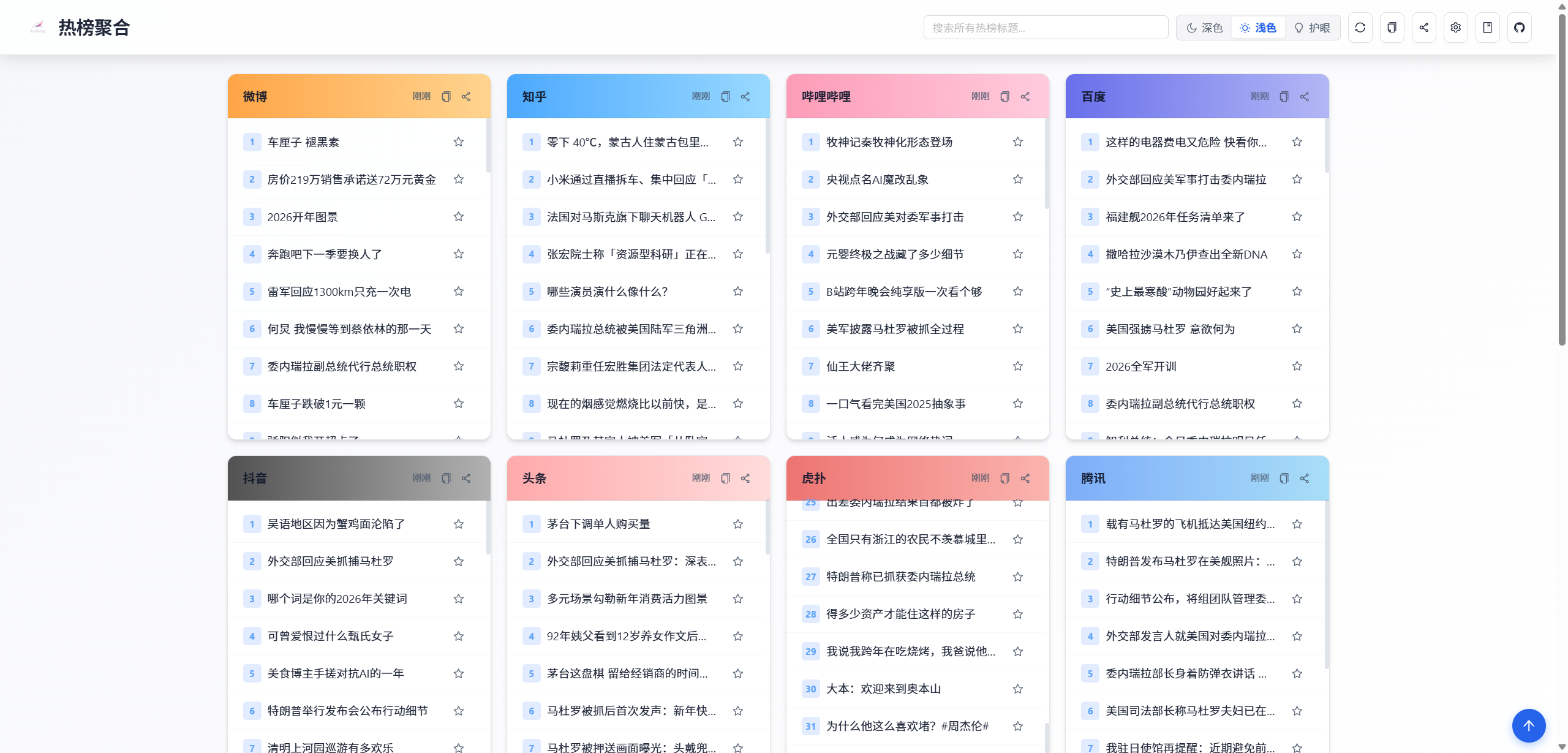
在信息爆炸的时代,我们每天都被来自四面八方的新闻和热点轰炸。微博、知乎、B站、抖音... 每个平台都有自己的热门榜单,想要一站式了解"今天互联网上发生了什么"变得越来越麻烦。
今天,我向大家介绍一个开源项目------Aneiang.Pa.News,它完美地解决了这个痛点。这是一个"热点/热搜聚合"应用,能将多个来源的热点内容整合到同一个清爽的界面中,让你一览无余。
- 在线体验: https://news.aneiang.com/
- GitHub 仓库: https://github.com/AneiangSoft/Aneiang.Pa.News
- Gitee 仓库: https://gitee.com/aneiangsoft/Aneiang.Pa.News
- Docker 镜像:
caco/aneiang-pa-news
✨ 项目亮点
- 多平台聚合:一站式浏览来自不同站点的热点新闻,无需在多个 App 之间来回切换。
- 清爽的阅读体验:基于 React 和 Ant Design 构建的现代化前端界面,简洁、美观、响应式,在桌面和移动设备上都有出色的表现。
- 一键海报分享:看到有趣的热榜?可以一键生成精美的分享海报,轻松分享到社交媒体。
- 高度可定制:支持自定义数据源、调整缓存策略,满足个性化需求。
- 部署极其简单:得益于 Docker,你可以在几分钟内拥有一个属于自己的、7x24 小时运行的热点聚合服务。
🚀 技术栈揭秘
Aneiang.Pa.News 采用了经典的前后端分离架构:
- 后端 (Pa.HotNews.Api) :基于 .NET 8 / ASP.NET Core 构建。它不仅负责从各大网站抓取和聚合热点数据,还通过高效的缓存机制确保了快速的响应。同时,它也直接托管了前端的静态文件,简化了部署。
- 前端 (Pa.HotNews.Web) :采用 React + Vite + Ant Design 的现代化技术栈。Vite 带来了闪电般的开发启动和构建速度,而 React 和 Ant Design 的组合则保证了组件化和高质量的 UI 体验。
