前言
本文默认读者已经掌握了Transformer的核心架构,因为不懂transformer直接看这篇文章可能有些费劲。没有也不要紧,我尽量解释简单些。
本文适配的读者主要是想要了解BERT的人群,同时强烈建议阅读BERT、ELMo、GPT的原论文,这样才能够最真实的体会到作者的想法。
目前我就仅仅写了ResNet的博客,现在在写BERT的,后续会依次更新Vision Transformer、Transformer,感兴趣的可以关注一下。
BERT的介绍
BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的一种基于 Transformer Encoder 的预训练语言表示模型。其核心思想是通过双向上下文建模 (deep bidirectional representation)来学习词的上下文相关语义,从而为下游任务(如问答、文本分类、NER 等)提供高质量的初始表示。
BERT中主要采取的是transformer中的encoder
图一:transformer的encoder图示
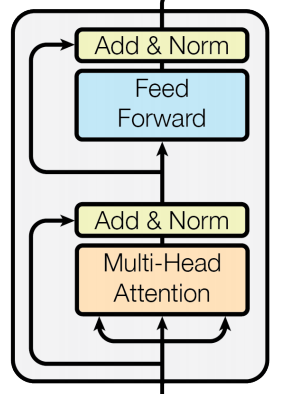
有趣的是,bert显然是凑出来的,为了对的上芝麻街中常与Ernie拌嘴的Bert,Bert的巨大成功导致NLP系列中的命名把芝麻街的名字用了个遍。包括以下:
| 模型名 | 角色 | 说明 |
|---|---|---|
| BERT | Bert(黄色长脸角色) | 谷歌的里程碑模型 |
| ERNIE | Ernie(Bert的室友) | 百度/清华等都有ERNIE模型 |
| ELMo | Elmo(红色小怪兽) | 早期语境化词向量模型 |
| Grover | Grover(蓝色毛茸茸怪物) | 生成新闻检测模型 |
| Big Bird | 大鸟(黄色大鸟) | 谷歌的长序列Transformer模型 |
| RoBERTa | 改编自Bert(更鲁棒) | Facebook优化的BERT变体 |
| ALBERT | 改编自Bert(更轻量) | 轻量版BERT |
图一:美国儿童节目《芝麻街》

图二:Bert在芝麻街中的人物形象

BERT的预训练任务
BERT 使用了两个自监督预训练任务:
掩码语言模型 Masked Language Model(MLM)
随机掩盖输入序列中 15% 的 token,其中 80% 替换为 MASK,10% 替换为随机词,10% 保留原词,然后让模型预测被掩盖的原始词。
目的:使模型学会利用上下文信息进行双向建模,避免传统语言模型只能单向训练的局限。
必须要明确的细节
BERT计算损失采取的是交叉熵损失函数(CrossEntropy()),计算损失的范围值随机选择的15%单词。下面是我曾经错误的理解,值得反省:由于我想当然的认为计算损失就是在15%中的MASK,没有考虑随机词和同义词。
场景一:输入被替换为 [MASK](80%概率)
-
模型看到的输入 :
my dog is [MASK] -
模型的任务 :在
[MASK]这个位置(即第四个词位),预测一个词汇分布(如hairy: 0.85, furry: 0.1, dog: 0.01, ...)。 -
损失计算 :计算模型预测的概率分布与
hairy这个独热(one-hot)标签 之间的交叉熵损失。模型被鼓励为hairy分配高概率。 -
这是最直观的"填空"任务。
场景二:输入被替换为随机词 apple(10%概率)
-
模型看到的输入 :
my dog is apple -
模型的任务 :在
apple这个位置(即第四个词位),预测一个词汇分布(如hairy: 0.7, fruit: 0.15, furry: 0.1, ...)。 -
损失计算 :同样 计算模型预测的概率分布与
hairy这个独热标签 之间的交叉熵损失。注意,这里的输入词是apple,但标签仍是hairy。 -
模型的挑战 :模型必须学会"无视"错误的输入
apple,而完全根据上下文(my dog is)来预测正确的词hairy。这极大地增强了模型的鲁棒性和基于上下文推理的能力。
场景三:输入保持不变 hairy(10%概率)
-
模型看到的输入 :
my dog is hairy -
模型的任务 :在
hairy这个位置(即第四个词位),预测一个词汇分布(如hairy: 0.9, furry: 0.08, animal: 0.01, ...)。 -
损失计算 :同样 计算模型预测的概率分布与
hairy这个独热标签 之间的交叉熵损失。 -
