从零开始:YOLO11 训练 DOTA OBB 遥感数据
1.数据/工具下载
数据下载:https://captain-whu.github.io/DOTA/dataset.html
代码下载:https://github.com/ultralytics/ultralytics
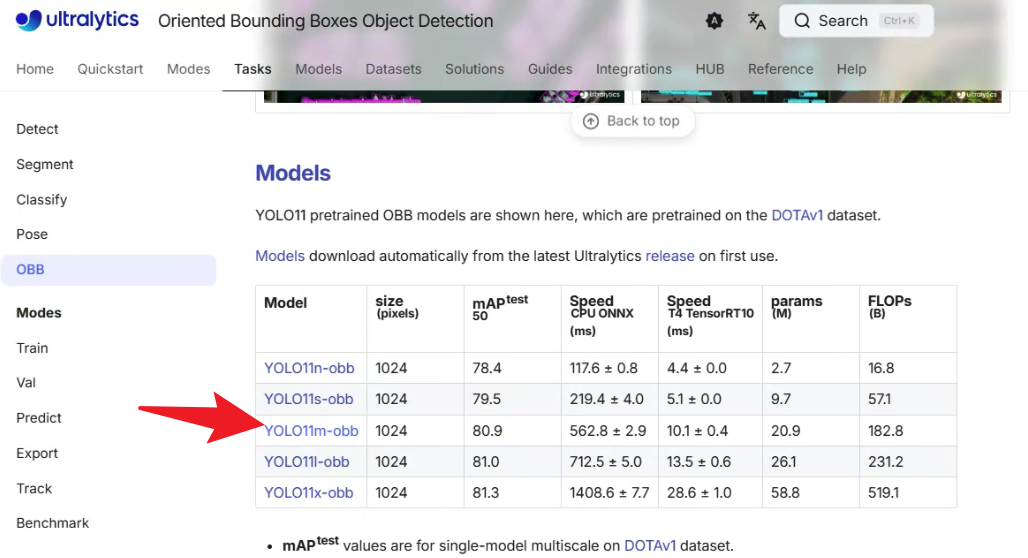
模型下载:https://docs.ultralytics.com/tasks/obb/
数据转换工具:https://ai4wild.com/zeyoo
2. 数据处理
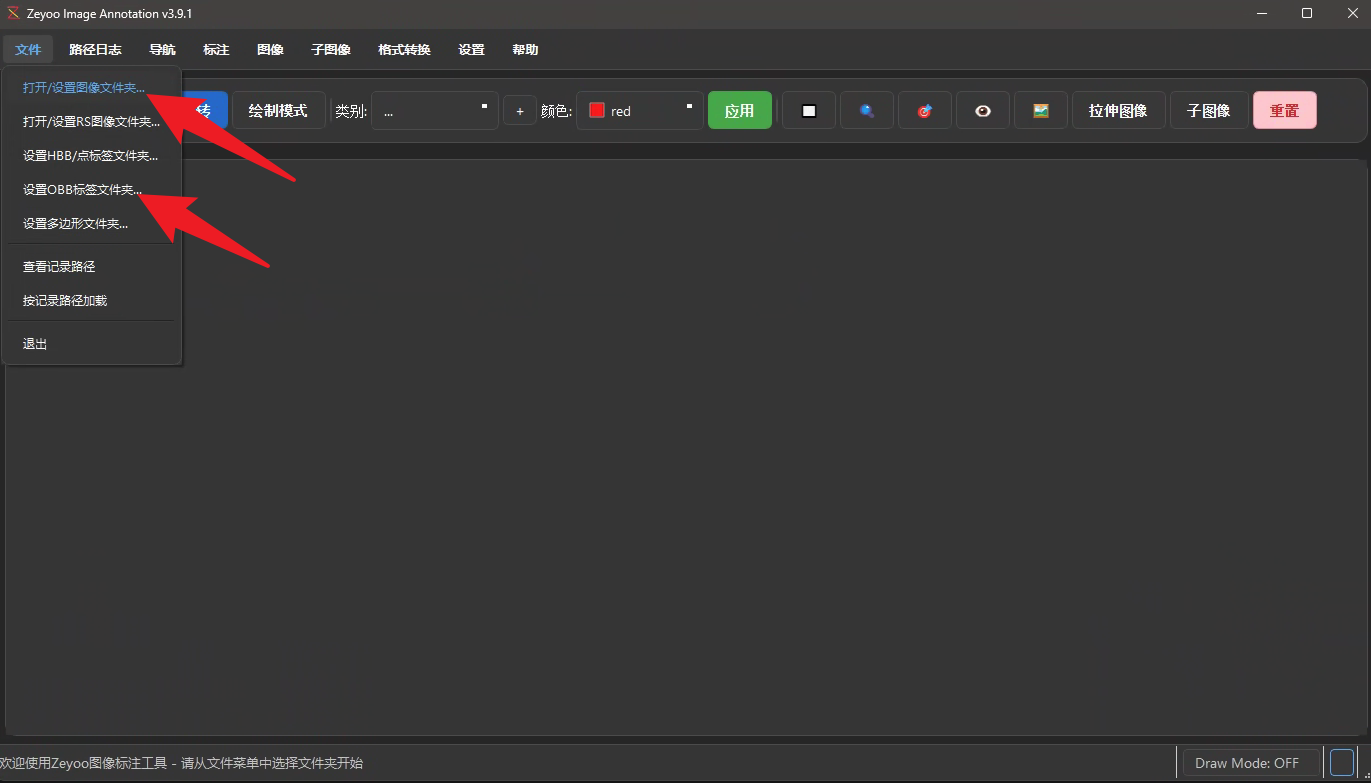
2.1 使用深度学习样本处理工具Zeyoo 可以方面的查看数据和格式转换
支持3种系统,windows ,mac 和 linux ubuntu

在图像文件夹路径直接选择解压好的dota 里面的images路径,在obb标签文件夹路径我们使用的是v1.5版本,同样直接选择解压好的文件夹路径
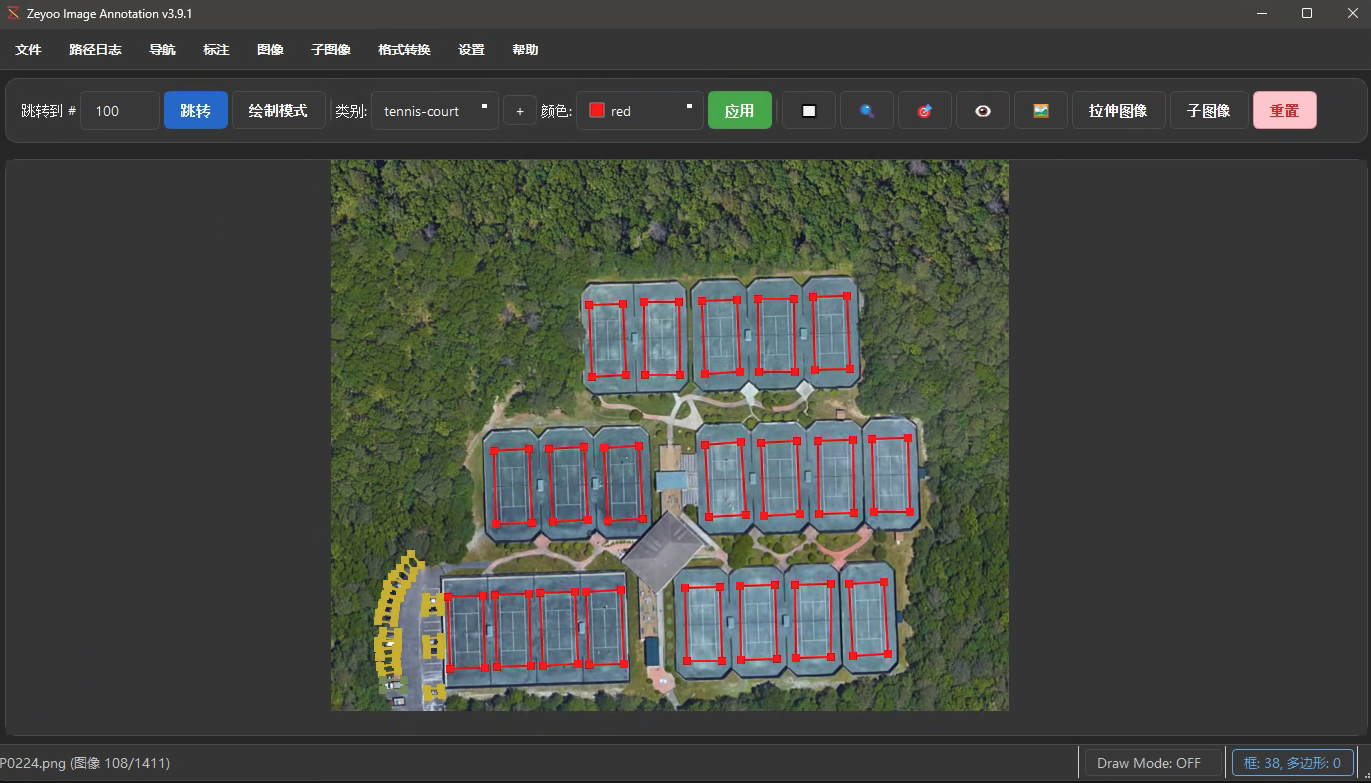
由于原始dota数据尺寸较大,长、宽都有上千像素,因此要先裁剪切分为小尺寸的图像。
选择子图像菜单下的分块切割图像。可以选择一些设置参数。
由于数据量很大,因此等待时间较长。
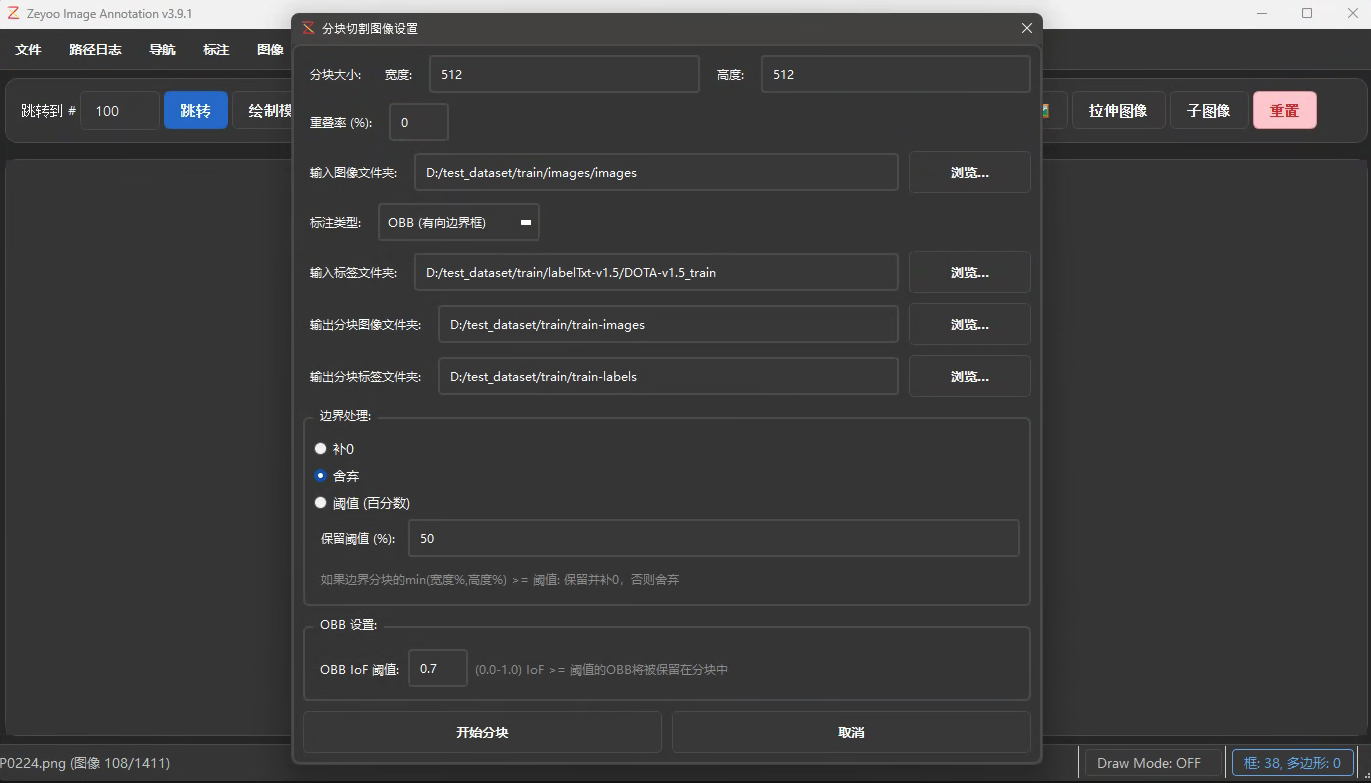
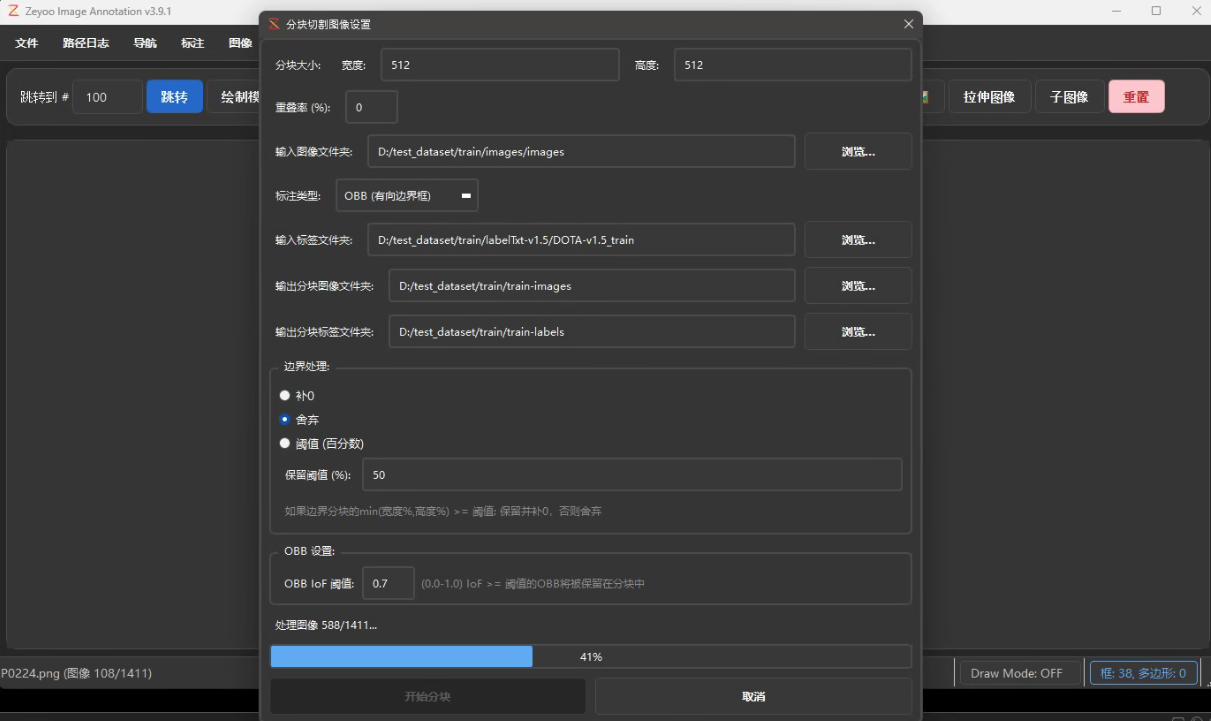
点击右上角重置按钮,关闭已加载的图像,然后在文件里,选择新生成的小尺寸图像和对应label,并通过软件自带的转换工具,转为YOLO格式
YOLO格式的旋转框如下,和DOTA原始格式不同
class_index x1 y1 x2 y2 x3 y3 x4 y4
例子:0 0.780811 0.743961 0.782371 0.74686 0.777691 0.752174 0.776131 0.749758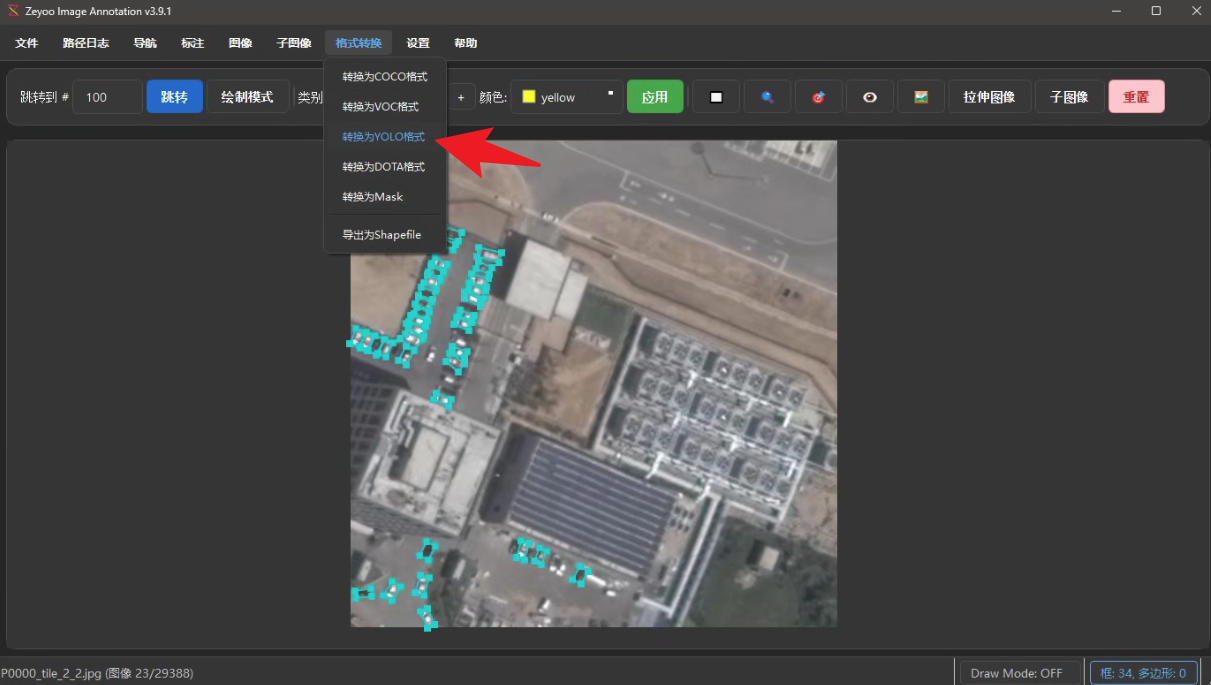
