【论文阅读】Steering Your Diffusion Policy with Latent Space Reinforcement Learning
- [1 团队与发表时间](#1 团队与发表时间)
- [2. 问题背景与核心思路](#2. 问题背景与核心思路)
- [3. 具体做法](#3. 具体做法)
-
- [3.1 模型设计](#3.1 模型设计)
- [3.2 Loss 设计](#3.2 Loss 设计)
- [3.3 数据设计](#3.3 数据设计)
- [4 实验效果](#4 实验效果)
- [5 结论](#5 结论)
- [6 扩散模型进行RL的方案](#6 扩散模型进行RL的方案)
-
- [6.1 纯离线设置 (Purely Offline Setting)](#6.1 纯离线设置 (Purely Offline Setting))
- [6.2 在线设置 (Online Setting)](#6.2 在线设置 (Online Setting))
- [6.3 残差策略 (Residual Policy)](#6.3 残差策略 (Residual Policy))
1 团队与发表时间
- 团队:主要由 加州大学伯克利分校(UC Berkeley) 的研究人员组成,包括 Mitsuhiko Nakamoto, Andrew Wagenmaker, Sergey Levine 等,此外还有来自华盛顿大学和亚马逊(Amazon)的合作者。
- 发表时间:该论文的 arXiv 版本更新于 2025 年 6 月 25 日。
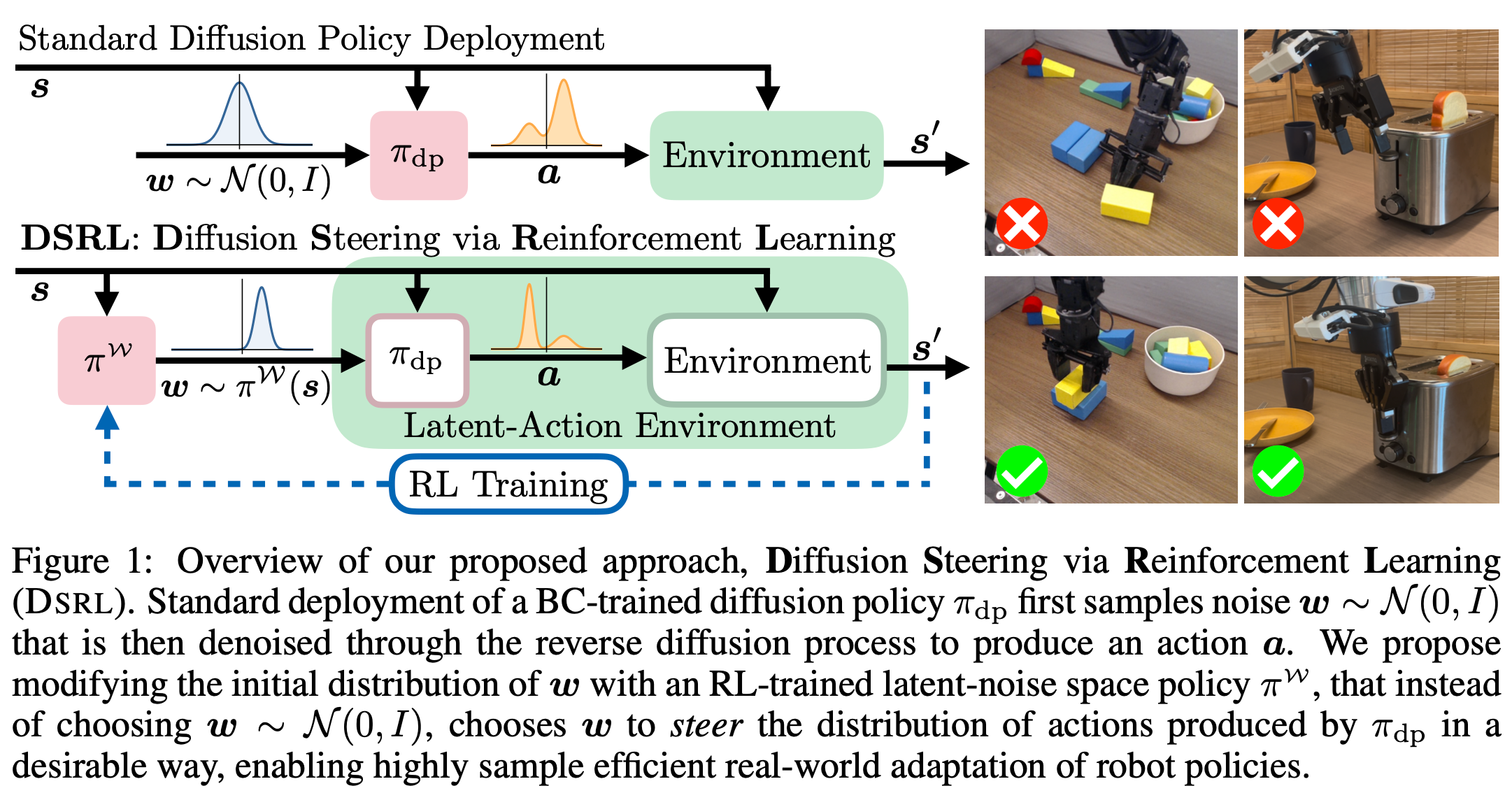
2. 问题背景与核心思路
-
问题背景:虽然基于行为克隆(BC)的扩散策略(Diffusion Policy)在机器人领域表现出色,但当预训练模型性能不足时,通常需要昂贵的人工演示来改进。传统的强化学习(RL)虽然能自主改进,但在高维动作空间中样本效率极低,且容易破坏扩散模型学到的先验分布,甚至造成训练不稳定。
- 多步去噪导致的梯度爆炸/消失:扩散模型生成动作不是"一步到位"的,而是经过几十步(如 50 步)去噪。如果你想通过动作 a a a 的奖励来反向传播更新模型权重,梯度必须链式传导 50 层网络。这就像训练一个极深的循环神经网络(RNN),梯度在传导过程中极易失控,导致训练瞬间崩盘。
-
核心思路:提出 DSRL。其核心想法是不在原始动作空间运行 RL,而是在扩散模型的"潜噪声空间(Latent-noise Space)"运行 RL。通过调整每一步去噪时加入的噪声(即"转向"),在保留原始行为分布的同时,引导策略向高奖励区域偏移。
3. 具体做法
3.1 模型设计
-
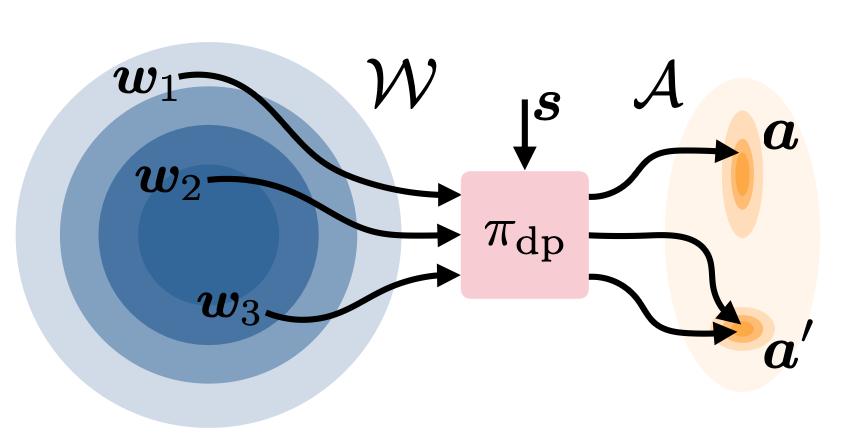
潜空间引导(Latent Steering):将预训练好的扩散策略视为一个"黑盒"。扩散策略通过多步去噪(从高斯噪声 ϵ \epsilon ϵ 迭代到动作 a a a)生成动作。
-
做法:
- 原本的扩散模型(比如 π 0 \pi_0 π0 或其他 Diffusion Policy)被当作一个固定的"基座"。
- 训练对象:DSRL 额外训练的是一个轻量级的 Actor 网络(通常是一个简单的多层感知机 MLP)。这个 Actor 的任务是根据当前状态 s s s,预测一个噪声位移(Noise Shift) Δ ϵ \Delta \epsilon Δϵ。
