大家好,我是阿喵。
前几天面了个刚毕业的小喵,问了个面试的"开胃菜"问题:"你在浏览器里输入www.baidu.com,按下回车,直到看到百度首页,中间发生了哪些事?"
小喵眼睛一亮,张口就来:"DNS解析!然后TCP三次握手,发HTTP请求,服务器返回数据,TCP四次挥手,最后浏览器渲染页面!"
阿喵点点头,追问了一句:"那DNS解析的时候,浏览器是先查本地缓存还是直接找根服务器?如果本地缓存没命中,下一步找哪个?递归查询和迭代查询的区别是什么?"
小喵瞬间卡壳,支支吾吾说不出话,脸都红了。

其实这道题,看似是考察"浏览器和服务器的交互流程",本质上是在考察对网络分层模型、DNS协议、TCP协议、HTTP协议以及浏览器渲染机制的综合理解。很多人只记了个"流程骨架",却没搞懂每个步骤背后的"血肉细节",一被追问就露怯。
今天本喵就用最接地气的语言、最生活化的例子,把这个流程扒得明明白白。全文一万字,从基础流程讲到底层原理,再到面试官高频追问和应对技巧,一站式搞懂这个面试必考题。
话不多说,咱们发车!🚗
一、热身:先搞懂几个核心概念,避免听懵
 在正式拆解流程之前,先给大家铺垫几个基础概念。就像看球赛之前要先懂规则一样,搞懂这些,后面的内容才能秒懂。
在正式拆解流程之前,先给大家铺垫几个基础概念。就像看球赛之前要先懂规则一样,搞懂这些,后面的内容才能秒懂。
-
URL:统一资源定位符,你可以理解为"网页的地址"。比如www.baidu.com,就像你家的门牌号,浏览器通过这个"门牌号"才能找到对应的服务器。
-
DNS:域名系统,作用是"把域名翻译成IP地址"。因为浏览器和服务器之间的通信,靠的是IP地址(比如180.101.49.12),而我们记不住复杂的IP,所以就用域名(www.baidu.com)来替代。DNS就相当于"地址簿",帮我们把好记的域名转换成机器能识别的IP。
-
TCP:传输控制协议,作用是"保证数据安全、可靠地传输"。比如你给朋友发消息,TCP会确保消息完整送达,不会丢字、错字。它的核心特点是"面向连接""可靠传输",就像打电话,先打通确认双方都能听到,再说话。
-
HTTP:超文本传输协议,作用是"规定浏览器和服务器之间的通信格式"。比如浏览器告诉服务器"我要百度首页的内容",服务器告诉浏览器"这是你要的内容",这些"对话"的格式,都是HTTP协议规定的。它就像两个人聊天的"话术规范"。
-
网络分层模型:这个是核心中的核心!我们常说的OSI七层模型(应用层、表示层、会话层、传输层、网络层、数据链路层、物理层),或者TCP/IP五层模型(应用层、传输层、网络层、数据链路层、物理层)。后面我们讲的每个步骤,都对应着不同的分层。简单理解:每一层都有自己的"工作职责",数据要从应用层一步步往下传递,经过物理层发送出去,到了服务器那边,再从物理层一步步往上传递,最终到应用层。就像快递运输,从你手里(应用层)交给快递员(传输层),再到快递网点(网络层),通过运输工具(数据链路层、物理层)送到对方城市,再一步步交到收件人手里(应用层)。
好,概念铺垫完毕。接下来,我们正式拆解"输入URL后,浏览器到底做了什么"这个完整流程。整个流程可以分为7个核心步骤,我们一步步来啃。
二、完整流程拆解:从输入URL到看到页面,共7步
我们以"输入www.baidu.com,按下回车,看到百度首页"为例,完整拆解每一个环节。就像跟着快递的运输路线,从你下单(输入URL)到收到包裹(看到页面),每一步都给你讲清楚。
步骤1:浏览器预处理------先"检查"一下URL有没有问题

你以为按下回车的瞬间,浏览器就直接去查DNS了?不!它先会做个"预处理",相当于快递员上门取件前,先检查一下你的包裹有没有问题。
具体做什么呢?
