1、Kafka生产者原理-Producer
1.1 生产者发送流程
消息发送的整体流程。生产端主要由两个线程协调运行。这两条线程分别为main线程和sender线程(发送线程)。
在创建KafkaProducer的时候,创建了一个Sender对象,并且启动了---个IO线程。
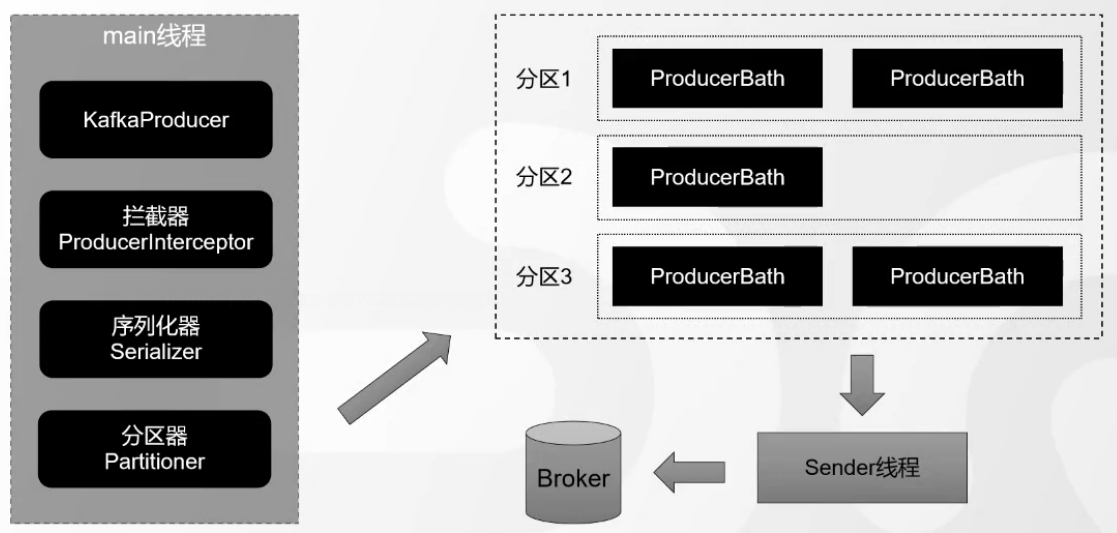
1.1.1 拦截器
第二步是执行拦截器的逻辑,在producer.send方法中:
java
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);拦截器的作用是实现消息的定制化(类似于Spring Interceptor、MyBatis的插件、Quartz的监听器)。拦截器定义在生产者代码:
java
List<String> interceptors = new ArrayList<>();
interceptors.add(" com.xxx.interceptor.Charginginterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);举个例子,假设发送消息的时候要扣钱,发一条消息1分钱(按量付费功能),就可以用拦截器实现。
java
public class Charginginterceptor implements ProducerInterceptor<String, String> {
//发送消息的时候触发
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
System.out.println("1分钱1条消息,不管那么多反正先扣钱");
return record;
}
//收到服务端的ACK的时候触发
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
System.out.pnntln(n消息被服务端接收啦");
}
@Override
public void close() {
System.out.printin("生产者关闭了");
}
//用键值对配置的时候触发
@Override
public void configure(Map<String, ?> configs) {
System. out.piintln(n configure...H);
}
}1.1.2 序列化
接下来是利用指定的工具对key和value进行序列化:
java
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());kafka针对不同的数据类型自带了相应的序列化工具。
除了自带的序列化工具之外,可以使用如Avro、JSON、Thrift. Protobuf等,或者使用自定义类型的序列化器来实现,实现Serializer接口即可。
1.1.3 分区路由
然后是分区指定:
java
int partition = partition(record, serializedKey, serialized Value, cluster);一条消息会发送到哪个partition呢?它返回的是一个分区的编号,从0开始。有四种情况:
- 指定了partition------直接将指定的值直接作为partiton值。
- 没有指定partition,自定义了分区器------将使用自定义的分区器算法选择分区。
- 没有指定partition,没有自定义分区器,但是key不为空------使用默认分区器DefaultPartitioner,将key的hash值与topic的partition数进行取余得到partition值;
- 没有指定partition,没有自定义分区器,但是key是空的------第一次调用时随机生成一个整数(后面每次调用在这个整数上自增),将这个值与topic可用的partition总数取余得到 partition值,也就是常说的round-robin算法。
1.1.4 消息累加器
选择分区以后并没有直接发送消息,而是把消息放入了消息累加器:
java
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptcallback, remainingWaitMs);RecordAccumulator 本质上是一个 ConcurrentMap:
java
ConcurrentMap<TopicPailition Deque<ProducerBatc>> batches;---个partition ---个Batch。batch满了之后,会唤醒Sender线程,发送消息:
java
if (result.batchlsFull || result.newBatchCreated) {
log.trace(Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}1.2 消息应答机制ACK
1.2.1 服务端响应策略
生产者的消息是不是发出去就完事了?如果说网络出了问题,或者说kafka服务端接收的时候出了问题,这个消息发送失败了,生产者是不知道的。所以,kafka服务端应该要有一种响应客户端的方式,只有在服务端确认以后,生产者才发送下一轮的消息,否则重新发送数据。
服务端什么时候才算接收成功呢?因为消息是存储在不同的partition里面的,所以是写入到partition之后响应生产者。当然,单个partition (leader)写入成功,还是不够可靠,如果有多个副本,follower 也要写入成功才可以。
为了安全性考虑,Kafka会等待所有的follower全部完成同步,才发送ACK给客户端,延迟相对来说高一些,但是节点挂掉的影响相对来说小一些,因为所有的节点数据都是完整的。
1.2.2 ISR
然而以上方案仍然存在问题:假设leader收到数据,所有follower都开始同步数据,但是有一个follower出了问题,没有办法从leader同步数据。按照这个规则,leader就要一致等待,无法发送 ack。
从概率的角度来讲,这种问题肯定是会出现的,就是某个follower出问题了,怎么解决呢?所以我们的规则就不能那么粗暴了,把规则改一下,不是所有的follower都有权利 让我等待,而是只有那些正常工作的follower同步数据的时候我才会等待。
我们应该把那些正常和leader保持同步的replica维护起来,放到一个动态set里面,这个就叫做in-sync replica set (ISR)。现在只要ISR里面的follower同步完数据之后,我就给客户端发送ACK。如果一个follower长时间不同步数据,就要从ISR剔除。同样,如果后面这个follower重新与leader保持同步,就会重新加入ISR。时间间隔由以下参数决定:
java
replica.lag.time.max.ms=100001.2.3 ACK应答
当然,如果所有的数据都一视同仁,而且这种策略只能由服务端决定,这就不是很灵活了。有一些数据丢了无所谓,我只想要快,不管它落没落盘同没同步,怎么办呢?
Kafka为客户端提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择相应的配置。
- acks=0: producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
- acks=1(默认): producer 等待 broker 的 ack, partition 的 leader 落盘成功后 返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
- acks=-1 (all) : producer等待 broker 的 ack, partition 的 Ieader和 follower全部落盘成功后才返回ack。
三种机制,性能依次递减(producer吞吐量降低),数据健壮性则依次递增。我们可 以根据业务场景使用不同的参数。