前言
最近有个需求就是将个人数据放到qwen或者豆包这些开放平台去分析时,因为是敏感数据,因此需要本地分析
这个时候本地部署大模型就很重要,笔者前面文章中介绍简单使用集成显卡跑本地LLM大模型的方式,因为是命令行交互,略显简陋
接下来就用一种webui的更加现代的方式,废话不多说,开整
效果展示
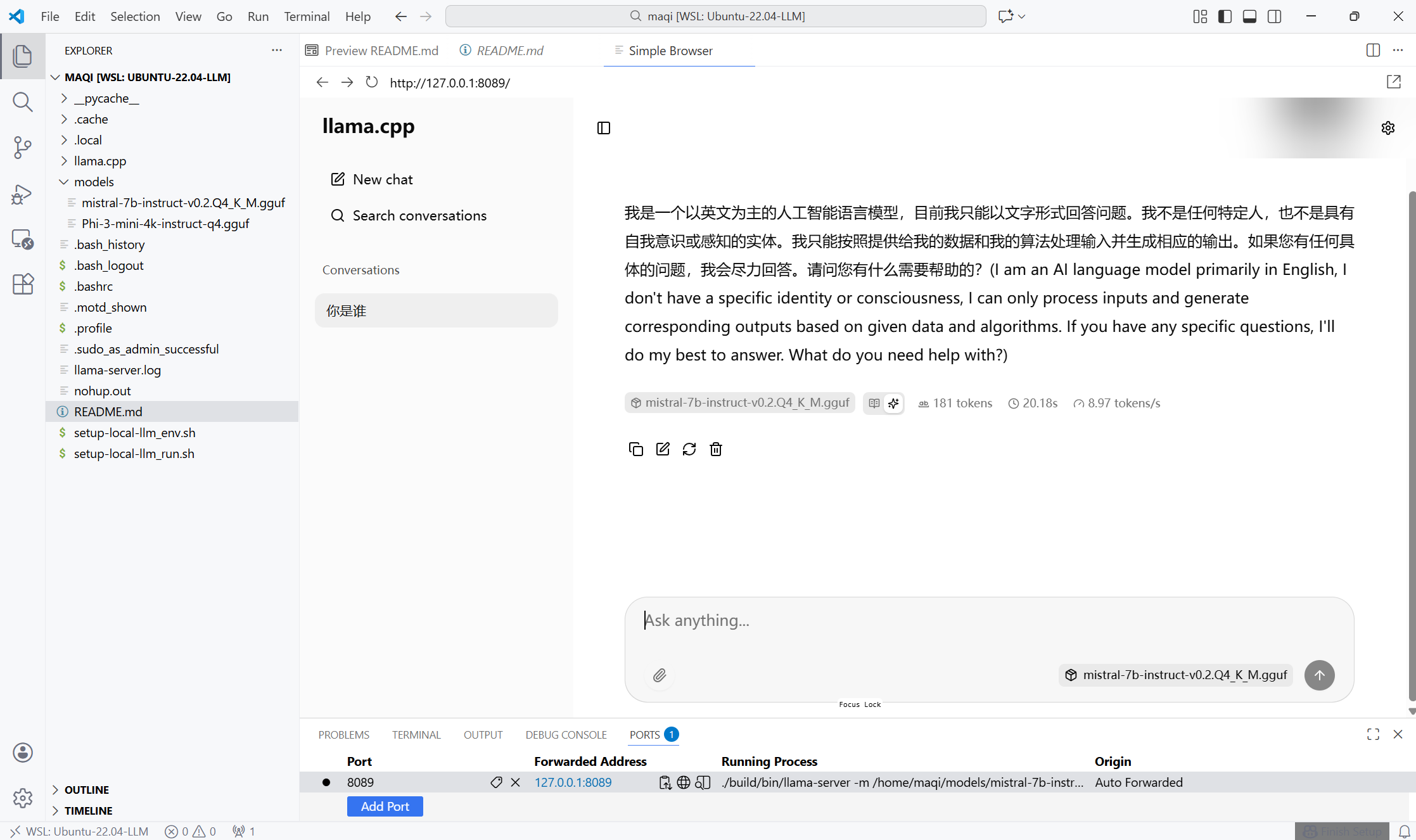
看到这里是不是有点跃跃欲试的感觉
一共分三部
WSL环境准备
- 导入镜像
wsl --import Ubuntu-22.04-LLM D:\Ubuntu-22.04 D:\ubuntu-22.04.tar --version 2 - 镜像列表
bash
PS C:\Users\HiMaq> wsl -l -v
NAME STATE VERSION
* Ubuntu-22.04 Stopped 2
Ubuntu-22.04-Core Stopped 2
Ubuntu-22.04-LLM Running 2- 双击进入WSL
至于不会用docker指令的 建议看下笔者的这篇文章
Docker快速入门(编译源码辅助技)
模型下载和源码下载
啥也别说了,前面的几步略显粗糙,细节还需个人揣摩,时间有限,不做赘述,既然你都进到wsl中,说明你的linux技能还是可以的
setup-local-llm_env.sh
bash
#!/bin/bash
# setup-local-llm.sh
# 在 WSL2 (Ubuntu) 中一键部署本地大模型 Web UI(无 Docker)
# 功能:代码生成 + 中英翻译
# 访问地址:http://localhost:8000
set -e
echo "🚀 开始部署本地大模型环境"
# === 安装系统依赖 ===
echo "🔧 安装系统依赖..."
