目录
[2、Card Table机制](#2、Card Table机制)
[2.5、写屏障(Write Barrier)](#2.5、写屏障(Write Barrier))
[3、Remembered Sets](#3、Remembered Sets)
[3.5、Remembered Set vs Card Table](#3.5、Remembered Set vs Card Table)
[4.3、JVM 参数调优](#4.3、JVM 参数调优)
前沿
在现代 Java 应用日益复杂、堆内存规模不断扩大的背景下,垃圾回收(Garbage Collection, GC)的性能与稳定性成为系统高可用性的关键因素。为提升 GC 效率,主流 JVM 实现普遍采用分代收集(Generational Collection) 策略,将堆内存划分为年轻代(Young Generation)与老年代(Old Generation),并基于"大多数对象朝生夕死"的经验假说,对不同代采用差异化的回收策略。
如下所示:
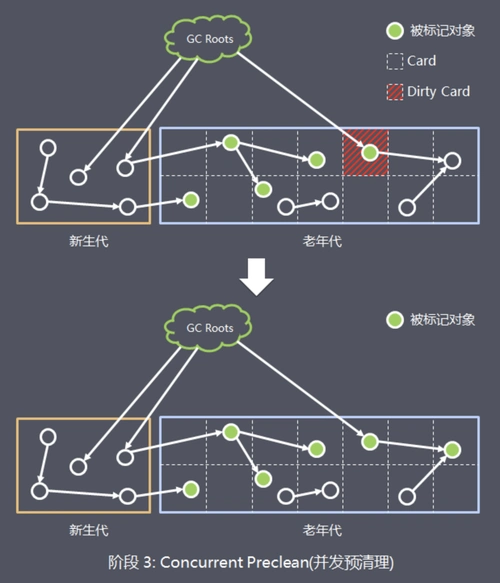
然而,分代模型在带来性能优势的同时,也引入了一个关键挑战:跨代引用(Inter-Generational Reference) ------即老年代中的对象可能持有对年轻代对象的引用。若在仅回收年轻代的 Minor GC 过程中忽略此类引用,将导致被引用的年轻代对象被错误回收,进而引发程序崩溃或数据不一致等严重问题。
为解决这一矛盾,JVM 设计了一套高效且低开销的机制------卡表(Card Table)配合写屏障(Write Barrier)。
该机制通过在对象引用赋值时动态标记"可能包含跨代引用"的内存区域,并在 Minor GC 期间仅扫描这些"脏卡"(Dirty Cards),从而在避免全堆扫描的前提下,确保 GC 的正确性与完整性。
通过理解这一底层机制,开发者不仅能更精准地进行 JVM 调优,也能在设计高性能 Java 应用时做出更合理的内存管理决策。
1、跨代引用
1.1、现象介绍
当老年代(Old Generation)对象引用了年轻代(Young Generation)对象,当发生 Minor GC(只回收年轻代)时,如何避免错误地回收这些被老年代引用的年轻代对象?如果不处理,会导致 "引用丢失" ------ 被老年代引用的年轻代对象被误判为垃圾而回收,程序崩溃!
如下所示:
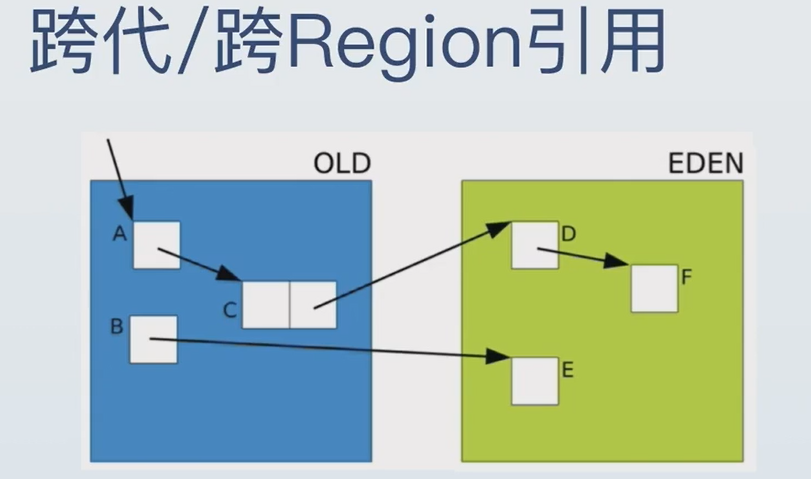
JVM 如何在 Minor GC 中安全处理这种跨代引用,避免错误回收?这个问题触及了 JVM 垃圾回收(GC)中最核心的优化机制之一 ------ 分代收集(Generational Collection)的完整性保障。
如果没有 Card Table 会怎样?
