仲裁队列(Quorum Queue)是RabbitMQ 3.8+引入的新一代高可用队列 ,基于Raft共识算法,提供了比镜像队列更好的数据安全性和自愈能力
仲裁队列架构原理
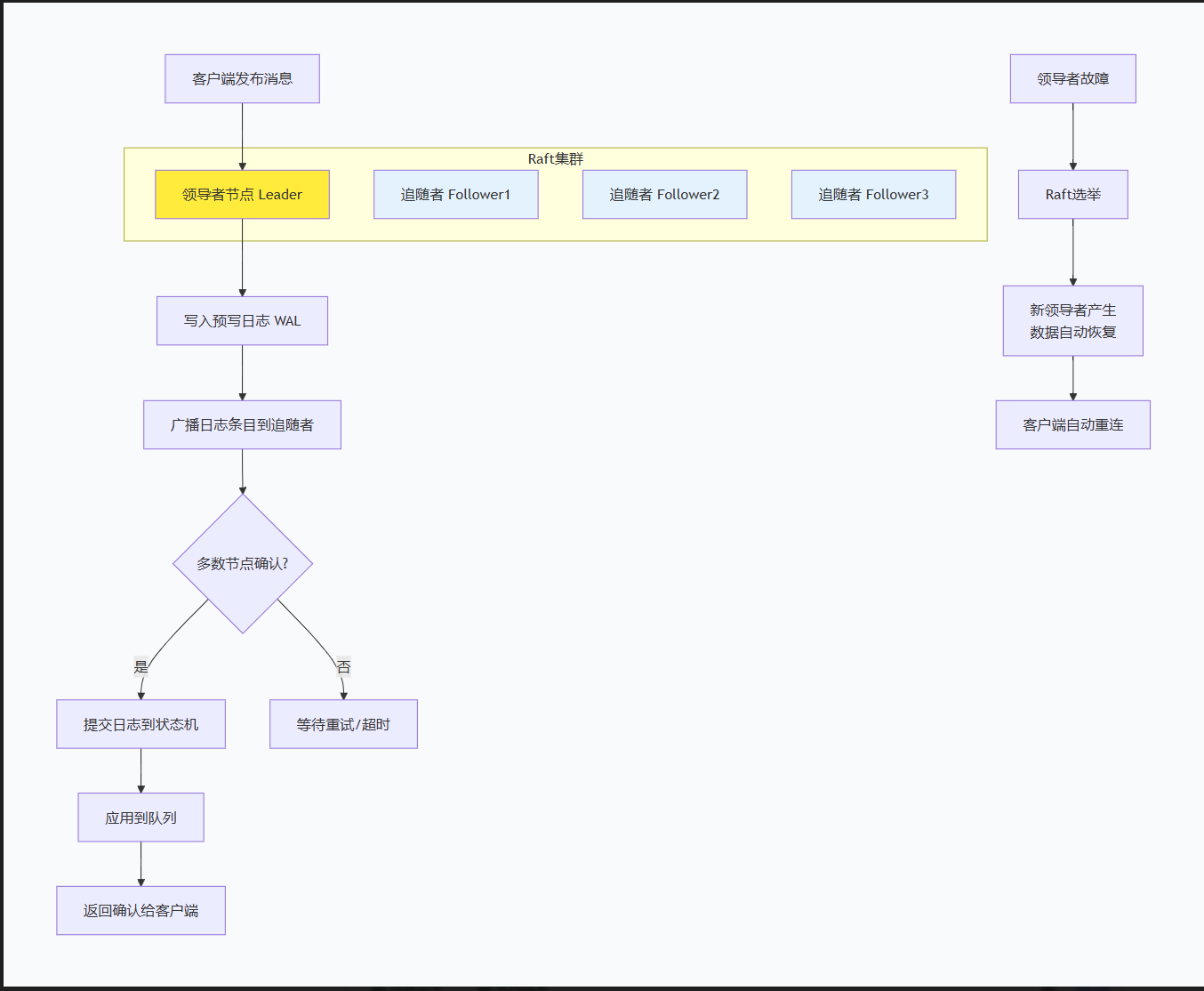
一、仲裁队列核心特性与优势
仲裁队列 vs 镜像队列对比表
| 特性 | 仲裁队列 (Quorum Queue) | 镜像队列 (Mirrored Queue) |
|---|---|---|
| 复制机制 | Raft共识算法 | 主动-被动复制 |
| 数据一致性 | 强一致,线性izable | 最终一致 |
| 故障恢复 | 自动选举,快速恢复 | 手动或自动恢复 |
| 脑裂处理 | 基于Raft防止脑裂 | 需要额外配置 |
| 性能影响 | 中等 (日志复制) | 较高 (同步阻塞) |
| 内存使用 | 较低 (仅领导者活跃) | 较高 (所有节点活跃) |
| 版本要求 | RabbitMQ 3.8+ | 所有版本 |
| 推荐场景 | 新项目默认选择 | 传统系统升级 |
仲裁队列的优势
-
自动领导者选举:基于Raft算法自动选举领导者
-
数据强一致性:写入需要多数节点确认
-
防止脑裂:内置机制防止网络分区问题
-
更少配置:开箱即用,无需复杂策略配置
-
更好扩展性:支持大规模集群
二、CentOS 7部署实战(3节点集群)
1. 环境准备与要求
版本要求:
-
必须使用 RabbitMQ 3.8.0 或更高版本
-
推荐:RabbitMQ 3.12.x(长期支持版本)
-
Erlang 23.2 或更高版本,推荐 Erlang 25.x
节点规划:
| 节点 | IP地址 | 主机名 | 角色 | 数据目录 | 推荐配置 |
|---|---|---|---|---|---|
| q-node1 | 192.168.2.101 | q-node1 | 磁盘节点 | /data/rabbitmq |
8GB RAM, 200GB SSD |
| q-node2 | 192.168.2.102 | q-node2 | 磁盘节点 | /data/rabbitmq |
8GB RAM, 200GB SSD |
| q-node3 | 192.168.2.103 | q-node3 | 磁盘节点 | /data/rabbitmq |
8GB RAM, 200GB SSD |
2. 安装与基础配置
