作者:赵宇(司忱)/数据开发工程师
导读:
本文整理自高德数据开发工程师、赵宇在 Streaming Lakehouse Meetup上的分享。聚焦高德地图轨迹服务在实时湖仓方向的落地实践。
面对轨迹数据"高实时、高并发、长周期存储"的典型特征,高德团队以访问跨度为依据完成热/温/冷分层,并以 Apache Paimon + StarRocks 构建统一的数据底座,支撑轨迹数据的近实时写入与高性能查询。
该方案通过性能验证覆盖千亿级轨迹数据查询等关键场景,在满足实时与查询性能的前提下,实现了分层存储下的"性能---成本"最优平衡,并为后续将流批一体能力扩展到更多业务域、打通 BI 与算法链路提供了可复制的路径。
高德地图轨迹相关的背景及面临的挑战
在进入背景介绍之前,先对轨迹项目在端侧的一些典型应用做一个简要说明。
以"足迹地图"功能为例:用户完成授权后,每一次导航结束,其行程轨迹会被记录并展示在轨迹列表中。用户打开某一段轨迹后,页面会展示该次行程的基础信息,例如驾驶时长、驾驶里程、平均速度等;同时还会在端上渲染出轨迹形状及关键点特征信息,例如会车位置、最大速度点等。 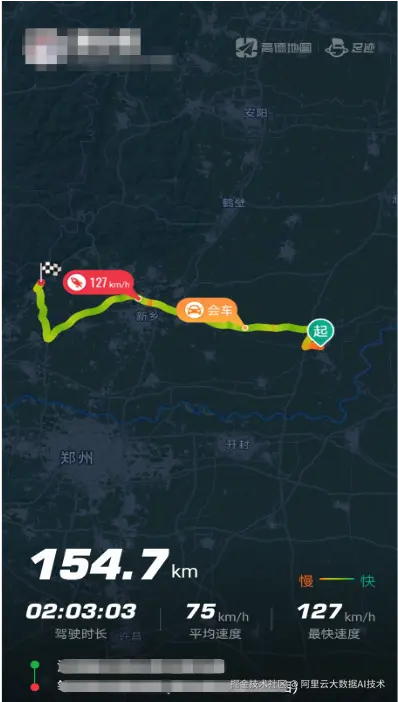
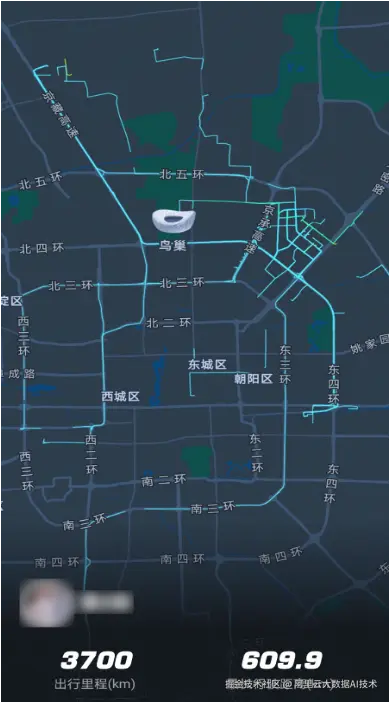
同时,高德地图会将用户的轨迹点与道路进行实时轨迹匹配,从而渲染出"足迹地图"的背景图。以下图为例,该图展示了一位用户在北京范围内行走过道路的渲染效果。
下图展示的是端侧"工作地图"的一个应用场景。通过该功能,用户可以查看一段轨迹在何时、何地开始 ,在哪些地点停留以及停留时长 ,并在结束后记录其最终结束位置 。 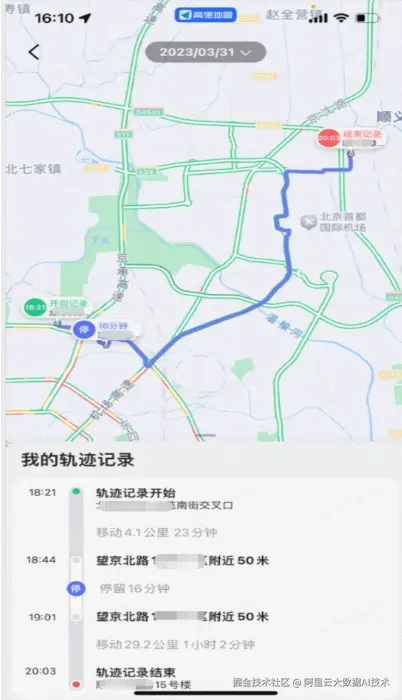
另一个需要补充的应用场景是此前较为热门的"猫鼠游戏"。在该玩法中,同一群组内的用户可以共享各自的实时位置;在一局游戏结束后,系统也会生成并展示用户在该局中的行程轨迹。
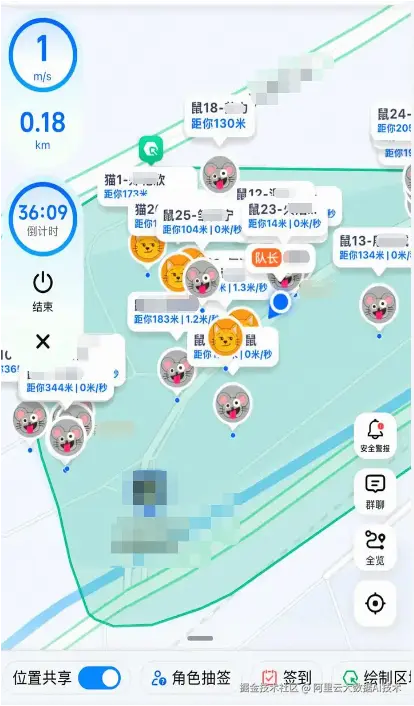
面临的核心挑战
由于高德地图轨迹数据具有较强的业务特殊性与实时性要求,因此无论在轨迹的采集、处理 ,还是在存储与查询 环节,都面临一系列挑战。 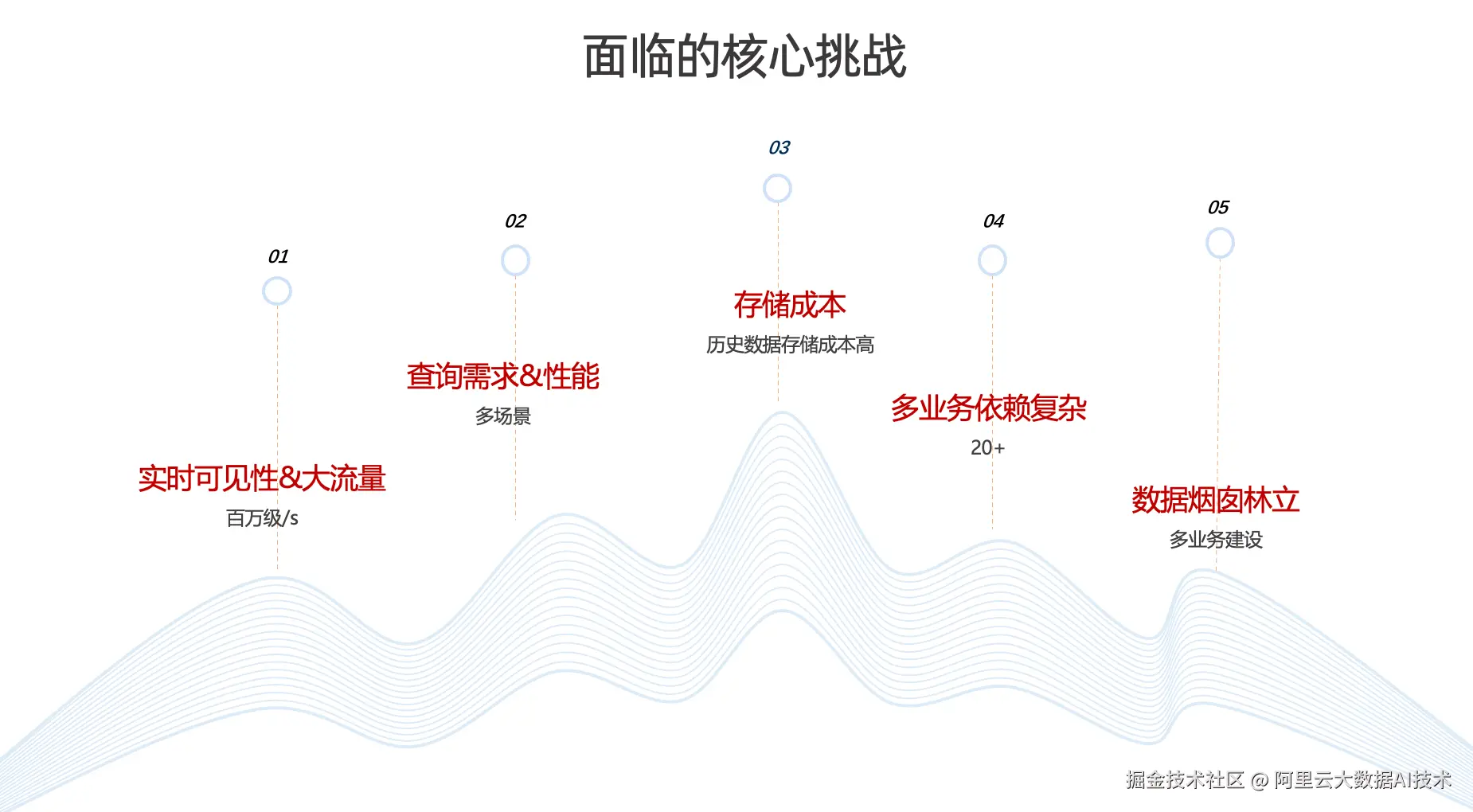
