Redis 本质是一个内存数据库 相比于MySQL这样的关系型数据库,最明显的特点就是快/效率高
当我们要插入新的数据时,就会把这个数据,同时写入到内存和硬盘
这俩份数据理论上是完全相同的,但是实际上有小概率有差异,取决于咱们具体怎么实现持久化
当查询某个数据时直接从内存读取
硬盘的数据只是在Redis重启时,用来恢复内存中的数据的
代价就是消耗更多空间(但毕竟硬盘便宜,这样的开销并不会带来太大成本)
Redis实现持久化 具体是按照什么样的策略呢
1.RDB =>Redis DataBase //定期备份
2.AOF=>Append Only File //实时备份
RDB
Redis定期将内存中的数据存储在硬盘中,并且将存储好的数据生成一个"快照"
后续Redis 一旦重启 就可以通过快照来将数据从硬盘缓存到内存中
"定期"存在两种方式
1.手动触发
通过Redis客户端,执行特定的命令,来触发快照生成
save 执行save时候 Redis就会全力以赴的去进行快照生成操作,此时就会阻塞redis的其他操作(Redis是单线程)
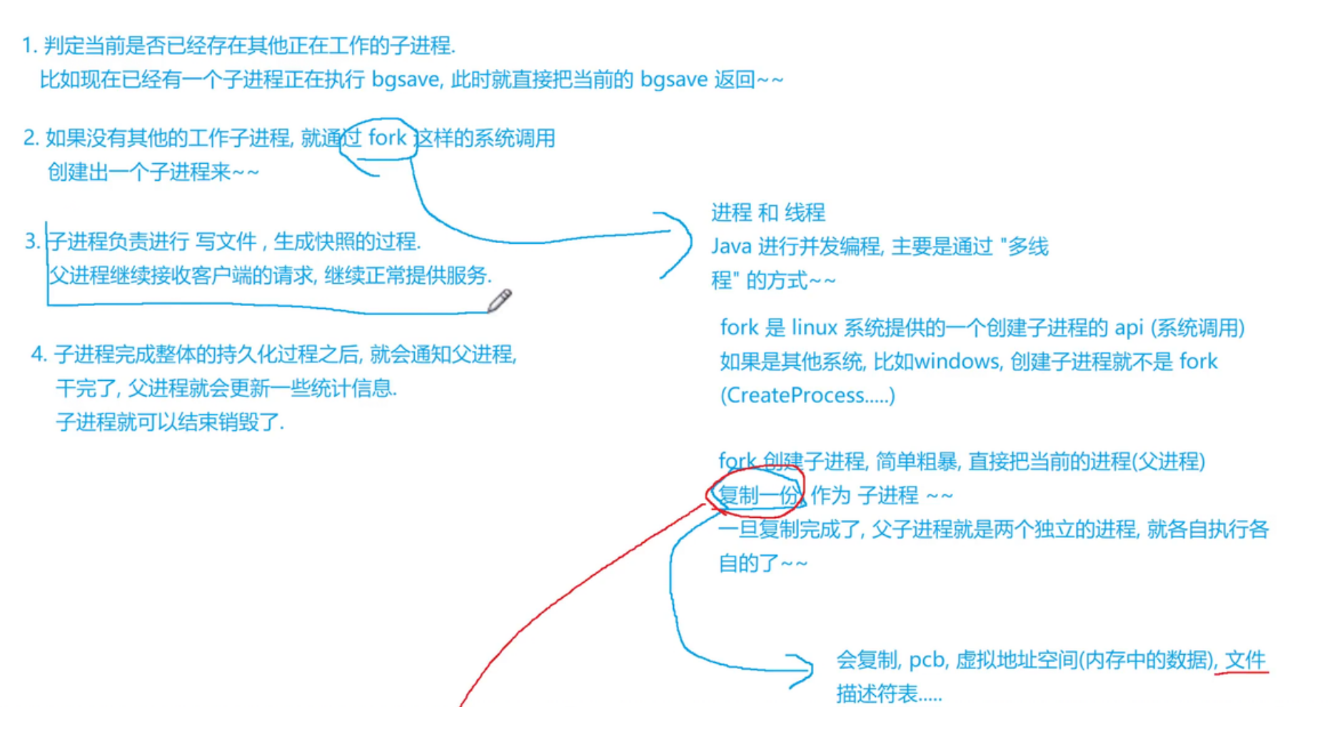
