自动化工具Drissonpage 保姆级教程(含xpath语法)
说明:本指南仅供技术研究与学习使用,请严格遵守相关法律法规,仅将自动化技术应用于合法合规的场景 ,如:公开数据的采集与分析、企业内部系统的自动化测试、个人工作效率提升工具等。严禁用于任何违法违规行为,违者责任自负!

一、工具简介
1. 什么是 DrissionPage?
DrissionPage 是一个创新的 Python 网页自动化工具,它巧妙地将两种主流技术融合在一起:
- 浏览器模式:类似 Selenium,可真实操作浏览器,完美处理动态加载的网页
- HTTP请求模式:类似 requests,直接发送 HTTP 请求,轻量高效
核心优势:你可以在同一脚本中根据需求智能切换这两种模式,实现"该快的时候快,该稳的时候稳"。且基于Chromium DevTools Protocol自研内核,重写了Selenium的所有功能。
2. 为什么选择 DrissionPage?
| 场景 | 传统方案 | DrissionPage 方案 |
|---|---|---|
| 静态网页数据采集 | requests + 解析库 | 使用请求模式,速度极快 |
| 动态交互操作 | Selenium 等浏览器驱动 | 使用浏览器模式,稳定可靠 |
| 混合型任务 | 需要编写两套代码 | 一套代码无缝切换 |
二、核心概念:自动化技术对比
| 工具 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| DrissionPage | 双模式融合,API 简洁,性能较好 | 相对较新,社区较小 | 需要灵活切换模式的自动化任务 |
| Selenium | 功能强大,社区活跃,浏览器支持好 | 执行速度慢,资源占用高 | 复杂交互、需要真实浏览器的场景 |
| Playwright | 现代化,支持多浏览器,自动等待 | 学习曲线较陡 | 现代 Web 应用测试 |
| Requests + BeautifulSoup | 速度快,资源占用低 | 不支持 JavaScript | 静态页面爬虫 |
bash
┌─────────────────────────────────────────┐
│ 网页自动化技术对比 │
├─────────────────────────────────────────┤
│ │
│ 1. 纯请求方式 (requests + 解析库) │
│ ✅ 优点:速度快、资源占用少 │
│ ❌ 缺点:无法执行JS、处理动态内容困难 │
│ │
│ 2. 浏览器驱动方式 (Selenium等) │
│ ✅ 优点:真实浏览器环境,全能 │
│ ❌ 缺点:速度慢、资源消耗大 │
│ │
│ 3. DrissionPage 融合方式 │
│ ✅ 两全其美:按需切换,灵活高效 │
│ │
└─────────────────────────────────────────┘三、快速上手
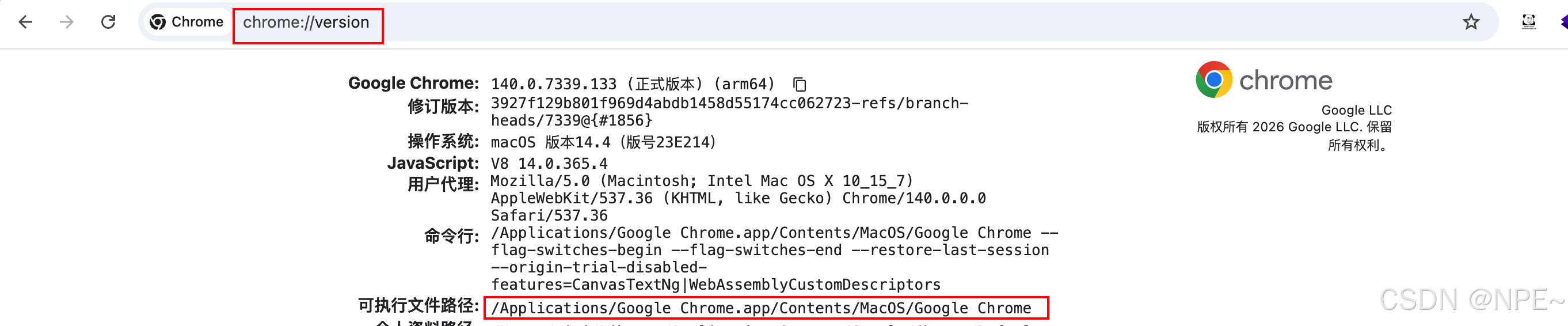
1. 确认浏览器路径
为了让Drissonpage操作本地浏览器,我们需要找到本地浏览器执行文件地址。
- 打开Chrome浏览器,搜索框中输入
chrome://version/ - 复制下面可执行文件地址
2. 编写代码
新建Python项目,并安装依赖
- 通过pip安装Drissonpage依赖
python
# 安装对应依赖
pip install DrissionPage- 编写代码,操作浏览器
python
import time
from DrissionPage import ChromiumPage, ChromiumOptions
co = ChromiumOptions()
# 填写本地浏览器路径
co.set_browser_path("/Applications/Google Chrome.app/Contents/MacOS/Google Chrome")
# 创建page对象
page = ChromiumPage(co)
# 访问百度
page.get("http://www.baidu.com")
