前言
🌐 在线演示 : mvp-ai-wllama.vercel.app/
🔗 GitHub仓库 : mvp-ai-wllama
说实话,第一次听说要在浏览器里跑大语言模型的时候,我的第一反应是:这怎么可能?不是需要 GPU 服务器吗?不是需要后端 API 吗?
但事实证明,wllama 的出现,真的让这一切变成了可能。于是就有了这个项目------一个完全在浏览器里运行的 AI 推理方案,不需要服务器,不需要后端,打开网页就能用。
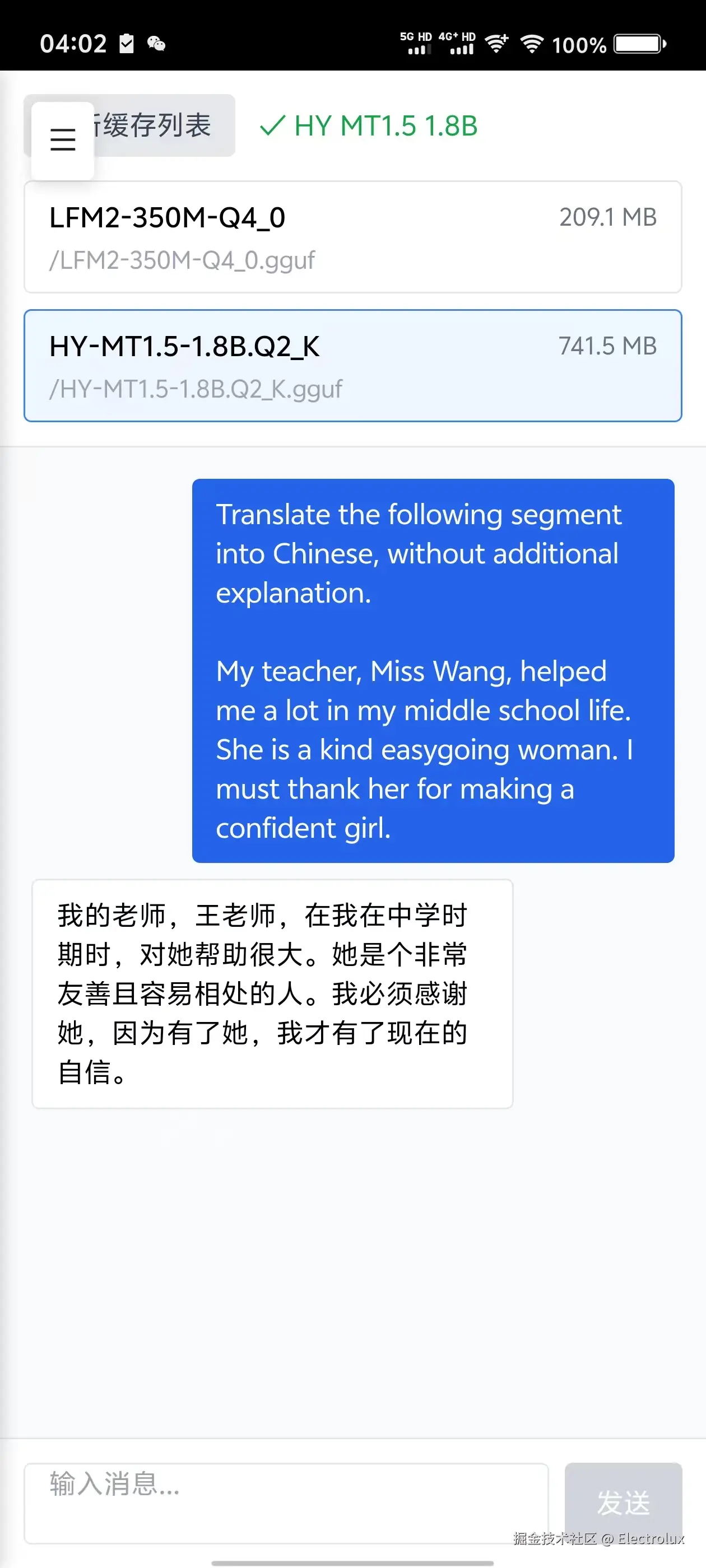
腾讯混元翻译模型示例
作为实际应用示例,本项目支持加载和运行 腾讯混元翻译模型(HY-MT1.5-1.8B-GGUF),这是一个专为多语言翻译任务设计的轻量级模型
模型特点:
- 🌍 多语言支持:支持 36 种语言的翻译任务
- 💬 对话式翻译:采用对话式交互,提供更自然的翻译体验
- 📦 多种量化版本:提供从 Q2_K(777MB)到 f16(3.59GB)的多种量化版本,满足不同性能和精度需求
- ⚡ 轻量高效:1.8B 参数量,在保证翻译质量的同时,大幅降低了计算和存储需求
量化版本选择建议:
- Q2_K(777MB):适合快速测试和资源受限环境
- Q4_K_M(1.13GB):平衡质量和性能的推荐选择
- Q5_K_M(1.3GB):更高精度的翻译质量
- Q8_0(1.91GB):接近原始精度的最佳选择
step1: 下载模型
step2: 打开 mvp-ai-wllama.vercel.app/wllama/mana... 导入模型, 在 mvp-ai-wllama.vercel.app/wllama/load... 中就可以直接使用了(无视框架,只要能执行js就能够调用)
效果展示
所有操作均在浏览器进行,先来看看最终效果:
为什么要做这个
传统的 AI 模型推理,你懂的:
- 得搞个 GPU 服务器,成本不低
- 后端服务部署,运维头疼
- 数据要传到服务器,隐私总让人担心
- 持续的服务成本,小项目根本玩不起
而浏览器端推理就不一样了:
- 用户的电脑就是"服务器",零成本
- 数据完全本地处理,隐私安全
- 离线也能用,体验更好
- 部署简单,一个静态页面就能搞定
所以,为什么不试试呢?
