多主节点集群
RabbitMQ多主节点(普通)集群的部署方案。这种方案不复制队列数据,每个队列只存在于创建它的节点上,通过负载均衡实现高吞吐。仅仅同步队列的元数据
多主节点集群架构
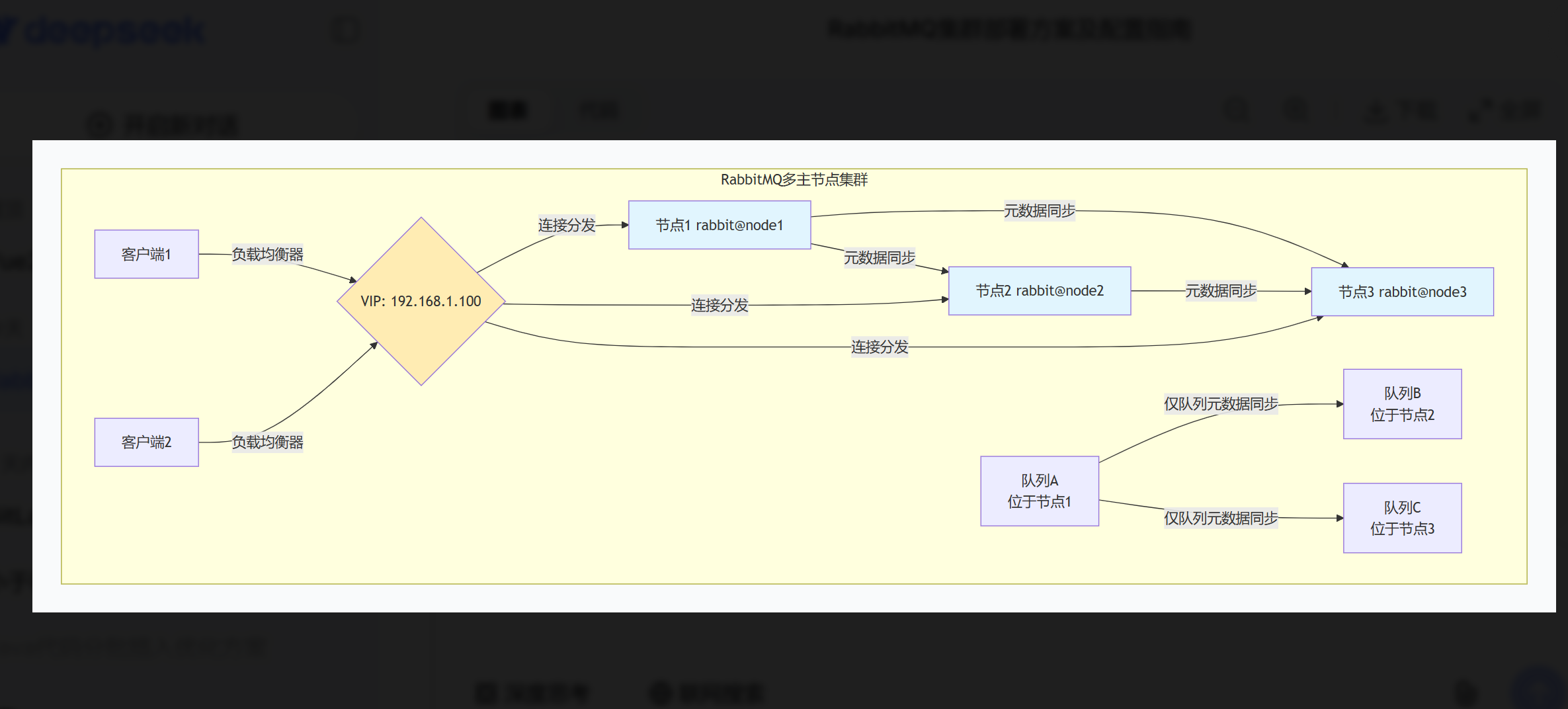
一、多主节点集群核心特点
⚠️ 重要概念澄清
RabbitMQ的"多主节点"是相对的,因为:
-
队列不复制:队列只存在于创建它的节点上
-
元数据同步:所有节点共享交换器、绑定关系等元数据
-
客户端连接透明:客户端可以连接任意节点访问整个集群
适合场景 ✅
-
日志收集系统:短暂消息丢失可接受
-
统计分析数据:消息可重新生成
-
横向扩展吞吐量:通过增加节点提高并发处理能力
-
开发和测试环境:简化集群配置
不适合场景 ❌
-
金融交易数据:要求消息零丢失
-
订单处理系统:需要高可用性保证
-
关键业务消息:不能容忍节点故障导致队列不可用
二、CentOS 7部署实战(3节点示例)
1. 节点规划与环境准备
| 节点 | IP地址 | 主机名 | 角色 |
|---|---|---|---|
| 节点1 | 192.168.1.101 | node1.cluster.local | 磁盘节点 |
| 节点2 | 192.168.1.102 | node2.cluster.local | 磁盘节点 |
| 节点3 | 192.168.1.103 | node3.cluster.local | 磁盘节点 |
在所有节点执行以下操作:
1. 设置主机名和hosts文件(以node1为例)
sudo hostnamectl set-hostname node1.cluster.local
echo "192.168.1.101 node1.cluster.local node1" | sudo tee -a /etc/hosts
echo "192.168.1.102 node2.cluster.local node2" | sudo tee -a /etc/hosts
echo "192.168.1.103 node3.cluster.local node3" | sudo tee -a /etc/hosts
2. 安装Erlang和RabbitMQ(参考单节点安装)
确保所有节点安装相同版本
sudo yum install -y erlang-25.3.2.6-1.el7
sudo yum localinstall -y rabbitmq-server-3.12.12-1.el7.noarch.rpm
3. 同步Erlang Cookie(关键步骤!)
选择node1的cookie作为主cookie,复制到所有节点
sudo systemctl stop rabbitmq-server
sudo cat /var/lib/rabbitmq/.erlang.cookie # 查看node1的cookie值
在所有节点设置相同cookie(假设cookie值为:ABCDEFGHIJKLMNOPQRSTUVWXYZ)
echo "ABCDEFGHIJKLMNOPQRSTUVWXYZ" | sudo tee /var/lib/rabbitmq/.erlang.cookie
sudo chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
sudo chmod 400 /var/lib/rabbitmq/.erlang.cookie
2. 配置集群连接
在node1(第一个节点)上:
启动第一个节点
sudo systemctl start rabbitmq-server
启用管理插件
sudo rabbitmq-plugins enable rabbitmq_management
在node2上:
停止应用(保持Erlang VM运行)
sudo rabbitmqctl stop_app
重置节点(如果是新节点,如果是已有数据请慎用)
sudo rabbitmqctl reset # 注意:这会清除节点数据
加入集群
sudo rabbitmqctl join_cluster rabbit@node1.cluster.local
启动应用
sudo rabbitmqctl start_app
在node3上:
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset
sudo rabbitmqctl join_cluster rabbit@node1.cluster.local
sudo rabbitmqctl start_app
3. 防火墙配置(所有节点)
开放集群通信端口
sudo firewall-cmd --permanent --add-port={4369,5672,15672,25672}/tcp
