执行摘要
基准测试显示,在Akamai云上运行的NVIDIA RTX PRO™ 6000 Blackwell推理吞吐量比H100最高提升1.63倍,在100个并发请求下每台服务器达到24,240 TPS。
如您所在的企业也在考虑采购云服务或进行云迁移,
点击链接了解Akamai Linode解决方案,现在申请试用可得高达5000美元专属额度
为Akamai推理云进行基准测试
本周,Akamai宣布推出Akamai推理云。我们将自身在全球分布式架构方面的专业知识与NVIDIA Blackwell AI基础设施相结合,从根本上重新思考并扩展了释放AI真正潜力所需的加速计算能力。
Akamai推理云平台将NVIDIA RTX PRO™服务器(配备NVIDIA RTX PRO 6000 Blackwell服务器版GPU、NVIDIA BlueField-3® DPU和NVIDIA AI Enterprise软件)与Akamai的分布式云计算基础设施和全球边缘网络(在全球拥有超过4,400个站点)相结合。
高效、通用且优化的GPU
分布式推理和下一代智能体体验需要高效、通用并能针对并发实时工作负载进行优化的GPU。RTX PRO 6000 Blackwell完全满足这三项要求。其FP4精度模式以数据中心级GPU的一小部分功耗和成本提供了卓越的吞吐量,使得将其部署到数百个站点变得切实可行。
该架构支持在单个GPU上并发处理包括文本、视觉和语音在内的多模态工作负载,减少了对专用加速器的需求,并限制了不必要的网络数据传输。
NVIDIA RTX Pro服务器针对代理式AI、工业和物理AI、科学计算、数据分析与模拟、视觉计算和企业应用等工作负载进行了优化。
NVIDIA强调,这些服务器能够实现高达6倍的大语言模型推理吞吐量、4倍更快的合成数据生成速度、7倍更快的基因组序列比对速度、3倍更高的工程模拟吞吐量、4倍更佳的实时渲染性能,以及4倍更多的并发多实例GPU工作负载。
性能验证
为了验证性能,我们测试了在Akamai云上运行的NVIDIA RTX Pro 6000 Blackwell服务器版GPU,并使用NVIDIA LaunchPad环境将其与NVIDIA H100 NVL 96GB进行了基准比较。
我们的目标是了解,与目前行业的黄金标准相比,下一代RTX Pro 6000 GPU在实际推理工作负载中的表现如何。
基准测试结果展示
基准测试结果证实了NVIDIA RTX Pro 6000 Blackwell在Akamai云上的设计优势。