第一,实时可见性要求高。
轨迹数据是判断用户行为的重要依据,数据鲜度至关重要。因此,端侧业务对轨迹数据的实时可见性提出了较高要求。并且日常的轨迹数据的写入流量达到了每秒百万级,在节假日等高峰时段还会出现翻倍增长。对数据链路而言,无论是实时计算能力还是整体稳定性,都面临较大压力与挑战。
第二,多场景查询需求复杂,对性能要求高。
轨迹数据不仅服务于离线挖掘以及问题排查,同样需要服务各种线上场景,对查询性能要求也非常高。
第三,历史数据规模大,存储成本高。
高德地图存储了全量历史轨迹数据。在缺乏有效分层、压缩与治理策略的情况下,数据规模持续增长将带来显著的存储成本压力。
第四,历史演进形成数据烟囱,业务依赖复杂。
受多年历史演进影响,轨迹相关链路形成了一定程度的数据烟囱;同时,存在 20+ 业务依赖,链路与接口关系较为复杂,进一步提升了在架构设计与存储整合上的技术难度。
统一链路优化方案
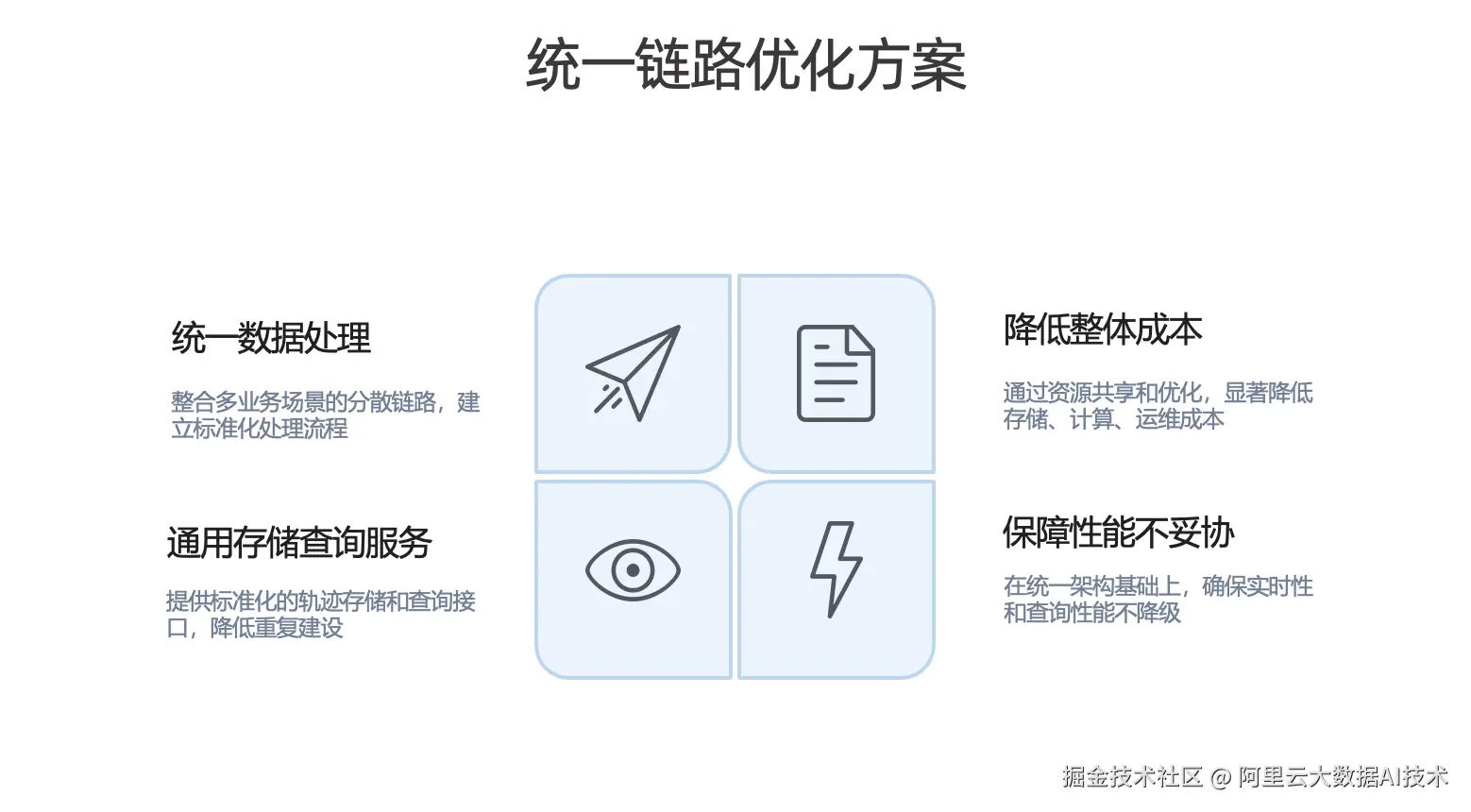
基于上述挑战,我们计划对不同业务的计算场景与存储体系进行整合,核心方向包括:
-
统一数据处理。 整合多业务场景下分散的计算链路,建立标准化的数据处理流程与规范。
-
建设通用存储与查询服务。 提供标准化的轨迹存储能力与统一查询接口,减少重复建设。
-
降低整体成本。 在控制资源成本的同时,降低后续人工运维成本与系统复杂度。
-
保障性能不妥协。 在统一架构下保障实时性与查询性能。
轨迹的能力建设与方案调研

首先介绍轨迹在全场景下的服务能力体系。
作为数据中台,我们承担离线与实时流量的统一入口角色。以轨迹业务为例,整体可按自下而上的链路理解:
从最底层的轨迹原始点数据出发,经由 ETL 加工与清洗,沉淀形成轨迹领域的基础数据资产,包括轨迹点、轨迹段、轨迹匹配结果,以及离线数据等。
依托数据中台与交通业务在轨迹领域的长期建设,我们进一步整合并沉淀出一组核心能力:例如公共层的轨迹实时流任务、通用的轨迹查询能力,以及特征平台等基础能力服务平台。
在核心能力之上,平台对全链路能力进行模块化封装,主要包括两类服务:
-
查询服务模块;
-
推送订阅模块。
基于上述两类模块,轨迹服务能够支撑多类业务场景的接入与调用,包括内部调查平台,以及面向 C 端的相关功能与应用。
业务访问跨度调研