-
Minor GC 必须 扫描整个老年代 找跨代引用
-
老年代通常很大(几百 MB ~ 几 GB)
-
Minor GC 停顿时间剧增(从几 ms 到几百 ms)
-
违背分代 GC 的初衷!
1.2、问题本质
一、背景:为什么需要特殊处理?
1.1 分代假说(Generational Hypothesis)
JVM 将堆内存分为:
-
年轻代(Young Generation):存放新创建的对象
-
老年代(Old Generation):存放长期存活的对象
基于经验观察:
-
绝大多数对象"朝生夕死" → 在年轻代就死亡
-
老年代对象很少引用年轻代对象(跨代引用是少数)
因此,Minor GC 只回收年轻代,效率高、停顿短。
如下所示:
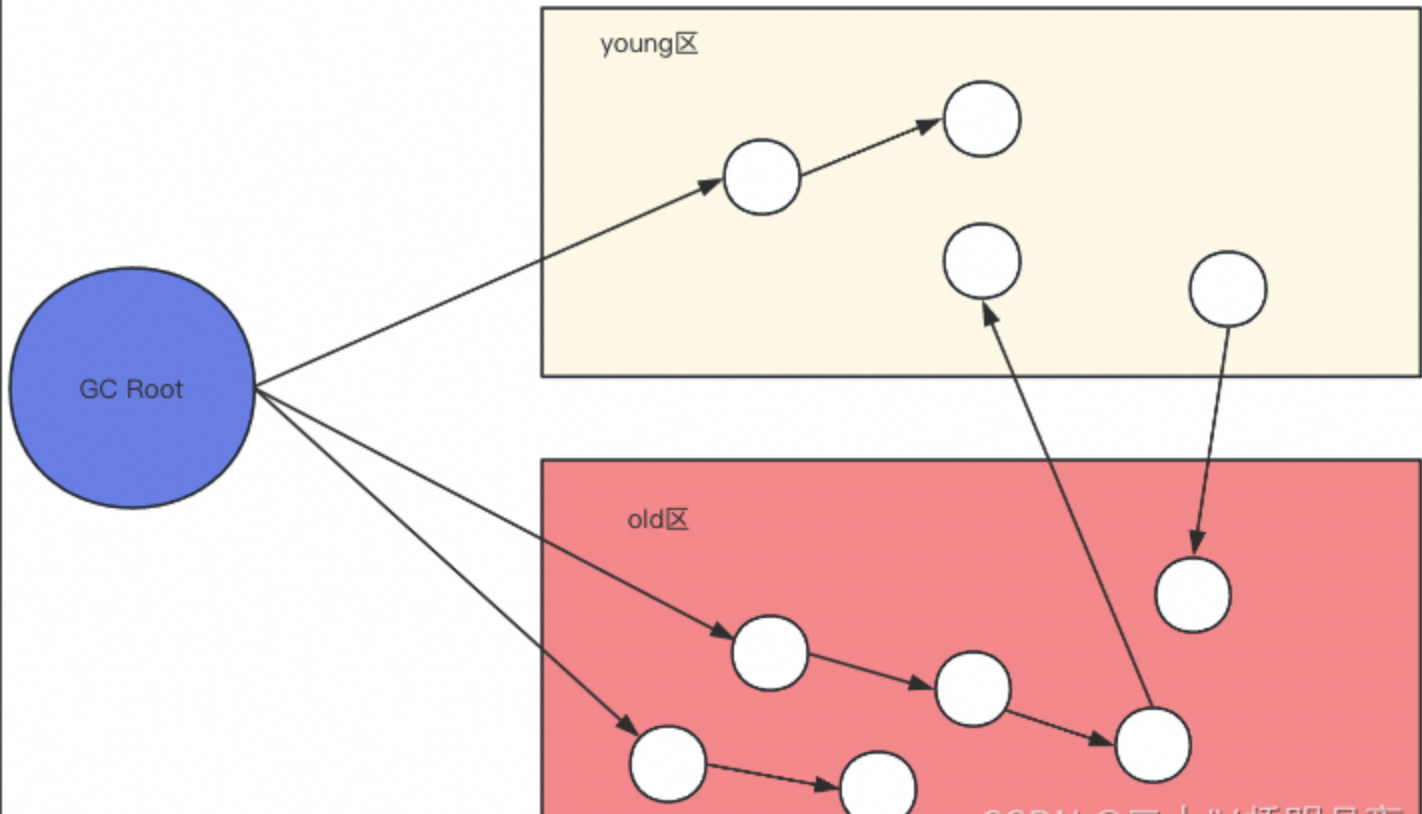
1.2 问题:跨代引用(Inter-Generational Reference)
代码如下所示:
java
// 老年代对象(长期存活)
Object oldObj = new Object(); // 经过多次 GC 后进入老年代
// 年轻代对象(新创建)
Object youngObj = new Object();
// 老年代对象引用年轻代对象!
