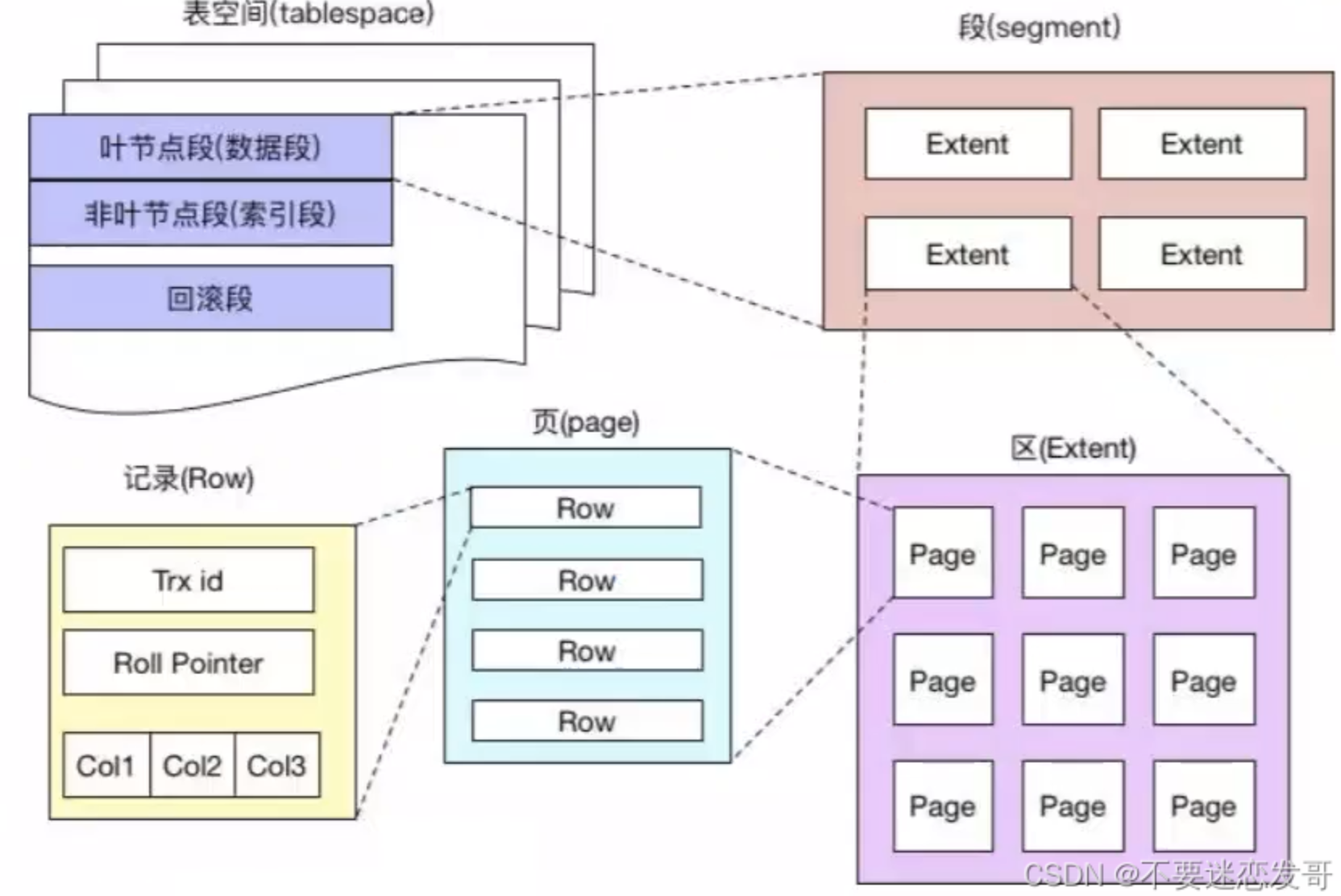
一、用Excel类比快速理解
想象MySQL的存储结构就像一个Excel文件的组织方式:
表空间(数据库)
↓
段(Sheet页签)→ 数据段、索引段、回滚段
↓
区(若干列的范围)→ 64个页的连续空间
↓
页(一行行的数据)→ 16KB大小,对应Excel的一个范围
↓
行(Excel中的一行)→ 实际的用户数据①、段(Segment):表空间的大分类
什么是段?
段是最大的逻辑单位 ,一个表空间由多个段组成。不同的段存放不同类型的数据。
常见的三种段
一个表 article:
┌─────────────────────┐
│ 表空间 │
├─────────────────────┤
│ ┌─ 数据段 │
│ │ (存放叶子节点) │
│ │ 存储真实用户数据 │
│ │ │
│ ├─ 索引段 │
│ │ (存放非叶节点) │
│ │ 存储B+树的树枝 │
│ │ │
│ └─ 回滚段 │
│ (存放undo log) │
│ 事务回滚时用 │
└─────────────────────┘具体例子理解
假设你有一个 article 表:
sql
CREATE TABLE article (
id INT PRIMARY KEY,
title VARCHAR(255),
content TEXT,
author VARCHAR(100)
);
-- 创建索引
CREATE INDEX idx_author ON article(author);此时MySQL会创建的段:
article表空间:
1. 数据段 - 存储所有行的实际数据
├─ id=1, title="MySQL教程", content="详细讲解", author="张三"
├─ id=2, title="Java指南", content="从入门到精通", author="李四"
└─ id=3, title="Python基础", content="快速上手", author="王五"
2. 索引段(主键索引) - 存储B+树的非叶子节点
└─ 树枝节点(不是真实数据,只是指向)
3. 索引段(idx_author索引) - 存储辅助索引的非叶子节点
└─ 树枝节点(不是真实数据,只是指向)
4. 回滚段 - 存储undo log
└─ UPDATE时的旧值记录
②、区(Extent):段内的分组单位
什么是区?
区是连续页的集合 ,一个区通常包含 64个连续的页。
计算:
1个页 = 16 KB
1个区 = 64个页 = 64 × 16KB = 1024KB = 1MB为什么要用区?
不用区(逐个分配页)的问题:
假设你有1000万行数据要存储:
第一次磁盘IO:读取第1个页(16KB)
第二次磁盘IO:读取第2个页(16KB)
...
第一百万次磁盘IO:读取第100万个页
总共要做100万次磁盘寻道!
效率太低,因为磁盘寻道时间很长(5-10毫秒)用区(64个页一起分配)的好处:
第一次磁盘IO:读取区1(64个页,1MB)
第二次磁盘IO:读取区2(64个页,1MB)
...
总共只要做1万次磁盘寻道,效率提高100倍!
这就是为什么用区而不用单独的页区的物理结构
磁盘上的实际分布:
段内存布局:
┌─────────────────────────────────────────────┐
│ 区1 │
│ ┌─────────────────────────────────────────┐ │
│ │ 页1 │ 页2 │ 页3 │ ... │ 页64 │ │
│ │16KB │16KB │16KB │ │ 16KB │ │
│ │ │ │ │ │ (共1MB) │ │
│ └─────────────────────────────────────────┘ │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 区2 │
│ ┌─────────────────────────────────────────┐ │
│ │ 页65 │ 页66 │ 页67 │ ... │ 页128 │ │
│ │16KB │16KB │16KB │ │ 16KB │ │
│ │ │ │ │ │ (共1MB) │ │
│ └─────────────────────────────────────────┘ │
└─────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────┐
│ 区3 ... │
└─────────────────────────────────────────────┘③、页(Page):数据存储的基本单元
什么是页?
