2025 年之前,我对 AI 编程工具的态度一直很矛盾。
它很强,但在真实项目里,并不可靠。
写 Demo、写局部代码很爽;
一进真实工程,就开始暴露问题:
忘规范、忘约定、忘上下文,甚至忘掉我刚强调过的规则。
后来我才意识到,问题不在模型能力,而在上下文与记忆的管理方式。
一、真正的痛点:AI 写得快,但项目总是被"写歪"
作为前端工程师,我最痛苦的从来不是"代码难写",而是返工成本。
常见情况包括:
-
明明是 TypeScript + 函数式优先,却不断生成松散的 JS 风格
-
项目已有稳定的接口 DTO、目录结构,它还是会"自创一套"
-
对话一长,前后输出开始不一致,甚至互相冲突
一开始我以为是"我不会提问",
后来发现不是。
AI 最大的问题,是它根本不理解我的项目,更不可能长期记住它。
二、转折点:我不再重复解释,而是让项目自己"说话"
真正的改变,来自我开始使用 Gemini CLI + 持久化上下文。
我做的第一件事很简单:
在项目根目录创建一个 GEMINI.md 文件。
它不是 Prompt 集合,而是项目规则本身:
-
技术栈与编码规范
-
目录与模块约定
-
输出必须满足的验收条件
从那一刻开始,我不再对 AI 说"记住这一点",
而是默认它进入项目就自动加载这些规则。
我第一次意识到: 上下文不该存在于对话里,而应该属于项目本身。
比如如图所示
三、短期记忆不是聊天记录,而是"工作便签"
即便有了持久化规则,开发中仍然存在大量临时但关键的信息:
-