oldObj.ref = youngObj;此时,youngObj 虽然在年轻代,但被老年代对象引用 ,不能被回收!
但如果 Minor GC只扫描年轻代的 GC Roots(如栈、寄存器),就会漏掉 oldObj.ref 这个引用 → 误判 youngObj 为垃圾 → 程序崩溃!
这就是 "引用丢失"(Missing Reference)问题。
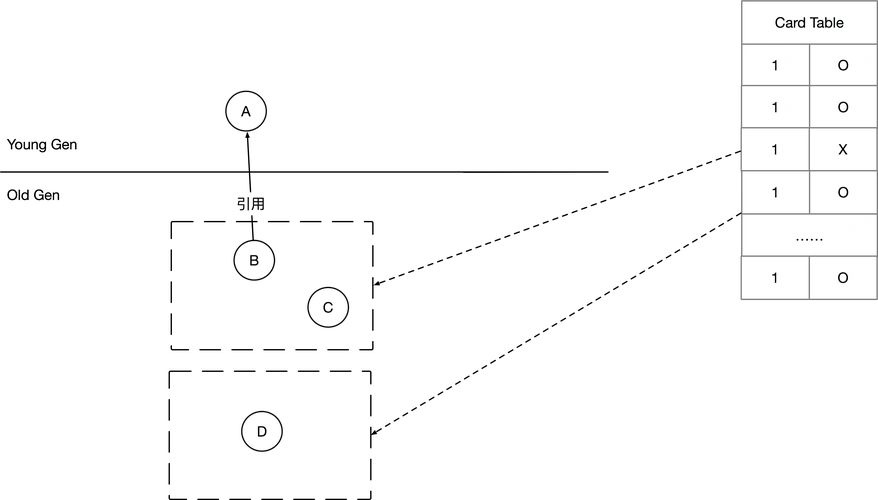
2、Card Table机制
2.1、介绍
JVM 通过 "写屏障(Write Barrier)" + "卡表(Card Table)" 机制高效解决跨代引用问题。
如下所示:
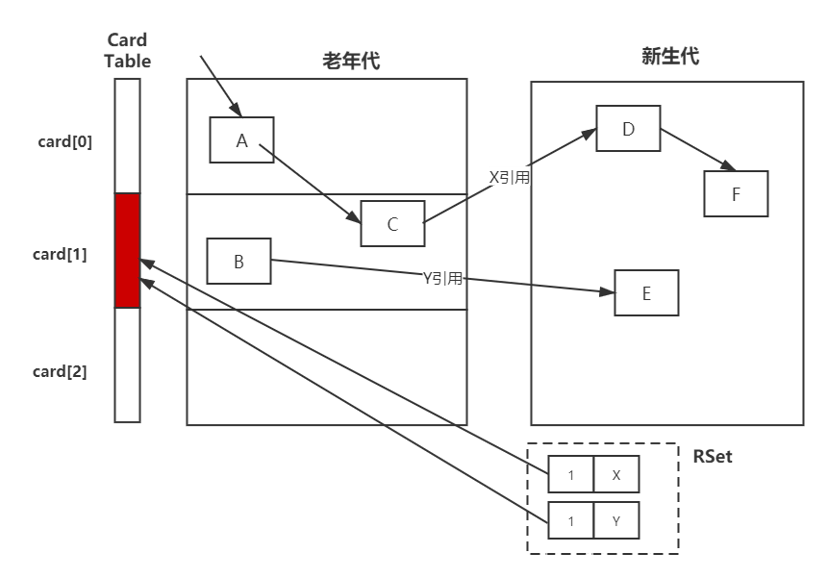
JVM 的核心思想是:
不扫描整个老年代,只记录"哪些老年代区域可能引用了年轻代",Minor GC 时只扫描这些区域。
实现这一思想的关键数据结构是:
-
Card Table(卡表)
-
Remembered Set(记忆集)(G1/ZGC 中更复杂,但 CMS/Parallel 用 Card Table)
JVM 将 整个堆内存(主要是老年代)划分为固定大小的块 ,称为 Card(卡片),通常 512B(通过 -xx:CardTableEntrySize 调整,但一般不改)。
每个 Card 对应一个 "脏位(DirtyBit) ,记录该 Card 是否包含 指向年轻代的引用。
老年代内存(1GB) → 划分为 1GB / 512B ≈ 200 万个 Card
如下所示:
bash
老年代内存: [Card0][Card1][Card2]...[CardN]
卡表(Card Table): [0] [1] [0] ... [1] ← 1 表示"脏"(有跨代引用)2.2、内存结构
-
Card Table 是一个字节数组,每个元素对应一个 Card
-
每个字节(8 位)中,最低位(bit 0)表示"脏位"(Dirty Bit)
