文章目录
- [从一个教学管理系统,理解 Spring Boot 三层架构的真实分工](#从一个教学管理系统,理解 Spring Boot 三层架构的真实分工)
-
- [0. 写在前面:为什么我要写这篇总结](#0. 写在前面:为什么我要写这篇总结)
- [1. 项目整体介绍](#1. 项目整体介绍)
-
- [1.1 项目是什么](#1.1 项目是什么)
- [1.2 功能模块一览](#1.2 功能模块一览)
- [1.3 技术选型说明](#1.3 技术选型说明)
- [2. 项目结构设计:为什么要这样分包](#2. 项目结构设计:为什么要这样分包)
-
- [2.1 整体包结构总览](#2.1 整体包结构总览)
- [2.2 Controller 层:只做一件事------接收请求、给出响应](#2.2 Controller 层:只做一件事——接收请求、给出响应)
-
- [为什么 Controller 不写业务](#为什么 Controller 不写业务)
- [为什么 Controller 不直接操作 Mapper](#为什么 Controller 不直接操作 Mapper)
- 示例代码:
- [2.3 Service 层:业务逻辑的"唯一入口"](#2.3 Service 层:业务逻辑的“唯一入口”)
-
- [为什么要有接口 + 实现类](#为什么要有接口 + 实现类)
- 示例代码:
- [2.4 Mapper 层:只关心数据,不关心业务](#2.4 Mapper 层:只关心数据,不关心业务)
- [3. 参数对象与返回对象的设计](#3. 参数对象与返回对象的设计)
-
- [3.1 为什么不用一堆 `@RequestParam`](#3.1 为什么不用一堆
@RequestParam) -
- [`QueryParam` 的价值](#
QueryParam的价值)
- [`QueryParam` 的价值](#
- [3.2 统一返回 `Result` 的意义](#3.2 统一返回
Result的意义) - 3.3总结
- [3.1 为什么不用一堆 `@RequestParam`](#3.1 为什么不用一堆
- [4. 分页、条件查询是如何贯穿三层的](#4. 分页、条件查询是如何贯穿三层的)
-
- [4.1. **Controller 层**:接收分页请求并传递参数](#4.1. Controller 层:接收分页请求并传递参数)
- [4.2. **Service 层**:调用 `PageHelper` 设置分页参数并查询](#4.2. Service 层:调用
PageHelper设置分页参数并查询) - [4.3. **Mapper 层**:执行查询操作](#4.3. Mapper 层:执行查询操作)
- 4.4分页查询流程总结
- 4.5流程图式文字
- [5. 数据统计接口设计](#5. 数据统计接口设计)
-
- [5.1 员工性别统计](#5.1 员工性别统计)
-
- [5.1.1 基本信息](#5.1.1 基本信息)
- [5.1.2 请求参数](#5.1.2 请求参数)
- [5.1.3 响应数据](#5.1.3 响应数据)
- [5.2 数据聚合与查询设计](#5.2 数据聚合与查询设计)
-
- [5.2.1 Mapper 层](#5.2.1 Mapper 层)
- [5.2.2 Service 层](#5.2.2 Service 层)
- [5.2.3 Controller 层](#5.2.3 Controller 层)
- [5.3 前端与接口数据联动](#5.3 前端与接口数据联动)
-
- [前端 `echarts` 饼状图配置:](#前端
echarts饼状图配置:)
- [前端 `echarts` 饼状图配置:](#前端
- [5.4 总结](#5.4 总结)
- [6. 文件上传 + OSS](#6. 文件上传 + OSS)
-
- 6.1为什么不存本地
- [6.2OSS 的基本流程](#6.2OSS 的基本流程)
- 6.3关键源码解析
-
- [6.3.1 Controller 层:处理文件上传请求](#6.3.1 Controller 层:处理文件上传请求)
- [6.3.2 Service 层:操作 OSS 存储](#6.3.2 Service 层:操作 OSS 存储)
- [6.3.3 配置类:阿里云 OSS 配置](#6.3.3 配置类:阿里云 OSS 配置)
- [6.3.4 配置文件示例 (`application.properties`)](#6.3.4 配置文件示例 (
application.properties))
- 6.4处理流程
- [6.5为什么使用 OSS 存储而不是本地存储](#6.5为什么使用 OSS 存储而不是本地存储)
- 6.6总结
- [7. 全局异常与自定义异常:为什么不 try-catch 到处写](#7. 全局异常与自定义异常:为什么不 try-catch 到处写)
-
- 7.1关键部分解析
-
- [7.1.1. **BusinessException**:自定义异常类](#7.1.1. BusinessException:自定义异常类)
- [7.1.2. **GlobalExceptionHandler**:全局异常处理](#7.1.2. GlobalExceptionHandler:全局异常处理)
- [7.2 **统一错误返回格式**](#7.2 统一错误返回格式)
- [7.3 **为什么不 `try-catch` 到处写**](#7.3 为什么不
try-catch到处写) - [7.4. **总结**](#7.4. 总结)
- [8. 写完这个项目,我对"三层架构"的真实理解](#8. 写完这个项目,我对“三层架构”的真实理解)
从一个教学管理系统,理解 Spring Boot 三层架构的真实分工
0. 写在前面:为什么我要写这篇总结
在学习 Spring Boot 的过程中,"三层架构"几乎是绕不开的一个概念。
Controller、Service、Mapper 这些名词并不陌生,注解也能照着教程写出来,但真正动手做项目时,很多人都会遇到类似的问题:
- Controller 里到底该不该写业务逻辑?
- Service 存在的意义是什么?如果只是转调 Mapper,有必要吗?
- Mapper 能不能直接在 Controller 里用?
- 参数、分页、异常、返回结果应该放在哪一层?
我在学习阶段也有同样的困惑。看教程时感觉"懂了",但一旦开始自己写接口,很容易变成一种状态:
代码能跑,但分层是"糊出来的",而不是"想清楚的"。
正是基于这样的背景,我完成了这个教学管理系统项目。
这个项目是什么?
这是一个练手用的教学管理系统后端项目 ,主要用于接口层面的练习,不包含复杂业务,也不强调前端实现。项目基于黑马视频教程 ,但并非完全照抄,而是在课程框架的基础上,结合自己的理解补全和整理,目的是把一个相对完整的三层结构真正跑通。
项目主要包含以下模块:
- 班级管理
- 学生管理
- 员工管理
- 部门管理
- 基础数据统计(报表接口)
- 文件上传(头像,基于阿里云 OSS)
涵盖了后端项目中最常见的一组能力组合:
CRUD + 分页 + 条件查询 + 统一返回 + 全局异常 + 简单业务统计。
为什么要写这篇总结?
写这篇文章的目的,不是展示功能有多复杂,也不是总结某个框架的全部特性,而是回答一个更基础、也更关键的问题:
在一个真实存在的 Spring Boot 项目中,
Controller、Service、Mapper 三层到底是如何协作的?
