RAG是什么
- 检索增强生成(Retrieval-augmented Generation)
- 基础的大模型,只能知道一些公网上的信息,并且也是基于公网数据训练学习的,不可能知道我们私有的业务数据。
- 虽然function-call、SystemMessage可以用来解决一部分问题,但归根结底还是太少了,最好的办法就是给AI外接一个专业知识库。
向量
- 向量通常用来做相似性搜索,相当于一个一维坐标,语义相似的词会在附近。
- 然而,对于更复杂的对象,比如狗,是没法通过一个维度展示的。
- 这时,我们需要提取多个特征,如颜色、大小、品种等,将每个特征表示为向量的一个维度,从而形成一个多维向量
- 例如,一只棕色的小型泰迪犬可以表示为一个多维向量 棕色, 小型, 泰迪犬。

- 如果需要检索见过更加精准, 我们肯定还需要更多维度的向量, 组成更多维度的空间,在多维向量空间中,相似性检索变得更加复杂。我们需要使用一些算法,如余弦相似度或欧几里得距离,来计算向量之间的相似性。
- 但我们在应用层,可以不去接触这些算法,向量数据库会帮我们实现。
案例
-
新建一个项目,引入maven依赖
xml<dependencyManagement> <dependencies> <!-- 引入 Spring Boot BOM --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>3.4.3</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- SpringBoot 核心包 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!-- SpringBoot Web容器 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- 阿里云百炼 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId> <version>1.0.0-beta3</version> </dependency> <!-- webflux --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> <!-- langchain4j核心 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>1.0.0-beta3</version> </dependency> </dependencies> -
文本向量化(这里选用阿里云百炼的通义千问)
-
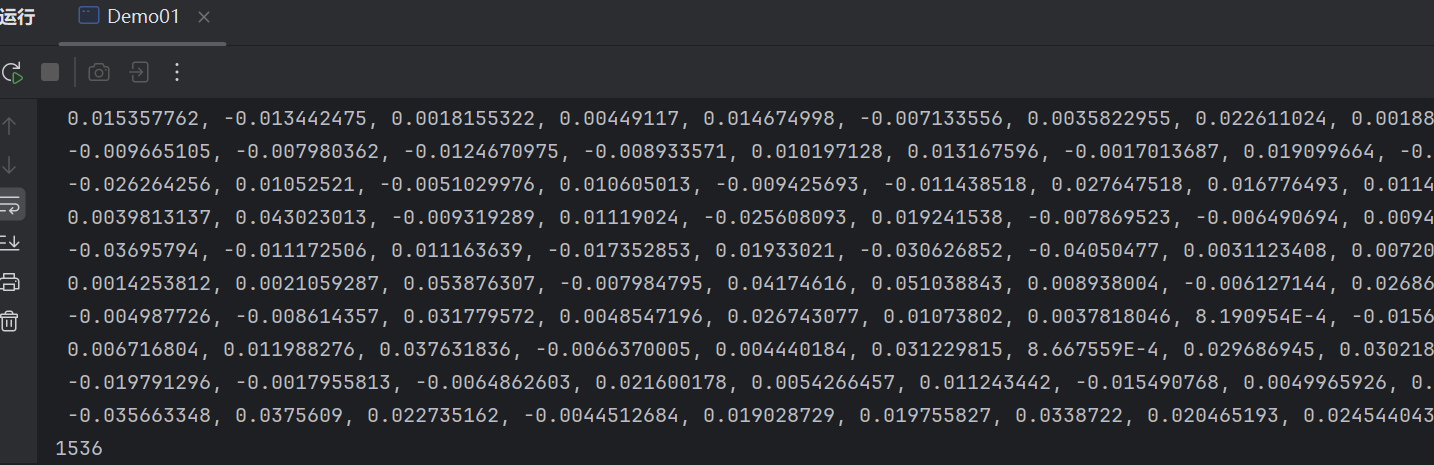
调用 embeddingModel.embed 方法,可以获取文本向量化后的数据
javaimport dev.langchain4j.community.model.dashscope.QwenEmbeddingModel; import dev.langchain4j.data.embedding.Embedding; import dev.langchain4j.model.output.Response; public class Demo01 { public static String xlKey = "sk-xxxxxxxxx"; public static void main(String[] args) { QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder() .apiKey(xlKey) .build(); Response<Embedding> embed = embeddingModel.embed("你好"); System.out.println(embed.content().toString()); System.out.println(embed.content().vector().length); } } -
结果是一个向量数组;其中每个浮点类型的数字,就是一个维度;下方的1536,表示一共有1536个维度;向量的维度越多,模型检索的精度就越高
-
向量数据库
- 文本向量值有了,现在要进行相似性检索,需要用到向量数据库
- 可以看下LangChain4j官网中,对于向量数据库的支持
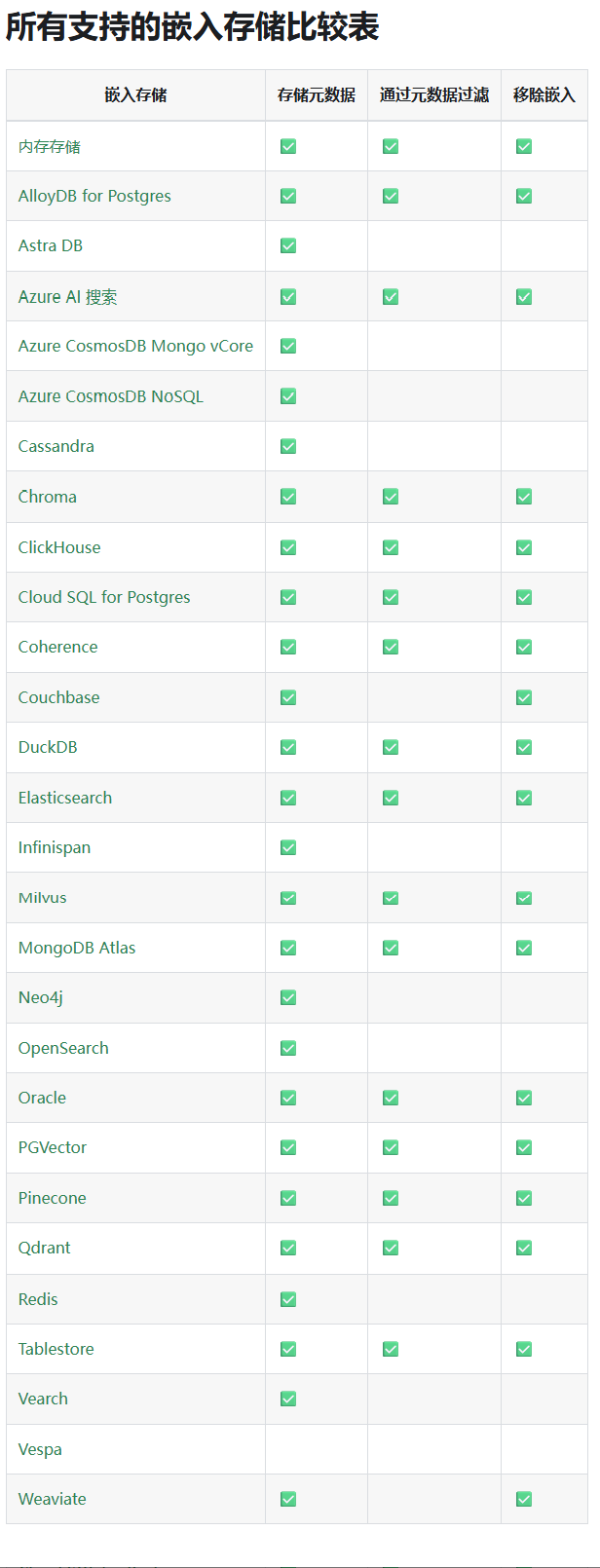
- 其中有很多我们熟悉的,Elasticsearch、Oracle、Redis等,用哪个点击进入会有详细说明
- LangChain4j官网中支持的向量数据库
相似性检索的步骤
- 首先是数据嵌入阶段(embedding),将文本、图像等数据转化为低维数值向量。
- 数据检索阶段:将问题转换为向量,然后去检索。然后把相似性的数据结合用户的提问,一起发给大模型。
- 大模型最终会结合对话和向量信息,返回给用户。
案例
-
这里我们使用最简单的内存存储 ,即In-memory
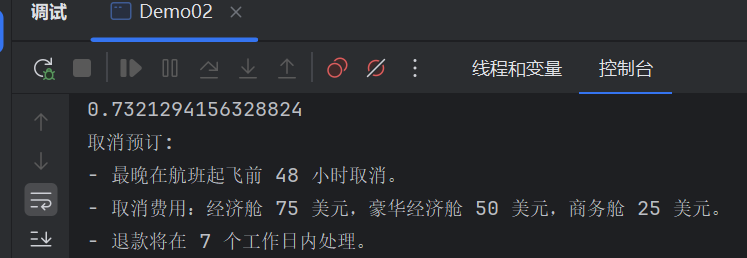