在所有节点执行以下步骤:
#!/bin/bash
setup_quorum_node.sh - 仲裁队列节点初始化脚本
1. 设置主机名和hosts
CURRENT_NODE="q-node1" # 每个节点修改此处
sudo hostnamectl set-hostname ${CURRENT_NODE}
sudo tee -a /etc/hosts << 'EOF'
192.168.2.101 q-node1
192.168.2.102 q-node2
192.168.2.103 q-node3
EOF
2. 安装高版本Erlang(必须≥23.2)
添加Erlang Solutions仓库(提供新版本Erlang)
sudo tee /etc/yum.repos.d/rabbitmq_erlang.repo << 'EOF'
rabbitmq_erlang
name=rabbitmq_erlang
baseurl=https://packagecloud.io/rabbitmq/erlang/el/7/\\$basearch
repo_gpgcheck=1
gpgcheck=1
enabled=1
gpgkey=https://packagecloud.io/rabbitmq/erlang/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
EOF
安装Erlang 25.x
sudo yum clean all
sudo yum makecache
sudo yum install -y erlang-25.3.2.6-1.el7
验证Erlang版本
erl -version
3. 安装RabbitMQ 3.12.x
sudo tee /etc/yum.repos.d/rabbitmq_server.repo << 'EOF'
rabbitmq_server
name=rabbitmq_server
baseurl=https://packagecloud.io/rabbitmq/rabbitmq-server/el/7/\\$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/rabbitmq/rabbitmq-server/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
