目录
[1. 项目背景与目标](#1. 项目背景与目标)
[2. 核心技术演进](#2. 核心技术演进)
[2.1 方案对比:为什么旧方案慢?](#2.1 方案对比:为什么旧方案慢?)
[2.2 关键代码优化点](#2.2 关键代码优化点)
[3. 存储策略深度解析 (HDFS Block vs Spark Partition)](#3. 存储策略深度解析 (HDFS Block vs Spark Partition))
[3.1 核心结论](#3.1 核心结论)
[3.2 各表最佳配置](#3.2 各表最佳配置)
[4. 最终落地代码 (极速版)](#4. 最终落地代码 (极速版))
[4.1 通用 Python 提交脚本 (submit_job.py)](#4.1 通用 Python 提交脚本 (submit_job.py))
[4.2 Dim 表 (4000万) & Info 表 (2000万) 通用逻辑](#4.2 Dim 表 (4000万) & Info 表 (2000万) 通用逻辑)
[4.3 Related 表 (5000万) & Content 表 (1600万) 通用逻辑](#4.3 Related 表 (5000万) & Content 表 (1600万) 通用逻辑)
[5. 常见问题排查 (Troubleshooting)](#5. 常见问题排查 (Troubleshooting))
[6. 验证结果](#6. 验证结果)
[7. 生产环境资源规划与分区策略 (基于集群实况)](#7. 生产环境资源规划与分区策略 (基于集群实况))
[7.1 集群现状与风险分析](#7.1 集群现状与风险分析)
[7.2 资源隔离策略:弃帅保车](#7.2 资源隔离策略:弃帅保车)
[7.3 并行度计算 (The Math)](#7.3 并行度计算 (The Math))
[7.4 分区策略:速度与存储的动态平衡](#7.4 分区策略:速度与存储的动态平衡)
[7.5 最终落地配置](#7.5 最终落地配置)
[A. 提交脚本 (spark-submit 参数)](#A. 提交脚本 (spark-submit 参数))
[B. 代码逻辑 (PARTITION_CONF)](#B. 代码逻辑 (PARTITION_CONF))
1. 项目背景与目标
之前生成千万级测试数据使用的Pyhive实现,生成数据耗时大,因此想测试Pyspark生成同数据量耗时多少。
在 CDH 集群(10个节点)上,基于现有的小样本数据,快速生成千万级测试数据,并确保数据分布均匀、写入高效。
集群配置如下:
| 表名 | 目标数据量 | 逻辑大小(估算) | 优化前耗时 | 优化后耗时 |
|---|---|---|---|---|
| Dim 表 (企业基本信息) | 4000 万 | ~30 GB | ~40 分钟 | < 5 分钟 |
| Info 表 (招标信息) | 2000 万 | ~10 GB | ~20 分钟 | < 3 分钟 |
| Related 表 (关联关系) | 5000 万 | ~3 GB | ~12 分钟 | < 2 分钟 |
| Content 表 (正文内容) | 1600 万 | ~0.5 GB | ~15 分钟 | < 1 分钟 |
环境配置:
-
CDH 版本: 6.3.2
-
Spark 模式: YARN Client
-
特殊限制 : 必须避开节点
cdh245(10.x.xx.245)。
2. 核心技术演进
2.1 方案对比:为什么旧方案慢?