模型的挑战 :模型需要学会"承认"输入有时就是正确的。这纠正了模型的偏置------防止它形成"只要是被选中的位置,输入就一定有问题,必须改成别的词"这种错误观念。这能确保模型输出的词汇分布更接近真实文本的自然分布。
| 处理方式(概率) | 模型输入(第4词位) | 损失计算的标签(第4词位) | 模型的学习目标 |
|---|---|---|---|
| 替换为 MASK (80%) | [MASK] |
hairy |
核心填空:根据上下文预测原词。 |
| 替换为随机词 (10%) | apple |
hairy |
纠错与鲁棒性:忽略错误输入,依靠上下文。 |
| 保持原词 (10%) | hairy |
hairy |
偏置修正:有时输入即答案,输出合理分布。 |
通过对MASK、随机词和原词的训练,我们要让BERT认识到不只有MASK的地方需要预测词语,更需要在错误的词语甚至是原词都要预测成正确的答案。实际上的下游任务,随机词和原词的目的是为了
下个句子预测 Next Sentence Prediction(NSP)
图三-下个句子预测(NSP)
输入两个句子 A 和 B,50% 概率 B 是 A 的下一句(标签 IsNext),50% 概率 B 是随机句子(标签 NotNext),模型判断两者是否连续。
目的:让模型学习句子间关系,这对问答(Question Answer/QA)、自然语言推理(NLI)等任务至关重要。
具体做法:
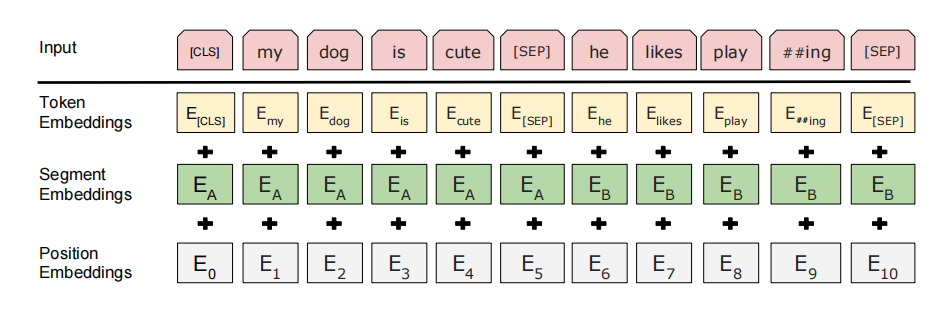
构造输入对:CLS句子ASEP句子BSEP,如上图三。其中CLS是英文单词Classification的缩写,意味着分类,SEP是英文单词Separator的缩写,意味着分隔符。
有50%的数据是句子B是句子A的真是下一句,自动生成的标签为IsNext.
有50%的数据是句子B不是句子A的下一句,是随机采样的,自动生成的标签为IsNotNext.
模型通过分类头CLS来判断句子B是否为句子A的下一句。这里的CLS分类头在Vision Transformer也有出现,在Vision Transformer中表示图片的分类结果。
结果:NSP任务对QNLI、MNLI、SQuAD 等任务有显著提升。
MNLI(Multi-Genre Natural Language Inference)是给定一个 前提句(premise) 和一个 假设句(hypothesis),判断两者之间的关系。QNLI(Question Natural Language Inference)判断问题与句子之间是否存在 语义相关性或蕴含关系。SQuAD(Stanford Question Answering Dataset)给定 一个问题 + 一段上下文段落,模型需找出段落中 连续的一段文本(span) 作为答案。
Token Embedding、Segment Embedding、Position Embedding的解释
Token Embedding
作用:将输入的每个词映射为一个固定的维度,表示其语义信息。
实现方式:BERT中的WordPiece分词方法,将单词拆解成更小的词元,如unhappy->un+happy。每个字词对应一个唯一的ID,通过查找嵌入表(Embedding Table)得到对应的
示例:
- 输入句子:"I love BERT"
- WordPiece 分词后:"I", "love", "BERT"
- 对应 Token IDs:1045, 2293, 18750
- 通过 Token Embedding 表查得三个向量。
Segment Embedding
作用:让BERT模型知道输入的两个句子中,哪个属于句子A,哪个属于句子B。
实现方式:BERT支持输入两个句子,使用SEP分割,定义了两种segment ID,0表示第一个句子,1表示第二个句子。
示例:
◦ 输入:"CLS I love BERT SEP It is powerful SEP"
◦ Segment IDs:0, 0, 0, 0, 0, 1, 1, 1, 1
◦ 每个位置加上对应的 Segment Embedding(0 或 1 的向量)。
Position Embedding
作用:为输入的序列引入位置信息
实现方式:与Transformer的正余弦编码不同,BERT采取的是学习的得到的位置参数(learned positional embeddings)
最终怎么处理的:
BERT的下游任务
1. 句子分类:情感分析(Sentiment Analysis)
📌 例子:
输入句子:"这部电影太棒了,剧情紧凑,演员演技出色!"
