中间件设计
今天,我们要完成对中间件的支持,计划实现一个 Logger() 中间件,可以在终端输出页面响应的时间。
引入中间件的原因在于,Web 框架需要提供一种灵活的方式来处理请求/响应的不同方面,比如日志记录、性能监控、权限验证等。这些操作如果直接嵌入到每个路由的处理函数中,不仅会造成重复代码,还会让业务逻辑和基础功能混杂在一起,不易维护。
那么具体如何展开呢?
在上一节我们讲到,路由组 的作用是为了对不同的路由进行分类管理,避免中间件的冲突。比如:一个大型应用中可能会有很多不同的功能模块(例如:/api,/admin,/v1 等),中间件应该能够按路由组来独立设置,而不是全局应用,避免影响到不同模块的独立性。中间件应该以路由组为单位而不是具体的每一条路由,那样会有大量重复的代码,并且也不符合中间件的定义,因此我们就可以从 RouterGroup 入手了。我们先来看看目前代码中的 RouterGroup 的结构:
go
type RouterGroup struct {
prefix string
middlewares []HandlerFunc // 支持中间件
parent *RouterGroup // 支持嵌套
engine *Engine // 所有 group 共享一个 Engine 实例
}可以看到,在上一节我们已经给其中添加了一个 middlewares []HandlerFunc 来支持中间件。在 RouterGroup 中,这个属性是用来注册该路由组别下所需要的全部的中间件的。具体来说,不同的路由可能需要使用不同的中间件,此时我们就需要到 Context 结构体中进行修改,用以支持对于具体路由的中间件的使用,来看一下目前 Context 的结构:
go
type Context struct {
Writer http.ResponseWriter
Req *http.Request
Path string // 请求资源路径
Method string // 请求方式
Params map[string]string // 提供对路由参数的访问(router.go 中的 getRoute 返回的 params 就存储在这里)
StatusCode int // 状态码
}这里并没有和中间件相关的内容,因此考虑增加内容来支持具体路由对于中间件的使用。
首先我们可以想到的就是添加一个类似于 RouterGroup 中的 middlewares 类似的数组,用于存储具体路由需要执行的中间件,不难想到可以添加一个下面的属性:
css
handlers []HandlerFunc那么,除了这个,还需要其他的内容吗?需要,我们还需要一个 index 用于控制中间件的执行过程。那么最终的设计如下:
go
type Context struct {
Writer http.ResponseWriter
Req *http.Request
Path string // 请求资源路径
Method string // 请求方式
Params map[string]string // 提供对路由参数的访问(router.go 中的 getRoute 返回的 params 就存储在这里)
StatusCode int // 状态码
// 用于中间件
handlers []HandlerFunc
index int // 用于控制中间件的执行顺序
}我们来解释一下这里的 index 具体是干嘛的,介绍这个之前我们现需要了解一下中间件。
对于某些中间件来说,我们需要在事件开始之前启动,事件结束之后才能结束,比如说我们今天要设计的统计执行时间的中间件,而 index 的设计就是为了能够让它们既能在 Handler 之前执行,也能在 Handler 之后"回头执行"。
如果不设计 index 来控制中间件的运行顺序,看一下下面的场景:
scss
A()
B()
Handler()A 和 B 都是一个中间件,这样的话,你只能在 Handler 之前做事情,比如鉴权、参数校验等。但实际上有很多中间件都的功能都需要等 Handler 执行完之后才能做,比如:
- 统计请求耗时
- 捕获 panic
- 打日志(需要拿到最终的状态码)
所以现有的结构没法支撑我们做到一层一层包住 Handler。你可以把中间件想象成这样一个结构:
scss
func Middleware(c *Context) {
// 前半段
c.Next()