sudo apt update
sudo apt install -y build-essential git wget cmake python3 python3-pip
sudo apt install -y ninja-build
sudo apt install -y libcurl4-openssl-dev
# ===安装 Python Web 依赖 ===
echo "🐍 安装 Python 依赖..."
pip3 install fastapi uvicorn httpx
# === 克隆并编译 llama.cpp ===
if [ ! -d "llama.cpp" ]; then
echo "📥 克隆 llama.cpp..."
git clone https://github.com/ggerganov/llama.cpp
fi
cd llama.cpp
echo "⚙️ 编译 llama.cpp(启用 AVX2 优化)..."
mkdir build
cd build
# === 配置 CMake(CPU + AVX2 加速)===
cmake .. \
-DCMAKE_BUILD_TYPE=Release \
-DLLAMA_AVX2=ON \
-DLLAMA_NATIVE=OFF \
-DLLAMA_SERVER=ON \
-DLLAMA_TESTS=OFF \
-G Ninja
ninja
# 这里编译没什么大问题的话基本环境就编译完成了
# 准备下载模型
mkdir -p models
cd models运行脚本编写
setup-local-llm_run.sh
bash
#!/bin/bash
# setup-local-llm.sh
# 在 WSL2 (Ubuntu) 中一键部署本地大模型 Web UI(无 Docker)
# === 第3步:下载 Phi-3-mini 模型(Q4_K_M 量化版)===
MODEL_DIR="$HOME/models"
# MODEL_PATH="$MODEL_DIR/Phi-3-mini-4k-instruct-q4.gguf"
# MODEL_PATH="$MODEL_DIR/qwen1_5-4b-chat-q4_k_m.gguf"
MODEL_PATH="$MODEL_DIR/mistral-7b-instruct-v0.2.Q4_K_M.gguf"
mkdir -p "$MODEL_DIR"
# if [ ! -f "$MODEL_PATH" ]; then
# echo "⬇️ 下载 Phi-3-mini 模型(约 2.2GB)..."
# wget -O "$MODEL_PATH" https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf
# else
# echo "✅ 模型已存在:$MODEL_PATH"
# fi
# https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf/resolve/main/Phi-3-mini-4k-instruct-q4.gguf
# https://huggingface.co/Qwen/Qwen1.5-4B-Chat-GGUF/resolve/main/qwen1_5-4b-chat-q4_k_m.gguf
# https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF/resolve/main/mistral-7b-instruct-v0.2.Q4_K_M.gguf
# 确保旧进程已杀掉
ps -A |grep llama-server
pkill -f llama-server
# === 启动服务(后台)===
echo "🧠 启动 llama.cpp 推理服务..."
cd "$HOME/llama.cpp"
# ./build/bin/llama-server \
# -m "$MODEL_PATH" \
# --port 8089 \
# --host 127.0.0.1 \
# -ngl 0 \
# --ctx-size 2048 \
# --n-predict 512 \
# --threads $(nproc) \
# --batch-size 512 \
nohup ./build/bin/llama-server \
-m "$MODEL_PATH" \
--port 8089 \
--host 127.0.0.1 \
-ngl 0 \
--ctx-size 2048 \
--n-predict 512 \
--threads $(nproc) \
--batch-size 512 \
> ~/llama-server.log 2>&1 &麻雀虽小五脏俱全,脚本中包含
- 模型切换
- token配置
- 后台启动模式
- 端口修改
- 模型下载选择
- 进程截杀
现在手动点开 http://127.0.0.1:8089/
做完这些是不是对模型的部署的理解又清晰了一些呢?