一、模型预训练
上一章中,我们从零手写实现了LLaMA模型结构及Pretrain、SFT全流程,深入理解了LLM的模型原理和训练细节。不过,在实际应用中,手写实现的LLM训练存在下面的问题:
手写实现LLM结构工作量大,难以实时跟进最新模型的结构创新;
从零实现的LLM训练无法较好实现多卡分布式训练,训练效率较低;
和现有预训练LLM不兼容,无法使用预训练好的模型参数。
因此,本章中,我们将会介绍目前LLM领域的主流训练框架Transformers,并结合分布式框架deepspeed、高效微调框架peft等主流框架,实践使用transformers进行模型Pretrain、SFT全流程,更好对接业界主流LLM技术方案。
1.框架介绍
transformers是由Hugging Face开发的NLP框架,通过模块化实现了对BERT、GPT、LLaMA、T5、ViT等上百种主流模型架构的统一支持。通过使用该框架,开发者无需重复实现基础网络结构,通过AutoModel类即可一键加载任意预训练。
同时,框架内置的Trainer类封装了分布式训练的核心逻辑,支持PyTorch原生DDP、DeepSpeed、Megatron-LM等多种分布式训练策略。通过简单配置训练参数,即可实现数据并行、模型并行、流水线并行的混合并行训练,在8卡A100集群上可轻松支持百亿参数模型的高效训练。配合SavingPolicy和LoggingCallback等组件,实现了训练过程的自动化管理。还支持与Deepspeed、peft、wandb、Swanlab等框架进行集成,直接通过参数设置即可无缝对接,从而快速、高效实现LLM训练。
更为重要的是,HuggingFace基于Transformers框架搭建了其庞大的AI社区,开放了数亿个预训练模型参数、25万+不同类型数据集,通过Transformers、Dataset、Evaluate等多个框架实现对预训练模型、数据集及评估函数的集成,从而帮助开发者进行模型的开发与应用。
当前时代,模型结构的调整和重新预训练越来越少,开发者更多的业务应用在与使用预训练好的LLM进行Post Train和SFT,来支持自己的下游业务应用。且由于预训练模型体量大,便捷集成deepspeed等分布式训练框架逐渐成为LLM时代NLP模型训练的必备技能。因此,Transformers已经逐渐成为主流框架。同时,新发布的开源LLM如DeepSeek、Qwen也都会第一时间在Transformers社区开放其预训练权重与模型调用Demo。通过使用Transformers框架可以高效便捷地完成LLM训练及开发。下面我们以Transformers为基础,介绍如何实现LLM地Pretrain及SFT。
2.初始化LLM
我们可以使用Transformers的AutoModel类来直接初始化已经实现好的模型。对于任意预训练模型,其参数中都包含有模型的配置信息。如果从头训练一个LLM,可以使用一个已有的模型架构来直接初始化。下面我们以Qwen-2.5-1.5B模型架构为例:
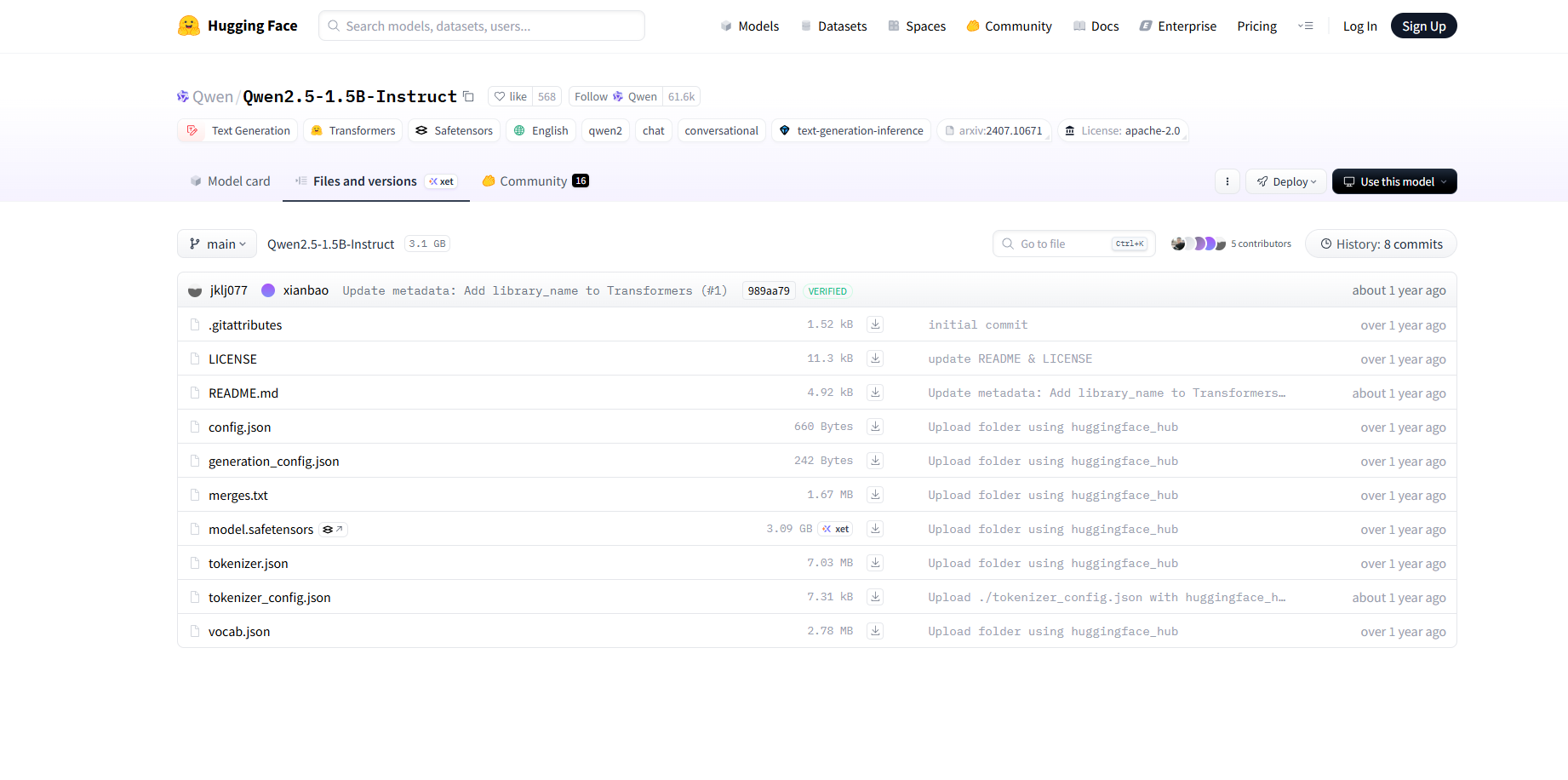
上述界面即为HuggingFace社区中的Qwen-2.5-1.5B模型参数,其中的config.json文件即是模型的配置信息,包括了模型的架构、隐藏层大小、模型层数等,如下图所示:

我们可以沿用该模型的配置信息,初始化一个Qwen-2.5-1.5B模型来进行训练,也可以在该配置信息的基础上进行更改,如修改隐藏层大小、注意力头数等,来定制一个模型结构。HuggingFace提供了Python工具来便捷下载想使用的模型参数:
python
import os
# 设置环境变量,此处使用HuggingFace镜像网站
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# 下载模型
os.system('huggingface-cli download --resume-download Qwen/Qwen-2.5-1.5B --local-dir ./model')模型下载完成之后,可以使用AutoConfig类直接加载下载好的配置文件:
python
# 加载定义好的模型参数-此处以 Qwen-2.5-1.5B 为例
# 使用 transforemrs 的 Config 类进行加载
from transformers import AutoConfig
# 下载参数的本地路径
model_path = "qwen-1.5b"
config = AutoConfig.from_pretrained(model_name_or_path)我们也可以对配置文件进行自定义,然后以同样的方式加载即可。可以使用AutoModel类基于加载好的配置对象生成对应的模型:
python
# 使用该配置生成一个定义好的模型
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_config(config,trust_remote_code=True)一般情况下,我们很少从零初始化LLM进行预训练,较多的做法是加载一个预训练好的LLM权重,在自己的预料上进行后训练。下面,我们介绍如何从下载好的模型参数中初始化一个预训练好的模型。
python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,trust_remote_code=True)类似的,直接使用from_pretrained方法加载即可,这里的model_name_or_path即为下载好的参数的本地路径。我们还需初始化一个tokenizer。这里我们直接使用Qwen-2.5-1.5B对应的tokenizer参数即可。
python
# 加载一个预训练好的 tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)下面我们可以对下载好的模型进行一个测试。
python
#!/usr/bin/env python3
"""
Qwen-2.5-1.5B 模型测试脚本
这个脚本用于测试已下载的 Qwen-2.5-1.5B 模型是否正常工作。
包括模型加载、分词器初始化和简单的推理测试。
使用方法:
python model_test.py
"""
import os
import sys
import torch
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer
from typing import Optional, Tuple
def check_model_files(model_path: str) -> bool:
"""
检查模型文件是否存在
Args:
model_path: 模型路径
Returns:
bool: 模型文件是否完整
"""
required_files = [
"config.json",
"tokenizer.json",
"model.safetensors.index.json"
]
print(f"🔍 检查模型文件完整性: {model_path}")
for file in required_files:
file_path = os.path.join(model_path, file)
if os.path.exists(file_path):
print(f" ✅ {file}")
else:
print(f" ❌ {file} 缺失")
return False
# 检查 safetensors 文件
safetensors_files = [f for f in os.listdir(model_path) if f.endswith('.safetensors')]
if safetensors_files:
print(f" ✅ 找到 {len(safetensors_files)} 个 safetensors 文件")
else:
print(" ⚠️ 未找到 safetensors 文件,模型可能未完全下载")
return True
def load_model_and_tokenizer(model_path: str, device: str = "auto") -> Tuple[AutoModelForCausalLM, AutoTokenizer]:
"""
加载模型和分词器
Args:
model_path: 模型路径
device: 设备类型 ("auto", "cpu", "cuda")
Returns:
tuple: (model, tokenizer)
"""
print(f"🚀 正在加载模型和分词器...")
