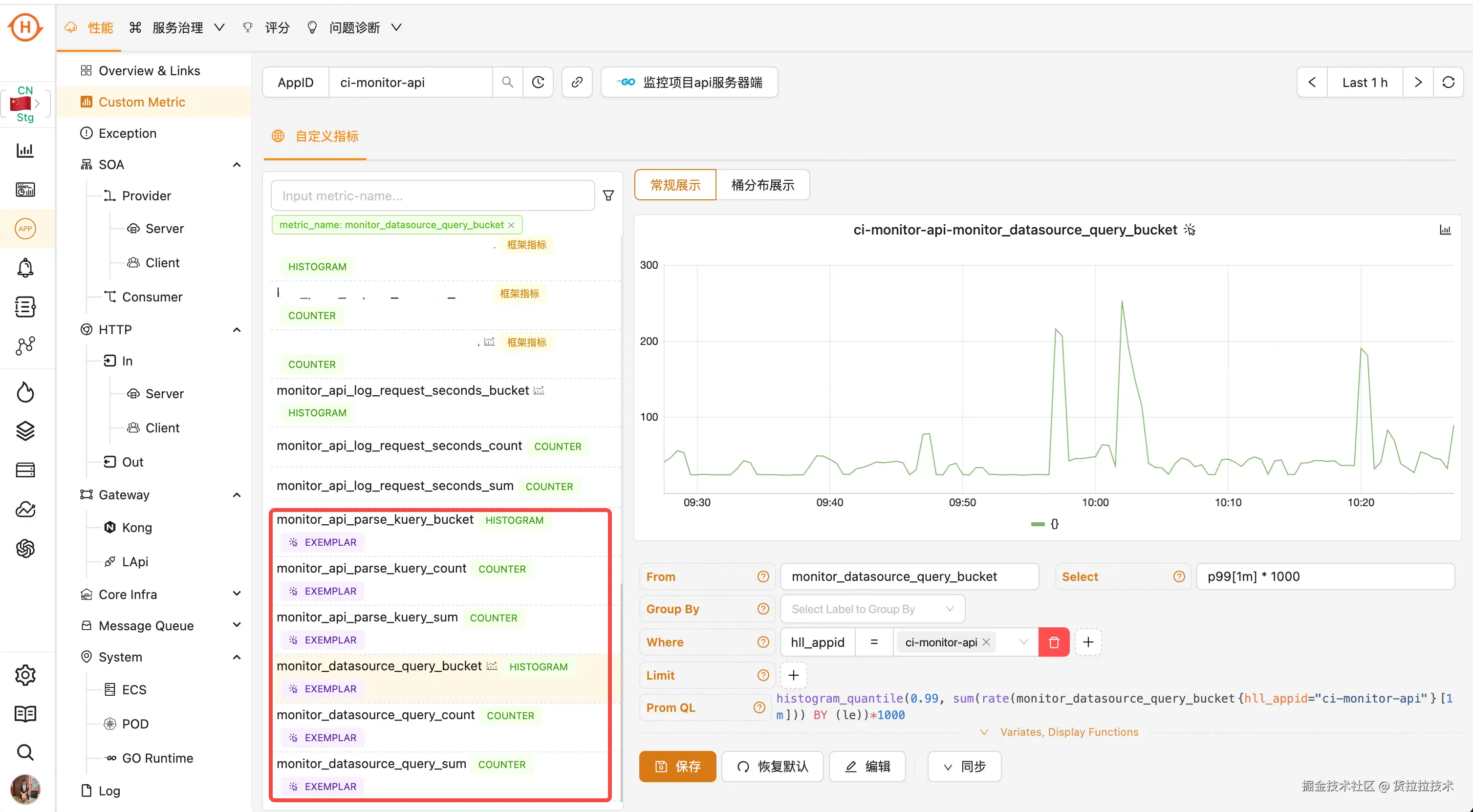
除业务指标外,Lala-Monitor 还为所有已配置的看板图表提供自动联动查询能力。系统定期扫描全量看板,识别包含 Exemplar 数据的指标,并为相关图表开启联动查询能力------无需任何人工配置,用户即可直接点击指标曲线查看关联的 Exemplar 日志。
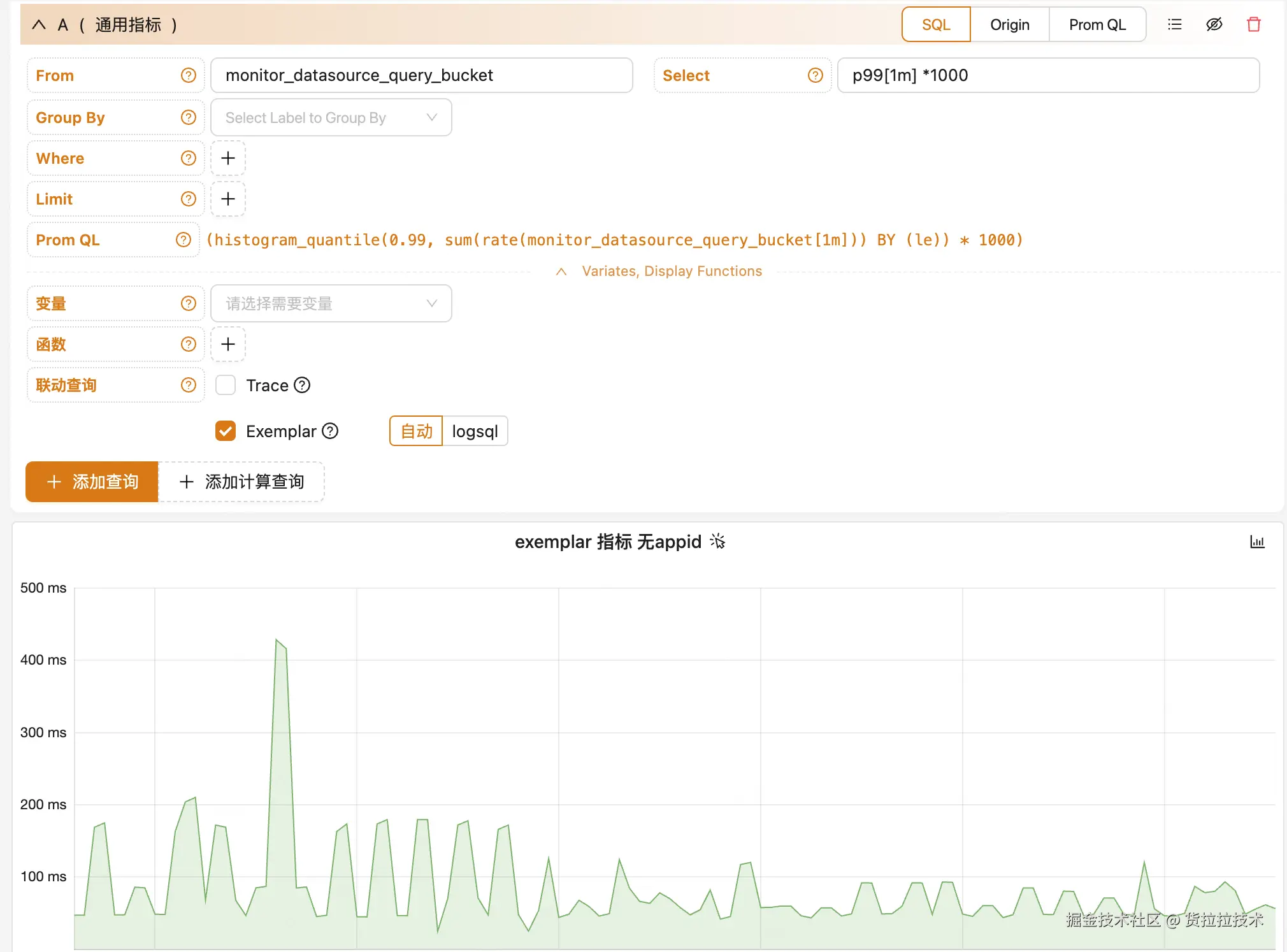
在绝大多数场景下,系统内置的自动关联机制能够准确建立指标与 Exemplar 的映射关系。但在特殊情况下------例如多个应用 ID(appid)共享相同指标名称,或需要与看板变量进行复杂联动时------用户可通过手动指定 appid 和 LogSQL 查询条件来精确控制关联逻辑,确保 Exemplar 数据的准确提取与展示。

Drill-Down 下钻分析
