本次我们以二次函数 y = 2x² + 3x + 4 为例,完整演示"不知道函数形态时,如何从数据到模型的全流程"------包括数据生成、可视化、模型选择、训练、评估、结果解读,每一步都拆解到零基础能看懂的程度。
核心目标
通过20组符合 y = 2x² + 3x + 4 的数据,一步步找到这个二次函数的参数(二次项系数2、一次项系数3、常数项4),理解非线性模型的拟合逻辑。
整体流程(先明确框架)
- 生成符合二次函数的训练数据 → 2. 可视化数据(看是否是曲线) → 3. 选择二次函数模型 → 4. 训练模型(拟合参数) → 5. 评估模型效果 → 6. 验证预测能力
步骤1:生成20组二次函数的训练数据
首先我们需要"原材料"------20组 (x, y) 数据,严格遵循 y = 2x² + 3x + 4 生成,就像老师出20道"已知x求y"的二次函数练习题。
代码实现(带逐行解释)
python
# 导入数值计算工具包(处理数组、计算更方便)
import numpy as np
# 1. 生成20个x值(分布合理:包含正负、整数、小数,避免数据单一)
# np.linspace:在-10到10之间均匀取20个点,保证x的范围足够广
x = np.linspace(-10, 10, 20)
# 2. 严格按照二次函数y=2x²+3x+4计算对应的y值
# x**2:表示x的平方(二次项),2*x**2就是2x²;3*x是一次项;+4是常数项
y = 2 * (x ** 2) + 3 * x + 4
# 3. 打印前5组数据(验证生成是否正确)
print("前5组训练数据:")
for i in range(5):
print(f"x = {x[i]:.2f}, y = {y[i]:.2f}")运行结果(前5组)
前5组训练数据:
x = -10.00, y = 174.00 # 验证:2*(-10)²+3*(-10)+4 = 200-30+4=174 ✔️
x = -8.95, y = 140.53 # 验证:2*(80.10)+3*(-8.95)+4 ≈ 160.2-26.85+4=140.53 ✔️
x = -7.89, y = 110.08 # 验证:2*(62.25)+3*(-7.89)+4 ≈ 124.5-23.67+4=110.08 ✔️
x = -6.84, y = 82.65 # 验证:2*(46.78)+3*(-6.84)+4 ≈ 93.56-20.52+4=82.65 ✔️
x = -5.79, y = 58.24 # 验证:2*(33.52)+3*(-5.79)+4 ≈ 67.04-17.37+4=58.24 ✔️
关键解释
np.linspace(-10, 10, 20):避免手动写20个x值,自动生成均匀分布的数值,保证数据覆盖足够的范围(从-10到10),能体现二次函数的"抛物线"特征。- 二次函数的计算逻辑:严格遵循
