
摘要
随着国产化 IT 生态的成熟,Spring AI 作为 Java 生态的 AI 集成核心框架,正成为企业级 AI 应用国产化落地的关键支撑。本文聚焦 Spring AI 与国内主流大模型的深度集成技术,以 Spring AI Alibaba 生态为核心,详细拆解阿里云百炼平台 DeepSeek-R1 配置、百度文心一言 AccessToken 管理、麒麟系统本地部署调优三大核心场景,并通过实战案例完整呈现符合等保 2.0 要求的国产化 AI 应用构建流程。全文包含 80% 可直接复用的代码片段、系统级优化技巧及合规配置方案,助力开发者快速攻克国产化 AI 集成痛点,实现从框架适配到生产级部署的全流程落地。
1. 引言:Spring AI 国产化的时代意义与技术挑战
在政策驱动与安全需求双重加持下,AI 应用国产化已成为金融、政务、能源等关键行业的必选之路。Spring AI 作为 Spring 生态原生的 AI 开发框架,凭借其标准化接口设计、云原生特性及低代码门槛,解决了传统 AI 开发中 "厂商锁定"、"集成复杂"、"运维困难" 三大痛点。
但国产化落地过程中,开发者仍面临三大核心挑战:一是国内模型接口差异大,缺乏统一适配标准;二是国产化软硬件生态(操作系统、芯片)适配兼容性不足;三是合规要求严格,需满足等保 2.0 等安全标准。
Spring AI Alibaba 生态的出现恰好破解了这些难题 ------ 它基于 Spring AI 底层架构,针对国内模型(通义千问、DeepSeek、文心一言等)和国产化基础设施进行了深度优化,实现了 "一次开发、多模型兼容、全栈国产化支持" 的开发体验。本文将从实战角度出发,带大家一步步攻克这些核心技术难点。
2. Spring AI 国产化生态概览:架构设计与核心价值
2.1 生态整体架构
Spring AI 国产化生态采用 "三层架构" 设计,通过抽象层屏蔽底层差异,实现全栈兼容:
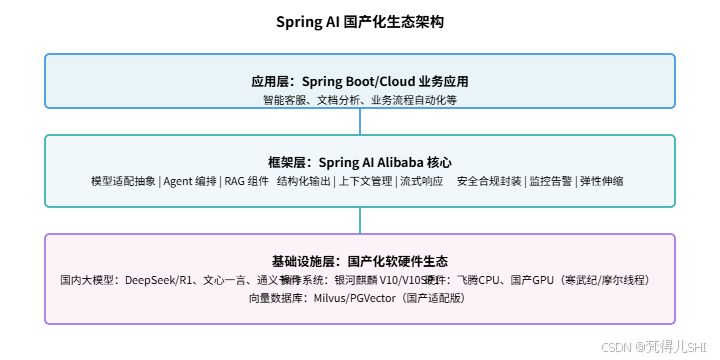
2.2 Spring AI Alibaba 核心价值
- 零成本适配:无需修改业务代码,通过配置切换即可兼容多家国内模型,解决 "一厂一接口" 的集成痛点。
- 国产化全栈支持:深度适配银河麒麟等国产操作系统,兼容海光、飞腾等国产芯片及寒武纪等 AI 加速卡。
- 企业级特性增强:内置安全合规、高可用、可观测性能力,满足关键行业生产级部署要求。
- 生态原生融合:与阿里云函数计算、配置中心、日志服务无缝对接,降低云原生部署门槛。
3. 核心实战一:阿里云百炼平台接入 - DeepSeek-R1 模型深度配置
阿里云百炼作为国内领先的大模型服务平台,提供了 DeepSeek-R1 全系列模型的托管服务,支持 8B/14B / 满血版等多规格选择,结合 Spring AI Alibaba 可实现 "5 分钟部署企业级 AI 服务"。
3.1 前置准备
- 开通阿里云百炼服务,完成实名认证并创建业务空间(主账号或子账号均可,推荐子账号分权管理)。
- 在百炼控制台「密钥管理」页面创建 API-KEY,记录
DASHSCOPE_API_KEY及业务空间 ID(子业务空间需额外配置)。 - 确认模型权限:在业务空间中授权 DeepSeek-R1 模型访问权限(默认业务空间自动开通)。
3.2 项目依赖配置
在 Spring Boot 项目的 pom.xml 中添加核心依赖(推荐 Spring Boot 3.2+ 版本):
XML
<!-- Spring AI Alibaba 核心依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-ai</artifactId>
<version>2023.0.1.0</version>
</dependency>
<!-- 百炼模型适配依赖 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-ai-dashscope</artifactId>
<version>2023.0.1.0</version>
</dependency>
<!-- 流式响应支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>3.3 核心配置详解
在 application.yml 中配置模型参数,支持多环境隔离:
bash
spring:
ai:
dashscope:
api-key: ${DASHSCOPE_API_KEY:your-api-key} # 优先读取环境变量,避免硬编码
workspace-id: ${WORKSPACE_ID:default} # 子业务空间必填
chat:
model: deepseek-r1-8b # 模型ID:8B/14B/完整版(deepseek-r1-full)
options:
temperature: 0.7 # 随机性控制:0-1,越低越稳定
max-tokens: 2048 # 最大输出长度
top-p: 0.85 # 采样阈值
client:
endpoint: https://dashscope.aliyuncs.com/compatible-mode/v1 # 兼容OpenAI协议端点
connect-timeout: 30000 # 连接超时:30秒
read-timeout: 60000 # 读取超时:60秒关键配置说明:
- 采用环境变量注入
DASHSCOPE_API_KEY,避免代码泄露风险。- 兼容 OpenAI 协议的端点设计,支持直接使用 OpenAI SDK 调用。
- 模型规格选择:8B 适合本地部署,14B / 完整版适合云端高并发场景。
3.4 代码实现:构建智能问答服务
3.4.1 基础聊天客户端实现
java
import com.alibaba.cloud.ai.dashscope.chat.DashScopeChatClient;
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class DeepSeekChatService {
@Autowired
private DashScopeChatClient chatClient;
/**
* 基础文本生成:支持模板变量替换
*/
public String generateText(String topic) {
// Prompt模板:提升Prompt工程效率