javaimport dev.langchain4j.community.model.dashscope.QwenEmbeddingModel; import dev.langchain4j.data.embedding.Embedding; import dev.langchain4j.data.segment.TextSegment; import dev.langchain4j.store.embedding.EmbeddingSearchRequest; import dev.langchain4j.store.embedding.EmbeddingSearchResult; import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore; public class Demo02 { public static void main(String[] args) { InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder() .apiKey("sk-xxxxxx") .build(); // 利用向量模型进行向量化, 然后存储向量到向量数据库 TextSegment segment1 = TextSegment.from(""" 预订航班: - 通过我们的网站或移动应用程序预订。 - 预订时需要全额付款。 - 确保个人信息(姓名、ID 等)的准确性,因为更正可能会产生 25 的费用。 """); Embedding embedding1 = embeddingModel.embed(segment1).content(); embeddingStore.add(embedding1, segment1); // 利用向量模型进行向量化, 然后存储向量到向量数据库 TextSegment segment2 = TextSegment.from(""" 取消预订: - 最晚在航班起飞前 48 小时取消。 - 取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。 - 退款将在 7 个工作日内处理。 """); Embedding embedding2 = embeddingModel.embed(segment2).content(); embeddingStore.add(embedding2, segment2); // 需要查询的内容 向量化 Embedding queryEmbedding = embeddingModel.embed("退票要多少钱").content(); // 去向量数据库查询 // 构建查询条件 EmbeddingSearchRequest build = EmbeddingSearchRequest.builder() .queryEmbedding(queryEmbedding) .maxResults(1)//取最符合的几条数据,这里是1条 .minScore(0.6)//只有符合0.6的才会选用,也可以不设置 .build(); // 查询 EmbeddingSearchResult<TextSegment> segmentEmbeddingSearchResult = embeddingStore.search(build); segmentEmbeddingSearchResult.matches().forEach(embeddingMatch -> { System.out.println(embeddingMatch.score()); // 0.8144288515898701 System.out.println(embeddingMatch.embedded().text()); // I like football. }); } } -
运行结果
-
可以看到AI将最符合的返回了,相似度为73.2%
知识库RAG演练
实现逻辑
- 知识库存储
- 文档读取
- 通过分割器将文档切片为文本集合
- 利用向量模型,将切片转化为向量
- 将向量存储到数据库
- 智能对话
- 用户的问题转化为向量
- 用向量从数据库中检索数据
- 把检索后的数据和用户的对话一起传到AI大模型
- AI大模型返回数据
Document Parser 文档解析器
- 要开发一个知识库,这些资料可能存在各种文档中,比如:word、txt、pdf、image、html等等, 所以langchain4j也提供了不同的文档解析器(不满足的时候也可以自定义解析器):
- TextDocumentParser:来自 langchain4j 模块,可解析 TXT、HTML、MD 等纯文本格式文件。
- ApachePdfBoxDocumentParser:来自 langchain4j-document-parser-apache-pdfbox 模块,用于解析 PDF 文件。
- ApachePoiDocumentParser:来自 langchain4j-document-parser-apache-poi 模块,支持解析 DOC、DOCX、PPT、PPTX、XLS、XLSX 等 MS Office 文件格式。
- ApacheTikaDocumentParser:来自 langchain4j-document-parser-apache-tika 模块,能自动检测并解析几乎所有现有文件格式。
- 代码实现文档解析器
-
