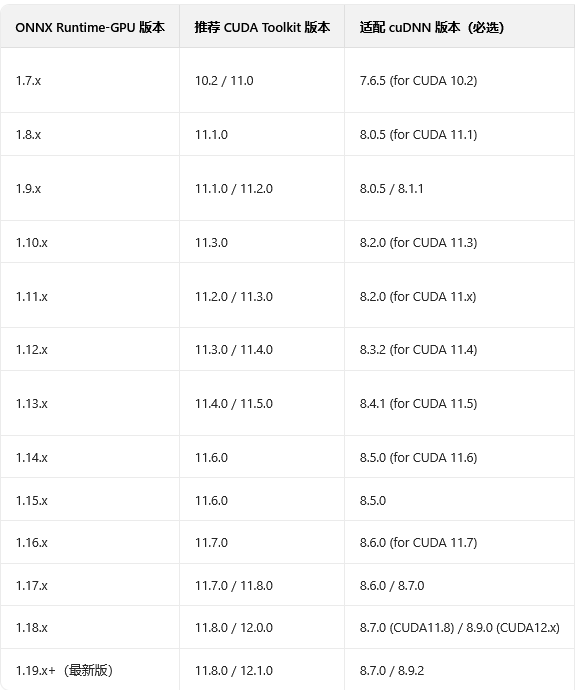
本次教程就以本人电脑的RX2060举例,选择对应版本的ONNXruntime、CUDA、cuDNN,下面是具体版本和QT代码的开启GPU运行效果
一、第一步查询自己电脑显卡当前版本,查询到版本后如果不知道自己对应的ONNX、cuDNN、CUDA请拉到步骤八有对应表,然后按照步骤来,附官方下载链接
cmd命令:nvidia-smi

二、CUDA Version 11.2 兼容 ONNX Runtime v1.11.0
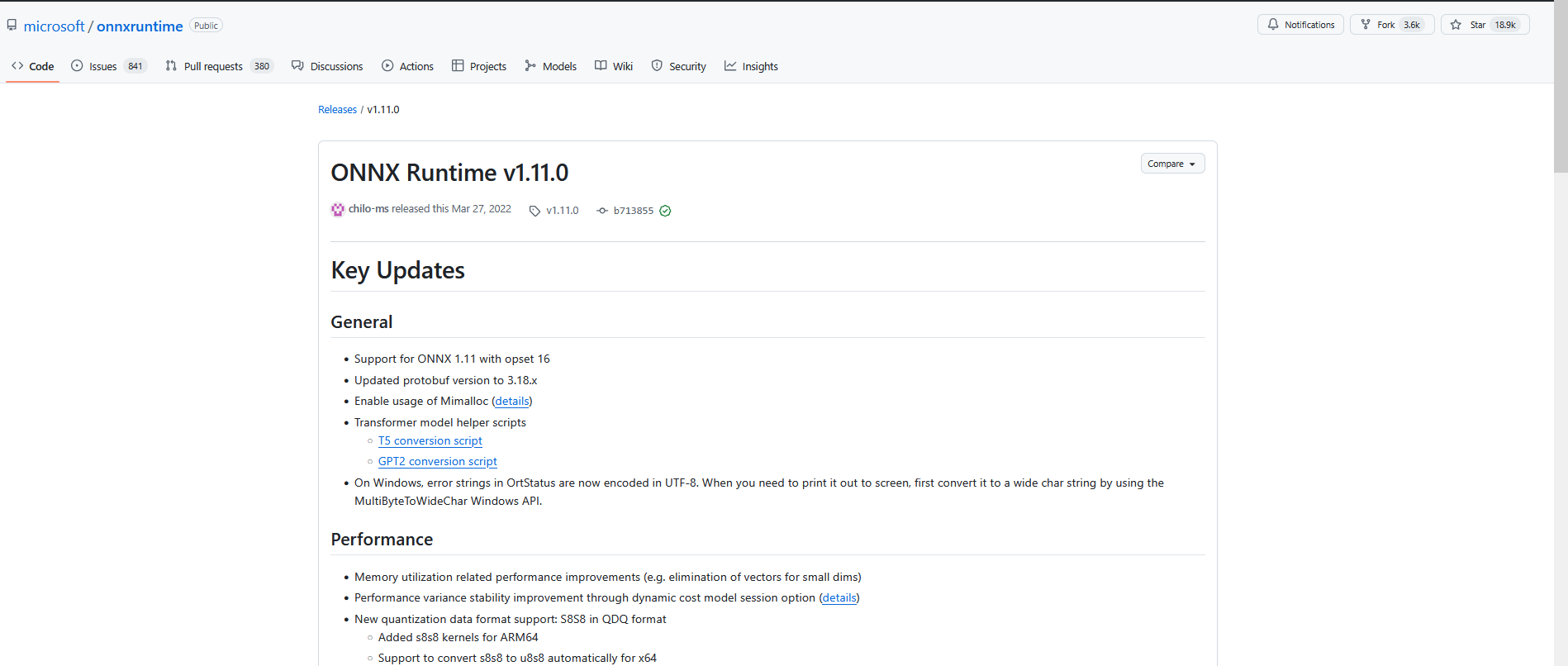
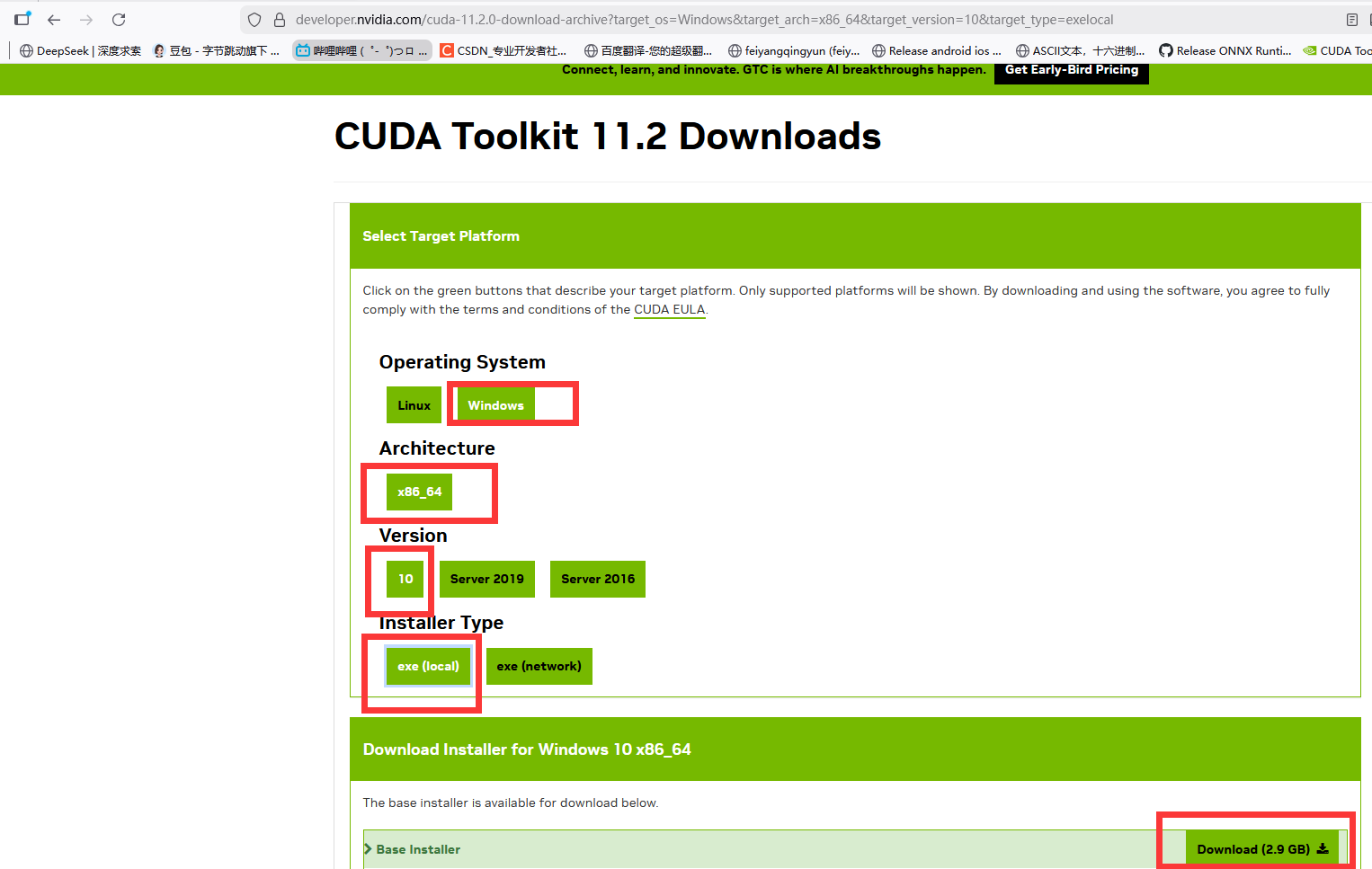
