引言:别把数据库只当硬盘用
在代码审查(Code Review)中,我们经常看到这样的反模式:
为了统计"每个部门薪资最高的前 3 名",开发者写了一条 SELECT * FROM employee 把几万条数据全部拉到内存中,然后在 Java/Python 代码里写嵌套循环、Map 分组、排序、截取。
这种"数据库只负责存,应用层负责算"的做法,在数据量小的时候尚可,一旦数据量上万,不仅造成网络 I/O 拥堵,还容易导致应用服务器 OOM(内存溢出)。
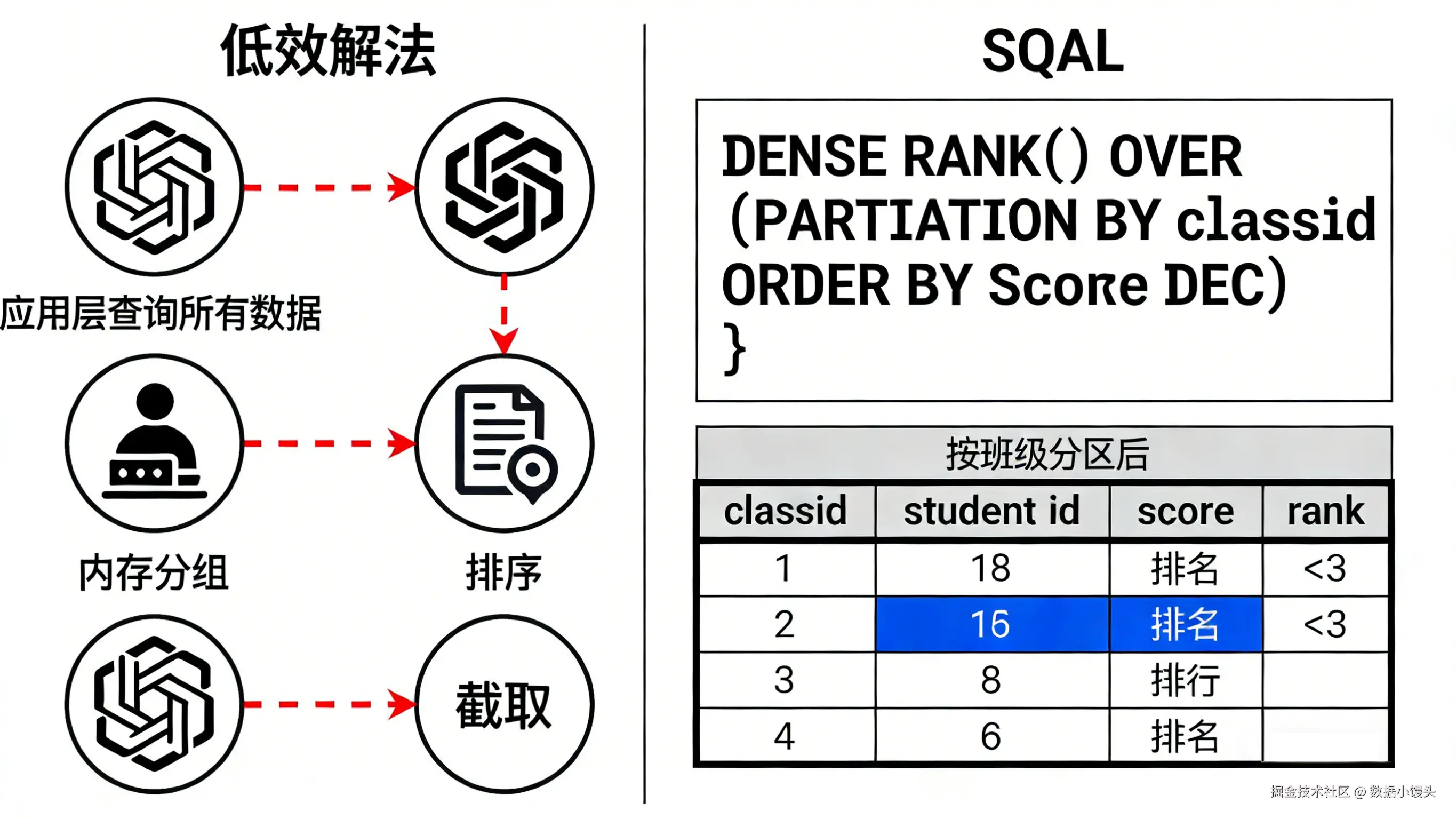
一:一行代码搞定"分组排名" ------ 窗口函数
场景需求:
找出每个班级(class_id)中,数学成绩(score)最高的前 3 名学生。
低效解法(应用层):
查询所有数据 -> 内存中按 class_id 分组 -> 对每组 List 进行 Sort -> 取 subList(0, 3)。
SQL 解法:
使用窗口函数 DENSE_RANK() 或 ROW_NUMBER()。
sql
SELECT * FROM (
SELECT
student_name,
class_id,
score,
-- 核心逻辑:按班级分区,按成绩降序,生成排名
DENSE_RANK() OVER (PARTITION BY class_id ORDER BY score DESC) as ranking