实现从类路径(resources)下读取文件;使用 TextDocumentParser
-
resourcesx下新建一个txt文件:cs.txt
txt- 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元, 商务舱 25 美元。退款将在 7 个工作日内处理。 -
java代码
javaimport dev.langchain4j.data.document.Document; import dev.langchain4j.data.document.loader.ClassPathDocumentLoader; import dev.langchain4j.data.document.parser.TextDocumentParser; public class Demo03 { public static void main(String[] args) { //文档读取 Document document = ClassPathDocumentLoader. loadDocument("demo03/cs.txt", new TextDocumentParser()); String text = document.text(); System.out.println(text); } } -
控制台

-
DocumentSplitter 文档拆分器
- 目的:要保证同一个主题保存在一个片段当中,不要出现断句
- 作用
- 文本读取到之后,按语义分成一段一段,每一块叫chunk
- 在后面可以更精确地进行语义相似性检索
- 可以避免LLM的最大Token限制
- langchain4j也提供了不同的文档拆分器
- 下面这些内置分割器都实现了一个split方法用来分隔
- DocumentByCharacterSplitter
- 无符号分割
- 就是严格根据字数分隔(不推荐,会出现断句)
- DocumentByRegexSplitter
- 正则表达式分隔
- 根据自定义正则分隔
- DocumentByParagraphSplitter
- 删除大段空白内容
- 处理连续换行符(如段落分隔)(\s*(?>\R)\s*(?>\R)\s*
- DocumentByLineSplitter
- 删除单个换行符周围的空白, 替换一个换行
- (\s*\R\s*)
- 示例:
- 输入文本:"This is line one.\n\tThis is line two."
- 使用 \s*\R\s* 替换为单个换行符:"This is line one.\nThis is line two."
- DocumentByWordSplitter
- 删除连续的空白字符。
- \s+
- 示例
- 输入文本:"Hello World"
- 使用 \s+ 替换为单个空格:"Hello World"
- DocumentBySentenceSplitter
- 按句子分割
- 该分割器使用Apache OpenNLP 库中的一个类,用于检测文本中的句子边界。它能够识别标点符号(如句号、问号、感叹号等)是否标记着句子的末尾,从而将一个较长的文本字符串分割成多个句子。
- 不管是哪个,依旧会优先单块字数,所以要设置长一点(但也不能太大,会导致检索精度下降;而且大模型有最大token数限制)
演示 DocumentByCharacterSplitter
-
java代码,还是在之前的基础上
javaimport dev.langchain4j.data.document.Document; import dev.langchain4j.data.document.loader.ClassPathDocumentLoader; import dev.langchain4j.data.document.parser.TextDocumentParser; import dev.langchain4j.data.document.splitter.DocumentByCharacterSplitter; import dev.langchain4j.data.segment.TextSegment; import java.util.List; public class Demo03 { public static void main(String[] args) { //文档读取 Document document = ClassPathDocumentLoader. loadDocument("demo03/cs.txt", new TextDocumentParser()); // String text = document.text(); // System.out.println(text); DocumentByCharacterSplitter splitter = new DocumentByCharacterSplitter( 20, // 每段最长字数 10 // 自然语言最大重叠字数 ); List<TextSegment> segments = splitter.split(document); System.out.println(segments); } } -
可以看到被分成了4份

-
查看这个构造方法

-
可以看到不怎么好用,如果选用按分割符分割呢?