三、CUDA Version 11.2 对应 CUDA Toolkit 11.2
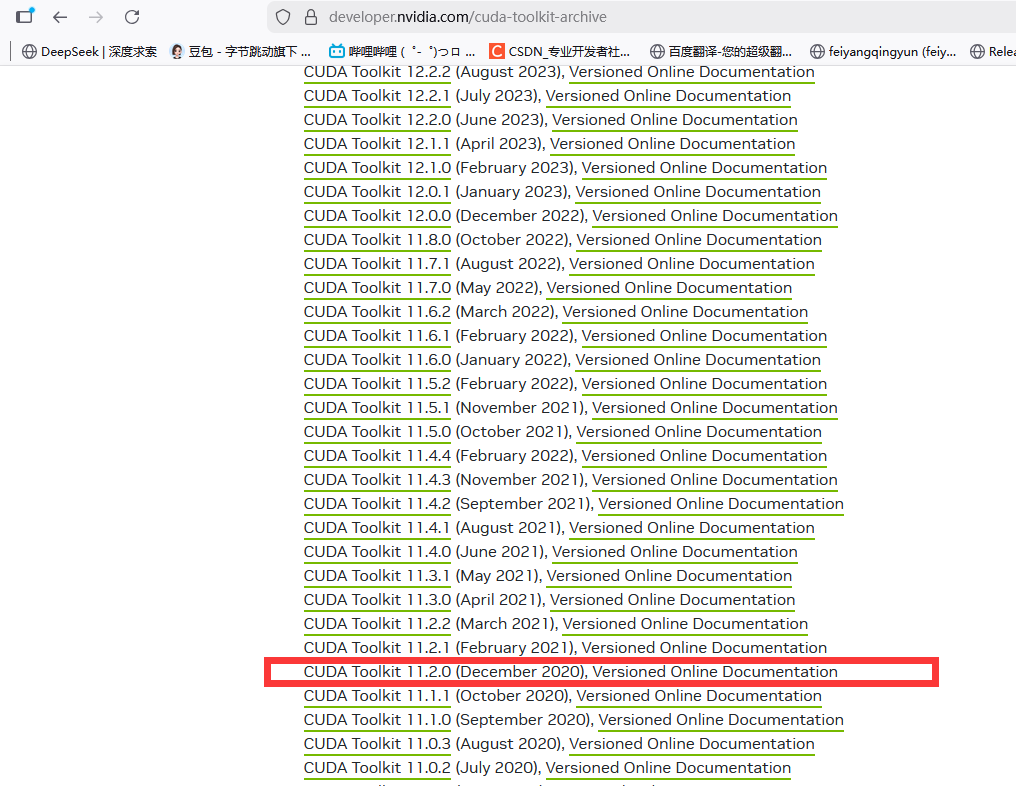
四、CUDA 11.2 兼容 cuDNN V8.2.0
五、下面的CUDA 11.2安装好后将cuDNN的bin 、include、lib等文件复制到 CUDA11.2中