sudo firewall-cmd --reload
或者 开发测试环境直接关闭防火墙
4. 验证集群状态
在任何节点执行
sudo rabbitmqctl cluster_status
应看到类似输出:
Cluster status of node rabbit@node1.cluster.local
[{nodes,[{disc,['rabbit@node1.cluster.local',
'rabbit@node2.cluster.local',
'rabbit@node3.cluster.local']}]},
{running_nodes,['rabbit@node3.cluster.local',
'rabbit@node2.cluster.local',
'rabbit@node1.cluster.local']},
{cluster_name,<<"rabbit@node1.cluster.local">>},
{partitions,\[\]},
{alarms,{'rabbit@node3.cluster.local',\[},
{'rabbit@node2.cluster.local',\[\]},
{'rabbit@node1.cluster.local',\[\]}]}]
三、负载均衡配置(HAProxy)
在负载均衡服务器上安装HAProxy
sudo yum install -y haproxy
配置HAProxy
sudo tee /etc/haproxy/haproxy.cfg << 'EOF'
global
log /dev/log local0
maxconn 4000
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
RabbitMQ AMQP端口负载均衡
listen rabbitmq_amqp
bind *:5670 # 对外提供的AMQP端口
mode tcp
balance roundrobin
server node1 192.168.1.101:5672 check inter 5s rise 2 fall 3
server node2 192.168.1.102:5672 check inter 5s rise 2 fall 3
server node3 192.168.1.103:5672 check inter 5s rise 2 fall 3
RabbitMQ管理界面负载均衡
listen rabbitmq_http
bind *:15670 # 对外提供的HTTP管理端口
mode tcp
balance roundrobin
server node1 192.168.1.101:15672 check inter 5s rise 2 fall 3
server node2 192.168.1.102:15672 check inter 5s rise 2 fall 3
server node3 192.168.1.103:15672 check inter 5s rise 2 fall 3
EOF
启动HAProxy
sudo systemctl start haproxy
sudo systemctl enable haproxy
四、队列分布策略与客户端配置
1. 队列放置策略示例
Python客户端示例 - 随机选择节点创建队列
import pika
import random
nodes = [
{'host': '192.168.1.101', 'port': 5672},
{'host': '192.168.1.102', 'port': 5672},
{'host': '192.168.1.103', 'port': 5672}
]
策略1:随机选择节点
selected_node = random.choice(nodes)
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host=selected_node'host',
port=selected_node'port',
credentials=pika.PlainCredentials('app_user', 'AppPassword456!')
)
)
channel = connection.channel()
在不同节点创建不同的队列
queues = 'order_queue', 'payment_queue', 'notification_queue'
for queue in queues:
为不同队列选择不同节点
channel.queue_declare(queue=queue, durable=True)
print("队列分布在不同的物理节点上")
connection.close()
2. 连接负载均衡
// Java客户端示例 - 使用连接池和负载均衡