# 自动选择设备
if device == "auto":
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"📱 使用设备: {device}")
print(f"📁 模型路径: {model_path}")
try:
# 加载分词器
print("🔤 加载分词器...")
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
# 设置填充token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# 加载模型 - 尝试多种方式
print("🧠 加载模型...")
# 方法1: 尝试使用默认参数
try:
if device == "cuda":
dtype = torch.float16
device_map = device
else:
dtype = torch.float32
device_map = None
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
dtype=dtype,
device_map=device_map
)
except Exception as e1:
print(f"⚠️ 方法1失败: {e1}")
print("🔄 尝试方法2: 不使用 device_map...")
# 方法2: 不使用 device_map
try:
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
torch_dtype=torch.float16 if device == "cuda" else torch.float32,
)
# 手动移动模型到设备
model = model.to(device)
except Exception as e2:
print(f"⚠️ 方法2失败: {e2}")
print("🔄 尝试方法3: 使用最低配置...")
# 方法3: 使用最低配置
model = AutoModelForCausalLM.from_pretrained(
model_path,
trust_remote_code=True,
)
model = model.to(device)
model.eval()
print("✅ 模型和分词器加载成功!")
return model, tokenizer
except ModuleNotFoundError as e:
if "Qwen2ForCausalLM" in str(e) or "torchao" in str(e):
print(f"❌ 模块导入失败: {e}")
print("💡 这是已知的 torchao 兼容性问题,建议:")
print("1. 临时解决方案: 卸载 torchao")
print(" pip uninstall torchao -y")
print("2. 或者使用简化测试脚本:")
print(" python simple_model_test.py")
print("3. 或者创建新的虚拟环境重新安装:")
print(" pip install torch transformers")
else:
print(f"❌ 模块导入失败: {e}")
print("💡 建议检查模型文件完整性")
raise
except Exception as e:
print(f"❌ 所有加载方法都失败: {e}")
print("💡 建议:")
print("1. 检查模型文件是否完整")
print("2. 更新 transformers 库: pip install --upgrade transformers")
print("3. 检查 torch 版本兼容性")
print("4. 尝试简化测试脚本: python simple_model_test.py")
raise
def test_inference(
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
prompt: str,
max_length: int = 100,
temperature: float = 0.7,
device: str = "cpu"
) -> str:
"""
执行推理测试
Args:
model: 模型
tokenizer: 分词器
prompt: 输入文本
max_length: 最大生成长度
temperature: 温度参数
device: 设备
Returns:
str: 生成的文本
"""
print(f"\n🧪 推理测试:")
print(f"📝 输入: {prompt}")
print(f"⚙️ 参数: max_length={max_length}, temperature={temperature}")
try:
# 编码输入
inputs = tokenizer(prompt, return_tensors="pt", padding=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
# 生成文本
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=temperature,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 解码输出
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 提取新生成的部分
input_length = len(tokenizer.decode(inputs["input_ids"][0], skip_special_tokens=True))
new_text = generated_text[input_length:].strip()
print(f"📤 输出: {new_text}")
print(f"📊 生成长度: {len(new_text)} 字符")
return new_text
except Exception as e:
print(f"❌ 推理失败: {e}")
return ""
def test_batch_inference(
model: AutoModelForCausalLM,
tokenizer: AutoTokenizer,
prompts: list,
max_length: int = 50,
device: str = "cpu"
) -> list:
"""
批量推理测试
Args:
model: 模型
tokenizer: 分词器
prompts: 输入文本列表
max_length: 最大生成长度
device: 设备
Returns:
list: 生成的文本列表
"""
print(f"\n🧪 批量推理测试 ({len(prompts)} 个样本):")
try:
# 编码所有输入
inputs = tokenizer(prompts, return_tensors="pt", padding=True)
inputs = {k: v.to(device) for k, v in inputs.items()}
# 生成文本
with torch.no_grad():
outputs = model.generate(
**inputs,
max_length=max_length,
temperature=0.8,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id
)
# 解码所有输出
results = []
for i, output in enumerate(outputs):
generated_text = tokenizer.decode(output, skip_special_tokens=True)
input_length = len(tokenizer.decode(inputs["input_ids"][i], skip_special_tokens=True))
new_text = generated_text[input_length:].strip()
results.append(new_text)
print(f"\n样本 {i+1}:")
print(f" 输入: {prompts[i]}")
print(f" 输出: {new_text}")
return results
except Exception as e:
print(f"❌ 批量推理失败: {e}")
return []
def test_model_capabilities(model: AutoModelForCausalLM, tokenizer: AutoTokenizer, device: str = "cpu"):
"""
测试模型的各种能力
Args:
model: 模型
tokenizer: 分词器
device: 设备
"""
print("\n🎯 模型能力测试:")
test_cases = [
{
"name": "文本补全",
"prompt": "今天天气很好,我想去"
},
{
"name": "问答测试",
"prompt": "问:中国的首都是哪里?\n答:"
},
{
"name": "代码生成",
"prompt": "写一个Python函数计算斐波那契数列:"
},
{
"name": "翻译测试",
"prompt": "Translate to English: 你好,世界!\n"
}
]
for test in test_cases:
print(f"\n📋 {test['name']}:")
test_inference(model, tokenizer, test["prompt"], max_length=50, device=device)
def main():
"""主函数"""
print("=" * 60)
print("🤖 Qwen-2.5-1.5B 模型测试脚本")
print("=" * 60)
# 设置模型路径
model_path = ""
# 检查模型文件
if not os.path.exists(model_path):
print(f"❌ 模型路径不存在: {model_path}")
print("请先下载模型,或修改 model_path 变量")
return 1
if not check_model_files(model_path):
print("⚠️ 模型文件不完整,测试可能失败")
print("建议运行 download_model_enhanced.py 重新下载")
try:
# 加载模型和分词器
device = "auto" # 自动选择设备
model, tokenizer = load_model_and_tokenizer(model_path, device)
# 获取实际设备
actual_device = next(model.parameters()).device
print(f"📍 模型实际运行在: {actual_device}")
# 测试1: 简单推理
print("\n" + "=" * 60)
print("🧪 测试 1: 简单推理")
print("=" * 60)
prompt = "人工智能是"
result = test_inference(
model, tokenizer, prompt,
max_length=50,
temperature=0.8,
device=actual_device
)
# 测试2: 批量推理
print("\n" + "=" * 60)
print("🧪 测试 2: 批量推理")
print("=" * 60)
prompts = [
"机器学习是",
"深度学习用于",
"自然语言处理可以"
]
results = test_batch_inference(
model, tokenizer, prompts,
max_length=30,
device=actual_device
)
# 测试3: 模型能力测试
print("\n" + "=" * 60)
print("🧪 测试 3: 模型能力测试")
print("=" * 60)
test_model_capabilities(model, tokenizer, actual_device)
# 测试4: 内存使用情况
print("\n" + "=" * 60)
print("🧪 测试 4: 内存使用情况")
print("=" * 60)
if torch.cuda.is_available():
memory_allocated = torch.cuda.memory_allocated() / 1024**3
memory_reserved = torch.cuda.memory_reserved() / 1024**3
print(f"💾 GPU 内存使用:")
print(f" 已分配: {memory_allocated:.2f} GB")
print(f" 已保留: {memory_reserved:.2f} GB")
else:
print("💾 CPU 内存使用: 无法获取详细信息")
print("\n" + "=" * 60)
print("✅ 所有测试完成!")