任务目标:判断情感是 正面(Positive) 还是 负面(Negative)
🧠 BERT 如何处理?
输入 :在句子开头加 [CLS],结尾加 [SEP]
→ [CLS] 这 部 电 影 太 棒 了 ,剧 情 紧 凑,演 员 演 技 出 色! [SEP]
输出 :取 [CLS] token 对应的隐藏向量(768维),接一个全连接分类层(如 Linear + Softmax)
训练:用交叉熵损失,微调整个 BERT + 分类头
✅ 为什么擅长?
[CLS] 在预训练中已学习到整句的语义表示
BERT 的双向上下文能捕捉"太棒了"、"演技出色"等强烈正面信号
实践中,BERT 在 IMDb、SST-2 等情感数据集上达到 SOTA(当时)
2. 句对任务:自然语言推理(NLI)
📌 例子:
前提(Premise) :"一只猫坐在窗台上。"
假设(Hypothesis) :"窗台上有一只动物。"
任务目标:判断两者关系是 蕴含(Entailment) 、矛盾(Contradiction) 还是 中立(Neutral)
→ 正确答案:蕴含(因为猫是动物)
🧠 BERT 如何处理?
输入 :把两个句子拼接,用 [SEP] 分隔
→ [CLS] 一 只 猫 坐 在 窗 台 上。 [SEP] 窗 台 上 有 一 只 动 物 [SEP]
输出 :同样取 [CLS] 向量,接 3 分类头(entail/contradict/neutral)
预训练支持 :BERT 原始预训练包含 NSP(Next Sentence Prediction),虽然后来发现作用有限,但句对建模能力已被 MLM 强化
✅ 为什么擅长?
BERT 能同时理解两个句子的语义,并建模它们之间的逻辑关系
在 MNLI、RTE 等数据集上大幅超越之前模型(如 LSTM+Attention)
3. 序列标注:命名实体识别(NER)
📌 例子:
输入句子:"苹果公司于1976年由乔布斯在加州创立。"
任务目标:为每个词标注实体类型
正确标注:
- "苹果" →
B-ORG(组织名开始)- "公司" →
I-ORG(组织名内部)- "1976年" →
B-DATE- "乔布斯" →
B-PER- "加州" →
B-LOC
🧠 BERT 如何处理?
输入 :[CLS] 苹果公司于1976年由乔布斯在加州创立。 [SEP]
输出 :对每个输入 token (除 [CLS]、[SEP])的隐藏向量,分别接一个分类器,预测其 NER 标签
注意:中文需先分词(或用字级别),英文通常用 WordPiece,需对齐标签,避免子词碎片问题
✅ 为什么擅长?
BERT 的深层上下文能区分"苹果"是公司(ORG)还是水果(O)
双向信息有助于识别边界(如"加州"是地名,不是"加"和"州"分开)
在 CoNLL-2003 英文 NER 上 F1 > 92%,远超 BiLSTM-CRF
4. 抽取式问答:SQuAD 风格问答
📌 例子:
问题 :"《哈利·波特》的作者是谁?"
上下文 :"J.K. 罗琳是《哈利·波特》系列小说的作者,她出生于英国。"
任务目标:从上下文中直接抽取出答案片段 → "J.K. 罗琳"
🧠 BERT 如何处理?
输入 :[CLS] 问 题 [SEP] 上 下 文 [SEP]
输出:
- 对上下文每个 token,预测它是否是答案的起始位置
- 同样预测结束位置
- 最终答案 = 起始到结束之间的文本
模型输出两个向量:start logits 和 end logits,取概率最高的合法组合
✅ 为什么极其擅长?