-
0:干净(Clean)→ 该 Card 没有指向年轻代的引用
-
1:脏(Dirty)→ 该 Card 可能有指向年轻代的引用
-
bash
内存布局:
┌───────────────┬───────────────┬───────────────┐
│ Card 0 │ Card 1 │ Card 2 │ ← 老年代内存(每块 512B)
└───────────────┴───────────────┴───────────────┘
↑ ↑ ↑
│ │ │
┌───────┴───────┬───────┴───────┬───────┴───────┐
│ 0x00 │ 0x01 │ 0x00 │ ← Card Table(每个字节对应一个 Card)
└───────────────┴───────────────┴───────────────┘
Clean Dirty Clean注意⚠️:
Card Table 只记录 "可能有" 跨代引用,不是精确记录。这是为了性能牺牲一点精度(后续会修正)。
如下所示:
2.5、写屏障(Write Barrier)
每当 老年代对象修改引用(如 obj.field = youngObj) 时,JVM 会触发 写屏障:
java
// 伪代码:老年代对象引用年轻代对象
oldObject.ref = youngObject; // ← 触发写屏障作用:实时维护卡表
写屏障的作用:
-
计算 oldObject 所在的 Card 地址
-
将对应 Card 标记为 "脏"(Dirty)
-
即:cardTablecardIndex = Dirty
💡 写屏障是 JIT 编译器插入的额外指令,对性能有轻微影响,但远小于全堆扫描。
3、写屏障
-
写屏障是在对象引用赋值时插入的一段额外代码
-
由 JIT 编译器在编译期自动插入
-
对程序员透明,但对 GC 至关重要
关键点 :只有 老年代 → 年轻代 的引用才会标记 Card 为 Dirty。
写屏障如何工作?