bgsave 执行快照操作不会影响Redis服务器处理其他客户端的请求和命令 此处Redis是使用多进程的方式来完成的并发编程
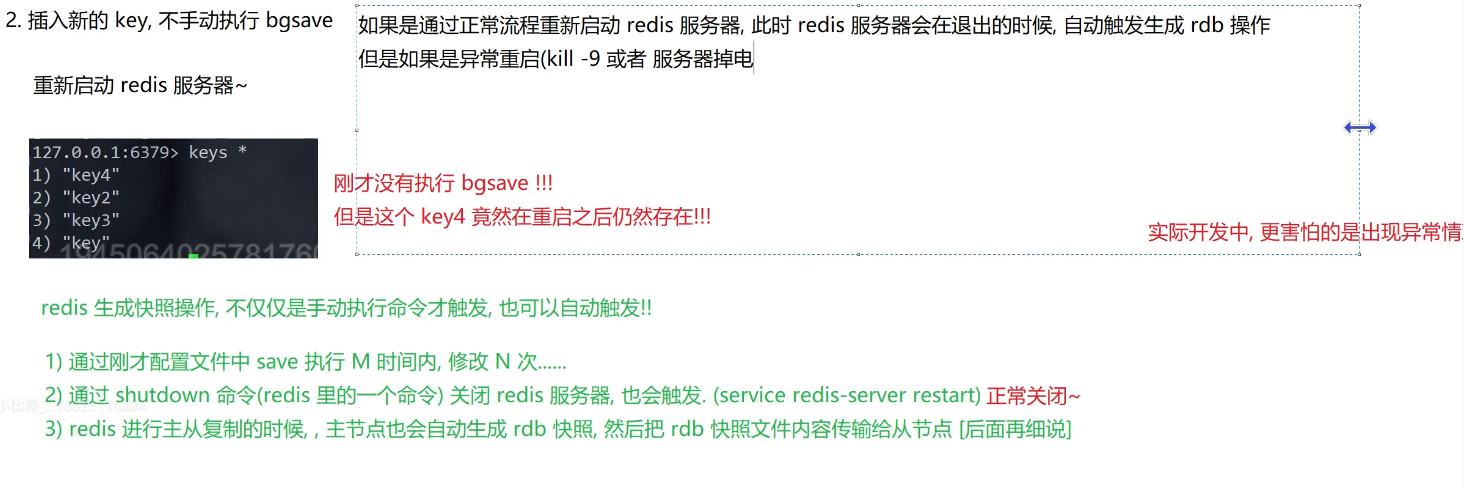
2.自动触发
在Redis配置文件中,设置一下,让Redis 每隔多长时间/每产生多少次修改 就触发
下面是在redis.conf文件中,自动触发的条件 可修改 但在我们修改中我们要注意每一次生成快照文件呢都会消耗成本 ,不能生成的太过频繁
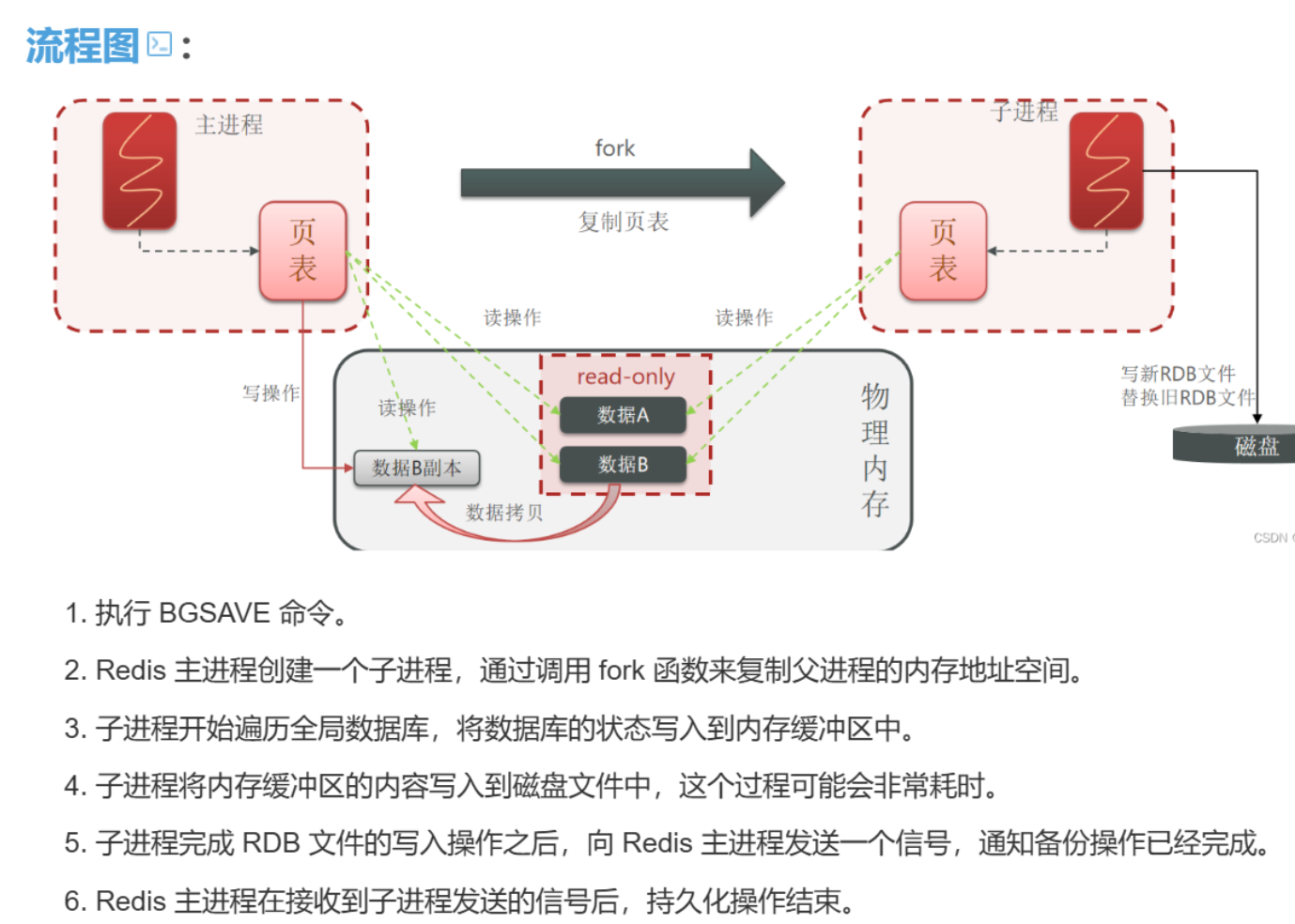
Redis RDB bgsave的执行流程

RDB的镜像文件
RDB 即快照模式,它是 Redis 默认的数据持久化方式,它会将数据库的快照保存在 dump.rdb 这个二进制文件中。
RDB的实际效果
如果使用save的话 就不会有子进程和文件替换的过程了,而是直接在文件中写入数据

redis-check-rdb是dump.rdb文件的检测工具 可检测文件问题

RDB的优缺点:
优点: 文件小,恢复快:二进制+压缩,体积比AOF小;加载时直接反序列化,比AOF重放操作日志快得多(尤其大数据量时)。 对主线程友好:通过BGSAVE子进程生成,主线程几乎无感知(仅fork()瞬间有微小开销)。 适合备份:二进制文件方便传输,常用于异地容灾或定期备份(比如每天凌晨生成一次RDB文件)。 缺点: 数据可能丢失:快照是「某一时刻」的镜像,如果Redis在两次快照之间崩溃,最后一次快照后的数据就丢了(比如配置save 900 1,最多丢15分钟数据)。 内存峰值风险:写时复制虽好,但如果内存很大(比如几百GB),fork()瞬间会占用较多CPU;如果主线程频繁修改数据,子进程需要不断复制页,内存可能翻倍(不过现在服务器内存都比较大,这个问题相对可控)。 不适合实时持久化:相比AOF(最多丢1秒数据),RDB的数据安全性低,不适合对一致性要求极高的场景(比如银行交易)。
AOF
每当Redis重启时 就会根据AOF来恢复数据,此时就不会根据RDB的文件 ,以AOF文件为准
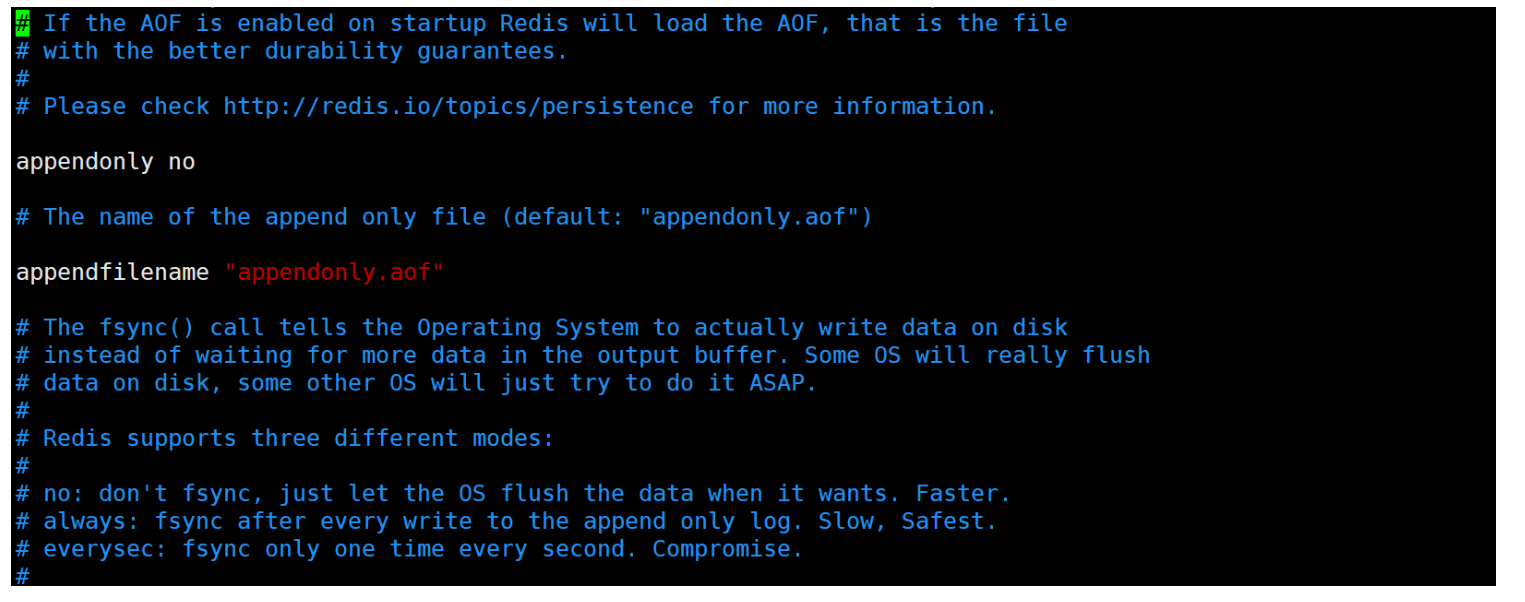
默认情况AOF是关闭状态 若使用需要再配置文件中 redis.conf 将其从no改为yes 启动AOF
AOF边写内存编写硬盘的机制会导致速率的降低吗?