time.sleep(50)效果:

四、XPath 语法精要
学习资源:
- 文档教学:
- W3School 教程:https://www.w3school.com.cn/xpath/index.asp
- 菜鸟教程:https://www.runoob.com/xpath/xpath-tutorial.html
- 工具推荐:Chrome浏览器可安装 SelectorsHub插件 ,可实时验证 XPath 是否正确(其他浏览器也有类似插件)
1. 最常用语法
python
##############基本定位##############
//div # 所有div元素
//div[@class='header'] # class为header的div
//a[@href='/login'] # href为/login的链接
//button[text()='提交'] # 文本内容为"提交"的按钮
##############灵活匹配##############
//div[contains(@class, 'nav')] # class包含"nav"的div
//a[starts-with(@href, 'https')] # href以https开头的链接
//div[contains(text(), '欢迎')] # 文本包含"欢迎"的div
##############层级与顺序##############
//div[@id='main']//a # main元素下的所有a标签(任何层级)
//div[@id='main']/a # main元素的直接子a标签
//ul/li[1] # 第一个li元素
//ul/li[last()] # 最后一个li元素
//tr[position()>1] # 第二个及之后的tr
##############文本匹配##############
//a[text()="立即购买"]
# 多条件组合
//input[@type="text" and @name="username"]
# 获取属性值(用于提取链接、图片等)
//a/@href # 获取所有链接地址
//img/@src # 获取所有图片地址
# 复杂文本匹配
//div[starts-with(text(), "订单编号:")] # 以指定文本开头
//span[contains(text(), "优惠")] # 文本包含特定内容2. 调试技巧
- Chrome应用商店安装SelectorsHub插件
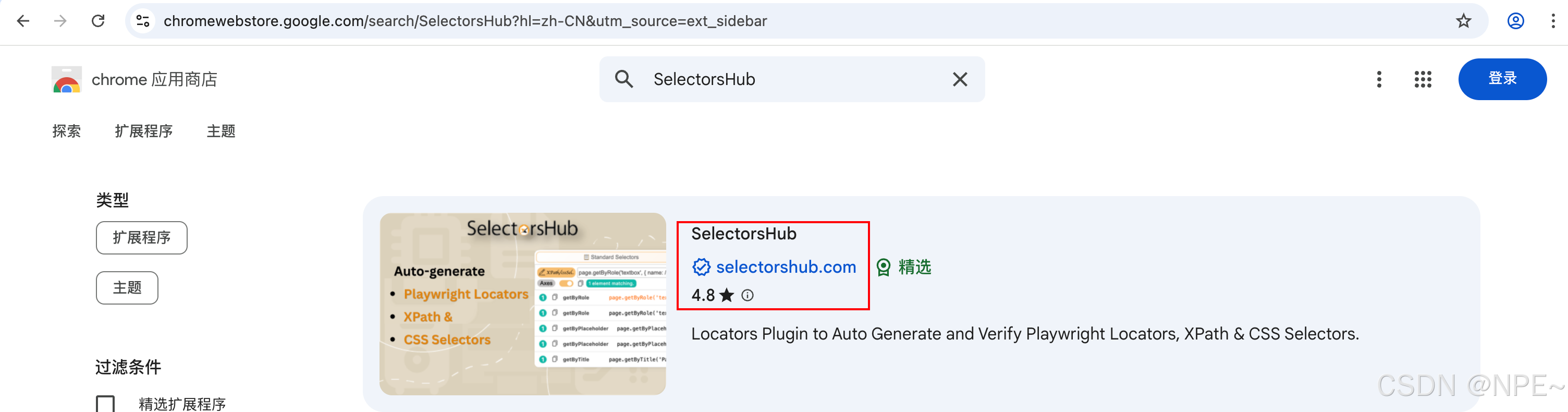
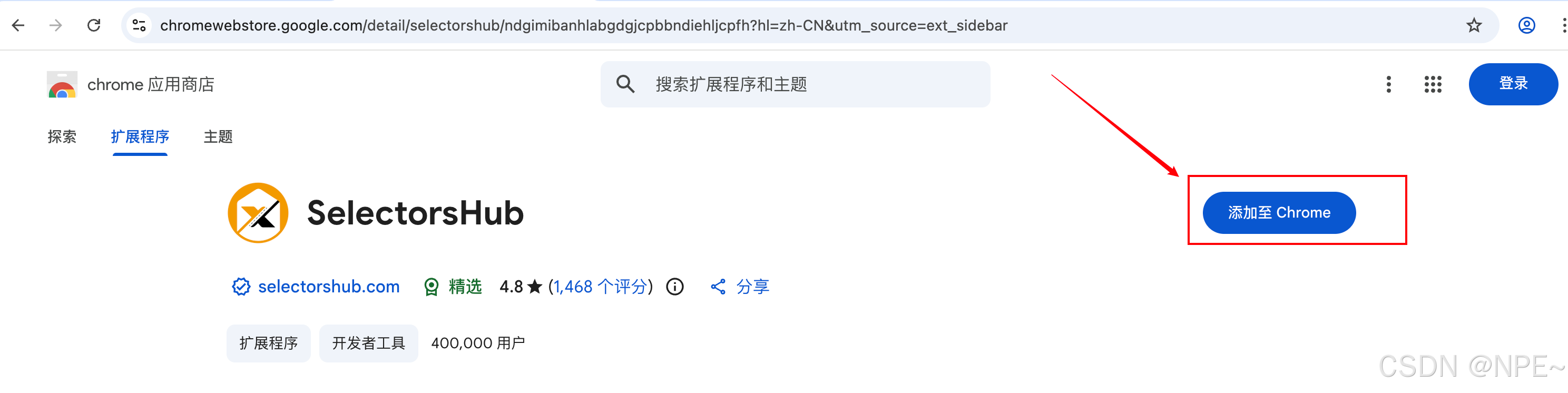
- 安装完成后将其固定在搜索框tab

- 打开任意网站后,鼠标点击插件图标,进入搜索框

- 按下F12或者option+command+I打开开发者工具,选中需要定位的元素。比如:我需要定位搜索框,通过选择器定位到对应元素位置后,查看对应html结构,在id为chat-input-area的div元素下

- 在SelectorsHub中输入对应xpath语法 //div@id="chat-input-area"

最后成功定位到对应元素。
五、DrissionPage 核心用法
1. 快速开始:一个完整示例
python
from DrissionPage import ChromiumPage
import time
# 1. 创建浏览器页面对象
page = ChromiumPage()
# 2. 访问网页(浏览器模式)
page.get('https://www.baidu.com')
# 3. 定位搜索框并输入(多种定位方式)
# 方式一:CSS选择器
search_input = page.ele('#kw')
# 方式二:XPath
search_input = page.ele('xpath://input[@id="kw"]')
# 方式三:文本匹配
search_input = page.ele('百度一下')
# 搜索框输入内容
search_input.input('ziyi 程序员 bilibili')