分割符分割(正则)
-
在使用按字符切分时,需要指定分割符,另外需要指定块的大小以及块之间重叠的大小(允许重叠是为了尽可能地避免按照字符进行分割造成的语义损失)。
-
chunk_size(块大小)指的就是我们分割的字符块的大小;
-
chunk_overlap(块间重叠大小)就是下图中加深的部分,上一个字符块和下一个字符块重叠的部分,即上一个字符块的末尾是下一个字符块的开始。

-
比如:
- 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元, 商务舱 25 美元。退款将在 7 个工作日内处理。 按照chunksize可能会分隔成: -最晚在航班起飞前 48 小时取消。取消费用:经济舱 7 5 美元,豪华经济舱...... 如果设置了重叠可能会: -最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。 -取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。退款将在 7 个工作日内处理。 -
整个流程如下
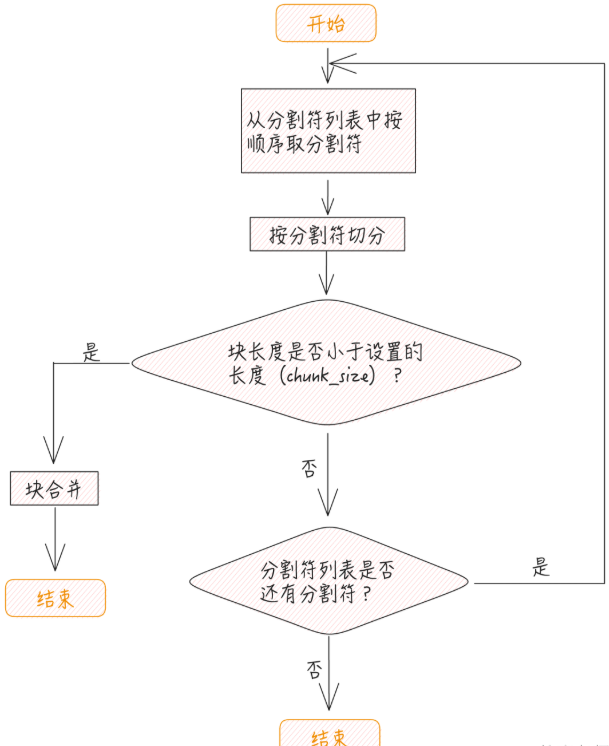
- 首先按照指定的分割符进行切分,切分过之后,如果块本身的长度小于 chunk_size 的大小,则触发合并逻辑。在进行合并时,遵循下面的规则:
- 如果相邻块加在一起的长度小于或等于chunk_size,则进行合并;
- 在进行合并时,如果重叠部分长度 小于或等于chunk_overlap,并且和前后两个相邻块合并后,两个合并后的块均不超过chunk_size,则两个合并后的块允许有重叠
- 首先按照指定的分割符进行切分,切分过之后,如果块本身的长度小于 chunk_size 的大小,则触发合并逻辑。在进行合并时,遵循下面的规则:
-
如果分割后每个块均大于 chunk_size,则必须要有子分割器,如果没有则报错
-
代码示例
-
txt文件:demo04/cs.txt
1.- 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。退款将在 7 个工作日内处理。 2.- 在航班起飞前 72小时(包括)~48小时(不包括)之间取消。取消费用:经济舱 30 美元,豪华经济舱 20 美元,商务舱 10 美元。退款将在 7 个工作日内处理。 3.- 在航班起飞前 72小时(不包括)之间取消。取消费用:经济舱 50 美元,豪华经济舱 5 美元,商务舱 5 美元。退款将在 7 个工作日内处理。 -
java代码
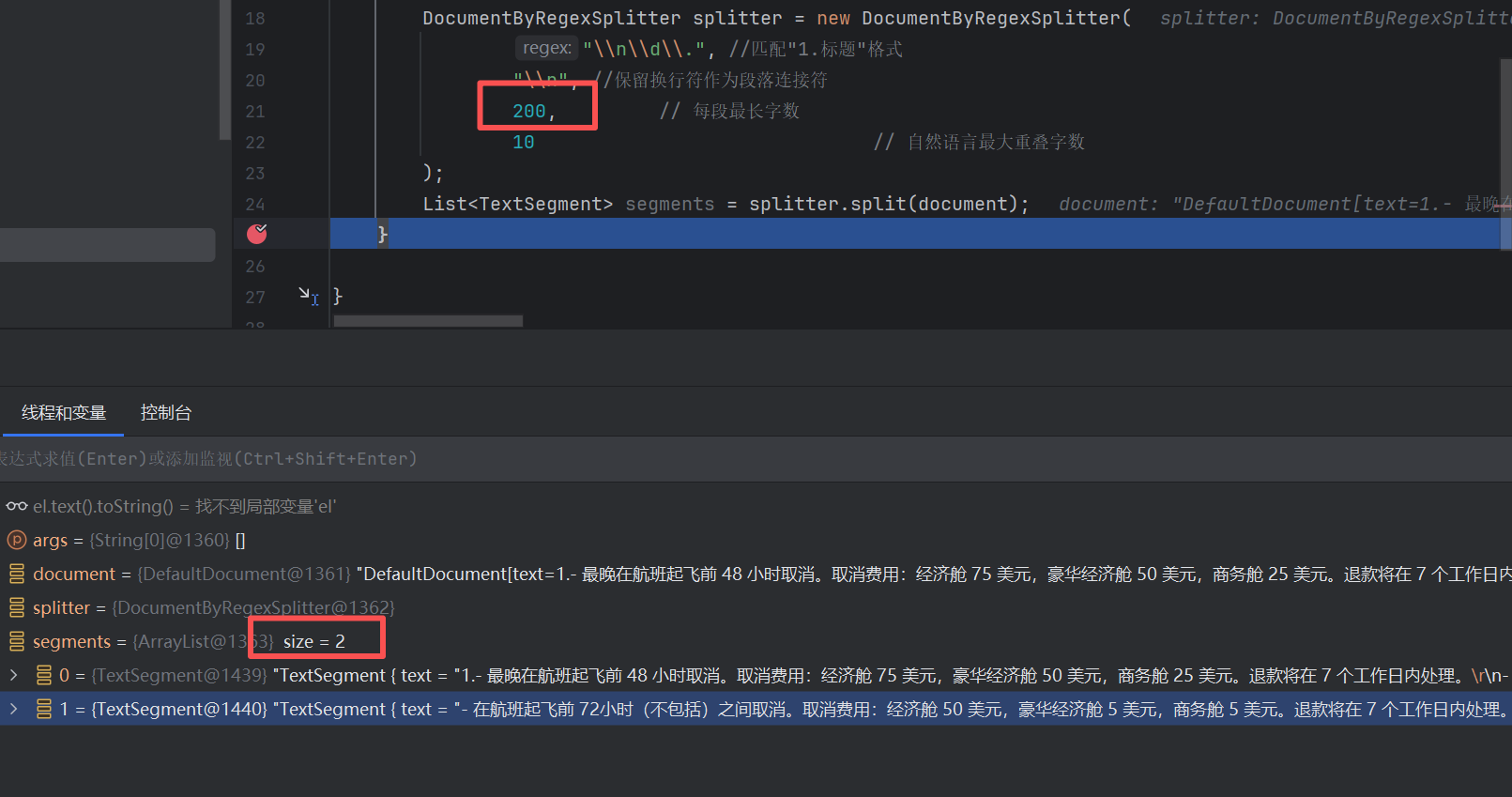
javaimport dev.langchain4j.data.document.Document; import dev.langchain4j.data.document.loader.ClassPathDocumentLoader; import dev.langchain4j.data.document.parser.TextDocumentParser; import dev.langchain4j.data.document.splitter.DocumentByRegexSplitter; import dev.langchain4j.data.segment.TextSegment; import java.util.List; public class Demo04 { public static void main(String[] args) { //文档读取 Document document = ClassPathDocumentLoader. loadDocument("demo04/cs.txt", new TextDocumentParser()); DocumentByRegexSplitter splitter = new DocumentByRegexSplitter( "\\n\\d\\.", //匹配 换行+"1. 这样的标题"格式 "\\n", //保留换行符作为段落连接符 200, // 每段最长字数 10 // 自然语言最大重叠字数 ); List<TextSegment> segments = splitter.split(document); } } -
设置为200的话,可以看到最终还是被分割成了两块
-
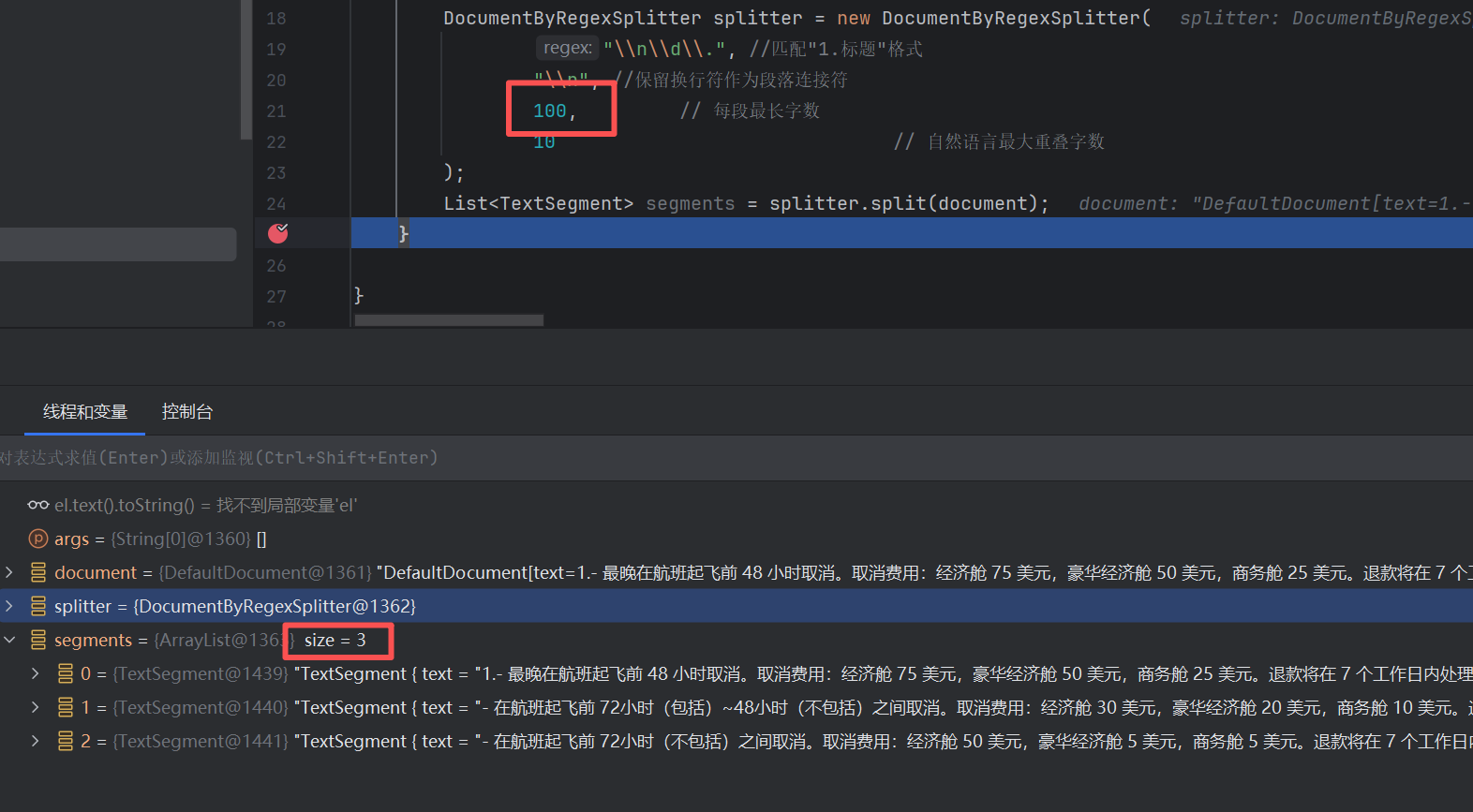
设置为100的话,就正确分割成了三块
-
分隔经验
- 过细分块的潜在问题
- 语义割裂: 破坏上下文连贯性,影响模型理解 。