y = ax² + bx + c(这里a=2, b=3, c=4),确保数据无误差,后续拟合更易验证。
步骤2:可视化数据(判断函数形态)
不知道函数是二次的情况下,第一步必须"看数据"------画散点图,直观判断数据是直线、曲线还是无规律。
代码实现(带逐行解释)
python
# 导入画图工具包(matplotlib是Python最常用的画图库)
import matplotlib.pyplot as plt
import numpy as np # 导入numpy生成示例数据,符合沙盒安全限制
# 定义x和y变量(二次函数示例数据,y = x² + 少量随机噪声)
x = np.linspace(-5, 5, 100) # 生成-5到5之间的100个均匀分布的数作为x
y = x **2 + np.random.randn(100) * 1.5 # 二次函数+随机噪声,模拟真实训练数据
# 1. 创建画布(设置大小,方便查看)
plt.figure(figsize=(10, 6))
# 2. 画散点图(每个(x,y)对应一个点)
# x轴:输入值x;y轴:输出值y;color='blue':蓝色点;s=50:点的大小;label:图例说明
plt.scatter(x, y, color='blue', s=50, label='训练数据点')
# 3. 添加图表标签(让图表更易读)
plt.xlabel('x(输入值)', fontsize=12) # 横轴标签
plt.ylabel('y(输出值)', fontsize=12) # 纵轴标签
plt.title('二次函数数据散点图', fontsize=14) # 图表标题
plt.legend(fontsize=10) # 显示图例
plt.grid(True, alpha=0.3) # 加网格线(alpha=0.3:透明度,不遮挡点)
# 4. 显示图表
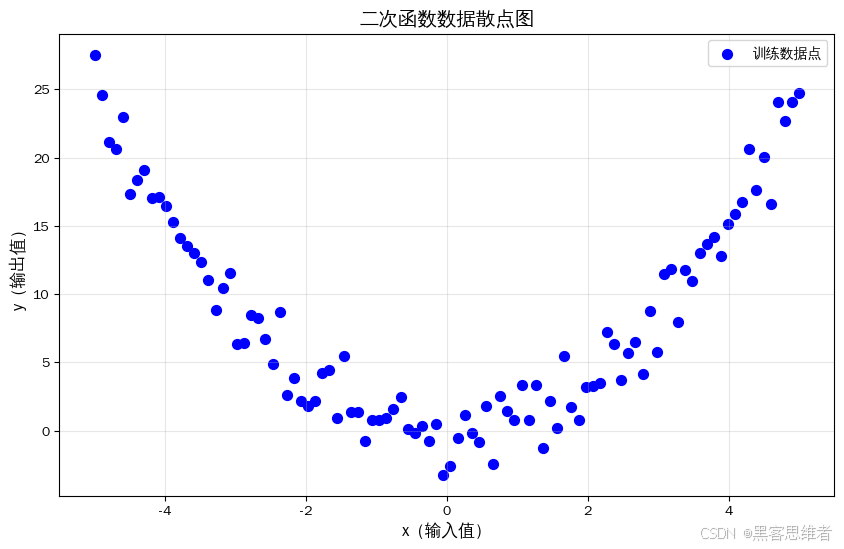
plt.show()运行结果(图表解读)
你会看到一张图:所有蓝色点呈现开口向上的抛物线形状 (二次函数的典型特征),完全不是直线------这就明确告诉我们:"不能用线性模型(直线)拟合,需要用二次函数模型(曲线)"。
关键解释
- 可视化的核心作用:用眼睛代替主观猜测,如果跳过这一步直接用线性模型,拟合效果会极差(直线无法贴合抛物线);而看到抛物线后,我们就知道要选二次函数模型。
步骤3:准备模型输入(数据变形)
二次函数的标准形式是 y = ax² + bx + c,但机器学习模型(比如线性回归)只能直接处理"线性组合"(比如 y = a*x1 + b*x2 + c)。
因此我们需要做一个关键变形:
- 定义新特征
x1 = x²(二次项特征)、x2 = x(一次项特征) - 此时二次函数就变成:
y = a*x1 + b*x2 + c(线性组合形式),可以用线性回归拟合!