明确要将轨迹能力建设为上述统一体系后,下一步需要回答"如何落地"的问题。因此,我们首先开展了对业务访问跨度的调研: 
访问跨度用于衡量"用户访问的轨迹数据距离当前时间有多远"。例如,用户查看 n 天前 的轨迹数据,则该次访问的跨度定义为 n。
基于这一口径,我们对日均访问跨度进行了统计(见左侧图)。结果显示:
-
0--1 天(当天与昨天)的访问占比约为 67%。这部分数据访问最为集中,可定义为热数据。
-
1--3 天直至 30--60 天 区间内的访问占比整体较为均匀,可定义为温数据。
-
60 天以上 覆盖更长周期的历史数据,整体访问占比约为 16% 。尽管访问频次相对较低,但由于其代表全量历史沉淀,体量非常大,可定义为冷数据。
在此基础上,我们进一步调研了"访问跨度在 60 天以上的用户"在查看历史轨迹时的行为特征:即这些用户所访问的历史轨迹,在其个人全部轨迹中的位置分布(可理解为是否仍会查看更久远的记录)。调研结果表明,仍有相当比例的用户会回看较早期的历史轨迹。
综合来看,一方面,近期数据访问频繁,对查询性能与实时响应提出更高要求;另一方面,60 天以上历史数据虽然访问相对较少,但仍存在明确的用户需求(例如具备纪念意义的行程回看等),且该部分数据体量更大,对存储成本高度敏感。
因此,整体上需要一套能够支持分层存储并同时满足高效查询的数据方案。
性能+存储需求调研

在推进该方案的过程中,我们也关注并调研了阿里巴巴集团的数据湖项目,这为后续的湖仓一体化提供了可行路径。
从能力构成来看,集团数据湖项目的核心优势主要体现在三点:
-
基于 Apache Flink + Apache Paimon,能够提供高性能的近实时数据写入能力,满足处理轨迹数据对时效性的要求。
-
数据写入 Paimon 后,可通过 StarRocks 外部表方式进行挂载,从而对 Paimon 表上的数据提供高性能查询能力。
-
采用 Paimon + 盘古的存储组合,相比其他存储介质具备显著的成本优势。
基于上述优势,其整体数据链路如左图所示:首先通过 Flink Job 消费消息队列中的源端轨迹消息,完成 ETL 处理及必要的聚合计算;随后将结果写入数据存储层,采用 Paimon + 盘古进行持久化存储;最后通过 StarRocks 挂载外部表的方式对湖表数据提供统一、低延迟的查询服务。
在验证 StarRocks + Paimon 是否能够覆盖轨迹项目的性能诉求与关键挑战时,我们开展了一系列性能评估与参数调优工作。