# 4. 点击搜索按钮
page.ele('xpath://button[@id="chat-submit-button"]').click()
# 5. 等待结果加载
time.sleep(3)
# 6. 打印搜索结果
results = page.eles('xpath://h3[contains(@class, "t")]')
for i, result in enumerate(results[:5], 1):
title = result.text
print(f'结果{i}: {title}')
# 此处仅为演示效果,休眠5s
time.sleep(5)
# 7. 关闭浏览器
page.quit()效果:


2. 请求模式说明
此处仅展示核心代码。代码中 page (ChromiumPage) 和 session (SessionPage) 是两个独立的对象。
- 浏览器模式:ChromiumPage是 Chromium 内核浏览器的页面,它用 POM 方式封装了操控网页所需的属性和方法。使用它,我们可与网页进行交互,如调整窗口大小、滚动页面、操作弹出框等等。
- HTTP模式:SessionPage是一个使用使用Session(requests 库)对象的页面,它使用 POM 模式封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。使用它可以请求后端接口,发起http请求。
python
# 浏览器模式获取动态 token
page.get('https://m.weibo.cn')
token = page.ele('meta[name="csrf"]').attr('content')
# 切换到 HTTP 模式批量抓取
session = SessionPage()
for page_num in range(1, 6):
url = f'https://m.weibo.cn/api/feed?token={token}&page={page_num}'
session.get(url)
print(session.json['data'])3. 元素定位方法
python
# 查找单个元素
element = page.ele('选择器') # 支持多种选择器
element = page.ele('xpath://div[@id="content"]')
element = page('选择器') # 简化写法
# 查找多个元素
elements = page.eles('选择器') # 返回列表
elements = page.eles('xpath://a[@class="link"]')
# 链式查找
parent = page.ele('#container')
child = parent.ele('.item') # 在父元素内查找
all_children = parent.eles('tag:div') # 查找所有div子元素4. 常用交互操作
python
# 输入文本
element.input('要输入的文本')
element.input('文本', clear=True) # 先清空再输入
# 点击操作
element.click() # 左键单击
element.click(by_js=True) # 使用JavaScript点击(规避一些限制)
# 获取信息
text = element.text # 获取元素文本
html = element.html # 获取内部HTML
attr_value = element.attr('href') # 获取属性值
# 下拉框选择
from DrissionPage import Select
select = Select(element) # 包装为Select对象
select.select('选项文本') # 按文本选择
select.select(index=0) # 按索引选择
# 文件上传
element.input('文件路径') # 对于文件输入框5. 等待与跳转
python