当执行:
obj.field = ref; // obj 是老年代对象,ref 是年轻代对象
JVM 会插入类似这样的伪代码:
java
// 1. 执行实际赋值
obj.field = ref;
// 2. 触发写屏障(Write Barrier)
if (obj 在老年代 && ref 在年轻代) {
// 计算 obj 所在的 Card 地址
intptr_t card_index = (intptr_t)obj >> 9; // 512 = 2^9
// 标记 Card 为 Dirty
card_table[card_index] = DIRTY; // 通常设为 0x01
}关键点 :只有 老年代 → 年轻代 的引用才会标记 Card 为 Dirty。
写屏障的性能影响
-
每次引用赋值都多几条指令
-
但现代 CPU 分支预测 + 卡表缓存友好,开销很小(通常 < 5%)
-
远小于"每次 Minor GC 扫描整个老年代"的代价
3、Remembered Sets
3.1、介绍
Remembered Set(记忆集)是一个"反向引用表":
每个 Region 都有一个 RSet,记录"哪些其他 Region(或对象)引用了本 Region 中的对象"。
如下所示:
Region X: obj1, obj2 ← 被 Region Y 和 Region Z 引用
Region Y: ref → obj1
Region Z: ref → obj2
则 Region X 的 RSet 内容为:
RSetX = { Y, Z }
当 G1 要回收 Region X 时:
- 不需要扫描整个堆
- 只需扫描 RSetX 中列出的 Region(Y 和 Z)
- 从中找出指向 X 的引用,作为 GC Roots
这样就避免了全堆扫描,实现局部回收(Partial Collection)。
Remembered Set(记忆集) 是现代 JVM 垃圾回收器(尤其是 G1、ZGC、Shenandoah 等并发/分区式 GC)中用于高效处理跨区域引用(Inter-Region Reference) 的核心数据结构。
它是对传统 Card Table(卡表)机制的演进与精细化。
在 G1 GC 中,概念升级为 Remembered Set(RSet):
-
每个 Region 有自己的 RSet
-
RSet 精确记录 "哪些 Region 引用了本 Region"
-
使用 Concurrent Refinement Threads 异步维护 RSet,减少写屏障开销
但核心思想一致:避免全堆扫描,只追踪跨区域引用。
3.2、使用原因
1.1 分代 GC 的局限性
在传统的 CMS 或 Parallel GC 中:
-
堆被简单分为 年轻代 + 老年代
-
使用 Card Table 记录"老年代中哪些 Card 可能引用了年轻代"
但这种模型在以下场景遇到瓶颈:
-