| 特性 | 旧方案 (循环膨胀法) | 新方案 (极速骨架法) |
|---|---|---|
| 算法逻辑 | 插入 -> 读取 -> 翻倍写入 -> 读取 -> ... (循环约20次) | spark.range() 内存生成骨架 -> CrossJoin 模板 -> 一次写入 |
| I/O 开销 | 极高(反复读写磁盘) | 极低(几乎纯内存计算,仅一次写入) |
| 任务调度 | 启动 20+ 个 Spark Job,调度延迟大 | 仅启动 1 个 Job,立即执行 |
| 文件特征 | 灾难级:同时包含 KB 级小文件和 300MB+ 大文件 | 完美级:文件大小均匀,数量可控 |
| 适用场景 | 小数据量翻倍 | 千万/亿级大规模造数 |
2.2 关键代码优化点
-
废弃
While循环 :改用spark.range(0, TARGET_ROWS)直接生成 ID 骨架。 -
动态分区探测 :增加
find_first_valid_partition函数,自动寻找源表最新分区作为"种子数据",避免全表扫描。 -
精准控制并行度 :使用
repartition(N)强制控制写入文件数量,解决小文件问题。 -
节点黑名单 :在提交脚本中配置
spark.yarn.excludeNodes=cdh245。
3. 存储策略深度解析 (HDFS Block vs Spark Partition)
3.1 核心结论
-
不要强求 128MB :对于几十 GB 的数据量,为了保证计算时的并行度 (Concurrency),文件大小可以小于 128MB。
-
最佳区间 :30MB - 100MB 是当前数据量下的最佳平衡点。
-
计算公式 :
repartition的数量 = 逻辑数据总量 / 目标文件大小(忽略副本)。
3.2 各表最佳配置
-
Dim 表 (30GB) :
repartition(400)-> 单文件 ~75MB。 -
Info 表 (10GB) :
repartition(100)-> 单文件 ~100MB。 -
Related 表 (3GB) :
repartition(100)-> 单文件 ~30MB (为了高并发读取,牺牲少量 NameNode 内存是值得的)。 -
Content 表 (0.5GB) :
repartition(50)-> 单文件 ~10MB (数据量太小,为了保证有 50 个 Task 并发跑,必须切这么细)。
4. 最终落地代码 (极速版)
以下是经过所有优化后的最终版本代码逻辑。
4.1 通用 Python 提交脚本 (submit_job.py)
核心功能:自动上传代码,配置 YARN 资源,避开故障节点。
python
# 关键配置片段
shell_content = f"""
{SPARK_SUBMIT_BIN} \\
--master yarn \\
--deploy-mode client \\
--name 'Optimized_Job' \\
--conf "spark.yarn.excludeNodes=cdh245,10.8.15.245" \\ # <--- 核心配置
--driver-memory 4g \\
--executor-memory 4g \\
--num-executors 10 \\
--conf "spark.sql.shuffle.partitions=400" \\
{self.remote_py_path}
"""4.2 Dim 表 (4000万) & Info 表 (2000万) 通用逻辑
核心功能:一次性生成,无循环,分区检测。
python
def explode_data_fast(spark):
# 1. 动态寻找源表有效分区(种子)
valid_part = find_first_valid_partition(spark, SOURCE_TABLE)
df_template = spark.table(SOURCE_TABLE).filter(col("partition_date") == valid_part).limit(1)
# 2. 内存生成骨架 (速度极快)
df_skeleton = spark.range(0, TARGET_ROWS)
# 3. 关联并生成数据 (使用广播 Join)
df_final = df_skeleton.crossJoin(broadcast(df_template)) \