-
检查URL格式:浏览器会先判断你输入的是不是一个合法的URL。比如你输入的是"baidu.com",它会自动补全成"www.baidu.com"(现在大部分浏览器默认用HTTPS);如果是输入的是"180.101.49.12"这种IP,就直接跳过DNS解析步骤。
-
检查缓存:浏览器会先查本地缓存里有没有这个URL对应的IP地址和页面资源。如果之前访问过百度,缓存还没过期,就直接用缓存里的信息,不用再走后面的流程,速度会飞快。就像你之前买过某家店的东西,知道地址,下次直接去,不用再查地址簿。
这里插一句:浏览器的缓存机制很重要,后面我们讲面试官追问的时候会详细说。现在你只需要知道,预处理阶段会先查缓存,能省则省。
如果预处理阶段没找到缓存,或者缓存过期了,就进入下一步------DNS解析。
步骤2:DNS解析------找"地址簿",把域名翻译成IP
这一步的核心目标:把你输入的"www.baidu.com"这个域名,翻译成对应的IP地址(比如180.101.49.12)。因为浏览器和服务器通信,必须用IP地址,域名只是给人看的"别名"。
DNS解析的过程,就像你要去朋友家,不知道地址,就先问自己的家人(本地缓存),家人不知道就问小区物业(本地DNS服务器),物业不知道就问市教育局(根服务器),一步步找到地址。
具体解析流程(从近到远,优先查近处的缓存,提高效率):
-
浏览器缓存:浏览器会先查自己的缓存(比如Chrome浏览器的缓存),如果之前访问过www.baidu.com,并且缓存没过期,就直接拿到IP,解析结束。
-
操作系统缓存:如果浏览器缓存没命中,就会查操作系统的缓存(比如Windows的hosts文件,Mac的/etc/hosts文件)。hosts文件里可以手动配置域名和IP的映射关系,比如你可以在hosts里写"127.0.0.1 www.test.com",这样访问www.test.com就会指向本地。很多开发调试的时候会用到这个。
-
本地DNS服务器缓存:如果操作系统缓存也没命中,就会向"本地DNS服务器"发送解析请求。本地DNS服务器是什么?就是你电脑联网时自动获取的DNS服务器地址(比如电信、联通的DNS服务器,或者你手动设置的8.8.8.8(谷歌DNS)、114.114.114.114(国内公共DNS))。本地DNS服务器也有缓存,大部分常见的域名(比如www.baidu.com、www.taobao.com)在这里都能查到。
-
根服务器查询(迭代查询):如果本地DNS服务器也没缓存,就到了关键步骤------向根服务器查询。根服务器是DNS解析的"顶层",全球只有13组根服务器(用字母A到M命名)。但根服务器不直接解析具体的域名,它只知道".com"" .cn"" .org"这些顶级域名对应的"顶级域名服务器"的地址。比如查询www.baidu.com,根服务器会告诉本地DNS服务器:"我找不到这个域名的IP,但我知道.com顶级域名服务器的地址,你去问它。"
-
顶级域名服务器查询:本地DNS服务器拿到.com顶级域名服务器的地址后,就向它发送解析请求。顶级域名服务器也不直接解析www.baidu.com,它只知道"baidu.com"这个二级域名对应的"权威DNS服务器"的地址。于是它会告诉本地DNS服务器:"我找不到,但我知道baidu.com的权威DNS服务器地址,你去问它。"
-
权威DNS服务器查询:本地DNS服务器拿到baidu.com的权威DNS服务器地址后,向它发送解析请求。权威DNS服务器是百度公司自己管理的DNS服务器,里面记录了www.baidu.com对应的IP地址(比如180.101.49.12)。它会把这个IP地址返回给本地DNS服务器。
-
结果返回:本地DNS服务器拿到IP地址后,会先把它缓存起来(方便下次查询),然后把IP地址返回给浏览器。至此,DNS解析完成!

举个生活化的例子帮助理解:
你(浏览器)要找"百度家"(www.baidu.com),不知道地址。
-
先问自己的备忘录(浏览器缓存):有没有记过?没有。
-
问家人(操作系统缓存):家人不知道。
-
问小区物业(本地DNS服务器):物业也没记过。
-
物业问市教育局(根服务器):教育局说"我不知道百度家在哪,但我知道负责管理.com小区的物业公司(顶级域名服务器)地址,你去问它。"
-
物业问.com小区的物业公司(顶级域名服务器):对方说"我不知道百度家在哪,但我知道百度家所在单元的管理员(权威DNS服务器)地址,你去问它。"
-
物业问百度家单元的管理员(权威DNS服务器):管理员说"百度家地址是180.101.49.12。"
-
物业把地址告诉你(浏览器),还记在自己的本子上(本地DNS缓存),方便下次有人问。
是不是一下子就懂了?这里有个关键点:从本地DNS服务器到根服务器、顶级域名服务器、权威DNS服务器的查询过程,是"迭代查询"------就是本地DNS服务器主动去问各个层级的服务器,直到拿到结果。而浏览器到本地DNS服务器的查询过程,是"递归查询"------浏览器只问本地DNS服务器,不管本地DNS服务器怎么去查,它只需要等结果。
递归查询和迭代查询的区别,面试官大概率会追问,记好这个例子,后面应对技巧部分会详细说。
步骤3:TCP三次握手------建立"可靠的通信通道"