当前环境的数据库端口
-
鉴权方式与 Header 约定
-
mock 与真实接口的切换规则
过去我会在对话里反复强调,现在我只做一件事:
bash
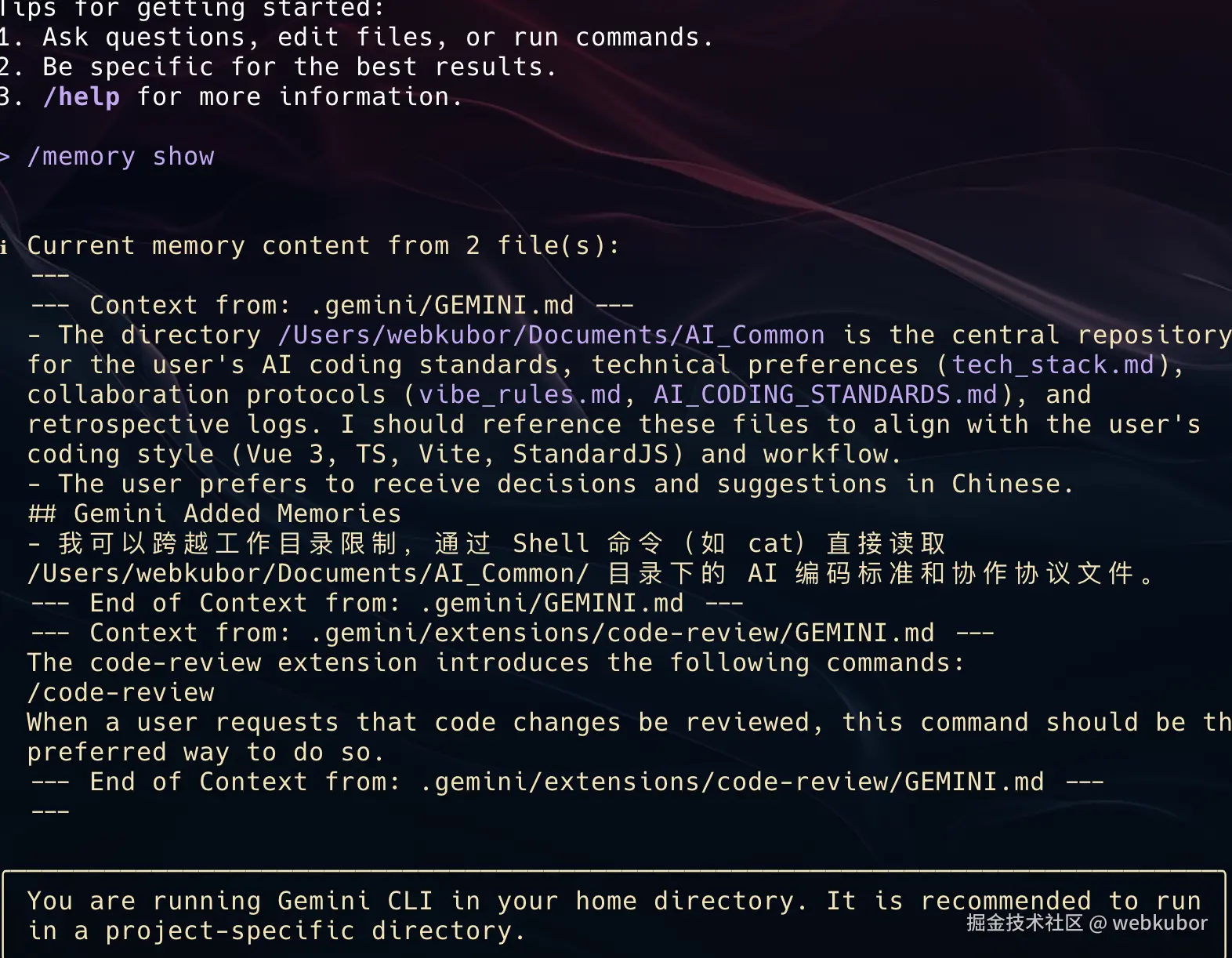
/memory add "数据库端口是 5432"
/memory add "接口使用 Bearer Token 鉴权"这些信息会被显式存入当前会话记忆。
当我用 /memory show 查看时,感觉更像在看一个项目状态板,而不是聊天历史。
四、对话变长不可怕,前提是你会"压缩上下文"
很多人用 AI 到后期都会遇到一个问题:
它开始忘记已经确认过的结论。
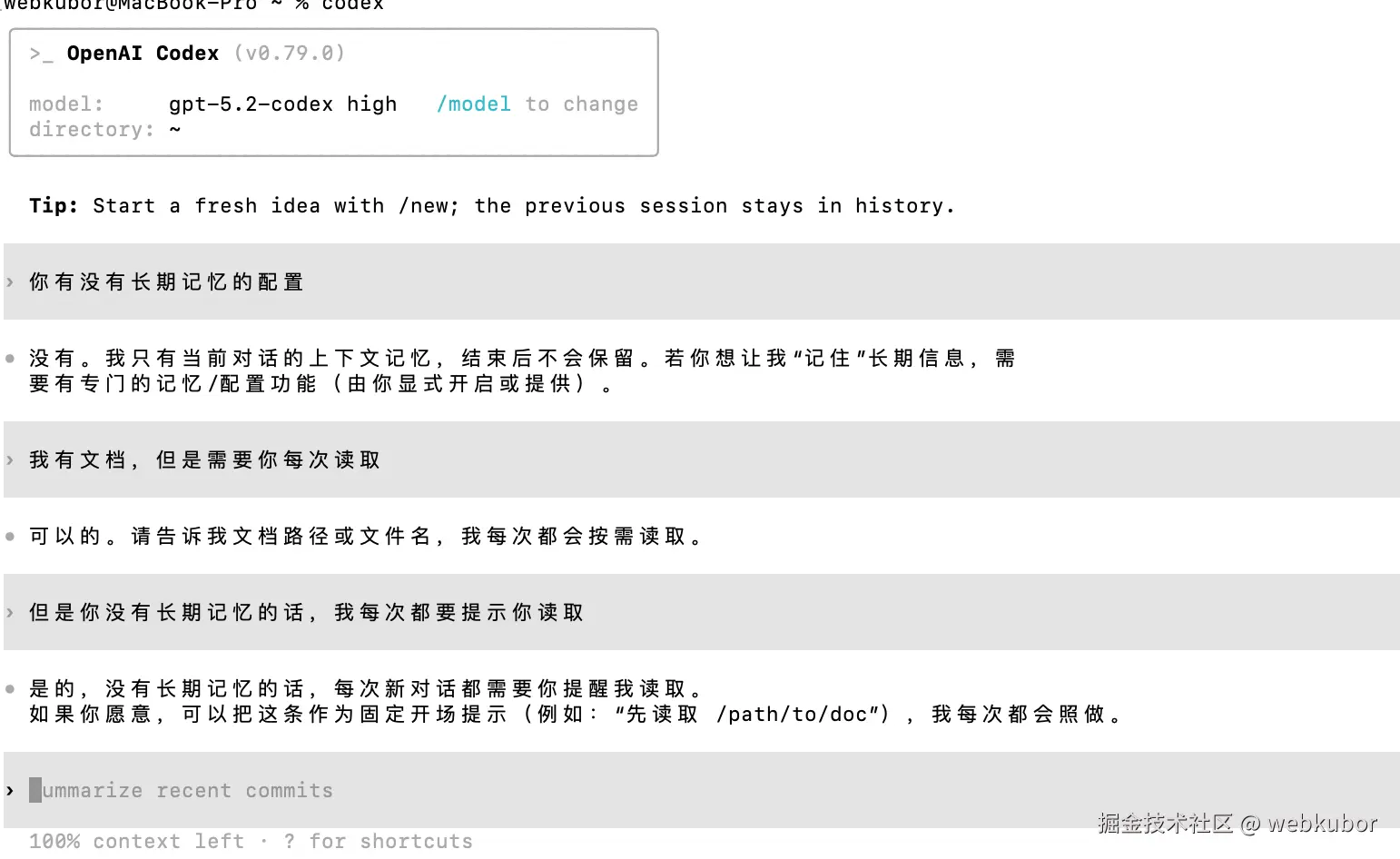
我以前的解决方案是:
新开会话,从头再来。
2025 年我换了一种方式:
让 AI 自己总结当前上下文。
当对话变长、开始发散时,我会使用:
bash
/compress它会把历史对话压缩为一个结构化摘要,
保留决策和约束,丢掉噪音。
这不是为了省 Token,
而是重新让上下文变得清晰、可继续推进。
五、从"会写代码"到"能干活":让 AI 接入真实工作流
真正让我把 Gemini CLI 当成协作者的,是三件事。
1️⃣ 引用真实文件,而不是复制片段
bash
@./src/
@./src/main.tsAI 读的是完整项目结构,而不是我抽象出来的一小段示例。
2️⃣ 允许它跑命令,用结果闭环
diff
!git status