.withColumn("u_id", expr("uuid()")) \
.withColumn("partition_date", lit(FAKE_PART)) \
.drop("id")
# 4. 并行写入 (Dim表设为400,Info表设为100)
# 这一步保证了文件大小均匀且适中
df_final.repartition(400).write.mode("overwrite").insertInto(TARGET_TABLE_NAME)4.3 Related 表 (5000万) & Content 表 (1600万) 通用逻辑
核心功能:取模关联算法,保证数据逻辑一致性。
python
# 骨架与种子数据的关联逻辑
df_joined = df_skeleton.crossJoin(broadcast(df_template)) \
.withColumn("uid_join_key", (col("row_idx") % 20000000).cast(LongType())) # 循环引用 Info 表 ID
# 写入时 Content 表因为数据量小,repartition(50) 即可
df_to_write.repartition(50).write.mode("overwrite").insertInto(TARGET_TABLE)5. 常见问题排查 (Troubleshooting)
在执行过程中出现的日志现象及解释:
-
HDFS 文件分布不均 / 耗时过长
-
原因 : 使用了旧的
while循环逻辑。 -
解决: 切换到上述"极速版"代码。
-
-
SparkRackResolver: Got an error when resolving hostNames-
原因: 集群未配置机架感知脚本。
-
影响 : 无影响,会自动回退到
/default-rack,可忽略。
-
-
Trying to remove executor ... Asked to remove non-existent executor-
原因: Spark 的动态资源分配 (Dynamic Allocation) 或 容器被抢占。
-
判断: 只要任务没 Fail,这是正常的资源调度行为。
-
-
KeyboardInterrupt-
原因 : 用户在 Driver 等待 YARN 资源分配时(
SchedulerBackend is ready...)手动中断了脚本。 -
解决: 耐心等待 1-2 分钟,或去 YARN 界面查看任务状态。建议脚本增加心跳保持机制。
-
6. 验证结果
任务执行完成后,通过以下命令验证,看到了完美的分布式存储状态:
bash
hdfs dfs -ls /user/hive/warehouse/.../partition_date=20991231/-
Info/Related 表: 生成 100 个文件,大小高度一致(约 30MB - 100MB)。
-
Content 表: 生成 50 个文件,大小高度一致(约 10MB)。
-
Dim 表: 生成 400 个文件,大小高度一致(约 75MB)。
结论:这就标志着造数任务不仅完成,而且达到了生产环境的高质量存储标准。
7. 生产环境资源规划与分区策略 (基于集群实况)
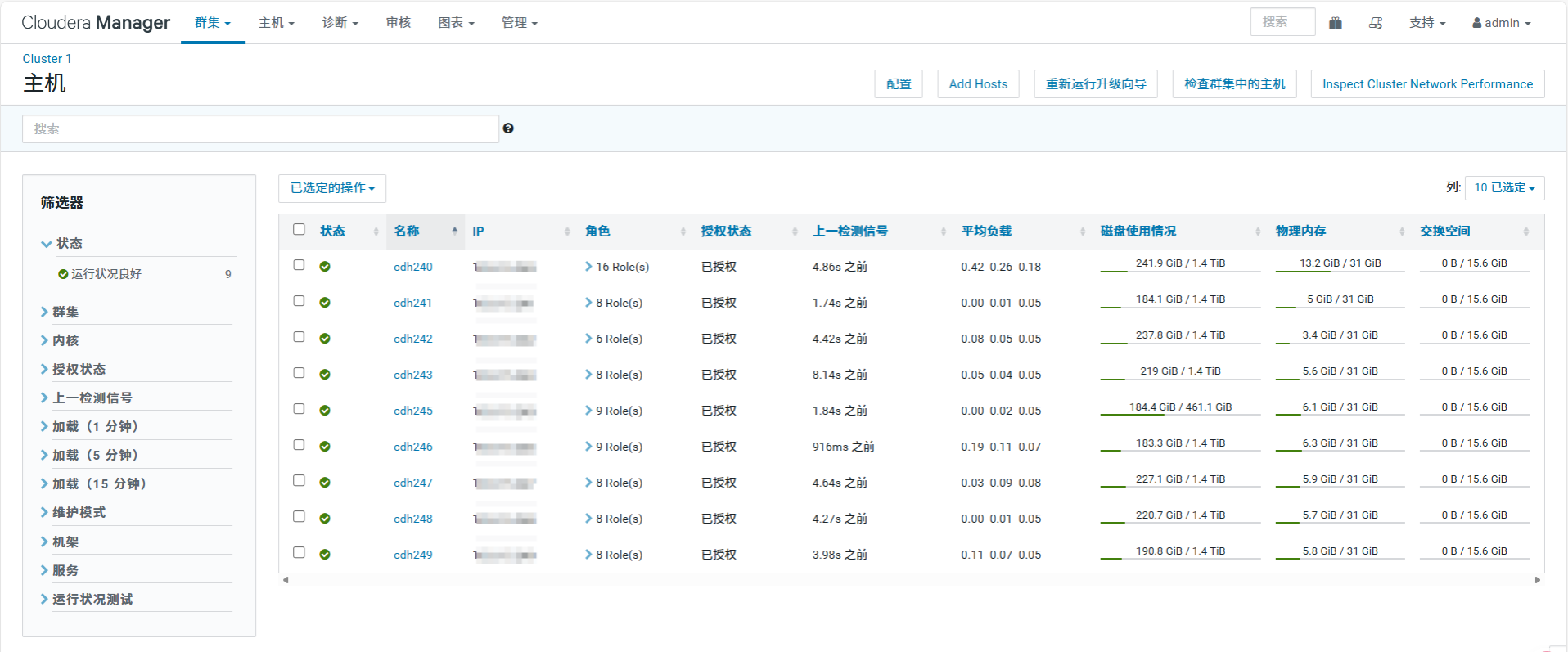
通过对 Cloudera Manager 集群资源的详细审计,重新制定了更符合生产环境现状的资源调度策略。下面详细阐述如何根据硬件规格计算并行度,以及如何保护集群核心节点。
7.1 集群现状与风险分析
-
硬件规格 :集群共 9 个节点 (
cdh240-cdh249),配置高度统一,单节点物理内存 31 GiB,磁盘约 1.4 TiB。 -
角色分布不均:
-
Master 节点 (
cdh240) :运行了 NameNode, ResourceManager 等 16 个角色,内存仅剩约 15GB 可用。 -
Worker 节点 (
cdh241等):仅运行 DataNode 等少数角色,内存极其空闲。
-
风险判断 :如果按照全集群平均分配资源,cdh240 会因资源耗尽而导致 NameNode 响应变慢,甚至引发整个集群的元数据服务卡顿。
7.2 资源隔离策略:弃帅保车
为了保障造数任务不影响集群稳定性,采取 "主节点避让" 策略:
-
计算节点池 :仅使用 8 个 Worker 节点 (
cdh241-cdh249),彻底排除cdh240。 -
