文章目录
- 前言
- 一、LightRAG
- 二、部署
-
- [1.PyCharm 配置、安装 bun](#1.PyCharm 配置、安装 bun)
- [2.安装LightRAG服务器 、Core 和运行lightrag-server](#2.安装LightRAG服务器 、Core 和运行lightrag-server)
- 3.WEBUI界面
-
- [3.1 文档管理](#3.1 文档管理)
- [3.2 知识图库](#3.2 知识图库)
- [3.3 检索Retrieval](#3.3 检索Retrieval)
- [3.4 API管理](#3.4 API管理)
- 三、总结
- 四、技术文献
-
- [传统 RAG](#传统 RAG)
- [Microsoft GraphRAG:](#Microsoft GraphRAG:)
- LightRAG
-
- [LightRAG 与 NaiveRAG 和 GraphRAG 有何不同?](#LightRAG 与 NaiveRAG 和 GraphRAG 有何不同?)
- [LightRAG 解决 GraphRAG 的两个主要痛点?](#LightRAG 解决 GraphRAG 的两个主要痛点?)
- [LightRAG 特点](#LightRAG 特点)
-
- 1.基于图的文本索引
- 2.双重-层级检索范式
- [3.LightRAG 如何利用知识图谱?](#3.LightRAG 如何利用知识图谱?)
- [4.Indexing 索引](#4.Indexing 索引)
- [5.Incremental Indexing 增量索引](#5.Incremental Indexing 增量索引)
- [6.Querying 查询](#6.Querying 查询)
前言
LightRAG webui本地部署、应用
一、LightRAG
二、部署
工具
- python 3.10.5
- PyCharm
- LightRAG-1.4.9.10
- Window11
1.PyCharm 配置、安装 bun
配置python 环境3.10.5 ,PyCharm 打开 LightRAG-1.4.9.10 源代码
PyCharm 终端p owershell 安装 bun powershell 命令
powershell
powershell -c "irm bun.sh/install.ps1|iex"
2.安装LightRAG服务器 、Core 和运行lightrag-server
python
pip install "lightrag-hku[api]"
pip install lightrag-hku
# 构建前端代码
cd lightrag_webui
bun install --frozen-lockfile
bun run build
cd ..