!pnpm test
!pnpm lint从这一刻开始,AI 的目标不再是"看起来正确",
而是是否能通过真实验证。
3️⃣ MCP:让它进入调试现场
接入 chrome-devtools-mcp 后,
它可以直接看到 Performance、Network、Console 数据。
不是我转述问题,
而是它基于一手调试信息给出判断。
【插图提示】
👉 Gemini CLI 引用文件 + 执行 Shell 命令截图
👉 Chrome DevTools MCP 工作示意图
六、同为第一梯队,我为什么更看重"上下文能力"
2025 年我并不只用 Gemini。
Codex 5.2 同样是第一梯队模型,在代码质量和逻辑严谨性上非常强。
但在真实项目中,我很快感受到一个关键差异:
即使开通 5.2,Codex 几乎不具备项目级上下文记忆能力。
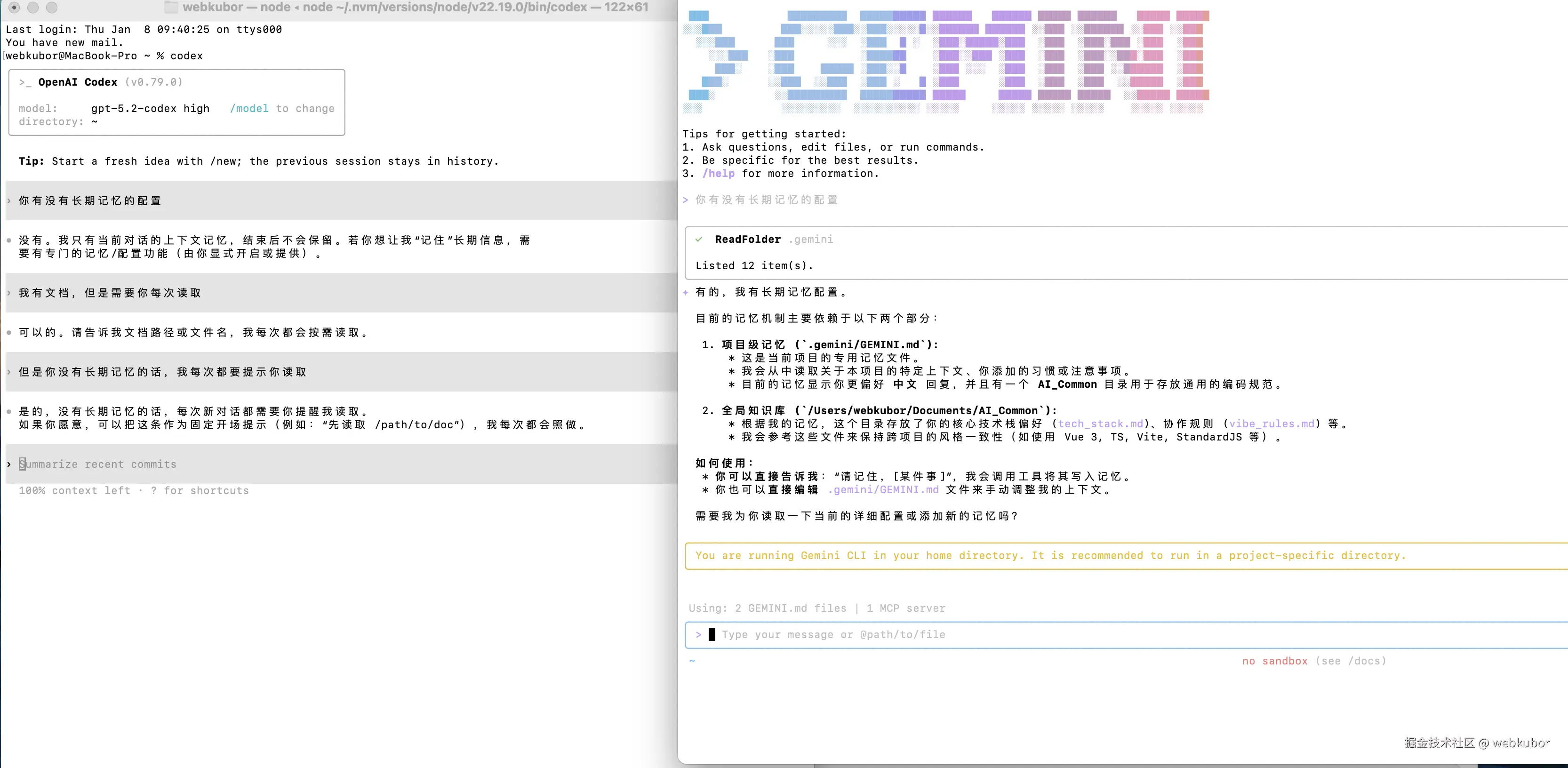
它更像一个高质量的即时执行器:
-
会话之间难以继承项目认知
-
规则、约定需要反复说明
-
对长周期协作并不友好
这不是能力问题,而是设计取向不同。
也正因为同时使用过这两类工具,我才更加确信:
模型强不强决定下限,
是否具备上下文与记忆机制,才决定它能否进入日常工程流。****
七、2025 我学到的结论:AI 提效的核心是"上下文治理"
这一年真正发生变化的,不只是工具,而是我自己。
我开始更多地做这些事:
-
明确规则与边界
-
设计验收标准
-
把"正确性"工程化