核心功能演示
- ✅ 本地模型加载:支持从本地文件直接加载 GGUF 模型
- ✅ 远程模型下载:从 URL 下载模型并自动缓存到 IndexedDB
- ✅ 缓存管理:完整的模型缓存管理系统,支持导入、导出、删除
- ✅ 流式生成:实时流式输出 AI 生成内容
- ✅ 多线程支持:自动检测并使用多线程模式提升性能
- ✅ 多实例支持:支持同时运行多个独立的模型实例,每个实例可加载不同模型
- ✅ 参数持久化:推理参数自动保存到 localStorage
- ✅ 事件驱动:完整的事件系统,支持监听模型加载、生成等事件
- ✅ 类型安全:完整的 TypeScript 类型定义
- ✅ PWA 支持:完整的渐进式 Web 应用支持,可安装到设备,支持离线使用
技术架构
核心技术栈
- React 19 + Next.js 15:现代化前端框架
- @wllama/wllama:基于 WebAssembly 的 Llama 模型运行时
- WebAssembly (WASM):高性能模型推理引擎
- TypeScript:类型安全的开发体验
- IndexedDB:模型文件缓存系统
- EventEmitter:事件驱动的架构设计
- localStorage:推理参数持久化存储
tip: 事实上核心库 wllama-core 不依赖于 React,你可以拿到项目中的 src/wllama-core,然后接入到任何系统中去,接入层可以参考 src/app/wllama/load-from-file/page.tsx 等应用层文件
架构流程图
python
用户选择模型
↓
React组件层
↓
WllamaCore (核心封装层)
↓
@wllama/wllama (WASM运行时)
↓
WebAssembly引擎
↓
GGUF模型文件
↓
IndexedDB缓存
↓
流式生成输出WASM模型推理核心流程
模型加载流程图解
markdown
用户选择模型文件/URL
↓
检查缓存(如从URL加载)
↓
缓存命中 → 从IndexedDB读取
缓存未命中 → 下载/读取文件
↓
加载到WASM内存
↓
初始化模型参数
↓
模型就绪,可开始推理核心代码实现
typescript
// src/wllama-core/wllama-core.ts
/**
* WllamaCore - 核心封装类,提供简洁的API
*/
export class WllamaCore {
private wllama: Wllama;
private isModelLoaded: boolean = false;
private inferenceParams: InferenceParams;
/**
* 从文件加载模型
*/
async loadModelFromFiles(
files: File[],
options?: LoadModelOptions
): Promise<void> {
if (this.isModelLoaded || this.isGenerating) {
throw new Error('Another model is already loaded or generation is in progress');
}
this.emit(WllamaCoreEvent.MODEL_LOADING);
try {
const loadOptions = {
n_ctx: options?.n_ctx ?? this.inferenceParams.nContext,
n_batch: options?.n_batch ?? this.inferenceParams.nBatch,
n_threads: options?.n_threads ?? (this.inferenceParams.nThreads > 0
? this.inferenceParams.nThreads
: undefined),
};
await this.wllama.loadModel(files, loadOptions);
// 获取模型元数据
const metadata = this.wllama.getModelMetadata();
this.modelMetadata = {
name: metadata.meta['general.name'] ||
metadata.meta['llama.context_length'] ||
files[0].name.replace('.gguf', ''),
...metadata.meta,
};
this.isModelLoaded = true;
this.emit(WllamaCoreEvent.MODEL_LOADED, {
metadata: this.modelMetadata,
runtimeInfo: this.runtimeInfo,
});
} catch (error) {
this.resetInstance();
const errorMsg = (error as Error)?.message ?? 'Unknown error';
this.emit(WllamaCoreEvent.ERROR, errorMsg);
throw new Error(errorMsg);
}
}
/**
* 从URL加载模型(支持自动缓存)
*/
async loadModelFromUrl(
url: string,
options?: LoadModelOptions & {
useCache?: boolean;
downloadOptions?: DownloadOptions;
}
): Promise<void> {
const useCache = options?.useCache !== false; // 默认启用缓存
try {
let file: File;
// 检查缓存
if (useCache) {
const cachedFile = await cacheManager.open(url);
if (cachedFile) {
this.logger?.log('Loading model from cache:', url);
file = cachedFile;
} else {
// 下载并缓存
this.logger?.log('Downloading and caching model:', url);
await cacheManager.download(url, options?.downloadOptions);
const downloadedFile = await cacheManager.open(url);
if (!downloadedFile) {
throw new Error('Failed to open cached file after download');
}
file = downloadedFile;
}
} else {
// 直接下载,不使用缓存
const response = await fetch(url, {
headers: options?.downloadOptions?.headers,
signal: options?.downloadOptions?.signal,
});
const blob = await response.blob();
const fileName = url.split('/').pop() || 'model.gguf';
file = new File([blob], fileName, { type: 'application/octet-stream' });
}
await this.loadModelFromFiles([file], options);
} catch (error) {
// 错误处理...