print("=" * 60)
return 0
except Exception as e:
print(f"\n❌ 测试过程中出现错误: {e}")
import traceback
traceback.print_exc()
return 1
if __name__ == "__main__":
sys.exit(main())下面是测试结果。
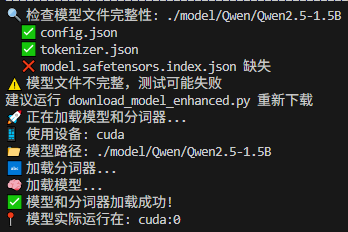
模型运行的基本信息。
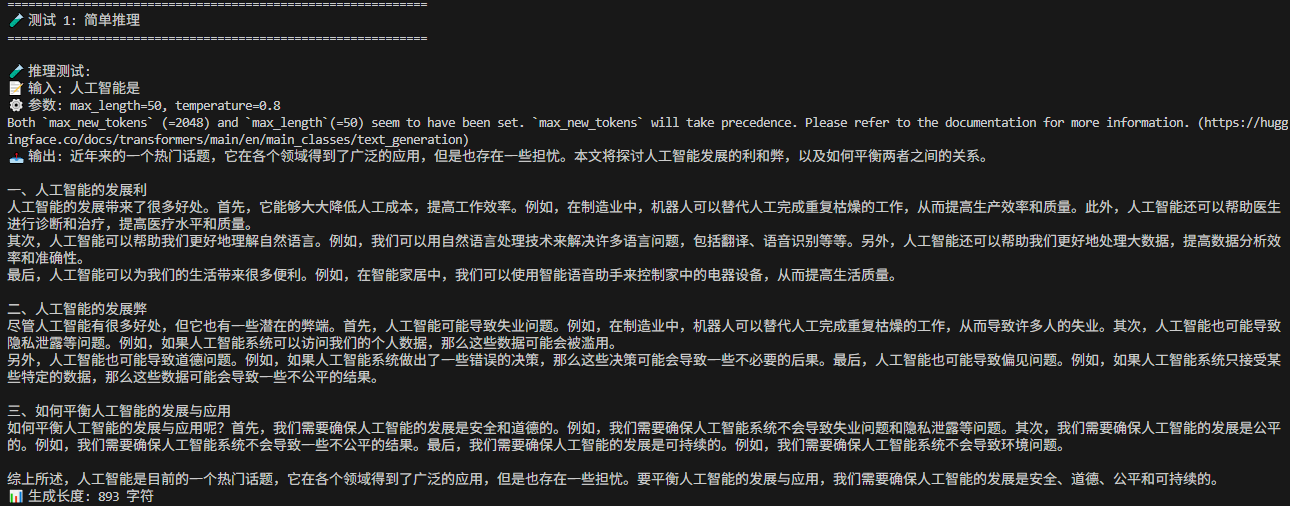
简单推理测试。
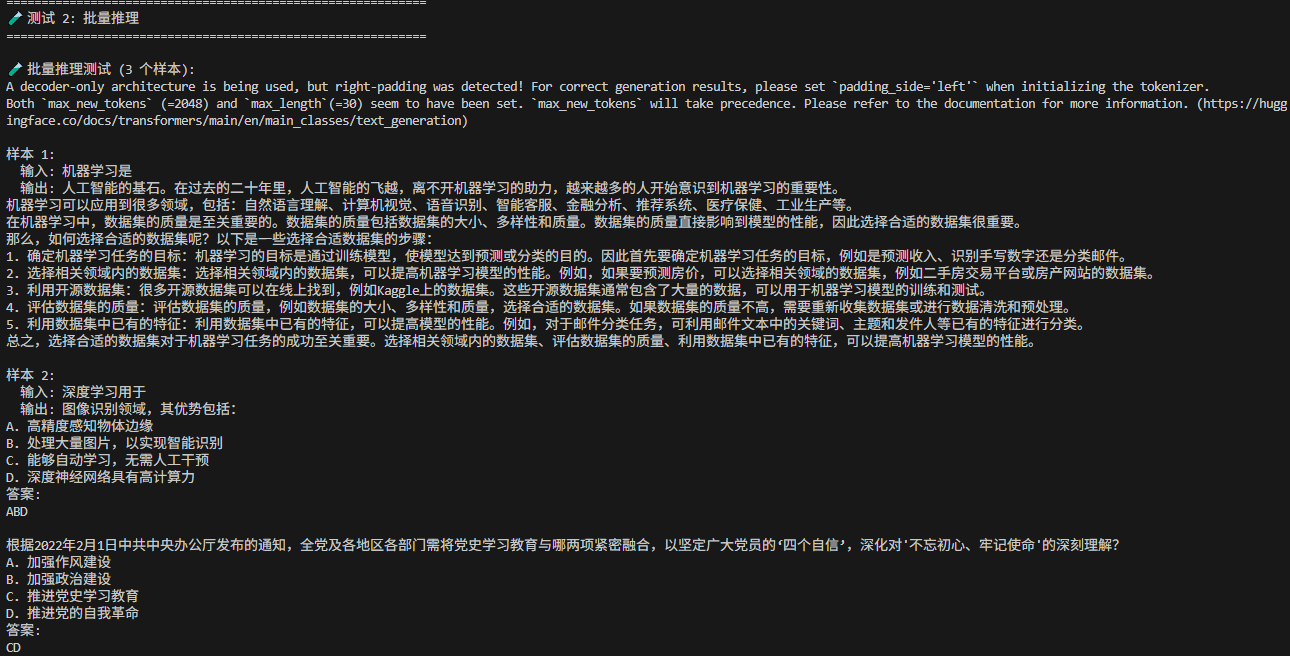
批量推理测试。
模型能力测试。
内存使用情况。
3.预训练数据处理
与之前一样,我们使用出门问问序列猴子开源数据集作为预训练数据集,可以使用和之前一样的方式进行数据集的下载和解压。
python
# 加在预训练数据
ds = load_dataset("json", data_files={"train": data_args.train_files})
logger.info("完成数据集加载")
logger.info(f"训练数据路径: {data_args.train_files}")
logger.info(f'训练文件总数: {len(ds["train"])}')由于这个数据集较大,加载时可能会出现时间较长或内存不够的问题,因此前期测试时可以将预训练数据集拆分一部分进行测试。加载出的ds是一个DatasetDict对象,加载的数据会默认保存在train键对应的值中,可以使用下面的方法查看。
python
ds["train"][0]可以通过feature属性查看数据集的特征(也就是列),这里需要保存一下数据集的列名,因为后续数据处理时,再将文本tokenize之后,需要移除原先的文本。
python
# 文本tokenize
column_names = list(ds["train"].features)
logger.info(f'训练集特征: {column_names}')
text_column_name = "text" if "text" in column_names else column_names[0]接下来使用加载好的tokenizer对数据集进行处理,此处使用map函数来进行批量处理。
python
# tokenize函数
def tokenize_function(examples):
output = tokenizer([item for item in examples[text_column_name]])
return output
# 仅主进程进行数据预处理
with training_args.main_process_first(desc="dataset map tokenization"):
tokenized_datasets = ds.map(
tokenize_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=True,
desc="Running tokenizer on dataset",
)处理完成后的数据集会包括'input_ids','attention_mask'两列,分别是文本tokenize之后的数值序列和注意力掩码(标识是否padding)。map方法会通过remove_columns参数将原先的'text'移除,训练中训练中不再使用。
由于预训练一般为CLM任务,一次性学习多个样本的序列语义不影响模型性能,且训练量大、训练时间长,对训练效率要求比较高。在预训练过程中,一般会把多个文本段拼接在一起,处理成统一长度的文本块,再对每个文本块进行训练。下面我们实现一个拼接函数将文本块拼接到2048个token长度,再通过map方法来进行批量处理:
python
# 文本切块
if data_args.block_size is None:
block_size = tokenizer.model_max_length
if block_size > 1024:
logger.warning(
"tokenizer 支持大于1K的上下文长度,默认设置为1K"
)
block_size = 1024
else:
if data_args.block_size > tokenizer.model_max_length:
logger.warning(
f"设定的块长为({data_args.block_size}), 大于模型的上下文长度"
f"将块长设置为模型上下文长度:{tokenizer.model_max_length}."