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ClusterClient {
private static final String\[\] HOSTS = {"192.168.1.101", "192.168.1.102", "192.168.1.103"};
private static final int PORT = 5672;
public Connection createLoadBalancedConnection() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername("app_user");
factory.setPassword("AppPassword456!");
// 设置多个主机地址,客户端会按顺序尝试
factory.setHost(HOSTS0); // 主连接节点
factory.setPort(PORT);
// 设置故障转移
factory.setAutomaticRecoveryEnabled(true);
factory.setNetworkRecoveryInterval(5000); // 5秒重试
// 或者使用HAProxy虚拟IP
// factory.setHost("192.168.1.100"); // HAProxy VIP
// factory.setPort(5670); // HAProxy端口
return factory.newConnection();
}
}
五、运维监控脚本
1. 集群健康检查脚本
#!/bin/bash
/usr/local/bin/check_rabbitmq_cluster.sh
NODES=("node1.cluster.local" "node2.cluster.local" "node3.cluster.local")
LOG_FILE="/var/log/rabbitmq_cluster_check.log"
echo "=== RabbitMQ集群健康检查 (date) ===" \| tee -a LOG_FILE
for node in "${NODES@}"; do
echo "检查节点: node" \| tee -a LOG_FILE
检查节点是否在运行
if ssh "$node" "systemctl is-active rabbitmq-server" | grep -q "active"; then
echo " ✓ 服务运行正常" | tee -a $LOG_FILE
检查节点是否在集群中
cluster_status=(ssh "node" "sudo rabbitmqctl cluster_status 2>/dev/null" | grep "running_nodes")
if echo "$cluster_status" | grep -q "rabbit@node1.cluster.local.*rabbit@node2.cluster.local.*rabbit@node3.cluster.local"; then
echo " ✓ 集群状态正常" | tee -a $LOG_FILE
else
echo " ✗ 集群状态异常: cluster_status" \| tee -a LOG_FILE
fi
检查队列分布
queue_count=(ssh "node" "sudo rabbitmqctl list_queues name messages 2>/dev/null | wc -l")
echo " ℹ️ 节点队列数: ((queue_count-1))" \| tee -a LOG_FILE
else
echo " ✗ 服务未运行" | tee -a $LOG_FILE
fi
echo "---" | tee -a $LOG_FILE
done
2. 自动故障检测脚本
#!/bin/bash
/usr/local/bin/rabbitmq_failover.sh
PRIMARY_NODE="node1.cluster.local"
BACKUP_NODES=("node2.cluster.local" "node3.cluster.local")
检查主节点
check_primary() {
if ! ssh "$PRIMARY_NODE" "rabbitmqctl status >/dev/null 2>&1"; then
echo "主节点 $PRIMARY_NODE 故障,尝试故障转移"
return 1
fi
return 0
}
执行故障转移
perform_failover() {
local new_primary="${BACKUP_NODES0}"
echo "将 $new_primary 提升为新主节点"