堆非常大(几十 GB 甚至上百 GB)
-
需要更细粒度的回收(如只回收部分老年代区域)
-
并发标记与回收要求更高精度的引用追踪
1.2 G1 GC 的分区思想
G1(Garbage-First)将整个堆划分为 固定大小的 Region(默认 1~32MB),不再严格区分年轻代/老年代,而是:
-
每个 Region 可以是 Eden、Survivor 或 Old
-
GC 时选择 "回收价值最高"的若干 Region(即 Garbage-First)
🎯 问题来了:Region A 中的对象可能引用 Region B 中的对象,如何在回收 Region B 时,知道哪些外部 Region 引用了它?
这就是 Remembered Set(RSet) 要解决的问题。
3.3、内部结构
RSet 并非简单列表,而是多级缓存结构,兼顾空间效率 与查询速度。以 HotSpot G1 为例:
典型层级(由快到慢):
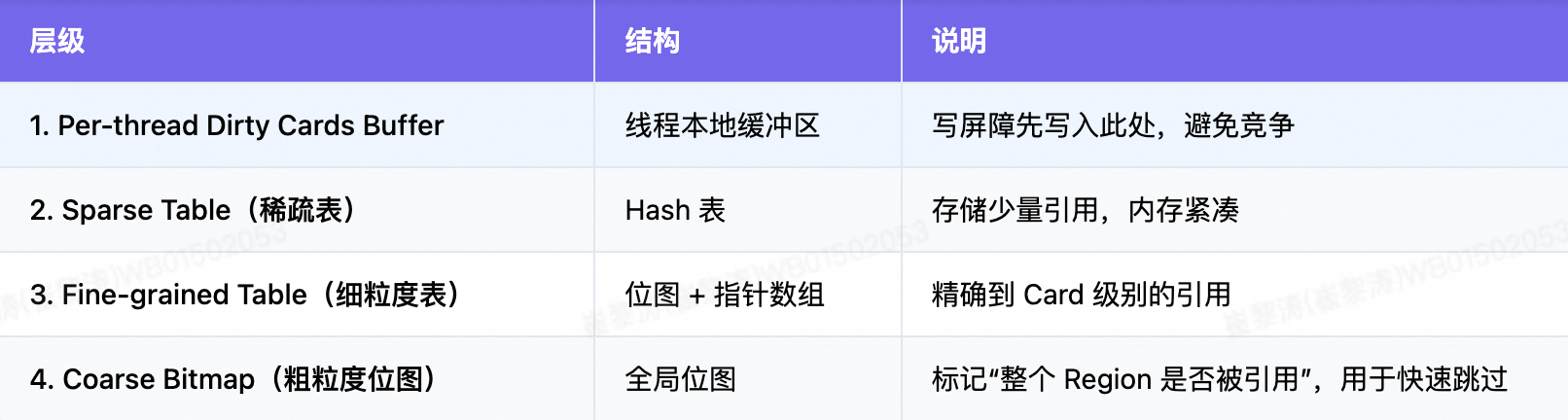
当引用数量少时,用 Sparse Table;引用多时,升级为 Fine-grained Table。
3.4、操作流程
写屏障 + 并发精化
4.1 写屏障(Write Barrier)
当执行 obj.field = ref 时:
-
如果
obj和ref不在同一个 Region -
JVM 插入写屏障,将
(from_region, to_region)记录到 Dirty Card Queue
java
// 伪代码
if (region_of(obj) != region_of(ref)) {
enqueue_into_dirty_card_queue(region_of(obj), card_of(obj));
}4.2 并发精化线程(Concurrent Refinement Threads)
-
后台线程(
G1 Concurrent Refinement)持续消费 Dirty Card Queue -
将粗粒度的 Card 信息 精化(Refine) 为 RSet 中的精确条目
-
避免在 Mutator 线程(应用线程)中做 heavy work,减少 STW 时间
✅ 这是 G1 实现低延迟的关键:引用更新的开销被摊销到并发阶段。
3.5、Remembered Set vs Card Table
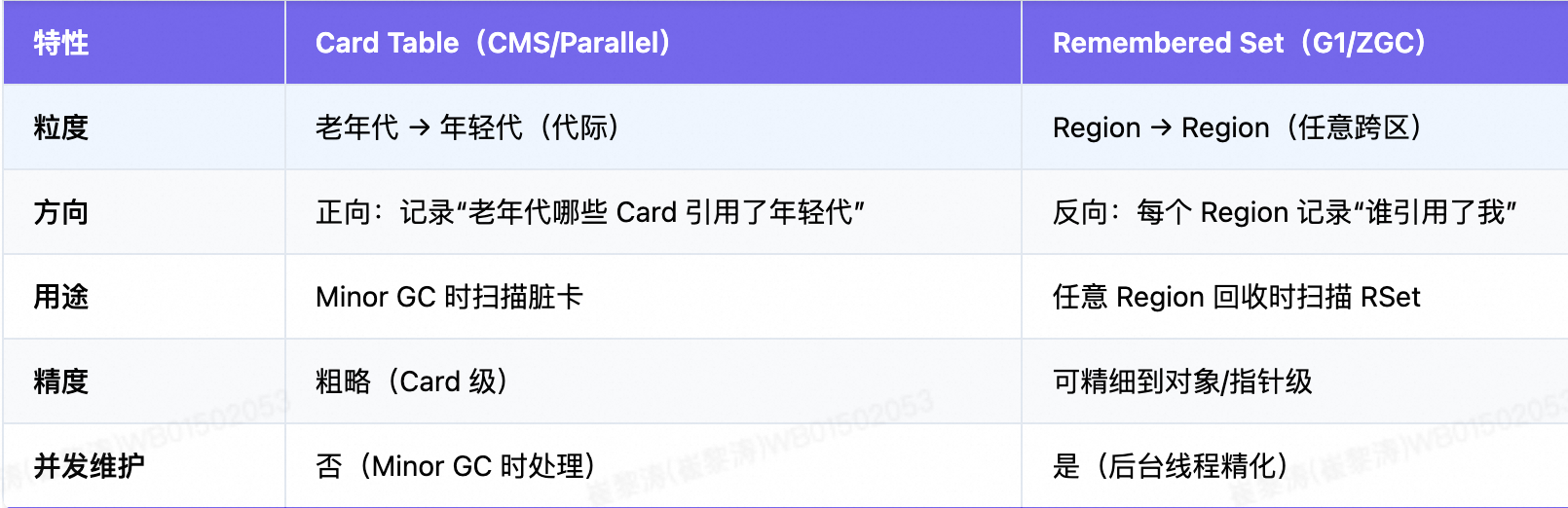
RSet 是 Card Table 的泛化与升级,支持更灵活的回收策略。
RSet 的代价与优化
空间开销
-
RSet 通常占 堆内存的 5%~20%
-
可通过参数控制:
bash
-XX:G1RSetSparseRegionEntries=... # 稀疏表容量
-XX:G1RSetRegionEntries=... # 细粒度表容量4、实际应用
4.1、工作流程
Minor GC 时如何利用 Card Table?