- 计算成本增加:分块过细会导致向量嵌入和检索次数增多,增加时间和算力开销。
- 信息冗余与干扰:碎片化的文本块可能引入无关内容,干扰检索结果的质量,降低生成答案的准确性。
- 分块过大的弊端
- 信息丢失风险:过大的文本块可能超出嵌入模型的输入限制,导致关键信息未被有效编码。
- 检索精度下降:大块内容可能包含多主题混合,与用户查询的相关性降低,影响模型反馈效果。
- 按场景经验总结
- 微博/短文本
- 句子级分块,保留完整语义
- 每块100-200字符
- 学术论文
- 段落级分块,叠加10%重叠
- 每块300-500字符
- 法律合同
- 条款级分块,严格按条款分隔
- 每块200-400字符
- 长篇小说
- 章节级分块,过长段落递归拆分为段落
- 每块500-1000字符
- 微博/短文本
- 总体常用设置
- 固定长度分块
- 字符数范围:通常建议每块控制在 100-500字符(约20-100词),以平衡上下文完整性与检索效率。
- 重叠比例:相邻块间保留 10-20%的重叠内容(如块长500字符时重叠50-100字符),减少语义断层。
- 语义分块
- 段落或章节:优先按自然段落、章节标题划分,保持逻辑单元完整。
- 动态调整:对于长段落,可递归分割为更小单元(如先按段落分块,过长时再按句子拆分)。
- 专业领域调整
- 高信息密度文本(如科研论文、法律文件):采用更细粒度分块(100-200字符),保留专业术语细节。
- 通用文本(如新闻、社交媒体):适当放宽分块大小(300-500字符)
- 固定长度分块
文本向量化
- 通过向量模型库进行向量化
- 在上文向量数据库的案例中已经演示过了
java
TextSegment segment1 = TextSegment.from("""
需要向量化的片段内容
""");
//利用
向量模型进行向量化
QwenEmbeddingModel embeddingModel= QwenEmbeddingModel.builder()
.apiKey("sk-xxxxxxxxxxxxx")
.build();
Embedding embedding1 = embeddingModel.embed(segment1).content();
//存储向量到向量数据库
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
embeddingStore.add(embedding1, segment1);用户的问题转化为向量、用向量从数据库中检索数据
-
在上文向量数据库的案例中已经演示过了
java// 需要查询的内容 向量化 Embedding queryEmbedding = embeddingModel.embed("退票要多少钱").content(); // 构建查询条件 EmbeddingSearchRequest build = EmbeddingSearchRequest.builder() .queryEmbedding(queryEmbedding) .maxResults(1)//取最符合的几条数据,这里是1条 .minScore(0.6)//只有符合0.6的才会选用,也可以不设置 .build(); // 查询 EmbeddingSearchResult<TextSegment> segmentEmbeddingSearchResult = embeddingStore.search(build); -
或者
java// 需要查询的内容 向量化 Response<Embedding> embed = embeddingModel.embed("退费费用"); // 构建查询条件 EmbeddingSearchRequest build = EmbeddingSearchRequest.builder() .queryEmbedding(embed.content()) .maxResults(1)//取最符合的几条数据,这里是1条 .minScore(0.6)//只有符合0.6的才会选用,也可以不设置 .build(); // 查询 EmbeddingSearchResult<TextSegment> segmentEmbeddingSearchResult = embeddingStore.search(build);
将匹配到的向量和用户提问一起发给大模型
-
就是检索增强
-
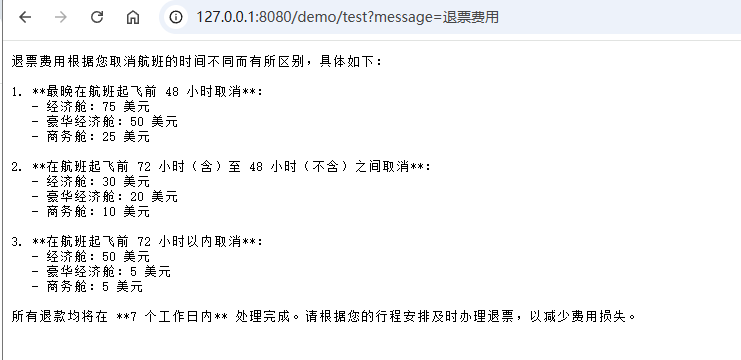
在 第三章-数据来源 中有体现
-
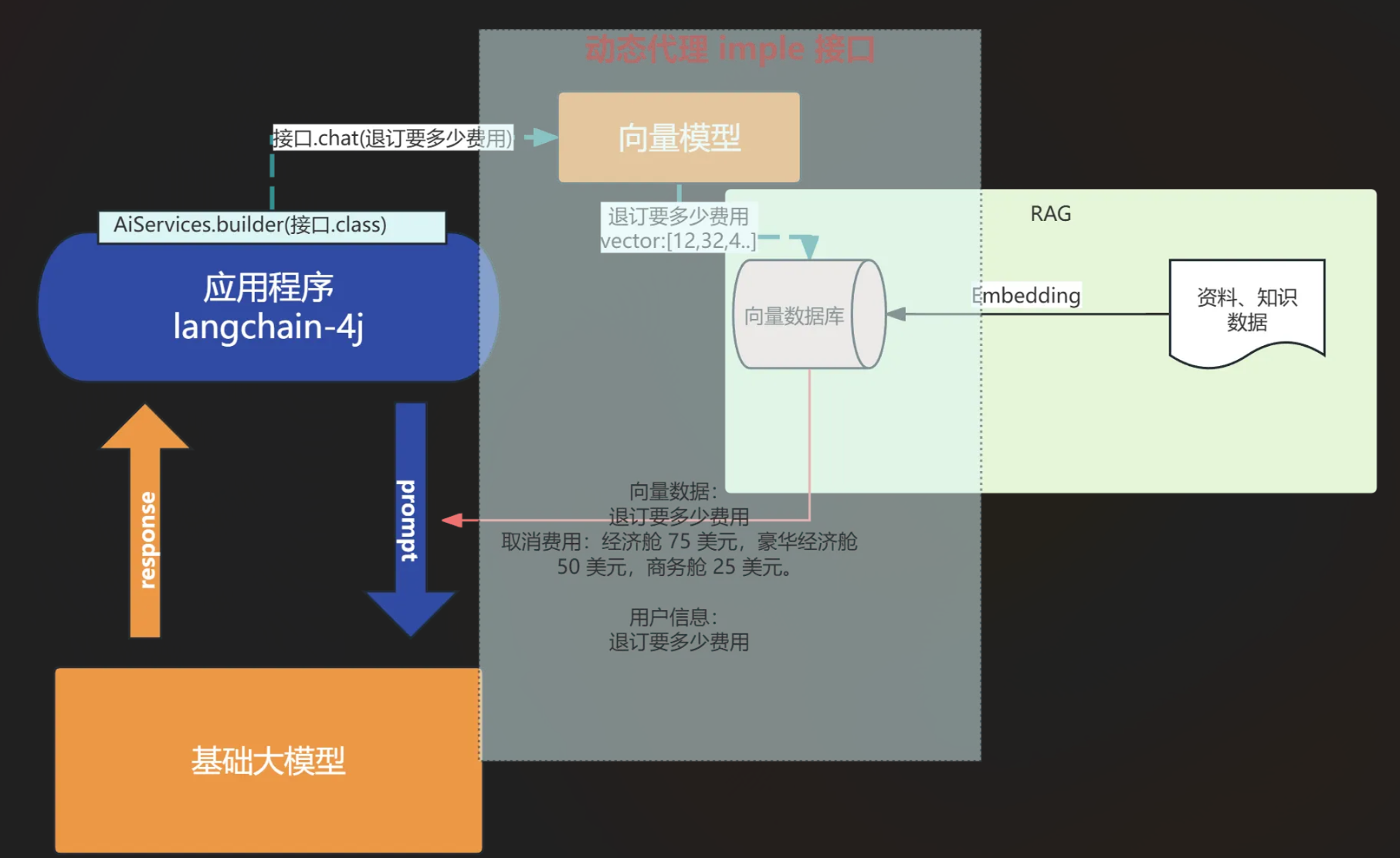
利用框架中的AiServices即可实现