}
}
}缓存管理系统:IndexedDB实现
项目采用 IndexedDB 实现模型文件的持久化缓存,支持大文件存储和快速检索:
typescript
// src/wllama-core/cache-manager.ts
/**
* CacheManager - 基于 IndexedDB 的缓存管理器
*/
export class CacheManager {
/**
* 从URL下载并缓存模型文件
*/
async download(url: string, options: DownloadOptions = {}): Promise<void> {
const filename = await urlToFileName(url);
const response = await fetch(url, {
headers: options.headers,
signal: options.signal,
});
if (!response.ok) {
throw new Error(`Failed to fetch: ${response.statusText}`);
}
// 流式读取并显示进度
const reader = response.body.getReader();
const chunks: Uint8Array[] = [];
let loaded = 0;
const contentLength = response.headers.get('content-length');
const total = contentLength ? parseInt(contentLength, 10) : 0;
while (true) {
const { done, value } = await reader.read();
if (done) break;
chunks.push(value);
loaded += value.length;
if (options.progressCallback && total > 0) {
options.progressCallback({ loaded, total });
}
}
const blob = new Blob(chunks as BlobPart[]);
const db = await getDB();
// 存储到 IndexedDB
const cachedFile: CachedFile = {
blob,
originalURL: url,
createdAt: Date.now(),
etag: response.headers.get('etag') || undefined,
contentType: response.headers.get('content-type') || undefined,
};
return new Promise((resolve, reject) => {
const transaction = db.transaction([STORE_FILES], 'readwrite');
const fileStore = transaction.objectStore(STORE_FILES);
fileStore.put(cachedFile, filename);
transaction.oncomplete = () => resolve();
transaction.onerror = () => reject(transaction.error);
});
}
/**
* 从缓存打开文件
*/
async open(nameOrURL: string): Promise<File | null> {
const db = await getDB();
let fileName = nameOrURL;
// 尝试直接使用名称
try {
const file = await this.getFileFromDB(db, fileName);
if (file) return file;
} catch {
// 尝试将URL转换为文件名
try {
fileName = await urlToFileName(nameOrURL);
const file = await this.getFileFromDB(db, fileName);
if (file) return file;
} catch {
return null;
}
}
return null;
}
/**
* 列出所有缓存文件
*/
async list(): Promise<CacheEntry[]> {
const db = await getDB();
const allFiles = await this.getAllFiles(db);
const result: CacheEntry[] = [];
for (const [fileName, cachedFile] of Object.entries(allFiles)) {
const metadata: CacheEntryMetadata = {
originalURL: cachedFile.originalURL || fileName,
};
// 复制其他元数据字段
Object.keys(cachedFile).forEach(key => {
if (key !== 'blob' && key !== 'originalURL') {
metadata[key] = (cachedFile as any)[key];
}
});
result.push({
name: fileName,
size: cachedFile.blob.size,
metadata,
});
}
return result;
}
}关键特性:
- URL哈希映射:使用 SHA-1 哈希将 URL 转换为唯一文件名
- 进度回调:支持下载进度实时反馈
- 元数据扩展:可扩展的元数据结构,支持 ETag、创建时间等
- 浏览器兼容:支持所有现代浏览器,包括较旧版本
事件驱动架构:EventEmitter设计
项目采用事件系统,实现组件间的松耦合通信:
typescript
// src/wllama-core/wllama-core.ts
export enum WllamaCoreEvent {
MODEL_LOADING = 'model_loading', // 模型加载中
MODEL_LOADED = 'model_loaded', // 模型加载完成
MODEL_UNLOADED = 'model_unloaded', // 模型已卸载
GENERATION_START = 'generation_start', // 生成开始
GENERATION_UPDATE = 'generation_update', // 生成更新
GENERATION_END = 'generation_end', // 生成结束
ERROR = 'error', // 错误
}
export class WllamaCore {
private eventListeners: Map<WllamaCoreEvent, Set<EventListener>> = new Map();
/**
* 注册事件监听器
*/
on(event: WllamaCoreEvent, listener: EventListener) {
if (!this.eventListeners.has(event)) {
this.eventListeners.set(event, new Set());
}
this.eventListeners.get(event)!.add(listener);
}
/**
* 移除事件监听器
*/
off(event: WllamaCoreEvent, listener: EventListener) {
this.eventListeners.get(event)?.delete(listener);