-
基于 Flink + Paimon 对写入吞吐进行了测试,结果表明该链路能够满足轨迹数据近实时处理的需求。
-
在千亿量级下轨迹的点查场景下,我们使用 StarRocks 进行了查询性能测试,结果达到既定的性能指标要求。
在此基础上,我们对 Paimon 的相关参数进行了调整,以在写入效率与查询性能之间实现更好的平衡。综合测试结果显示,整体链路验证通过:可以采用 StarRocks 作为 OLAP 引擎直连数据湖存储,实现轨迹数据的及时查询与分析。
在存储侧,借助 Paimon + 盘古的组合方案,轨迹存储成本实现了显著优化,年度节省达到百万级规模。
总体而言,StarRocks + Paimon 方案在满足性能指标的前提下,实现了明确的成本优化效果。
Paimon + StarRocks在轨迹应用中的落地及探索
数据分层架构设计(热数据)

接下来我将进一步说明 Paimon + StarRocks 在轨迹应用中的落地方式与实践探索。
前文提到,我们基于"访问跨度"将轨迹数据划分为三层:热数据、温数据、冷数据。在具体实现上,热数据又进一步细分为 A/B 两层。
热数据 A 层: 面向对性能要求极高、对响应时延(RT)极为敏感的业务场景。该层采用 Redis 存储,保留近 1 天的数据。
-
数据组织方式:以用户信息 + 轨迹点信息为主。
-
典型场景:实时位置类查询与高频互动场景,例如"猫鼠游戏"、家人地图、最新位置查询,以及 WIA(工作地图)等。
热数据 B 层: 主要承载近几天内的轨迹查询需求。该层采用 Lindorm 存储,保留近 3 天的数据。
-
数据组织方式:以"用户 + 时间片 + 轨迹段" 的结构化设计,以满足多种业务不同的查询方式。
-
典型场景:足迹/运动等近三天轨迹查询;同时也支撑部分内部调查平台使用,以及实时轨迹匹配等能力的在线调用。
数据分层架构设计(温、冷数据)

温数据与冷数据部分采用前文提到的 Apache Paimon + StarRocks 方案。我们将三天以外的历史轨迹数据统一写入 Paimon,在显著降低湖存储成本的同时,构建起流批一体的统一数据架构。
温数据层(3 天--60 天)
温数据层使用 Paimon + StarRocks 存储并查询 3 天至 60 天范围内的轨迹数据,整体可实现百毫秒级响应。