- 相较于H100(FP8),吞吐量提升1.63倍,这表明RTX Pro 6000 Blackwell以更小巧、更易于部署的规格提供了数据中心级的性能,非常适合于分布式环境。
- 从FP8切换到FP4带来的1.32倍性能提升,展示了NVIDIA的精度效率如何直接转化为在边缘更快、更具成本效益的推理。
- 在100+并发请求下保持稳定的性能,验证了该GPU处理全球分布式推理中多租户、对延迟敏感的工作负载的能力。
综合来看,这些结果表明,Blackwell的效率和并发性优势使其成为Akamai分布式推理架构的理想基础,能够在我们的全球网络中提供高吞吐、低延迟和可扩展的性能。
基准测试概述
我们遵循NVIDIA的基准测试方法来评估一致负载条件下的推理性能。在本文中,我们将介绍设置、方法和关键发现,并讨论这些结果对在Akamai云上运行AI工作负载的意义。
设置
为了评估Akamai云上的NVIDIA RTX Pro 6000 GPU,我们使用了Llama-3.3-Nemotron-Super-49B-v1.5模型,这是一个源于Meta Llama-3.3-70B-Instruct(即参考模型)的大语言模型。它是一个针对推理、人类聊天偏好以及智能体任务(如RAG和工具调用)进行后训练的推理模型。
我们为同一模型使用了两个NVIDIA推理微服务配置文件,以比较精度模式并了解其对性能和效率的影响。这两个配置文件------tensorrt_llm-rtx6000_blackwell_sv-fp8-tp1-pp1-throughput-2bb5 和 tensorrt_llm-rtx6000_blackwell_sv-nvfp4-tp1-pp1-throughput-2bb5------除了精度设置外完全相同。
第一个使用FP8 精度,第二个使用NVIDIA的FP4精度。NVIDIA的FP4版本直接在NVIDIA Blackwell GPU中得到支持。
通过运行两者,我们旨在观察降低数值精度如何影响吞吐量和延迟。NVFP4以低于1%的精度损失带来了显著的性能和效率提升,实现了更快、更低功耗的大规模推理,而FP8则提供了更高的数值精度。比较两者有助于为实际工作负载确定速度、效率和推理保真度之间的最佳权衡。
我们在位于Akamai云LAX数据中心的NVIDIA RTX Pro 6000 Blackwell服务器版GPU上运行了测试。为了进行比较,我们使用了NVIDIA LaunchPad环境中的NVIDIA H100 GPU。