}
/**
* 触发事件
*/
private emit(event: WllamaCoreEvent, data?: unknown) {
const listeners = this.eventListeners.get(event);
if (listeners) {
listeners.forEach((listener) => listener(data));
}
}
}支持的事件类型
model_loading- 模型加载中model_loaded- 模型加载完成model_unloaded- 模型已卸载generation_start- 生成开始generation_update- 生成更新(流式输出)generation_end- 生成结束error- 错误事件
多实例事件系统
在多实例模式下,所有事件数据都包含 instanceId 字段,用于区分不同实例的事件:
typescript
// 监听特定实例的事件
instance1.on(WllamaCoreEvent.MODEL_LOADED, (data: any) => {
console.log('实例1模型已加载:', data.instanceId);
console.log('模型元数据:', data.metadata);
});
// 监听所有实例的事件,通过 instanceId 区分
const handleUpdate = (data: { data: string; instanceId: string }) => {
if (data.instanceId === 'chat-1') {
console.log('聊天1更新:', data.data);
} else if (data.instanceId === 'chat-2') {
console.log('聊天2更新:', data.data);
}
};
instance1.on(WllamaCoreEvent.GENERATION_UPDATE, handleUpdate);
instance2.on(WllamaCoreEvent.GENERATION_UPDATE, handleUpdate);事件数据结构:
typescript
// 所有事件数据都包含 instanceId
interface BaseEventData {
instanceId: string;
}
// 模型加载事件
interface ModelLoadedEventData extends BaseEventData {
metadata: ModelMetadata;
runtimeInfo: RuntimeInfo;
}
// 生成更新事件
interface GenerationUpdateEventData extends BaseEventData {
data: string;
}核心功能特性
1. 多种模型加载方式
支持三种模型加载方式,满足不同使用场景:
typescript
import { WllamaCore, WLLAMA_CONFIG_PATHS } from '@/wllama-core';
const wllamaCore = new WllamaCore({ paths: WLLAMA_CONFIG_PATHS });
// 方式1: 从本地文件加载
const files = [/* File 对象 */];
await wllamaCore.loadModelFromFiles(files, {
n_ctx: 4096,
n_batch: 128,
});
// 方式2: 从URL加载(自动缓存)
await wllamaCore.loadModelFromUrl('https://example.com/model.gguf', {
n_ctx: 4096,
useCache: true, // 默认启用
downloadOptions: {
progressCallback: (progress) => {
console.log(`下载进度: ${progress.loaded}/${progress.total}`);
},
},
});
// 方式3: 从缓存加载
import { cacheManager } from '@/wllama-core';
const cachedFile = await cacheManager.open('https://example.com/model.gguf');
if (cachedFile) {
await wllamaCore.loadModelFromFiles([cachedFile], { n_ctx: 4096 });
}2. 流式生成支持
支持实时流式输出,提供流畅的用户体验:
typescript
const result = await wllamaCore.createChatCompletion(messages, {
nPredict: 4096,
useCache: true,
sampling: { temp: 0.2 },
onNewToken(token, piece, currentText, opts) {
// 实时更新UI
setMessages(prev => {
const updated = [...prev];
updated[updated.length - 1].content = currentText;
return updated;
});
// 可以随时停止生成
// opts.abortSignal();
},
});3. 参数持久化
推理参数自动保存到 localStorage,下次使用时自动恢复:
typescript
// 设置参数(自动保存)
wllamaCore.setInferenceParams({
nContext: 8192,
temperature: 0.7,
nPredict: 2048,
});
// 获取参数
const params = wllamaCore.getInferenceParams();
console.log(params);
// {
// nThreads: -1,
// nContext: 8192,
// nBatch: 128,
// temperature: 0.7,
// nPredict: 2048
// }4. 多线程支持
自动检测并使用多线程模式,大幅提升推理性能:
typescript
// src/middleware.ts
export function middleware(request: NextRequest) {
const response = NextResponse.next();
// 启用 SharedArrayBuffer 支持(多线程所需)
response.headers.set('Cross-Origin-Opener-Policy', 'same-origin');
response.headers.set('Cross-Origin-Embedder-Policy', 'require-corp');
return response;
}注意事项:
- 必须在 HTTPS 环境下运行(或 localhost)
- 需要浏览器支持 SharedArrayBuffer
- 设置响应头后需要重启开发服务器
5. 多实例支持
支持创建和管理多个独立的 WllamaCore 实例,每个实例可以加载不同的模型,独立进行推理:
typescript
import { wllamaCoreFactory, WLLAMA_CONFIG_PATHS, Message, WllamaCoreEvent } from '@/wllama-core';
// 创建多个实例
const instance1 = wllamaCoreFactory.getOrCreate('chat-1', { paths: WLLAMA_CONFIG_PATHS });