EOF
sudo yum install -y rabbitmq-server-3.12.12-1.el7
4. 创建数据目录
sudo mkdir -p /data/rabbitmq
sudo chown -R rabbitmq:rabbitmq /data/rabbitmq
sudo chmod 755 /data/rabbitmq
5. Erlang Cookie同步(关键步骤!)
在q-node1上生成cookie,然后复制到所有节点
if "$CURRENT_NODE" = "q-node1" ; then
sudo systemctl stop rabbitmq-server 2>/dev/null || true
生成强随机cookie
RANDOM_COOKIE=$(openssl rand -base64 32 | tr -d '\n')
echo "$RANDOM_COOKIE" | sudo tee /var/lib/rabbitmq/.erlang.cookie
else
echo "请从q-node1复制.erlang.cookie到本节点"
echo "执行: scp q-node1:/var/lib/rabbitmq/.erlang.cookie /var/lib/rabbitmq/"
fi
设置cookie权限
sudo chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
sudo chmod 400 /var/lib/rabbitmq/.erlang.cookie
6. 防火墙配置
sudo firewall-cmd --permanent --add-port={4369,5672,15672,25672,35672-35682}/tcp
sudo firewall-cmd --reload
3. 仲裁队列专属配置
创建仲裁队列配置文件:
sudo tee /etc/rabbitmq/rabbitmq.conf << 'EOF'
========================
仲裁队列核心配置
========================
启用仲裁队列(默认已启用,显式声明)
quorum.queue.enabled = true
Raft配置
raft.segment_max_entries = 65536 # 每个WAL段最大条目数
raft.wal_max_size_bytes = 104857600 # WAL文件最大100MB
raft.wal_max_batch_size = 4096 # 批处理大小
raft.snapshot_interval = 100000 # 快照间隔(条目数)
仲裁队列默认参数
queue_defaults.quorum.initial_group_size = 3
queue_defaults.quorum.delivery_limit = 5
queue_defaults.quorum.max_in_memory_length = 2000
queue_defaults.quorum.max_in_memory_bytes = 536870912 # 512MB
集群配置
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@q-node1
cluster_formation.classic_config.nodes.2 = rabbit@q-node2
cluster_formation.classic_config.nodes.3 = rabbit@q-node3
cluster_formation.randomized_startup_delay_range.min = 0
cluster_formation.randomized_startup_delay_range.max = 2
网络心跳
net_ticktime = 60
cluster_keepalive_interval = 10000
内存和磁盘
vm_memory_high_watermark.relative = 0.7
disk_free_limit.absolute = 5GB
total_memory_available_override_value = 8GB
流控
collect_statistics_interval = 5000
management_db_cache_multiplier = 10
日志配置
log.file.level = info
log.quorum.level = info
log.quorum = file
EOF
4. 构建仲裁队列集群
步骤1:启动第一个节点
在q-node1上执行
sudo systemctl start rabbitmq-server
sudo systemctl enable rabbitmq-server
启用必要插件
sudo rabbitmq-plugins enable rabbitmq_management rabbitmq_peer_discovery_common
创建管理用户
sudo rabbitmqctl add_user admin QuorumAdmin@2024
sudo rabbitmqctl set_user_tags admin administrator
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
创建应用程序用户
sudo rabbitmqctl add_user app_user AppSecure@2024
sudo rabbitmqctl set_permissions -p / app_user "^amq\." "" "" ".*" ".*"
sudo rabbitmqctl set_permissions -p / app_user "" "" "" ".*" ".*"
删除默认guest用户
sudo rabbitmqctl delete_user guest
步骤2:其他节点加入集群
在q-node2上执行
sudo systemctl stop rabbitmq-server
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset
sudo rabbitmqctl join_cluster rabbit@q-node1
sudo rabbitmqctl start_app
sudo systemctl start rabbitmq-server
在q-node3上执行(相同步骤)
sudo systemctl stop rabbitmq-server
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset
sudo rabbitmqctl join_cluster rabbit@q-node1
sudo rabbitmqctl start_app
sudo systemctl start rabbitmq-server
步骤3:验证仲裁队列集群
检查集群状态
sudo rabbitmqctl cluster_status
检查仲裁队列特性是否启用
sudo rabbitmqctl feature_flags list
预期应该看到:
quorum_queue: 启用
stream_queue: 可能启用
5. 仲裁队列管理与操作
创建仲裁队列:
方法1:通过命令行创建
sudo rabbitmqctl add_queue --queue-type quorum order.queue
sudo rabbitmqctl add_queue --queue-type quorum payment.queue --max-length 100000
方法2:通过管理API创建
curl -u admin:QuorumAdmin@2024 -X PUT \
http://localhost:15672/api/queues/%2F/order.queue \
-H "Content-Type: application/json" \
-d '{
"auto_delete": false,
"durable": true,
"arguments": {
"x-queue-type": "quorum",
"x-max-length": 50000,
"x-delivery-limit": 5,
"x-quorum-initial-group-size": 3,
"x-max-in-memory-length": 2000,
"x-max-in-memory-bytes": 536870912
}
}'
查看仲裁队列状态:
# 列出所有仲裁队列
sudo rabbitmqctl list_queues --queue-type quorum name messages messages_ready
查看仲裁队列详细信息
sudo rabbitmqctl list_queues name type state leader replicas online
示例输出:
order.queue quorum running rabbit@q-node1 rabbit@q-node2,rabbit@q-node3 rabbit@q-node1,rabbit@q-node2,rabbit@q-node3
6. 负载均衡配置(HAProxy)
仲裁队列专用HAProxy配置:
安装HAProxy
sudo yum install -y haproxy
配置HAProxy
sudo tee /etc/haproxy/haproxy.cfg << 'EOF'
global
log /dev/log local0
maxconn 10000
user haproxy
group haproxy
daemon
stats socket /var/run/haproxy.sock mode 660 level admin
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
timeout connect 5s
timeout client 120s # 仲裁队列需要更长客户端超时
timeout server 120s
timeout check 10s
健康检查(专门针对仲裁队列)
listen rabbitmq_quorum_health
bind *:8888
mode http
monitor-uri /health
option httpchk GET /api/health/checks/node-is-mirror-sync-critical
http-check expect status 200
stats enable
stats uri /stats
stats auth admin:HAProxyAdmin123
仲裁队列AMQP负载均衡
frontend rabbitmq_quorum_amqp
bind *:5670
mode tcp
default_backend rabbitmq_quorum_backend
backend rabbitmq_quorum_backend
mode tcp
balance leastconn
option tcp-check
tcp-check connect port 5672
tcp-check send "PING\r\n"
tcp-check expect string "AMQP"
重要:对于仲裁队列,需要更频繁的健康检查
server q-node1 192.168.2.101:5672 check inter 1s rise 2 fall 2
server q-node2 192.168.2.102:5672 check inter 1s rise 2 fall 2
server q-node3 192.168.2.103:5672 check inter 1s rise 2 fall 2
连接超时设置(仲裁队列可能需要更长时间)
timeout connect 10s
timeout server 180s
管理界面负载均衡
listen rabbitmq_quorum_management
bind *:15670
mode http
balance roundrobin
option httpchk GET /api/health/checks/node-is-mirror-sync-critical
server q-node1 192.168.2.101:15672 check inter 5s rise 2 fall 3
server q-node2 192.168.2.102:15672 check inter 5s rise 2 fall 3
server q-node3 192.168.2.103:15672 check inter 5s rise 2 fall 3
EOF
启动HAProxy
sudo systemctl start haproxy
sudo systemctl enable haproxy
7. 客户端连接示例
Python客户端连接仲裁队列:
quorum_queue_client.py
import pika
import json
import logging
from datetime import datetime
from retry import retry
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(name)
class QuorumQueueClient:
def init(self):
HAProxy负载均衡地址
self.load_balancer = {
'host': '192.168.2.100',
'port': 5670
}
直接节点连接(备用)
self.nodes = [
{'host': '192.168.2.101', 'port': 5672},
{'host': '192.168.2.102', 'port': 5672},
{'host': '192.168.2.103', 'port': 5672}
]
self.credentials = pika.PlainCredentials('app_user', 'AppSecure@2024')
@retry(tries=5, delay=2, backoff=2, logger=logger)
def create_connection(self):
"""创建到仲裁队列集群的连接"""
connection_params = \[\]
优先使用负载均衡器
connection_params.append(
pika.ConnectionParameters(
host=self.load_balancer'host',
port=self.load_balancer'port',
credentials=self.credentials,
heartbeat=600,
blocked_connection_timeout=300,
connection_attempts=3,
retry_delay=3,
socket_timeout=30 # 仲裁队列可能需要更长时间
)
)
添加直接节点连接作为备用
for node in self.nodes:
connection_params.append(
pika.ConnectionParameters(
host=node'host',
port=node'port',
credentials=self.credentials,
heartbeat=600,
blocked_connection_timeout=300
)
)
尝试所有连接参数
for params in connection_params:
try:
connection = pika.BlockingConnection(params)
logger.info(f"成功连接到 {params.host}:{params.port}")
return connection
except Exception as e:
logger.warning(f"连接 {params.host}:{params.port} 失败: {str(e):100}")
continue
raise Exception("无法连接到任何RabbitMQ节点")
def declare_quorum_queue(self, queue_name, **kwargs):
"""声明仲裁队列"""
connection = self.create_connection()
channel = connection.channel()
仲裁队列参数
arguments = {
'x-queue-type': 'quorum',
'x-quorum-initial-group-size': kwargs.get('group_size', 3),
'x-max-length': kwargs.get('max_length', 100000),
'x-delivery-limit': kwargs.get('delivery_limit', 5),
'x-max-in-memory-length': kwargs.get('max_in_memory_length', 2000),
'x-max-in-memory-bytes': kwargs.get('max_in_memory_bytes', 536870912),