此外,项目还提供了一个备选的 Blazor 前端 (Pa.HotNews.Blazor),展示了 .NET 生态内的多种可能性。
快速上手:拥有你自己的热点聚合站
得益于 Docker,部署 Aneiang.Pa.News 变得前所未有的简单。即使你不是开发者,只要你的设备安装了 Docker,也能轻松搞定。
-
拉取 Docker 镜像
bashdocker pull caco/aneiang-pa-news:1.0.3 -
创建日志目录
bashmkdir -p logs -
启动容器
bashdocker run -d --name aneiang-pa-news \ -p 5000:8080 \ -e ASPNETCORE_URLS=http://+:8080 \ -e HotNews__EnableCache=true \ -e HotNews__CacheSeconds=1800 \ -v $(pwd)/logs:/app/logs \ caco/aneiang-pa-news:1.0.3
现在,打开浏览器访问 http://localhost:5000,你的个人热点聚合站就已经成功运行了!
深入探索
对于开发者来说,这个项目也是一个绝佳的学习案例。你可以:
- 学习后端 :研究
Pa.HotNews.Api如何通过Aneiang.Pa.AspNetCore依赖实现灵活的数据抓取和接口暴露。 - 学习前端 :在
Pa.HotNews.Web中,你可以看到 React Hooks、组件化开发、与后端 API 交互以及使用 Vite 构建的最佳实践。 - 学习 Docker 部署 :通过
Dockerfile和docker-compose.yml,深入理解如何将一个 .NET 和 React 应用容器化,并实现高效的构建和部署流程。
总结
Aneiang.Pa.News 不仅仅是一个方便的工具,它还是一个结合了 .NET 和 React 生态的优秀开源项目。它展示了如何用现代技术栈解决一个常见的日常需求,并将其打包成一个易于部署和使用的产品。
无论你是一个希望简化信息获取渠道的普通用户,还是一个正在寻找学习项目或灵感的开发者,Aneiang.Pa.News 都值得你一试。