答案是不 虽然AOF边写内存边写硬盘 ,但它在收到内存数据的变动时,会将数据积攒到内存缓冲区中等到达到一定数量时,再统一写到硬盘中,所以并不会影响Redis的性能,如果数据在缓冲区时,进程挂了 那数据则会丢失,此时就要我们去做出一些取舍。
缓冲区的刷新策略
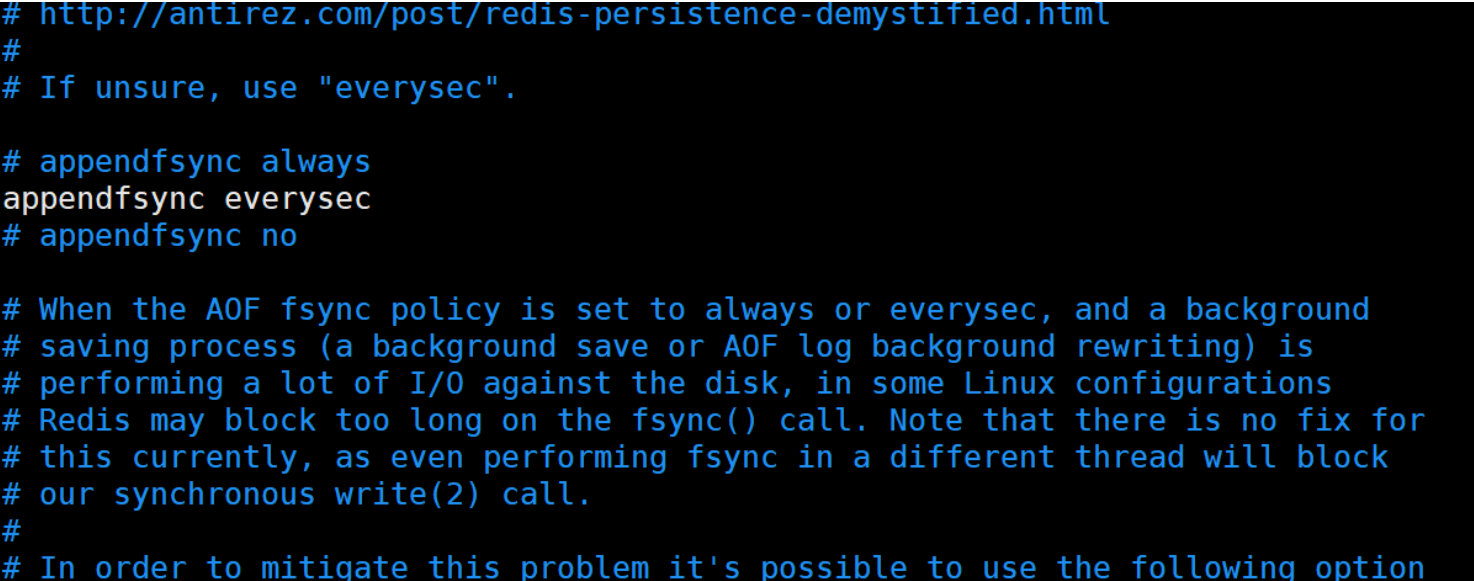
appendfsync 的三种取值代表三种策略
always 命令写入aof_buf 调佣fsnc同步,完成后返回 || 频率最高的,数据可靠性最高,性能最低
everysec 命令写入aof_buf后只执行write操作,不进行fsnc,每秒由同步线程进行fsnc ||频率低一些,数据可靠性会降低,性能会高
no命令写入aof_buf后只执行write操作,有os控制fsnc频率 ||频率最低 交由服务器自行设定 数据可靠性最低 但性能是最高的
AOF重写机制
AOF文件会记录Redis 的操作过程 但实际上在redis重新启动时只关注最终结果
因此redis就存在一个机制来剔除掉其中的冗余
AOP重写
1.手动触发bgrewriteaof 命令