# 配置 env 文件
cp env.example .env # 使用你的LLM和Embedding模型访问参数更新.env文件
# 启动API-WebUI服务
lightrag-server .env文件修改LLM模型和Embedding模型
yaml
### 184行:LLM Configuration - aliyuncs【qwen3-max】
LLM_BINDING=openai
LLM_MODEL=qwen3-max
LLM_BINDING_HOST=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_BINDING_API_KEY=sk-XXXXXXXXXXXXXXX
......
### OpenAI compatible embedding - aliyuncs【text-embedding-v1]
EMBEDDING_BINDING=openai
EMBEDDING_MODEL=text-embedding-v1
EMBEDDING_DIM=1536 ### 不同的embedding 模型嵌入向量的维度值不一样
EMBEDDING_SEND_DIM=false
EMBEDDING_TOKEN_LIMIT=8192
EMBEDDING_BINDING_HOST=https://dashscope.aliyuncs.com/compatible-mode/v1
EMBEDDING_BINDING_API_KEY=sk-XXXXXXXXXXXXXXX3.WEBUI界面
webui首页 http://127.0.0.1:9621/webui/#/
3.1 文档管理

文档矢量化分 4 段:原始文档变成可检索的向量结构,大致会经过:
- 文档预处理 & 分块
- 文本块的向量化和存储
- 基于 LLM 从文本块中抽取实体与关系
- 为实体描述 / 关系描述生成向量,并存入向量库
生成的文件说明:
文本块向量:对 chunk 内容做 embedding,存入 chunks 向量表(如 vdb_chunks.json)
实体描述向量:对实体的文本描述做 embedding,存入 entities 向量表(vdb_entities.json)
关系描述向量:对关系的文本描述做 embedding,存入 relationships 向量表(vdb_relationships.json)
知识图谱:保存结构化实体与关系,如graph_chunk_entity_relation.graphml 等
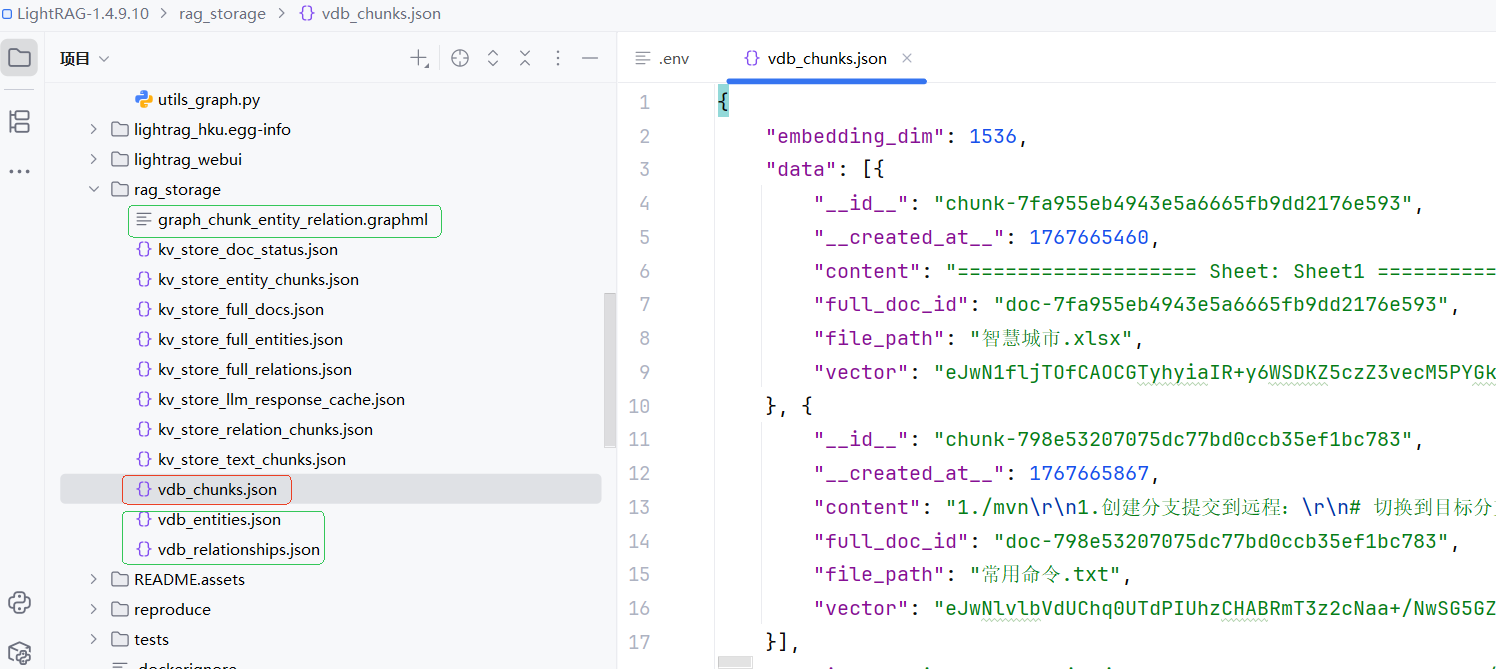
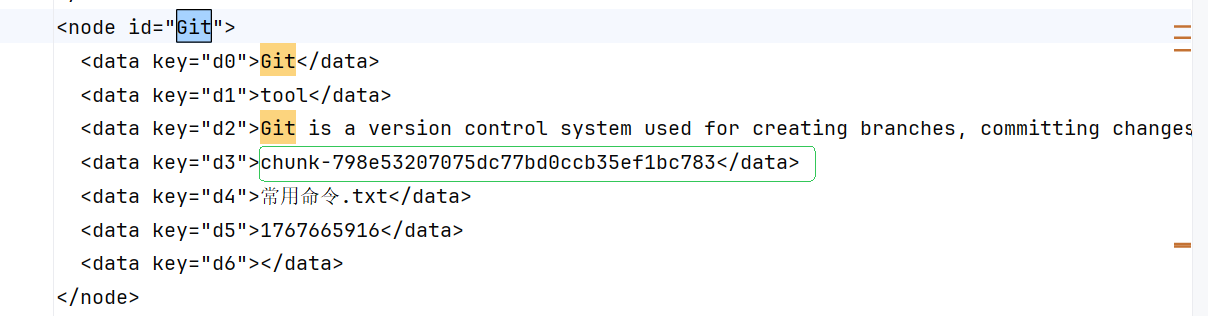
附:上传的文件:常用命令.txt
markup
1.创建分支提交到远程:
# 切换到目标分支
git checkout prod_20241230chenjunok
# 添加所有修改的文件到暂存区
git add .