先选择是OBB框标注,可以在类别选项卡里扫描并加载所有类别名,此处可以自定义不同类别对应的YOLO标注序号
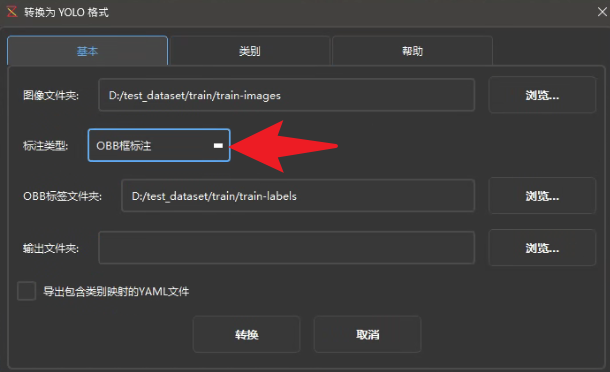
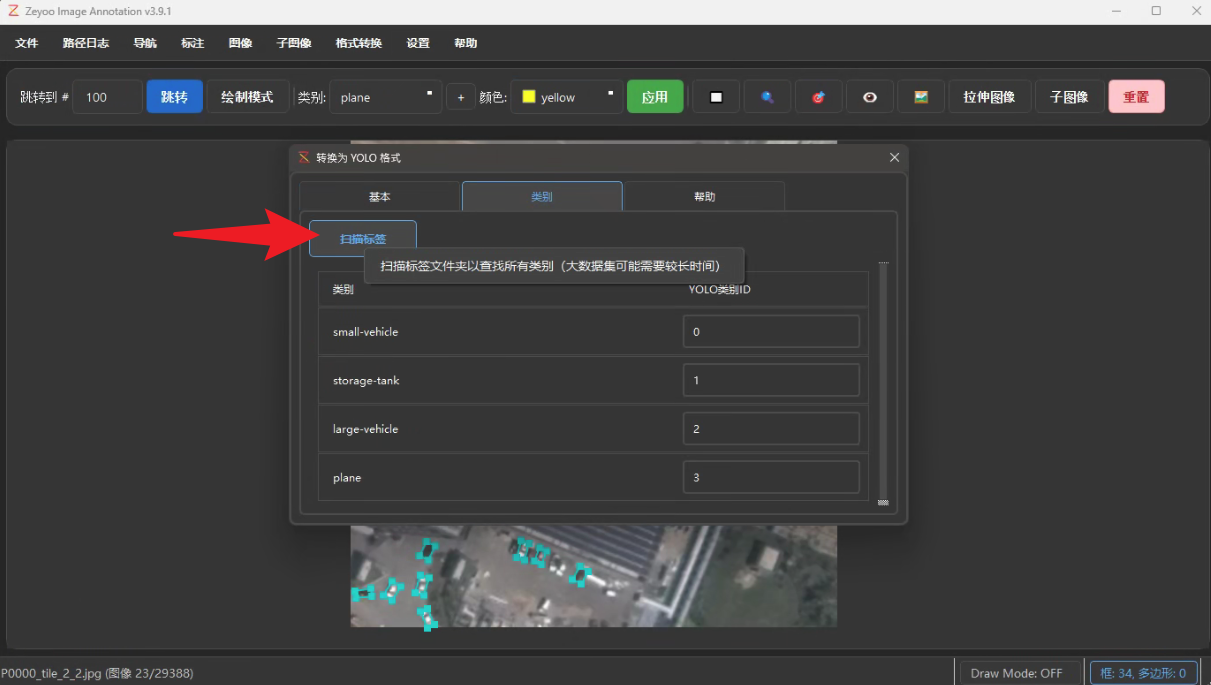
勾选:导出包含类别映射的YAML文件,这样下方的yaml可以直接生成:
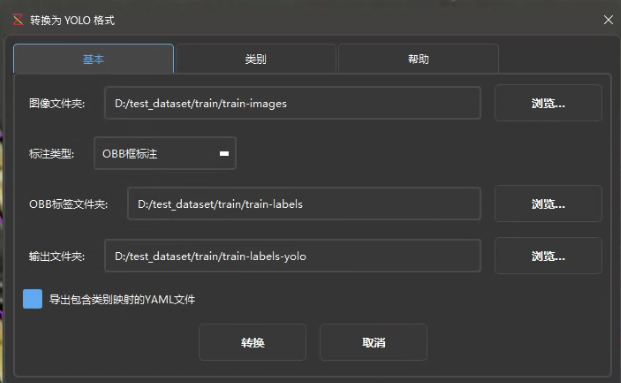
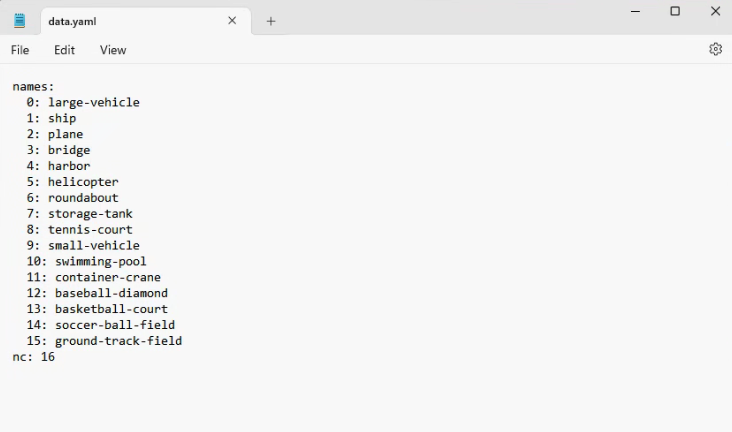
添加上yolo数据路径即可:
path: D:/test_dataset/train/data
train: images/train
val: images/val
names:
0: large-vehicle
1: ship
2: plane
3: bridge
4: harbor
5: helicopter
6: roundabout
7: storage-tank
8: tennis-court