2.自动触发 auto-aof-rewrite-min-size:表示触发重写时AOF的最小文件大小,默认是64MB
auto-aof-rewrite-percentage:代表当前AOF占用大小相较于上次重写时增加的比例
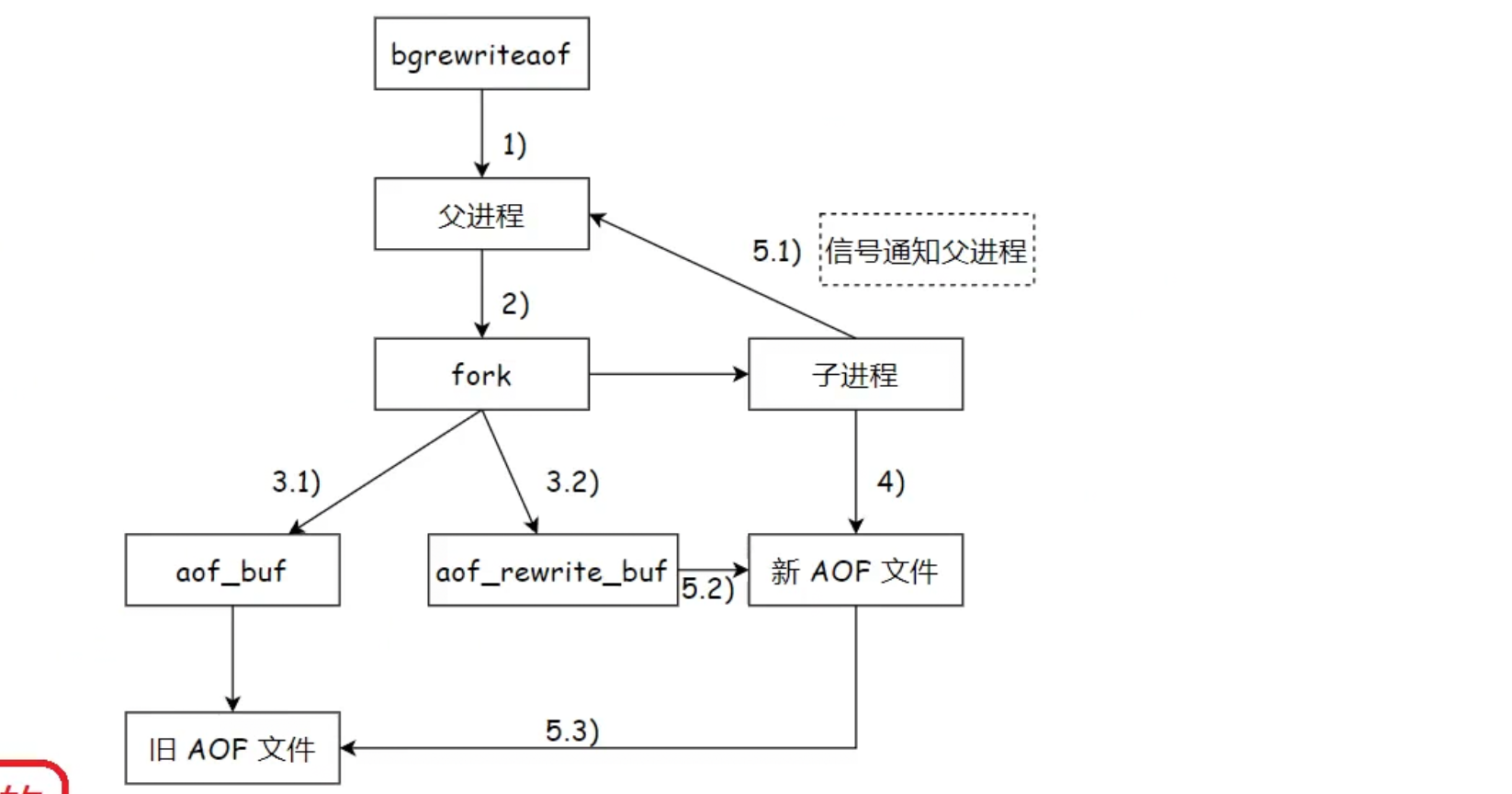
在AOF重写的流程 也是创建fork 父进程仍进行请求的接收 子进程来进行AOF文件的重写
但需注意的是AOF 并不注重过程 而是只关心最终内存形态 所以只会针对内存最终数据的形式以AOF文件格式去重写
子进程只需要将当前AOF文件的数据内容获取出来,然后以AOF文件的格式去重写到新的AOF文件中
**!!!**在子进程fork完后 父进程仍接收请求所以 父进程就会将修改的信息 传入缓冲区 然后再刷新到原有的AOF文件中
但子进程获取到的数据只是父进程fork之前的数据,因此会再设立一个缓冲区 特地放置fork之后的数据
等子进程将fork之前的数据重写完毕后就会重写aof-rewrite-buf缓冲区的内存数据
重写完毕后就可以用新的AOF文件替代就AOF文件了
!!!当处理fork之后的数据更新到aof-rewrite-buf缓存区时 还有必要进行就AOF的写入吗?
答案是有必要 当新的AOF文件写的过程中发生服务器断,那么内存数据就完蛋 了 此时呢 旧的AOF文件,就可发挥 恢复数据内容 防止数据丢失
如果Redis 在进行bgrewriteaof时 如果再次接收到bgrewriteaof指令 则不会执行新的命令
如果在进行RDB 的bgsave时 接收到bgrewriteaof指令,就会等快照结束后执行bgrewriteaof 指令
RDB与AOF 的区别呢 就是RDB不管fork之后的数据了而AOF则会对fork之后的数据缓存到aof-rewrite-buf中
但实时备份不一定比定期备份好 主要看使用场景
混合持久化
AOF本来是按照文本的方式写入文件的,但是文本的方式写文件,后续的加载的成本是比较高的
redis就引用了"混合持久化的方式"结合了RDB和AOF的特点
按照AOF的方式,每一个请求操作都记录入文件,再出发aof 重写之后,就会把当前内存的状态按照RDB的二进制格式写入新的AOF文件中,后续再进行的操作,任然是按照AOF文本的方式追加到文件后面

当redis同时存在AOF文件 和RDB文件时 以AOF文件数据为准,因为AOF数据更全