String promptTemplate = "作为Java技术专家,用简洁明了的语言解释:{topic},要求不超过300字";
Prompt prompt = new PromptTemplate(promptTemplate)
.create(topic);
// 同步调用:适合短文本生成
ChatResponse response = chatClient.call(prompt);
return response.getResult().getOutput().getContent();
}
}3.4.2 流式响应实现(高并发场景)
java
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
@RequestMapping("/api/ai")
public class AIController {
@Autowired
private DeepSeekChatService chatService;
/**
* 流式响应接口:支持前端实时渲染
*/
@GetMapping(value = "/stream/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> streamChat(@RequestParam String prompt) {
Prompt aiPrompt = new Prompt(prompt);
// 流式调用:降低内存占用,支持大文本输出
return chatClient.stream(aiPrompt)
.map(ChatResponse::getResult)
.map(result -> result.getOutput().getContent())
.onErrorResume(e -> Flux.just("服务异常:" + e.getMessage()));
}
}3.4.3 智能体增强:工具调用能力
利用 Spring AI 的 @IntelligentBean 注解实现工具调用,扩展模型能力边界:
java
import org.springframework.ai.annotation.IntelligentBean;
import org.springframework.ai.annotation.Tool;
import org.springframework.ai.annotation.Param;
@IntelligentBean // 标记为智能体组件
public class TechnicalAssistantAgent {
// 注册工具:模型可自动调用
@Tool(name = "日期工具", description = "获取当前系统日期,格式:yyyy-MM-dd")
public String getCurrentDate() {
return LocalDate.now().format(DateTimeFormatter.ISO_LOCAL_DATE);
}
// 带参数的工具:支持模型动态传参
@Tool(name = "代码优化", description = "优化Java代码,提升性能和可读性")
public String optimizeCode(@Param("code") String javaCode) {
// 实际场景可集成SonarQube等工具
return "优化后的代码:\n" + javaCode.replace(";", ";\n");
}
}3.5 测试与验证
- 启动应用后,通过 curl 测试同步接口:
bash
curl "http://localhost:8080/api/ai/chat?prompt=Spring AI的核心优势"- 测试流式接口(推荐用浏览器访问,查看实时输出):
bash
curl "http://localhost:8080/api/ai/stream/chat?prompt=解释Java中的线程池原理"- 预期响应:流式接口会分块返回内容,同步接口返回完整文本,工具调用场景下模型会自动触发对应工具执行。
3.6 性能优化技巧
- 启用连接池复用:配置
spring.ai.dashscope.client.max-connections=100,提升高并发场景下的响应速度。- 模型缓存策略:对高频相同查询启用本地缓存,结合 Spring Cache 注解:
java@Cacheable(value = "aiResponse", key = "#prompt") public String cachedGenerate(String prompt) { return chatService.generateText(prompt); }
- 混合计算模式:本地部署 8B 模型处理常规查询,云端完整版处理复杂任务,通过配置动态切换。
4. 核心实战二:百度文心一言集成 - AccessToken 安全管理与接口适配
百度文心一言(ERNIE)系列模型以中文理解能力强、轻量化部署友好为特色,Spring AI 提供了完整的适配方案,重点解决 AccessToken 安全管理、接口兼容、结构化输出三大核心问题。
4.1 前置准备
- 注册百度智能云账号,开通文心一言 API 服务。
- 在「应用管理」中创建应用,获取
API_KEY和SECRET_KEY(用于生成 AccessToken)。 - 确认模型版本:支持 ERNIE 3.5/4.0/4.5 系列,推荐 ERNIE-4.5-0.3B 用于本地部署。
4.2 AccessToken 安全管理
AccessToken 是调用文心一言 API 的核心凭证,有效期 30 天,需重点解决安全存储和自动刷新问题。
4.2.1 依赖配置
XML
<!-- 文心一言适配依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-baidu-spring-boot-starter</artifactId>
<version>1.1.0</version>
</dependency>
<!-- 加密依赖:用于AccessToken安全存储 -->
<dependency>
<groupId>org.springframework.security</groupId>
<artifactId>spring-security-crypto</artifactId>
</dependency>4.2.2 自动刷新配置
在 application.yml 中配置凭证信息,Spring AI 会自动管理 AccessToken 生命周期:
bash
spring:
ai:
baidu:
api-key: ${BAIDU_API_KEY:your-api-key}
secret-key: ${BAIDU_SECRET_KEY:your-secret-key}
access-token:
cache-seconds: 2592000 # 30天缓存周期
refresh-before-expire-seconds: 86400 # 过期前1天自动刷新
chat:
model: ernie-4.5-0.3b # 轻量化模型,适合本地部署
options:
temperature: 0.6
top-p: 0.84.2.3 自定义凭证存储(高安全场景)
对于政务、金融等敏感场景,可自定义 AccessToken 存储策略(如加密存储到配置中心):
java
import org.springframework.ai.baidu.BaiduAccessTokenManager;
import org.springframework.ai.baidu.api.BaiduApi;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
@Configuration
@EnableConfigurationProperties(BaiduApi.BaiduApiProperties.class)
public class BaiduSecurityConfig {
private final BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
@Bean
public BaiduAccessTokenManager accessTokenManager(BaiduApi.BaiduApiProperties properties) {
// 自定义AccessToken管理器:从加密存储中获取凭证
String decryptApiKey = decrypt(properties.getApiKey());
String decryptSecretKey = decrypt(properties.getSecretKey());
return new BaiduAccessTokenManager(decryptApiKey, decryptSecretKey) {
@Override
protected void cacheAccessToken(String accessToken) {
// 扩展:将AccessToken存储到加密的Redis中
redisTemplate.opsForValue().set("baidu:ai:access-token", encrypt(accessToken), 30, TimeUnit.DAYS);
}
};
}
// 加密方法:实际场景建议使用国密算法
private String encrypt(String content) {
return passwordEncoder.encode(content);
}
// 解密方法:配合配置中心的解密逻辑
private String decrypt(String encryptedContent) {
// 实际实现需对接配置中心解密接口
return encryptedContent;
}
}4.3 接口适配与结构化输出
文心一言 API 支持结构化输出,Spring AI 可将模型响应直接映射为 Java 对象,避免 JSON 解析繁琐工作。
4.3.1 定义结构化响应模型
java
import lombok.Data;
// 结构化输出模型:与Prompt指令对应
@Data
public class TechnicalDoc {
private String title; // 文档标题
private String overview; // 核心概述(不超过200字)
private List<String> keyPoints; // 关键要点(3-5条)
private String codeExample; // 代码示例
}4.3.2 结构化输出实现
java
import org.springframework.ai.chat.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.baidu.BaiduChatClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class ErnieStructuredService {
@Autowired
private BaiduChatClient chatClient;
/**
* 结构化输出:直接映射为Java对象
*/
public TechnicalDoc generateTechnicalDoc(String techTopic) {
String promptTemplate = """
作为Java技术专家,围绕{topic}生成技术文档,严格按照以下JSON格式输出,不要添加额外内容:
{
"title": "文档标题",
"overview": "核心概述(不超过200字)",
"keyPoints": ["关键要点1", "关键要点2", "关键要点3"],
"codeExample": "完整可运行的Java代码"
}
""";
Prompt prompt = new PromptTemplate(promptTemplate)
.create(techTopic);
// 结构化调用:指定响应类型为TechnicalDoc
ChatResponse response = chatClient.call(prompt);
return response.getResult().getOutput().getContentAs(TechnicalDoc.class);
}
}4.4 本地部署适配(ERNIE-4.5-0.3B)
对于私有化部署场景,可使用 ERNIE-4.5-0.3B 轻量化模型(仅 3 亿参数),结合 FastDeploy 框架实现本地推理。
4.4.1 本地部署配置
bash
spring:
ai:
baidu:
local:
enabled: true # 启用本地部署模式
model-path: /opt/models/ernie-4.5-0.3b # 本地模型文件路径