类似 Grafana 的 drilldown 机制,Lala-Monitor 实现了基于 Exemplar 的深度下钻分析能力。用户可直接点击指标曲线上的数据点,系统会自动携带该点的标签信息和 PromQL 查询条件,精准跳转至关联的 Trace 详情页和 Exemplar 日志分析界面,实现从宏观指标到微观上下文的无缝穿透。
如下图所示,当用户在 HTTP RT 监控曲线中发现性能突刺点(红色标记处),只需点击该数据点,Lala-Monitor 将自动触发 Exemplar drill-down 流程:系统智能捕获该时间点的指标上下文(包括 hll_ip、route 等关键标签),并携带精确的时间窗口(10:28:30.000 ~ 10:29:30.000)跳转至 Exemplar 日志分析界面。在此界面中,用户可直接查看与性能异常相关的结构化日志,包括 TraceID、请求参数及响应时间等关键信息;

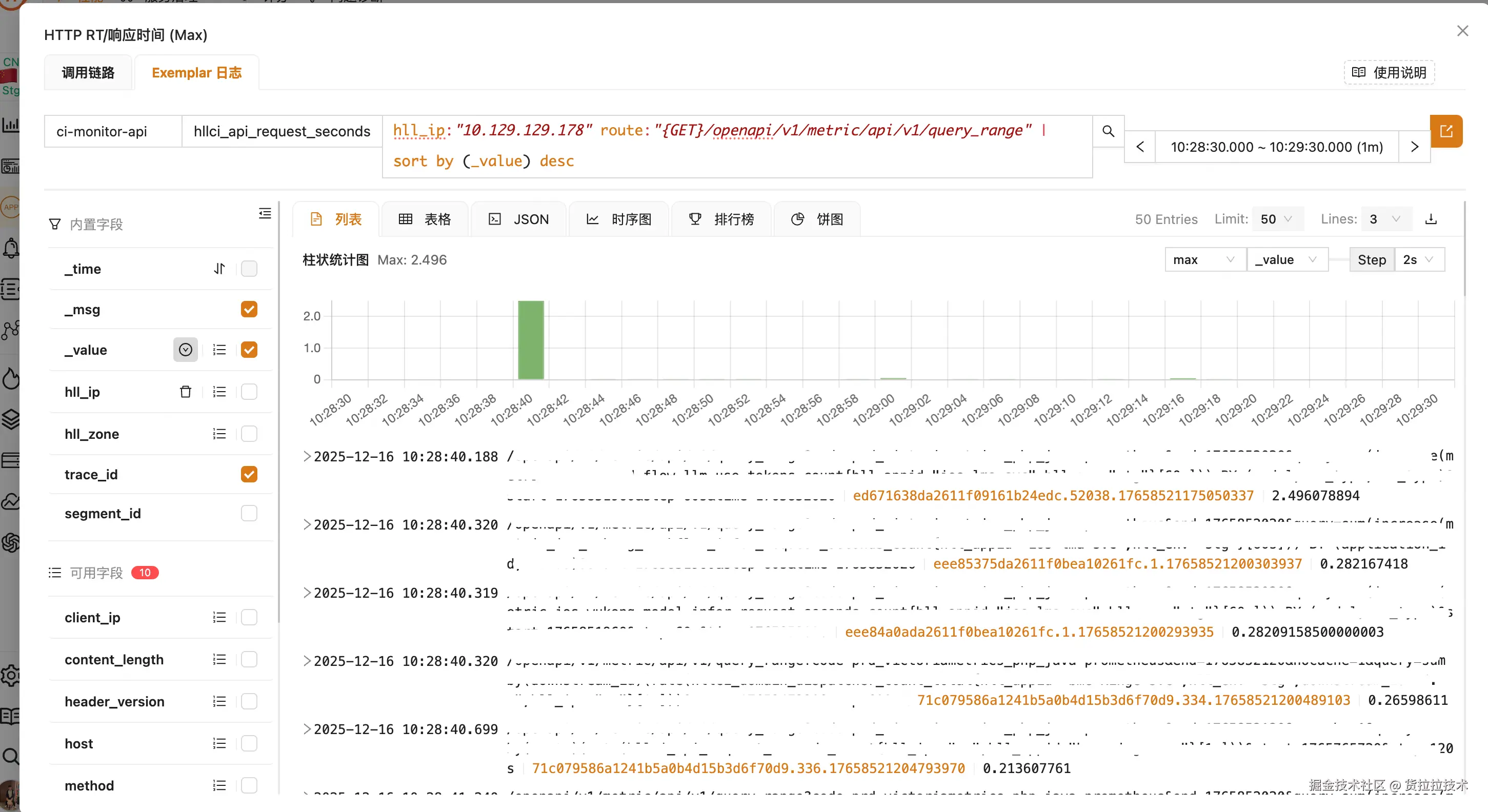
系统会基于当前 PromQL 查询特征智能推荐聚合函数(如图中自动推荐 max),用户也可通过下拉菜单灵活切换 sum、avg、p99 等多种聚合方式,对查询窗口内的 Exemplar 数据进行多维度统计分析,精准识别性能异常点与业务关键特征。
日志分析
除指标 drill-down 作为主要入口外,Lala-Monitor 提供独立的 Exemplar 日志分析页面,支持完整的日志检索能力。该界面具备与 Elasticsearch 相似的交互体验:支持交互式搜索、字段过滤、关键词排除、正则匹配及 TopN 统计分析,同时针对 Exemplar 结构化特性优化了聚合操作。
在性能方面,Vlog 的在亿级日志行规模下仍保持秒级响应。这得益于当前的数据分片策略:每个 Exemplar 流(_stream)由appid+metric-name唯一标识,确保单个数据流规模可控。例如,"order-service+http_request_duration"流仅包含该服务的 HTTP 延迟数据,避免了跨业务、跨类型日志混杂数据量膨胀导致的性能衰减。

Drill-Up 多维统计
多维统计将 Exemplar 结构化日志转化为可视化图表,实现高基数维度的聚合分析。与 Prometheus 指标要求维度可枚举、基数收敛的特性不同,Exemplar 支持对 user_id、driver_id 等高发散性业务维度进行实时统计,使研发能够从海量日志中快速识别异常模式和业务特征,突破指标系统在维度分析上的限制。
以下的时序图可用来对多个维度进行 group by 的统计,类似 prometheus 的 range query
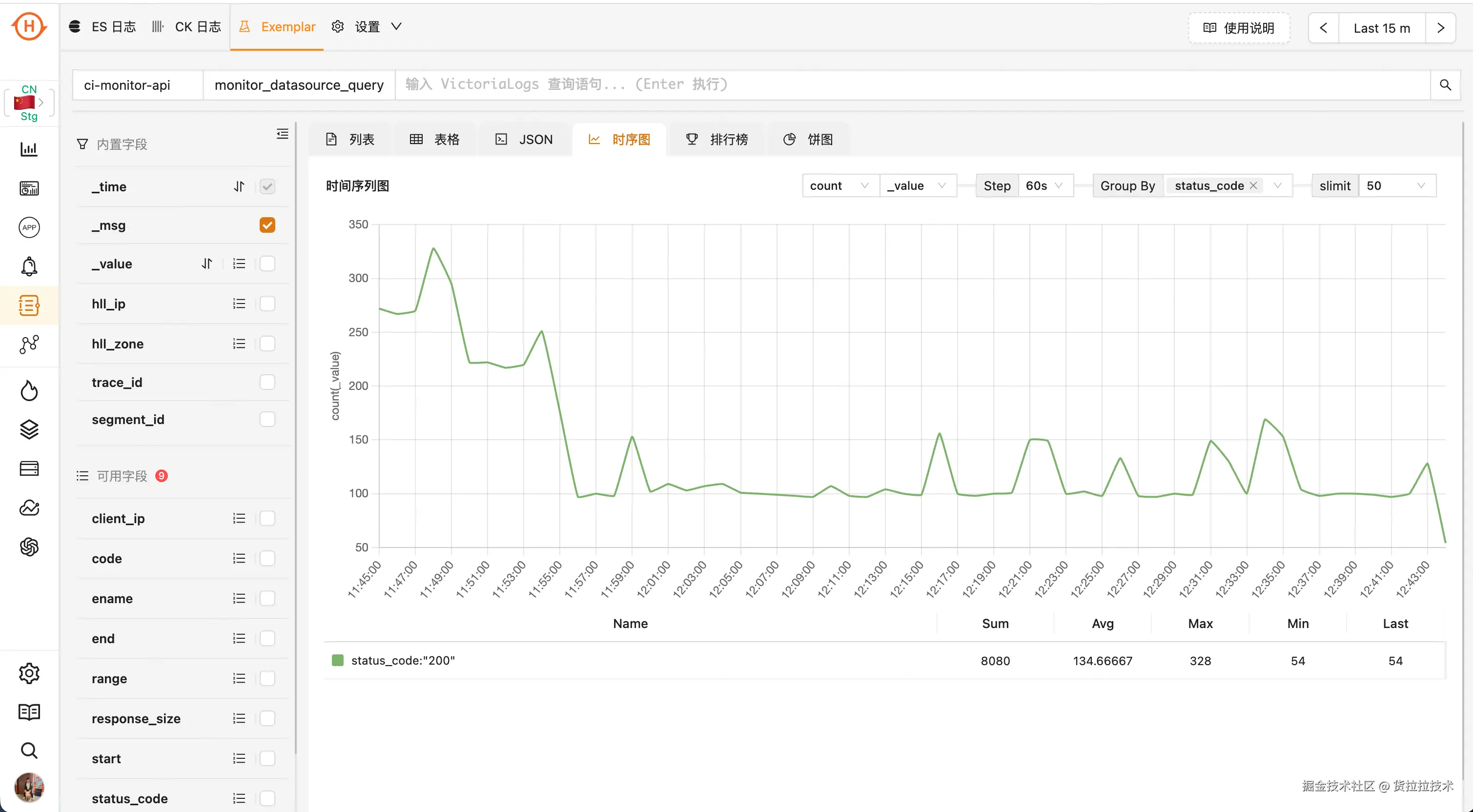
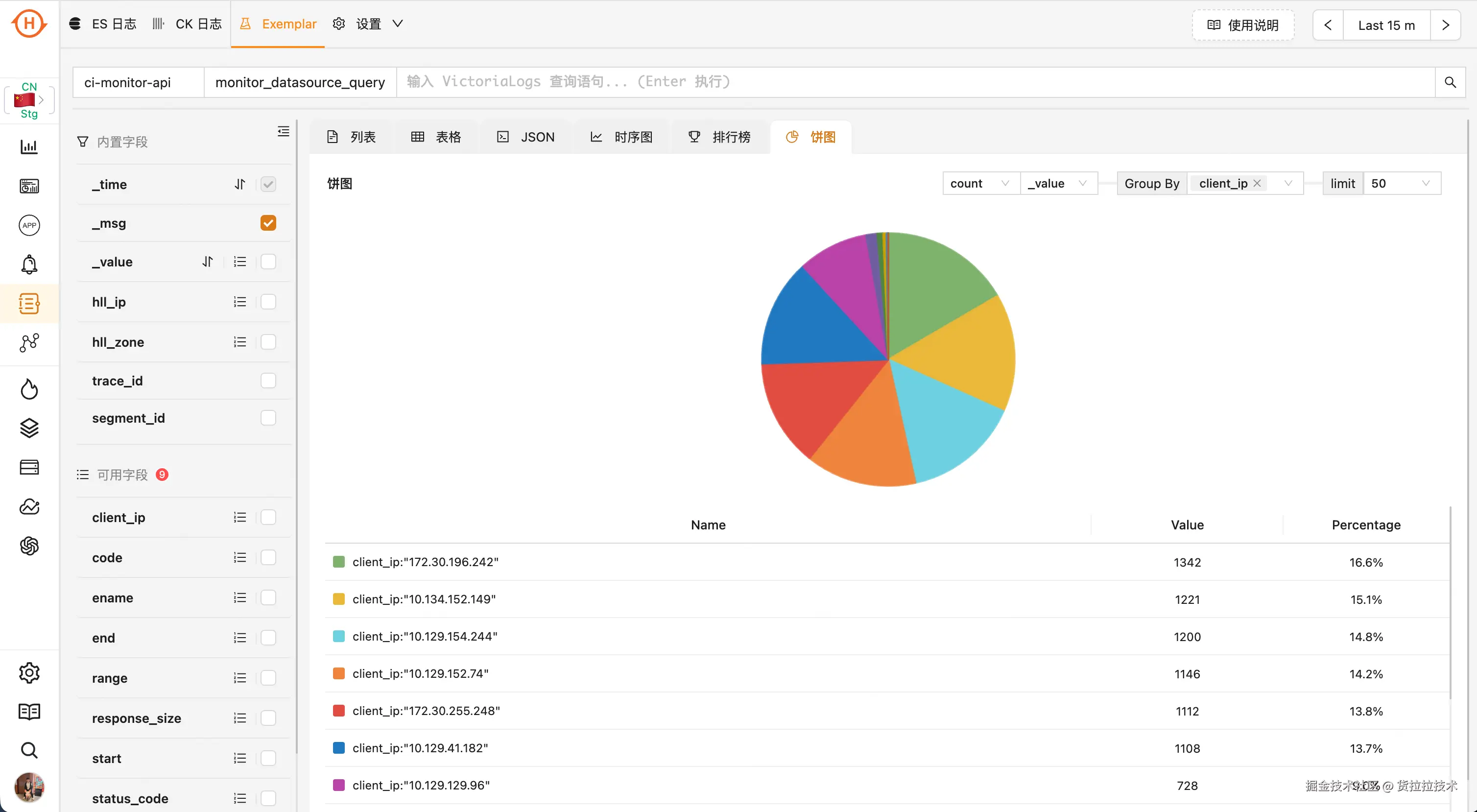
而排行榜和饼图的功能基本一致,可进行总量计算,类似 promethues 的 instant query
五、Exemplar 在货拉拉的落地
在完成 Client SDK 和 Server Collector 建设后,我们首先在内部监控平台上线验证,效果符合预期。
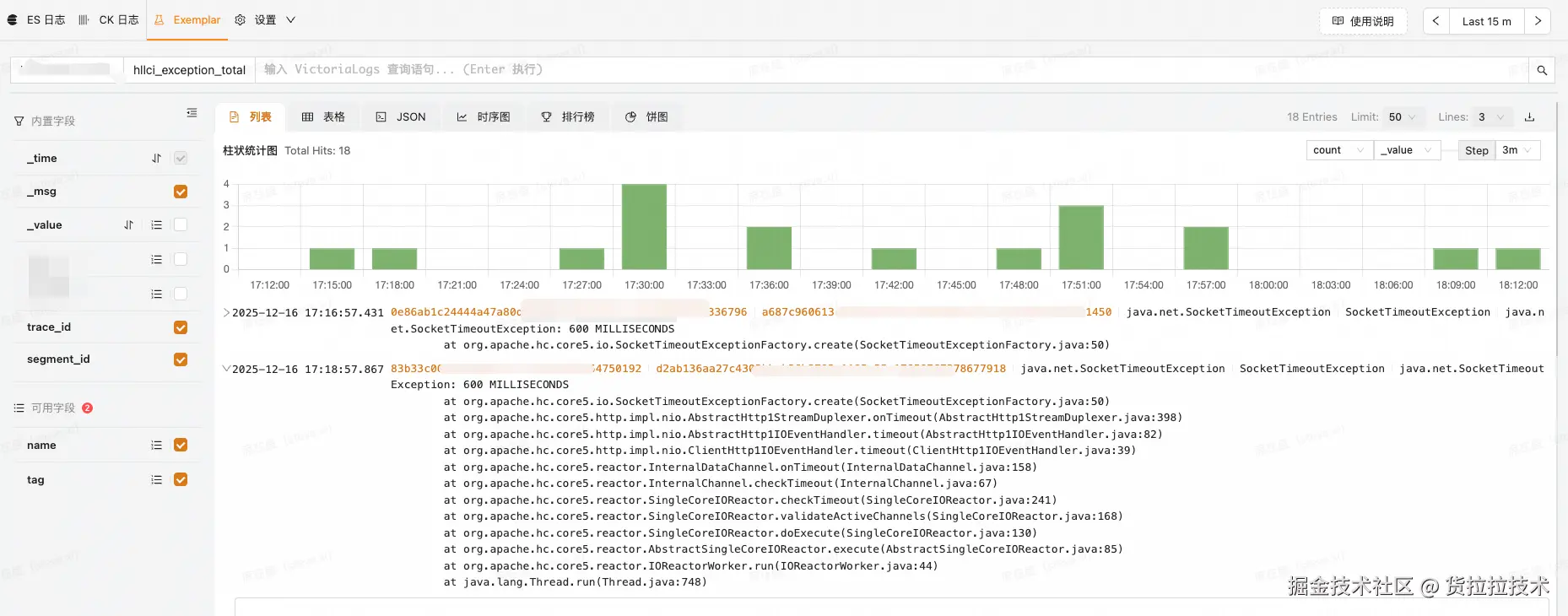
- 针对业务自定义指标场景,重点解决高基数问题。业务定位时需通过用户 ID、司机 ID、订单 ID 等关键属性下钻,但传统指标无法将此类高基数数据放入 Label。通过 Exemplar 机制,我们可以直接在指标采样中携带业务 ID 及关联 Trace 信息,使问题分析能从业务属性直接切入,无需跨系统转换查找 Trace。
- 目前核心订单服务的订单统计指标、企业业务的异常统计指标等几十个核心服务已完成上线,业务团队反馈问题定位效率显著提升,获得一线同学的一致认可。