- BERT 能精准对齐问题词("作者")和上下文中的对应实体("J.K. 罗琳")
- 双向注意力让模型理解"作者"与"J.K. 罗琳"的语义关联
- 在 SQuAD 1.1 上,BERT-large 首次超越人类表现(EM: 87.4 vs 人类 86.8)
5. 文本生成:机器翻译(举例说明为何不擅长)
📌 例子:
输入(中文):"你好,世界!"
期望输出(英文):"Hello, world!"
❌ BERT 为什么不适合?
架构限制 :BERT 是 纯编码器(Encoder-only),没有解码器(Decoder)
训练方式 :MLM 是独立预测被 mask 的词 ,不建模自回归生成(即从左到右逐词生成)
无法生成新序列 :BERT 只能对已有输入序列做理解或 fill-in-the-blank,不能从零生成流畅文本
表格一:BERT下游任务的简单总结
| 任务类型 | 具体例子 | BERT 输入形式 | 输出方式 | 擅长原因 |
|---|---|---|---|---|
| 句子分类 | "这电影太差了" → 负面 | [CLS] 句子 [SEP] |
[CLS] + 分类头 |
[CLS] 聚合全局语义 |
| 句对任务 | 前提+假设 → 蕴含 | [CLS] 句1 [SEP] 句2 [SEP] |
[CLUS] + 3分类 |
强大的句对交互建模 |
| 序列标注 | "乔布斯" → B-PER | [CLS] 乔 布 斯 ... [SEP] |
每个 token 分类 | 逐词上下文理解 |
| 抽取式问答 | 问+文 → "J.K. 罗琳" | [CLS] 问 [SEP] 文 [SEP] |
预测 start/end 位置 | 精准语义对齐 |
| 文本生成 | 中文 → 英文翻译 | ❌ 不适用 | ❌ 无法自回归生成 | 无解码器,非生成式架构 |
图四-BERT的预训练和微调统一为整体
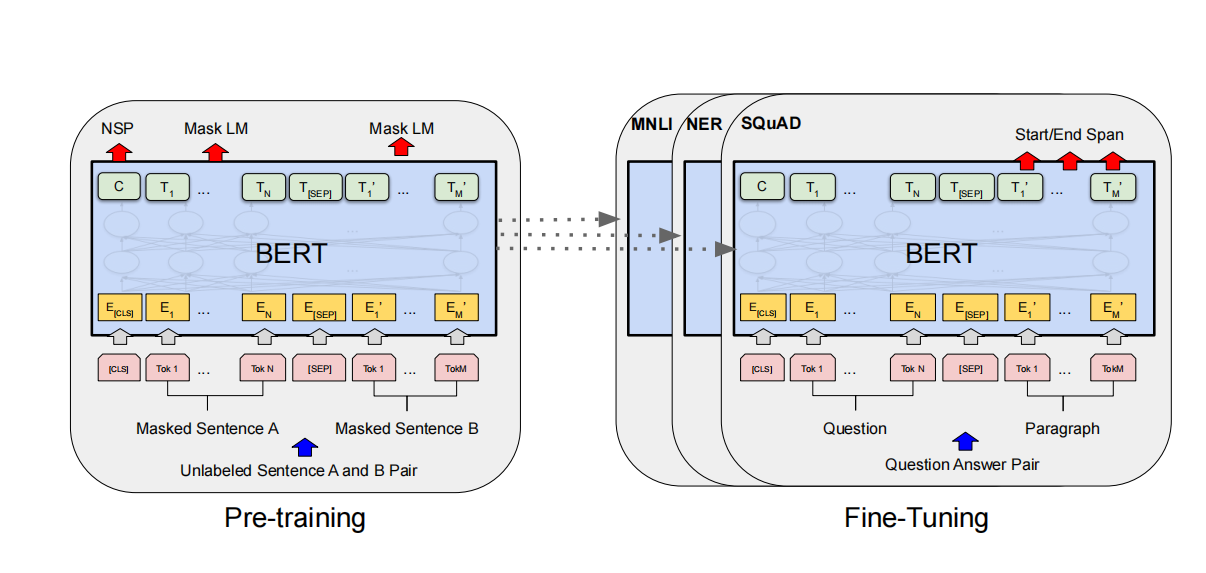
BERT的贡献
虽然"预训练 + 微调"(Pre-training + Fine-tuning)的思想在BERT之前已有雏形,但BERT之所以被广泛认为是"开启"这一范式的关键里程碑,是因为它首次系统性地证明了:一个通用的、大规模预训练的语言模型,仅通过简单微调,就能在多种NLP任务上取得显著优于以往方法的性能。以下是详细解释
- 统一架构,通用于几乎所有NLP任务
• 无论是文本分类、问答、NER、推理还是句子相似度,只需在BERT顶部加一个简单任务头,其他结构完全一致。
• 无需为每个任务设计复杂专用模型(如BiLSTM-CRF、Match-LSTM等)。
- 端到端微调整个模型
• BERT微调时更新全部参数(包括Transformer编码器和任务头),最大化利用预训练知识。
• 相比ELMo的"特征提取"方式,微调能动态适配任务需求,性能显著提升。
区分自监督学习和无监督学习
我单独拿一章介绍是因为我发现我没区分这两个概念,导致我看BERT就有疑问,为什么说是无监督学习?查了资料才发现BERT中的MLM和NSP是自监督学习。