const instance2 = wllamaCoreFactory.getOrCreate('chat-2', { paths: WLLAMA_CONFIG_PATHS });
// 每个实例可以加载不同的模型
await instance1.loadModelFromUrl('https://example.com/model1.gguf');
await instance2.loadModelFromUrl('https://example.com/model2.gguf');
// 独立进行推理
const messages1: Message[] = [{ role: 'user', content: '你好' }];
const messages2: Message[] = [{ role: 'user', content: 'Hello' }];
const [result1, result2] = await Promise.all([
instance1.createChatCompletion(messages1),
instance2.createChatCompletion(messages2),
]);
// 监听不同实例的事件(事件数据包含 instanceId)
instance1.on(WllamaCoreEvent.MODEL_LOADED, (data: any) => {
console.log('实例1模型已加载:', data.instanceId);
});
instance2.on(WllamaCoreEvent.GENERATION_UPDATE, (data: any) => {
console.log('实例2生成更新:', data.data, '实例ID:', data.instanceId);
});
// 获取所有实例
const allInstances = wllamaCoreFactory.getAll();
console.log(`当前有 ${allInstances.size} 个实例`);
// 销毁指定实例
await wllamaCoreFactory.destroy('chat-1');
// 销毁所有实例
await wllamaCoreFactory.destroyAll();关键特性:
- 实例隔离 :每个实例的推理参数存储在独立的 localStorage 键中(格式:
params-{instanceId}) - 事件隔离 :每个实例的事件监听器独立,事件数据包含
instanceId用于区分 - 资源管理:通过工厂类统一管理所有实例,支持获取、创建、销毁等操作
- 向后兼容 :原有的直接创建
WllamaCore实例的方式仍然支持
6. PWA 支持
项目完整支持渐进式 Web 应用(PWA),用户可以像原生应用一样安装和使用:
核心特性:
- 可安装性:支持添加到主屏幕,提供原生应用体验
- 离线支持:通过 Service Worker 实现离线访问
- 智能缓存:自动缓存应用资源,提升加载速度
- 自动更新:Service Worker 自动检测并更新应用
manifest.json 配置:
json
{
"name": "MVP AI Wllama",
"short_name": "Wllama",
"description": "AI Wllama Application",
"start_url": "/",
"display": "standalone",
"background_color": "#ffffff",
"theme_color": "#000000",
"orientation": "portrait-primary",
"icons": [
{
"src": "/icon-192.png",
"sizes": "192x192",
"type": "image/png",
"purpose": "any maskable"
},
{
"src": "/icon-512.png",
"sizes": "512x512",
"type": "image/png",
"purpose": "any maskable"
}
]
}Service Worker 实现:
项目实现了智能的 Service Worker,支持:
- 资源缓存:自动缓存应用页面和静态资源
- 离线回退:网络不可用时使用缓存内容
- 后台更新:后台自动更新缓存,不阻塞用户操作
- 快速失败:网络请求超时快速失败,避免长时间等待
typescript
// public/sw.js
const CACHE_NAME = 'wllama-cache-v1';
// 安装时立即激活
self.addEventListener('install', () => self.skipWaiting());
// 激活时清理旧缓存
self.addEventListener('activate', (event) => {
event.waitUntil(
caches.keys().then((names) =>
Promise.all(names.filter((n) => n !== CACHE_NAME).map((n) => caches.delete(n)))
).then(() => self.clients.claim())
);
});
// 拦截网络请求,实现缓存策略
self.addEventListener('fetch', (event) => {
// 缓存优先策略:优先使用缓存,后台更新
event.respondWith(
(async () => {
const cache = await caches.open(CACHE_NAME);
const cached = await cache.match(event.request);
if (cached) {
// 有缓存:立即返回,后台更新
event.waitUntil(
fetch(event.request).then((res) => {
if (res?.status === 200) {
return cache.put(event.request, res.clone());
}
}).catch(() => {})
);
return cached;
}
// 无缓存:网络请求
try {
const res = await fetch(event.request);
if (res?.status === 200) {
event.waitUntil(cache.put(event.request, res.clone()));
}
return res;
} catch {
// 网络失败:返回缓存或空响应
return cached || new Response('', { status: 503 });
}
})()
);
});Service Worker 管理:
项目提供了智能的 Service Worker 管理组件,只在 PWA 环境下注册:
typescript
// src/components/ServiceWorkerManager.tsx
export default function ServiceWorkerManager({ swPath = '/sw.js' }) {
useEffect(() => {
if (!('serviceWorker' in navigator)) return;
const isPWA = () => {
return window.matchMedia('(display-mode: standalone)').matches ||
window.matchMedia('(display-mode: minimal-ui)').matches ||
(window.navigator as any).standalone === true;
};
