cpp
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import cv2 as cv
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体为"黑体"(Windows自带,支持中文)
plt.rcParams['axes.unicode_minus'] = False # 解决负号"-"显示为方块的问题
# 设置随机种子以确保结果可复现
torch.manual_seed(42)
# 定义数据转换
transform = transforms.Compose([
transforms.ToTensor(), # 转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化,使用MNIST数据集的均值和标准差
])
# 加载MNIST数据集
def load_data(batch_size=64):
print("正在加载MNIST数据集...")
# 训练数据集
#yolo的准备数据集,图片和TXT
train_dataset = datasets.MNIST(
root='./data', # 数据集保存路径(无则自动下载到该路径
train=True, # 标记为加载训练集(False则为测试集)
download=True, # 本地无数据时自动从官网下载
transform=transform # 应用预处理变换(转Tensor、归一化等)
)
# 测试数据集
#yolo验证集
test_dataset = datasets.MNIST(
root='./data',
train=False,# 加载测试集(用于模型评估,不参与训练)
download=True,
transform=transform
)
# 创建数据加载器
#YOLO 训练脚本,设置batch_size
#shuffle=True:和 YOLO 训练时打乱图片顺序一样,避免模型 "记住" 数据顺序
#(比如 YOLO 记住 "前 10 张都是车牌",MNIST 记住 "前 10 张都是数字 5"),保证模型学的是通用规律
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,# 按批次读取数据
shuffle=True # 训练集随机打乱,避免模型学习数据顺序
)
#训练完 YOLO 模型后,加载验证集 / 测试图片,用模型推理
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False # 测试集无需打乱,不影响评估结果
)
print(f"数据集加载完成: 训练集{len(train_dataset)}张图像, 测试集{len(test_dataset)}张图像")
return train_loader, test_loader
# 定义神经网络模型
#简单数字分类,简易版backbone
class MNISTNet(nn.Module):
def __init__(self):
super(MNISTNet, self).__init__()
# 输入层到第一个隐藏层 (784 -> 128)
# 28×28:MNIST 数据集的官方固定值(必须遵守)
self.fc1 = nn.Linear(28 * 28, 128)
# 第一个隐藏层到第二个隐藏层 (128 -> 64)
#自定义
self.fc2 = nn.Linear(128, 64)
# 第二个隐藏层到输出层 (64 -> 10)
# YOLO 检测 "车牌、行人、车辆"3 类目标,就必须把输出分类数设为 3
#10个数字设置为10,0~9
self.fc3 = nn.Linear(64, 10)
# Dropout层防止过拟合
self.dropout = nn.Dropout(0.25)
def forward(self, x):
# 将输入的28x28图像展平为784维向量
x = x.view(-1, 28 * 28)
# 第一个隐藏层,使用ReLU激活函数
x = F.relu(self.fc1(x))
# 应用Dropout
x = self.dropout(x)
# 第二个隐藏层,使用ReLU激活函数
x = F.relu(self.fc2(x))
# 应用Dropout
x = self.dropout(x)
# 输出层,不使用激活函数(因为我们将在训练中使用交叉熵损失)
x = self.fc3(x)
return x