# 提交更改
git commit -m "release问题修复"
# 推送到远程仓库
git push origin release_fix_chenjun
2.重置下拉代码:
git pull origin V2.1_chenjun
git fetch --all
git reset --hard origin/V2.1
D:\companyProject\employeeResign3.2 知识图库
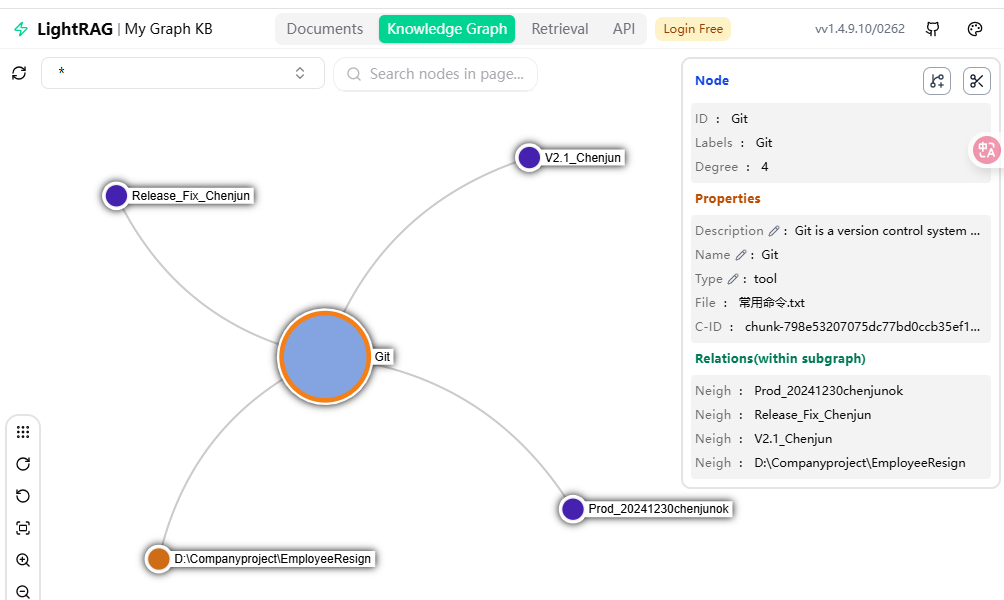
3.3 检索Retrieval
输入 "重置下拉代码", 检索 上传的文件:常用命令.txt 并 响应。

3.4 API管理
三、总结
LightRAG 在构建 RAG 系统方面提供了相对完整的解决方案。相比传统的纯向量检索,它的核心特点是引入了知识图谱,能把非结构化文本组织成实体-关系网络,这种混合检索策略(语义向量+图谱关系)确实能让 LLM 获得更丰富的上下文信息。
LightRAG 是一种基于 GraphRAG 的创新方法,结合了知识图谱的属性与基于嵌入的检索系统,使其既快速又高效,实现了 SOTA (最先进的技术方案)结果。它在多个基准测试中都优于 naive RAG 和 GraphRAG。
四、技术文献
传统 RAG 系统的局限性 Limitations of Traditional RAG Systems
传统 RAG
- 存在显著局限性,包括依赖扁平的数据表示 和上下文意识 不足,可能导致答案支离破碎,未能捕捉复杂的相互依赖关系。
- 当数据语料库增长时,会出现可扩展性低效,导致检索质量差
解决办法:文本索引和检索过程中融入图结构,如 Microsoft GraphRAG
Naive RAG Workflow

Microsoft GraphRAG:
知识图谱是由一组节点组成的数据结构,这些节点保留了不同实体之间存在于不同数据点之间的关系。结构化知识图谱使 GraphRAG(Edge 等人)能够通过连接点或对比信息片段,在多跳推理中表现出色。
GraphRAG 流水线 涉及索引和查询,即:
1. Indexing -- GraphRAG 索引