FROM t_scores
) t
WHERE t.ranking <= 3;解析:
OVER (PARTITION BY ... ORDER BY ...) 语法定义了一个"窗口"。数据库会在这个窗口范围内进行计算,而不是对全表聚合。
- ROW_NUMBER():强制排名,1, 2, 3, 4(即使分数一样,名次也不同)。
- RANK():跳跃排名,1, 1, 3, 4(分数一样并列第一,第三名空缺)。
- DENSE_RANK():连续排名,1, 1, 2, 3(分数一样并列第一,且不占用后续名次)。
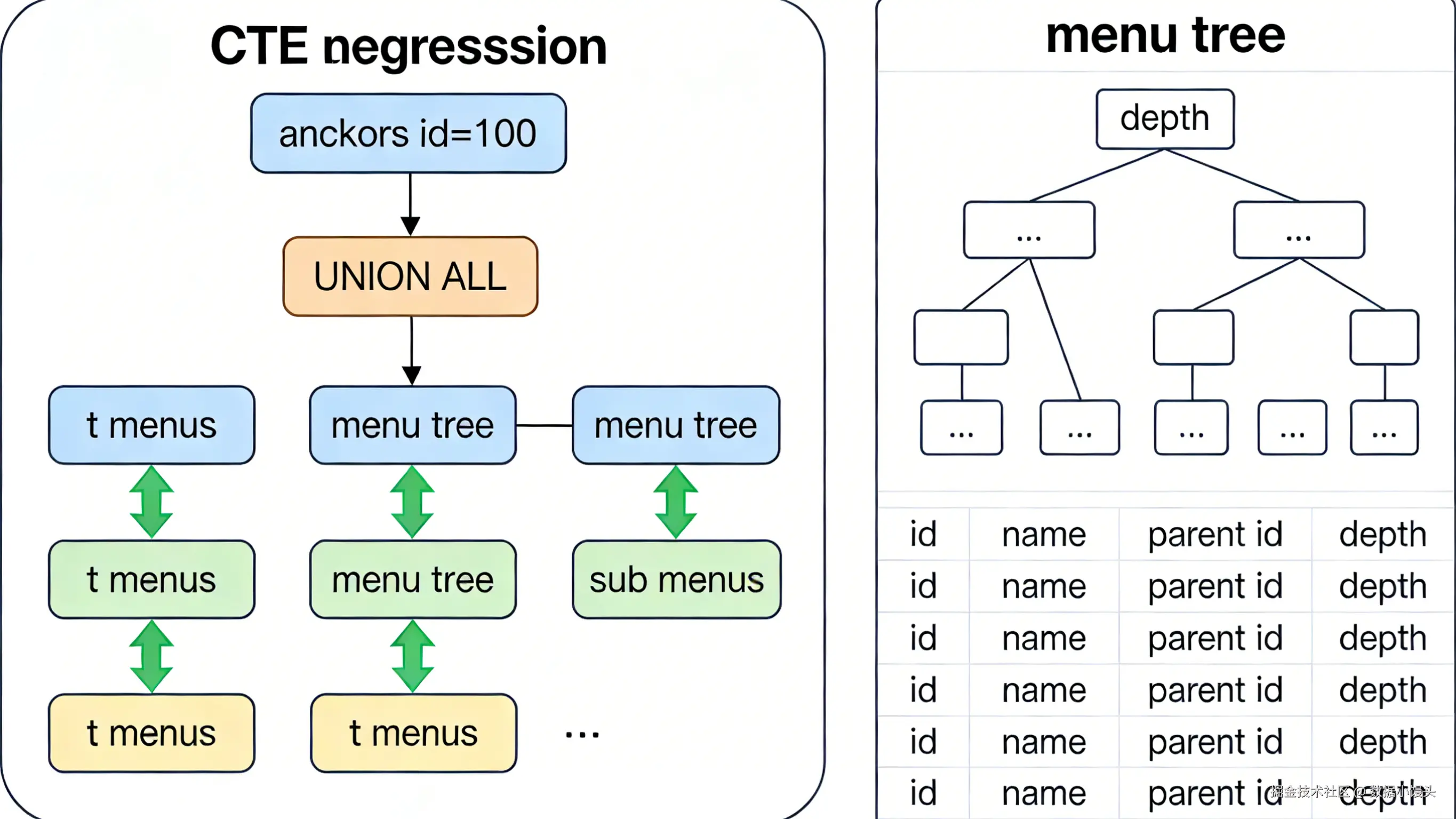
二:告别递归调用 ------ CTE 处理无限层级数据
场景需求:
一张菜单表 t_menus,包含 id 和 parent_id。需要查出"系统设置"节点下的所有子菜单(包括子菜单的子菜单...),构建树形结构。
低效解法(递归查询):
- 查出 id=1(系统设置)。
- 循环查 parent_id=1 的子节点。
- 对每个子节点,再查其子节点...
- 这是典型的 N+1 查询问题,与数据库交互次数过多,网络延迟极高。
SQL 解法:
使用 CTE(Common Table Expressions) 的递归语法 WITH RECURSIVE。
sql