9: small-vehicle
10: swimming-pool
11: container-crane
12: baseball-diamond
13: basketball-court
14: soccer-ball-field
15: ground-track-field
nc: 16这里我们重命名为了obb.yaml
建议YOLO数据文件夹命名格式为:
dataset/
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ └── ...
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ └── ...
├── val/
│ ├── images/
│ └── labels/
├── test/
│ ├── images/
│ └── labels/
└── data.yaml # 配置文件3. 模型运行
3.1 下载模型和对应权重
代码下载:https://github.com/ultralytics/ultralytics
模型下载:https://docs.ultralytics.com/tasks/obb/
新建train.py ,运行。
python
import os
import torch
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO("yolo11m-obb.pt")
results = model.train(
data=r"D:\test_dataset\train\data\obb.yaml",
epochs=10,
imgsz=512,
batch=5,
device=0,
workers=0,
)测试输出:
python
import os
from pathlib import Path
from ultralytics import YOLO
import cv2
def predict_obb(input_folder: str, output_folder: str, model_path):
os.makedirs(output_folder, exist_ok=True)
model = YOLO(model_path)
image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.tif', '.tiff', '.webp'}
input_path = Path(input_folder)
image_files = [f for f in input_path.iterdir()
if f.is_file() and f.suffix.lower() in image_extensions]
if not image_files:
print(f"在 {input_folder} 中未找到图像文件")
return
print(f"找到 {len(image_files)} 张图像,开始预测...")
for img_file in image_files:
results = model(str(img_file))
for result in results:
result_img = result.plot()
output_path = Path(output_folder) / f"{img_file.stem}_result{img_file.suffix}"
cv2.imwrite(str(output_path), result_img)
print(f"已处理: {img_file.name}")
print(f"\n预测完成!结果保存在: {output_folder}")
if __name__ == '__main__':
INPUT_FOLDER = r"D:\test_dataset\test_images"
OUTPUT_FOLDER = r"D:\test_dataset\obb_results"
MODEL_PATH = r"runs/obb/train11/weights/best.pt"
predict_obb(INPUT_FOLDER, OUTPUT_FOLDER, MODEL_PATH)