当发生 Minor GC 时,步骤如下:
步骤 1:识别所有 GC Roots
-
栈帧中的局部变量
-
寄存器
-
静态变量
-
JNI 引用
-
+ 来自老年代的跨代引用(通过 Card Table 获取)
步骤 2:扫描 Dirty Cards
-
遍历 Card Table,找出所有 card_tablei
==Dirty 的 Card -
对每个 Dirty Card:
-
扫描该 Card 内存区域中的所有对象
-
检查这些对象的引用字段
-
如果引用指向 年轻代 ,则将该引用加入 "根集合"(Root Set)
-
步骤 3:正常进行年轻代 GC
-
从所有 GC Roots(包括跨代引用)出发,标记存活对象
-
回收未标记对象
结果:youngObj 被正确标记为存活,不会被回收!
4.2、流程图解
如下所示:
bash
老年代
┌───────────────┬───────────────┬───────────────┐
│ Card A │ Card B │ Card C │
│ (干净) │ (脏!有引用) │ (干净) │
└───────────────┴───────────────┴───────────────┘
↑
└── Card Table: [0, 1, 0]Minor GC 时:
-
扫描常规 GC Roots
-
扫描 Card B(因为 dirty=1)→ 发现 oldObj.ref → youngObj
-
将 youngObj 加入存活对象集合
-
youngObj 不会被回收!
4.3、JVM 参数调优
如下所示:
| 参数 | 作用 |
|---|---|
| -XX:+UseCondCardMark | 避免并发写屏障重复标记(减少 cache contention) |
| -XX:CardTableEntrySize | Card 大小(默认 512B,一般不调) |
| -XX:+PrintGCDetails | 查看 GC 日志中是否有 "Dirty Cards" 相关信息 |
常见误区:

总结:JVM 如何安全处理跨代引用?
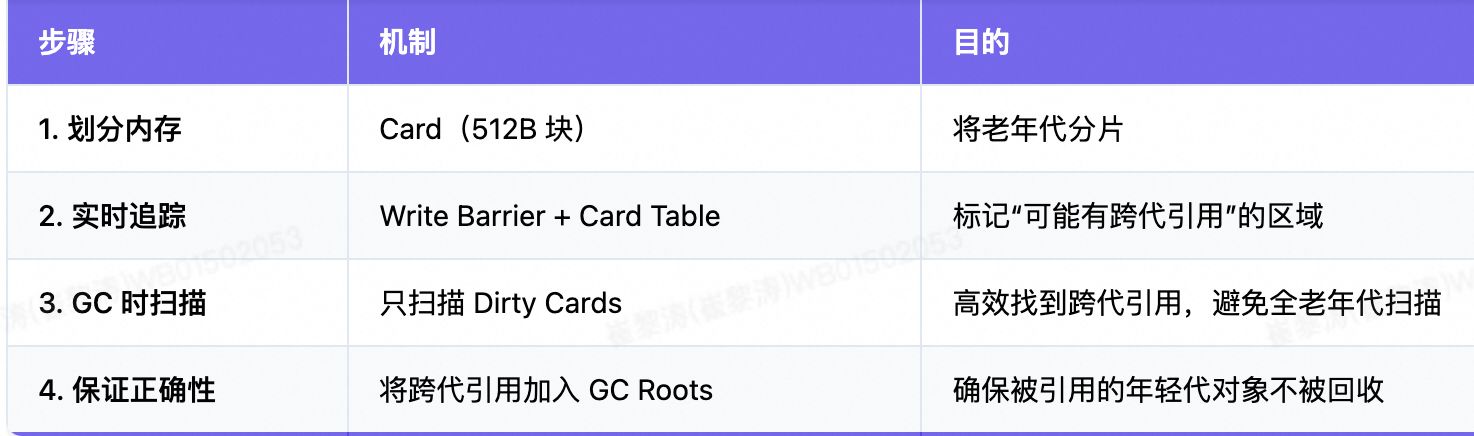
这就是 JVM 分代 GC 既高效又安全的核心秘密!
通过这种设计,Minor GC 的停顿时间保持在 毫秒级,即使老年代有几十 GB,也能快速完成年轻代回收。