## 智能等待(推荐)
# 等待单个匹配选择器的元素在页面上变为可见状态,显式等待元素出现,最多10秒。
# 比如等待页面出现button为登录按钮
page.wait.ele_displayed('xpath://button[contains(text(), "登录")]', timeout=10)
# 等待一组匹配选择器的元素加载完成(存在于DOM中)
# 选择所有 class 属性值中包含 AnswerItem 这个单词的HTML元素
page.wait.eles_loaded('.AnswerItem', timeout=10)
# 等待页面跳转完成
page.wait.load_start()
page.wait.load_complete()
# 强制等待
import time
time.sleep(2)
# 页面导航
page.get('https://example.com') # 跳转到新页面
page.back() # 后退
page.forward() # 前进
page.refresh() # 刷新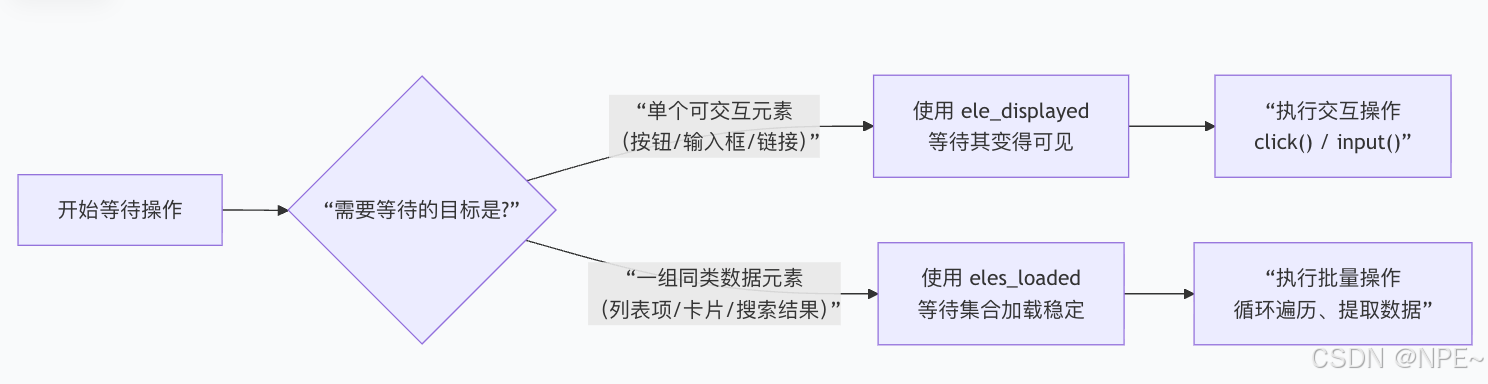
6. 登录态保持
绝大部分网站都需要校验登录态,因此保持登录态是很有必要的。
python
# 浏览器模式登录
page.get('https://passport.zhihu.com/login')
page.ele('#username').input('user@example.com')
page.ele('#password').input('your_password')
page.ele('button[type="submit"]').click()
# 同步 Cookie 到 HTTP 模式
session.cookies = page.cookies
# 使用共享登录态
session.get('https://www.zhihu.com/notifications')7. 反爬绕过
目前很多网站都做了反爬策略,不过可以通过如下一些操作绕过一些检测。
- 指纹伪装配置:让爬虫看起来像是用户通过真实浏览器发送的请求
python
co = ChromiumOptions()
# 修改浏览器指纹
co.set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
co.set_platform('Win32')
co.set_resolution(1920, 1080)
# 禁用 WebRTC。WebRTC是一项允许浏览器进行实时音视频通信的技术,禁用它可以绕过反爬,
## 核心原因是它能泄露你的真实IP地址,让网站发现你使用了代理,从而暴露爬虫身份。
co.set_argument('--disable-webrtc')- 流量特征优化:通过随机延迟点击、滚动等操作时间,绕过机器检测,让爬虫看起来更像真人
python
# 随机化操作间隔
import random
page.set.click_options(interval=(0.5, 2))
# 模拟人类滚动
page.scroll.to_bottom(step=300, duration=1.5)- 设置代理IP:通过配置代理IP,降低同一IP请求频次
python
### 模式一:直接操作浏览器网页方式
# 对于 ChromiumPage (浏览器模式) - 正确方式
co = ChromiumOptions()
co.set_proxy('http://127.0.0.1:1080') # 通过选项设置
page = ChromiumPage(co)
### 模式二:HTTP请求方式
# 对于 SessionPage (请求模式)
session = SessionPage()
session.proxies = {'http': 'http://127.0.0.1:1080', 'https': 'https://127.0.0.1:1080'} # 支持http/https
# 或使用 set.proxies() 方法
session.set.proxies('http://127.0.0.1:1080')六、实战项目:知乎热门问题数据获取