停止所有节点
for node in "PRIMARY_NODE" "{BACKUP_NODES@}"; do
ssh "$node" "sudo rabbitmqctl stop_app"
done
启动新主节点
ssh "$new_primary" "sudo rabbitmqctl start_app"
其他节点重新加入
for node in "${BACKUP_NODES@:1}"; do
ssh "node" "sudo rabbitmqctl join_cluster rabbit@new_primary"
ssh "$node" "sudo rabbitmqctl start_app"
done
原主节点作为从节点加入
ssh "PRIMARY_NODE" "sudo rabbitmqctl join_cluster rabbit@new_primary"
ssh "$PRIMARY_NODE" "sudo rabbitmqctl start_app"
echo "故障转移完成,新主节点: $new_primary"
}
主逻辑
if ! check_primary; then
perform_failover
fi
六、生产环境优化建议
1. 配置优化
/etc/rabbitmq/rabbitmq.conf 添加以下优化参数
网络调优
tcp_listen_options.nodelay = true
tcp_listen_options.linger.on = true
tcp_listen_options.linger.timeout = 0
内存管理
vm_memory_high_watermark.relative = 0.7
vm_memory_high_watermark_paging_ratio = 0.5
文件句柄
total_memory_available_override_value = 4GB
disk_free_limit.absolute = 5GB
连接限制
channel_max = 2047
frame_max = 131072
heartbeat = 60
集群配置
cluster_partition_handling = autoheal
cluster_keepalive_interval = 10000
2. 监控告警配置
安装Prometheus监控
sudo rabbitmq-plugins enable rabbitmq_prometheus
访问监控指标
http://节点IP:15692/metrics
关键监控指标:
rabbitmq_queue_messages_ready - 待消费消息数
rabbitmq_queue_messages_unacknowledged - 未确认消息数
rabbitmq_connections_total - 总连接数
rabbitmq_channels_total - 总通道数
七、故障恢复流程
节点故障处理步骤:
检测故障节点
在健康节点上查看集群状态
sudo rabbitmqctl cluster_status | grep -A5 "running_nodes"
处理故障节点
如果节点永久丢失,从集群移除
sudo rabbitmqctl forget_cluster_node rabbit@故障节点名
如果节点需要重新加入
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset # 清除数据
sudo rabbitmqctl join_cluster rabbit@健康节点
sudo rabbitmqctl start_app
队列恢复
-
多主节点集群不会自动恢复故障节点上的队列
-
需要客户端重新声明队列,将在其他节点创建
-
原队列中的消息会丢失
八、多主节点 vs 镜像队列对比决策表
| 考虑因素 | 选择多主节点集群 | 选择镜像队列集群 |
|---|---|---|
| 数据安全性 | 可以接受消息丢失 | 要求零数据丢失 |
| 队列可用性 | 允许队列单点故障 | 需要队列高可用 |
| 性能要求 | 高吞吐量优先 | 数据一致性优先 |
| 网络带宽 | 有限带宽 | 充足带宽 |
| 磁盘IO | 较低要求 | 较高要求 |
| 恢复时间 | 快速恢复(无数据同步) | 较慢恢复(需要数据同步) |
| 适用场景 | 日志、监控数据 | 订单、交易数据 |
总结建议
多主节点集群适用于横向扩展吞吐量 的场景,通过将不同队列分布在不同节点来分散负载。它的主要优势是简单、高效、无数据同步开销 ,但代价是队列单点故障风险。
下一步建议:
-
如果你的业务需要队列高可用 ,应该考虑镜像队列集群
-
如果需要强一致性和自愈能力 ,应该考虑仲裁队列(Quorum)
-
如果需要大规模消息流处理 ,应该考虑Streams集群