java...... interface Assistant { String chat(String message); } ChatLanguageModel model = QwenChatModel .builder() .apiKey("sk-xxxxxxx") .modelName("qwen-max") .build(); ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.build .embeddingStore(embeddingStore) //向量数据库 .embeddingModel(embeddingModel) //向量模型 .maxResults(5) // 最相似的5个结果 .minScore(0.6) // 只找相似度在0.6以上的内容 .build(); // 为Assistant动态代理对象 chat ---> 对话内容存储ChatMemory----> 聊天记录ChatMemory取出来 Assistant assistant = AiServices.builder(Assistant.class) .chatLanguageModel(model) .contentRetriever(contentRetriever) //内容检索器 .build(); System.out.println("用户开始询问退费费用"); System.out.println(assistant.chat("退费费用")); -
控制台
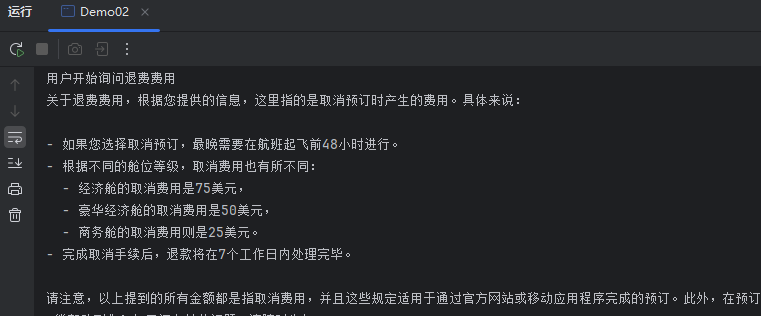
-
AiService向量检索原理
整合Springboot
-
新建一个项目
-
pom.xml
xml<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.qi</groupId> <artifactId>LangChain4j_demo04_2</artifactId> <version>1.0-SNAPSHOT</version> <name>Archetype - LangChain4j_demo04_2</name> <url>http://maven.apache.org</url> <dependencyManagement> <dependencies> <!-- 引入 Spring Boot BOM --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>3.4.3</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- SpringBoot 核心包 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!-- SpringBoot Web容器 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- 阿里云百炼 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId> <version>1.0.0-beta3</version> </dependency> <!-- webflux --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> <!-- langchain4j核心 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>1.0.0-beta3</version> </dependency> </dependencies> </project> -
application.yml
ymllangchain4j: community: dashscope: chatModel: api-key: "sk-xxxxxx" model-name: qwen-plus streaming-chat-model: api-key: "sk-xxxxxx" model-name: qwen-plus embedding-model: api-key: "sk-xxxxxx" # model-name: -
Application
javapackage com.qi.demo; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); System.out.println("----------------项目启动成功----------------"); } } -
