前文提到,在模型蒸馏领域,存在黑盒蒸馏和白盒蒸馏两种范式。
DistilQwen2.51这篇工作结合了这两种范式,并开源了代码2。
本文将参照其代码,从实践的角度,进一步理解这两种蒸馏方式是怎么做的。
原理回顾
DistilQwen2.5 的博客3展现了其模型的训练过程。
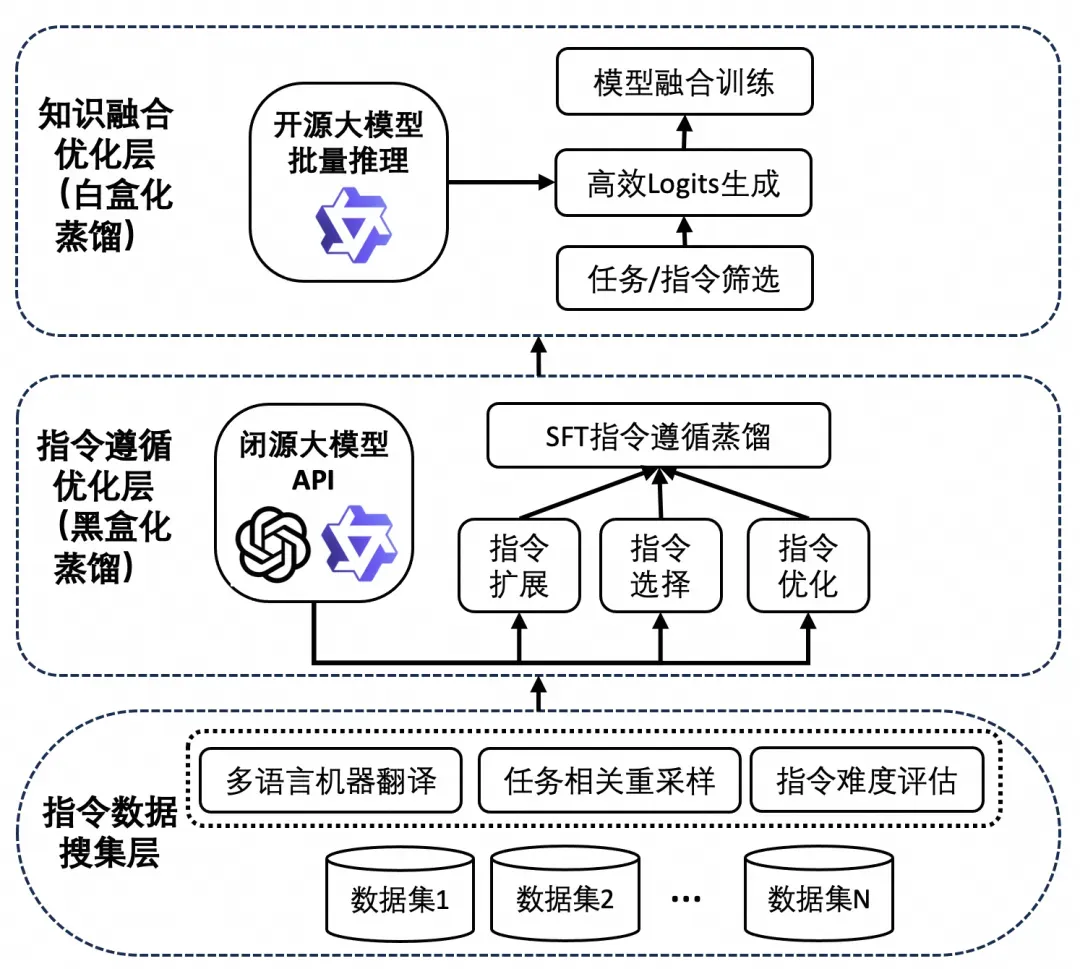
训练过程分三个步骤:
- 数据预处理:采集各种数据,进行数据清洗,难度划分等工作,在训练前完成
- 黑盒蒸馏:借助闭源大模型的API,对SFT指令数据进行处理
- 白盒蒸馏:师生模型联合训练,进行蒸馏
环境配置
下面克隆easydistill的代码,它是一个模型蒸馏的工具包,除了 DistilQwen2.5 之外,还包括其它模型的蒸馏算法。
git clone https://github.com/modelscope/easydistill.git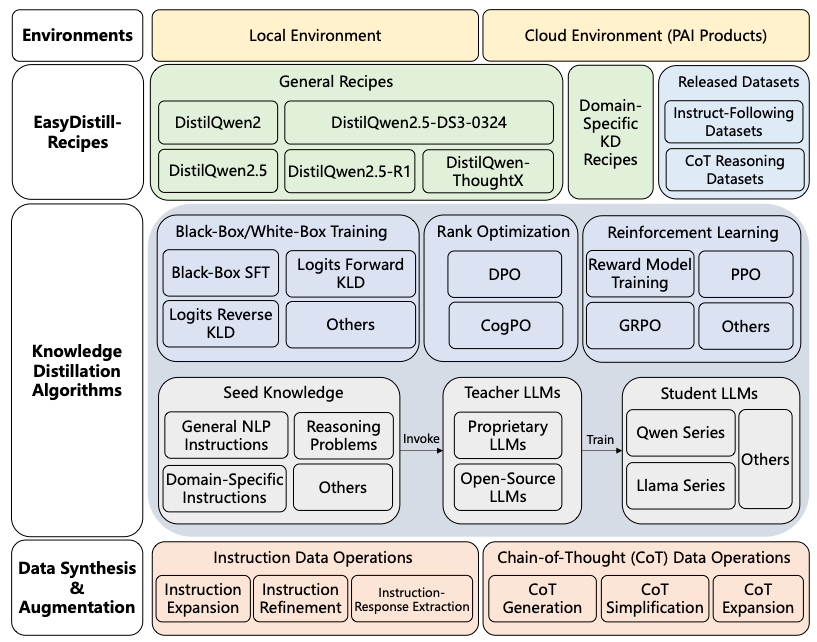
使用 uv 来配置基本依赖:
uv venv --python 3.11
source .venv/bin/activate
python setup.py install实现黑盒蒸馏
easydistill的用法教程几乎没有,连一些基础的用法说明都没有。
好在通过AI,我找了它的正确使用方式。
它的设计逻辑有点类似于mmdetection,做了很多配置文件,通过命令行去加载这些配置文件,以实现功能。
除命令行用法之外,更直观的方式是通过python直接去运行脚本文件。
下面尝试使用硅基流动4的api,进行黑盒蒸馏。
配置模型需要修改 configs/kd_black_box_api.json 这个文件,需要填写如下图所示的url和api_key。
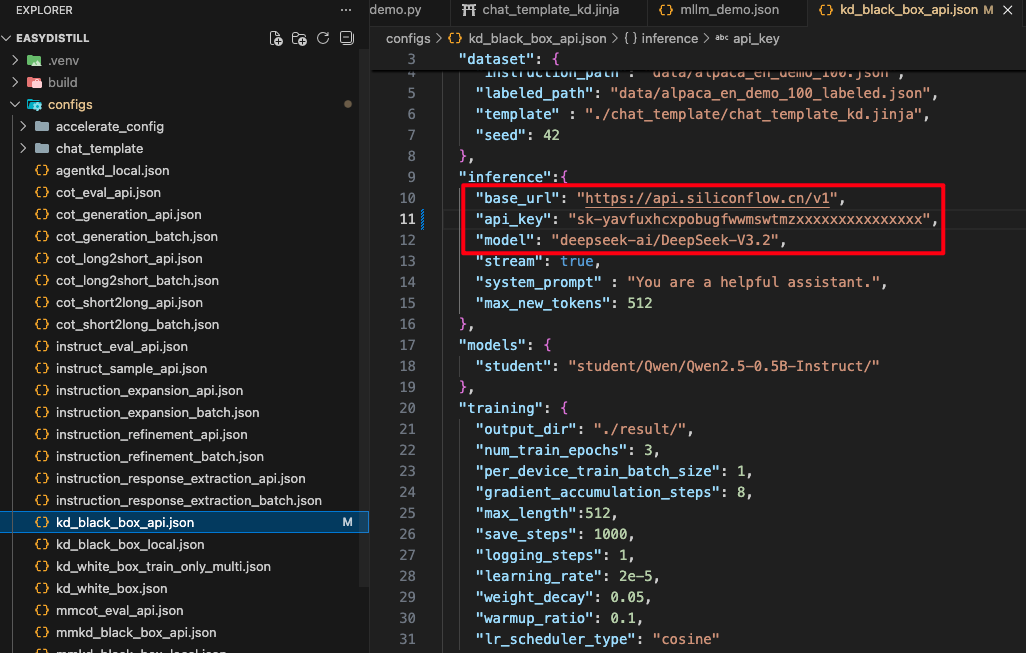
它默认没有 model 的参数选项,如果直接配置,它会调用api平台的第一个模型,在硅基流动中,第一个默认模型是Pro版本的GLM-4.7,它不能用赠金,只能用余额。
