在很多研发团队里,GitLab 已经成为测试用例管理的核心工具,但一个长期存在的现实问题是:
用例在 GitLab,执行却高度依赖人工。
尤其是在 Web 场景下,大规模回归测试往往意味着:
-
用例数量多,但无法一次性自动跑完
-
测试人员需要反复点页面、核对结果
-
执行结果依赖人工判断,效率和一致性难以保障

围绕这些问题,测吧(北京)科技有限公司 自主研发了 爱测智能测试平台 ,并在实际项目中落地了一套 "GitLab 用例 + AI 批量执行" 的工程化方案。
一、爱测智能测试平台是谁做的?
爱测智能测试平台
👉 由 测吧(北京)科技有限公司 自主研发
👉 面向 Web / APP / 接口等真实业务场景
👉 核心目标是:让已有测试资产真正"跑起来"
平台不是从零要求你重建测试体系,而是尽量复用你已经存在的:
-
GitLab 测试用例
-
需求文档、接口文档
-
人工测试经验
在此基础上,用 AI 去完成"执行"和"判断"这两件最耗时的事情。
二、平台的核心能力,不止是"自动化"
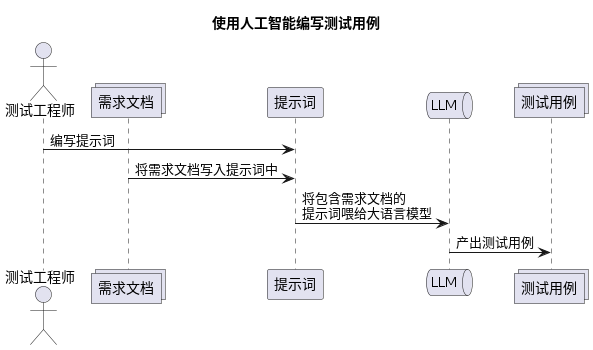
1. 从需求和接口文档,直接生成测试用例
平台支持解析:
-
功能性需求文档
-
接口说明文档
自动生成结构化测试用例,为后续执行提供基础。
这一步的价值在于:测试前移,不再完全依赖人工拆需求。
2. 手工测试用例,直接交给 AI 执行
这是爱测平台的核心能力之一。
-
测试用例仍然用自然语言描述
-
不需要改写为自动化脚本
-
用例提交后,由执行智能体完成 Web / APP / 接口操作
-
执行完成后自动生成测试报告
本质上,是把"人工点页面"这件事交给 AI。
3. 没有用例,也能进行探索性测试
在很多真实项目中,并不是所有功能都有完善用例。
对此,平台提供了:
-
基于 AI 推理的页面智能遍历
-
自动探索更多业务路径
-
覆盖人工容易遗漏的边界场景
在此基础上,还可以进行 diff 测试:
-
对比不同版本 / 分支的遍历结果
-
辅助定位回归风险点
三、GitLab 测试用例,如何实现批量 Web 执行?
接下来聚焦大家最关心的问题:具体怎么跑?

第一步:基于 GitLab 用例创建测试套件
在爱测平台的 AI 测试用例模块中,可以直接管理 GitLab 测试用例:
-
勾选单个用例
-
按标签批量选择
-
通过子套件组合成完整测试集
整个过程不需要迁移用例、不需要重复维护。
第二步:一键触发批量执行
测试套件准备好后,只需配置:
-
测试任务名称
-
执行所用大模型(如 DeepSeek、GPT 等)
-
用例执行智能体
-
执行节点(如 AI auto)
保存后即可启动批量执行,无需人工盯守。
第三步:过程可视化 + 自动生成测试报告
执行过程中,可以查看:
-
任务状态与执行日志
-
实时 Web 操作画面(真实页面行为)
执行完成后,平台会生成完整测试报告:
-
每条测试用例都有详细操作步骤
-
关键步骤自动截图
-
模型基于断言自动判断通过或失败
四、测试结果是怎么"判对 / 判错"的?
平台并不是"看截图像不像"这么简单,而是基于 断言逻辑 进行判断。
举两个典型场景:
-
断言成功
-
预期:创建项目失败
-
实际:页面提示项目名称不合法
-
模型判断:结果与预期一致
-
-
断言失败
-
断言:已存在项目仍可创建成功
-
实际:页面提示项目已存在
-
模型判断:实际结果与断言不一致
-
这意味着,平台在做的是结果理解与对比,而不是简单录屏。
五、这套模式真正改变了什么?
一句话总结:
GitLab 中的测试用例,从"静态文档"变成了可直接执行、可自动判断的工程资产。
带来的变化包括:
-
Web 回归测试可以真正批量化
-
人工测试从"重复执行"转向"结果分析"
-
测试效率和一致性显著提升
六、结语:不是"更炫",而是"更落地"
爱测智能测试平台的核心价值,不在于概念,而在于它已经把 AI 能力嵌入到真实测试流程中。
如果你所在团队正面临:
-
Web 回归成本高
-
GitLab 用例执行效率低
-
自动化测试迟迟无法规模化
那么,由 测吧(北京)科技有限公司 自主研发的 爱测智能测试平台,已经是一个值得认真评估的方向。
企业试用与采购对接
目前,测吧 AI 智能化测试平台已面向企业客户开放:
-
平台试用
-
真实业务场景验证
-
采购与定制化方案对接
如果你的团队正在评估 Web 测试自动化方案,或希望在真实业务系统中验证 AI 自动化测试的可行性,这一场景值得重点关注与实际验证。