拿到IP地址后,浏览器就知道要和哪个服务器通信了。但在发送数据之前,还需要建立一个可靠的通信通道------这就是TCP三次握手的作用。
为什么需要三次握手?因为网络是不可靠的,可能会有延迟、丢包。三次握手的目的,是让浏览器(客户端)和服务器(服务端)都确认:"我的发送能力没问题,你的接收能力也没问题",确保后续数据传输不会出问题。
就像两个人打电话:
甲(客户端):"喂,乙,你能听到我说话吗?"(第一次握手)
乙(服务端):"能听到!甲,你能听到我说话吗?"(第二次握手)
甲(客户端):"能听到!那我们开始聊天吧。"(第三次握手)
三次握手完成,电话接通,双方可以放心聊天了。TCP三次握手的原理和这个一模一样,只是用"数据包"代替了说话。
具体三次握手的过程(用专业术语补充,面试要能说清楚):
-
第一次握手(SYN):客户端向服务端发送一个SYN(同步)数据包,里面包含客户端的初始序列号(比如x),并请求建立连接。此时客户端状态变为SYN_SENT。
-
第二次握手(SYN+ACK):服务端收到SYN数据包后,会回复一个SYN+ACK(同步+确认)数据包。里面包含服务端的初始序列号(比如y),以及对客户端SYN的确认号(x+1,表示"我收到了你x序列号的数据包,下次请发x+1开始的数据包")。此时服务端状态变为SYN_RCVD。
-
第三次握手(ACK):客户端收到服务端的SYN+ACK数据包后,会回复一个ACK(确认)数据包。里面包含对服务端SYN的确认号(y+1,表示"我收到了你y序列号的数据包,下次请发y+1开始的数据包")。此时客户端状态变为ESTABLISHED。服务端收到这个ACK数据包后,状态也变为ESTABLISHED。
三次握手完成,TCP连接建立成功!接下来就可以开始传输数据了。
这里有个面试官超爱问的问题:"为什么是三次握手,而不是两次?" 很多人会说"因为需要确认双方的收发能力",但这个回答太笼统,不够深入。后面应对技巧部分会给大家详细拆解,让你一句话怼翻面试官。
步骤4:发送HTTP请求------告诉服务器"我要什么"
TCP连接建立后,就到了应用层的工作------浏览器向服务器发送HTTP请求。HTTP请求的作用,就是告诉服务器"我需要什么资源"。
 HTTP请求由三部分组成:请求行、请求头、请求体。我们用一个例子来拆解,比如访问www.baidu.com的HTTP请求:
HTTP请求由三部分组成:请求行、请求头、请求体。我们用一个例子来拆解,比如访问www.baidu.com的HTTP请求:
- 请求行:包含请求方法、请求URL、HTTP版本。比如:GET / HTTP/1.1。
-
请求方法:最常见的是GET和POST,还有PUT、DELETE、PATCH等。这里访问百度首页用的是GET方法,因为是"获取资源"。
-
请求URL:这里是"/",表示根路径,也就是请求百度首页的根资源。
-
HTTP版本:比如HTTP/1.1、HTTP/2、HTTP/3。现在大部分网站用的是HTTP/1.1或HTTP/2。
- 请求头:包含一些附加信息,比如浏览器类型、支持的文件格式、Cookie、缓存信息等。比如:
bash
- User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 (告诉服务器"我是Chrome浏览器,Windows系统")- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 (告诉服务器"我能接受的文件格式有这些")- Cookie: BAIDUID=1234567890ABCDEF:FG=1; BIDUPSID=1234567890ABCDEF (告诉服务器"我之前访问过你,这是我的身份标识")- 请求体:只有POST、PUT等方法会有请求体,用来传递数据(比如表单数据、JSON数据)。GET方法没有请求体,参数会拼在URL后面(比如www.baidu.com/s?wd=java)。
举个生活化的例子:HTTP请求就像你去餐厅吃饭,给服务员的"点餐单"。
-
请求行:相当于"我要一份宫保鸡丁(请求方法+请求URL),用普通话点(HTTP版本)"。
-
请求头:相当于"我不吃辣(附加信息1),要微甜(附加信息2),之前在你家吃过(Cookie)"。
-
请求体:相当于"如果是点套餐,里面包含的配菜信息(需要传递的数据)"。
服务器收到这个"点餐单"后,就知道该怎么处理了。
这里补充一个Java后端视角的知识点:在Java中,我们可以用Spring Boot来接收HTTP请求。比如用@GetMapping("/")接收GET请求,用@PostMapping("/user")接收POST请求。请求头里的Cookie、User-Agent等信息,可以通过HttpServletRequest对象获取。后面面试官如果追问"Java中如何处理HTTP请求",可以结合这个知识点回答,显得你不仅懂原理,还懂实践。
步骤5:服务器处理请求并返回HTTP响应------给浏览器"它要的东西"
服务器收到HTTP请求后,就开始处理请求。处理请求的过程,就是后端开发的核心工作之一。比如百度的服务器收到"获取首页"的请求后,会从数据库中查询相关数据,生成HTML页面,然后把这个页面作为响应数据返回给浏览器。