const checkAndManageSW = async () => {
const existingReg = await navigator.serviceWorker.getRegistration();
const currentIsPWA = isPWA();
// 只在 PWA 环境注册 Service Worker
if (currentIsPWA && !existingReg) {
const reg = await navigator.serviceWorker.register(swPath);
console.log('Service Worker 注册成功(PWA 环境)');
} else if (!currentIsPWA && existingReg) {
// 不在 PWA 环境时卸载
await existingReg.unregister();
const cacheNames = await caches.keys();
await Promise.all(cacheNames.map(name => caches.delete(name)));
}
};
checkAndManageSW();
}, [swPath]);
}使用方式:
-
安装应用:
- 在支持的浏览器中访问应用
- 浏览器会显示"添加到主屏幕"提示
- 点击安装后,应用会像原生应用一样运行
-
离线使用:
- 安装后,应用的核心功能可以在离线状态下使用
- Service Worker 会自动缓存访问过的页面
- 模型文件存储在 IndexedDB 中,离线时仍可使用
-
自动更新:
- Service Worker 会自动检测新版本
- 后台更新缓存,不影响当前使用
- 下次打开应用时会使用新版本
注意事项:
- PWA 功能需要在 HTTPS 环境下运行(或 localhost)
- Service Worker 只在 PWA 模式下注册,避免在普通浏览器中占用资源
- 模型文件缓存使用 IndexedDB,与 Service Worker 缓存分离
- 支持手动卸载 Service Worker(通过 ServiceWorkerUninstall 组件)
7. 缓存管理功能
完整的缓存管理系统,支持导入、导出、删除等操作:
typescript
import { cacheManager, toHumanReadableSize } from '@/wllama-core';
// 列出所有缓存文件
const entries = await cacheManager.list();
console.log(`缓存文件数: ${entries.length}`);
entries.forEach(entry => {
console.log(`${entry.metadata.originalURL || entry.name}: ${toHumanReadableSize(entry.size)}`);
});
// 获取缓存总大小
const totalSize = entries.reduce((sum, entry) => sum + entry.size, 0);
console.log(`总大小: ${toHumanReadableSize(totalSize)}`);
// 删除特定文件
await cacheManager.delete('https://example.com/model.gguf');
// 清空所有缓存
await cacheManager.clear();
// 从文件导入到缓存
const fileInput = document.querySelector('input[type="file"]') as HTMLInputElement;
const file = fileInput.files?.[0];
if (file) {
await cacheManager.write(`/${file.name}`, file, {
etag: '',
originalSize: file.size,
originalURL: `/${file.name}`,
});
}使用示例
基本使用(React组件)
typescript
// src/app/wllama/load-from-file/page.tsx
"use client"
import { useState, useRef, useEffect } from 'react';
import { WllamaCore, Message, WLLAMA_CONFIG_PATHS } from '@/wllama-core';
export default function MinimalExample() {
const [messages, setMessages] = useState<Message[]>([]);
const [input, setInput] = useState('');
const [isModelLoaded, setIsModelLoaded] = useState(false);
const wllamaCoreRef = useRef<WllamaCore | null>(null);
useEffect(() => {
wllamaCoreRef.current = new WllamaCore({ paths: WLLAMA_CONFIG_PATHS });
return () => {
wllamaCoreRef.current?.unloadModel().catch(() => {});
};
}, []);
const loadModel = async (e: React.ChangeEvent<HTMLInputElement>) => {
const files = Array.from(e.target.files || []);
if (!files.length || !wllamaCoreRef.current) return;
try {
await wllamaCoreRef.current.loadModelFromFiles(files, {
n_ctx: 4096,
n_batch: 128
});
setIsModelLoaded(true);
} catch (err) {
console.error('加载失败:', err);
}
};
const send = async () => {
if (!input.trim() || !wllamaCoreRef.current || !isModelLoaded) return;
const userMsg: Message = { role: 'user', content: input.trim() };
const assistantMsg: Message = { role: 'assistant', content: '' };
setMessages((prev) => [...prev, userMsg, assistantMsg]);
setInput('');
try {
const result = await wllamaCoreRef.current.createChatCompletion(
[...messages, userMsg],
{
nPredict: 4096,
useCache: true,
sampling: { temp: 0.2 },
onNewToken(_token, _piece, text) {
setMessages((prev) => {
const updated = [...prev];
if (updated.length > 0 && updated[updated.length - 1].role === 'assistant') {
updated[updated.length - 1].content = text;
}