// 后半段
}这个结构的重点在于c.Next() ,这里的 Next() 并不是调用下一个函数这么简单,它真正的含义是:
"把执行权交给下一个中间件/Handler,等它们全部执行完,再回来继续执行我后面的代码。"
这在普通的函数调用中是做不到的,因此为了做到这一点,为了实现 Next(),我们必须:
-
把 所有中间件 + Handler 放进一个列表(
c.handlers) -
用一个
index记录"现在执行到第几个" -
通过
Next()手动推进这个执行链
最后用一个具体的例子来理解一下,假设我们有这样一个中间件的调用:
css
A -> B -> Handler那么底层的执行顺序应该是:
css
A 前
B 前
Handler
B 后
A 后这不是普通的"顺序调用", 而是一个人为构造的调用栈。
Context.handlers + index + Next() 就是在 模拟函数调用栈的展开与回收。
我在理解这部分的时候的困难是:我忘记了自己在编写一个框架,而不是一个框架的使用者。 因为框架本身就是为了便于开发,隐去一些不必要的或者重复的逻辑。那作为开发者(或者说框架的使用者),我在开发使用中间件的时候,我知道中间件应该包含Handler,我知道直接使用 A -> B -> Handler 就应该是类似于栈的执行顺序,其他框架直接这么用也是没问题的(底层会包含Handler),这是大家都通用的,因此我(框架使用者)这么用应该是没问题的。因此,框架需要完成从 A -> B -> Handler 到 A 前->B 前->Handler->B 后->A 后,需要支持大家的使用习惯,同时框架的设计也该如此。因此,我们要引入 index,我们要在框架层面完成从顺序调用到人为构造一个调用栈的转换。
Next() 的设计
我们先看Next()的具体实现:
go
func newContext(w http.ResponseWriter, req *http.Request) *Context {
return &Context{
Writer: w,
Req: req,
Path: req.URL.Path,
Method: req.Method,
index: -1, // Context 定义多了一个 index,所以初始化的时候也不要忘了
}
}
// Next 用于控制中间件的执行顺序,调用后会将控制权交给下一个中间件
func (c *Context) Next() {
c.index++
s := len(c.handlers)
for ; c.index < s; c.index++ {
c.handlers[c.index](c)
}
}我们先理解如何通过一个数组和一个索引来实现中间件的控制的,通过模拟一次真实的执行来理解。假设某路由需要执行 2 个中间件:A,B。
作为开发者(框架使用者),我们会这样写:
scss
A(c)
B(c)
H(c) // Handler它们被放进一个数组:
ini
handlers = [A, B, H]
index = -1现在开始执行。
第一步
首先框架会调用 c.Next():
scss
c.Next()为什么需要先调用 c.Next()呢,原因是:
- 启动执行链:框架需要主动启动中间件链的执行,这样才能确保中间件按照正确顺序执行。
- 生命周期管理 :框架控制整个请求的生命周期,从接收请求到执行中间件,再到最终返回响应,中间件链的启动必须由框架
至于具体在框架的哪个位置调用 c.Next(),待会会实现。
调用 Next 之后,进入内部代码:
scss
index++ // index = 0
handlers[0](c) // 调用 A注意:现在还在 Next() 里面,只是 Next 调用了 A。
第二步
进入中间件 A 内部:
go
func A(c) {
part1
c.Next()
part2
}先执行 part1,然后再次调用 c.Next()。
第三步
再次进入 Next,注意这次是从 A 内部进入的 Next:
scss
index++ // index = 1
handlers[1](c) // 调用 B此时:
- 第一次 Next 还没结束
- A 也还没结束(part2 还未执行)
- 又进入了第二层 Next
这是普通函数调用栈嵌套。
第四步
进入 B:
go
func B(c) {
part3
c.Next()
part4