服务器处理请求的大致流程(以Java后端为例):

-
服务器软件(比如Tomcat、Nginx)接收HTTP请求,把请求交给后端应用(比如Spring Boot应用)。
-
后端应用根据请求URL和请求方法,找到对应的处理方法(比如Controller里的方法)。
-
处理方法执行业务逻辑(比如查询数据库、调用其他服务)。
-
生成响应数据(比如HTML页面、JSON数据)。
-
服务器软件把响应数据封装成HTTP响应,通过TCP连接返回给浏览器。
HTTP响应和HTTP请求对应,也由三部分组成:响应行、响应头、响应体。
- 响应行:包含HTTP版本、状态码、状态描述。比如:HTTP/1.1 200 OK。
-
状态码:这是面试官高频考点!用来表示请求的处理结果。常见的状态码:
-
200 OK:请求成功。
-
301 Moved Permanently:永久重定向(比如域名变更)。
-
302 Found:临时重定向(比如登录后跳转到首页)。
-
400 Bad Request:请求参数错误。
-
401 Unauthorized:未授权(比如没登录就访问需要登录的接口)。
-
403 Forbidden:禁止访问(比如没有权限访问某个资源)。
-
404 Not Found:资源不存在(比如访问了一个不存在的URL)。
-
500 Internal Server Error:服务器内部错误(比如后端代码抛异常了)。
-
502 Bad Gateway:网关错误(比如反向代理服务器无法连接后端服务)。
-
503 Service Unavailable:服务不可用(比如服务器过载、维护中)。
-
504 Gateway Timeout:网关超时(比如后端服务处理时间太长)。
- 响应头:包含服务器信息、响应数据的格式、缓存信息等。比如:
-
Server: BWS/1.1 (告诉浏览器"我是百度的服务器")
-
Content-Type: text/html;charset=utf-8 (告诉浏览器"响应体是HTML格式,编码是UTF-8")
-
Set-Cookie: BAIDUID=1234567890ABCDEF:FG=1; expires=Wed, 15-Jul-2026 08:00:00 GMT; path=/; domain=.baidu.com (服务器给浏览器设置Cookie)
- 响应体:就是服务器返回的具体资源,比如HTML页面、图片、JSON数据等。访问百度首页的响应体,就是百度首页的HTML代码。
还是用餐厅的例子:HTTP响应就像服务员给你上的"菜"。
-
响应行:相当于"你的菜做好了(200 OK),用的是普通话给你确认(HTTP版本)"。
-
响应头:相当于"这道菜是宫保鸡丁(Content-Type),用的是陶瓷盘装的(服务器信息),建议趁热吃(缓存信息)"。
-
响应体:就是宫保鸡丁本身(具体的资源)。
步骤6:TCP四次挥手------关闭"通信通道"
浏览器收到服务器返回的响应数据后,就可以开始渲染页面了。但此时TCP连接还没关闭,需要通过四次挥手来关闭连接,释放资源。
 为什么需要四次挥手?因为TCP连接是"全双工"的(双方可以同时发送数据),关闭连接时,需要确保双方都已经发送完所有数据,并且都知道对方要关闭连接了。
为什么需要四次挥手?因为TCP连接是"全双工"的(双方可以同时发送数据),关闭连接时,需要确保双方都已经发送完所有数据,并且都知道对方要关闭连接了。
还是用打电话的例子:
甲(客户端):"我说完了,准备挂电话了。"(第一次挥手)
乙(服务端):"好的,我知道你要挂了,我再看看有没有没说完的。"(第二次挥手)
乙(服务端):"我也说完了,你可以挂电话了。"(第三次挥手)
甲(客户端):"好的,挂了。"(第四次挥手)
四次挥手完成,电话挂断。TCP四次挥手的原理和这个一样。
具体四次挥手的过程(专业术语补充):
-
第一次挥手(FIN):客户端向服务端发送一个FIN(结束)数据包,表示客户端不再发送数据了,请求关闭连接。此时客户端状态变为FIN_WAIT_1。
-
第二次挥手(ACK):服务端收到FIN数据包后,回复一个ACK数据包,确认收到客户端的关闭请求。此时服务端状态变为CLOSE_WAIT,客户端状态变为FIN_WAIT_2。这时候服务端还可以继续向客户端发送数据。
-
第三次挥手(FIN+ACK):服务端发送完所有数据后,向客户端发送一个FIN+ACK数据包,表示服务端也不再发送数据了,请求关闭连接。此时服务端状态变为LAST_ACK。
-
第四次挥手(ACK):客户端收到FIN+ACK数据包后,回复一个ACK数据包,确认收到服务端的关闭请求。此时客户端状态变为TIME_WAIT(等待一段时间,确保服务端收到ACK后再关闭),服务端收到ACK后状态变为CLOSED。等待时间结束后,客户端状态也变为CLOSED。
四次挥手完成,TCP连接关闭。这里有个面试官常问的问题:"为什么四次挥手需要TIME_WAIT状态?" 后面应对技巧部分会详细解答。
步骤7:浏览器渲染页面------把HTML变成你看到的样子