-
数据组织方式:以"用户 + 时间片 + 轨迹段" 的结构化设计,以覆盖多种查询形态。
-
数据特征:整体 QPS 较低、访问频率相对有限,对 RT 的容忍度相对更高。
冷数据层(60 天以上全量历史)
冷数据层同样采用 Paimon + StarRocks,承载 60 天以上的全量历史轨迹数据。相较温数据层,该层在存储结构上做了进一步优化,将多段轨迹按照轨迹的唯一 ID 聚合为一条完整轨迹,并且引入压缩策略以显著降低历史数据的存储开销。
温/冷数据层主要支撑足迹地图等产品能力对历史轨迹的查询与展示。同时,在离线分析场景中(如 AI 训练、规律挖掘等)以及内部调查平台等工具型场景,也会使用该部分数据资产。
整体链路架构图
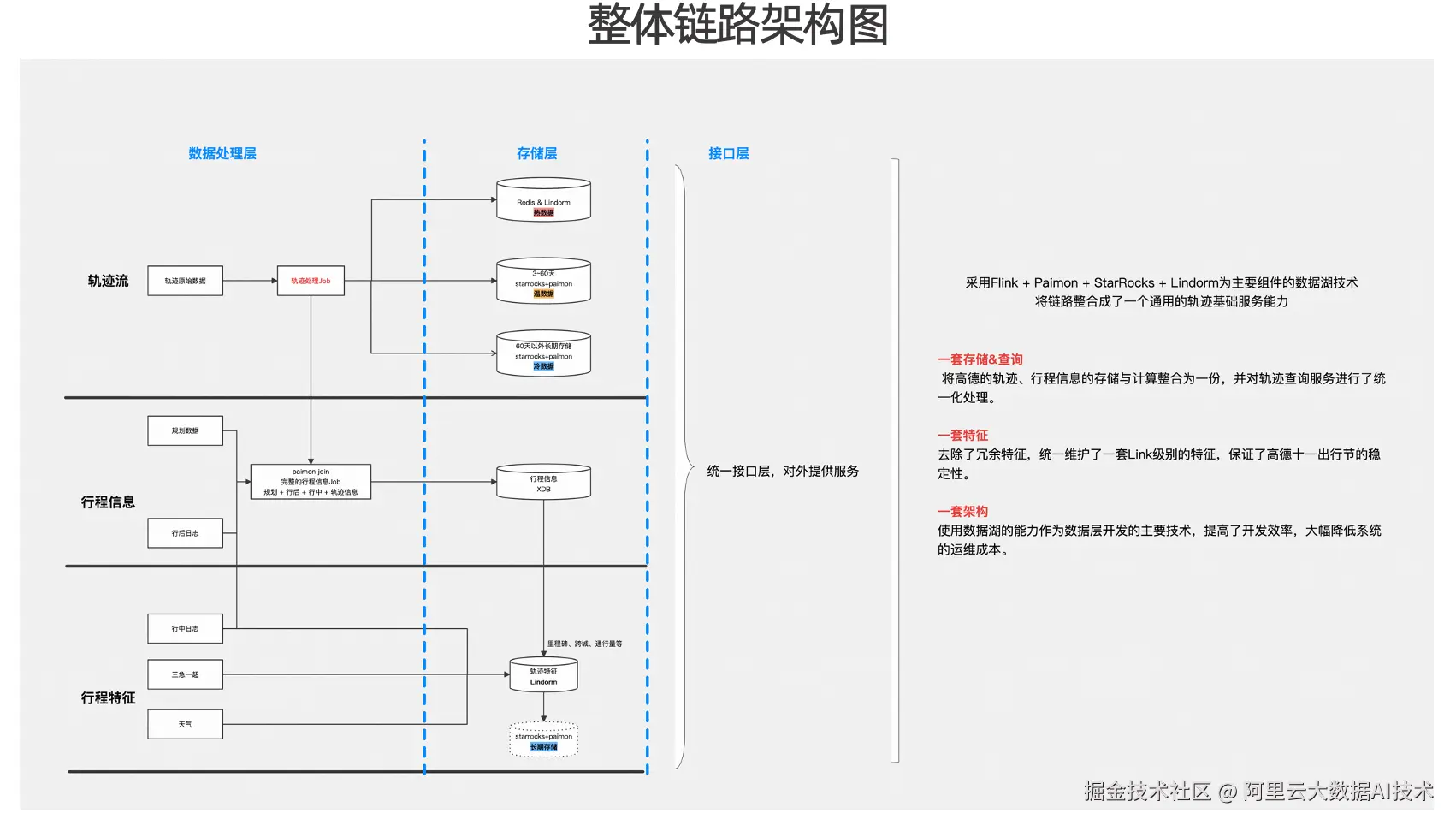
整体链路的架构示意图可按三层理解:数据处理层、存储层与接口层。
从轨迹流处理链路来看,Flink 消费原始轨迹数据后,会根据访问跨度与数据分层策略,将数据分别写入热/温/冷 三类存储介质。与此同时,在轨迹流加工过程中,链路还会引入规划数据及行后(规划导航)相关数据,并借助 Paimon 的Partial Update引擎完成宽表化关联,从而生成完整的行程信息并进行持久化存储。
在行程信息沉淀后,平台进一步基于行程信息与行程特征,并结合三急一超数据、天气数据等外部维度,构建里程碑、跨城识别、Link通行量等实时特征能力。
在接口层,平台对外统一提供查询服务能力。综合来看,基于 Flink + Paimon + StarRocks 的数据湖方案,并以 Lindorm、Redis 等存储介质作为补充,轨迹链路被整合为一套通用的轨迹基础能力,并在建设目标上体现为"三个一":
-
一套存储架构: 将高德轨迹数据与行程信息在同一架构下进行统一存储与计算整合,同时对轨迹查询服务进行统一化治理。
-
一套特征体系。 在推进该体系建设过程中,我们对既有特征进行了梳理与收敛,去除历史沉淀下的冗余特征,统一维护一套 Link 级实时特征。在关键业务周期内,该特征体系也支撑并保障了高德"十一出行节"等高峰场景下的稳定性。
-
一套数据湖架构。 基于数据湖能力,平台形成了一套统一的数据开发与数据服务架构,并将其作为数据开发层的主要技术路径。一方面提升了研发交付效率,另一方面也降低了后续人工运维成本。