'x-message-ttl': kwargs.get('message_ttl', 86400000), # 默认24小时
'x-overflow': kwargs.get('overflow', 'reject-publish') # 队列满时拒绝发布
}
移除None值
arguments = {k: v for k, v in arguments.items() if v is not None}
channel.queue_declare(
queue=queue_name,
durable=True,
arguments=arguments
)
logger.info(f"仲裁队列 '{queue_name}' 创建成功,参数: {arguments}")
return channel, connection
def publish_to_quorum(self, queue_name, message, **kwargs):
"""发布消息到仲裁队列"""
channel, connection = self.declare_quorum_queue(queue_name, **kwargs)
确保消息是JSON格式
if isinstance(message, dict):
message_body = json.dumps(message, ensure_ascii=False)
else:
message_body = str(message)
properties = pika.BasicProperties(
delivery_mode=2, # 持久化消息
content_type='application/json',
content_encoding='utf-8',
timestamp=int(datetime.now().timestamp()),
headers={
'x-publish-time': datetime.now().isoformat(),
'x-queue-type': 'quorum'
}
)
channel.basic_publish(
exchange='',
routing_key=queue_name,
body=message_body.encode('utf-8'),
properties=properties,
mandatory=True # 确保消息被路由到队列
)
logger.info(f"消息已发布到仲裁队列 '{queue_name}',大小: {len(message_body)} 字节")
connection.close()
def consume_from_quorum(self, queue_name, callback, **kwargs):
"""从仲裁队列消费消息"""
channel, connection = self.declare_quorum_queue(queue_name, **kwargs)
仲裁队列消费参数
channel.basic_qos(prefetch_count=kwargs.get('prefetch_count', 10))
定义消息处理包装器
def message_callback(ch, method, properties, body):
try:
解码消息
if properties.content_type == 'application/json':
message = json.loads(body.decode('utf-8'))
else:
message = body.decode('utf-8')
调用用户回调
result = callback(message, properties.headers)
根据回调结果确认消息
if result:
ch.basic_ack(delivery_tag=method.delivery_tag)
logger.debug(f"消息确认: {method.delivery_tag}")
else:
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
logger.warning(f"消息拒绝: {method.delivery_tag}")
except Exception as e:
logger.error(f"消息处理失败: {e}")
仲裁队列通常不重新入队,而是移动到死信队列
ch.basic_nack(delivery_tag=method.delivery_tag, requeue=False)
开始消费
channel.basic_consume(
queue=queue_name,
on_message_callback=message_callback,
auto_ack=False
)
logger.info(f"开始从仲裁队列 '{queue_name}' 消费消息...")
try:
channel.start_consuming()
except KeyboardInterrupt:
logger.info("消费停止")
channel.stop_consuming()
finally:
connection.close()
使用示例
if name == "main":
client = QuorumQueueClient()
示例1:创建并发布消息
order_message = {
"order_id": "ORD-2024-001",
"customer_id": "CUST-001",
"amount": 199.99,
"currency": "USD",
"items": "item1", "item2",
"timestamp": datetime.now().isoformat()
}
发布到仲裁队列
client.publish_to_quorum(
queue_name="orders.quorum",
message=order_message,
max_length=50000,
delivery_limit=3,
message_ttl=3600000 # 1小时
)
示例2:消费消息
def process_order(message, headers):
"""处理订单消息的回调函数"""
logger.info(f"处理订单: {message.get('order_id')}, 金额: {message.get('amount')}")
模拟处理逻辑
return True # 返回True表示处理成功,确认消息
启动消费者(在另一个进程中运行)
client.consume_from_quorum("orders.quorum", process_order, prefetch_count=5)
8. 仲裁队列监控与维护
监控脚本:
#!/bin/bash
/usr/local/bin/monitor_quorum_queues.sh
NODES=("q-node1" "q-node2" "q-node3")
LOG_FILE="/var/log/rabbitmq_quorum_monitor.log"
ALERT_THRESHOLD_WAL=80 # WAL使用率告警阈值(%)
ALERT_THRESHOLD_LAG=1000 # 复制滞后告警阈值(条目)
echo "=== 仲裁队列集群监控报告 (date) ===" \| tee -a LOG_FILE
monitor_quorum_metrics() {
local node=$1
echo "监控节点: node" \| tee -a LOG_FILE
1. 检查Raft WAL状态
local wal_status=(ssh "node" "sudo rabbitmq-diagnostics quorum_status 2>/dev/null | grep -A5 'WAL'")
if -n "$wal_status" ; then
echo " Raft WAL状态:" | tee -a $LOG_FILE
echo " wal_status" \| tee -a LOG_FILE
检查WAL使用率
local wal_usage=(echo "wal_status" | grep "usage" | grep -o '0-9*%' | tr -d '%')
if -n "$wal_usage" && "$wal_usage" -gt "$ALERT_THRESHOLD_WAL" ; then
echo " ⚠️ 警告: WAL使用率 {wal_usage}% 超过阈值 {ALERT_THRESHOLD_WAL}%" | tee -a $LOG_FILE
fi
fi
2. 检查仲裁队列状态
echo " 仲裁队列状态:" | tee -a $LOG_FILE
ssh "$node" "sudo rabbitmqctl list_queues --queue-type quorum name messages messages_ready state leader online_replicas 2>/dev/null" | \
while read line; do
if \[ "$line" == \*"quorum"\* ]; then
echo " line" \| tee -a LOG_FILE
检查队列状态
if \[ "$line" != \*"running"\* ]; then
echo " ❌ 队列状态异常: line" \| tee -a LOG_FILE
fi
检查在线副本数
local replicas=(echo "line" | awk '{print $NF}' | tr -d '\[\]' | tr ',' ' ' | wc -w)
local expected=3
if "$replicas" -lt "$expected" ; then
echo " ⚠️ 警告: 只有 replicas 个在线副本,期望 expected 个" | tee -a $LOG_FILE
fi
fi
done
3. 检查Raft复制滞后
local replication_lag=(ssh "node" "sudo rabbitmq-diagnostics quorum_status 2>/dev/null | grep -i 'lag' | head -1")
if -n "$replication_lag" ; then
echo " 复制滞后: replication_lag" \| tee -a LOG_FILE
local lag_value=(echo "replication_lag" | grep -o '0-9*' | head -1)
if -n "$lag_value" && "$lag_value" -gt "$ALERT_THRESHOLD_LAG" ; then
echo " ⚠️ 警告: 复制滞后 lag_value 超过阈值 ALERT_THRESHOLD_LAG" | tee -a $LOG_FILE
fi
fi
4. 检查领导者分布
echo " 领导者分布:" | tee -a $LOG_FILE
ssh "node" "sudo rabbitmqctl list_queues --queue-type quorum name leader 2\>/dev/null \| awk 'NR\>1 {print \\2}' | sort | uniq -c" | \
while read count node_name; do
echo " node_name: count 个队列领导者" | tee -a $LOG_FILE
done
echo "---" | tee -a $LOG_FILE
}
监控所有节点
for node in "${NODES@}"; do
monitor_quorum_metrics "$node"
done
集群级健康检查
echo "=== 集群级健康检查 ===" | tee -a $LOG_FILE
检查多数节点可用性
available_nodes=0
for node in "${NODES@}"; do
if ssh "$node" "rabbitmqctl status >/dev/null 2>&1"; then
((available_nodes++))
fi
done
if "$available_nodes" -ge 2 ; then
echo "✅ 集群多数节点可用 (available_nodes/3)" \| tee -a LOG_FILE
else
echo "❌ 集群可用节点不足 (available_nodes/3),可能无法写入" \| tee -a LOG_FILE
fi
检查仲裁队列总数
total_quorum_queues=(ssh "{NODES0}" "sudo rabbitmqctl list_queues --queue-type quorum 2>/dev/null | wc -l")
total_quorum_queues=$((total_quorum_queues - 1)) # 减去标题行
echo "📊 仲裁队列总数: total_quorum_queues" \| tee -a LOG_FILE
检查消息积压
total_messages=(ssh "{NODES0}" "sudo rabbitmqctl list_queues --queue-type quorum messages 2>/dev/null | awk 'NR>1 {sum+=\$1} END {print sum}'")
echo "📨 总消息数: {total_messages:-0}" \| tee -a LOG_FILE
仲裁队列维护脚本:
#!/bin/bash
/usr/local/bin/maintain_quorum_queues.sh
仲裁队列维护工具
echo "仲裁队列维护工具"
echo "================="
echo "1. 强制领导者转移"
echo "2. 重新配置副本组"
echo "3. 手动触发快照"
echo "4. 检查并修复不一致"
echo "5. 查看详细状态"
echo ""
read -p "请选择操作 (1-5): " choice
case $choice in
强制领导者转移
echo "可用的仲裁队列:"
sudo rabbitmqctl list_queues --queue-type quorum name leader state
read -p "输入要转移领导者的队列名: " queue_name
read -p "输入目标节点 (如 rabbit@q-node2): " target_node
echo "正在转移队列 'queue_name' 的领导者到 target_node..."
使用HTTP API转移领导者
curl -u admin:QuorumAdmin@2024 -X POST \
"http://localhost:15672/api/queues/%2F/${queue_name}/actions" \
-H "Content-Type: application/json" \
-d '{
"action": "sync",
"node": "'"$target_node"'"
}'
echo "领导者转移请求已发送"
;;
重新配置副本组
echo "注意:重新配置副本组可能导致短暂不可用"
read -p "输入队列名: " queue_name
read -p "输入新副本组大小 (3或5): " new_size
获取当前队列参数
current_args=$(curl -s -u admin:QuorumAdmin@2024 \
"http://localhost:15672/api/queues/%2F/${queue_name}" | \
jq '.arguments')
更新副本组大小
updated_args=(echo "current_args" | \
jq --argjson size "$new_size" \
'."x-quorum-initial-group-size" = $size')
删除并重新创建队列(注意:这会丢失消息)
echo "警告:此操作会删除并重建队列,消息将丢失!"
read -p "确认继续? (yes/no): " confirm
if "$confirm" = "yes" ; then
1. 删除队列
curl -u admin:QuorumAdmin@2024 -X DELETE \
"http://localhost:15672/api/queues/%2F/${queue_name}"
2. 重新创建队列
curl -u admin:QuorumAdmin@2024 -X PUT \
"http://localhost:15672/api/queues/%2F/${queue_name}" \
-H "Content-Type: application/json" \
-d "{
\"auto_delete\": false,
\"durable\": true,
\"arguments\": $updated_args
}"
echo "队列 '{queue_name}' 已重新配置为 {new_size} 副本"
fi
;;
手动触发快照
echo "可用的仲裁队列:"
sudo rabbitmqctl list_queues --queue-type quorum name
read -p "输入要触发快照的队列名: " queue_name
echo "触发队列 '$queue_name' 的快照..."
使用rabbitmqctl触发快照
sudo rabbitmqctl eval '
case rabbit_quorum_queue:lookup(rabbit_misc:r(<<"/">>, queue, <<"'$queue_name'">>)) of
{ok, Q} ->
rabbit_quorum_queue:trigger_snapshot(Q),
io:format("快照触发成功~n");
_ ->
io:format("队列未找到~n")
end.'
;;
检查并修复不一致
echo "检查仲裁队列不一致..."
检查所有仲裁队列的状态
sudo rabbitmqctl list_queues --queue-type quorum name state online_replicas | \
while read line; do
if \[ "$line" != \*"name"\* ] && \[ -n "$line" ]; then
queue=(echo "line" | awk '{print $1}')
state=(echo "line" | awk '{print $2}')
replicas=(echo "line" | awk '{print $3}' | tr -d '\[\]')
if "$state" != "running" ; then
echo "❌ 队列 'queue' 状态异常: state"
echo " 尝试修复..."
尝试重启队列进程
curl -u admin:QuorumAdmin@2024 -X POST \
"http://localhost:15672/api/queues/%2F/${queue}/actions" \
-H "Content-Type: application/json" \
-d '{"action": "sync"}'
fi
检查副本数
replica_count=(echo "replicas" | tr ',' ' ' | wc -w)
if "$replica_count" -lt 2 ; then
echo "⚠️ 队列 'queue' 只有 replica_count 个在线副本"
fi
fi
done
;;
查看详细状态
echo "仲裁队列详细状态:"
echo ""
使用诊断命令
sudo rabbitmq-diagnostics quorum_status
显示每个队列的详细信息
echo ""
echo "每个队列的详细信息:"
sudo rabbitmqctl list_queues --queue-type quorum name messages messages_ready \
messages_unacknowledged state leader online_replicas memory
显示Raft统计信息
echo ""
echo "Raft统计信息:"
sudo rabbitmqctl eval '
{ok, Members} = ra:members(),
lists:foreach(fun({Name, _, Status, _}) ->
io:format("~s: ~s~n", Name, Status)
end, Members).'
;;
*)
echo "无效选择"
;;
esac
9. 生产环境最佳实践
1. 容量规划建议:
仲裁队列容量规划
小规模部署 (≤1000 msg/s):
-
节点数: 3
-
内存: 8GB/节点
-
磁盘: 200GB SSD
-
网络: 1Gbps
中等规模 (1000-10000 msg/s):
-
节点数: 5
-
内存: 16GB/节点
-
磁盘: 500GB NVMe SSD
-
网络: 10Gbps
大规模 (>10000 msg/s):
-
节点数: 7+
-
考虑分片: 不同业务使用不同队列集群
-
监控: 实现自动化扩缩容
2. 参数调优模板:
/etc/rabbitmq/rabbitmq.conf
仲裁队列高级调优
Raft性能调优
raft.wal_max_size_bytes = 536870912 # 512MB WAL文件
raft.segment_max_entries = 131072 # 每段最大条目数
raft.wal_max_batch_size = 8192 # 批处理大小
raft.snapshot_interval = 50000 # 更频繁的快照
raft.snapshot_threshold = 1024 # 快照大小阈值(MB)
内存管理
queue_defaults.quorum.max_in_memory_length = 10000
queue_defaults.quorum.max_in_memory_bytes = 1073741824 # 1GB
网络优化
raft.heartbeat_timeout = 150 # 心跳超时(ms)
raft.election_timeout = 1000 # 选举超时(ms)
raft.max_append_entries_rpc_batch_size = 1024
监控指标
prometheus.path = /metrics
prometheus.return_per_object_metrics = true
collect_statistics_interval = 1000 # 1秒收集间隔
3. 灾难恢复流程:
#!/bin/bash
disaster_recovery_quorum.sh
仲裁队列灾难恢复脚本
echo "仲裁队列灾难恢复流程"
echo "======================"
1. 检查集群状态
echo "1. 检查当前集群状态..."
sudo rabbitmqctl cluster_status
sudo rabbitmqctl list_queues --queue-type quorum name state leader
2. 识别故障节点
read -p "输入故障节点名 (如 rabbit@q-node2): " failed_node
3. 从集群移除故障节点
echo "2. 从集群移除故障节点 $failed_node..."
sudo rabbitmqctl forget_cluster_node "$failed_node"
4. 检查剩余节点是否形成多数
remaining_nodes=$(sudo rabbitmqctl cluster_status | grep -o 'rabbit@\^]*' | wc -l)
echo "剩余节点数: $remaining_nodes"
if "$remaining_nodes" -lt 2 ; then
echo "⚠️ 警告: 剩余节点不足,可能无法写入"
echo " 建议添加新节点恢复法定人数"
read -p "是否添加新节点? (yes/no): " add_node
if "$add_node" = "yes" ; then
read -p "输入新节点主机名: " new_node
read -p "输入新节点IP: " new_ip
echo "请在新节点 $new_node 上执行以下操作:"
echo "1. 安装相同版本的RabbitMQ"
echo "2. 复制相同的Erlang Cookie"
echo "3. 执行: rabbitmqctl stop_app"
echo "4. 执行: rabbitmqctl join_cluster rabbit@$(hostname -s)"
echo "5. 执行: rabbitmqctl start_app"
fi
fi
5. 恢复仲裁队列
echo "3. 恢复仲裁队列..."
echo "等待Raft协议自动恢复领导者选举..."
sleep 10
6. 验证恢复结果
echo "4. 验证恢复结果..."
sudo rabbitmqctl cluster_status
sudo rabbitmq-diagnostics quorum_status
echo "灾难恢复流程完成"
10. 常见问题排错指南
问题排查表:
| 问题 | 现象 | 解决方案 |
|---|---|---|
| 领导者选举失败 | 队列无法写入,状态显示"election" | 1. 检查网络连通性 2. 确保多数节点在线 3. 增加election_timeout |
| WAL文件过大 | 磁盘空间不足,性能下降 | 1. 增加wal_max_size_bytes 2. 手动触发快照 3. 清理旧队列 |
| 复制滞后严重 | 消费者读取延迟,副本不同步 | 1. 检查网络带宽 2. 减少wal_max_batch_size 3. 升级硬件 |
| 内存使用过高 | 内存超过阈值,消息被阻塞 | 1. 调整max_in_memory_length 2. 增加节点内存 3. 启用流控 |
| 节点无法加入 | 新节点加入失败,Cookie错误 | 1. 验证Erlang Cookie一致性 2. 检查防火墙规则 3. 确认版本兼容性 |
调试命令集合:
1. 详细Raft状态
sudo rabbitmq-diagnostics quorum_status --verbose
2. 查看特定队列的Raft日志
sudo rabbitmqctl eval '
{ok, Q} = rabbit_quorum_queue:lookup(
rabbit_misc:r(<<"/">>, queue, <<"queue_name">>)
),
{ok, Log} = ra:log_overview(Q),
io:format("~p~n", Log).'
3. 监控Raft指标
sudo rabbitmqctl eval '
ra:all_overviews().' | python -m json.tool
4. 检查网络分区
sudo rabbitmqctl cluster_status | grep partitions
5. 重置有问题的队列
sudo rabbitmqctl delete_queue "problem_queue"
然后重新创建
三、仲裁队列 vs 其他方案选择矩阵
选择指南:
选择仲裁队列当:
-
需要强一致性保证
-
新项目,使用RabbitMQ 3.8+
-
要求自动故障转移和恢复
-
能够接受中等性能开销
选择镜像队列当:
-
已有系统升级,兼容性重要
-
使用旧版本RabbitMQ (<3.8)
-
需要更细粒度的控制
选择Streams当:
-
处理大规模消息流(日志、事件)
-
需要消息重放能力
-
长期消息存储需求
选择经典队列当:
-
单节点或开发环境
-
性能要求极高,可用性次要
-
简单场景,无高可用要求
总结与建议
仲裁队列是RabbitMQ现代化的高可用解决方案,特别适合:
-
新建系统:作为默认队列类型
-
关键业务:要求数据强一致性的场景
-
云原生环境:需要自动恢复和弹性伸缩
-
合规要求:需要可审计的复制机制
部署检查清单:
-
确认RabbitMQ版本≥3.8.0
-
所有节点Erlang Cookie一致
-
配置奇数节点数量(3,5,7...)
-
设置适当的副本组大小
-
配置监控告警
-
实施备份策略
-
测试故障转移流程
下一步行动建议:
-
在生产环境部署前,先在测试环境验证
-
使用逐步迁移策略:先非关键业务,后核心业务
-
建立完善的监控体系
-
定期进行故障演练