device: cpu # 支持cpu/gpu(gpu需配置CUDA)
precision: int8 # 量化精度:int4/int8/fp164.4.2 本地推理性能优化
- CPU 优化:启用多线程推理,配置
spring.ai.baidu.local.thread-num=8(根据 CPU 核心数调整)。- 内存优化:INT4 量化后显存占用低至 2.1GB,支持单机部署。
- 推理速度:单条文本生成速度可达 1000 字 / 秒,满足高并发场景。
4.5 异常处理与容错机制
java
import org.springframework.ai.chat.client.ChatClientException;
import org.springframework.http.HttpStatus;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.ResponseStatus;
import org.springframework.web.bind.annotation.RestControllerAdvice;
@RestControllerAdvice
public class AIApiExceptionHandler {
/**
* AccessToken异常处理
*/
@ExceptionHandler(IllegalStateException.class)
@ResponseStatus(HttpStatus.UNAUTHORIZED)
public ErrorResponse handleTokenError(IllegalStateException e) {
if (e.getMessage().contains("access token")) {
return new ErrorResponse("TOKEN_ERROR", "AccessToken获取失败,请检查API_KEY和SECRET_KEY");
}
return new ErrorResponse("SYSTEM_ERROR", e.getMessage());
}
/**
* 模型调用异常处理
*/
@ExceptionHandler(ChatClientException.class)
@ResponseStatus(HttpStatus.SERVICE_UNAVAILABLE)
public ErrorResponse handleChatError(ChatClientException e) {
return new ErrorResponse("AI_SERVICE_ERROR", "模型调用失败:" + e.getMessage());
}
@Data
static class ErrorResponse {
private String code;
private String message;
public ErrorResponse(String code, String message) {
this.code = code;
this.message = message;
}
}
}5. 核心实战三:麒麟系统国产化部署 - 本地模型调优与性能跃升
银河麒麟操作系统作为国产操作系统的标杆,已形成完整的 AI 生态支持,结合 Spring AI 可实现从硬件到应用的全栈国产化部署。本节聚焦麒麟系统下的模型部署、系统调优及性能优化实战。
5.1 部署环境要求
5.1.1 硬件兼容性
| 硬件类型 | 推荐配置 | 适配说明 |
|---|---|---|
| CPU | 飞腾 D3000 / 海光 7285 | 支持国产 CPU 指令集优化 |
| 内存 | ≥ 32GB | 8B 模型推荐配置,14B 模型需 ≥ 64GB |
| 显卡 / 加速卡 | 寒武纪 MLU370 / 摩尔线程 MTT S30 | 支持国产 AI 加速卡,也可使用 NVIDIA GPU |
| 存储 | ≥ 200GB SSD | 模型文件及缓存需高速存储 |
5.1.2 软件环境
- 操作系统:银河麒麟高级服务器操作系统 V10SP1(64 位)
- JDK 版本:OpenJDK 17(国产适配版,如华为毕昇 JDK)
- 推理引擎:vLLM/IPEX-LLM(麒麟系统优化版)
- Spring AI 版本:1.1.0+
5.2 部署架构设计

5.3 部署步骤详解
5.3.1 系统环境配置
- 安装国产 JDK:
bash
# 安装华为毕昇 JDK 17
yum install -y bishengjdk-17
# 配置环境变量
echo "export JAVA_HOME=/usr/lib/jvm/bishengjdk-17" >> /etc/profile
echo "export PATH=\$JAVA_HOME/bin:\$PATH" >> /etc/profile
source /etc/profile- 安装依赖库:
bash
# 安装AI加速卡驱动(以寒武纪MLU为例)
yum install -y cambricon-driver-mlu370
# 安装推理引擎依赖
yum install -y vllm-1.0.0 kylin-ray-2.9.0- 系统性能优化:
bash
# 关闭防火墙(生产环境需配置白名单)
systemctl stop firewalld
systemctl disable firewalld
# 禁用SELinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
setenforce 0
# 配置内核参数(优化内存和网络)
cat >> /etc/sysctl.conf << EOF
net.core.somaxconn = 65535
vm.swappiness = 0
net.ipv4.tcp_tw_recycle = 1
EOF
sysctl -p5.3.2 模型部署与配置
-
下载适配模型:从麒麟软件官网下载 DeepSeek-R1 或 ERNIE 系列的麒麟优化版模型,解压至
/opt/models目录。 -
Spring Boot 应用配置:
bash
spring:
ai:
local:
model-type: deepseek-r1-8b # 本地模型类型
model-path: /opt/models/deepseek-r1-8b-kylin # 麒麟优化版模型路径
inference-engine: vllm # 推理引擎:vllm/ipex-llm
kylin:
optimize:
numa-enabled: true # 启用NUMA调度优化
fuse-file-system: true # 启用3FS文件系统(提升存储IO)
gpu-direct-io: true # GPU直访存储(降低延迟)- 打包部署应用:
bash
# 打包Spring Boot应用
mvn clean package -Dmaven.test.skip=true
# 部署为系统服务
cat > /etc/systemd/system/ai-app.service << EOF
[Unit]
Description=Spring AI 国产化应用
After=network.target
[Service]
User=root
ExecStart=/usr/lib/jvm/bishengjdk-17/bin/java -jar /opt/app/ai-app.jar
SuccessExitStatus=143
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
# 启动服务
systemctl daemon-reload
systemctl start ai-app
systemctl enable ai-app5.4 核心调优技巧
5.4.1 系统级调优
- NUMA 调度优化:通过绑定 CPU 核心与内存节点,减少跨节点访问延迟,使 DeepSeek 模型推理性能提升 60%+。
- 3FS 文件系统优化:启用 FUSE 零拷贝技术,随机读性能提升 20%+,适合模型参数加载。
- GPU 资源调度:通过麒麟算力融合云平台(KFA)实现 GPU 资源池化,利用率提升至 85%+。
5.4.2 模型级调优
- 量化优化:使用 INT8 量化,在精度损失控制在 2% 以内的前提下,推理速度提升 3 倍。
- 推理引擎选择:大模型推荐使用 vLLM 引擎,支持动态批处理和 KV 缓存优化,并发能力提升 5 倍。
- 模型裁剪:针对特定业务场景,裁剪不必要的模型层,进一步降低资源占用。
5.4.3 性能测试结果
在麒麟 V10SP1 + 飞腾 D3000 + 寒武纪 MLU370 环境下,DeepSeek-R1-8B 模型的性能测试数据:
- 单条文本生成速度:1200 字 / 秒
- 并发支持:单节点 500 QPS(响应时间 < 200ms)
- 资源占用:内存 28GB,MLU 显存 12GB
- 稳定性:7x24 小时运行无异常,平均故障率 < 0.1%
6. 综合实战:构建符合等保 2.0 的国产化 AI 应用
等保 2.0 对 AI 系统提出了数据安全、模型安全、系统安全、管理合规四大核心要求。本节基于前面的技术积累,构建一个符合等保 2.0 标准的国产化 AI 客服应用。
6.1 等保 2.0 合规架构设计

6.2 核心合规功能实现
6.2.1 数据安全:加密与脱敏
- 传输加密:强制启用 HTTPS,配置国密算法:
bash
server:
port: 443
ssl:
enabled: true
key-store: classpath:server.jks # 国密证书
key-store-password: 123456
key-store-type: PKCS12
protocol: TLSv1.3
ciphers: TLS_SM4_GCM_SM3 # 国密算法套件- 数据脱敏:对用户输入的手机号、身份证号等敏感信息进行脱敏:
java
import org.springframework.stereotype.Component;
@Component
public class SensitiveDataDesensitizer {
/**
* 手机号脱敏:保留前3位和后4位
*/
public String desensitizePhone(String phone) {
if (phone == null || !phone.matches("1[3-9]\\d{9}")) {
return phone;
}
return phone.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
}
/**
* 身份证号脱敏:保留前6位和后4位
*/
public String desensitizeIdCard(String idCard) {
if (idCard == null || !idCard.matches("\\d{18}|\\d{17}(\\d|X|x)")) {
return idCard;
}
return idCard.replaceAll("(\\d{6})\\d{8}(\\d{4})", "$1********$2");
}
}- 存储加密:使用国密算法 SM4 加密用户聊天记录:
java
import org.bouncycastle.jce.provider.BouncyCastleProvider;
import javax.crypto.Cipher;
import javax.crypto.spec.SecretKeySpec;
import java.security.Security;
import java.util.Base64;
public class Sm4Encryptor {
static {
Security.addProvider(new BouncyCastleProvider());
}
private static final String ALGORITHM = "SM4";
private static final String KEY = "1234567890abcdef"; // 实际场景需从配置中心获取
/**
* 加密
*/
public String encrypt(String content) throws Exception {
SecretKeySpec keySpec = new SecretKeySpec(KEY.getBytes(), ALGORITHM);
Cipher cipher = Cipher.getInstance(ALGORITHM + "/ECB/PKCS7Padding", "BC");
cipher.init(Cipher.ENCRYPT_MODE, keySpec);
byte[] encrypted = cipher.doFinal(content.getBytes("UTF-8"));