这是最后一步!浏览器收到服务器返回的HTML、CSS、JS等资源后,会把这些"代码"渲染成我们肉眼能看到的网页。这个过程看似简单,其实内部做了很多工作,也是前端面试的重点,但后端面试也可能会问到大致流程。
 浏览器渲染页面的大致流程:
浏览器渲染页面的大致流程:
- 解析HTML,生成DOM树(文档对象模型):浏览器会从上到下逐行解析HTML代码,把每个标签(比如、、
)转换成DOM树中的节点。DOM树描述了HTML的结构,每个节点对应一个HTML元素。
- 例子:
Hello World 解析后,DOM树的根节点是html,子节点是body,body的子节点是div,div的子节点是文本"Hello World"。
-
解析CSS,生成CSSOM树(CSS对象模型):浏览器会解析HTML中的标签、外部CSS文件,生成CSSOM树。CSSOM树描述了每个HTML元素的样式(比如颜色、字体、大小、位置)。
-
合并DOM树和CSSOM树,生成渲染树(Render Tree):渲染树只包含需要显示的节点(比如隐藏的节点<display: none>不会出现在渲染树中),并且每个节点都带有样式信息。渲染树的作用是告诉浏览器"哪些节点要显示,以及显示成什么样子"。
-
布局(Layout):根据渲染树,计算每个节点的位置和大小。比如计算div元素在页面中的x坐标、y坐标,宽度、高度等。这个过程也叫"重排"。
-
绘制(Painting):根据布局结果,把每个节点绘制到屏幕上。比如给文字上色、给div加背景色、绘制图片等。这个过程也叫"重绘"。
-
合成(Composite):把绘制好的各个图层合并成一个完整的页面,显示在浏览器中。现在的浏览器会把页面分成多个图层(比如文字层、图片层、视频层),分别绘制后再合成,这样可以提高渲染效率。
举个生活化的例子:浏览器渲染页面就像装修房子。
-
解析HTML生成DOM树:相当于绘制房子的户型图(结构)。
-
解析CSS生成CSSOM树:相当于确定每个房间的装修风格(颜色、家具款式)。
-
生成渲染树:相当于确定哪些房间要装修(隐藏的房间不装修),以及每个房间的最终装修效果。
-
布局:相当于确定每个家具的摆放位置和大小。
-
绘制:相当于给房间刷漆、摆放家具。
-
合成:相当于把各个房间组合成一个完整的房子,让你可以住进去(看到页面)。
这里补充一个后端需要知道的知识点:后端返回的HTML、CSS、JS代码的质量,会影响浏览器的渲染效率。比如HTML代码结构混乱、CSS选择器太复杂、JS代码执行时间太长,都会导致页面渲染变慢。所以后端开发在写模板代码(比如Thymeleaf、Freemarker)时,也要注意优化,避免影响用户体验。
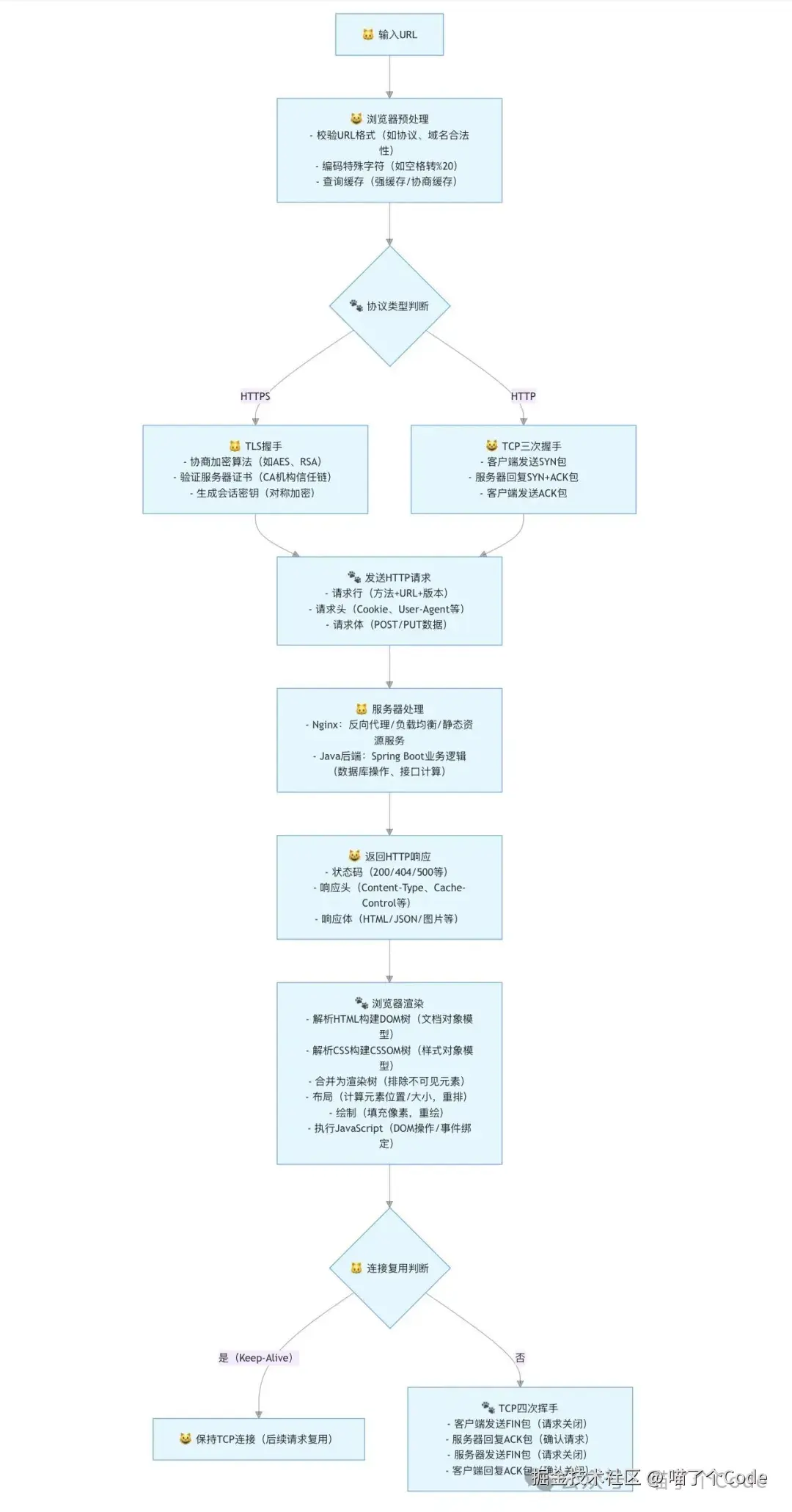
总流程图如下:
三、面试官高频追问:这些问题,你必须会答
前面讲的是基础流程,面试时面试官不会只问你"有哪些步骤",而是会追问流程中的细节。这部分是"加分项",也是区分你和其他面试者的关键。本喵整理了10个高频追问问题,每个问题都给出"应对技巧+标准答案",让你面试时游刃有余。
追问1:DNS解析中,递归查询和迭代查询的区别是什么?
应对技巧:用"谁主动查询"来区分,结合前面的"找朋友家地址"的例子,一句话就能说清楚。避免只说定义,要结合流程讲。
标准答案:
递归查询和迭代查询的核心区别是"查询的发起者和责任不同":
-
递归查询:是"浏览器向本地DNS服务器"的查询方式。浏览器只向本地DNS服务器发送查询请求,不需要自己去问其他服务器,不管本地DNS服务器怎么查询,浏览器只需要等待最终的IP结果。就像你问物业朋友家的地址,物业会帮你找到地址,你不用自己去问其他人。
-
迭代查询:是"本地DNS服务器向根服务器、顶级域名服务器、权威DNS服务器"的查询方式。本地DNS服务器向某个服务器发送查询请求后,如果该服务器不知道结果,会返回下一个服务器的地址,让本地DNS服务器自己去查询,直到拿到最终的IP结果。就像物业问教育局朋友家地址,教育局不知道,就告诉物业去问.com小区的物业公司,物业再自己去问,直到找到地址。
追问2:为什么TCP三次握手需要三次,而不是两次?
应对技巧:核心是"解决网络延迟导致的无效连接问题"。很多人会说"确认双方收发能力",但要进一步说明"两次握手会有什么问题",这样回答才够深入。
标准答案:
三次握手的核心目的是"确保双方的发送和接收能力都正常,并且避免网络延迟导致的无效连接"。如果只进行两次握手,会出现以下问题:
假设客户端发送了一个SYN数据包(第一次握手),但因为网络延迟,这个数据包过了很久才到达服务端。服务端收到后,以为是新的连接请求,就回复一个SYN+ACK数据包(第二次握手),然后建立连接,等待客户端发送数据。但此时客户端可能已经超时,放弃了这个连接,不会再回复ACK。服务端会一直等待,浪费服务器资源。
而三次握手时,服务端只有收到客户端的第三次ACK数据包,才会确认连接建立。如果是延迟的SYN数据包,客户端不会回复ACK,服务端等待一段时间后就会释放资源,避免无效连接占用资源。
简单说:三次握手可以确保"客户端知道服务端能收能发,服务端也知道客户端能收能发",而两次握手只能确保"服务端知道客户端能发,客户端知道服务端能收能发",无法确保"服务端知道客户端能收"。
追问3:为什么TCP四次挥手需要四次,而不是三次?
