刘敏 | 迅雷大数据平台负责人
尤帅 | 迅雷大数据平台资深工程师
陈照 | 阿里云公共云业务事业部解决方案架构师
潘锦棉 | 阿里云公共云业务事业部解决方案架构师
刘瑞伟 | 阿里云公共云业务事业部大数据解决方案架构师
一、背景介绍
企业简介
迅雷(纳斯达克股票代码:XNET)作为全球分布式技术领域的先行者,以技术构建商业,以服务创造共识,从而建立一个高效可信的存储与传输网络。
自2003年创立以来,公司通过持续深耕P2P传输、边缘计算与区块链技术,构建起覆盖全球的高效可信数据网络:这一网络不仅承载着亿级用户的日常数字生活,更成为Web3.0时代基础设施的重要实践者。
凭借对极致用户体验的追求,迅雷打造了多款行业标杆产品:革命性的迅雷下载引擎重新定义了文件传输效率,迅雷云盘以去中心化存储架构实现数据主权回归,玩客云等智能硬件则开创了共享计算新生态。
截至2025年,迅雷产品矩阵已服务全球超4亿注册用户,形成极具价值的实时行为数据金矿。
技术底座决定商业边界。迅雷深耕三大技术能力:
-
海量数据实时治理能力:每秒处理PB级传输日志与存储元数据
-
亿级节点动态调度系统:通过智能算法实现全球分布式节点毫秒级响应
-
跨场景联邦计算架构:在保障隐私安全前提下激活数据要素价值
这套经受高并发淬炼的技术体系,不仅支撑着影视、游戏、IoT等行业的关键业务场景,更沉淀出对数据流动规律的深度认知:这正是迅雷与阿里云在大数据智能时代展开深度协同的底层逻辑。
核心业务痛点
随着业务的发展,在大数据平台侧遇到了一些痛点:
-
数据处理效率存在瓶颈 :原 Hadoop 集群难以充分利用业界领先的 Native 加速 与 Remote Shuffle Service 等技术,整体性能提升受限,进而影响降本增效。
-
计算资源弹性不足:原 Hadoop 集群资源固定,当出现数据量突增、任务回溯等需要临时扩容的场景时,容易发生资源紧张;且扩容周期较长,难以快速缓解问题。
-
运维复杂度较高:原集群在资源层面需要较多人力介入;Spark 引擎升级、Python 环境管理等常见运维操作流程复杂且生产风险较高。同时,由于集群版本偏低,在业务用量增长后更易触发开源缺陷,导致稳定性下降,且难以原地升级。
-
成本管控压力较大:调度任务呈现"夜间繁忙、日间空闲"的典型波峰波谷特征,固定资源在日间存在较多闲置,造成不必要的成本浪费。
技术升级核心诉求
-
降本增效:在提升数据处理效率的同时,降低集群运维成本与硬件投入成本;
-
极致弹性:实现计算资源"按需分配、秒级扩容",精准匹配业务流量波动,避免资源闲置与短缺;
-
极简运维:摆脱集群管理负担,让技术团队聚焦核心业务开发与优化;
-
稳定可靠:保障高并发场景下数据处理的稳定性与准确性,支持任务断点续跑、故障自动恢复。
二、阿里云 EMR Serverless Spark 技术赋能
1、Serverless 模式突破算力瓶颈,实现弹性敏捷的数据处理 
原集群是一个典型的服务器架构,困境是,资源要么长期被打满,要么在空窗期大量闲置。图中 yarn_cluster_totalMB 基本是一条平直的上沿线,代表集群的总内存容量是固定不变的;而 yarn_cluster_allocatedMB 在大多数时间几乎贴着这条上沿线运行,意味着集群绝大部分时间都处在全分配的状态。看上去利用率很高,但从架构与交付视角,这更像是在提示:集群已经被当作一个"刚性资源池"使用,而不是一个能够平滑承接业务波动的弹性资源底座。
当 allocatedMB 长时间接近 totalMB,系统几乎没有任何缓冲空间。只要业务侧出现突发峰值、某个作业发生数据倾斜导致执行时间拉长、或者出现 shuffle 放大、重试增多,YARN 的调度就会立刻转向排队与拥塞。于是用户感知到的往往不是"高利用率",而是更直观的体验问题:提交任务后排队时间变长,交互式分析不再及时,批处理窗口被挤压,甚至在极端情况下形成雪崩效应------任务变慢占用资源更久,导致后续任务更排队;排队越多,超时与重试越多,反过来又进一步加剧拥塞。 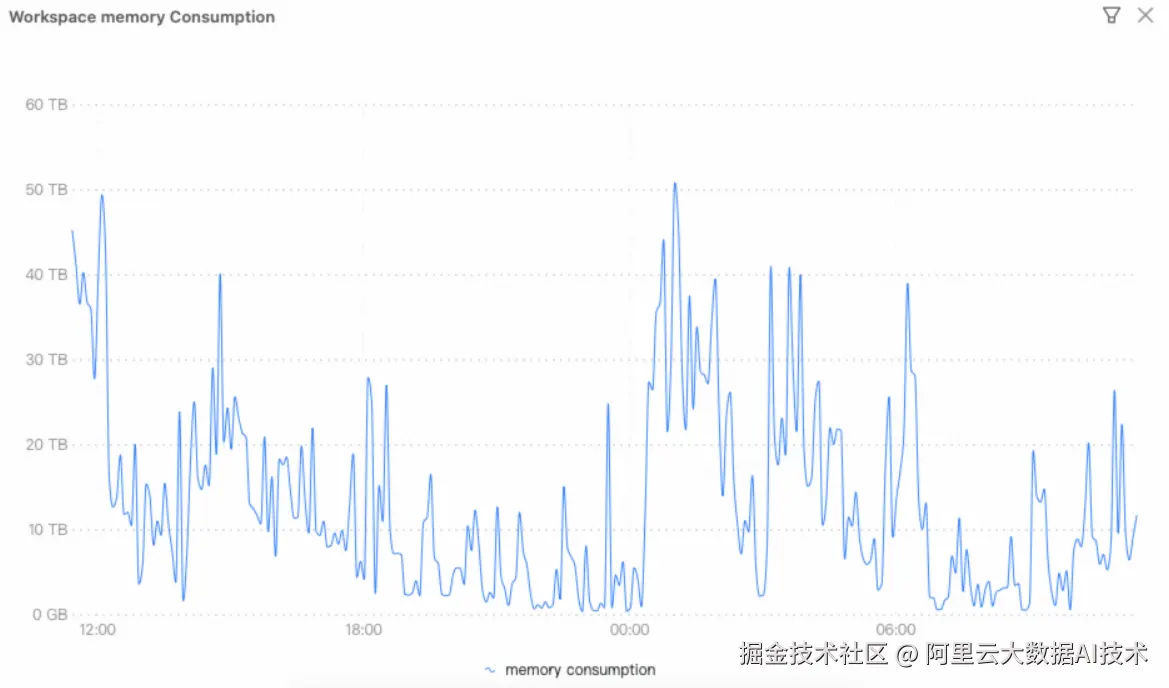