cuda 11.2的安装路径:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2
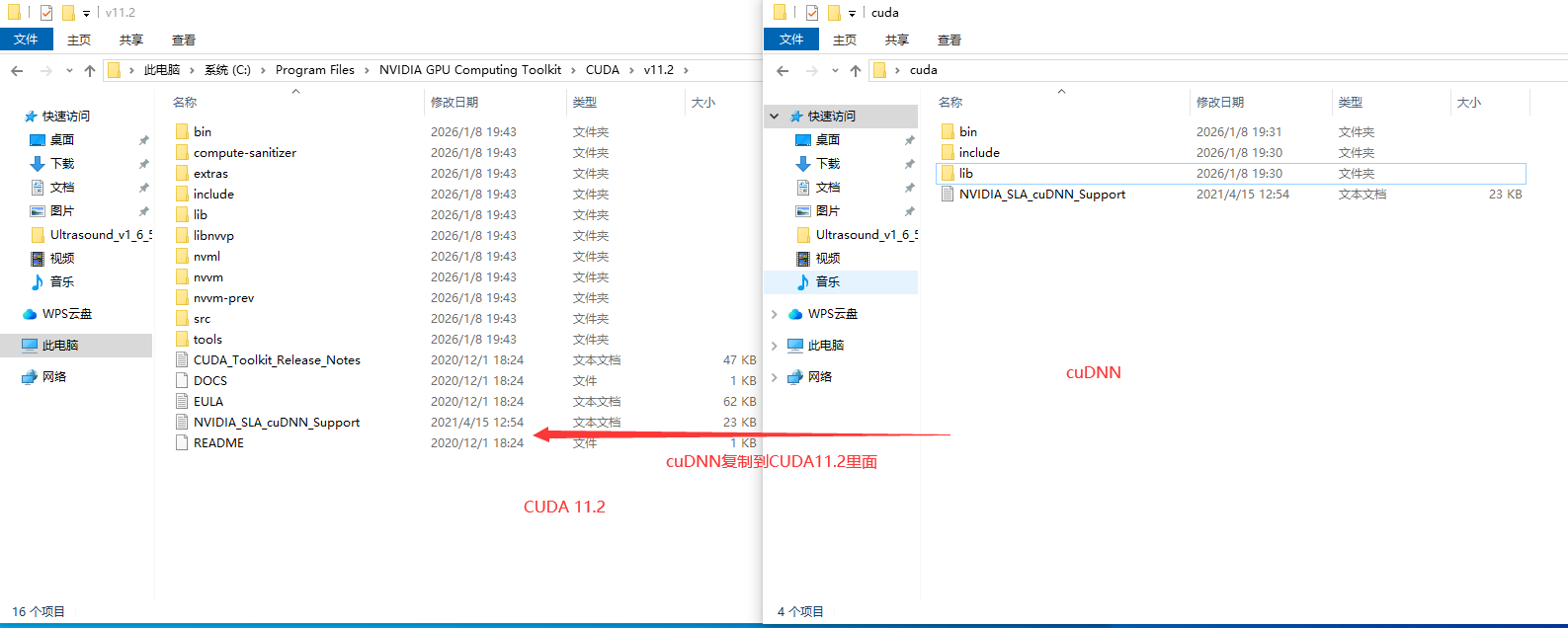
为什么把cuDNN的这四个文件复制到CUDA中?