return updated;
});
},
}
);
} catch (err) {
console.error('生成失败:', err);
}
};
return (
<div>
<input type="file" accept=".gguf" onChange={loadModel} />
{/* UI组件... */}
</div>
);
}从URL加载(自动缓存)
typescript
// 从URL加载模型,自动缓存到IndexedDB
await wllamaCore.loadModelFromUrl('https://example.com/model.gguf', {
n_ctx: 4096,
useCache: true, // 默认启用
downloadOptions: {
progressCallback: (progress) => {
const percent = progress.total > 0
? (progress.loaded / progress.total) * 100
: 0;
console.log(`下载进度: ${percent.toFixed(1)}%`);
},
},
});
// 下次加载时,会自动从缓存读取,无需重新下载
await wllamaCore.loadModelFromUrl('https://example.com/model.gguf', {
n_ctx: 4096,
// useCache: true 是默认值
});事件监听
typescript
wllamaCore.on(WllamaCoreEvent.MODEL_LOADING, () => {
console.log('模型加载中...');
});
wllamaCore.on(WllamaCoreEvent.MODEL_LOADED, (data) => {
const { metadata, runtimeInfo } = data as {
metadata?: ModelMetadata;
runtimeInfo?: RuntimeInfo;
};
console.log('模型已加载:', metadata?.name);
console.log('多线程模式:', runtimeInfo?.isMultithread);
});
wllamaCore.on(WllamaCoreEvent.GENERATION_UPDATE, (text) => {
console.log('生成中:', text as string);
});
wllamaCore.on(WllamaCoreEvent.ERROR, (error) => {
console.error('错误:', error as string);
});多实例使用
使用工厂类创建和管理多个实例:
typescript
import { wllamaCoreFactory, WLLAMA_CONFIG_PATHS, Message, WllamaCoreEvent } from '@/wllama-core';
// 方式1: 使用 getOrCreate(推荐,如果实例已存在则返回现有实例)
const instance1 = wllamaCoreFactory.getOrCreate('chat-1', { paths: WLLAMA_CONFIG_PATHS });
const instance2 = wllamaCoreFactory.getOrCreate('chat-2', { paths: WLLAMA_CONFIG_PATHS });
// 方式2: 使用 create(如果实例已存在会抛出错误)
// const instance1 = wllamaCoreFactory.create({ paths: WLLAMA_CONFIG_PATHS }, 'chat-1');
// 方式3: 使用 getDefault(获取或创建默认实例,向后兼容)
// const defaultInstance = wllamaCoreFactory.getDefault({ paths: WLLAMA_CONFIG_PATHS });
// 加载不同的模型
await instance1.loadModelFromUrl('https://example.com/model1.gguf');
await instance2.loadModelFromUrl('https://example.com/model2.gguf');
// 监听事件(事件数据包含 instanceId)
instance1.on(WllamaCoreEvent.GENERATION_UPDATE, (data: any) => {
if (data.instanceId === 'chat-1') {
console.log('聊天1更新:', data.data);
}
});
instance2.on(WllamaCoreEvent.GENERATION_UPDATE, (data: any) => {
if (data.instanceId === 'chat-2') {
console.log('聊天2更新:', data.data);
}
});
// 同时进行多个对话
const messages1: Message[] = [{ role: 'user', content: '你好' }];
const messages2: Message[] = [{ role: 'user', content: 'Hello' }];
await Promise.all([
instance1.createChatCompletion(messages1),
instance2.createChatCompletion(messages2),
]);
// 获取实例信息
console.log('实例1 ID:', instance1.getInstanceId());
console.log('当前实例数:', wllamaCoreFactory.getInstanceCount());
// 清理
await wllamaCoreFactory.destroy('chat-1');
await wllamaCoreFactory.destroy('chat-2');
// 或清理所有实例
// await wllamaCoreFactory.destroyAll();PWA 安装和使用
项目支持完整的 PWA 功能,用户可以像安装原生应用一样安装:
安装步骤:
-
在桌面浏览器:
- 访问应用后,浏览器地址栏会显示安装图标
- 点击安装图标,选择"安装"
- 应用会添加到桌面,可以独立窗口运行
-
在移动设备:
- iOS Safari:点击分享按钮 → "添加到主屏幕"
- Android Chrome:浏览器会自动显示"添加到主屏幕"横幅
- 安装后,应用会出现在主屏幕上
离线使用:
- 安装后,应用的核心功能可以在离线状态下使用
- 已加载的模型文件存储在 IndexedDB 中,离线时仍可使用
- Service Worker 会缓存访问过的页面,离线时也能浏览
Service Worker 管理:
项目提供了 Service Worker 管理功能,可以通过组件控制:
typescript
// Service Worker 只在 PWA 环境下自动注册
// 可以通过全局方法管理
(window as any).swManager.status(); // 查看状态
(window as any).swManager.unregister(); // 卸载 Service WorkerPWA 配置要点:
manifest.json配置了应用的基本信息、图标和显示模式- Service Worker 实现了智能缓存策略
- 支持自动更新,后台检测新版本
- 只在 PWA 环境下注册,避免在普通浏览器中占用资源
非React环境使用