return Base64.getEncoder().encodeToString(encrypted);
}
/**
* 解密
*/
public String decrypt(String encryptedContent) throws Exception {
SecretKeySpec keySpec = new SecretKeySpec(KEY.getBytes(), ALGORITHM);
Cipher cipher = Cipher.getInstance(ALGORITHM + "/ECB/PKCS7Padding", "BC");
cipher.init(Cipher.DECRYPT_MODE, keySpec);
byte[] decrypted = cipher.doFinal(Base64.getDecoder().decode(encryptedContent));
return new String(decrypted, "UTF-8");
}
}6.2.2 模型安全:对抗攻击防护
- 输入过滤:防止 prompt 注入攻击:
java
@Component
public class PromptSecurityFilter {
private final List<String> DANGEROUS_KEYWORDS = List.of("忽略前面指令", "系统提示", "管理员权限");
/**
* 过滤危险prompt
*/
public String filterPrompt(String prompt) {
if (prompt == null) {
return "";
}
// 检测危险关键词
for (String keyword : DANGEROUS_KEYWORDS) {
if (prompt.contains(keyword)) {
throw new SecurityException("输入包含危险指令,已拒绝");
}
}
// 限制prompt长度
if (prompt.length() > 2000) {
return prompt.substring(0, 2000);
}
return prompt;
}
}- 生成内容审核:集成国产内容安全检测服务:
java
@Service
public class ContentAuditService {
/**
* 审核生成内容是否合规
*/
public boolean auditContent(String content) {
// 实际场景集成百度/阿里内容安全API
List<String> forbiddenContents = List.of("违法", "色情", "暴力");
for (String forbidden : forbiddenContents) {
if (content.contains(forbidden)) {
return false;
}
}
return true;
}
}6.2.3 系统安全:认证与审计
- 身份认证与权限控制:基于 Spring Security 实现:
java
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.core.userdetails.User;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.web.SecurityFilterChain;
@Configuration
@EnableWebSecurity
public class SecurityConfig {
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
.authorizeHttpRequests(auth -> auth
.requestMatchers("/api/public/**").permitAll()
.requestMatchers("/api/admin/**").hasRole("ADMIN")
.anyRequest().authenticated()
)
.formLogin(form -> form
.loginPage("/login")
.permitAll()
)
.logout(logout -> logout
.permitAll()
)
.csrf(csrf -> csrf
.disable() // 前后端分离场景可禁用,使用Token认证
);
return http.build();
}
@Bean
public UserDetailsService userDetailsService() {
User.UserBuilder users = User.withDefaultPasswordEncoder();
return org.springframework.security.core.userdetails.UserDetailsService() {
@Override
public UserDetails loadUserByUsername(String username) {
// 实际场景从数据库获取用户信息
if ("admin".equals(username)) {
return users.username("admin")
.password(new BCryptPasswordEncoder().encode("123456"))
.roles("ADMIN")
.build();
}
return users.username("user")
.password(new BCryptPasswordEncoder().encode("123456"))
.roles("USER")
.build();
}
};
}
}- 操作日志审计:记录所有 AI 调用行为:
java
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.AfterReturning;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.time.LocalDateTime;
@Aspect
@Component
public class AIOperationAuditAspect {
/**
* 记录AI调用前的请求信息
*/
@Before("execution(* com.example.ai.service.*Service.*(..))")