cuDNN(CUDA Deep Neural Network Library)是基于 CUDA 的专用加速库(专门优化深度学习算子),但它并不是 CUDA Toolkit 的默认组成部分,而是独立发布的。系统 / 框架调用 cuDNN 的前提是:CUDA Toolkit 能在其 "默认搜索路径" 中找到 cuDNN 的头文件、库文件,
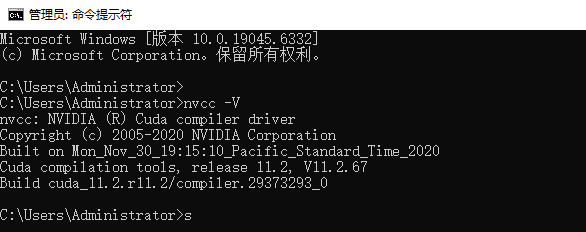
六、cmd中验证CUDA是否安装成功 nvcc -V
七、新建QT项目,配置项目属性
添加包含目录:C:\Users\Administrator\Desktop\onnxruntime-win-x64-gpu-1.11.0\include
添加库目录:C:\Users\Administrator\Desktop\onnxruntime-win-x64-gpu-1.11.0\lib
链接器中输入:
onnxruntime.lib
onnxruntime_providers_cuda.lib
onnxruntime_providers_shared.lib
onnxruntime_providers_tensorrt.lib
还要把这4个dll组件放到项目根目录中
下面为验证代码,验证是否开启GPU:
QtWidgetsApplication2.h
cpp
#pragma once
#include <QtWidgets/QMainWindow>
#include "ui_QtWidgetsApplication2.h"
#include "onnxruntime_cxx_api.h"
#include "onnxruntime_c_api.h"
#include <QThread>
#include <vector>
#include <QTimer>
class SimpleGPUDetector;
class QtWidgetsApplication2 : public QMainWindow
{
Q_OBJECT
public:
QtWidgetsApplication2(QWidget *parent = nullptr);
~QtWidgetsApplication2();
private:
Ui::QtWidgetsApplication2Class ui;
SimpleGPUDetector* CUDA; // 对象
QThread* CUDA_thread; // 线程
};
class SimpleGPUDetector : public QObject
{
Q_OBJECT
public:
SimpleGPUDetector();
// 检查CUDA是否可用的实现
bool isCUDAAvailable() const;
// 检查是否有任意GPU支持的实现
bool isAnyGPUAvailable() const;
// 获取可用提供者列表的实现
std::vector<std::string> getAvailableProviders() const;
public:
// SessionOptions的实现
void slotCreateGPUSessionOptions(int gpu_id);
// 创建SessionOptions会话
Ort::SessionOptions createGPUSessionOptionsSafe(int gpu_id) const;
std::vector<std::string> availableProviders_; // 记录可用的执行提供者
Ort::Env env_; // 环境对象
};QtWidgetsApplication2.cpp
cpp
#include "QtWidgetsApplication2.h"
QtWidgetsApplication2::QtWidgetsApplication2(QWidget* parent)
: QMainWindow(parent)
, CUDA(nullptr)
, CUDA_thread(nullptr)
{
ui.setupUi(this);
CUDA_thread = new QThread(this);
CUDA = new SimpleGPUDetector();
CUDA->moveToThread(CUDA_thread);
CUDA_thread->start();
}
QtWidgetsApplication2::~QtWidgetsApplication2()
{
if (CUDA_thread && CUDA_thread->isRunning()) {
CUDA_thread->quit();
if (!CUDA_thread->wait(3000)) {
CUDA_thread->terminate();
CUDA_thread->wait();
}
}
delete CUDA;
CUDA = nullptr;
delete CUDA_thread;
CUDA_thread = nullptr;
}
// 初始化ONNX Runtime环境
SimpleGPUDetector::SimpleGPUDetector() : env_(ORT_LOGGING_LEVEL_WARNING, "GPUDetector")
{
try {
// 获取ONNX Runtime所有可用的执行提供者
auto providers = Ort::GetAvailableProviders();
// 转换为vector<string>存储
availableProviders_ = std::vector<std::string>(providers.begin(), providers.end());
// 遍历打印每个可用的执行提供者
for (const auto& provider : availableProviders_) {
qDebug() << " - " << QString::fromStdString(provider);
}
// 打印CUDA和GPU可用性
qDebug() << "CUDA可用: " << (isCUDAAvailable() ? "是" : "否");
qDebug() << "任意GPU可用: " << (isAnyGPUAvailable() ? "是" : "否");
// 创建SessionOptions的实现
slotCreateGPUSessionOptions(0);
}
catch (const std::exception& e) {
qCritical() << "初始化GPU检测器失败: " << e.what();
availableProviders_.clear();
}
}
// 检查CUDA是否可用的实现
bool SimpleGPUDetector::isCUDAAvailable() const
{
for (const auto& provider : availableProviders_) {
if (provider.find("CUDA") != std::string::npos) {
return true;
}
}
return false;
}
// 检查是否有任意GPU支持的实现
bool SimpleGPUDetector::isAnyGPUAvailable() const
{
const std::vector<std::string> gpu_providers = { "CUDA", "DML", "TensorRT", "CoreML", "ROCm" };
for (const auto& provider : availableProviders_) {
for (const auto& gpu_p : gpu_providers) {
if (provider.find(gpu_p) != std::string::npos) {
return true;
}
}
}
return false;
}
// 获取可用提供者列表的实现
std::vector<std::string> SimpleGPUDetector::getAvailableProviders() const
{
return availableProviders_;
}
// 创建SessionOptions会话
Ort::SessionOptions SimpleGPUDetector::createGPUSessionOptionsSafe(int gpu_id) const
{
// 创建默认的SessionOptions对象:ONNX Runtime的会话配置
Ort::SessionOptions session_options;
// 设置图优化级别为基础级:降低优化级别,减少初始化崩溃概率
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_BASIC);
// 检查CUDA是否可用
if (isCUDAAvailable()) {
try {
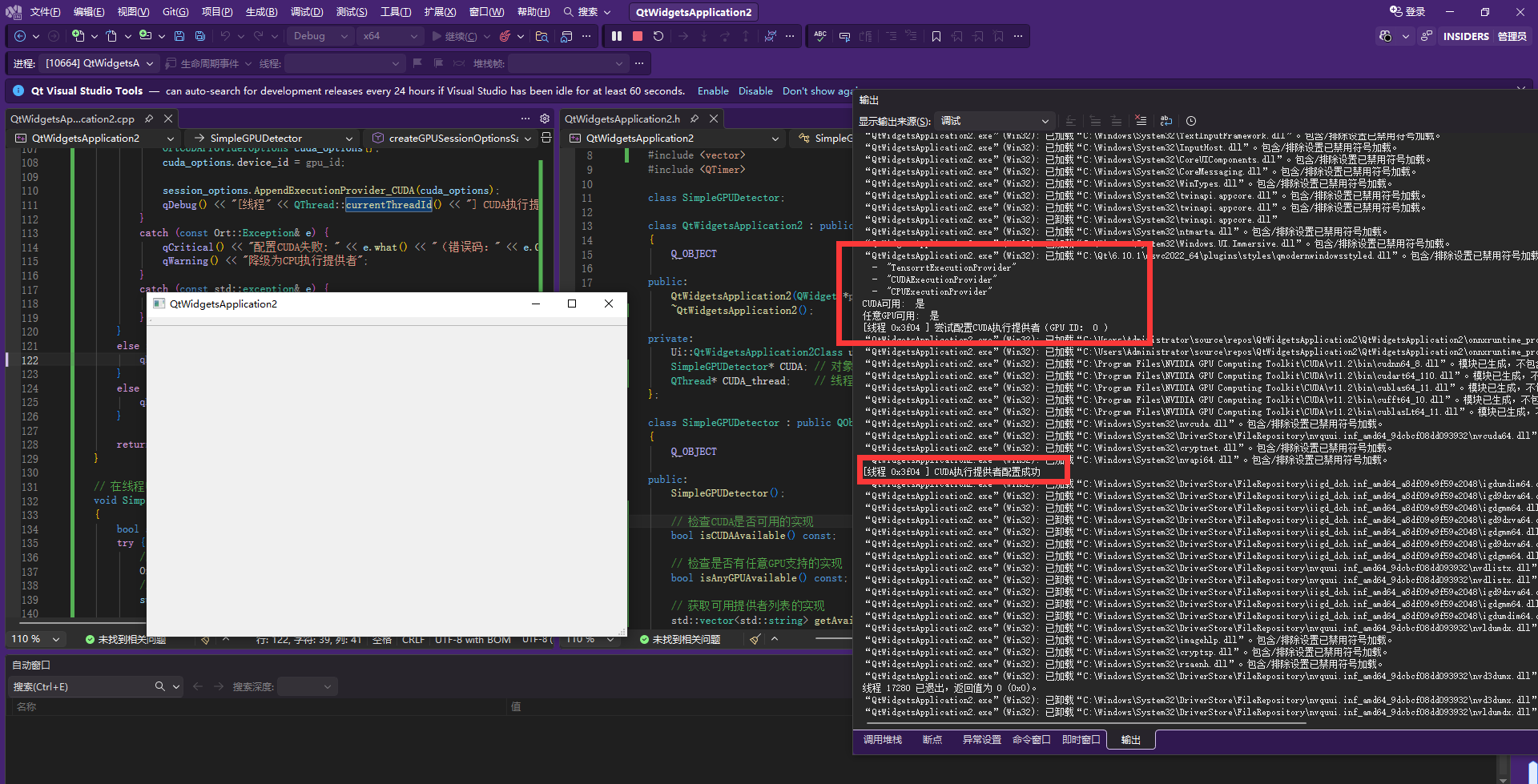
qDebug() << "[线程" << QThread::currentThreadId() << "] 尝试配置CUDA执行提供者(GPU ID:" << gpu_id << ")";
OrtCUDAProviderOptions cuda_options{};
cuda_options.device_id = gpu_id;
session_options.AppendExecutionProvider_CUDA(cuda_options);
qDebug() << "[线程" << QThread::currentThreadId() << "] CUDA执行提供者配置成功";
}
catch (const Ort::Exception& e) {
qCritical() << "配置CUDA失败: " << e.what() << "(错误码:" << e.GetOrtErrorCode() << ")";
qWarning() << "降级为CPU执行提供者";
}
catch (const std::exception& e) {
qCritical() << "配置CUDA时发生异常: " << e.what();
}
}
else if (isAnyGPUAvailable()) {
qDebug() << "[线程" << QThread::currentThreadId() << "] 使用其他GPU执行提供者";
}
else {
qDebug() << "[线程" << QThread::currentThreadId() << "] 无GPU支持,使用CPU执行提供者";
}
return session_options;
}
// 在线程中创建SessionOptions的实现
void SimpleGPUDetector::slotCreateGPUSessionOptions(int gpu_id)
{
bool success = false;
try {
// 1. 安全创建GPU版本的SessionOptions
Ort::SessionOptions opt = createGPUSessionOptionsSafe(gpu_id);
// 标记成功
success = true;
// 示例:加载模型(可选,替换为你的模型路径)
// if (success) {
// Ort::Session session(env_, "your_model.onnx", opt);
// qDebug() << "模型加载成功";
// }
}
// 捕获所有异常:避免加载模型/创建配置时崩溃
catch (const std::exception& e) {
qCritical() << "创建SessionOptions/加载模型失败: " << e.what();
success = false;
}
}运行效果:开启GPU成功,在会话中添加模型即可使用GPU加速
八、对应表
需要注意的是CUDA Toolkit 的版本就是cmd命令 nvidia-smi 查询的 CUDA Version的版本 他们是对应的,CUDA Toolkit 是完整工具包
CUDA Toolkit 11.2 是完整安装包,其核心版本就是 11.2 ,你看到的 "CUDA Version: 11.2" 本质就是这个 Toolkit 的版本标识