WITH RECURSIVE menu_tree AS (
-- 1. 锚点成员 (Anchor Member):查询根节点
SELECT id, name, parent_id, 1 as depth
FROM t_menus
WHERE id = 100 -- 假设 100 是"系统设置"的 ID
UNION ALL
-- 2. 递归成员 (Recursive Member):基于上一轮的结果继续查
SELECT t.id, t.name, t.parent_id, mt.depth + 1
FROM t_menus t
INNER JOIN menu_tree mt ON t.parent_id = mt.id
)
SELECT * FROM menu_tree;解析:
数据库引擎在内部维护了一个临时表。第一部分(Anchor)先放入初始数据;第二部分(Recursive)引用这个临时表,不断把符合 JOIN 条件的新数据追加进来,直到没有新数据产生为止。整个过程只与数据库交互一次。
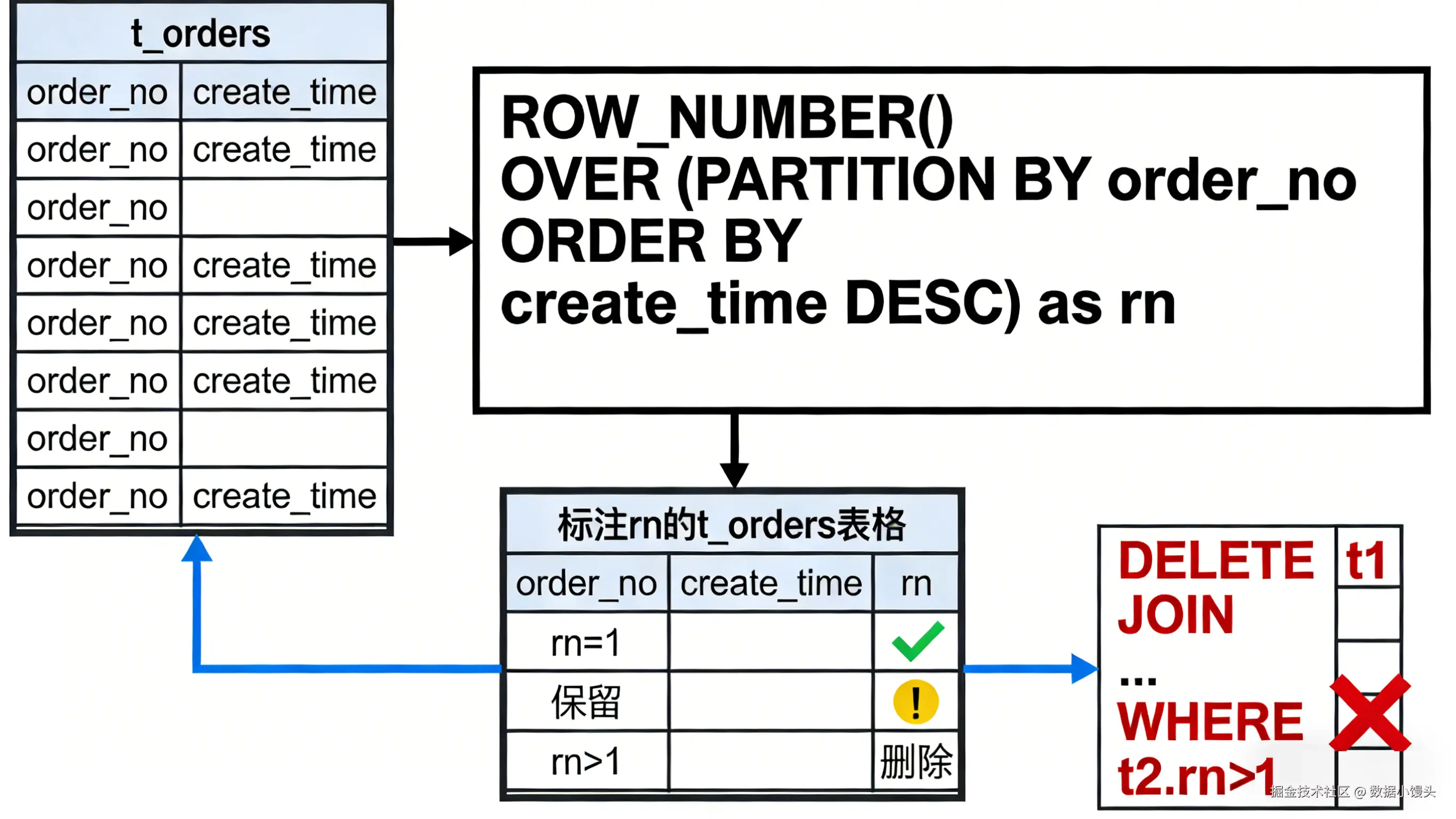
三:优雅的数据清洗 ------ 高效去重 (Dedup)
场景需求:
由于程序 Bug,t_orders 表中出现了重复订单(order_no 相同),保留 create_time 最近的一条,删除其余重复项。
低效解法(自连接):