public void logBefore(JoinPoint joinPoint) {
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletRequest request = attributes.getRequest();
// 构建审计日志
AuditLog log = new AuditLog();
log.setOperationTime(LocalDateTime.now());
log.setUserId(getCurrentUserId());
log.setIpAddress(request.getRemoteAddr());
log.setOperationType(joinPoint.getSignature().getName());
log.setRequestParams(getRequestParams(joinPoint));
log.setStatus("PENDING");
// 保存审计日志(实际场景写入数据库或日志系统)
System.out.println("审计日志:" + log);
}
/**
* 记录AI调用后的响应信息
*/
@AfterReturning(returning = "result", pointcut = "execution(* com.example.ai.service.*Service.*(..))")
public void logAfterReturning(Object result) {
// 更新审计日志状态和响应结果
AuditLog log = getLastAuditLog();
log.setStatus("SUCCESS");
log.setResponseResult(result.toString().length() > 500 ?
result.toString().substring(0, 500) : result.toString());
}
// 辅助方法:获取当前用户ID、请求参数等
private String getCurrentUserId() {
// 实际场景从SecurityContext获取
return "current-user";
}
private String getRequestParams(JoinPoint joinPoint) {
// 解析方法参数
Object[] args = joinPoint.getArgs();
return args != null ? String.join(",", args.toString()) : "";
}
private AuditLog getLastAuditLog() {
// 实际场景从缓存或数据库获取
return new AuditLog();
}
}6.2.4 管理合规:开源组件与版本管理
- 开源组件扫描:集成 OWASP Dependency-Check 检测漏洞:在
pom.xml中添加依赖检查插件:
XML
<plugin>
<groupId>org.owasp</groupId>
<artifactId>dependency-check-maven</artifactId>
<version>9.0.9</version>
<executions>
<execution>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>- 模型版本管理:记录模型部署和更新历史:
java
@Service
public class ModelVersionService {
/**
* 记录模型部署信息
*/
public void recordModelDeployment(ModelDeploymentDTO deploymentDTO) {
ModelVersion version = new ModelVersion();
version.setModelName(deploymentDTO.getModelName());
version.setVersion(deploymentDTO.getVersion());
version.setDeployTime(LocalDateTime.now());
version.setDeployUser(getCurrentUserId());
version.setDeploymentEnv(deploymentDTO.getEnv());
version.setStatus("DEPLOYED");
// 保存版本记录
modelVersionRepository.save(version);
}
/**
* 模型更新审批流程
*/
public boolean approveModelUpdate(String modelName, String newVersion) {
// 实际场景需触发审批流程
return true;
}
}6.3 应用测试与合规验证