页是InnoDB最小的IO单位,标准大小为 16 KB。
关键点:
一次磁盘IO的最小单位就是1个页不管你只查询1行还是1000行,如果在同一个页内,都是一次IO
如果数据跨多个页,就需要多次IO
页的内部结构
一个16KB的页分为几个部分:
一个页(16KB = 16384字节)的结构:
┌──────────────────────────────────────────┐
│ 页头(Page Header)- 48字节 │
│ 记录页的状态信息、行数等 │
├──────────────────────────────────────────┤
│ │
│ 用户数据区(User Records)- 大约15KB │
│ 存储实际的行数据 │
│ │
│ 例如: │
│ ┌──────────────────────────────────┐ │
│ │行1: id=1, title="MySQL", ... │ │
│ ├──────────────────────────────────┤ │
│ │行2: id=2, title="Java", ... │ │
│ ├──────────────────────────────────┤ │
│ │行3: id=3, title="Python", ... │ │
│ ├──────────────────────────────────┤ │
│ │... 直到页满(大约16KB) │ │
│ └──────────────────────────────────┘ │
│ │
├──────────────────────────────────────────┤
│ 页尾(Page Trailer)- 8字节 │
│ 校验和等信息 │
└──────────────────────────────────────────┘一个页能存多少行数据?
取决于每行的大小:
假设你的article表每行数据大小为500字节:
一个页(16KB)能存多少行?
16384 字节 ÷ 500字节/行 = 32行
假设你的user表每行数据大小为200字节:
16384 字节 ÷ 200字节/行 = 81行
所以行数不固定,取决于列定义的大小磁盘IO的体现
示例:SELECT * FROM article WHERE id = 2
执行过程:
1. MySQL找到存储id=2的页位置(假设在第5个页)
2. 从磁盘读取第5个页到内存(一次IO,读取16KB)
3. 在内存中搜索id=2的记录
4. 返回数据给应用
关键:不管这个页里有几行,一次都是读16KB!④、行(Row):实际的用户数据
什么是行?
行是MySQL存储的最小逻辑单位,对应一条记录。
article表的一行数据:
┌─────────────────────────────────────────┐
│ id=1 │
│ title="深入理解MySQL" │
│ content="这是一篇很长的文章..." │
│ author="张三" │
└─────────────────────────────────────────┘行格式(Row Format)
Excel的一行(用户数据)
↓
如何拆分单元格?(行格式决定)↓
单元格内容存储在哪里?(行内或行外)
MySQL有多种行存储格式,MySQL 8.0默认是 DYNAMIC:
行格式对比:
COMPACT(较早版本):
┌──────────────────────────────────┐
│ 变长字段长度 │ NULL标识位 │ 字段值 │
│(一起存储) │ │ │
└──────────────────────────────────┘
如果数据超过限制 → 在溢出页中存储指针
DYNAMIC(MySQL 8.0默认):
┌──────────────────────────────────┐
│ 变长字段长度 │ NULL标识位 │ 字段值 │
│(一起存储) │ │ │
└──────────────────────────────────┘
更激进地将长数据存储到溢出页
比COMPACT更节省当前页的空间MySQL行格式:可以决定内容放在当前单元格还是另开一个"备注页"
关键点:
-
一行中的所有列值如何组织?
-
变长字段(VARCHAR、TEXT)如何存储?
-
NULL值如何处理?
-
行溢出(一行太大)时怎么办?
可以通过
sql
show table status like '%article%' 查看行格式。
行溢出(Row Overflow)
当一行的某个字段(比如TEXT、VARCHAR)特别大时:
一个页只有16KB,但某行数据超过16KB怎么办?
DYNAMIC格式的处理:
┌─────────────────────────────────┐
│ 当前页(16KB) │
├─────────────────────────────────┤
│ id=1 │
│ title="标题"(很短) │
│ content=指向溢出页1的指针 → │
│ author="张三" │
│ │
│ 其他行... │
│ │
└─────────────────────────────────┘
↓
┌─────────────────────────────────┐
│ 溢出页(Overflow Page) │
├─────────────────────────────────┤
│ 存储超大的content字段值 │
│ "这是一篇超级超级长的内容..." │
│ "可以超过1MB..." │
└─────────────────────────────────┘DYNAMIC格式的特点:
如果一行总大小超过页的阈值(通常是8KB):
DYNAMIC的做法:整行都放溢出页?