- 运行逻辑:在去噪过程中,原本输入给模型的纯高斯噪声 ϵ \epsilon ϵ 会被替换为 ϵ + Δ ϵ \epsilon + \Delta \epsilon ϵ+Δϵ。扩散模型依然按照原来的权重运行,但因为输入的"种子"变了,最终生成的动作就会向高奖励区域偏移。
-
架构:使用了基于 Soft Actor-Critic (SAC) 框架的结构,包含 Actor 网络(预测噪声位移)和 Critic 网络(评估状态-噪声对的价值)。
-
优势:
- 防止先验崩溃(Maintaining Priors):扩散模型里蕴含了大量从人类演示中学到的平滑动作先验。如果直接用 RL 微调权重,非常容易出现"灾难性遗忘",导致机器人动作变得抖动、不自然。冻结权重能确保机器人永远在"人类可能的动作分布"附近进行微调。
- 极高的样本效率:更新一个 8B 模型的参数需要海量数据和算力。而 DSRL 只训练一个极小的 Actor 网络(用来预测噪声偏移),这使得它在 20-40 次真机尝试内就能收敛,这在全参数微调中几乎是不可能的。
- 先天的保守优势:无论你给这个扩散模型输入什么样的初始噪声 w w w(哪怕是奇形怪状的 w w w),这个被冻结的"黑盒"模型最终吐出来的动作 a a a 几乎总是符合人类演示风格的、在分布内(In-distribution)的动作。因此噪声 w w w的探索是无穷的,而策略并不会出分布。
-
3.2 Loss 设计
- Actor Loss:基于 SAC 的目标函数,包含最大化预期奖励和熵正则项。通过最小化 Q ( s , Δ ϵ ) Q(s, \Delta \epsilon) Q(s,Δϵ) 的负值来优化,同时约束 Δ ϵ \Delta \epsilon Δϵ 的大小,以防偏离原始分布太远。
- Critic Loss:使用标准的时间差分(TD)误差来训练 Q Q Q 函数(Critic),评估在当前状态下采用特定噪声转向后的长期价值。
- 软约束:通过 KL 散度或熵正则化,确保微调后的策略不会完全丧失预训练模型中蕴含的人类演示先验。
3.3 数据设计
- 离线预训练数据:利用已有的行为克隆(BC)数据集(如人类演示)来初始化扩散策略。
- 在线交互数据:在强化学习阶段,机器人通过执行带有噪声转向的动作与环境交互,收集新的三元组 ( s , Δ ϵ , r ) (s, \Delta \epsilon, r) (s,Δϵ,r) 用于更新 Actor 和 Critic。
- 样本效率:由于是在低维且分布简单的噪声空间优化,DSRL 相比于直接在连续动作空间搜索,所需的数据量大幅减少。
4 实验效果
- 模拟环境(Libero, Aloha):在多个标准机器人基准测试中,DSRL 在极少的样本下(通常只需几十个或几百个 episodes)就能显著提升预训练策略的成功率。
- 真机实验:在"打开烤箱"和"放勺子到盘子里"等任务中,通过与 π 0 \pi_0 π0(Physical Intelligence 的基础模型)结合,DSRL 仅需 20-40 次真机交互 就能将成功率从接近 0% 提升到 80% 以上。实验证明其样本效率比直接在动作空间运行 SAC 高出数倍。
5 结论