resources/demo/cs.txt
1.- 最晚在航班起飞前 48 小时取消。取消费用:经济舱 75 美元,豪华经济舱 50 美元,商务舱 25 美元。退款将在 7 个工作日内处理。 2.- 在航班起飞前 72小时(包括)~48小时(不包括)之间取消。取消费用:经济舱 30 美元,豪华经济舱 20 美元,商务舱 10 美元。退款将在 7 个工作日内处理。 3.- 在航班起飞前 72小时(不包括)之间取消。取消费用:经济舱 50 美元,豪华经济舱 5 美元,商务舱 5 美元。退款将在 7 个工作日内处理。 -
AssistantConfig
javapackage com.qi.demo.config; import com.qi.demo.Application; import dev.langchain4j.community.model.dashscope.QwenEmbeddingModel; import dev.langchain4j.data.document.Document; import dev.langchain4j.data.document.DocumentParser; import dev.langchain4j.data.document.loader.FileSystemDocumentLoader; import dev.langchain4j.data.document.parser.TextDocumentParser; import dev.langchain4j.data.document.splitter.DocumentByLineSplitter; import dev.langchain4j.data.embedding.Embedding; import dev.langchain4j.data.segment.TextSegment; import dev.langchain4j.memory.ChatMemory; import dev.langchain4j.memory.chat.MessageWindowChatMemory; import dev.langchain4j.model.chat.ChatLanguageModel; import dev.langchain4j.model.chat.StreamingChatLanguageModel; import dev.langchain4j.rag.content.retriever.ContentRetriever; import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever; import dev.langchain4j.service.AiServices; import dev.langchain4j.service.TokenStream; import dev.langchain4j.store.embedding.EmbeddingStore; import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore; import org.springframework.boot.CommandLineRunner; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import java.net.URISyntaxException; import java.nio.file.Path; import java.nio.file.Paths; import java.util.List; @Configuration public class AssistantConfig { public interface Assistant { String chat(String message); // 流式响应 TokenStream stream(String message); } //向量数据库 @Bean public InMemoryEmbeddingStore<TextSegment> embeddingStore (){ return new InMemoryEmbeddingStore<>(); } @Bean public Assistant assistant(ChatLanguageModel qwenChatModel, StreamingChatLanguageModel qwenStreamingChatModel, // ToolsService