# 训练模型
def train_model(model, train_loader, epochs=5, learning_rate=0.01, momentum=0.9):
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
# 确保模型在训练模式
model.train()
train_losses = []
train_accuracies = []
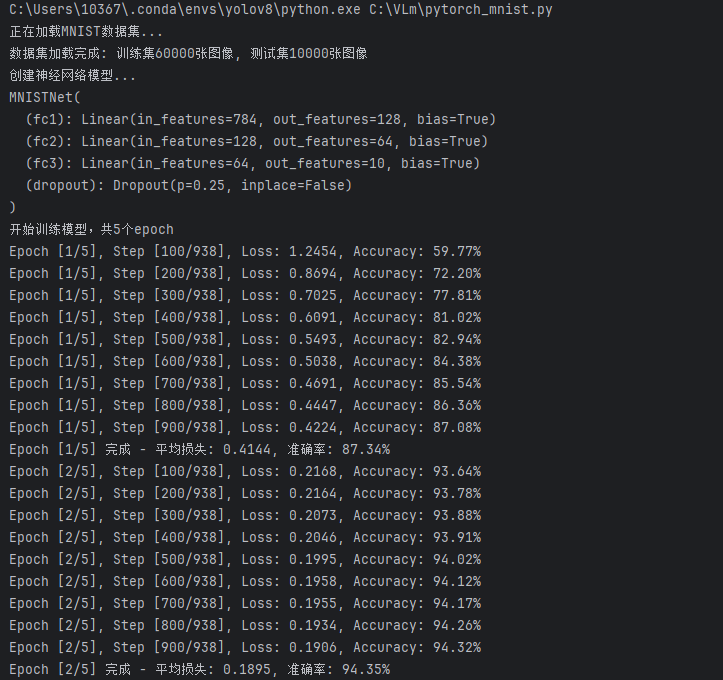
print(f"开始训练模型,共{epochs}个epoch")
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 统计损失
running_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每100个batch打印一次训练状态
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Step [{i + 1}/{len(train_loader)}], '\
f'Loss: {running_loss / (i + 1):.4f}, Accuracy: {100 * correct / total:.2f}%')
# 记录每个epoch的平均损失和准确率
epoch_loss = running_loss / len(train_loader)
epoch_acc = 100 * correct / total
train_losses.append(epoch_loss)
train_accuracies.append(epoch_acc)
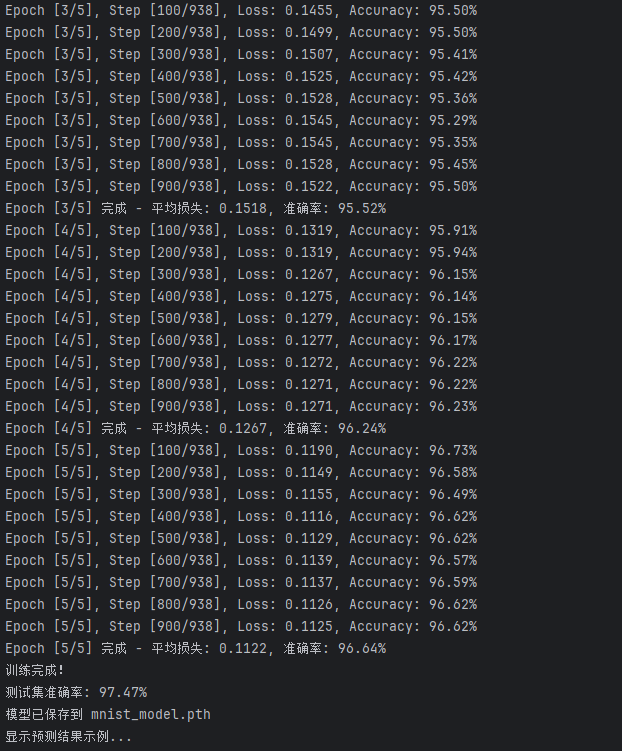
print(f'Epoch [{epoch + 1}/{epochs}] 完成 - 平均损失: {epoch_loss:.4f}, 准确率: {epoch_acc:.2f}%')
print("训练完成!")
return train_losses, train_accuracies
# 测试模型
def test_model(model, test_loader):
# 设置模型为评估模式
model.eval()
correct = 0
total = 0
# 不计算梯度
with torch.no_grad():
for images, labels in test_loader:
# 前向传播
outputs = model(images)
# 预测结果
_, predicted = torch.max(outputs.data, 1)
# 统计
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算准确率
accuracy = 100 * correct / total
print(f'测试集准确率: {accuracy:.2f}%')
return accuracy
# 保存模型
def save_model(model, filepath='mnist_model.pth'):
torch.save(model.state_dict(), filepath)
print(f"模型已保存到 {filepath}")
# 可视化结果
def visualize_results(images, labels, predictions):
# 显示一些测试图像及其预测结果
plt.figure(figsize=(10, 4))
for i in range(min(5, len(images))):
plt.subplot(1, 5, i + 1)
# 转换为numpy数组并恢复原始形状
img = images[i].numpy().squeeze()
plt.imshow(img, cmap='gray')
plt.title(f'预测: {predictions[i]}\n实际: {labels[i]}')
plt.axis('off')
plt.tight_layout()
plt.show()
# 主函数
def main():
# 设置训练参数
batch_size = 64
epochs = 5
learning_rate = 0.01
model_save_path = 'mnist_model.pth'
# 加载数据
train_loader, test_loader = load_data(batch_size)
# 创建模型实例
print("创建神经网络模型...")
model = MNISTNet()
print(model)
# 训练模型
train_losses, train_accuracies = train_model(model, train_loader, epochs, learning_rate)
# 测试模型
test_accuracy = test_model(model, test_loader)
# 保存模型
save_model(model, model_save_path)
# 可视化一些测试结果
# 获取一批测试数据
images, labels = next(iter(test_loader))
# 预测
with torch.no_grad():
outputs = model(images)
_, predictions = torch.max(outputs, 1)
# 可视化结果
print("显示预测结果示例...")
visualize_results(images, labels, predictions)
# 绘制训练过程
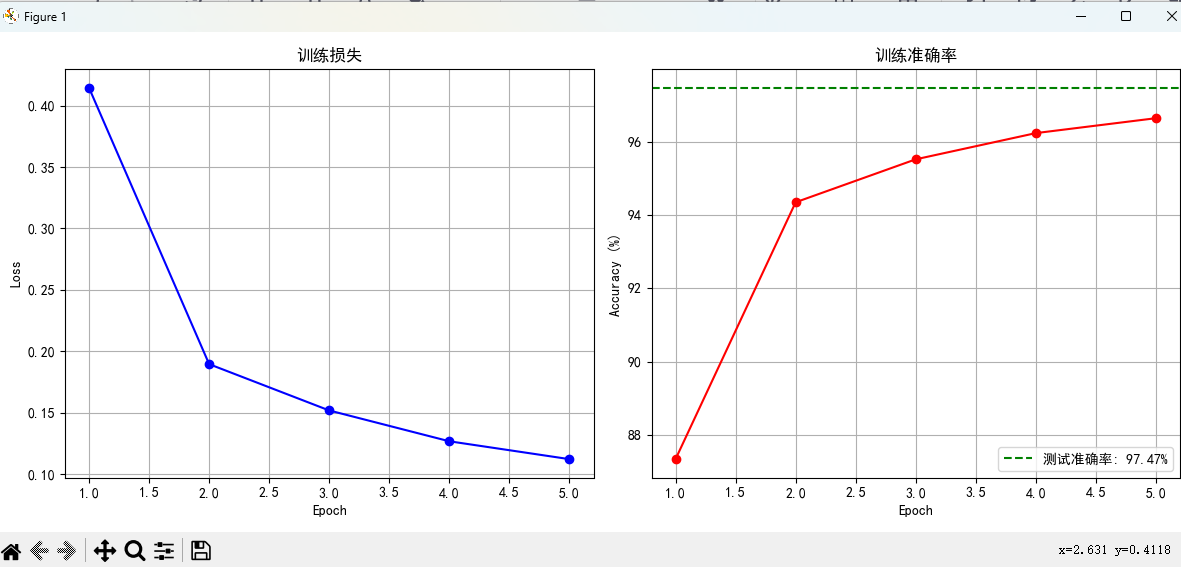
plt.figure(figsize=(12, 5))
# 绘制损失曲线
plt.subplot(1, 2, 1)
plt.plot(range(1, epochs + 1), train_losses, 'b-', marker='o')
plt.title('训练损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.grid(True)
# 绘制准确率曲线
plt.subplot(1, 2, 2)
plt.plot(range(1, epochs + 1), train_accuracies, 'r-', marker='o')
plt.axhline(y=test_accuracy, color='g', linestyle='--', label=f'测试准确率: {test_accuracy:.2f}%')
plt.title('训练准确率')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
main()结果