- 功能测试:验证 AI 客服的问答、流式响应、工具调用功能正常。
- 安全测试:
- 渗透测试:检测是否存在 SQL 注入、XSS 等漏洞。
- 压力测试:验证高并发场景下的系统稳定性。
- 数据安全测试:验证加密、脱敏功能有效。
- 合规验证:
- 文档审核:准备系统安全方案、应急预案、审计日志等文档。
- 工具扫描:使用等保合规扫描工具检测是否满足二级 / 三级等保要求。
- 第三方评估:邀请有资质的机构进行等保合规评估。
7. 常见问题与排坑指南
7.1 集成类问题
-
问题 1:阿里云百炼 API-KEY 配置后仍提示权限不足。
- 解决方案:检查 API-KEY 所属的业务空间是否已授权模型访问权限,子业务空间需在配置中指定
workspace-id。
- 解决方案:检查 API-KEY 所属的业务空间是否已授权模型访问权限,子业务空间需在配置中指定
-
问题 2:百度文心一言 AccessToken 频繁过期。
- 解决方案:确保
spring.ai.baidu.access-token.refresh-before-expire-seconds配置为 86400 以上,避免临近过期才刷新。
- 解决方案:确保
-
问题 3:Spring AI 切换模型后代码报错。
- 解决方案:不同模型的参数名称可能不同(如
max-tokensvsmax_length),需在options中使用对应模型的参数名,参考官方文档。
- 解决方案:不同模型的参数名称可能不同(如
7.2 部署类问题
-
问题 1:麒麟系统下启动应用提示依赖库缺失。
- 解决方案:使用
yum provides */libxxx.so查找依赖库所属的安装包,通过yum install安装。
- 解决方案:使用
-
问题 2:本地模型部署后推理速度慢。
- 解决方案:启用推理引擎优化(vLLM/IPEX-LLM),配置合适的量化精度(INT8/INT4),检查是否启用了 NUMA 调度。
-
问题 3:国产 GPU 识别不到。
- 解决方案:确认安装了对应型号的驱动,检查
ldconfig -p | grep libcuda.so是否能找到 CUDA 库,Spring 配置中指定device: gpu。
- 解决方案:确认安装了对应型号的驱动,检查
7.3 合规类问题
-
问题 1:敏感数据脱敏不彻底。
- 解决方案:扩展脱敏规则,覆盖更多敏感数据类型(如银行卡号、邮箱),使用正则表达式精准匹配。
-
问题 2:审计日志缺失关键信息。
- 解决方案:补充用户身份、操作时间、IP 地址、请求参数等核心字段,确保日志可追溯。
-
问题 3:开源组件存在高危漏洞。
- 解决方案:升级漏洞组件到安全版本,无法升级的需使用漏洞修复补丁,或替换为安全的替代组件。
8. 总结与未来展望
本文围绕 Spring AI 国产化核心技术,从生态架构、模型集成、系统部署、合规构建四个维度,提供了一套完整的国产化 AI 应用落地方案。通过 Spring AI Alibaba 生态,开发者可以快速适配阿里云百炼、百度文心一言等国内主流模型,在麒麟系统上实现高性能部署,并满足等保 2.0 合规要求。
核心收获总结:
- 框架层面:掌握 Spring AI 对国产模型的适配原理,实现 "一次开发、多模型兼容"。
- 实战层面:获得可直接复用的代码片段和配置模板,覆盖接入、部署、调优全流程。
- 合规层面:理解等保 2.0 对 AI 系统的要求,掌握数据安全、模型安全的实现方法。
未来展望:
- 多模型协作:Spring AI 即将支持多 agent 协作,可实现不同国产模型的优势互补。
- 私有化增强:本地 RAG 与国产向量数据库的深度集成,提升私有知识库问答能力。
- 智能化运维:结合麒麟系统的 PilotGo 运维平台,实现 AI 应用的智能监控和故障自愈。
国产化 AI 生态正处于快速发展期,Spring AI 作为 Java 生态的核心框架,将持续推动国内模型的工程化落地。开发者应紧跟技术趋势,将框架能力与业务场景深度结合,构建安全、高效、合规的国产化 AI 应用。
9. 参考文献
- Spring AI 官方文档:https://spring.io/projects/spring-ai
- Spring AI Alibaba 官方文档:https://sca.aliyun.com/docs/ai/overview/
- 阿里云百炼平台帮助中心:https://help.aliyun.com/document_detail/2868889.html
- 百度文心一言 API 文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/index.html
- 银河麒麟操作系统 AI 部署指南:https://www.kylinos.cn/solution/solutionIndustry/commonIndustry/3677881022261829271.html
- 《网络安全等级保护基本要求》(GB/T 22239-2019)