toolsService, EmbeddingStore embeddingStore, QwenEmbeddingModel qwenEmbeddingModel) { ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10); ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder() .embeddingStore(embeddingStore) .embeddingModel(qwenEmbeddingModel) .maxResults(5) // 最相似的5个结果 .minScore(0.6) // 只找相似度在0.6以上的内容 .build(); Assistant assistant = AiServices.builder(Assistant.class) .chatLanguageModel(qwenChatModel) .streamingChatLanguageModel(qwenStreamingChatModel) // .tools(toolsService) .contentRetriever(contentRetriever) .chatMemory(chatMemory) .build(); return assistant; } //提前存储向量数据到向量数据库 @Bean CommandLineRunner ingestTermOfServiceToVectorStore(QwenEmbeddingModel qwenEmbeddingModel, EmbeddingStore embeddingStore) throws URISyntaxException { // 读取 Path documentPath = Paths.get(Application.class.getClassLoader().getResource("demo/cs.txt").toURI()); return args -> { DocumentParser documentParser = new TextDocumentParser(); Document document = FileSystemDocumentLoader.loadDocument(documentPath, documentParser); DocumentByLineSplitter splitter = new DocumentByLineSplitter( 500, 200 ); List<TextSegment> segments = splitter.split(document); // 向量化 List<Embedding> embeddings = qwenEmbeddingModel.embedAll(segments).content(); // 存入 embeddingStore.addAll(embeddings,segments); }; } } -
DemoController
javapackage com.qi.demo.controller; import com.qi.demo.config.AssistantConfig; import dev.langchain4j.service.TokenStream; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import reactor.core.publisher.Flux; @RequestMapping("/demo") @RestController public class DemoController { @Autowired private AssistantConfig.Assistant assistant; @RequestMapping(value = "/test",produces ="text/stream;charset=UTF-8") public Flux<String> test1(@RequestParam("message") String message) { TokenStream stream = assistant.stream(message); return Flux.create(sink -> { stream.onPartialResponse(s -> sink.next(s)) .onCompleteResponse(c -> sink.complete()) .onError(sink::error) .start(); }); } } -
调用接口