核心库 wllama-core 不依赖 React,可以在任何 JavaScript/TypeScript 环境中使用:
typescript
// 纯JavaScript/TypeScript环境
import { WllamaCore, WLLAMA_CONFIG_PATHS } from './wllama-core';
const wllamaCore = new WllamaCore({ paths: WLLAMA_CONFIG_PATHS });
// 加载模型
await wllamaCore.loadModelFromFiles(files, { n_ctx: 4096 });
// 生成文本
const result = await wllamaCore.createChatCompletion([
{ role: 'user', content: '你好!' }
], {
nPredict: 4096,
sampling: { temp: 0.2 },
});
console.log(result);项目结构
csharp
mvp-ai-wllama/
├── src/
│ ├── app/ # Next.js 应用页面
│ │ ├── wllama/
│ │ │ ├── load-from-file/ # 从文件加载页面
│ │ │ ├── load-from-url/ # 从URL加载页面
│ │ │ ├── load-from-cache/ # 从缓存加载页面
│ │ │ ├── manager-cache/ # 缓存管理页面
│ │ │ └── multi-instance/ # 多实例演示页面
│ │ └── layout.tsx # 布局组件(包含 PWA manifest 配置)
│ ├── wllama-core/ # 核心库(无React依赖)
│ │ ├── wllama-core.ts # 核心封装类
│ │ ├── wllama-core-factory.ts # 工厂类(多实例管理)
│ │ ├── cache-manager.ts # 缓存管理器
│ │ ├── storage.ts # localStorage工具
│ │ ├── utils.ts # 工具函数
│ │ ├── types.ts # 类型定义
│ │ └── config.ts # 配置
│ └── components/ # React组件
│ ├── StudioLayout/ # 布局组件
│ ├── Loading.tsx # 加载组件
│ ├── ServiceWorkerManager.tsx # Service Worker 管理组件
│ └── ServiceWorkerUninstall.tsx # Service Worker 卸载组件
├── public/
│ ├── manifest.json # PWA 清单文件
│ ├── sw.js # Service Worker 文件
│ ├── icon-192.png # PWA 图标(192x192)
│ ├── icon-512.png # PWA 图标(512x512)
│ └── wasm/
│ └── wllama/
│ ├── multi-thread/ # 多线程WASM
│ └── single-thread/ # 单线程WASM
└── src/middleware.ts # Next.js中间件(多线程支持)部署方案
Vercel一键部署
项目已配置,可直接部署到Vercel:
bash
# 安装依赖
npm install
# 构建项目
npm run build
# Vercel 会自动检测并部署🌐 在线演示 : mvp-ai-wllama.vercel.app/
静态文件部署
项目支持静态导出,构建后的文件可部署到任何静态托管服务:
bash
# 构建静态文件
npm run build
# 输出目录: out/
# 可直接部署到 GitHub Pages、Netlify、Nginx 等多线程支持配置
如需启用多线程支持,需要配置正确的 HTTP 响应头:
typescript
// src/middleware.ts
export function middleware(request: NextRequest) {
const response = NextResponse.next();
// 启用 SharedArrayBuffer 支持
response.headers.set('Cross-Origin-Opener-Policy', 'same-origin');
response.headers.set('Cross-Origin-Embedder-Policy', 'require-corp');
return response;
}注意事项:
- 必须在 HTTPS 环境下运行(或 localhost)
- 需要浏览器支持 SharedArrayBuffer
- 某些CDN可能不支持这些响应头,需要配置
技术优势总结
| 特性 | 传统方案 | 本方案 |
|---|---|---|
| 数据安全 | ❌ 需要上传服务器 | ✅ 完全本地处理 |
| 部署成本 | ❌ 需要后端服务 | ✅ 纯静态部署 |
| 模型格式 | ⚠️ 需要转换 | ✅ 直接支持GGUF格式 |
| 离线使用 | ❌ 需要网络 | ✅ 完全离线 |
| 性能优化 | ⚠️ 依赖网络 | ✅ IndexedDB缓存 + 多线程 |
| 隐私保护 | ⚠️ 数据上传 | ✅ 数据不出浏览器 |
| 参数控制 | ⚠️ 复杂配置 | ✅ 简单API + 自动持久化 |
| 流式输出 | ⚠️ 需要WebSocket | ✅ 原生支持流式生成 |
技术原理
使用WebAssembly运行Llama模型
传统AI模型推理需要:
- 搭建GPU服务器
- 配置CUDA环境
- 处理模型加载和推理
- 管理服务器资源
本方案通过WebAssembly技术:
- 在浏览器中直接运行Llama模型推理
- 使用WASM实现高性能计算
- 完全客户端化,无需服务器
- 支持多线程加速(SharedArrayBuffer)
GGUF模型格式
GGUF(GPT-Generated Unified Format)是专门为Llama模型设计的格式:
- 量化支持:支持多种量化级别(Q4_K_M, Q8_0等)
- 快速加载:优化的文件结构,加载速度快
- 内存效率:量化后模型体积大幅减小
- 跨平台:统一的格式,跨平台兼容
IndexedDB缓存机制
- 持久化存储:模型文件存储在浏览器IndexedDB中,关闭浏览器后仍保留
- URL映射:使用SHA-1哈希将URL映射为唯一文件名
- 进度追踪:支持下载进度实时反馈
- 元数据扩展:可扩展的元数据结构,支持ETag、创建时间等
多线程加速原理
- SharedArrayBuffer:允许多个Web Worker共享内存
- 自动检测:自动检测浏览器是否支持多线程
- 性能提升:多线程模式下推理速度可提升2-4倍
- 安全限制:需要设置COOP/COEP响应头
参考项目
开源地址
🔗 GitHub仓库 : mvp-ai-wllama
总结
本项目提供了一个完整的纯前端Llama模型推理方案,通过WebAssembly技术实现了模型推理的本地化,结合React和现代化的缓存系统,打造了一个功能完善、性能优秀的AI对话应用。
核心亮点:
- 🚀 纯前端架构,无需后端服务
- 🔒 数据完全本地化,保护隐私安全
- ⚡ 基于WebAssembly的高性能推理
- 💾 IndexedDB缓存系统,支持大文件存储
- 🔄 流式生成支持,实时输出
- 🧵 多线程加速,性能提升显著
- 🔀 多实例支持,可同时运行多个模型实例
- 📱 PWA 支持,可安装到设备,支持离线使用
- 📦 零React依赖的核心库,可接入任何系统
- 🎯 完整的类型定义,开发体验优秀
欢迎Star和Fork,一起推动前端AI技术的发展!
相关阅读: