在日常数据库运维过程中,经常会遇到这样一类问题:
数据库整体性能正常,但某一条 SQL 在业务系统中执行极慢,
然而 DBA 在后台手工执行时,却发现 执行速度非常快。
这类问题往往不在"数据库整体性能",而隐藏在具体 SQL 的执行细节和业务执行环境差异中。
本文记录了一次真实的 SQL 性能排查过程,最终定位到 临时表使用不当 所引发的问题。
一、问题现象:整体正常,单条 SQL 异常
客户业务系统运行过程中,出现如下现象:
• 数据库整体运行状态正常
• CPU、IO、等待事件均无明显异常
• 仅有 一条业务 SQL 在前台执行非常缓慢
• 同一条 SQL 在后台手工执行时,执行速度却非常快
从表象来看,这并不像是数据库整体性能瓶颈,更像是某条 SQL 在特定执行场景下存在问题。
二、通过 AWR 报告定位性能热点
为进一步确认问题,通过 AWR 报告(使用 @?/rdbms/admin/awrrpti.sql 生成)对系统性能进行分析。
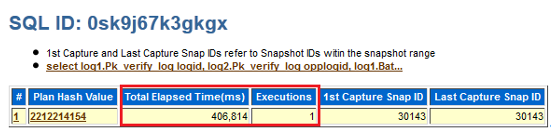
AWR 报告显示:
• 系统的主要性能消耗集中在 一条 SQL
• 该 SQL 单次执行时间约为 406,814 ms
从执行时间来看,这条 SQL 明显是当前系统的主要性能瓶颈。

三、执行计划"完美",却解释不了慢的问题
继续查看该 SQL 的执行计划,发现一个容易让人放松警惕的情况:
• 执行计划 cost 不大
• 各个执行步骤看起来都非常合理
• 没有明显的全表扫描或低效访问路径
从执行计划角度判断,这条 SQL 理论上不应该这么慢。
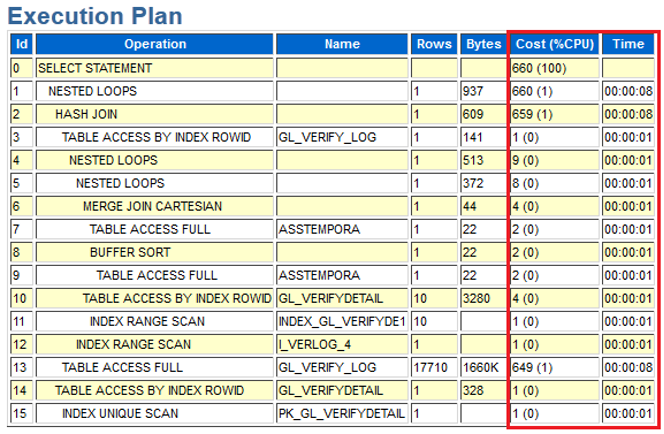
但事实是:
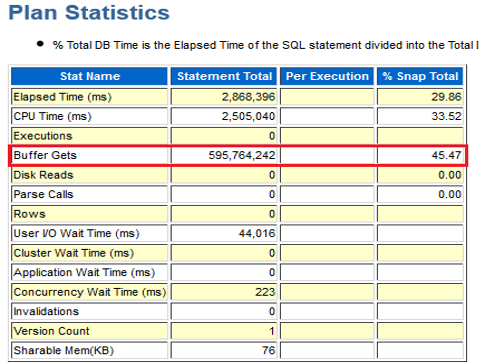
SQL 确实执行得非常慢。
四、执行统计信息暴露异常:buffer gets 极高
在进一步查看 SQL 的执行统计信息后,问题开始显现出来。
该 SQL 的统计信息显示:
• buffer gets 达到 595,764,242
• 这是一个极不正常的数值
而从数据规模来看:
• SQL 中涉及的最大表 GL_VERIFY_LOG 只有 17,710 行
• 其他表的数据量更是可以忽略不计
在如此小的数据规模下,却出现如此高的 buffer gets,显然不符合正常逻辑。
五、常规思路排查:统计信息并非根因
第一反应自然是怀疑:
是否因为对象统计信息不准确,导致优化器判断失误?
于是对 SQL 涉及的所有对象进行了 100% 采样的统计信息收集。
但结果是:
• SQL 执行性能没有任何改善
• buffer gets 依然很高
同时可以确认:
• SQL 未使用绑定变量
• 不存在 bind peeking 导致的执行计划不稳定问题
• 后台执行时显示的执行计划,与 AWR 中的执行计划一致
此时,执行计划、统计信息、SQL 写法,似乎都"没有问题"。
六、关键细节:执行计划中的 Dynamic Sampling
在反复对比前台与后台执行差异时,注意到一个细节:
后台执行该 SQL 时,执行计划中出现了 Dynamic Sampling(动态采样)。

这是一个非常关键的信号。
在 Oracle 中,涉及临时表的 SQL,往往会触发动态采样,以便在运行时获取更准确的数据分布信息。
这一现象直接将排查方向指向了 SQL 中可能存在的临时表。
七、问题根因确认:临时表数据量差异
继续深入检查 SQL 涉及的对象,最终确认:
• SQL 中使用了临时表 ASSTEMPORA
• 前台业务程序执行 SQL 前,会向该临时表中加载 大量数据
• 后台 DBA 手工执行 SQL 时,该临时表 数据为空
这就解释了所有现象:
• 前台执行:
• 临时表数据量大
• SQL 执行过程中产生大量 buffer gets
• 导致执行时间极长
• 后台执行:
• 临时表无数据
• SQL 执行路径看起来"非常理想"
• 执行时间极短
八、优化方案:为临时表补充索引
问题的本质在于:
临时表在高数据量参与 SQL 计算时,缺失必要索引。
针对该问题,在临时表 ASSTEMPORA 上创建索引:
CREATE INDEX ASSTEMPORA_IDX ON ASSTEMPORA (assid);索引创建完成后:
• 前台 SQL 执行时间明显缩短
• buffer gets 大幅下降
• 业务模块性能恢复正常
问题得到彻底解决。
九、小结:临时表同样需要"正式对待"
通过这次问题排查,可以得到几个非常重要的经验结论:
-
执行计划看起来没问题,并不代表 SQL 一定高效
-
前台与后台执行差异,往往来自 数据状态不同
-
临时表一旦承载真实业务数据,就必须像普通表一样设计索引
-
执行计划中的 Dynamic Sampling 是一个非常重要的排查线索
很多 SQL 性能问题,并不是写得复杂,而是在真实业务场景下,被放大了原本被忽略的设计缺陷。