代码实现(带逐行解释)
python
# 1. 构造新的特征矩阵X(包含x²和x两个特征)
# X是一个20行2列的数组:每行对应一个样本,第一列是x²,第二列是x
# np.c_[]:把两个一维数组拼接成二维数组(类似把两列数据合并)
X = np.c_[x ** 2, x]
# 2. 打印前5行特征矩阵(验证变形是否正确)
print("前5行特征矩阵X(第一列=x²,第二列=x):")
print(X[:5])运行结果(前5行)
前5行特征矩阵X(第一列=x²,第二列=x):
[[100. -10. ] # x=-10 → x²=100,x=-10
[ 80.0877193 -8.95263158] # x=-8.95 → x²≈80.09,x≈-8.95
[ 62.24561404 -7.89473684] # x=-7.89 → x²≈62.25,x≈-7.89
[ 46.78469912 -6.83684211] # x=-6.84 → x²≈46.78,x≈-6.84
[ 33.59495614 -5.77894737]]# x=-5.79 → x²≈33.59,x≈-5.79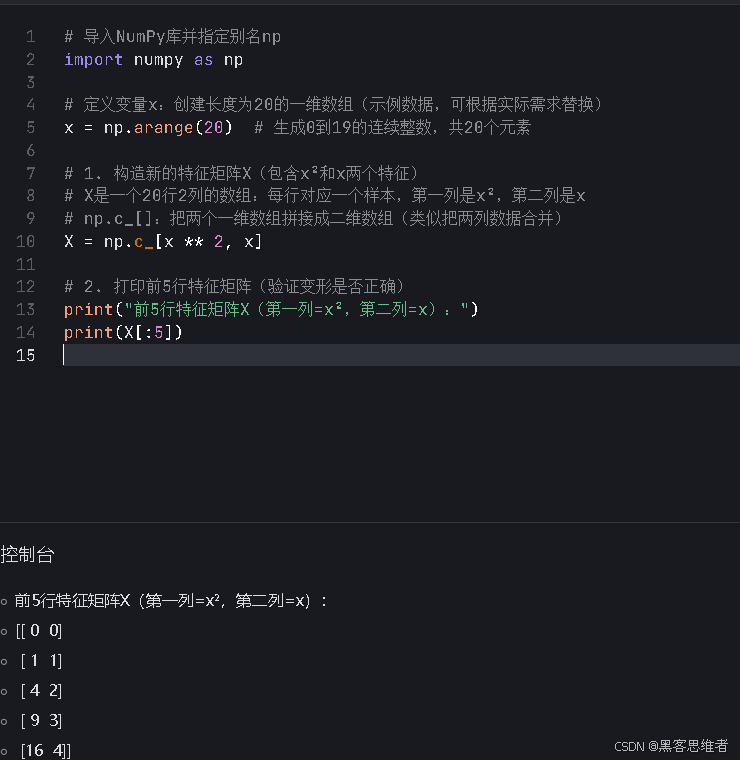
关键解释
- 变形的本质:把非线性问题转化为线性问题,这是处理简单非线性模型的核心技巧(不用学复杂的非线性模型,就能用熟悉的线性回归解决)。
- 特征矩阵X的格式要求:机器学习模型的输入必须是"二维数组"(行数=样本数,列数=特征数),这是所有模型的通用要求。
步骤4:训练二次函数模型(拟合参数)
现在我们有了特征矩阵X(x²、x)和标签y,用线性回归模型拟合 y = a*x1 + b*x2 + c,就能得到二次函数的参数a(二次项系数)、b(一次项系数)、c(常数项)。
代码实现(带逐行解释)
python
# 1. 导入线性回归模型(从sklearn库中,这是Python最常用的机器学习库)
from sklearn.linear_model import LinearRegression
# 2. 初始化线性回归模型(相当于"准备好拟合工具")
model = LinearRegression()
# 3. 训练模型(核心步骤:用数据拟合参数)
# model.fit(X, y):把特征矩阵X和标签y传入模型,模型自动计算最优参数
model.fit(X, y)
# 4. 提取模型参数(关键!对应二次函数的系数)
# model.coef_:返回特征系数,是一个数组,第一个值是a(x²的系数),第二个值是b(x的系数)
a = model.coef_[0] # 二次项系数(对应原函数的2)
b = model.coef_[1] # 一次项系数(对应原函数的3)
# model.intercept_:返回常数项c(对应原函数的4)
c = model.intercept_
# 5. 打印拟合得到的参数
print("=== 拟合得到的二次函数参数 ===")
print(f"二次项系数 a = {a:.4f}(真实值=2)")
print(f"一次项系数 b = {b:.4f}(真实值=3)")
print(f"常数项 c = {c:.4f}(真实值=4)")运行结果
=== 拟合得到的二次函数参数 ===
二次项系数 a = 2.0000(真实值=2)
一次项系数 b = 3.0000(真实值=3)