)
block_size = min(data_args.block_size, tokenizer.model_max_length)
def group_texts(examples):
# 将文本段拼接起来
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
# 计算拼起来的整体长度
total_length = len(concatenated_examples[list(examples.keys())[0]])
# 如果长度太长,进行分块
if total_length >= block_size:
total_length = (total_length // block_size) * block_size
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
result["labels"] = result["input_ids"].copy()
return result
with training_args.main_process_first(desc="文本分块"):
lm_datasets = tokenized_datasets.map(
group_texts,
batched=True,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=True,
desc=f"文本分块到{block_size}",
batch_size = 40000,
)
logger.info("完成数据预处理")
train_dataset = lm_datasets["train"]处理得到的train_dataset就是一个可直接用于CLM Pretrain的预训练数据集了,其每个样本长度为1024个token。
4.使用 Trainer 进行训练
接下来,我们使用transformers提供的Trainer类进行训练。Trainer封装了模型的训练逻辑,且做了较好的效率优化、可视化等工作,可以高效、便捷地完成LLM地训练。
首先,我们需要配置训练地超参数,使用TrainingArguments类来实例化一个参数对象:
python
from transformers import TrainingArguments
# 配置训练参数
training_args = TrainingArguments(
output_dir="output",# 训练参数输出路径
per_device_train_batch_size=4,# 训练的 batch_size
gradient_accumulation_steps=1,# 梯度累计步数,实际 bs = 设置的 bs * 累计步数
logging_steps=500,# 打印 loss 的步数间隔
num_train_epochs=1,# 训练的 epoch 数
save_steps=500, # 保存模型参数的步数间隔
learning_rate=5e-5,# 学习率
gradient_checkpointing=True# 开启梯度检查点
)然后基于初始化的model、tokenizer和training_args,并传入处理好的训练数据集,实例化一个trainer对象:
python
logger.info("初始化Trainer")
trainer = Trainer(
model=model,
args=training_args,
train_dataset = train_dataset,
tokenizer=tokenizer,
data_collator=default_data_collator,
)再使用train方法,即会按照配置好的训练超参进行训练和保存:
5.使用 DeepSpeed 实现分布式训练
由于预训练规模大、时间长,一般需要使用多卡进行分布式训练,否则训练时间会太长。下面我们介绍如何基于上述代码,使用DeepSpeed框架实现分布式训练,从而完成业界可用的LLM Pretrain。
长时间训练时一般会使用bash脚本设定超参数,然后再启动写好的python脚本实现训练。下面是具体的训练代码。
首先导入需要的库:
python
import logging
import math
import os
import sys
from dataclasses import dataclass, field
# from torchdata.datapipes.iter import IterableWrapper
from itertools import chain
import deepspeed
from typing import Optional,List
import datasets
import pandas as pd
import torch
from datasets import load_dataset
import transformers
from transformers import (
AutoConfig,
AutoModelForCausalLM,
AutoTokenizer,
HfArgumentParser,
Trainer,
TrainingArguments,
default_data_collator,
set_seed,
)
import datetime
from transformers.testing_utils import CaptureLogger
from transformers.trainer_utils import get_last_checkpoint
import swanlab首先需要定义几个超参的类型,用于处理sh脚本中设定的超参值。由于transformers本身有TraingingArguments类,其中就包括了训练的一些必备超参数。所以我们只需定义TrainingArguments中未包含的超参即可,主要包括模型相关的超参(定义在ModelArguments)和数据相关的超参(定义在DataTrainingArguments):
python
@dataclass
class ModelArguments:
"""
关于模型的参数
"""
model_name_or_path: Optional[str] = field(
default = None,
metadata = {
"help": (
"后训练使用,为预训练模型参数地址"
)
},
)
config_name: Optional[str] = field(
default = None, metadata = {"help": "预训练使用,Config文件地址"}
)
tokenizer_name: Optional[str] = field(
default = None, metadata = {"help": "预训练Tokenizer地址"}
)
torch_dtype: Optional[str] = field(
default = None,
metadata = {
"help": (
"模型训练使用的数据类型,推荐bfloat16"
),
"choices": ["auto", "bfloat16", "float16", "float32"],
},
)
@dataclass
class DataTrainingArguments:
"""
关于训练的参数
"""
train_files: Optional[List[str]] = field(default=None,metadata={"help": "训练数据路径"})
block_size: Optional[int] = field(
default=None,
metadata={
"help":(
"设置的文本块长度"
)
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help":"预处理使用线程数"},
)然后即可定义一个主函数实现上述训练过程的封装。首先通过transformers提供的HfArgumentParser工具来加载sh脚本中设定的超参:
python
# 加载脚本参数
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()在大规模的训练中,一般使用log来保存训练过程的信息,一般不推荐使用print直接打印,容易发生关键训练信息的丢失。在这里,我们直接使用python自带的logging库来实现日志记录。首先需要进行log的设置:
python
# 设置日志
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
# 将日志级别设置为INFO
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()这里我们将日志的级别设置为INFO。logging的日志共有DEBUG、INFO、WARNING、ERROR以及CRITICAL五个级别,将日志设置为哪个级别就只会输出该级别及该级别之上的信息。设置完成后,在需要记录日志的地方,直接使用logger即可,记录时会指定记录日志的级别,例如:
python
# 训练整体情况记录
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")在大规模训练中,发生中断是往往难以避免的,训练一般会固定间隔保存checkpoint,中断之后基于最近的checkpoint恢复训练即可。因此,我们需要首先检测是否存在旧的checkpoint并从checkpoint恢复训练:
python
# 检查checkpoint
last_checkpoint = None
if os.path.isdir(training_args.output_dir):
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"输出路径 ({training_args.output_dir}) 非空"
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"从{last_checkpoint}恢复训练"
)接着通过上文介绍过的方式初始化模型,此处将从零初始化和基于已有预训练模型初始化包装在一起:
python
# 初始化模型
if model_args.config_name is not None:
# from scrach
config = AutoConfig.from_pretrained(model_args.config_name)
logger.warning("你正在从零初始化一个模型")
logger.info(f"模型参数配置地址:{model_args.config_name}")
logger.info(f"模型参数:{config}")
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
logger.info(f"预训练一个新模型 - Total size={n_params/2**20:.2f}M params")
elif model_args.model_name_or_path is not None:
logger.warning("你正在初始化一个预训练模型")
logger.info(f"模型参数地址:{model_args.model_name_or_path}")
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
logger.info(f"继承一个预训练模型 - Total size={n_params/2**20:.2f}M params")
else:
logger.error("config_name 和 model_name_or_path 不能同时为空")
raise ValueError("config_name 和 model_name_or_path 不能同时为空")再类似的进行tokenizer的加载和预训练数据的处理。
类似的,使用Trainer进行训练:
python
logger.info("初始化Trainer")
trainer = Trainer(
model=model,
args=training_args,
train_dataset = train_dataset,
tokenizer=tokenizer,
data_collator=default_data_collator,
)
# 从checkpoint加载
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
logger.info("开始训练")
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # 保存模型注意,由于上文检测了是否存在checkpoint,此处使用resume_from_checkpoint来实现从checkpoint恢复训练的功能。
由于在大规模训练中监测训练进度、loss下降趋势尤为重要,在脚本中,我们使用了swanlab作为训练检测的工具。在脚本开始进行了swanlab的初始化:
python
# 初始化 SwanLab
swanlab.init(project="pretrain", experiment_name="from_scrach")在启动训练后,即可在swanlab网站上观察训练进度。
完成上述这些代码之后,我们就可以使用sh脚本来定义超参数的值,并通过DeepSpeed启动训练,从而实现多卡分布式训练:
bash
#!/bin/bash
CUDA_VISIBLE_DEVICES=2,5
deepspeed pretrain.py \
--config_name ./model/Qwen/Qwen2.5-1.5B \
--tokenizer_name ./model/Qwen/Qwen2.5-1.5B \
--train_files ./dataset/mobvoi_seq_monkey_general_open_corpus.jsonl.tar.bz2 \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 16 \
--do_train \
--output_dir ./output_optimized \
--eval_strategy no \
--learning_rate 1e-4 \
--num_train_epochs 1 \
--warmup_steps 200 \
--logging_dir ./output_optimized/pretrain/logs \
--logging_strategy steps \
--logging_steps 5 \
--save_strategy steps \
--save_steps 500 \
--preprocessing_num_workers 10 \
--save_total_limit 1 \
--seed 12 \
--block_size 1024 \
--bf16 \
--gradient_checkpointing \
--deepspeed ./ds_config_zero3_offload.json \
--report_to swanlab \
--dataloader_num_workers 4 \
--remove_unused_columns false \
--group_by_length \
--length_column_name length在安装了DeepSpeed第三方库后,可以直接通过Deepspeed命令来启动多卡训练。上面的脚本主要是定义了各种超参数的值,可以参考使用。在这里我们使用ZeRO-3进行训练,并且加载了pretrain_optimized_fixed.sh作为DeepSpeed的配置参数:
bash
{
"fp16": {
"enabled": false
},
"bf16": {
"enabled": true
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 100,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false,
"memory_breakdown": false
}二、模型有监督微调
上面一节我们介绍了如何使用Transformers框架快速、高效地进行模型预训练。下面我们将介绍如何使用Transformers框架对预训练好地模型进行有监督微调。
1.Pretrain VS SFT
首先需要回顾一下LLM进行预训练和进行有监督微调的核心差异是什么。目前成熟的LLM一般通过Pretrain-SFT-RLHF三个阶段来训练,在Pretrain阶段,会对海量无监督文本进行自监督建模,来学习文本语义规则和文本中的世界知识;在SFT阶段,一般通过对Pretrain好的模型进行指令微调,即训练模型根据用户指令完成对应任务,从而使模型能够遵循用户指令,根据用户指令进行规划、行动和输出。因此,Pretrain和SFT均使用CLM建模,其核心差异在于,Pretrain使用海量无监督文本进行训练,模型直接对文本执行"预测下一个token"的任务;而SFT使用构建成对的指令对数据,模型根据输入的指令,建模后续的输出。反映到具体的训练实现上,Pretrain会对全部text进行loss计算,要求模型对整个文本实现建模预测;而SFT仅对输出进行loss计算,不计算指令部分的loss。
因此,相较于Pretrain代码,SFT部分仅需要修改数据处理环节,实现对指令对数据转化为训练样本的构建,其余部分和Pretrain是完全一致的实现逻辑。
2.微调数据处理
我们使用贝壳开源的BelleGroup数据集进行SFT。
在SFT过程中,我们会定义一个Chat Template, 这个Template即表示了如何将对话数据转化为一个模型可以建模拟合的文本序列。当我们使用做过SFT的模型进行下游任务微调时,一般需要查看该模型的Chat Template并进行适配,这是为了不损伤其在SFT中学到的指令遵循能力。由于我们此处使用Pretrain模型进行SFT,可以自定义一个Chat Template。由于我们使用了Qwen-2.5-1.5B模型结构进行Pretrain,此处我们沿承使用Qwen-2.5的Chat Template。
我们首先定义几个特殊的token,特殊token在模型进行拟合中有特殊的作用,包括文本序列开始(BOS)、文本序列结束(EOS)、换行符等。定义特殊token,有助于避免模型在拟合过程中的语义混淆:
python
# 不同的tokenizer需要特别定义
# BOS
im_start = tokenizer("<|im_start|>").input_ids
# EOS
im_end = tokenizer("<|im_end|>").input_ids
# PAD
IGNORE_TOKEN_ID = tokenizer.pad_token_id
#换行符
n1_tokens = tokenizer('\n').input_ids
# 角色标识符
_system = tokenizer('system').input_ids + n1_tokens
_user = tokenizer('human').input_ids + n1_tokens
_assistant = tokenizer('assistant').input_ids + n1_tokensQwen系列的Chat Template一般有三个对话角色:System、User和Assistant。System是系统提示词,负责激活模型的能力,默认为"You are a helpful assistant.",一般不会在SFT过程中更改使用。User即为用户给出的提示词,此处由于数据集中的对话角色为"human",我们将"user"修改为了"human"。Assistant即为LLM给出的回复,也就是模型在SFT过程中需要拟合的文本。
接着,由于该数据集是一个多轮对话数据集,我们需要对多轮对话进行拼接处理,将多轮对话拼接到一个文本序列中:
python
# 拼接多轮对话
input_ids, targets = [], []
for i in tqdm(range(len(sources))):
source = sources[i]
# 从user开始
if source[0]['from'] != 'human':
source = source[1:]
# 分别是输入和输出
input_id, target = [], []
# system: [BOS]system\nYou are a helpful assistant.[Eos]\n
system = im_start + _system + tokenizer(system_message).input_ids + im_end + n1_tokens
input_id += system
# system 不需要拟合
target += im_start + [IGNORE_TOKEN_ID] * (len(system) - 3) + im_end + n1_tokens
assert len(input_id) == len(target)
#依次拼接
for j, sentence in enumerate(source):
role = roles[sentence["from"]]
# user: <|im_start|>human\ninstruction[EOS]\n
# assistant: <|im_start|>assistant\nresponse[EOS]\n
_input_id = tokenizer(role).input_ids + n1_tokens + \
tokenizer(sentence["value"]).input_ids + im_end + n1_tokens
input_id += _input_id
if role == '<|im_start|>human':
# user 不需要拟合
_target = im_start + [IGNORE_TOKEN_ID] * (len(_input_id) - 3) + im_end + n1_tokens
elif role == '<|im_start|>assistant':
# assistant 需要拟合
_target = im_start + [IGNORE_TOKEN_ID] * len(tokenizer(role).input_ids) + \
_input_id[len(tokenizer(role).input_ids)+1:-2] + im_end + n1_tokens
else:
print(role)
raise NotImplementedError
target += _target
assert len(input_id) == len(target)
# 最后进行PAD
input_id += [tokenizer.pad_token_id] * (max_len - len(input_id))
target += [IGNORE_TOKEN_ID] * (max_len - len(target))
input_ids.append(input_id[:max_len])
targets.append(target[:max_len])上述代码继承了Qwen的Chat Template逻辑,核心是在于User的文本不需要拟合,因此targets中User对应的文本内容是使用的IGNORE_TOKEN_ID进行遮蔽,而Assistant对应的文本内容则是文本原文,是需要计算loss的。目前主流LLM的IGNORE_TOKEN_ID一般设置为-100。
完成拼接后,将tokenize后的数值序列转化为Torch.tensor,再拼接成Dataset所需的字典返回即可:
python
input_ids = torch.tensor(input_ids)
targets = torch.tensor(targets)
return dict(
input_ids = input_ids,
labels = targets,
attention_mask = input_ids.ne(tokenizer.pad_token_id),
)完成上述处理逻辑后,需要自定义一个Dataset类,在该类中调用该逻辑进行数据的处理:
python
class SupervisedDataset(Dataset):
def __init__(self, raw_data, tokenizer, max_len: int):
super(SupervisedDataset, self).__init__()
# 加载并预处理数据
sources = [example["conversations"] for example in raw_data]
data_dict = preprocess(sources, tokenizer, max_len)
self.input_ids = data_dict["input_ids"]
self.labels = data_dict["labels"]
self.attention_mask = data_dict["attention_mask"]
def __len__(self):
return len(self.input_ids)
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
return dict(
input_ids = self.input_ids[i],
labels = self.labels[i],
attention_mask = self.attention_mask[i],
)这个类继承自Torch的Dataset类,可以直接在Trainer中使用。完成数据处理后,基于之前的脚本,修改数据处理逻辑即可,后续训练几乎完全一致。下面是主函数的逻辑:
python
def main():
# 加载脚本参数
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# 初始化Swanlab
swanlab.init(project="sft", experiment_name="qwen-1.5b-finetune")
# 设置日志
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers = [logging.StreamHandler(sys.stdout)],
)
# 将日志级别设置为INFO
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
#训练整体情况记录
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# 检查checkpoint
last_checkpoint = None
if os.path.isdir(training_args.output_dir):
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"输出路径({training_args.output_dir}) 非空"
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"从{last_checkpoint}恢复训练"
)
# 设置随机数种子
set_seed(training_args.seed)
# 初始化模型
logger.warning("加载预训练模型")
logger.info(f"模型参数地址:{model_args.model_name_or_path}")
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
n_params = sum({p.data_ptr(): p.numel() for p in model.parameters()}.values())
logger.info(f"继承一个预训练模型 - Total size={n_params/2**20:.2f}M params")
# 初始化Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path)
logger.info("完成tokenizer加载")
# 加载微调数据
with open(data_args.train_files) as f:
lst = [json.loads(line) for line in f.readlines()[:10000]]
logger.info("完成训练集加载")
logger.info(f"训练集地址: {data_args.train_files}")
logger.info(f'训练样本总数:{len(lst)}')
train_dataset = SupervisedDataset(lst, tokenizer=tokenizer, max_len=2048)
logger.info("初始化Trainer")
trainer = Trainer(
model=model,
args=training_args,
train_dataset = train_dataset,
tokenizer = tokenizer
)
# 从checkpoint加载
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
logger.info("开始训练")
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()之后,通过sh脚本使用Deepspeed启动。
三、高效微调
在前面的章节中,我们详细介绍了基于Transformers框架对模型进行Pretrain、SFT以及RLHF的原理和实践细节。但是由于LLM参数量大,训练数据多,通过上述方式对模型进行训练(主要指SFT及RLHF)需要调整模型全部参数,资源压力非常大。
1.高效微调方案
针对全量微调的昂贵问题,目前主要有两种解决方案:
Adapt Tuning。即在模型中添加Adapter层,在微调时冻结原参数,仅更新Adapter层。
具体而言,其在预训练模型每层中插入用于下游任务的参数,即Adapter模块,在微调时冻结模型主体,仅训练特定于任务的参数,如下图所示。
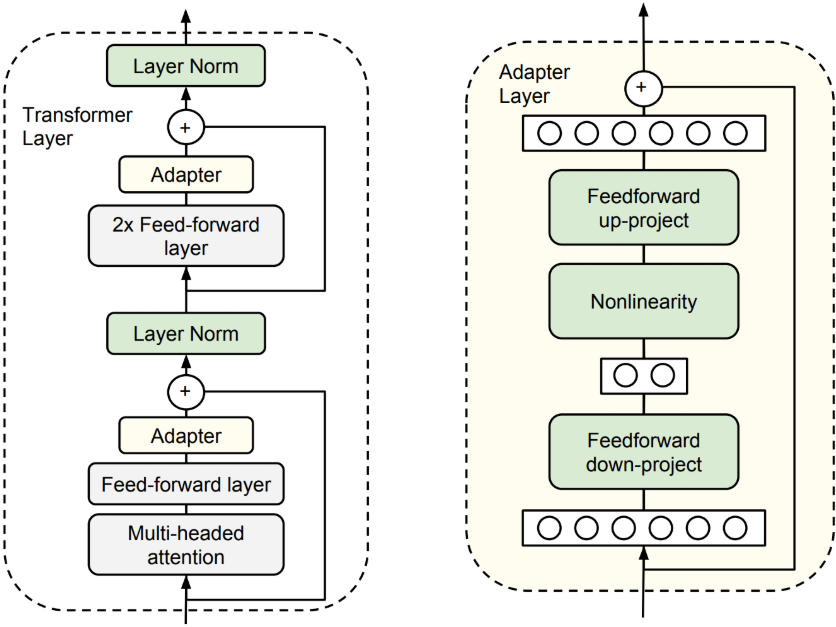
每个Adapter模块由两个前馈子层组成,第一个前馈子层将Transformer块的输出作为输入,将原始输入维度d投影到m,通过控制m的大小来限制Adapter模块的参数量,通常情况下m<<d。在输出阶段,通过第二个前馈子层还原输入维度,将m重新投影到d,作为Adapter模块的输出。
LoRA事实上就是一种改进的Adapt Tuning方法。但Adapt Tuning方法存在推理延迟问题,由于增加了额外参数和额外计算量,导致微调后的模型计算速度相较原预训练模型更慢。