方法论
对于此基准测试,我们运行了一个旨在测量现实负载条件下基线推理性能的压力测试。每个请求处理200个输入令牌并生成200个输出令牌,代表了大语言模型典型的短提示-响应交互。
为了测试可扩展性和一致性,我们执行了100个并发运行,使我们能够观察系统处理持续同时推理量时的吞吐量和延迟行为。这种方法提供了模型和硬件在生产类工作负载下性能的一个受控但具有代表性的快照。
我们测量了两个关键指标:首令牌时间(TTFT)和每秒令牌数(TPS)。TTFT以毫秒为单位,衡量模型在收到提示后开始生成响应的速度------这是延迟和用户感知响应性的重要指标。TPS衡量整体吞吐量,显示系统在生成开始后每秒可以生成多少令牌。
两者结合提供了现实世界性能的平衡视图,反映了初始推理的速度以及负载下的持续输出效率。
作为基准测试方法的一部分,我们运行了两组测试来评估NVIDIA RTX 6000 Blackwell服务器版GPU的性能特征。
- FP4与FP8精度比较
我们在同一模型上测试了两个NIM配置文件------一个使用FP8 精度,另一个使用FP4精度------以衡量NVIDIA新型FP4量化对推理性能的影响。NVIDIA强调FP4是效率和吞吐量方面的一项重大进步。 - RTX 6000与H100 GPU比较
然后,我们将RTX 6000 Blackwell 的结果与在NVIDIA LaunchPad 环境中运行的H100 GPU 进行了比较,通过查看两个NIM配置文件FP8 及FP4来评估实际推理优势。这使我们能够评估RTX 6000不仅在不同精度模式下的表现,还与NVIDIA当前的数据中心GPU标准进行对比。
详细结果
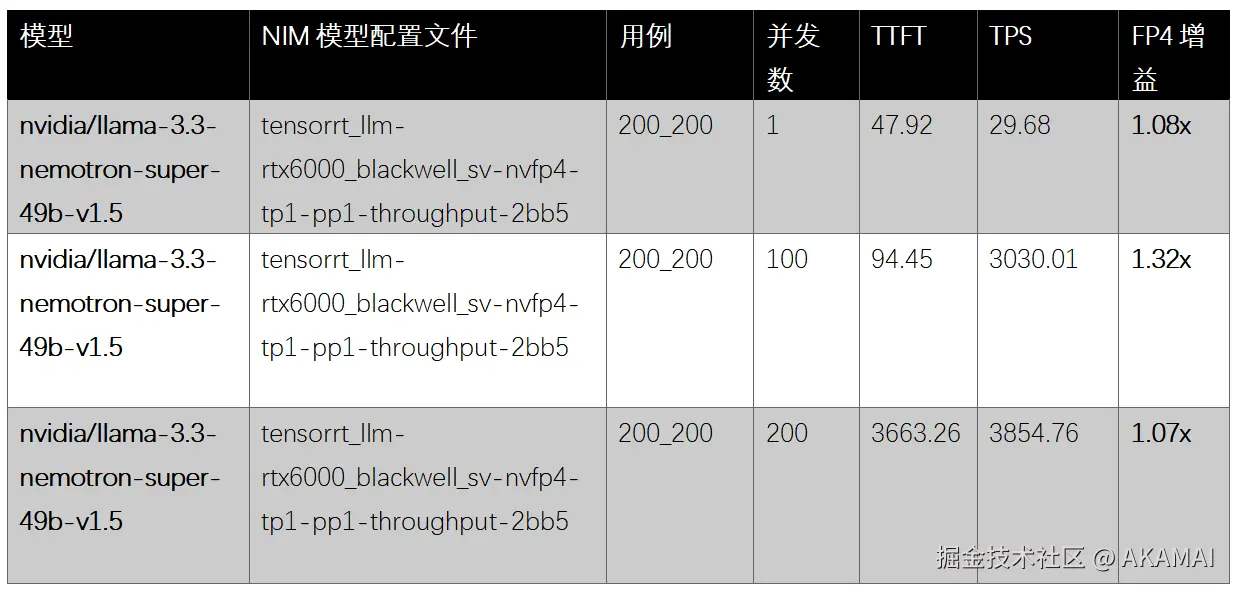
我们确定最佳并发级别为100 ------即在100个同时推理请求下,我们观察到了最稳定和最具代表性的性能结果。在C=100时,RTX 6000从FP8切换到FP4精度带来了1.32倍的性能提升,显示了NVIDIA FP4量化的效率增益。
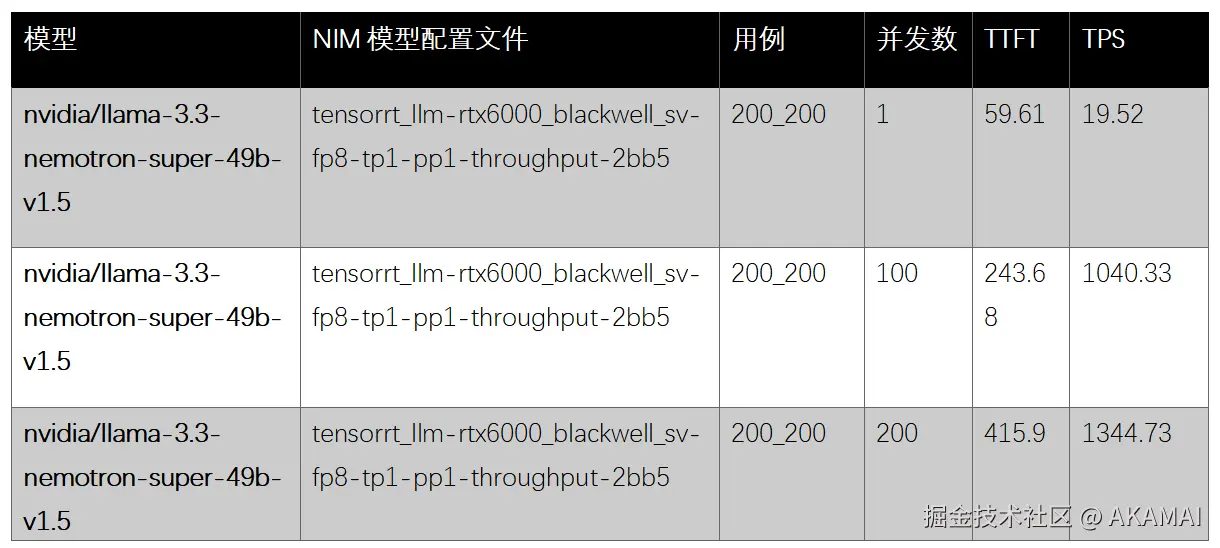
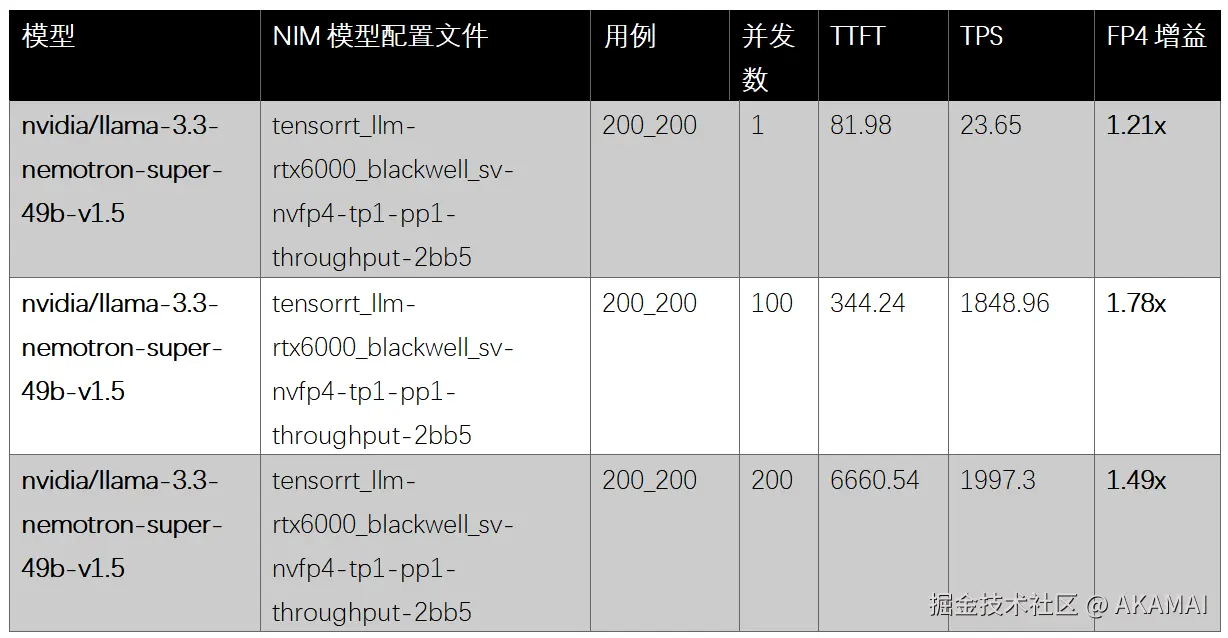