第一阶段 : 知识图谱(KG)创建:GraphRAG 依赖于精心设计的提示词prompt和多部分的采集检定,使用 LLM 从源文档中提取实体和关系,构建增量结构化的 KG。
第二阶段 : 语义聚类:基于节点连接密度和可扩展性,应用莱顿算法通过将密切相关的节点分组为层级簇来发现模块化群体。群体划分用于将图索引划分为元素组(节点、边、协变量),LLM 可以在索引和查询时并行汇总这些元素,通过关注高度相关的群落而非整个图,高效地减少搜索空间。利用大型语言模型,这些社区通过自下而上的方法进行总结,作为描述符,完全覆盖了图索引。
2. Querying -- GraphRAG 查询
查询阶段,当用户提出问题时,查询中的实体和关系会被识别出来用于 QFS(Query-Focused Summarization查询相关的摘要)。通过比较问题与图索引之间的这些元素,可以识别出最相关的社区。
然后这些社区总结会被随机洗牌,LLM 生成不同社区层级 (本地或全球层面)的中间回复,并匹配 0 到 100 的帮助度评分。该分数表明生成答案与用户查询的相关性。最终的全局答案采用多阶段地图缩减法生成,将中间部分反应汇总,依据帮助度评分作为 LLM 的上下文,按顺序递减排序。
3. GraphRAG 的缺点
- GraphRAG 运行起来通常非常慢 ,因为它需要多个 LLM API 调用,可能会遇到速率限制。
- 非常昂贵 。基于测试的网络社区显示,使用 GPT4时,索引简单书籍《狄更斯的圣诞颂歌》可能花费 6-7 美元,且有 3.2 万字 。
- 要将新数据纳入现有图索引,我们也需要重建整个 KG 的旧数据,这是一种低效的方法。
- 没有对重复元素进行显式的去重步骤,导致图索引噪声较大。
尽管 GraphRAG 看起来很有前景,但由于运营成本和计算复杂性,它并不是一个高效的解决方案。
LightRAG
一个简单、快速且高效的图 x RAG。LightRAG 通过将文档分割成更小、更易管理的块块 Di 来增强检索过程。
这种分块策略使得快速识别相关内容,无需逐一浏览整个文档。 LightRAG 与 NaiveRAG 和 GraphRAG 有何不同?
全面的信息检索,提供多元答案。
高效且低成本的检索
快速适应数据,并以最小的重新索引方式更新数据。
LightRAG 解决 GraphRAG 的两个主要痛点?
通过比社区穿越更好的方法,减少索引和响应时间。
通过增量更新算法,只更新特定元素实例,轻松适应新数据。LightRAG 特点
1.基于图的文本索引
结合了图索引和基于嵌入的标准方法。具体来说,LLM 剖析后,关键值对中的实体和关系的值(V)传递到中间步骤,使用嵌入模型生成向量嵌入。这些 KV 数据结构比仅嵌入 RAG 或 GraphRAG 中低效的块遍历技术提供了更精确的检索。
去重以优化图作 D(.): 为了高效处理数据,重复实体和关系合并,从而降低开销和整体图大小。
2.双重-层级检索范式
借助基于图的文本索引,LightRAG 流水线采用双层检索策略。该方法从 KG 内的多跳子图中识别低级和高级键,以回答多样化的查询。
低层检索 Local Query Keywords: 针对单个节点和边缘的具体细致信息 ,以处理本地查询,如"什么是 Mechazilla?"在这个层面,它提供了详细的节点级洞察。
高层检索Global Query Keywords : 汇总来自不同文档的多个实体信息,回答需要更广泛主题或抽象思考的全球性问题,如"埃隆·马斯克的愿景如何促进其项目的可持续发展?"
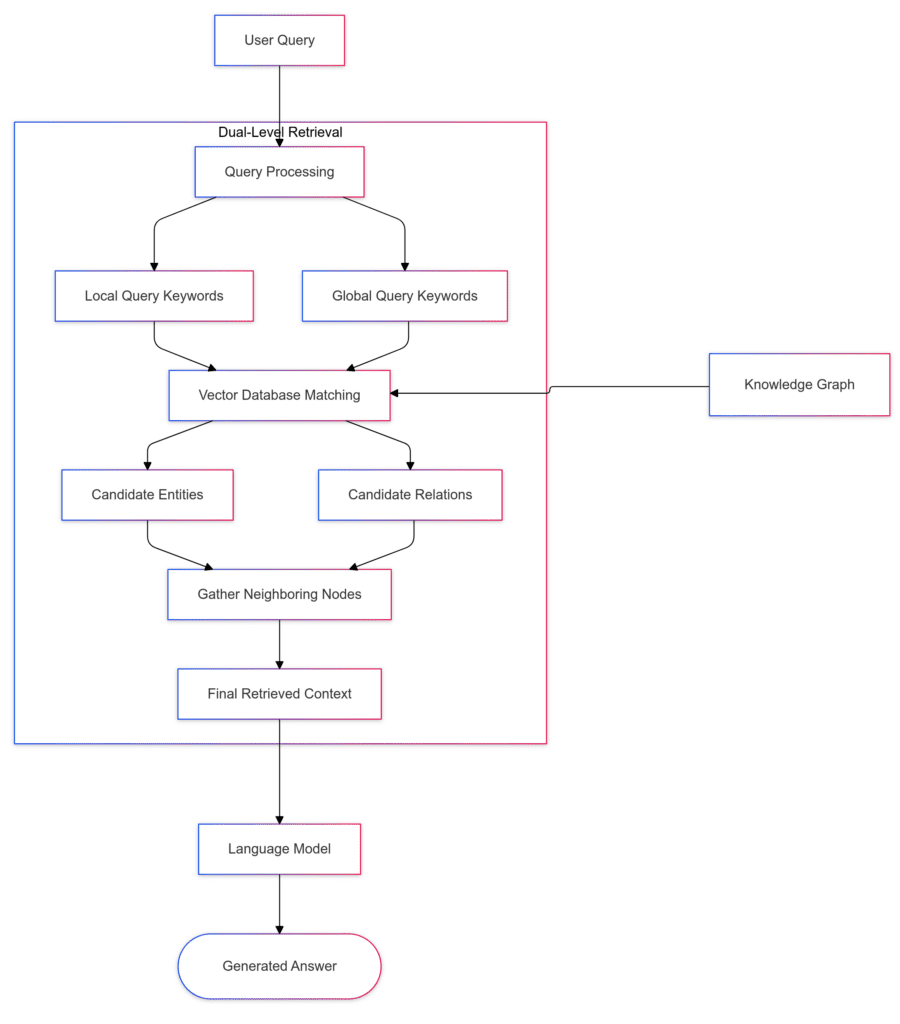
3.LightRAG 如何利用知识图谱?
对于给定的查询,LightRAG 的检索算法会同时提取本地 k(l) 和全局查询关键词 k(g)。 然后利用向量相似度,将相关实体匹配到带有低层密钥的本地查询和带有高级概念的全局查询关键词。
通过在局部子图中收集一跳邻近节点,LightRAG 集成了额外的上下文层,提高了图索引中边结果的相关性。这种双层检索结构结合了关键词匹配与由构建的 KG 诱导的相关结构信息。
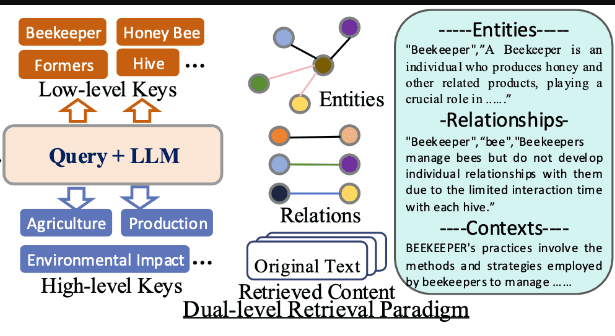
检索实体关系与上下文
检索的内容是 LLM 剖析阶段的输出,包含名称、实体和关系的描述以及原文的简短摘要。
4.Indexing 索引
索引流程图:
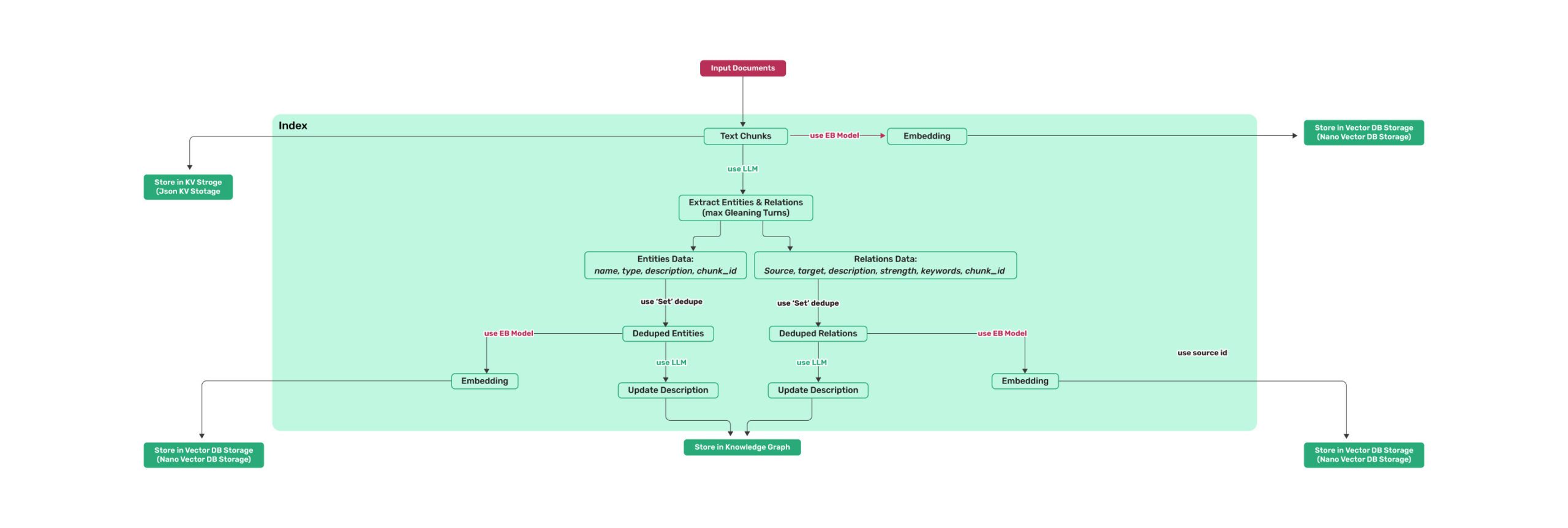
- kv_store_text_chunks.json 存储文档文本块及其相关的元数据,如 chunk_size(令牌)、实际内容、块索引、父文档 ID 等。

- kv_store_llm_response.json 存储由大型语言模型生成的关于实体及其关系的摘要。它采用缓存机制防止对相同 ID 进行冗余索引。 如用户输入query = "重置下拉代码命令"
- vdb_entities.json 包含从文本块中提取的具有唯一 ID、实体名称等的实体向量嵌入。

- vdb_relationship.json 文件存储通过 ID 连接源实体和目标实体之间的关系,以表示连接。

- 最后,构建的图索引保存为 graph_chunk_entity_relation.graphml ,我们稍后将利用它来可视化 Neo4j 中的 KG。
5.Incremental Indexing 增量索引
索引新文件,自动更新 LLM 响应 kv_store_llm_response.json,包含任何新的实体和关系,且不会与现有数据冲突或重复。
用户输入query = "redis启动过程"
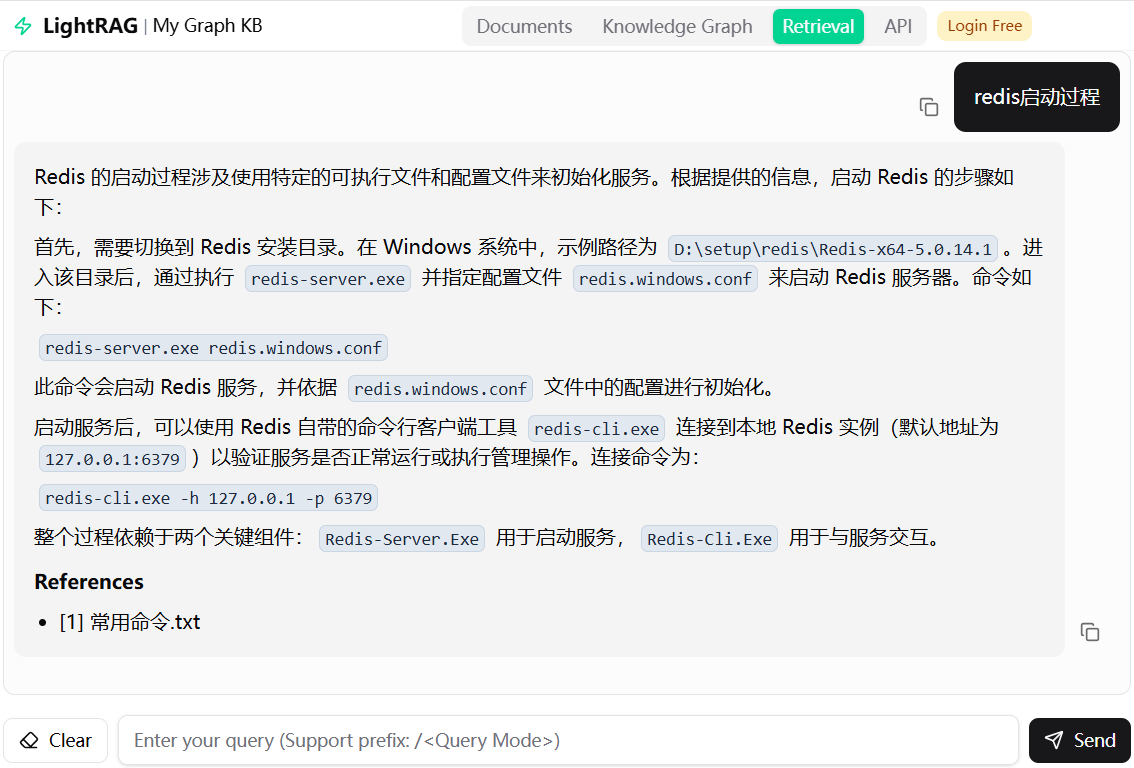
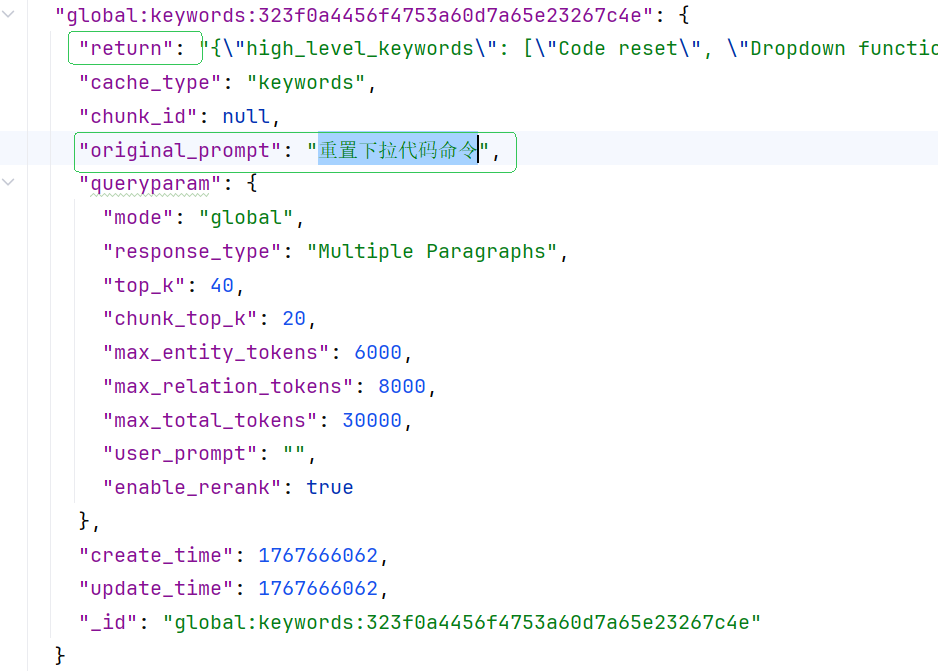
LLM 响应, kv_store_llm_response.json文件添加增量节点信息:global:keywords:b3f3bc653c7ca6f095224a9e787b1965
json
{
"global:keywords:323f0a4456f4753a60d7a65e23267c4e": {
"return": "{\"high_level_keywords\": [\"Code reset\", \"Dropdown functionality\"], \"low_level_keywords\": [\"\\u91cd\\u7f6e\\u4e0b\\u62c9\\u4ee3\\u7801\\u547d\\u4ee4\"]}",
"cache_type": "keywords",
"chunk_id": null,