应对技巧:核心是"TCP是全双工通信,双方需要分别关闭发送通道"。要说明"四次挥手的每一步对应的是关闭哪个方向的通道"。
标准答案:
因为TCP是"全双工"通信,客户端和服务端可以同时发送数据。关闭连接时,需要分别关闭"客户端到服务端"和"服务端到客户端"两个方向的通信通道,所以需要四次挥手:
-
第一次挥手:客户端关闭"客户端→服务端"的发送通道,告诉服务端"我不再发数据了"。
-
第二次挥手:服务端确认收到关闭请求,但此时"服务端→客户端"的发送通道还没关闭,服务端可能还有数据要发送。
-
第三次挥手:服务端发送完所有数据后,关闭"服务端→客户端"的发送通道,告诉客户端"我也不再发数据了"。
-
第四次挥手:客户端确认收到关闭请求,关闭自己的接收通道,服务端收到后也关闭自己的接收通道。
如果是三次挥手,就无法确保服务端已经发送完所有数据。比如服务端收到客户端的FIN后,直接发送FIN+ACK,可能会导致服务端还没发送完的数据丢失。
追问4:TCP四次挥手后的TIME_WAIT状态有什么作用?为什么需要等待?
应对技巧:核心是"解决两个问题:确保服务端收到最终的ACK;避免延迟的数据包干扰新连接"。用"网络延迟"的场景来解释,更容易理解。
标准答案:
TIME_WAIT状态是客户端在第四次挥手后进入的状态,默认等待2MSL(MSL是最大分段生存期,即一个数据包在网络中的最大存活时间,通常是30秒或60秒)。它的作用有两个:
-
确保服务端收到最终的ACK数据包:客户端发送第四次挥手的ACK后,可能因为网络延迟,这个ACK数据包会丢失。服务端没收到ACK,就会重新发送第三次挥手的FIN+ACK。客户端在TIME_WAIT状态下,可以收到这个重发的FIN+ACK,然后重新发送ACK,确保服务端能收到,正常关闭连接。
-
避免延迟的数据包干扰新连接:如果客户端直接关闭连接,而网络中还有之前的TCP数据包(延迟的数据包),这些数据包可能会被新的、使用相同端口的TCP连接接收,导致新连接的数据混乱。TIME_WAIT状态会等待足够长的时间(2MSL),确保网络中所有延迟的数据包都已经失效,再关闭连接。
追问5:HTTP和HTTPS的区别是什么?HTTPS为什么更安全?

应对技巧:先讲核心区别(是否加密、端口、协议组成),再讲HTTPS的加密原理(对称加密+非对称加密+CA证书)。结合Java后端的实践(比如Spring Boot配置HTTPS需要SSL证书),会更加分。
标准答案:
HTTP和HTTPS的核心区别:
-
安全性:HTTP是明文传输,数据在网络中传输时可能被窃取、篡改、伪造;HTTPS是加密传输,数据被加密后再传输,安全性更高。
-
端口:HTTP默认使用80端口;HTTPS默认使用443端口。
-
协议组成:HTTPS = HTTP + SSL/TLS。SSL/TLS是一种加密协议,负责对HTTP数据进行加密和解密。
-
证书:HTTPS需要使用CA(证书颁发机构)颁发的数字证书,用来验证服务器的身份;HTTP不需要。
HTTPS的安全原理(核心是"对称加密+非对称加密"结合):
-
客户端向服务器发送HTTPS请求,服务器返回自己的数字证书(包含公钥)。
-
客户端验证证书的合法性(比如是否由可信的CA颁发、证书是否过期)。验证通过后,生成一个随机的对称密钥,用服务器的公钥加密这个密钥,发送给服务器。
-
服务器用自己的私钥解密,得到客户端生成的对称密钥。
-
后续客户端和服务器之间的所有通信数据,都用这个对称密钥进行加密和解密。
为什么这样安全?因为:
-
非对称加密(公钥+私钥)用来传输对称密钥,确保对称密钥不会被窃取。
-
对称加密用来传输实际的通信数据,因为对称加密的效率比非对称加密高,适合大量数据传输。
-
数字证书用来验证服务器的身份,避免被中间人攻击(比如有人冒充服务器发送自己的公钥)。
Java后端实践:在Spring Boot中配置HTTPS,需要先从CA获取SSL证书(比如.jks格式的证书),然后在application.yml中配置证书路径、密码、端口等信息。
追问6:HTTP的状态码301和302有什么区别?实际应用中怎么选?
应对技巧:核心区别是"是否永久重定向",以及"对搜索引擎的影响"。结合实际应用场景(比如域名变更、临时跳转)来解释,更易理解。
标准答案:
301和302的核心区别是"重定向的性质":
- 301 Moved Permanently:永久重定向。表示请求的资源已经永久迁移到了新的URL,以后所有访问旧URL的请求,都应该直接访问新URL。
-
特点:搜索引擎会把旧URL的权重转移到新URL上,旧URL的索引会被替换成新URL。
-
应用场景:域名变更(比如旧域名www.old.com永久迁移到www.new.com)、网站结构调整(比如页面路径永久改变)。
- 302 Found:临时重定向。表示请求的资源暂时迁移到了新的URL,以后可能还会迁回旧URL,访问旧URL的请求只是暂时跳转到新URL。
-
特点:搜索引擎不会把旧URL的权重转移到新URL上,会保留旧URL的索引。
-
应用场景:登录后跳转到首页、网站维护时临时跳转到维护页面、A/B测试时临时跳转不同的页面。
实际应用中选择:如果是永久的资源迁移,用301;如果是临时的跳转,用302。如果误用(比如临时跳转用了301),可能会导致搜索引擎权重错误转移,影响网站的SEO。
追问7:浏览器的缓存机制是怎样的?为什么要做缓存?