与使用FP8精度的H100相比,RTX Pro 6000 Blackwell服务器在使用NVFP4精度时实现了1.63倍 的性能提升。即使使用FP8,Blackwell服务器也展示了1.21倍的优势,显示了超越旧FP8格式的下一代推理优化。
总体而言,在此并发级别下,RTX Pro 6000 Blackwell服务器实现了3,030.01 TPS ,这相当于我们基础设施即服务(IaaS)虚拟机产品可提供高达24,240.08 TPS,突显了Blackwell架构在Akamai云上强大的推理性能和可扩展性。
测试1:FP8与FP4精度比较
RTX Pro 6000 Blackwell FP8与FP4的性能结果。
LAX:NVIDIA RTX Pro 6000 Blackwell服务器 FP8

LAX:NVIDIA RTX PRO 6000 Blackwell服务器 FP4
测试2:RTX Pro 6000 Blackwell服务器与H100 GPU比较
H100 NVL FP8与RTX Pro 6000 Blackwell服务器 FP8和FP4的性能结果比较。
LaunchPad:H100 NVL FP8

LaunchPad:NVIDIA RTX PRO 6000 Blackwell服务器 FP8
LaunchPad:NVIDIA RTX PRO 6000 Blackwell服务器 FP4
结论
本次基准测试旨在评估NVIDIA RTX Pro 6000 Blackwell服务器版GPU在Akamai云上执行LLM推理的表现,以及在相似假设下与NVIDIA H100 GPU的比较。使用NVIDIA推荐的基准测试方法,我们测试了FP8和FP4两种精度模式,以了解性能、效率和延迟之间的权衡。
结果清楚地表明,FP4带来了可衡量的增益,在RTX 6000上相比FP8吞吐量提升1.32倍 。与FP8下的H100相比,RTX 6000(FP4)实现了1.63倍的性能提升,突显了Blackwell架构在推理工作负载方面的潜力。
这些发现表明,在Akamai分布式云上运行的RTX 6000 GPU能够以更低的成本和延迟为实际AI推理提供高吞吐量和高效的扩展。对于正在评估GPU方案的团队而言,这种组合能在全球范围内达成速度、效率与可及性的卓越平衡。
获取访问权限
注册以获取在Akamai推理云上使用RTX Pro 6000 Blackwell服务器版的访问权限。
如您所在的企业也在考虑采购云服务或进行云迁移,
点击链接了解Akamai Linode解决方案,现在申请试用可得高达5000美元专属额度