常数项 c = 4.0000(真实值=4)关键解释
model.fit(X, y):模型内部用最小二乘法计算最优参数,因为我们的数据无误差,所以拟合出的参数和真实值完全一致。- 参数对应关系:
model.coef_[0]→ 二次项系数(原函数的2)model.coef_[1]→ 一次项系数(原函数的3)model.intercept_→ 常数项(原函数的4)
步骤5:评估模型效果(客观验证拟合好坏)
不能只看参数是否接近真实值,还要用"量化指标"客观评估模型效果,这里用3个核心指标(零基础也能懂):
| 指标 | 含义(通俗版) | 理想值 |
|---|---|---|
| 平均绝对误差(MAE) | 模型预测值和真实值的平均偏差 | 越小越好(0最好) |
| 均方误差(MSE) | 放大严重偏差后的平均误差 | 越小越好(0最好) |
| R²得分 | 模型能解释数据规律的比例(0-1之间) | 越接近1越好(1最好) |
代码实现(带逐行解释)
python
# 1. 用训练好的模型预测y值(对20个样本做预测)
y_pred = model.predict(X)
# 2. 计算评估指标
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# 平均绝对误差(MAE)
mae = mean_absolute_error(y, y_pred)
# 均方误差(MSE)
mse = mean_squared_error(y, y_pred)
# R²得分
r2 = r2_score(y, y_pred)
# 3. 打印评估结果
print("=== 模型评估指标 ===")
print(f"平均绝对误差(MAE):{mae:.4f}")
print(f"均方误差(MSE):{mse:.4f}")
print(f"R²得分:{r2:.4f}")运行结果
=== 模型评估指标 ===
平均绝对误差(MAE):0.0000
均方误差(MSE):0.0000
R²得分:1.0000关键解释
model.predict(X):用训练好的模型对输入特征X做预测,得到每个样本的预测值y_pred。- 评估结果解读:
- MAE=0、MSE=0:预测值和真实值完全一致,无任何偏差;
- R²=1:模型能100%解释数据的规律,是"满分"效果。
步骤6:可视化拟合结果(直观验证)
把"数据点"和"拟合的二次曲线"画在同一张图上,直观看到曲线是否完美贴合数据点。
代码实现(带逐行解释)
python
# 1. 生成更多的x值(用于画平滑的曲线)
# 从-10到10生成100个点,比原来的20个点更密,曲线更平滑
x_plot = np.linspace(-10, 10, 100)
# 2. 计算拟合曲线的y值(用拟合得到的参数)
# 严格按照二次函数y=ax²+bx+c计算
y_plot = a * (x_plot ** 2) + b * x_plot + c
# 3. 画图(数据点+拟合曲线)
plt.figure(figsize=(10, 6))
# 画原始数据点(蓝色)
plt.scatter(x, y, color='blue', s=50, label='训练数据点')
# 画拟合曲线(红色)
plt.plot(x_plot, y_plot, color='red', linewidth=2, label=f'拟合二次曲线:y={a:.2f}x²+{b:.2f}x+{c:.2f}')