单节点资源计算:
-
物理内存:31 GB
-
系统/Hadoop预留:-7 GB
-
YARN 安全可用 :24 GB
-
7.3 并行度计算 (The Math)
基于 8 个 Worker 节点进行算力规划:
-
Executor 规格:采用标准容器规格,避免大内存 GC 卡顿。
-
内存:4 GB (24GB / 6 = 4GB,整除且高效)
-
核心:2 Cores (兼顾并发与调度开销)
-
-
集群总容量:
-
单节点 Executor 数:24 \\text{ GB} / 4 \\text{ GB} = 6 \\text{ 个}
-
集群总 Executor 数:8 \\text{ Nodes} \\times 6 = 48 \\text{ 个}
-
安全申请数 :45 个 (预留 3 个余量给 Driver 和临时任务)
-
-
总并行度 (Total Cores):
- 45 \\text{ Executors} \\times 2 \\text{ Cores} = \\mathbf{90 \\text{ 并发核心}}
7.4 分区策略:速度与存储的动态平衡
基于 90 个并发核心 和 HDFS 128MB Block 两个基准,重新计算各表分区数。
| 表名 | 数据量 (逻辑) | 策略分析 | 最终分区数 (Repartition) | 单文件大小 | 预期效果 |
|---|---|---|---|---|---|
| Dim | 30 GB | 存储优先:30GB/128MB \\approx 240。 且 240 \> 90,CPU 吃饱。 | 240 | ~128 MB | HDFS 完美存储 并发度极高 |
| Info | 10 GB | 计算优先:10GB/128MB \\approx 80。 80 < 90,为跑满 CPU,强行提至 100。 | 100 | ~100 MB | 计算速度最大化 无 CPU 空转 |
| Related | 3 GB | 计算优先:数据较小。 为跑满 CPU,强制设为 90。 | 90 | ~33 MB | 极速完成 瞬间利用全集群算力 |
| Content | 0.5 GB | 避免碎片:数据极小。 仅使用一半算力,防止生成 KB 级小文件。 | 45 | ~11 MB | 平衡 拒绝小文件风暴 |
7.5 最终落地配置
A. 提交脚本 (spark-submit 参数)
显式排除 Master 节点,申请 45 个 Executor 榨干 Worker 节点性能。
python
spark-submit \
--master yarn \
--deploy-mode client \
--name 'Data_Gen_Production' \
--driver-memory 4g \
--executor-memory 4g \
--executor-cores 2 \
--num-executors 45 \
--conf spark.default.parallelism=180 \
--conf spark.sql.shuffle.partitions=180 \
--conf "spark.yarn.excludeNodes=cdh240,10.8.15.240" \
your_script.pyB. 代码逻辑 (PARTITION_CONF)
将上述计算的分区数值固化到代码中。
python
# 基于 90 Core 并发算力的生产环境配置
PARTITION_CONF = {
"dim_enterprise": 240, # 存储对齐 (128MB)
"info_bidding": 100, # 算力对齐 (跑满 CPU)
"related_company": 90, # 算力对齐 (跑满 CPU)
"content_table": 45 # 碎片控制 (半数并发)
}
def write_optimized(df, table_name):
# 获取科学计算后的分区数,默认为 200
target_p = PARTITION_CONF.get(table_name, 200)
print(f">>> [生产模式] 表 {table_name} -> 重分区数: {target_p}")
df.repartition(target_p) \
.write \
.mode("overwrite") \
.insertInto(table_name)