应对技巧:
先讲缓存的目的(提高访问速度、减少服务器压力),再讲缓存的分类(强缓存、协商缓存),以及各自的实现原理(响应头字段)。结合前面URL流程中的"预处理阶段查缓存",形成完整的逻辑链。
标准答案:
浏览器缓存的核心目的是"提高页面访问速度,减少服务器的请求压力"。因为缓存可以把之前访问过的资源(比如HTML、CSS、JS、图片)存储在本地,下次访问时直接从本地获取,不用再向服务器请求,节省了网络传输时间和服务器资源。
浏览器缓存分为两种:强缓存和协商缓存。
- 强缓存:
-
原理:浏览器第一次访问资源时,服务器会在响应头中返回资源的过期时间。浏览器把资源缓存到本地,下次访问时,直接检查本地缓存的资源是否过期。如果没过期,就直接使用本地缓存,不向服务器发送任何请求。
-
实现响应头字段:
-
Expires:HTTP/1.0的字段,值是一个绝对时间(比如Expires: Wed, 15-Jul-2026 08:00:00 GMT)。缺点是依赖客户端的本地时间,如果客户端时间不准,会导致缓存失效或过期。
-
Cache-Control:HTTP/1.1的字段,值是相对时间(比如Cache-Control: max-age=3600,表示资源在3600秒内有效)。优先级比Expires高,现在大部分网站都用这个。
- 协商缓存:
-
原理:强缓存过期后,浏览器不会直接丢弃本地缓存,而是向服务器发送一个请求,询问服务器"本地缓存的资源是否还有效"。如果服务器认为有效,就返回304 Not Modified,告诉浏览器直接使用本地缓存;如果服务器认为无效,就返回200 OK和新的资源,浏览器更新本地缓存。
-
实现响应头/请求头字段:
-
Last-Modified + If-Modified-Since:Last-Modified是服务器返回的资源最后修改时间(响应头);If-Modified-Since是浏览器下次请求时,把Last-Modified的值带过去(请求头),服务器对比这个时间和资源当前的最后修改时间。缺点是只能精确到秒,如果资源在1秒内被修改,无法识别。
-
ETag + If-None-Match:ETag是服务器返回的资源唯一标识(比如资源的哈希值,响应头);If-None-Match是浏览器下次请求时,把ETag的值带过去(请求头),服务器对比这个标识和资源当前的标识。优先级比Last-Modified高,精度更高。
缓存的流程:浏览器访问资源时,先查强缓存,如果命中就直接使用;如果强缓存未命中,就发送协商缓存请求,服务器判断资源是否有效,有效则用本地缓存,无效则更新缓存。
追问8:GET和POST请求的区别是什么?为什么POST比GET更安全?
应对技巧:不要只说"GET查数据,POST传数据",要从多个维度(参数位置、数据大小、缓存、安全性、幂等性)分析。重点说明"POST更安全是相对的,不是绝对的"。
标准答案:
GET和POST的区别,从6个核心维度总结:
-
核心用途:GET用于"查询/获取资源"(只读操作);POST用于"提交/修改资源"(写操作)。
-
参数位置:GET的参数拼在URL后面(比如www.baidu.com/s?wd=java),肉眼可见;POST的参数放在请求体(Request Body)里,URL中看不到。
-
数据大小限制:GET的参数受URL长度限制(不同浏览器和服务器限制不同,一般是几KB);POST的参数放在请求体里,理论上没有大小限制(实际受服务器配置限制)。
-
缓存:GET请求默认会被浏览器缓存;POST请求默认不会被浏览器缓存。
-
幂等性:GET是幂等的(多次请求的结果相同,不会改变服务器数据);POST是非幂等的(多次请求可能产生不同结果,比如重复下单)。
-
安全性:POST比GET相对更安全,但不是绝对安全。因为GET的参数在URL中,容易被偷窥、记录(比如浏览器历史记录、代理服务器日志);POST的参数在请求体中,相对隐蔽。但两者都是明文传输(HTTP协议下),如果要绝对安全,需要用HTTPS加密。
补充:很多人认为"POST比GET更安全",其实是误解。POST只是参数位置更隐蔽,并不是数据被加密了。在HTTP协议下,无论是GET还是POST的参数,都可以被抓包工具捕获。只有用HTTPS加密后,数据才是真正安全的。
追问9:如果输入URL后,页面无法显示,可能的原因有哪些?如何排查?