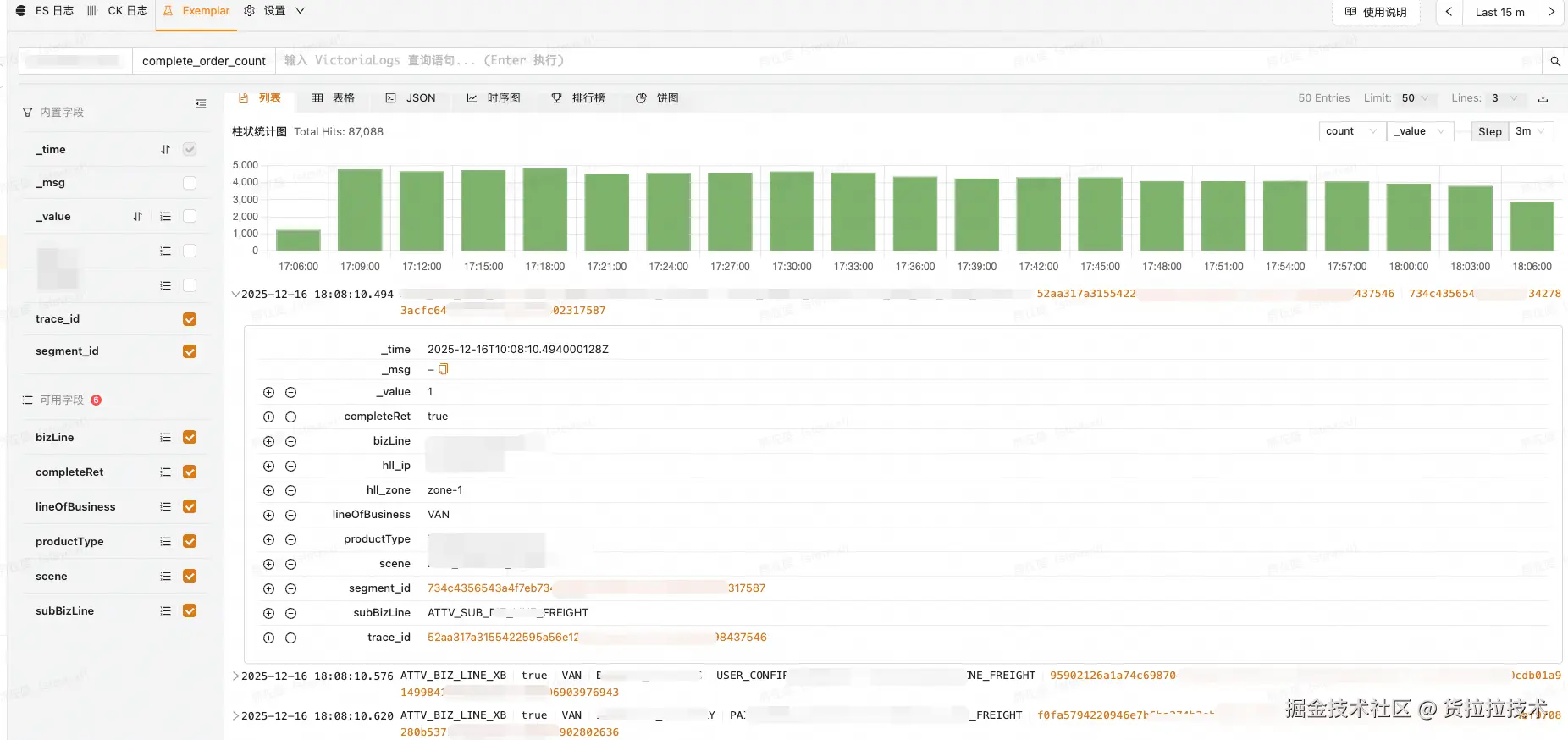
接下来,我们将把 Exemplar 能力下沉至基础组件(如 SOA、MySQL/Redis 客户端),覆盖更多基础设施层指标。
六、未来展望
过去几个月,我们已初步落地 Exemplar 技术,覆盖部分核心业务场景。2026 年,我们将重点深化 Exemplar 在数据融合领域的应用价值:
框架指标→链路的精准关联
当前货拉拉 Java 框架中,链路数据通过 SkyWalking 的 gRPC 通道上报 Trace,框架指标数据则依赖 Micrometer 采集。两者虽能基于接口类型、方法名等维度进行关联,但存在显著缺陷:
- 数据粒度不匹配:指标层面的接口聚合会丢失明细特征,而链路数据保持原始粒度;
- 维度定义差异:指标与链路在埋点时的维度命名、取值逻辑存在不一致;
- 检索能力受限:现有的 trace 存储方案仅支持 Segment 级 RT 倒序,缺乏 Span 级精细化排序能力;