"original_prompt": "重置下拉代码命令",
"queryparam": {
"mode": "global",
"response_type": "Multiple Paragraphs",
"top_k": 40,
"chunk_top_k": 20,
"max_entity_tokens": 6000,
"max_relation_tokens": 8000,
"max_total_tokens": 30000,
"user_prompt": "",
"enable_rerank": true
},
"create_time": 1767666062,
"update_time": 1767666062,
"_id": "global:keywords:323f0a4456f4753a60d7a65e23267c4e"
},
"global:keywords:b3f3bc653c7ca6f095224a9e787b1965": {
"return": "{\"high_level_keywords\": [\"Redis startup process\", \"Database initialization\", \"System boot sequence\"], \"low_level_keywords\": [\"Redis\", \"Configuration file\", \"Persistence setup\", \"Port binding\", \"Log initialization\"]}",
"cache_type": "keywords",
"chunk_id": null,
"original_prompt": "redis启动过程",
"queryparam": {
"mode": "global",
"response_type": "Multiple Paragraphs",
"top_k": 40,
"chunk_top_k": 20,
"max_entity_tokens": 6000,
"max_relation_tokens": 8000,
"max_total_tokens": 30000,
"user_prompt": "",
"enable_rerank": true
},
"create_time": 1767752257,
"update_time": 1767752257,
"_id": "global:keywords:b3f3bc653c7ca6f095224a9e787b1965"
}
}6.Querying 查询
根据查询模式(如naive、局部local、全局global和混合hybrid),相关关键词会从查询中提取,并与 KV 存储和向量数据库进行比较,以根据余弦相似度cosine检索候选实体和关系。
查询阶段在以程图:
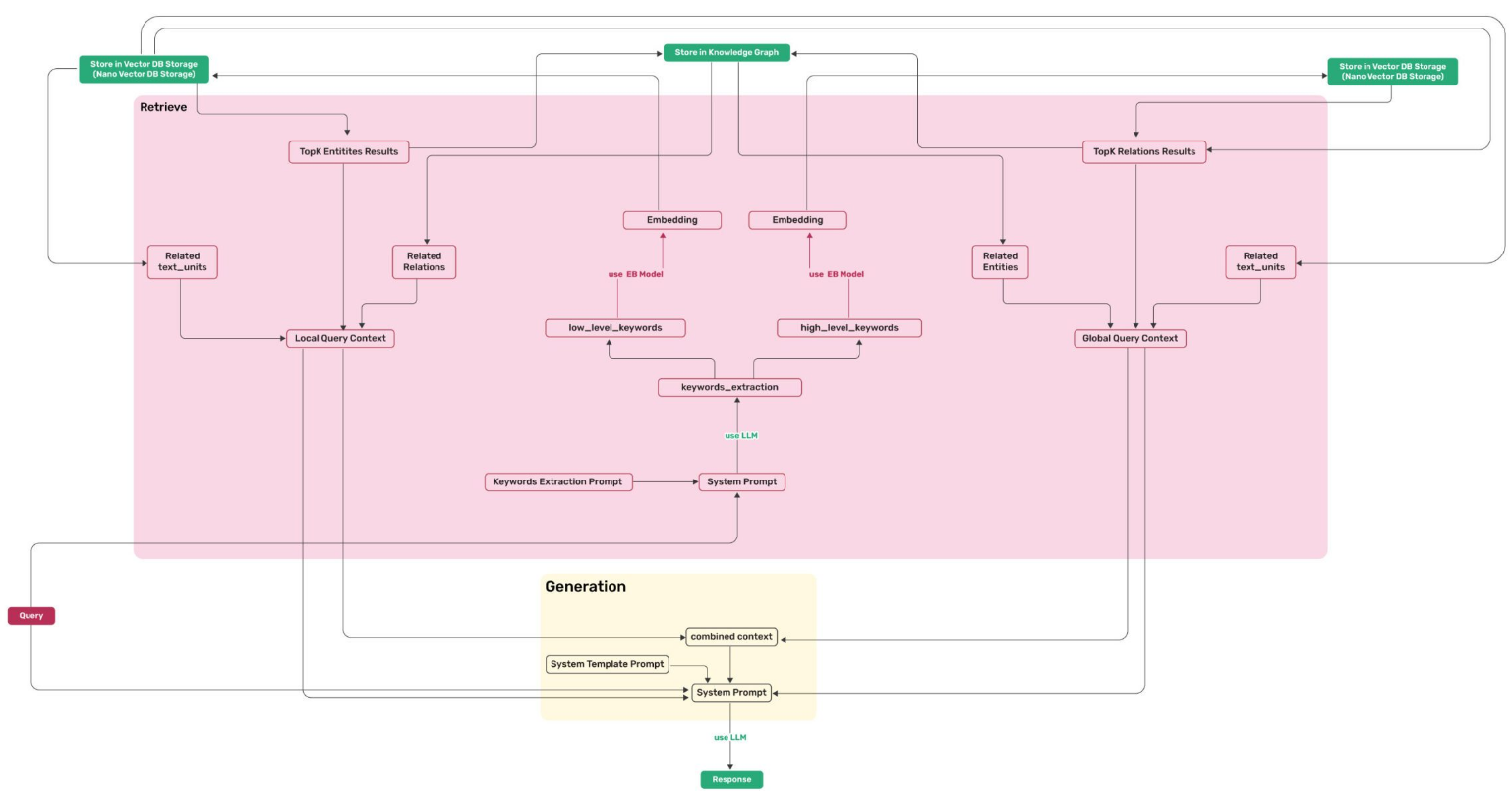
- Naive RAG -- 传统RAG
python
# mode="naive"
await rag.aquery(
"What are the top themes in this story?", param=QueryParam(mode="naive")
)- Local Quer -- LightRAG 本地查询
python
# mode="local"
await rag.aquery(
"What are the top themes in this story?", param=QueryParam(mode="local")
)- Global Query -- LightRAG 全局查询
python
# mode="global"
await rag.aquery(
"What are the top themes in this story?", param=QueryParam(mode="global")
)- Hybrid Query -- LightRAG 混合查询
python
# mode="hybrid"
await rag.aquery(
"What are the top themes in this story?", param=QueryParam(mode="hybrid")
)代码参考:LightRAG-1.4.9.10\examples\lightrag_openai_demo.py