应对技巧:
从"流程倒推"的思路排查,比如DNS解析失败、TCP连接失败、HTTP请求错误、服务器错误、浏览器渲染失败等。结合实际排查工具(比如ping、telnet、F12开发者工具),体现你的实践能力。
标准答案:
页面无法显示的原因,对应URL流程的各个步骤,排查思路也是从流程倒推:
- DNS解析失败:
-
现象:浏览器提示"无法解析域名""找不到服务器"。
-
排查:用ping命令测试域名(比如ping www.baidu.com),如果提示"请求找不到主机",说明DNS解析失败。可能的原因:本地DNS服务器配置错误、域名不存在、网络连接异常。解决方法:更换DNS服务器(比如改成8.8.8.8)、检查网络连接、确认域名是否正确。
- TCP连接失败:
-
现象:浏览器提示"无法连接到服务器"。
-
排查:用telnet命令测试IP和端口(比如telnet 180.101.49.12 80),如果提示"无法连接"或"连接超时",说明TCP连接失败。可能的原因:服务器未启动、端口被占用、防火墙拦截、服务器宕机。解决方法:检查服务器是否正常运行、确认端口是否正确且未被占用、关闭防火墙或配置放行规则、联系服务器运维人员排查。
- HTTP请求错误:
-
现象:浏览器提示400、401、403、404等4xx状态码。
-
排查:打开浏览器F12开发者工具,查看"网络"面板,找到对应的请求,查看请求URL、请求参数、请求头是否正确。400是请求参数错误,检查参数格式和必填项;401是未授权,确认是否需要登录或携带令牌;403是禁止访问,检查是否有访问权限;404是资源不存在,确认URL是否正确。
- 服务器错误:
-
现象:浏览器提示500、502、503、504等5xx状态码。
-
排查:500是服务器内部错误,需要查看后端日志(比如Spring Boot的日志),定位代码异常;502是网关错误,检查反向代理服务器(比如Nginx)是否能正常连接后端服务;503是服务不可用,可能是服务器过载或维护中,查看服务器资源使用情况;504是网关超时,检查后端服务处理时间是否过长,优化业务逻辑。
- 浏览器渲染失败:
-
现象:页面空白、样式错乱、JS报错。
-
排查:打开F12开发者工具,查看"控制台"面板,查看是否有JS语法错误;查看"元素"面板,检查HTML结构和CSS样式是否正确;查看"网络"面板,确认CSS、JS、图片等资源是否成功加载。可能的原因:JS代码语法错误、CSS选择器错误、资源路径错误、浏览器兼容性问题。解决方法:修复JS和CSS错误、修正资源路径、添加浏览器兼容代码(比如polyfill)。
- 网络异常:
-
现象:页面加载缓慢、断断续续或直接失败。
-
排查:检查本地网络连接(比如Wi-Fi是否正常、网线是否插好),用测速工具测试网络速度;尝试访问其他网站,确认是单个网站问题还是整体网络问题。解决方法:重启路由器、切换网络(比如从Wi-Fi切换到流量)、联系网络运营商排查。
- 域名没进行ICP备案
本喵有一次开发的时候 ,所有东西都配好了之后,发现网站怎么都打不开,查了各种原因,最后发现,居然是没有备案。如果是域名访问的,还需要排查这一层哦。
四、总结:面试答题模板+核心要点回顾
看到这里,相信你已经对"输入URL后浏览器的完整流程"了如指掌。很多后端同学觉得这是前端的知识,但其实它是网络通信的基础,也是后端面试的"开胃菜"------面试官通过这道题,能快速判断你对网络协议、通信流程的理解深度。最后,本喵给大家整理了一份可直接套用的面试答题模板,再回顾核心要点,帮你加深记忆、轻松应考。
面试答题模板(直接背)
输入URL后,浏览器的完整流程可分为7步,逻辑清晰、层层递进:
-
浏览器预处理:先校验URL合法性,自动补全HTTPS等协议;查询本地缓存(强缓存+协商缓存),若缓存未过期则直接使用,无需后续流程。
-
DNS解析:将域名翻译成IP地址,解析顺序为"浏览器缓存→操作系统缓存→本地DNS服务器缓存→根服务器→顶级域名服务器→权威DNS服务器",最终将IP返回浏览器。
-
TCP三次握手:客户端与服务器通过三次握手建立可靠连接,确保双方收发能力正常,为数据传输铺垫。
-
发送HTTP请求:浏览器封装HTTP请求(请求行+请求头+请求体),通过TCP连接发送给服务器,明确告知服务器所需资源。
-
服务器处理并返回响应:服务器通过Tomcat等软件接收请求,由后端应用(如Spring Boot)执行业务逻辑,生成响应数据并封装成HTTP响应(响应行+响应头+响应体)返回给浏览器。
-
TCP四次挥手:数据传输完成后,双方通过四次挥手关闭TCP连接,释放系统资源。
-
浏览器渲染页面:解析HTML生成DOM树、解析CSS生成CSSOM树,合并为渲染树,经布局、绘制、合成后,最终呈现可视化页面。
核心要点回顾
-
流程与协议协同:全流程7步(预处理→DNS解析→TCP握手→HTTP请求→服务器响应→TCP挥手→浏览器渲染) 环环相扣,核心依赖三大协议 :DNS 负责"域名转IP"(解决"找得到服务器"),TCP 负责"可靠传输"(解决"数据传得稳"),HTTP负责"规范通信格式"(解决"数据传什么、怎么传"),三者共同支撑从URL输入到页面呈现的全链路。
-
面试高频核心:前文重点拆解的 "DNS递归/迭代查询区别""TCP三次握手/四次挥手的原理及次数必要性""HTTP状态码(2xx/3xx/4xx/5xx)含义""浏览器缓存机制(强缓存+协商缓存)""GET/POST区别""HTTP与HTTPS的安全差异" ,是面试官最常追问的点,需结合生活化例子(如打电话、找地址、点餐) 理解记忆,避免死记硬背。
-
后端实践关联:作为Java后端,需将流程与实战结合,比如:用Spring Boot的 @GetMapping/@PostMapping 接收HTTP请求、通过HttpServletRequest 获取请求头信息;配置Tomcat/Nginx 优化TCP连接与HTTP响应效率;利用SSL证书 配置HTTPS保障安全;通过Redis缓存、浏览器缓存 减少服务器压力;结合ping/telnet/F12工具 排查接口调用与页面访问问题,做到 "懂原理、会实践、能排查" 。
最后:给后端开发者的小建议
很多后端同学会忽视网络基础知识点,觉得"我只写业务代码就行"。但实际上,理解URL访问的完整流程,能帮你更好地排查接口调用问题(比如为什么接口超时、为什么数据传输异常),也能让你在设计分布式系统、微服务通信时,考虑得更全面(比如如何优化请求速度、如何保证通信可靠)。
建议大家不仅要记住流程,更要动手实践:比如用ping、telnet工具排查网络问题,用浏览器F12查看HTTP请求/响应细节,在Spring Boot项目中配置HTTPS、优化缓存。理论+实践结合,才能真正掌握这些知识。
如果这篇文章帮你理清了思路,记得点赞、在看、转发三连~ 关注喵了个Code,后续会分享更多Java后端面试干货、实战技巧,带你少走弯路,轻松拿offer!🚀
互动留言:你面试时被问过这个问题吗?还有哪些面试题想让本喵拆解?评论区告诉我!