我希望通过这个项目,把"三层架构"从一句抽象原则,拆解成可以被感知、被模仿、被复用的工程实践,包括:
- 每一层应该做什么
- 每一层不应该做什么
- 常见功能(分页、条件查询、统计)是如何自然地贯穿三层的
- 为什么这样分层,代码会更清晰、更容易维护
阅读建议
这不是一篇零基础教程,也不会从环境搭建开始讲起。文中默认读者已经具备以下基础:
- 了解 Spring Boot 的基本使用方式
- 对 Controller / Service / Mapper 有基本概念
- 能读懂简单的 Java 代码和 MyBatis SQL
文章会结合具体代码结构与设计思路展开,重点放在"为什么要这样设计",而不仅仅是"怎么写"。
1. 项目整体介绍
1.1 项目是什么
本项目是Tlias智能学习辅助系统 ,一个教学管理系统 的后端接口部分。项目的目标是通过学习和实践,熟悉和掌握Spring Boot 的常见应用场景,特别是三层架构(Controller / Service / Mapper)的分层设计,以及常见的后端开发模式。
项目只做后端接口,不涉及前端页面实现,主要面向管理端 用户。系统将为管理员提供班级管理、学生管理、员工管理和部门管理等功能。
1.2 功能模块一览
该项目的主要功能模块如下:
- 班级管理 :
提供班级的增、删、改、查功能,支持分页显示和条件查询功能,方便管理员对班级信息进行管理。 - 学生管理 :
提供学生的基本信息管理,包括学生的增删改查、分页显示,以及按条件查询(如姓名、学号等)功能。 - 员工管理 :
管理系统中的员工信息,包括岗位、性别等,提供类似班级和学生的增删改查功能,并支持条件查询和分页显示。 - 部门管理 :
管理各类部门的信息,为了优化组织结构和提高管理效率,管理员可以查看、修改、删除和添加部门。 - 数据统计 :
提供员工的岗位和性别统计、学生的班级人数和学历统计等报表功能,支持将数据以图表形式展示,帮助管理人员快速了解数据分布情况。 - 文件上传(头像,OSS) :
提供用户头像上传功能,采用阿里云的OSS存储服务来存储头像图片。这样避免了服务器压力和本地存储空间问题,提升了系统的扩展性和稳定性。
1.3 技术选型说明
++根据教学原视频++,选用了以下技术栈:
- Spring Boot :
作为整个项目的基础框架,用于简化项目的开发与配置,提供了快速构建和部署的能力。 - MyBatis + MySQL :
使用 MyBatis 作为 ORM 框架,简化了数据库操作,同时选择 MySQL 作为数据库引擎,存储系统中的数据。 - PageHelper :
用于分页查询,极大简化了分页逻辑的实现,使得分页功能的开发更加高效和便捷。 - Lombok :
用于简化 Java 类中的 getter、setter 等方法的编写,减少了冗余代码,提升了开发效率。 - 统一返回 Result :
采用统一的返回结构,所有接口的响应数据都使用同一个格式,使前端开发者与后端接口之间的交互更加清晰一致。 - 全局异常处理 :
通过@ControllerAdvice统一处理系统中的异常,保证每个接口的错误响应结构一致,提高系统的可维护性。 - Apifox 调试接口 :
使用 Apifox 工具进行接口调试,帮助快速发现问题,减少了开发与前端交互中的摩擦,提升了接口文档的易读性与一致性。
2. 项目结构设计:为什么要这样分包
2.1 整体包结构总览
以下是项目的目录结构,基于三层架构,每一层的职责明确,确保了系统的模块化和可维护性。
2.2 Controller 层:只做一件事------接收请求、给出响应
Controller 层的职责是处理前端请求和返回结果。在此层,我们只做接收请求和返回响应 的工作,不涉及任何业务逻辑,业务逻辑应该交给 Service 层。
为什么 Controller 不写业务
Controller 的职责仅限于:
- 接受用户请求
- 调用 Service 层的业务方法
- 将结果返回给前端
Controller 不应写任何业务逻辑,避免耦合和代码臃肿。
为什么 Controller 不直接操作 Mapper
直接操作 Mapper 会导致业务逻辑混杂,违反了单一职责原则。Controller 应该与数据库操作解耦,所有数据操作通过 Service 层来实现,这样业务逻辑更清晰,也更容易维护。
示例代码:
java
@Slf4j
@RestController
@RequestMapping("/emps")
public class EmpController {
@Autowired
private EmpService empService;
/**
* 分页查询员工信息
*/
@GetMapping
public Result page(EmpQueryParam empQueryParam) {
log.info("分页查询:{}", empQueryParam);
PageResult<Emp> pageResult = empService.page(empQueryParam);
return Result.success(pageResult);
}
/**
* 保存员工信息
*/
@PostMapping
public Result save(@RequestBody Emp emp) {
log.info("保存员工:{}", emp);
empService.save(emp);
return Result.success();
}
/**
* 批量删除员工信息
*/
@DeleteMapping
public Result delete(@RequestParam List<Integer> ids) {
log.info("批量删除员工:{}", ids);
empService.delete(ids);
return Result.success();
}
/**
* 获取单个员工信息
*/
@GetMapping("/{id}")
public Result getInfo(@PathVariable Integer id) {
log.info("查询员工信息:{}", id);
Emp emp = empService.getInfo(id);
return Result.success(emp);
}
/**
* 更新员工信息
*/
@PutMapping
public Result update(@RequestBody Emp emp) {
log.info("修改员工信息:{}", emp);
empService.update(emp);
return Result.success();
}
/**
* 查询所有员工
*/
@GetMapping("/list")
public Result findAll() {
log.info("查询所有员工信息:");
List<Emp> list = empService.findAll();
return Result.success(list);
}
}2.3 Service 层:业务逻辑的"唯一入口"
Service 层负责核心业务逻辑的处理,是整个应用的业务逻辑入口。所有复杂的业务判断、数据校验、事务管理等都应由 Service 层来完成。
为什么要有接口 + 实现类
通过定义接口与实现类的分离,系统的可扩展性更强,且易于进行单元测试和 Mock 测试。
示例代码:
java
@Service
public class EmpServiceImpl implements EmpService {
@Autowired
private EmpMapper empMapper;
@Autowired
private EmpExprMapper empExprMapper;
@Autowired
private EmpLogService empLogService;
@Override
public PageResult<Emp> page(EmpQueryParam empQueryParam) {
// 设置分页参数
PageHelper.startPage(empQueryParam.getPage(), empQueryParam.getPageSize());
// 执行查询
List<Emp> empList = empMapper.list(empQueryParam);
// 封装结果并返回
Page<Emp> page = (Page<Emp>) empList;
return new PageResult<>(page.getTotal(), page.getResult());
}
@Transactional(rollbackFor = Exception.class)
@Override
public void save(Emp emp) {
// 保存员工基本信息
emp.setCreateTime(LocalDateTime.now());
emp.setUpdateTime(LocalDateTime.now());
empMapper.insert(emp);
// 保存员工工作经历信息
List<EmpExpr> exprList = emp.getExprList();
if (!CollectionUtils.isEmpty(exprList)) {
exprList.forEach(empExpr -> empExpr.setEmpId(emp.getId()));
empExprMapper.insertBatch(exprList);
}
// 记录操作日志
EmpLog empLog = new EmpLog(null, LocalDateTime.now(), "新增员工" + emp);
empLogService.insertLog(empLog);
}
@Transactional(rollbackFor = Exception.class)
@Override
public void delete(List<Integer> ids) {
// 删除员工基本信息
empMapper.deleteByIds(ids);
// 删除员工工作经历信息
empExprMapper.deleteByEmpIds(ids);
}
@Override
public Emp getInfo(Integer id) {
return empMapper.getById(id);
}
@Override
public void update(Emp emp) {
emp.setUpdateTime(LocalDateTime.now());
empMapper.updateById(emp);
List<EmpExpr> exprList = emp.getExprList();
if (!CollectionUtils.isEmpty(exprList)) {
exprList.forEach(empExpr -> empExpr.setEmpId(emp.getId()));
empExprMapper.insertBatch(exprList);
}
}
@Override
public List<Emp> findAll() {
return empMapper.findAll();
}
}2.4 Mapper 层:只关心数据,不关心业务
Mapper 层是与数据库进行交互的层级,主要负责数据的持久化操作。Mapper 层不应该包含任何业务逻辑,它只是将 SQL 与 Java 对象进行映射。
示例代码:
java
@Mapper
public interface EmpMapper {
/**
* 查询员工列表
*/
List<Emp> list(EmpQueryParam empQueryParam);
}
xml
<mapper namespace="com.itheima.mapper.EmpMapper">
<select id="list" resultType="com.itheima.pojo.Emp">
SELECT e.*, d.name deptName FROM emp e
LEFT JOIN dept d ON e.dept_id = d.id
<where>
<if test="name != null and name != ''">
e.name LIKE CONCAT('%', #{name}, '%')
</if>
<if test="gender != null">
AND e.gender = #{gender}
</if>
<if test="begin != null and end != null">
AND e.entry_date BETWEEN #{begin} AND #{end}
</if>
</where>
ORDER BY e.update_time DESC
</select>
</mapper>这样,整个三层架构设计就完成了,确保了系统各层职责的明确分离,提高了可维护性和可扩展性。
3. 参数对象与返回对象的设计
3.1 为什么不用一堆 @RequestParam
在实际开发中,使用多个 @RequestParam 注解来处理请求参数可能导致 Controller 方法的签名变得冗长且难以维护。尤其在处理多个查询参数时,管理这些参数变得更加复杂,因此将请求参数封装成参数对象 (如 QueryParam)是一个更优的设计方案。
QueryParam 的价值
QueryParam 类的设计主要用于将多个查询参数封装成一个对象,它的价值体现在以下几个方面:
-
可读性
使用参数对象(如
EmpQueryParam、StudentQueryParam)能使方法签名变得简洁,避免了多个@RequestParam注解的冗长,使得代码更加清晰、易读。通过命名良好的参数对象,其他开发人员能够快速理解这些参数的作用,而无需逐一查看每个参数的定义。例如,以下
EmpQueryParam类通过集中管理分页和查询条件,能够更好地提升代码的可读性:
java
@Data
public class EmpQueryParam {
private Integer page = 1; // 页码
private Integer pageSize = 10; // 每页记录数
private String name; // 姓名
private Integer gender; // 性别
@DateTimeFormat(pattern = "yyyy-MM-dd")
private LocalDate begin; // 入职日期
@DateTimeFormat(pattern = "yyyy-MM-dd")
private LocalDate end; // 离职日期
}-
扩展性
随着需求的增加,查询参数可能会不断增加。如果每个新参数都使用
@RequestParam来传递,Controller 的方法签名会变得非常冗长,不利于扩展。而使用QueryParam,新增查询条件时,只需要在对象中添加新的字段,而不需要修改每个方法的签名,极大提升了系统的扩展性。 -
封装性
将请求参数封装为对象,使得查询条件能够被清晰地组织起来,并且可以方便地进行校验和默认值设置。例如,在
EmpQueryParam中可以为分页字段提供默认值,避免了在 Controller 中做额外的逻辑处理。
通过将分页、筛选条件、时间范围等查询条件封装到一个对象中,代码更加整洁,也减少了冗余的 @RequestParam 参数。
3.2 统一返回 Result 的意义
为了确保系统返回结果的一致性和简化前后端的协作,统一的返回格式变得至关重要。使用统一的返回类 Result 能够帮助我们规范接口的返回结构,提高代码的可读性和可维护性。
前后端协作
在前后端分离的开发模式中,前端与后端之间的接口数据格式需要保持一致。使用统一的返回格式 Result 能够确保无论何时调用接口,前端都能以相同的方式接收和处理响应数据。
Result 类不仅能提供标准的 状态码 、提示信息 和 返回数据,还能够支持动态返回数据类型(如分页结果、查询结果等)。这使得前端能够根据相同的格式进行数据解析和展示。
java
@Data
public class Result {
private Integer code; // 状态码:1 表示成功,0 表示失败
private String msg; // 错误信息或提示信息
private Object data; // 具体返回的数据
// 成功返回结果
public static Result success() {
Result result = new Result();
result.code = 1;
result.msg = "success";
return result;
}
// 成功返回数据
public static Result success(Object object) {
Result result = new Result();
result.data = object;
result.code = 1;
result.msg = "success";
return result;
}
// 错误返回结果
public static Result error(String msg) {
Result result = new Result();
result.msg = msg;
result.code = 0;
return result;
}
}通过统一的 Result 格式,前端和后端可以在相同的数据结构下进行数据交换,减少了前后端对数据格式的理解偏差。
错误处理一致性
系统中的错误处理需要统一。无论是数据库异常、业务逻辑异常,还是其他运行时异常,所有异常信息 都应该通过一个统一的返回格式发送给前端。通过 Result 类,错误信息都可以统一管理,保证前后端的一致性。
例如,如果系统发生错误,可以通过 Result.error 方法返回标准的错误信息,便于前端统一处理:
java
public class GlobalExceptionHandler {
@ExceptionHandler
public Result handleException(Exception e){
log.error("服务器发生异常:{}", e.getMessage());
return Result.error("服务器异常,请联系管理员~");
}
}这样,所有异常的返回格式都是统一的,不管是用户输入错误、系统错误,还是数据操作错误,都会返回一个结构一致的 Result。
为什么配合全局异常使用
全局异常处理 与统一返回 Result 的结合使用,能够确保系统在异常情况下仍然保持一致的返回格式。通过在 @RestControllerAdvice 中统一处理异常,所有异常的处理逻辑都集中在一个地方,减少了代码的重复性,同时也提高了系统的可维护性。
例如,当某个请求因参数错误而失败时,系统会通过全局异常处理器返回一个标准化的错误信息,前端可以基于统一的错误结构展示友好的提示信息:
java
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler
public Result handleBusinessException(BusinessException e){
log.error("业务异常:{}", e.getMessage());
return Result.error(e.getMessage());
}
@ExceptionHandler
public Result handleDuplicateKeyException(DuplicateKeyException e){
log.error("重复键异常:{}", e.getMessage());
return Result.error("数据库中已存在该记录");
}
}这样,所有错误响应都会遵循相同的结构,前端可以根据统一的状态码和错误消息格式进行统一处理,极大减少了前后端沟通的成本。
3.3总结
通过使用 QueryParam 类封装请求参数,和 Result 类统一返回接口数据,我们能够:
- 提升 代码的可读性 ,避免了大量
@RequestParam的使用。 - 提高系统的 扩展性 ,在需要增加查询条件时,只需修改
QueryParam类而无需更改每个方法签名。 - 确保 前后端协作 的一致性,统一的返回格式让前端能够高效、准确地处理响应数据。
- 保证 错误处理一致性 ,所有异常通过统一的
Result格式返回,增强系统的可维护性。
这种设计方法有效地提升了系统的可扩展性、可维护性,并且为前后端协作提供了更好的支持,是一个非常常用的开发模式。
4. 分页、条件查询是如何贯穿三层的
这是将三层架构有效衔接起来的关键。分页和条件查询从 Controller 层 到 Service 层 再到 Mapper 层,每一层的职责明确,通过合理分工保证了代码的清晰和可维护性。
4.1. Controller 层:接收分页请求并传递参数
在 Controller 层 ,我们接收前端传递的分页参数和查询条件。这些参数通过封装成 QueryParam 对象传递给 Service 层 ,并通过调用 Service 层 的分页查询方法来处理查询逻辑。
java
@GetMapping
public Result page(EmpQueryParam empQueryParam) {
log.info("分页查询:{}", empQueryParam);
// 调用 Service 层获取分页查询结果
PageResult<Emp> pageResult = empService.page(empQueryParam);
return Result.success(pageResult); // 返回分页结果
}在这个方法中,EmpQueryParam 封装了前端传来的查询条件和分页信息,然后传递给 Service 层。
4.2. Service 层 :调用 PageHelper 设置分页参数并查询
Service 层 负责执行业务逻辑,包括调用分页插件 PageHelper 设置分页参数,并调用 Mapper 层 进行数据库查询。PageHelper 会在查询时自动应用分页逻辑(如 LIMIT),并返回分页查询结果。
java
@Override
public PageResult<Emp> page(EmpQueryParam empQueryParam) {
// 1. 设置分页参数,PageHelper 会根据传入的分页参数自动设置分页逻辑
PageHelper.startPage(empQueryParam.getPage(), empQueryParam.getPageSize());
// 2. 调用 Mapper 层的查询方法获取分页结果
List<Emp> empList = empMapper.list(empQueryParam);
// 3. 将分页结果封装成 PageResult 返回
Page<Emp> page = (Page<Emp>) empList;
return new PageResult<>(page.getTotal(), page.getResult());
}在 Service 层 ,PageHelper.startPage(empQueryParam.getPage(), empQueryParam.getPageSize()) 设置了分页参数,然后 empMapper.list(empQueryParam) 会执行查询,获取分页后的数据。
4.3. Mapper 层:执行查询操作
Mapper 层 的任务仅仅是执行 SQL 查询,它不关心分页逻辑。分页逻辑由 PageHelper 在 Service 层 控制。Mapper 层负责根据传入的查询条件返回符合要求的数据。
xml
<select id="list" resultType="com.itheima.pojo.Emp">
SELECT e.*, d.name deptName
FROM emp e
LEFT JOIN dept d ON e.dept_id = d.id
<where>
<if test="name != null and name != ''">
e.name LIKE CONCAT('%', #{name}, '%')
</if>
<if test="gender != null">
AND e.gender = #{gender}
</if>
<if test="begin != null and end != null">
AND e.entry_date BETWEEN #{begin} AND #{end}
</if>
</where>
ORDER BY e.update_time DESC
</select>这个 list 查询方法通过 MyBatis 执行条件查询,查询条件来自 EmpQueryParam 对象。PageHelper 会在查询时动态插入分页参数,Mapper 层只负责执行 SQL 查询并返回数据。
4.4分页查询流程总结
通过三层架构的合理分工,分页查询的整个流程是清晰的:
- Controller 层 :接收前端的分页参数和查询条件(如:
page=1&pageSize=10&name=张三),并封装成EmpQueryParam对象传递给 Service 层。 - Service 层 :调用
PageHelper.startPage()设置分页参数,然后调用 Mapper 层 的查询方法获取分页结果,最终将总记录数和当前页数据封装成PageResult返回给 Controller。 - Mapper 层 :根据
EmpQueryParam中的条件,执行数据库查询,返回分页后的结果。
4.5流程图式文字
为了更清晰地展示这个流程,下面是整个分页查询的流程描述:
- Controller 层 → 接收分页参数和查询条件 → 调用 Service 层 的
page()方法 - Service 层 → 使用
PageHelper.startPage()设置分页 → 调用 Mapper 层 的list()方法执行查询 - Mapper 层 → 执行 SQL 查询,返回分页结果
- Service 层 → 封装查询结果为
PageResult→ 返回给 Controller 层 - Controller 层 → 封装
PageResult为统一的Result返回给前端
5. 数据统计接口设计
报表统计接口是系统中一个非常重要的功能,它不同于传统的 CRUD 操作,主要用于对数据进行 聚合 和 分析 ,然后将分析结果以图表的形式展示给用户。具体到这个项目,前端使用了 echarts 来可视化数据。
在这一部分,我们将讨论如何设计 数据统计接口 ,并介绍如何从数据库中获取聚合数据,如何通过接口返回给前端,以及在前端使用的 echarts 渲染图表图片示例。
5.1 员工性别统计
5.1.1 基本信息
- 请求路径 :
/report/empGenderData - 请求方式:GET
- 接口描述:统计员工性别信息,返回男性和女性员工的数量。
5.1.2 请求参数
- 无请求参数。
5.1.3 响应数据
- 参数格式 :
application/json - 参数说明:接口返回的数据是一个 JSON 格式,包含了员工性别统计的结果。
响应数据样例:
json
{
"code": 1,
"msg": "success",
"data": [
{"name": "男性员工", "value": 5},
{"name": "女性员工", "value": 6}
]
}code:返回状态码,1 表示成功,0 表示失败。msg:返回消息,表示请求的处理结果。data:包含数据的数组,数组中的每一项包含name和value字段:name:类别名称(如 "男性员工" 或 "女性员工")。value:该类别的员工人数。
5.2 数据聚合与查询设计
报表统计接口不同于普通的 CRUD 接口,它需要对数据进行聚合(如统计、分组等)。在 Mapper 层 中,我们通过 MyBatis 执行聚合查询,并将结果返回到 Service 层 ,最后由 Controller 层 返回给前端。
5.2.1 Mapper 层
在 Mapper 层 中,我们使用 SQL 聚合函数来进行数据统计。对于员工性别统计,我们可能会执行类似以下的 SQL 查询:
xml
<select id="countEmpGenderData" resultType="java.util.Map">
SELECT
IF(gender = 1, '男性员工', '女性员工') AS name,
COUNT(*) AS value
FROM emp
GROUP BY gender
</select>IF(gender = 1, '男性员工', '女性员工') AS name:根据gender字段的值(1 表示男性,2 表示女性),将其转换为类别名称。COUNT(*) AS value:统计每个类别(性别)的员工数量。GROUP BY gender:按照性别分组,统计每个性别的员工数量。
5.2.2 Service 层
在 Service 层,我们调用 Mapper 层的聚合查询方法,获取数据并返回给 Controller 层。
java
@Override
public List<Map<String, Object>> countEmpGenderData() {
return empMapper.countEmpGenderData();
}5.2.3 Controller 层
在 Controller 层 ,我们将从 Service 层 获取到的聚合数据格式化后返回给前端。
java
@GetMapping("/report/empGenderData")
public Result getEmpGenderData() {
List<Map<String, Object>> genderData = empService.countEmpGenderData();
// 格式化为前端可用的格式
List<Map<String, Object>> result = genderData.stream().map(data -> {
Map<String, Object> formattedData = new HashMap<>();
formattedData.put("name", data.get("name"));
formattedData.put("value", data.get("value"));
return formattedData;
}).collect(Collectors.toList());
return Result.success(result);
}在这个方法中,我们首先调用 empService.countEmpGenderData() 获取从 Mapper 层返回的聚合数据,然后将其格式化成适合前端使用的形式。
5.3 前端与接口数据联动
前端使用 echarts 渲染图表时,将从接口获得的统计数据动态填充到图表中。以下是一个 饼状图 的 echarts 配置示例:
前端 echarts 饼状图配置:
javascript
option = {
tooltip: {
trigger: 'item'
},
legend: {
top: '5%',
left: 'center'
},
series: [
{
name: 'Access From',
type: 'pie',
radius: ['40%', '70%'],
avoidLabelOverlap: false,
itemStyle: {
borderRadius: 10,
borderColor: '#fff',
borderWidth: 2
},
label: {
show: false,
position: 'center'
},
emphasis: {
label: {
show: true,
fontSize: 40,
fontWeight: 'bold'
}
},
labelLine: {
show: false
},
data: [
{ value: 5, name: '男性员工' },
{ value: 6, name: '女性员工' }
]
}
]
};在这里,data 数组中的内容是由后端接口返回的数据填充的。每个 name 对应员工性别的类别(男性员工或女性员工),value 对应该类别的员工数量。前端通过调整图表的 option 配置项来渲染数据并展示图形。这里建议访问echarts官网页面,https://echarts.apache.org/zh/index.html,示例图如下:
5.4 总结
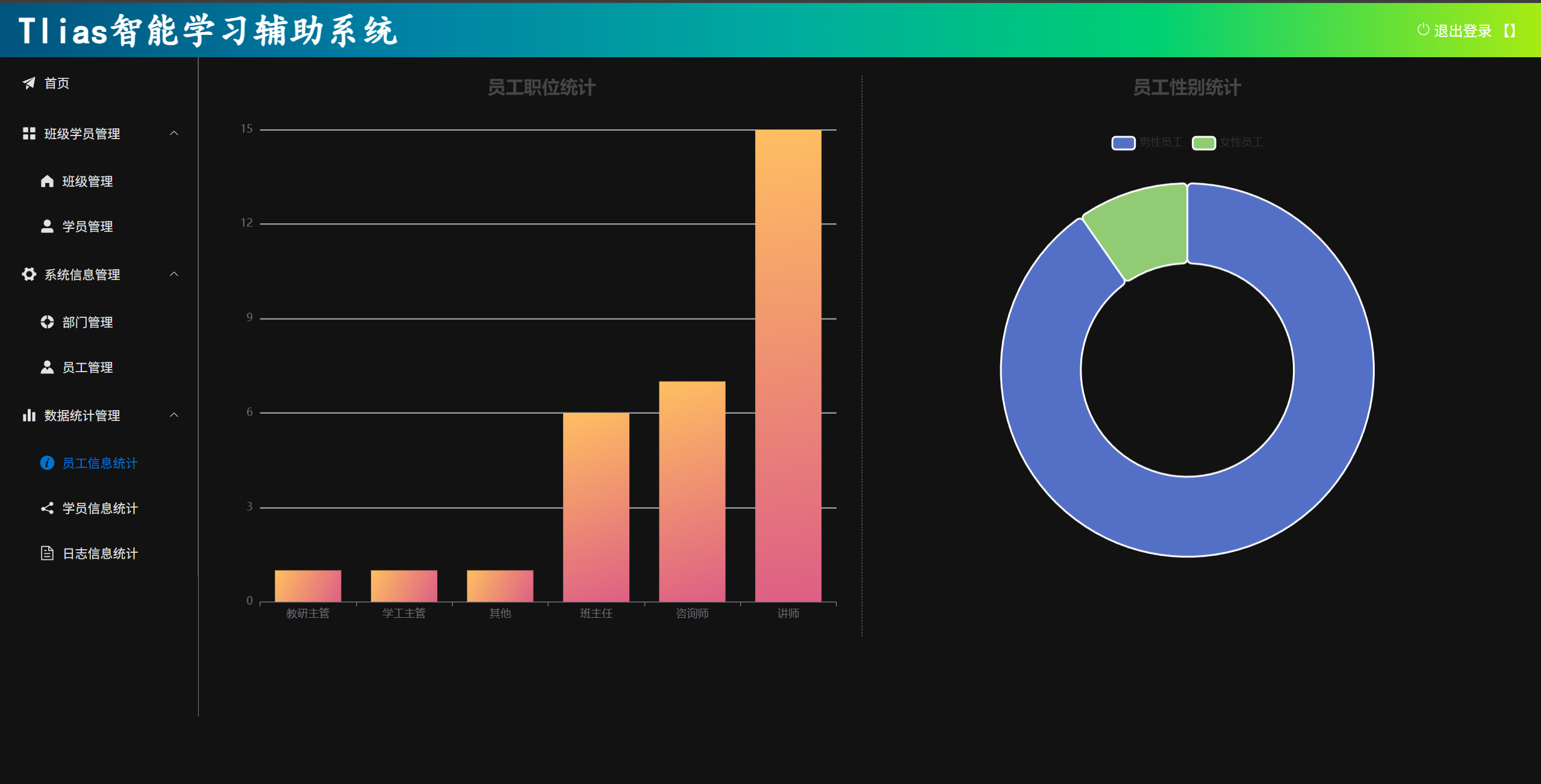
报表统计接口的设计相较于常规的 CRUD 接口要复杂一些,因为它需要执行 聚合查询 ,例如通过 SQL 的 GROUP BY 和 COUNT 等函数来对数据进行分组和统计。接口设计的关键是如何从 Mapper 层 获取统计数据,并将其格式化后返回给 Controller 层 ,最后由 Controller 层 返回前端。前端可以利用 echarts 等图表库将数据展示成直观的图表,提升用户体验。
在这个过程中,前后端的配合非常重要。接口设计要确保返回的数据符合前端的需求,而前端则通过适当的图表配置来呈现数据。这样的设计不仅增强了系统的可视化效果,也提升了用户的互动体验。
6. 文件上传 + OSS
在现代应用中,文件上传和存储是一项基础而重要的功能。相比将文件存储在本地磁盘,使用 云存储服务(如阿里云 OSS)能提供更好的扩展性和数据安全性。以下是整个文件上传与 OSS 存储实现的设计与代码解析。
6.1为什么不存本地
- 存储空间限制:本地存储的空间是有限的,随着文件数量的增多,磁盘空间会迅速耗尽。而云存储能够提供弹性扩展,支持大规模数据存储。
- 扩展性与高可用性:阿里云 OSS 提供高可用性,文件存储在云端,并且多地分布冗余,确保数据不丢失。而本地存储需要单独管理和备份,工作量较大。
- 安全性:OSS 提供了严格的权限管理,确保文件的安全性。对于外部访问的文件,OSS 支持 URL 签名和权限控制,避免了本地存储可能带来的安全风险。
- 成本效益:阿里云 OSS 按需付费,避免了本地存储的高成本和管理负担。
6.2OSS 的基本流程
- 配置 OSS :在配置文件中定义
endpoint、bucketName和region等信息,用于连接阿里云 OSS。 - 文件上传:在上传接口中,将文件传递给阿里云 OSS,通过 OSS SDK 上传文件。
- 返回文件 URL:上传成功后,返回文件在 OSS 中的 URL,供前端使用。
6.3关键源码解析
6.3.1 Controller 层:处理文件上传请求
在 Controller 层 ,我们使用 @PostMapping 接收文件上传请求,并调用 AliyunOSSOperator 工具类将文件上传到 OSS。
java
@Slf4j
@RestController
public class UploadController {
@Autowired
private AliyunOSSOperator aliyunOSSOperator;
@PostMapping("/upload")
public Result upload(MultipartFile file) throws Exception {
log.info("文件上传:{}", file.getOriginalFilename());
// 将文件交给 OSS 存储管理
String url = aliyunOSSOperator.upload(file.getBytes(), file.getOriginalFilename());
log.info("文件上传OSS,url:{}", url);
return Result.success(url);
}
}file.getBytes()获取文件字节内容。aliyunOSSOperator.upload()将文件上传到 OSS 存储。- 上传成功后,返回文件在 OSS 上的 URL。
6.3.2 Service 层:操作 OSS 存储
在 Service 层 ,AliyunOSSOperator 负责处理与阿里云 OSS 的交互,具体来说,它会生成唯一的文件名,并上传文件内容。
java
@Component
public class AliyunOSSOperator {
@Autowired
private AliyunOSSProperties aliyunOSSProperties;
public String upload(byte[] content, String originalFilename) throws Exception {
String endpoint = aliyunOSSProperties.getEndpoint();
String bucketName = aliyunOSSProperties.getBucketName();
String region = aliyunOSSProperties.getRegion();
// 获取凭证
EnvironmentVariableCredentialsProvider credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider();
// 设置文件存储目录和文件名
String dir = LocalDate.now().format(DateTimeFormatter.ofPattern("yyyy/MM"));
String newFileName = UUID.randomUUID() + originalFilename.substring(originalFilename.lastIndexOf("."));
String objectName = dir + "/" + newFileName;
// 创建 OSSClient 实例
ClientBuilderConfiguration clientBuilderConfiguration = new ClientBuilderConfiguration();
clientBuilderConfiguration.setSignatureVersion(SignVersion.V4);
OSS ossClient = OSSClientBuilder.create()
.endpoint(endpoint)
.credentialsProvider(credentialsProvider)
.clientConfiguration(clientBuilderConfiguration)
.region(region)
.build();
try {
// 上传文件
ossClient.putObject(bucketName, objectName, new ByteArrayInputStream(content));
} finally {
ossClient.shutdown();
}
// 返回文件的 URL
return endpoint.split("//")[0] + "//" + bucketName + "." + endpoint.split("//")[1] + "/" + objectName;
}
}AliyunOSSOperator 类的 upload() 方法执行了以下几个步骤:
- 从配置中读取 OSS 的
endpoint、bucketName和region。 - 使用
UUID生成唯一的文件名,避免文件名冲突。 - 使用阿里云 OSS SDK 的
OSSClient上传文件内容。 - 上传成功后返回文件的 URL。
6.3.3 配置类:阿里云 OSS 配置
java
@Data
@Component
@ConfigurationProperties(prefix = "aliyun.oss")
public class AliyunOSSProperties {
private String endpoint;
private String bucketName;
private String region;
}AliyunOSSProperties 类用于读取配置文件中的阿里云 OSS 相关信息,如 endpoint、bucketName 和 region,这些信息是连接和操作阿里云 OSS 存储所必需的。
6.3.4 配置文件示例 (application.properties)
properties
aliyun.oss.endpoint=your-endpoint
aliyun.oss.bucketName=your-bucket-name
aliyun.oss.region=your-region在配置文件中,我们将 aliyun.oss.endpoint、aliyun.oss.bucketName 和 aliyun.oss.region 配置为连接 OSS 所需要的参数。你需要根据你的实际 OSS 配置信息来替换这些值。
6.4处理流程
- 前端请求上传文件 :前端通过
POST请求上传文件到/upload接口。 - Controller 层接收文件 :
UploadController接收前端传来的文件,通过MultipartFile类型的参数。 - Service 层调用工具类上传文件到 OSS :
AliyunOSSOperator负责将文件内容上传到阿里云 OSS 存储。 - 返回文件 URL:文件上传成功后,返回文件的 URL 地址,前端可以使用该 URL 来显示或访问文件。
6.5为什么使用 OSS 存储而不是本地存储
- 可扩展性:OSS 提供了极高的存储弹性,能够应对大规模的文件存储需求,而本地存储的空间是有限的。
- 高可用性:OSS 提供高可用性,文件存储在云端,并通过多个副本确保数据不会丢失。
- 安全性:OSS 提供了更强的权限控制机制,确保文件的安全性。
- 便于管理和分发:通过 OSS 提供的 URL 可以方便地管理和分享文件,无需管理本地存储路径和访问权限。
6.6总结
通过使用 阿里云 OSS ,我们避免了将文件存储在本地磁盘中,提供了更好的存储扩展性和可靠性。通过 Controller 层接收文件,Service 层调用工具类上传文件,最终将文件的 URL 返回给前端,整个过程清晰高效。这种设计使得文件上传变得简单、灵活,并且符合生产环境的最佳实践。
OSS 存储的使用为系统提供了更好的可扩展性 、高可用性 和数据安全性,极大简化了文件管理的复杂度。
7. 全局异常与自定义异常:为什么不 try-catch 到处写
在开发过程中,错误处理是一项非常重要的任务。传统的错误处理方式通常是在每个方法中使用 try-catch 来捕获异常并做出响应。然而,这种方式有几个缺点:
- 代码重复 :每个方法都需要写
try-catch,增加了代码的冗余。 - 不一致的错误处理:不同的地方可能会有不同的错误响应格式,导致前端处理错误时不一致。
- 维护困难 :如果需要修改错误处理逻辑(比如增加日志记录、统一的错误返回格式等),就必须修改所有
try-catch的地方。
为了解决这些问题,Spring 提供了 全局异常处理 的功能,通过 @ControllerAdvice 来统一处理异常,结合 自定义异常 类(如 BusinessException)来使得错误处理更具灵活性和可维护性。
7.1关键部分解析
7.1.1. BusinessException:自定义异常类
BusinessException 用于处理业务逻辑相关的异常。在实际开发中,很多时候我们需要捕获特定的业务异常,来向用户反馈明确的错误信息。这个类继承自 RuntimeException,可以根据需要携带错误码和详细的错误信息。
java
@Data
public class BusinessException extends RuntimeException {
private Integer code; // 错误码
private String message; // 错误信息
// 构造函数 - 只传入错误信息,默认错误码为500
public BusinessException(String message) {
super(message);
this.code = 500;
this.message = message;
}
// 构造函数 - 传入错误码和错误信息
public BusinessException(Integer code, String message) {
super(message);
this.code = code;
this.message = message;
}
// 构造函数 - 传入错误信息和异常原因
public BusinessException(String message, Throwable cause) {
super(message, cause);
this.code = 500;
this.message = message;
}
// 构造函数 - 传入错误码、错误信息和异常原因
public BusinessException(Integer code, String message, Throwable cause) {
super(message, cause);
this.code = code;
this.message = message;
}
}code:用于表示错误码,可以根据不同的错误类型定义不同的错误码。message:错误信息,描述错误的具体原因。
7.1.2. GlobalExceptionHandler:全局异常处理
@RestControllerAdvice 注解结合 @ExceptionHandler 可以集中处理全局的异常,避免了每个方法中都要写 try-catch。在一个集中处理的地方,我们可以根据异常类型进行不同的处理,并返回统一格式的错误信息。
java
@Slf4j
@RestControllerAdvice
public class GlobalExceptionHandler {
// 处理数据库重复键异常
@ExceptionHandler
public Result handleDuplicateKeyException(DuplicateKeyException e) {
log.error("服务器发生异常:{}", e.getMessage());
String message = e.getMessage();
int i = message.indexOf("Duplicate entry");
String errMsg = message.substring(i);
String[] arr = errMsg.split(" ");
return Result.error(arr[2] + " 已存在");
}
// 处理业务逻辑异常
@ExceptionHandler
public Result handleBusinessException(BusinessException e) {
log.error("服务器发生异常:{}", e.getMessage());
String message = e.getMessage();
return Result.error(message);
}
// 处理请求参数类型不匹配的异常
@ExceptionHandler
public Result handleMethodArgumentTypeMismatchException(MethodArgumentTypeMismatchException e) {
log.error("服务器发生异常:{}", e.getMessage());
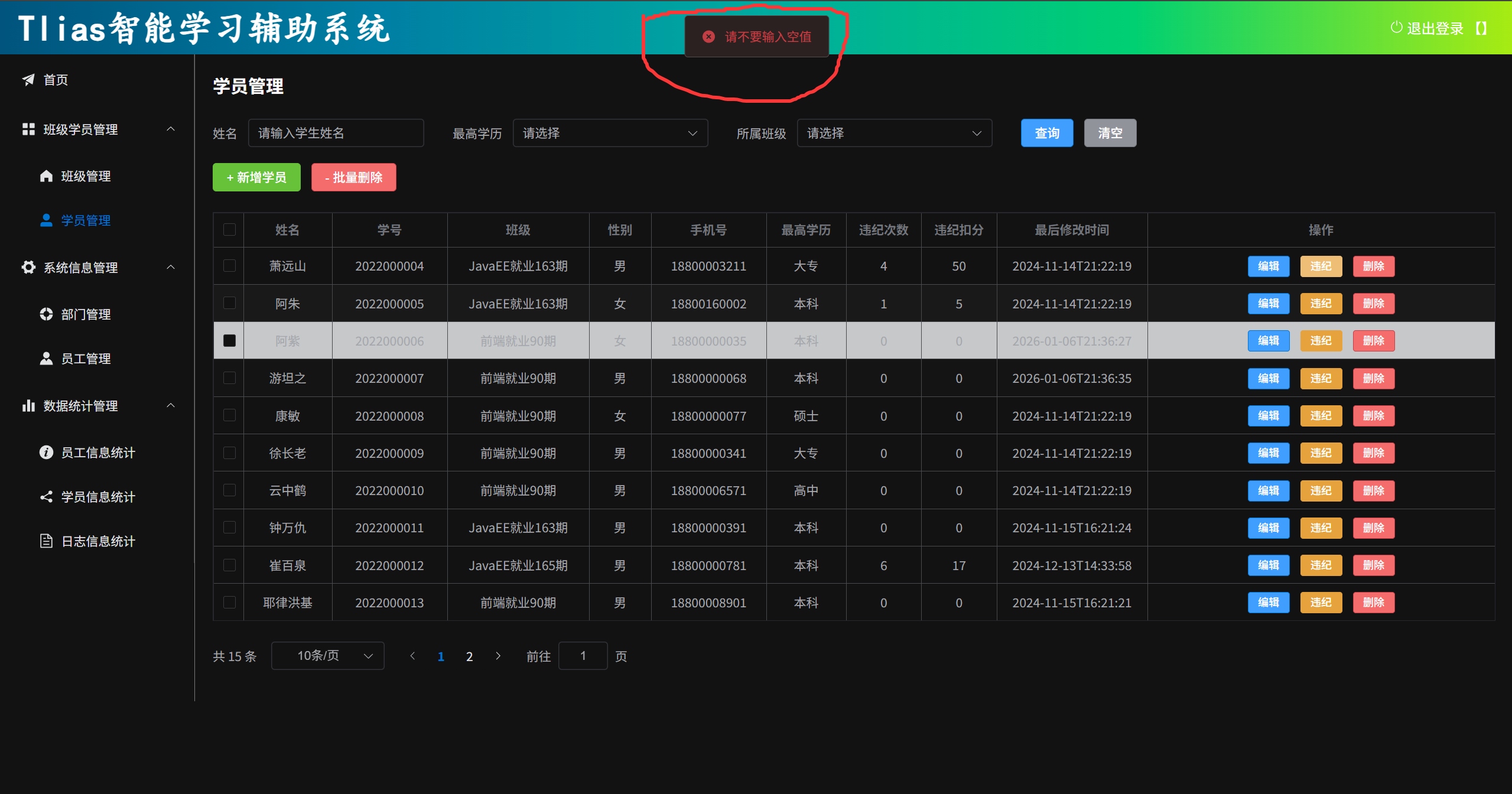
return Result.error("请不要输入空值");
}
}7.2 统一错误返回格式
在 GlobalExceptionHandler 中,我们通过 @ExceptionHandler 处理不同的异常,并将错误信息通过 Result 类统一返回。Result 类是我们定义的返回格式,它包括了 code、msg 和 data,用来封装统一的错误响应。
java
public class Result {
private Integer code; // 错误码:1 表示成功,0 表示失败
private String msg; // 错误信息
private Object data; // 额外数据
// 成功返回结果
public static Result success() {
Result result = new Result();
result.code = 1;
result.msg = "success";
return result;
}
// 错误返回结果
public static Result error(String msg) {
Result result = new Result();
result.code = 0;
result.msg = msg;
return result;
}
// Getter and Setter methods
}7.3 为什么不 try-catch 到处写
- 代码冗余 :每个方法都写
try-catch会导致代码重复且增加了出错的可能性。 - 错误处理不一致 :不同的
try-catch块可能会返回不同的错误信息,导致前端处理错误时不一致。 - 难以维护 :如果需要修改错误处理逻辑(例如统一记录日志、统一错误返回格式等),必须修改每个
try-catch块,增加了维护的复杂度。
通过 @ControllerAdvice 和 @ExceptionHandler,我们可以将异常处理集中起来,减少代码重复,提高代码可维护性和一致性。
7.4. 总结
通过自定义异常(如 BusinessException)和全局异常处理(通过 @ControllerAdvice),我们能够更优雅地处理异常,并保证错误信息的统一返回格式。这样的设计不仅提高了系统的健壮性,也让代码更加清晰和可维护,避免了传统的 try-catch 带来的冗余和不一致问题。
这种方法让我们能够专注于业务逻辑,而不需要每个地方都写繁琐的异常处理代码,从而提升了开发效率和代码质量。
8. 写完这个项目,我对"三层架构"的真实理解
作为这篇文章的个人反思章节,我想分享一下在这个项目开发过程中,我对"三层架构"从最初的困惑到最终的理解转变。这不仅是对技术的学习,也是对整个项目开发和架构设计思想的一次深刻反思。
一开始的困惑
刚开始接触三层架构时,我对这种分层的设计感到有些不适应。每当我创建了一个 Controller 层后,我就会陷入一种"接下来做什么"的困境。我知道应该有 Service 层和 Mapper 层,但我经常犹豫是否应该直接在 Service 层实现逻辑,还是先在 Mapper 层定义接口并配合 XML 文件写 SQL 查询。尤其是在 Mapper 层 ,我一直在纠结是应该直接在接口方法上加注解(如 @Select)还是在 resources 文件夹中建立 XML 文件,再手动写 SQL 语句。
初始阶段,这种思维的切换让我很迷茫,缺乏一种清晰的流程感。每当我从一个层次切换到另一个层次时,我没有形成足够的条件反射,总是需要想一想"接下来应该做什么",这种思维的跳跃让我感到有些力不从心。
写完后的变化
随着项目逐步开发并最终完成,我逐渐体会到了三层架构的优势,也对它的设计思想有了更深刻的理解。我发现,每一层都有其独立而清晰的职责------Controller 层只负责接收请求和返回响应,Service 层负责具体的业务逻辑,Mapper 层负责与数据库交互。
这种清晰的分层让我逐渐适应了将不同职责的功能分配到不同层次的工作方式。当我写完 Controller 层后,我意识到它的任务只是接收请求并传递给 Service 层,而 Service 层的工作则是处理具体的业务逻辑,最终调用 Mapper 层进行数据查询。每一层完成自己的任务,避免了过度耦合和职责混乱。
对"分层"的重新理解
从最初的不适应到最终的习惯,我对 分层设计 的理解也发生了转变。三层架构 的核心思想是 解耦,它通过将不同的责任分配给不同的层次,极大提高了代码的可维护性和可扩展性。
- 清晰的职责分配:通过三层架构,每一层都只关注自己应该做的事情,不会越界干涉其他层的职责。例如,Controller 层仅负责接受请求和返回结果,不需要考虑具体的业务逻辑;Service 层专注于处理业务,数据访问的细节则交给 Mapper 层来处理。
- 提高可维护性:当系统出现问题时,我可以非常清晰地知道问题出在哪一层。比如说在与前端联调时,如果出现后台报错,我会首先看日志,确认是业务逻辑层(Service 层)的问题,还是数据访问层(Mapper 层)的问题。通过查看具体的层次,迅速定位到代码中的问题,并进行修复。
- 封装与复用性:随着代码的分层,我发现将不同的业务逻辑封装到独立的层中,不仅让代码变得更加简洁,也为日后的扩展和维护带来了便利。比如,如果某个功能需要改动,只需要修改相关层的代码,而不需要影响到其他层的代码。
分层架构带来的优势
通过这次项目开发,我逐步体会到了 分层架构 带来的诸多好处:
- 错误定位更加精准:在实际调试过程中,分层架构让我能更容易地识别错误所在的层次。无论是 Controller 层、Service 层还是 Mapper 层,当出现问题时,我能通过日志迅速定位到错误的具体层次,避免了全局搜索的低效。
- 代码复用性更高:每一层的封装使得代码更加模块化。在 Service 层中,我们可以直接调用 Mapper 层的方法,而不需要关心数据查询的细节,Service 层的逻辑也能被多个 Controller 层复用。不同功能的业务逻辑可以通过引入不同的 Service 层进行组合,提升了代码的复用性。
- 代码维护更加方便:分层让每个层次的代码都集中在特定区域,这使得后期的维护和功能扩展更加容易。如果某个功能的实现需要修改,只需修改相关的 Service 或 Mapper 层,而不需要大范围的改动。
总结
在开发过程中,最初的困惑是因为我没有完全理解三层架构的思想,尤其是在层与层之间的职责和工作流上,我没有形成条件反射。随着项目的深入,我逐渐意识到,三层架构的本质就是解耦,每一层专注自己的任务,减少了相互之间的依赖和耦合,增加了系统的灵活性和可扩展性。通过这样的设计,我能够更加高效地处理系统的错误定位、代码复用以及后期的维护。
最终,我深刻地理解了分层架构对代码的优化作用,并且在实际项目中体会到了它的好处。分层架构不仅提高了代码的可维护性和扩展性,也让开发过程变得更加有条理、清晰且高效。