不对!更准确地说:
TEXT/BLOB等大字段:
- 完全存储在溢出页
- 行内只留20字节的指针
例如一个2KB的TEXT字段:
在行内:20字节指针
在溢出页:完整的2KB数据。
示例:
sql
CREATE TABLE blog (
id INT PRIMARY KEY,
title VARCHAR(255),
content TEXT, -- 可能很大,几MB
summary VARCHAR(500)
) ROW_FORMAT=DYNAMIC;
-- 存储方式:
-- 行内:id、title、summary、content指针
-- 溢出页:完整的content内容COMPACT格式的特点
TEXT/BLOB字段处理:
前768字节存储在行内
剩余部分存储在溢出页
行内额外存储20字节指针指向剩余部分
总行内占用:768 + 20 = 788字节
示例:
sql
-- 假设我们经常查询content的前500个字符
SELECT LEFT(content, 500) FROM blog WHERE id = 1;
-- COMPAT格式的优势:
-- 数据可能在行内(前768字节),不需要访问溢出页
-- 减少一次磁盘IO完整的层级关系图
表空间(整个数据库文件)
│
├─ 数据段 Segment
│ │
│ ├─ 区1 Extent (1MB = 64 × 16KB)
│ │ ├─ 页1 Page (16KB)
│ │ │ ├─ 行1 Row (id=1, title="MySQL", ...)
│ │ │ ├─ 行2 Row (id=2, title="Java", ...)
│ │ │ ├─ 行3 Row (id=3, title="Python", ...)
│ │ │ └─ ... 更多行直到页满
│ │ ├─ 页2 Page (16KB)
│ │ │ ├─ 行32 Row
│ │ │ ├─ 行33 Row
│ │ │ └─ ... 继续
│ │ └─ ... 页64 Page
│ │
│ ├─ 区2 Extent (1MB)
│ │ ├─ 页65 Page
│ │ └─ ... 页128 Page
│ │
│ └─ 区N Extent
│
└─ 索引段 Segment
├─ 区1 Extent
│ ├─ 页1 Page (存储B+树非叶节点)
│ └─ ...
└─ ...磁盘IO成本分析
小表(< 1MB)
表 small_user (100行,总大小10KB)
初期分配:
- 分配1个区(64个页,1MB)
- 但实际只用了1个页(16KB)
- 浪费了:1MB - 16KB = 992KB
磁盘IO:读取整个表只需1次IO中等表(1-100MB)
表 article (100万行,总大小50MB)
初期分配:
- 分配50个区(50 × 1MB = 50MB)
- 总页数:50 × 64 = 3200个页
扫描整个表需要多少次IO?
- 最坏情况:3200次IO
- 实际顺序扫描:会优化成连续读取,减少寻道时间查询时的磁盘IO
查询1:SELECT * FROM article WHERE id = 5
通过主键索引定位到某一页
1次IO读取该页(16KB)
返回数据
查询2:SELECT * FROM article WHERE id IN (1,2,3,4,5)
如果这5行在同一个页 → 1次IO
如果分在3个页 → 3次IO
如果分在5个页 → 5次IO
所以为什么要建索引?