自监督学习和无监督学习都是**零样本(zero-shot)**的学习。但是实际上是有一定的差距的:
本文的BERT中的MLM和NSP均属于自监督学习。对那15%处理的MASK、随机词和原词,BERT都被要求对那个词语进行预测,而在处理之前,正确答案就出来了,**因为答案是来自于数据,并非人工标注。**如无论是my dog is MASK、my dog is apple、my dog is hairy,他们的答案都已经是hairy,这个hairy是来自文本,不是人工标注的。
无监督学习(Unsupervised Learning)是机器学习的三大核心范式之一(另外两种是监督学习、半监督学习),其核心特征是训练数据无人工标注的标签,模型需要自主从数据中挖掘内在的结构、规律或模式,而非学习 "输入→标签" 的映射关系。常见的无监督学习方法有聚类(K-means)、降维(Autoencoder、PCA)、密度估计与生成模型(GAN、VAE)。
早期机器学习领域对自监督学习(Self-Supervised Learning/SSL)和传统无监督学习(Unsupervised Learning/UL)的区分并不严格,二者常被混为一谈;直到 BERT、MoCo 等模型推动 SSL 爆发后,学界才逐步明确二者在目标、机制与应用上的核心差异,形成相对清晰的界定。
| 类型 | 是否需要标签? | 标签来源 | 典型任务 | 代表方法/模型 |
|---|---|---|---|---|
| 有监督学习(Supervised Learning) | ✅ 需要 | 人工标注 | 分类、回归、目标检测 | ResNet、BERT(微调阶段)、SVM |
| 无监督学习(Unsupervised Learning) | ❌ 不需要 | 无标签 | 聚类、降维、密度估计 | K-Means、PCA、GAN(生成部分) |
| 自监督学习(Self-Supervised Learning) | ⚠️ 用"伪标签" | 从数据自身构造 | 表示学习、预训练 | BERT(MLM/NSP)、SimCLR、MAE |
| 半监督学习(Semi-Supervised Learning) | ✅ + ❌ 混合 | 少量人工 + 大量无标签 | 分类(标签稀缺场景) | FixMatch、MixMatch、UDA |
| 弱监督学习(Weakly Supervised Learning) | ✅(但不准确) | 不精确/噪声标签 | 图像定位、多实例学习 | 多实例学习(MIL)、远程监督 |
| 对比学习(Contrastive Learning) | ⚠️ 自监督的一种 | 通过"正负样本对"构造监督 | 表示学习 | SimCLR、MoCo、CLIP |
面试常见问题汇总
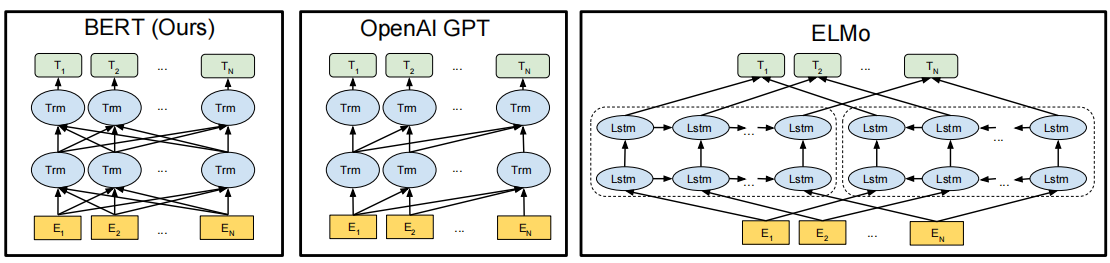
BERT的全称是什么?它与之前的预训练模型(如GPT、ELMo)的核心区别是什么?