如果不选择模型,会直接将钱包烧成负数。
我fork了该仓库,适配了一下硅基流动平台,增加了模型配置选项,如果有同类使用方式,可参考我的代码实现5。
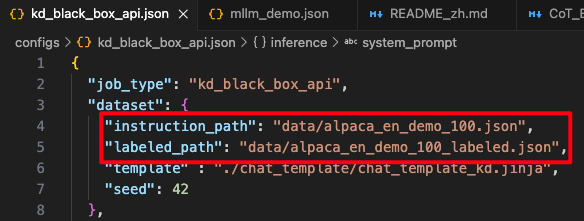
蒸馏的数据集同样在该文件中进行配置:
- instruction_path:输入的数据集
- labeled_path:输出的数据集
数据集必须是json格式,我这里从alpaca_en_demo这个数据集(总共有1k条数据)中,随机挑选了100条数据。
准备好后,运行以下代码,开始蒸馏。
python -m easydistill.kd.infer --config configs/kd_black_box_api.json蒸馏完成后,会得到labeled_path配置的文件。
黑盒蒸馏过程解析
实质上,黑盒蒸馏就是借助大模型,对数据集进行逐条优化。
在代码中,默认的系统提示词是You are a helpful assistant.,这个提示词很泛用,也可以根据具体任务去做修改。

优化的效果如何呢,下面看几个例子。
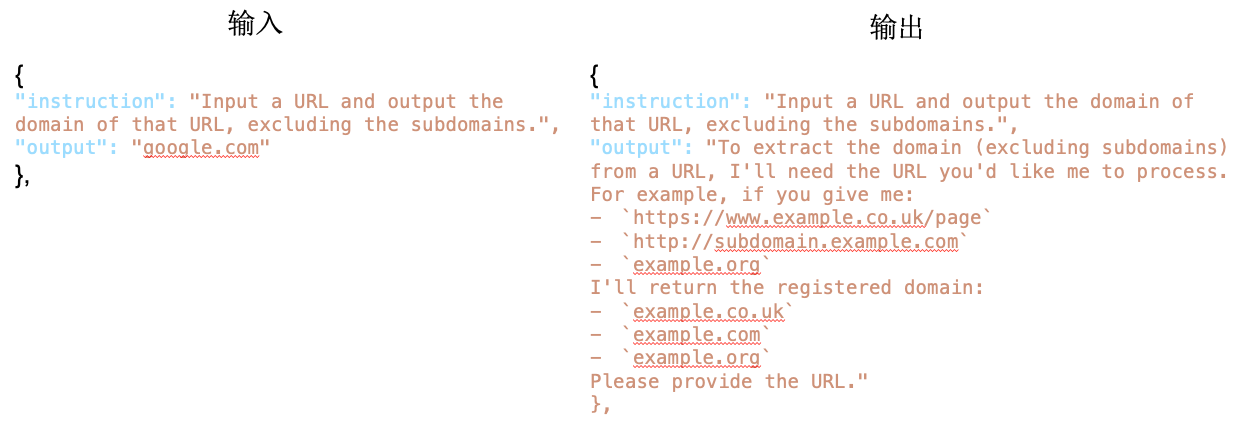
第一个例子:指令要求输入一个url,然后输出它的主域名。
原始的数据集答案(output)是"google.com",显然这是个偏差,答案不够泛化。
输入到大模型之后(这里需要注意,模型只看见系统提示词和指令,看不到原始答案),结果变成了右边非常具有泛化性的输出。
第二个例子:要求模型想象在罗马旅行,会看见的内容,类似于写故事。
原始的答案很简短,优化后的答案变得很长,下图中没完成放下,只进行了截取。

但是,有些内容优化后之后,未必会更好。
第三个例子:让模型直接写一段话的反义词,但优化后的模型扯了一堆废话,还不如原本的答案简洁。

白盒蒸馏过程解析
在DistilQwen2.5这个模型中,白盒蒸馏是使用教师模型的logits概率分布作为软标签,然后通过KL散度损失让学生学习教师的概率分布。