使用 DELETE 配合 NOT IN (SELECT MAX(id)...)。这种写法在数据量大时,极易造成死锁或超时。
SQL 解法:
利用窗口函数给重复行打标,然后根据标记删除。
sql
DELETE t1 FROM t_orders t1
JOIN (
SELECT
id,
-- 按订单号分组,按时间降序排列,行号为 1 的即为最新数据
ROW_NUMBER() OVER (PARTITION BY order_no ORDER BY create_time DESC) as rn
FROM t_orders
) t2 ON t1.id = t2.id
WHERE t2.rn > 1; -- 删除行号大于 1 的(即旧数据)解析:
这种方式避免了复杂的 GROUP BY 子查询,逻辑清晰且执行效率更高。它首先在内存中计算出每一行的"留存优先级"(即 rn),然后利用 JOIN 精准定位需要删除的行 ID。
总结
SQL 不仅仅是存储数据的仓库,它更是一个高性能的集合计算引擎。
在 MySQL 8.0 等现代数据库中:
- 遇到"分组取 Top N"或 "累计统计",请优先想到 窗口函数。
- 遇到"树形结构"或 "层级遍历",请优先想到 CTE 递归。
- 遇到"复杂去重",请优先想到 ROW_NUMBER()。
将计算下推(Push Down)到数据库层,不仅能大幅减少网络传输量,还能让你的后端代码变得干净、清爽。