}执行 part3,再调用 c.Next()。
第五步
第三次进入 Next:
scss
index++ // index = 2
handlers[2](c) // 调用 H进入 Handler。
第六步
Handler 没有调用 Next(),所以它直接 return。
第七步
程序开始回退调用栈:
- 从 Handler 返回到 B
- 执行
part4 - B 执行完,返回到 A
- 执行
part2 - A 执行完,返回到最初的 Next
- 整个请求结束
这部分很好理解,其实就是递归,一层一层回退。
最终执行顺序
所以,最终的执行顺序是:
css
A.part1
B.part3
H
B.part4
A.part2走完整个流程后我们可以看到,确实实现了:
中间件不是"按顺序执行", 而是"按调用栈展开、再按调用栈回收"。
最后,还需要解释一下 Next() 内部为什么要用一个循环:
scss
func (c *Context) Next() {
c.index++
s := len(c.handlers)
for ; c.index < s; c.index++ {
c.handlers[c.index](c)
}
}而不是:
scss
func (c *Context) Next() {
c.index++
c.handlers[c.index](c)
}这是因为,有些 handler 并不会调用 Next(),就比如我们上面模拟的过程,最后一步的 handler 没有调用 Next(),如果出现多个 handler 一起调用的情况,此时不用循环就无法推进下去了。
一句话总结就是,for 是为了兜底推进,确保可以执行到底把流程走完。
所以总结一下:
Next() 是为了提供一种灵活的控制流,让每个中间件不仅能够在前置逻辑(请求前)执行,还能在后置逻辑(请求后)进行处理。
index 不仅仅是控制顺序,实际上它还模拟了一个状态机的行为,可以理解为是"中间件栈"的索引。
在中间件的设计中,Next() 的作用类似于函数调用栈的行为。当调用 Next() 时,程序会依次执行每个中间件,类似于函数调用栈的"展开"。一旦当前中间件执行完成,它会回到上一级中间件继续执行未完成的部分,直到整个栈被"回收"。这种设计让中间件不仅可以在请求处理的前半部分执行逻辑(例如:请求参数校验),也可以在后半部分执行一些收尾操作(例如:统计请求耗时或记录日志)。通过 Next() 和 index 的结合,模拟了一个执行顺序严格控制的栈结构,从而使中间件可以灵活地在请求生命周期的前后两部分完成各自的功能。
代码实现
通过上面的讲解,我们已经知道了如何做到对中间件的支持。接下来还需要对框架中的一些函数进行修改。
首先我们要在 gee.go 中定义一个 Use 函数,将中间件注册到某个 Group:
scss
func (group *RouterGroup) Use(middlewares ...HandlerFunc) {
group.middlewares = append(group.middlewares, middlewares...)
}这个函数实际上就是给某个路由分组添加其可能需要用到的中间件。这里需要注意是对 RouterGroup.middlewares 进行操作,而不是对 Context.handlers 进行操作。前者用于存储该路由分组下所有可能用到的中间件,而后者用于实现中间件的流程控制,即可以存储中间件,也可以存储实际需要调用的函数 handlers。
同时,我们还需要对 gee.go 中的 ServerHTTP 进行修改:
scss
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 这部分逻辑用于判断传入的路径所属的 group 包含哪些中间件
var middlewares []HandlerFunc
for _, group := range engine.groups {
// 如果传入路径包含某个 group 的 prefix(前缀),说明传入的路径属于这个 group,那么这个 group 所包含的全部的中间件就都需要应用于该请求路径
if strings.HasPrefix(req.URL.Path, group.prefix) {
middlewares = append(middlewares, group.middlewares...)
}
}
c := newContext(w, req)
c.handlers = middlewares // 前面 for 循环找出了该请求路径下需要的全部中间件 middlewares,把这个加入到 Context.handlers,之后就可以根据 Context.handlers 来执行具体的中间件了
engine.router.handle(c)
}当我们接收到一个具体请求时,要判断该请求适用于哪些中间件,在这里我们简单通过 URL 的前缀来判断。得到中间件列表后,赋值给 c.handlers。
最后,我们还需要对 router.go 中的 handle 函数进行修改:
go
// 根据 Context 查找 handler 并调用
func (r *router) handle(c *Context) {
n, params := r.getRoute(c.Method, c.Path)
if n != nil {
c.Params = params
key := c.Method + "-" + n.pattern
//r.handlers[key](c)
c.handlers = append(c.handlers, r.handlers[key]) // 修改 1
} else {
// 修改 2
c.handlers = append(c.handlers, func(c *Context) {
c.String(http.StatusNotFound, "404 NOT FOUND: &s\n", c.Path)
})
}
c.Next() // 修改 3
}主要修改的部分在代码中标注出来了,其实就是将两个处理都加到 Context.handlers 中。这里更多的是告诉我们:对于这种错误处理之类的代码,完全可以提取出来作为一个中间件进行处理。这里的处理并不是最终的实现,最终的实现应该是将错误处理、日志记录等功能提取成 独立的中间件函数,然后通过框架的中间件机制将它们自动应用到请求处理流程中。
使用 Demo 测试
首先在 gee 文件夹下添加一个中间件logger.go:
go
package gee
import (
"log"
"time"
)
func Logger() HandlerFunc {
return func(c *Context) {
// 开始计时
t := time.Now()
// 处理请求
c.Next()
// 计算时间
log.Printf("[%d] %s in %v", c.StatusCode, c.Req.RequestURI, time.Since(t))
}
}接下来在 main.go 编写测试 demo:
go
package main
import (
"gee"
"log"
"net/http"
"time"
)
// 自定义中间件
func onlyForV2() gee.HandlerFunc {
return func(c *gee.Context) {
// Start timer
t := time.Now()
// if a server error occurred
//c.Fail(500, "Internal Server Error")
// Calculate resolution time
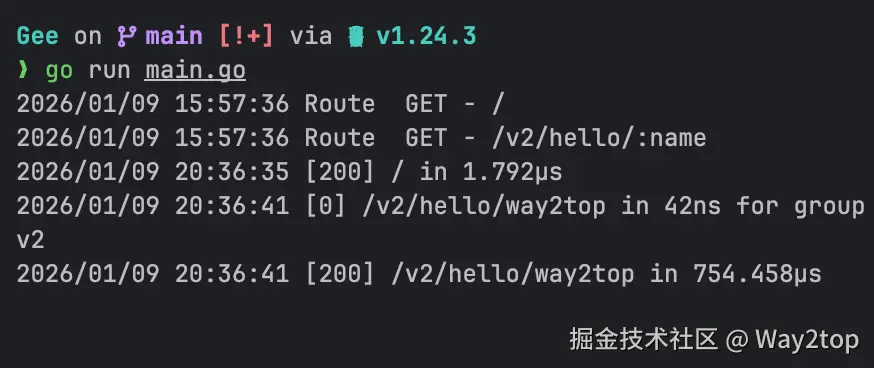
log.Printf("[%d] %s in %v for group v2", c.StatusCode, c.Req.RequestURI, time.Since(t))
}
}
func main() {
r := gee.New()
r.Use(gee.Logger()) // global middleware
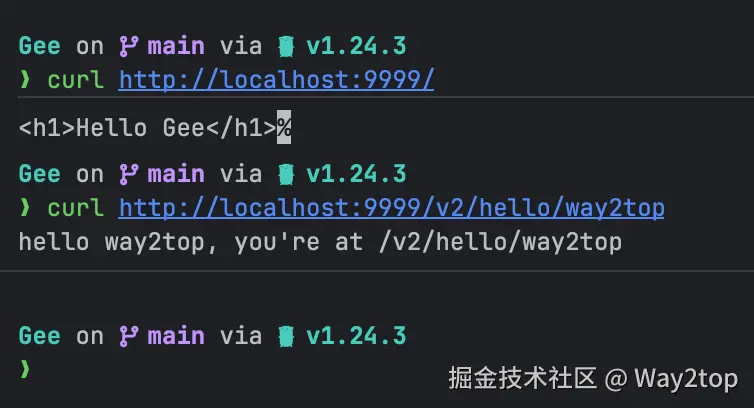
r.GET("/", func(c *gee.Context) {
c.HTML(http.StatusOK, "<h1>Hello Gee</h1>")
})
v2 := r.Group("/v2")
v2.Use(onlyForV2()) // v2 group middleware
{
v2.GET("/hello/:name", func(c *gee.Context) {
// expect /hello/geektutu
c.String(http.StatusOK, "hello %s, you're at %s\n", c.Param("name"), c.Path)
})
}
r.Run(":9999")
}运行代码,然后在终端进行测试,可以看到终端确实输出了响应时间相关代码。