使用该方法进行白盒蒸馏有个前提:教师模型和学生模型的分词器(tokenizer)要对齐,最简单的方式就是用同一个分词器。
就像文章中提到的用Qwen3-Max去蒸馏Qwen-0.5B,都是Qwen系列,适配同一个分词器。
代码中,有两种方式可以进行白盒蒸馏:
- 异步蒸馏:在算力资源有限的情况下,可以预先通过 kd/infer.py 去计算教师模型的logits概率分布,后面训小模型时,直接加载这个预先计算好的数据。
- 同步蒸馏:直接运行 kd/train.py,同时加载大小两个模型,边计算边使用。
小模型的损失计算由两部分组成:
- 交叉熵损失:小模型自身输出的损失
- 蒸馏损失:用KL散度来进行衡量
Ltotal=(1−λ)LLM + λLKD\mathcal { L } _ { \mathrm { t o t a l } } = \left( 1 - \lambda \right) \mathcal { L } _ { \mathrm { L M } } \ + \ \lambda \mathcal { L } _ { \mathrm { K D } }Ltotal=(1−λ)LLM + λLKD
式中,λ\lambdaλ为平衡系数,默认为0.5。
在代码中,对于KL散度损失的计算有两种实现方式。
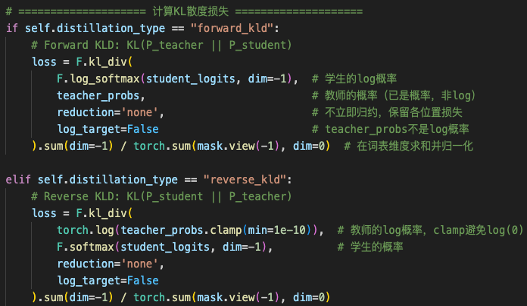
前向KLD(Forward KLD)指的是:教师觉得"有可能"的词,学生不给概率,就会被更多惩罚。
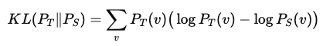
例如:
输出Token = {A, B, C}
教师输出概率={0.6, 0.3, 0.1}
学生输出概率={0.9, 0.1, 0.0}
KL损失因选项C(教师认为有可能,而学生认为不可能)而增加。
反向KLD(Reverse KLD)指的是:学生"自己打算说"的词,如果教师觉得不可能,就会被更多惩罚。
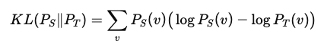
例如:
输出Token = {A, B, C}
教师输出概率={0.6, 0.3, 0.1}
学生输出概率={0.4, 0.1, 0.5}
KL损失因选项C(学生认为概率大,教师认为概率小)而增加。
默认采用的是前向KLD。
局限性讨论
看完之后,实际上会发现一个问题,在白盒蒸馏的过程中,DistilQwen2.5直接用KL散度去进行评估。
而KL散度的一个前提是:大小模型的输出长度要一样才能计算。
如果长度不一样,代码中会以短的作为基准,对长的进行截断。
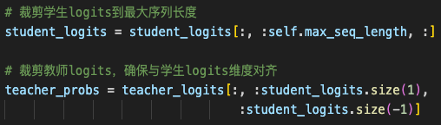
举个例子,任务是写一个故事:
prompt =「Write a story」
教师模型:<bos> Once upon a time ... (500 tokens) ... The End <eos>
学生模型:<bos> Once upon a time ... (120 tokens) <eos>教师模型输出了500个tokens,学生模型输出了120个tokens。
此时,KL散度仅计算前120 tokens,教师模型的121-500 token,不参与计算。
问了一下AI,这个点确实有一些研究思路:
- 方法 1:Teacher-forcing 蒸馏
关键思想:不是让学生自由生成,而是"强行走教师的 token 轨迹" - 方法 2:EOS / length-aware 蒸馏
显式引入:EOS token 的 KL,让学生学会:"在这个位置,老师还没停,我也不该停" - 方法 3:Sequence-level 蒸馏
用 teacher 输出作为 pseudo-label,直接对完整序列做 CE - 方法 4:多轨迹采样 + 蒸馏
教师生成多个不同长度版本,覆盖多种停止模式,让学生学到"长度分布",而不是单一长度
参考
1 https://arxiv.org/abs/2504.15027
2 https://github.com/modelscope/easydistill
3 https://developer.aliyun.com/article/1653842