数据分层架构设计总结

关于数据分层架构设计,整体可以从两个方面进行总结:
第一:访问频次分层 我们以访问跨度为核心指标完成数据热度分析,并基于"时间衰减"的策略,将数据随生命周期在不同存储介质之间动态迁移。
第二:智能数据迁移
在数据访问过程中,系统可根据访问模式在不同层级间自动路由查询,确保数据的就近访问。该机制带来阶梯式的存储成本收益。
基于上述设计,分层架构主要体现两项核心价值:
-
能够同时覆盖从实时决策 到历史分析的多样化业务需求;
-
通过分层存储实现性能与成本之间的最佳平衡。
查询场景下的一些优化实践
1、存储优化:轨迹压缩-降低存储成本 
前文提到,我们对轨迹数据进行了压缩,以显著降低历史存储成本。具体实现上采用了 Google 的 Polyline 编码。其基本思路是:将经纬度浮点数按固定倍率进行量化(缩放)后转换为整数,再对相邻点的坐标增量进行差分编码,并通过可变长度编码将结果映射为 ASCII 字符串,从而实现对经纬度序列的高效压缩。本质上,该算法是对经纬度整数序列(及其差分结果)进行紧凑编码。
我们在上述算法思路的基础上,结合高德常见的通用轨迹格式进行了适配与改造,从而实现对轨迹数据的统一压缩。以压缩前的数据样例为例,一段轨迹由多个点构成;每个点通常包含 时间、经度、纬度、速度、方向、高程等字段信息。
经过压缩后,轨迹数据会被编码为一段紧凑的字符串(形态上类似"乱码")。从效果来看,单条轨迹的压缩率可达到 43%--50% ;轨迹越长,压缩效果越明显。整体而言,高德轨迹数据全面应用该压缩方案后,综合收益约为 47% 。在性能方面,该压缩算法具备较好的资源效率:即便在亿级轨迹的压缩规模下,CPU 资源消耗仍保持在较低水平。
2、存储优化:集团 Alake 门户的存储优化功能 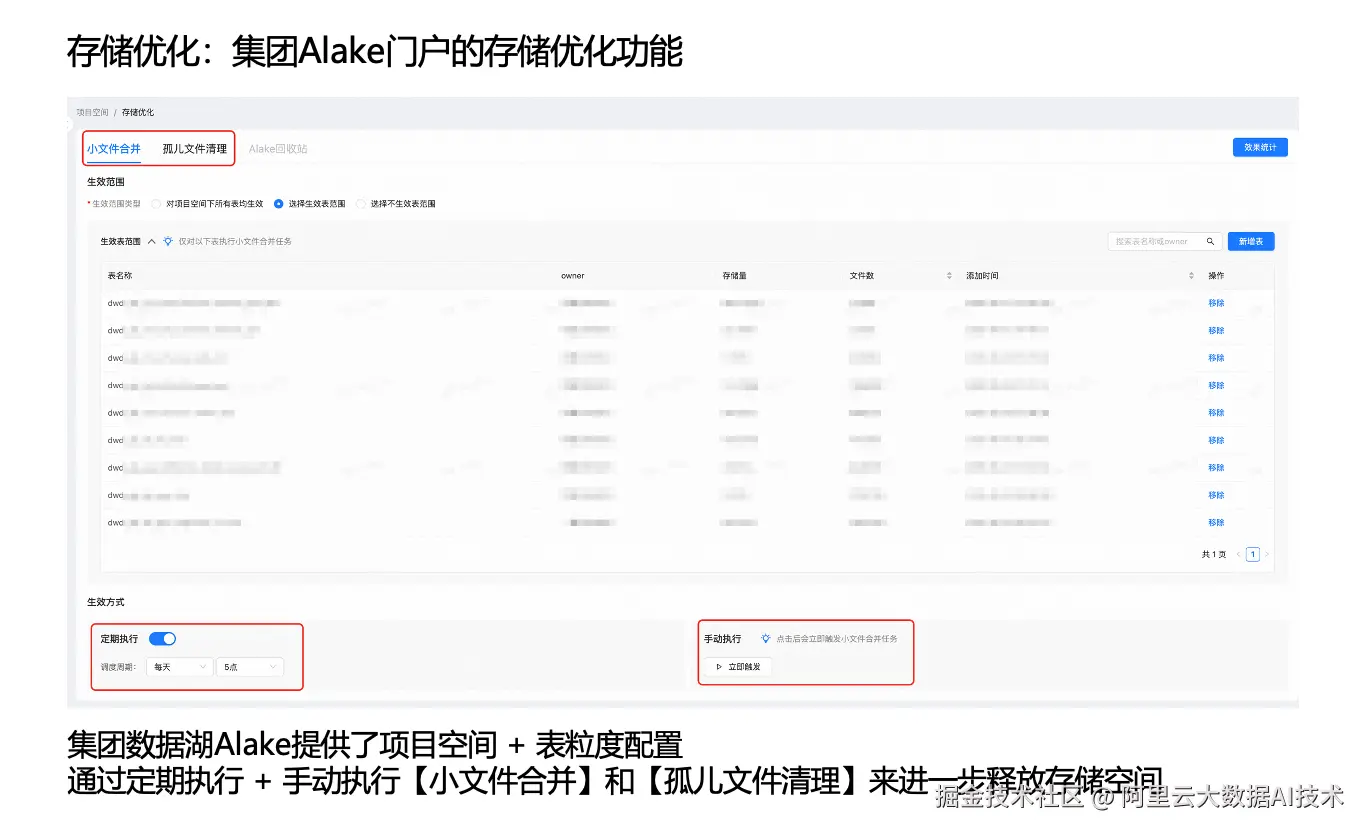
由于本项目使用集团数据湖能力,集团门户提供了存储治理相关的优化功能。在 Flink 写入 Paimon 的过程中,可能会因检查点(Checkpoint)提交失败等原因产生小文件,并在异常场景下形成孤儿文件。
为此,集团数据湖门户支持按"项目空间 + 表"粒度进行配置。我们将目标表纳入治理范围后,可通过定期执行或手动触发的方式开展:
-
小文件合并/整理(文件压实、合并小文件);
-
孤儿文件清理。