通过索引快速定位所需的页
减少需要读取的页数
减少磁盘IO
Java程序员的实际应用
①、为什么批量插入要分批?
java
// 不好的做法:逐条插入
for (int i = 0; i < 100000; i++) {
// 每条INSERT都会涉及:
// 1. 找到对应的页
// 2. 修改页内数据
// 3. 写redo log
// 4. 提交事务
// 100000次操作,效率很低
insert(data);
}
// 更好的做法:批量插入
List<Data> batch = new ArrayList<>();
for (int i = 0; i < 100000; i++) {
batch.add(data);
if (batch.size() == 1000) {
// 1000条一起提交
batchInsert(batch);
batch.clear();
}
}②、为什么查询的列数少更快?
sql
-- 慢:读取整行数据
SELECT * FROM article WHERE id = 1;
-- 需要读16KB的页,虽然只需要id和title,但整行都读了
-- 快:只读需要的列
SELECT id, title FROM article WHERE id = 1;
-- 同样读16KB的页,但只解析需要的字段③、为什么要建立合适的索引?
sql
-- 没有索引:全表扫描
SELECT * FROM article WHERE author = '张三';
-- 需要读取所有的数据页,可能几百次IO
-- 有索引:快速定位
CREATE INDEX idx_author ON article(author);
-- 通过索引段找到相关的页,可能只需几次IO总结记忆口诀
一个表,分成多个段(数据段、索引段、回滚段)
一个段,分成多个区(每个区1MB,包含64个页)
一个区,分成多个页(每个页16KB)
一个页,存储多行数据(根据行大小而定)
磁盘读写的单位是页(16KB)
内存和磁盘之间的交互以页为单位
优化数据库性能的核心就是减少页的读取次数MySQL存储结构:从物理文件到逻辑结构详解
①、物理层:数据库文件是什么?
物理文件结构
sql
你的硬盘:
/var/lib/mysql/your_database/
├── your_table.ibd # 表空间文件(物理文件)
├── other_table.ibd
└── ibdata1 # 系统表空间
这个.ibd文件:
┌──────────────────────────────────────────┐
│ 一堆二进制数据 │
│ 00010101010101010101010101010101... │
│ 01010101010101010101010101010101... │
│ ... 持续几MB到几GB │
└──────────────────────────────────────────┘
肉眼看起来:全是0和1
MySQL看起来:有组织的段、区、页、行为什么需要逻辑结构?
sql
如果没有逻辑结构:
文件就是一串连续的字节:0x00 0x01 0x02 ... 0xFF
问题:
1. 如何找到id=100的数据?
2. 如何知道哪些数据属于索引?
3. 如何高效管理空间?
4. 如何支持事务回滚?
答案:建立逻辑结构(段、区、页)②、逻辑层:段是什么?
段在文件中的存在方式
sql
表空间文件.ibd内部:
物理布局:
┌─────────────────────────────────────────┐
│ 区1 │ 区2 │ 区3 │ 区4 │ 区5 │ 区6 │ ... │
│ 1MB │ 1MB │ 1MB │ 1MB │ 1MB │ 1MB │ │
└─────────────────────────────────────────┘
逻辑布局:
数据段 = {区1, 区3, 区5} ← 不一定连续!
索引段 = {区2, 区4} ← 物理上分散,逻辑上统一
回滚段 = {区6} ← 单独管理
段管理器(Segment Header)记录:
"数据段包含:区1、区3、区5..."③、逻辑层:区是什么?
区是物理上连续的页集合
sql
关键点:区在物理上是连续的!
物理文件.ibd:
┌─────────────────────────────────────────────────┐
│ ... 其他数据 ... │
│ │
│ 区边界(从这里开始连续1MB) │
│ ↓ │
│ 页1 页2 页3 ... 页64 │
│ (16KB) (16KB) (16KB) (16KB) │
│ │
│ ↑ │
│ 这64个页在磁盘上是物理连续的! │
│ │
│ ... 其他数据 ... │
└─────────────────────────────────────────────────┘④、逻辑层:页是什么?
页是MySQL的最小I/O单元
sql
物理事实:
1. 磁盘一次最少读512字节(一个扇区)
2. 文件系统一次最少读4KB(一个块)
3. MySQL一次最少读16KB(一个页)
为什么是16KB?
平衡点:太大浪费内存,太小增加IO次数
经过测试,16KB在大多数场景下最优