需求说明:
- 目标:采集知乎热榜前 20 问题
- 字段:标题、热度值
- 难点:动态加载、登录验证、反爬机制、数据提取、结果持久化
代码示例:
python
from DrissionPage import ChromiumPage, ChromiumOptions
import pandas as pd
import time
import random
def get_zhihu_top20():
"""
获取知乎Top20榜单数据
功能涵盖:反爬优化、登录态、数据提取、结果持久化
"""
# 1. 基础配置与反爬
co = ChromiumOptions()
co.set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
# 后续可设置账号池、IP代理池等
# 2. 创建浏览器对象
page = ChromiumPage(addr_or_opts=co)
page.get('https://www.zhihu.com')
time.sleep(2)
# 3. 处理登录(简化版,需手动干预)后续可自动配置账号密码,自动化登录
# 检查当前是否是未登录状态
if page.ele('xpath=//div[@id="root"]/div/main/div[@class="SignFlowHomepage"]'):
print("请手动完成登录...")
print("1. 如需扫码,请直接用手机知乎APP扫码")
print("2. 如需密码登录,请在页面输入账号密码")
print("3. 登录成功后,请回到程序按回车继续")
input("完成后请按回车键...") # 暂停,等待用户手动操作
print("继续执行...")
else:
print("当前已登录,无需登录。")
# 4. 访问热榜并抓取数据
page.get('https://www.zhihu.com/hot')
# 等待页面元素加载
page.wait.eles_loaded('.HotItem', timeout=10)
results = []
# 等待并获取热榜条目
items = page.eles('css:.HotItem')
for item in items[:20]: # 只取前20条
try:
title = item.ele('.HotItem-title').text
heat = item.ele('.HotItem-metrics HotItem-metrics--bottom').text
results.append({'标题': title, '热度': heat})
time.sleep(random.uniform(0.1, 0.3)) # 微小延迟,避免请求过快
except Exception as e:
print(f"处理条目时出错: {e}")
# 5. 保存结果
if results:
df = pd.DataFrame(results)
df.to_excel('知乎热榜.xlsx', index=False)
print(f"成功获取 {len(results)} 条热榜数据,已保存至 知乎热榜.xlsx")
else:
print("未获取到数据,可能是选择器失效或页面未正确加载。")
# 保持浏览器打开供检查,生产环境可关闭
# page.quit()
if __name__ == '__main__':
get_zhihu_top20()效果:

七、常见问题解决
问题1:元素找不到
解决:
python
1. 增加等待时间
2. 检查选择器是否正确
3. 使用更稳定的定位方式问题2:点击无效
解决:
python
1. 尝试 click(by_js=True)
2. 先滚动到元素位置
3. 等待元素可点击问题3:页面加载慢
解决:
python
1. 设置超时时间
2. 禁用图片加载
3. 使用请求模式获取数据问题4:被网站检测(反爬限制)
解决:
python
1. 添加随机延迟
2. 使用代理IP、账号池
3. 模拟人类操作模式