上述治理动作能够进一步释放存储空间,同时通过周期性合并/整理作业减少 Paimon 表中的小文件数量,从而保障湖表的高效查询能力。
3、查询优化:数据分区存储,分区裁剪 
在读取性能方面,我们从业务访问特征出发对数据进行了分区存储。以千亿级轨迹点查询场景为例,若缺少合理分区,从海量历史数据中定位一条轨迹可能需要触发全表扫描,导致 I/O 与 CPU 开销显著上升。
在轨迹业务中,分区设计会天然遇到"跨天"问题。例如,用户在当日 22:00 开始导航、次日 01:00 结束行程,则该行程对应的轨迹点/轨迹段会跨越多个日期分区。若仍按自然日期分区存储与写入,完整轨迹的查询与写入都会涉及多个分区。
为解决这一问题,我们在历史数据层做了一个关键设计:轨迹点聚合。具体而言,通过轨迹的唯一 ID,将同一条轨迹的多个点聚合为一条完整轨迹,并配合前文介绍的压缩算法,进一步降低存储成本。在分区策略上,我们以轨迹开始日期作为分区键,从而保证单条轨迹只落入一个分区,同时规避跨天写入与跨分区查询的问题。
在表模型设计上,Paimon 表以轨迹 ID作为主键。由于 Paimon 主键表支持 Upsert,我们可以利用其主键合并能力支持轨迹补全与数据修复等场景;同时,主键过滤条件也能够显著加速查询。 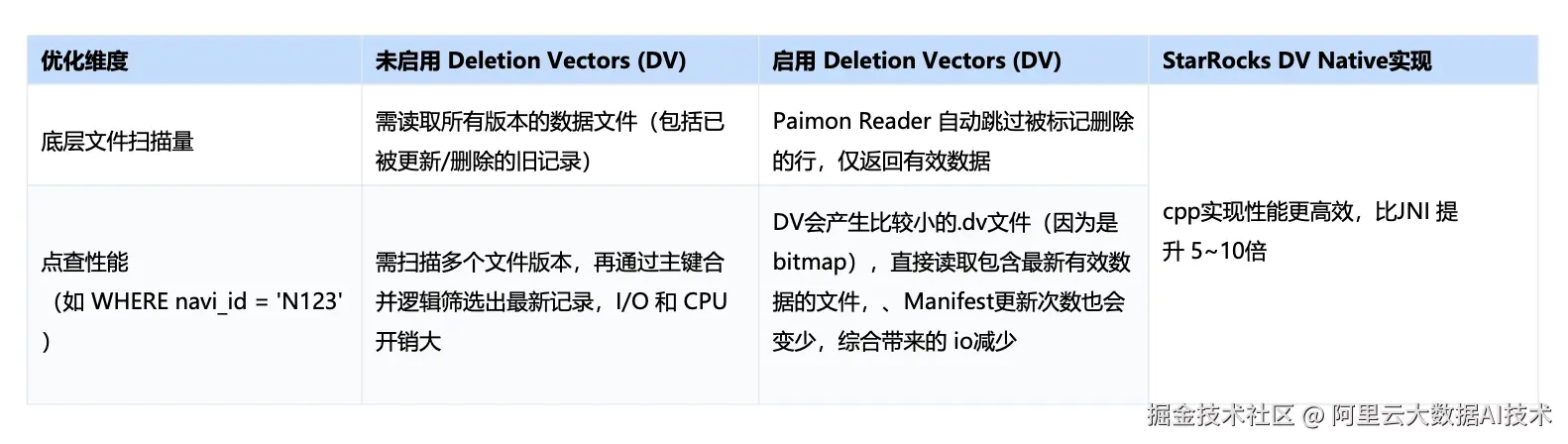
此外,该表开启了 DV(Deletion Vector)相关能力:当 Reader 读取开启 DV 的表时,可自动跳过已标记删除的行,仅返回最新有效数据;同时,Manifest 的更新频次也会降低,综合带来 I/O 的进一步减少。配合 StarRocks 的 DV Native 实现(C++),整体执行效率相较 JNI 路径可获得显著提升(可达到 5 倍以上)。
4、性能优化:调整参数 
我们也针对 Paimon 表做过一系列参数调优,以进一步优化点查场景下的读取效率与稳定性。
例如:将 file-block-size 从默认的 128MB 下调至 32MB。在轨迹历史数据体量大、以点查为主的场景下,更小的 block/row group 粒度有利于更精细的数据裁剪与下推:
-
粒度更小意味着可以更准确地定位命中范围,从而在读取时跳过更多不相关的 row group;
-
有助于降低 I/O 放大(只读取命中的 group,而非扩大到整文件级别);
-
更小的 group 也更利于多线程/多任务并行读取。
我们也尝试过开启"使用线程池处理序列化"的相关参数。但由于该线程池默认大小通常为 CPU 核心数的 2 倍,在高 QPS 场景下反而容易形成排队与瓶颈。为此,我们将该参数设置为 false ,使序列化由每条 SQL 在执行过程中自行完成。 此外,我们将 manifest 缓存大小从默认的 1GB 调整至 4GB,用于提升 manifest 命中率。高德轨迹查询存在一定比例的"访问更早历史数据"的特征,若 manifest 频繁过期并被淘汰。扩大缓存后,可覆盖更长时间范围的 manifest 元数据。
5、稳定性调优:多实例隔离 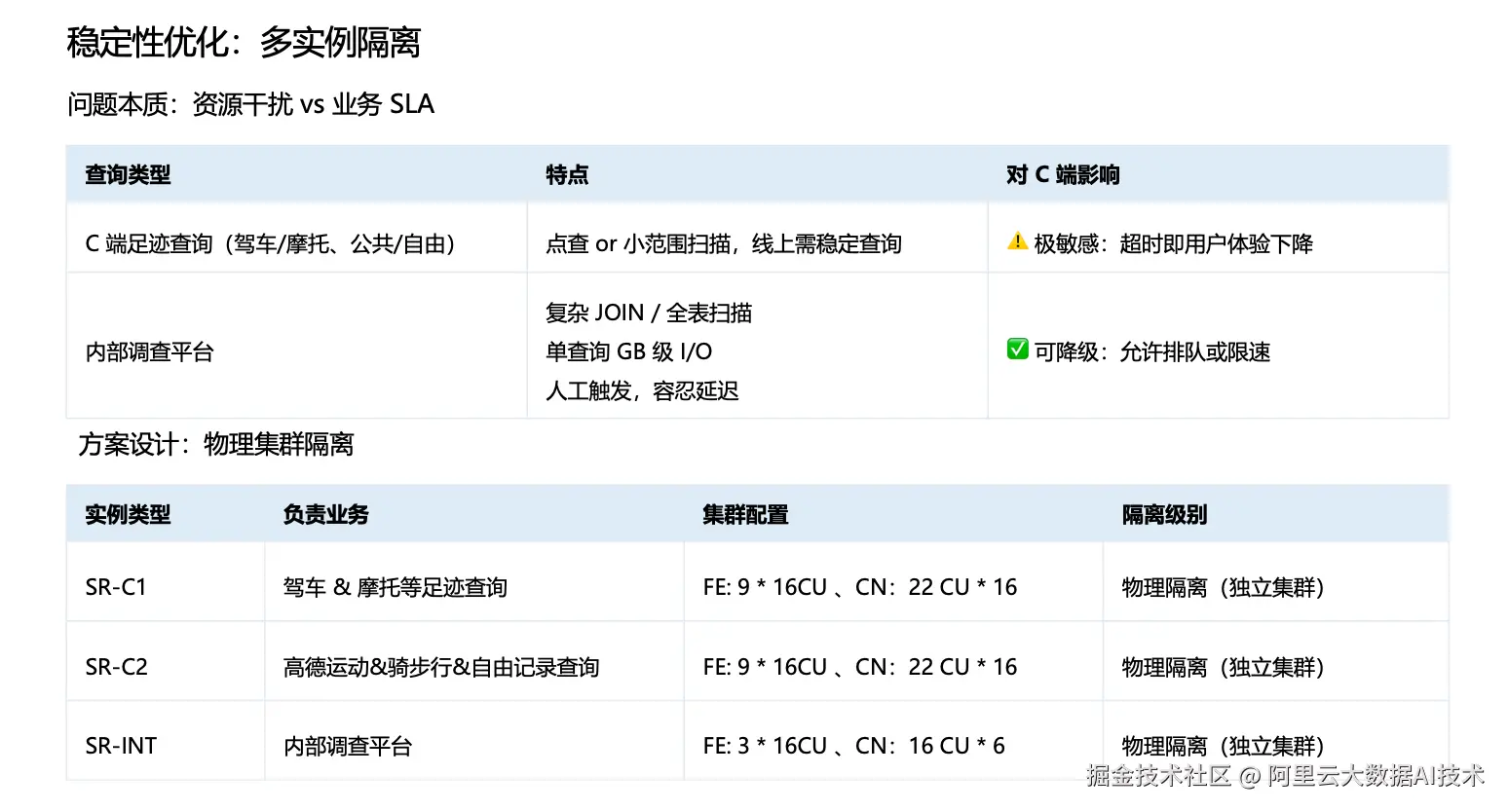
最后一类需要重点解决的是稳定性与资源隔离问题。前文提到,轨迹数据既服务于 C 端在线业务,也支撑内部调查平台等内部工具,两类业务在 SLA 与查询特征上存在明显差异,若缺乏隔离机制,容易产生资源干扰。
以 C 端足迹类查询为例,其典型特征是点查或小范围扫描,对响应时延(RT)高度敏感;一旦出现超时或明显抖动,用户体验会直接受影响。
相比之下,内部调查平台的查询更多由内部同学按需触发,常见形态包括复杂 Join、更大范围扫描甚至全表扫描,单次查询可能带来 GB 级 I/O 开销。由于其主要用于分析与排查,该类场景对延迟具备更高容忍度。
为解决不同业务 SLA 带来的稳定性问题,我们将SR集群采用物理隔离的方式进行资源治理:将 C 端业务拆分为两个集群,同时将内部调查平台独立部署在一个规模相对较小的集群中。通过这种方式,不同场景之间在查询时候的资源竞争得到有效缓解,既避免了相互干扰,也更好地保障了 C 端业务的 SLA。
高德地图实时湖仓未来规划
前文提到,我们所在部门是数据中台,承担高德实时与离线流量的统一入口职责。除轨迹数据外,平台还覆盖多种类型的业务数据。
本次在轨迹场景中实现了流批一体的落地验证,后续将进一步扩大业务范围:
-
逐步将流批一体能力扩展到高德其他基础服务的日志类数据。
-
与下游 BI 团队及算法团队打通从数据生产、治理到消费的全链路协作。
在此基础上,我们也计划围绕上述多源业务数据,对用户行为与偏好进行特征挖掘,并将相关能力进一步与 AI Agent 结合,形成面向业务的智能化赋能路径。