这些缺陷导致点击指标时难以精准下钻至关键 Trace,影响问题定位效率。明年,我们将重构关联机制,通过 Exemplar 标准化上报 TraceID 与 SpanID,实现框架指标与链路的精准映射。
基于 Exemplar 数据的故障定位
Exemplar 的核心价值不仅在于实现指标与上下文的关联,更在于其作为结构化日志所具备的分析潜力。在此基础上,我们将重点在明年进行基于 Exemplar 进行自动化推导链设计,将可观测数据真正转化为可执行的故障洞察。
该推导链以报警、巡检、人工触发为起点,以根因为终点,通过以下环节进行自动推理:
- 报警触发与 Exemplar 抽样:当指标报警触发时,系统自动回溯该指标在异常窗口内的所有 Exemplar 数据。得益于 Exemplar 与指标样本的原生绑定,无需额外关联逻辑即可获取高质量上下文样本;
- Trace 自动关联 :从 Exemplar 中提取
trace_id集合,批量查询分布式链路系统,还原完整调用拓扑。由于 Exemplar 已携带精确时间戳与服务上下文,可避免模糊检索带来的噪声; - 异常维度收敛 :复用已实现的指标下钻分析,结合关联 Trace 的结构化字段(如
service_name、endpoint、error_code)进行实时聚合,识别高频异常维度。例如,若 80% 的 Trace 均包含error_code=DB_TIMEOUT,则将其标记为候选根因; - 多指标协同折叠 :当某个 appid 多个指标同时报警时,计算其 Exemplar 中
trace_id的交集。若交集显著,则判定为同一底层故障,并将多个告警折叠为单一事件,避免告警风暴; - 结构化推导输出:最终生成包含"异常指标---关联 Trace---收敛维度---影响范围"的完整证据链,直接嵌入报警通知或运维工单,为故障处理提供可操作的上下文,而非仅仅堆砌几个相关的 trace。