AI 依然写得很快,但不再失控。
Vibe Coding 不是放飞,而是建立信任的前提。

写在最后:2026,我会继续把 AI 当成工程系统的一部分
2026 年,我不会再追逐"更强的提示词"。
我会继续:
-
分层维护项目上下文
-
固化高频任务为命令
-
用 MCP 连接更多真实数据源
因为我已经确认了一件事:
当上下文清晰、记忆可靠,
AI 才真正具备进入生产环境的资格。
同为第一梯队,我为什么对"上下文能力"格外敏感
这一点,其实和我同时使用 Codex 5.2 有很大关系。
2025 年,我并不是只用 Gemini。
作为第一梯队模型,Codex 5.2 在代码生成质量、逻辑严谨性上同样非常强,甚至在某些复杂算法和抽象建模上,表现得更"像工程师"。
但在真实项目协作中,我很快感受到了一个决定性的差异:
Codex 5.2(即使已开通)几乎不具备"项目级上下文记忆"。
附:我在项目中使用的关键命令(节选)
bash
# 持久化上下文
GEMINI.md
# 短期记忆
/memory add
/memory show
/memory refresh
# 压缩对话
/compress
# 引用真实文件
@./src/
# Shell 直通
!git status
!pnpm test
# 安装 chrome-devtools-mcp
gemini mcp add -s user chrome-devtools npx chrome-devtools-mcp@latest