DSRL 证明了在扩散模型的潜噪声空间进行强化学习是实现快速、自主策略改进的有效途径。它解决了扩散策略难以进行样本高效微调的难题,实现了"黑盒"式微调(无需深入修改扩散模型内部架构)。
6 扩散模型进行RL的方案
6.1 纯离线设置 (Purely Offline Setting)
在离线 RL 中,我们只有一份历史数据集(包含状态、动作和奖励),目标是从中学习一个能获得高奖励的策略。
-
按价值加权的 BC (Weighted BC by Value):
- 方法:这种方法不改变扩散模型的基本训练方式,但在损失函数上加权。给那些高奖励(高 Q Q Q 值或 V V V 值)的样本更大的权重,给表现差的样本小权重。
- 本质:它是行为克隆(BC)的变体。模型依然在模仿,但它被告知"多模仿好学生,少模仿坏学生"。
-
直接最大化奖励 (Directly maximizing a reward):
- 方法:不只是模仿数据,而是直接将 R R R(奖励)或 Q Q Q(价值)作为目标函数。通过对扩散策略的参数求导,让模型生成的动作序列朝着奖励更高的方向偏移。
- 难点:扩散模型是多步去噪,求导链条非常长,计算开销大且容易梯度爆炸。
-
拒绝采样 (Rejection Sampling):
- 方法:先用预训练好的扩散策略生成一大堆候选动作(比如生成 10 个),然后用一个学好的 Q Q Q 函数(评分器)对这 10 个动作打分,最后只执行分最高的那一个。
- 本质:这是一种"后处理"策略,不需要重新训练模型,但在推理(Inference)时计算量翻倍。
6.2 在线设置 (Online Setting)
在线 RL 允许机器人与环境实时交互,根据反馈不断调整策略。
- 基于 PPO 微调前几步去噪 (Finetune first few steps with PPO):
- 方法:扩散模型去噪通常有几十步。有些方法只用经典的 PPO 算法去更新前几步(高噪声阶段)的神经网络参数。
- 理由:早期步决定了动作的大致轮廓,后期步只是修饰细节。这种方法试图通过只动"大方向"来降低 RL 的学习难度。
- 匹配 Q 函数的 Score (Matching the score of the Q-function):
- 方法:数学上,扩散模型学习的是概率分布的"分值(Score)"。如果能学到一个奖励函数的分值 ∇ log R \nabla \log R ∇logR,并将其加到扩散模型的梯度中,就能把动作推向高奖励区。
- 本质:通过数学推导,将"寻找高奖励动作"转化成"沿着奖励梯度的方向去噪"。
- 迭代式 BC (Iterative BC / Best-of-N):
- 方法:机器人先去跑,选出表现好的轨迹(即那些 Q Q Q 值大的),把这些轨迹放回训练集,再次进行行为克隆(BC)。
- 本质:自我进化。不断重复"尝试 -> 筛选好样本 -> 重新模仿好样本"的过程。
6.3 残差策略 (Residual Policy)
- 方法:保持预训练好的扩散策略( a d i f f a_{diff} adiff)完全不动,另外训练一个轻量级的神经网络(残差网络)输出一个修正值 Δ a \Delta a Δa。最终执行的动作是 a = a d i f f + Δ a a = a_{diff} + \Delta a a=adiff+Δa。
- 本质:给扩散模型打一个"补丁",用 RL 专门学习这个补丁。