Prefix Tuning。该种方法固定预训练LM,为LM添加可训练,任务特定的前缀,这样就可以为不同任务保存不同的前缀,微调成本也小。具体而言,在每一个输入token前构造一段与下游任务相关的virtual tokens作为prefix,在微调时只更新prefix部分的参数,而其他参数冻结不变。
目前常用的微量微调方法的Ptuning,其实就是Prefix Tuning的一种改进。但Prefix Tuning也存在固定的缺陷:模型可用序列长度减少。由于加入了virtual tokens,占用了可用序列长度,因此越高的微调质量,模型可用序列长度就越低。
2.LoRA 微调
如果一个大模型是将数据映射到高维空间进行处理,这里假定在处理一个细分的小任务时,是不需要那么复杂的大模型的,可能只需要在某个子空间范围内就可以解决,那么也就不需要对全量参数进行优化了,我们可以定义当某个子空间参数进行优化时,能够达到全量参数优化性能的一定水平(如90%精度)时,那么这个子空间参数矩阵的秩就可以称为对应当前待解决问题的本征秩。
预训练模型本身就隐式地降低了本征秩,当针对特定任务进行微调后,模型中权重矩阵其实具有更低的本征秩。同时,越简单的下游任务,对应的本征秩越低。因此,权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。我们可以通过优化密集层在适应过程中变化的秩分解矩阵来间接训练神经网络中的一些密集层,从而实现仅优化密集层的秩分解矩阵来达到微调效果。
例如,假设预训练参数为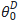 ,在特定下游任务上密集层权重参数矩阵对应的本征秩为
,在特定下游任务上密集层权重参数矩阵对应的本征秩为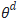 ,对应特定下游任务微调参数为
,对应特定下游任务微调参数为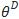 ,那么有:
,那么有:
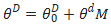
这个M即为LoRA优化的秩分解矩阵。
相对于其他高效微调方法,LoRA存在以下优势:
1.可以针对不同的下游任务构建小型LoRA模块,从而在共享预训练模型参数基础上有效地切换下游任务。
2.LoRA使用自适应优化器(Adaptive Optimizer),不需要计算梯度或维护大多数参数的优化器状态,训练更有效、硬件门槛更低。
3.LoRA使用简单的线性设计,在部署时将可训练矩阵与冻结权重合并,不存在推理延迟。
4.LoRA与其他方法正交,可以组合。
因此,LoRA成为目前高效微调LLM的主流方法,尤其是对于资源受限、有监督训练数据受限的情况下,LoRA微调往往会成为LLM微调的首选方法。
3.LoRA 微调的原理
3.1 低秩参数化更新矩阵
LoRA假设权重更新的过程中也有一个较低的本征秩,对于预训练的权重参数矩阵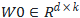 (d为上一层输出维度,k为下一层输入维度),使用低秩分解来表示其更新:
(d为上一层输出维度,k为下一层输入维度),使用低秩分解来表示其更新:
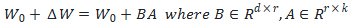
在训练过程中,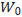 冻结不更新,A、B包含可训练参数。
冻结不更新,A、B包含可训练参数。
因此,LoRA的前向传递函数为:
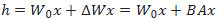
在开始训练时,对A使用随机高斯初始化,对B使用零初始化,然后使用Adam进行优化。训练思路如下图所示:

3.2 应用于Transformer
在Transformer结构中,LoRA技术主要应用在注意力模块的四个权重矩阵:、
、
、
,而冻结MLP的权重矩阵。通过消融实验发现同时调整
和
会产生最佳结果。
在上述条件下,可训练参数个数为:

其中,为应用LoRA的权重矩阵的个数,
为Transformer的输入输出维度,
为设定的LoRA秩。
一般情况下,r取到4、8、16。
4. LoRA 的代码实现
目前一般通过peft库来实现模型的LoRA微调。peft库是huggingface开发的第三方库,其中封装了包括LoRA、Adapt Tuning、P-tuning等多种高效微调方法,可以基于此便捷地实现模型地LoRA微调。
下面简单解析peft库中地LoRA微调代码。
4.1 实现流程
LoRA微调的内部实现流程主要包括以下几个步骤:
1.确定要使用LoRA的层。peft库目前支持调用LoRA的层包括:nn.Linear、nn.Embedding、nn.Conv2d三种。
2.对每一个要使用LoRA的层,替换为LoRA层。所谓LoRA层,实则是在该层原结果基础上增加了一个旁路,通过低秩分解(即矩阵A和矩阵B)来模拟参数更新。
3.冻结原参数,进行微调,更新LoRA层参数。
4.2 确定 LoRA 层
在进行LoRA微调时,首先需要确定LoRA微调参数,其中一个重要参数即是target_modules。target_modules一般是一个字符串列表,每一个字符串是需要进行LoRA的层名称,例如:
target_modules = ["q_proj","v_proj"]这里的q_proj即为注意力机制中的,v_proj即为注意力机制中的
。我们可以根据模型架构和任务要求自定义需要进行LoRA操作的层。
在创建LoRA模型时,会获取该参数,然后再原模型中找到对应的层,该操作主要通过re对层名进行正则匹配实现:
# 找到模型的各个组件中,名字里带"q_proj","v_proj"的
target_module_found = re.fullmatch(self.peft_config.target_modules, key)
# 这里的 key,是模型的组件名4.3 替换 LoRA 层
对于找到的每一个目标层,会创建一个新的LoRA层进行替换。
LoRA层在具体实现上,是定义了一个基于LoRA基类的Linear类,该类同时继承了nn.Linear和LoraLayer。LoraLayer即是Lora基类,其主要构造了LoRA的各种超参:
python
class LoraLayer:
def __init__(
self,
r: int, # LoRA 的秩
lora_alpha: int, # 归一化参数
lora_dropout: float, # LoRA 层的 dropout 比例
merge_weights: bool, # eval 模式中,是否将 LoRA 矩阵的值加到原权重矩阵上
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
self.disable_adapters = Falsenn.Linear就是Pytorch的线性层实现。Linear类就是具体的LoRA层,主要实现方法如下:
python
class Linear(nn.Linear, LoraLayer):
# LoRA 层
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs,
):
# 继承两个基类的构造函数
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
# 参数矩阵 A
self.lora_A = nn.Linear(in_features, r, bias=False)
# 参数矩阵 B
self.lora_B = nn.Linear(r, out_features, bias=False)
# 归一化系数
self.scaling = self.lora_alpha / self.r
# 冻结原参数,仅更新 A 和 B
self.weight.requires_grad = False
# 初始化 A 和 B
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.T替换时,直接将原层的weight和bias复制给新的LoRA层,再将新的LoRA层分配到指定设备即可。
4.4 训练
实现了LoRA层的替换后,进行微调训练即可。由于在LoRA层中已冻结原参数,在训练中只有A和B的参数会被更新,从而实现了高效微调。训练的整体过程与原Fine-tune类似。由于采用了LoRA方式,forward函数也会对应调整:
python
def forward(self, x: torch.Tensor):
if self.disable_adapters:
if self.r > 0 and self.merged:
self.weight.data -= (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = False
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
'''主要分支'''
elif self.r > 0 and not self.merged:
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
if self.r > 0:
result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
return result
else:
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)上述代码由于考虑到参数合并问题,有几个分支,这里我们主要阅读第二个分支即可。基于LoRA的前向计算过程如前文公式所示,首先计算原参数与输入的乘积,再加上A、B分别与输入的乘积即可。
5. 使用 peft 实现 LoRA 微调
peft进行了很好的封装,支持我们便捷、高效地对大模型进行微调。此处以LLM SFT为例,简要介绍如何使用peft对大模型进行微调。如果是应用在RLHF上,整体思路是一致的。
首先加载所需的库:
python
import torch.nn as nn
from transformers import AutoTokenizer, AutoModel
from peft import get_peft_model, LoraConfig, TaskType, PeftModel
from transformers import Trainer其次加载原模型与原tokenizer,此处和之前一致:
python
# 加载基座模型
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, trust_remote_code=True)
model = AutoModel.from_pretrained(
MODEL_PATH, trust_remote_code=True
)接着,设定peft参数:
python
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)注意,对不同的模型,LoRA参数可能有所区别。例如,对于ChatGLM,无需指定target_modeules,peft可以自行找到;对于BaiChuan,就需要手动指定。task_type是模型的任务类型,大模型一般都是CAUSAL_LM即传统语言模型。
然后获取LoRA模型:
python
model = get_peft_model(model, peft_config)此处的get_peft_model的底层操作,即为上文分析的具体实现。
最后使用trnsformers提供的Trainer进行训练即可,训练占用的显存就会有大幅度的降低:
python
trainer = Trainer(
model=model,
args=training_args,
train_dataset= IterableWrapper(train_dataset),
tokenizer=tokenizer
)
trainer.train()如果是应用在DPO、KTO上,则也相同的加入LoRA参数并通过get_peft_model获取一个LoRA模型即可,其他的不需要进行任何修改。但要注意的是,LoRA微调能够大幅度降低显卡占用,且在下游任务适配上能够取得较好的效果,但如果是需要学习对应知识的任务,LoRA由于只调整低秩矩阵,难以实现知识的注入,一般效果不佳,因此不推荐使用LoRA进行模型预训练或后训练。
四、通过强化学习进行偏好对齐
强化学习(Reinforcement Learning,简称RL)其实并不是什么新鲜事物。它的理论基础可以追溯到20世纪初的行为心理学。Edward Thorndike提出了"效果律",即如果一个行为带来积极的结果,那么这种行为重复发生的概率会增加。B.F.Skinner则进一步发展了这种思想,提出操作性条件作用学说,通过奖励和惩罚来塑造行为。
计算机科学领域的强化学习是从这些心理学原理生发出来的。在20世纪80年代,随着计算能力的提升和数学理论的发展,人们开始尝试将这些生物心理学的学习概念应用于机器和计算机程序,从而发展出了现代意义上的强化学习。
1.强化学习的基本原理
下面我们开始讲解核心部分-强化学习的基本原理。
状态(State):这是一个系统在某一时刻的具体状况。比如在一个棋盘游戏中,状态可以表示棋盘上所有棋子的当前排列情况。而对于自动驾驶汽车来说,状态可能包括汽车的速度、位置,以及周围障碍物的位置等。
动作(Action):动作是智能体在给定状态下可执行的操作。以自行车为例,动作可能包括前进、停止、转弯等。在复杂的系统中,动作集可以非常庞大。
奖励(Reward):这是智能体在执行某个动作后获得的反馈,通常是一个数值。奖励可以是立即的,也可以是延后的。一个好的动作可能会得到正奖励,而不好的动作可能会得到负奖励。
策略(Policy):策略是一套指导智能体如何选择动作的规则。简单来说,策略就是告诉智能体在每个状态下应该做什么。
价值函数(Value Function):这是一种对策略的评估工具,旨在预测从当前状态出发,长期来看能够获得的总奖励。值函数帮助智能体不仅考虑当前步骤的奖励,而且能够更好地权衡短期和长期收益。
模型(Model):在有些强化学习系统中,我们会建立一个环境模型,帮助智能体预见其动作的结果。这在很多复杂计算情况下非常有用。
通过上述元素的共同作用,帮助智能体通过不断地在虚拟环境中试错来学习最佳的行动策略。在强化学习中,智能体是学习和决策的主体。它通过以下步骤与环境进行交互:
观察状态:智能体首先观察当前的状态(State)
选择动作:根据观察到的状态和预先确定的策略,智能体选择一个动作(Action)
执行动作:智能体执行所选的动作。
接收奖励和新状态:执行动作后,智能体从环境中接收到相应的奖励(Reward)和更新后的新状态(State)
更新策略:智能体使用获得的奖励信息来调整策略,以便在未来获得更好的结果。
将这个过程不断重复,智能体在反复的交互中不断优化其策略,目标是让它在给定的任务中表现越来越好。
2.强化学习的目标
强化学习的目标十分明确:通过在给定环境中反复试探和学习,使得智能体能够选择一系列动作从而最大化其总累计奖励。我们可以用游戏来比喻。在游戏中,玩家的目标是通过一系列操作(比如走路、跳跃、打怪)来赢得高分数或完成关卡。在强化学习中,这种高分或成功通过关卡的概念对应于"最大化奖励"。
在数学上,这个目标可以表示为训练一个策略,使得在所有状态s下,智能体选择的动作能够使得回报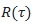 的期望值最大化。具体来说,我们希望最大化以下期望值:
的期望值最大化。具体来说,我们希望最大化以下期望值:
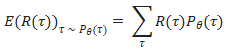
其中:
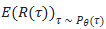 :表示在策略
:表示在策略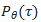 下轨迹
下轨迹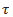 的回报的期望值。
的回报的期望值。
:轨迹的回报,即从起始状态到终止状态获得的所有奖励总和。
:表示一条轨迹,即智能体在环境中的状态和动作序列。
:在参数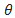 下生成轨迹的概率,通常由策略或策略网络确定。
下生成轨迹的概率,通常由策略或策略网络确定。
:策略的参数,控制着策略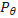 的行为。
的行为。
为了找到这个策略,我们使用梯度上升的方法,不断更新策略参数,使得不断增大。
这种学习方式非常有效,因为它不依赖于大量的标注数据,而是通过对环境直接进行交互和反馈进行学习。这使得强化学习在许多需要适应和决策的负责任务中,比如机器人控制、自动驾驶、金融交易乃至游戏中,都展现出巨大的潜力。
强化学习也可以用于偏好对齐问题,比如可以让大模型学习模仿人类的交流方式,也会用于自动驾驶等领域。强化学习的应用领域非常广泛,未来也会有更多的应用场景。
3.奖励模型
在自然语言处理领域,大语言模型(如Llama系列、Qwen系列等)已经展现了强大的文本理解和生成能力。然而,这些预训练模型并不总是能直接满足特定的业务需求和人类价值观。为此,人们通常需要对预训练模型进行"指令微调"(Instruction Tuning),即向模型提供特定的指令(prompts)和示例,使其在对话、问答、文本生成等任务中表现得更符合人类期望。
在完成初步的指令微调后,我们还想要使模型的回答不仅正确,还能最大程度上满足人类的审美、价值观和安全标准。为此,引入了强化学习与人类反馈(Reinforcement Learning from Human Feedback, RLHF)的概念。在RLHF中,我们会先从人类标注者那里获得对模型回答的偏好(例如,给出多个模型回答,让人类标注者对它们进行排名),然后通过这些反馈来指导模型学习,从而不断提高模型生成内容与偏好的契合度。
为了在RLHF流程中自动对模型的回答进行"打分"(赋予奖励),我们需要构建一个专门的奖励模型(Reward Model)。这个奖励模型会根据人类标注的数据进行训练,并在实际部署中独立对模型输出进行自动评分,从而减少持续人工参与的成本和延迟。
4.数据集构建
在构建奖励奖励模型(Reward Model)之前,我们首先需要准备高质量的人类反馈数据集。这个数据集的核心目标是为每条给定的提示(prompt)提供多个候选回答(completion),并由人类标注者对这些回答进行细致的评定与排序。通过对回答的对比和筛选,我们得以为机器模型提供明确的参考标准,帮助其进一步学习在给定任务下如何生成更符合人类期望的输出。
可以按照以下步骤进行数据收集:
1.收集初始回答:首先,我们需要从一个已经过基本微调的"大模型"(往往是具有一定指令理解和生成能力的预训练模型)中,为一组精心设计的提示生成多条回答。这些回答将作为后续人类标注工作的基础。
2.人工标注与评估:拥有多条候选回答后,我们邀请专业标注人员或众包标注者对每条回答的质量进行评价。这些评估通常会基于一系列预先设计的评价标准,如回答的准确性、完整性、上下文相关性、语言流畅度以及是否遵循道德与安全准则。对不同回答的比较与排序帮助我们识别最佳和最差的回答,从而形成有价值的训练数据。
3.数据格式化与整理:标注完成后,我们将数据进行整理与格式化,通常采用JSON、CSV或其他便于计算机处理的结构化数据格式。数据集中需明确标识每个问题(prompt)、其对应的多个回答(completions),以及人类标注者对这些回答的选择(如标记为"chosen"的最佳答案与"rejected"的较差答案)。这些标记信息可直接作为奖励模型学习的监督信号,使其在训练中自动倾向于生成高质量回答。
下面是一个简单的数据示例,其中展示了两个问题(question)及其对应的回答和人类评价结果。通过"chosen"与"rejected"字段的对比,我们可以直观地看出哪条回答更为优质。
bash
[
{
"question": "Python中的列表是什么?",
"chosen": "Python中的列表是一种有序的可变容器,允许存储多个元素,并且可以通过索引访问。",
"rejected": "Python中的列表用于存储数据。"
},
{
"question": "Python中的元组是什么?",
"chosen": "Python中的元组是一种有序的不可变容器,允许存储多个元素,并且一旦创建就不能修改。",
"rejected": "Python中的元组用于存储数据。"
}
]在上述示例中,人类标注者认为"chosen"字段下的回答相对于对应的"rejected"回答在描述、准确性和信息量等方面都更为优质。例如,对于列表的定义,"chosen"答复更清晰地解释了列表的特征(有序、可变、支持索引访问),而非仅仅停留在"用于存储数据"这种笼统描述。