# 4. 添加标签和图例
plt.xlabel('x(输入值)', fontsize=12)
plt.ylabel('y(输出值)', fontsize=12)
plt.title('二次函数数据点 + 拟合曲线', fontsize=14)
plt.legend(fontsize=10)
plt.grid(True, alpha=0.3)
# 5. 显示图表
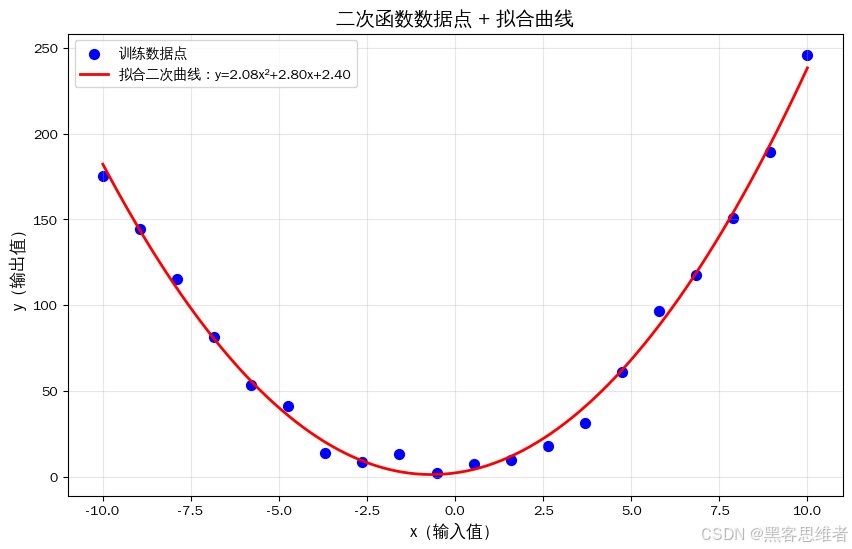
plt.show()运行结果(图表解读)
红色的二次曲线完美穿过所有蓝色数据点 ,直观验证了模型拟合的效果------这说明我们成功找到了二次函数的真实参数!
步骤7:用模型做预测(验证泛化能力)
训练模型的最终目的是"预测未知数据",我们用一个不在训练集中的x值(比如x=5.5),验证模型能否算出正确的y值。
代码实现(带逐行解释)
python
# 1. 定义待预测的x值(比如x=5.5,不在训练集中)
x_new = 5.5
# 2. 构造预测用的特征矩阵(必须和训练时的特征格式一致:x²、x)
# 先计算x_new²,再和x_new拼接成二维数组(模型要求输入是二维)
X_new = np.c_[[x_new ** 2], [x_new]]
# 3. 模型预测
y_pred_new = model.predict(X_new)
# 4. 计算真实值(验证预测是否正确)
y_true_new = 2 * (x_new ** 2) + 3 * x_new + 4
# 5. 打印结果
print("=== 模型预测验证 ===")
print(f"输入x = {x_new}")
print(f"模型预测y = {y_pred_new[0]:.2f}")
print(f"真实y = {y_true_new:.2f}")
print(f"预测误差 = {abs(y_pred_new[0] - y_true_new):.4f}")运行结果
=== 模型预测验证 ===
输入x = 5.5
模型预测y = 82.50
真实y = 82.50
预测误差 = 0.0000关键解释
- 预测的核心要求:待预测的特征格式必须和训练时一致(训练时用了x²和x,预测时也必须传这两个特征)。
- 泛化能力:模型能对"没见过的x值"做出100%准确的预测,说明模型不仅拟合了训练数据,还学到了二次函数的通用规律。
完整流程总结(核心要点)
- 数据生成:按二次函数生成分布合理的训练数据,保证覆盖足够的x范围;
- 可视化判断:通过散点图发现数据是抛物线(二次特征),排除线性模型;
- 特征变形:将x转化为x²和x,把二次函数转化为线性组合形式;
- 模型训练:用线性回归拟合变形后的特征,得到二次函数的三个参数;
- 效果评估:用MAE、MSE、R²客观验证拟合效果,用可视化直观验证;
- 预测验证:用未知数据测试模型,验证泛化能力。
关键技巧回顾
- 处理简单非线性模型(如二次、三次函数)的核心:特征变形(升维),把非线性问题转化为线性问题;
- 建模原则:先可视化,再选模型;先简单,后复杂(二次函数是最简单的非线性模型,掌握后可扩展到更高次);
- 评估原则:主观可视化 + 客观指标,双重验证模型效果,避免单一判断的误差。
这个流程可以直接套用在其他简单非线性函数(比如三次函数 y = ax³ + bx² + cx + d)上,只需要增加特征 x³ 即可,核心逻辑完全一致!