答案:
BERT全称是Bidirectional Encoder Representations from Transformers 。
核心区别:
-
双向性:BERT使用Masked Language Model(MLM)预训练,同时利用左右上下文信息,而GPT是单向的(仅左到右),ELMo是浅层双向(独立训练左右LSTM后拼接)。
-
预训练任务:除了MLM,BERT还引入Next Sentence Prediction(NSP)任务,以理解句子间关系。
-
架构:BERT基于Transformer Encoder,ELMo基于LSTM,GPT基于单向Transformer。
ELMo虽然采用了前向语言模型(Forward ML)和后向语言模型(Backward ML),但是是把他们拼接起来,没有实现实际的交互,并不是双向的,是伪双向的的。GPT本身是自回归语言模型,这本身就决定了GPT是从左到右的,此外,由于GPT采取了因果掩码,导致GPT他只能向前看。
图五-如何理解BERT、GPT、ELMo之间的差别
关键技术题:BERT 用了哪两个预训练任务?为什么需要它们?
问法示例:
• BERT 的预训练任务有哪些?请详细说明。
• 为什么 BERT 要设计 "Next Sentence Prediction" 任务?
参考答案:
BERT 使用了两个无监督预训练任务:
- Masked Language Model(MLM):
◦ 随机掩盖输入序列中 15% 的 token(其中 80% 替换为 MASK,10% 替换为随机词,10% 保留原词),然后让模型预测被掩盖的原始词。
◦ 目的:使模型学会利用上下文信息进行双向建模,避免传统语言模型只能单向训练的局限。
- Next Sentence Prediction(NSP):
◦ 输入两个句子 A 和 B,50% 概率 B 是 A 的下一句(标签 IsNext),50% 概率 B 是随机句子(标签 NotNext),模型判断两者是否连续。
◦ 目的:让模型学习句子间关系,这对问答、自然语言推理(NLI)等任务至关重要。
进阶/批判性题:BERT 有哪些局限性?后来的模型如何改进?
问法示例:
• 你觉得 BERT 有什么不足?
• RoBERTa、ALBERT、ELECTRA 是如何改进 BERT 的?
参考答案(简要):
• 局限性:
-
MLM 造成 pretrain-finetune 不一致;
-
NSP 任务被后续研究(如 RoBERTa)证明可能无效甚至有害;
-
预训练计算成本高;
-
静态 mask(每个 epoch mask 一样)限制多样性。
• 改进方向:
◦ RoBERTa:去掉 NSP,动态 mask,更大 batch,更多数据。
◦ ALBERT:参数共享 + 因式分解,大幅减少参数。
◦ ELECTRA:用 replaced token detection(RTD)替代 MLM,更高效。
模型输入题:BERT 如何处理单句和句对任务?
问法示例:
• BERT 的输入格式是怎样的?如何区分两个句子?
• CLS 和 SEP 的作用分别是什么?
参考答案:
BERT 的输入由三部分 embedding 相加而成:
• Token Embedding(词本身)
• Segment Embedding(区分句子 A / B)
• Position Embedding(位置信息)
具体格式:
• 单句任务:CLS + tokens + SEP
• 句对任务:CLS + sentA + SEP + sentB + SEP
其中:
• CLS:Classification token,其最终隐藏状态 C 作为整个序列的聚合表示,用于分类任务。
• SEP:分隔符,用于区分句子边界。
• Segment Embeddings:A 句所有 token 用 EA,B 句用 EB,帮助模型区分两个句子。
参考资料:
ELMo的论文链接:https://arxiv.org/abs/1802.05365
GPT1的论文链接:language_understanding_paper.pdf
Bert的论文链接:https://arxiv.org/pdf/1810.04805.pdf
李沐对BERT论文讲解:BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili
CSDN目前6.7w阅读量的BERT:万字长文,带你搞懂什么是BERT模型(非常详细)看这一篇就够了!-CSDN博客
知乎的长文:
(99+ 封私信 / 80 条消息) 从Word Embedding到Bert模型---自然语言处理中的预训练技术发展史 - 知乎