在迁移到 EMR Serverless Spark 之后,从上述这张 Workspace memory consumption 曲线呈现出非常典型的"潮汐型负载"特征:在业务高峰期内存用量可以快速拉升到数十 TB;而在任务完成、负载回落后,资源占用又能迅速下降,甚至回归到接近 0 的水平。对迅雷而言,这意味着计算资源不再被固定集群容量所束缚,峰值时能够按需获得足够的内存与并发能力去承接批处理窗口、突发任务或临时分析,从而显著降低排队、拥塞与"顶格运行"的风险,让作业完成时间与交付节奏更可控。
从系统能力角度看,这条曲线体现的是 Serverless Spark 把"容量规划与资源池运维"从用户侧彻底剥离:平台能够基于作业生命周期自动拉起资源、按需扩展、在空闲时自动回收,实现真正的弹性伸缩与更强的资源隔离。最终带来的直接收益是成本与使用量强绑定------高峰期用多少付多少,低谷期几乎不产生资源占用,也就不再为闲置容量长期买单;同时平台用自动化调度与回收机制保障资源供给的及时性与稳定性。
2、灵活访问归档数据
迅雷数据团队将大量OSS数据以归档、冷归档、深度冷归档类型存储达到降低存储费用的目的,这些归档数据无法直接访问,需要提前执行解冻操作。
EMR Serverless Spark提供自动和手动两种解冻方式便于作业灵活访问归档数据,详见解冻OSS归档文件
-
自动解冻,在作业生产plan阶段识别出归档文件,自动提交解冻请求,使得作业执行时能够正常读取数据。但对于分区值需要动态计算得出的场景,自动解冻方式无法一次提交所有解冻请求,进而影响作业执行效率。
sql--conf spark.sql.emr.autoRestoreOssArchive.enabled=true -
手动解冻,提供restore sql语法显示对表、分区提前解冻,解冻过程对用户更友好。
借助上述功能,我们能够快速响应数据分析师对历史归档数据的访问需求,降低存储成本的同时加速业务迭代。
sql
-- 解冻整个表对应的OSS归档文件供后续查询。
RESTORE TABLE table_name;
-- 指定分区解冻, 精细化控制解冻粒度,节省资源与时间。
RESTORE TABLE table_name PARTITION (pt1='a', pt2='b');3、基于Kyuubi的交互式开发
Serverless Spark内置了100%兼容开源的Kyuubi Gateway,并在云原生稳定性和多租隔离性等方面进行了增强。一方面能复用Driver/Executor资源,避免容器启动延迟,提供秒级查询,另一方面利用Spark的动态资源伸缩,闲时及时释放资源,避免浪费,从而提供高性价比的交互式分析能力。
迅雷自研的数据开发平台通过beeline和hue无缝对接Kyuubi Gateway,支持日常的数仓任务开发以及即席查询,显著提升开发分析效率,同时大幅降低了数据开发,数据分析和临时查询成本。
三、业务与技术价值双重突破
迁移到 EMR Serverless Spark 之后,最直观的感受是 TCO 明显下降:不再需要为固定集群按峰值长期备资源,平台按作业生命周期弹性拉起与回收,低谷期资源占用可降到接近 0,只为实际消耗付费。同时,托管化带来的稳定性与调度效率提升,减少了排队、重试和资源争抢等隐性成本,使同样的业务产出用更少的资源与更少的运维投入就能完成。
更关键的是交付确定性提升:大作业整体可提速约 1 小时,报表链路从过去的长尾波动变成更可控的出数节奏,关键报表能稳定在 6:00 前产出。夜间人工干预大幅减少,基本无需运维人员深夜响应。本质上反映了失败率与长尾显著降低------平台通过弹性供给、隔离与自动化恢复,把原本需要人工兜底的容量与稳定性问题前移到系统能力中解决,让生产链路更稳、更准点。
四、未来展望
在场景拓展 上,将EMR Serverless Spark广泛应用于临时查询、数据集成等更多业务场景,进一步释放其弹性、免运维的优势;另一方面,在技术深化上,积极探索AI与大数据的融合创新,充分发挥Serverless Spark在海量数据处理与AI协同方面的潜力,为业务创造更大价值。