传送锚点
-
- 1.概述
- [2. DSA + MLA:降低成本](#2. DSA + MLA:降低成本)
- 3.扩展强化学习:可靠地提升性能
- [4. 工具使用的修正思维:更智能的情境管理](#4. 工具使用的修正思维:更智能的情境管理)
- 5.智能与效率的权衡
每位机器学习工程师都应该了解的 DeepSeek-V3.2 三大方向设定贡献,直观易懂地解释。
1.概述
DeepSeek-V3.2 的发布表明,通过架构改进和有意扩展强化学习来降低长上下文计算成本,可以实现 GPT-5 级别的推理和代理性能。而这一切都可以通过更小、更老、更便宜、更快速的主干网实现。
Ilya Sutskever 表示,预训练的结束已经到来,因为基础实验室已经耗尽了网络上所有可用的代币。
本文将介绍 DeepSeek-V3.2 论文中前三项方向设定贡献,我们认为这些贡献将发展成为机器学习工程师值得理解的新标准培训实践。这些同时也是经过测试的"旋钮",如果你想针对特定场景改进基础模型,可以转动它们。
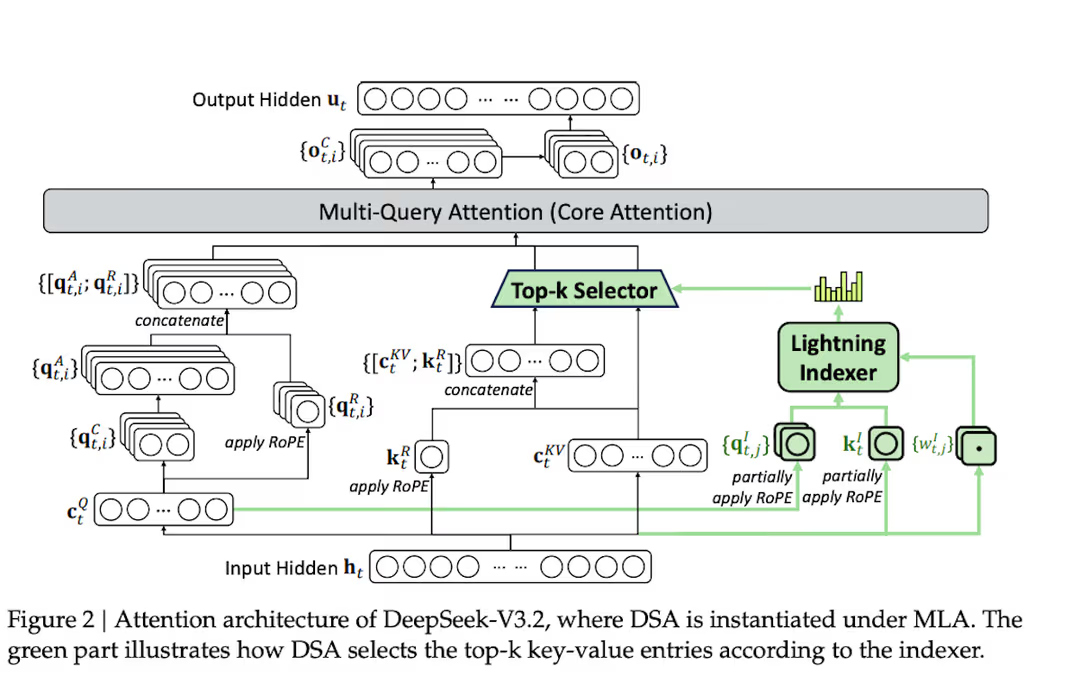
2. DSA + MLA:降低成本
从架构上看,DeepSeek-V3.2 几乎与 V3.1-Terminus 是同一型号。主要创新是基于多头潜在注意力(MLA)的深度寻稀疏注意力(DSA)技术,这是一种密集注意力变体,将 KV 向量投射到低维空间以减少内存占用。
DSA 由两个组成部分组成:
-
首先,一个小型闪电索引器会对所有过去的标记进行评分,以确定与当前查询标记的相关性。
-
然后,标记选择器从 128k 上下文中选择前 k 个标记(2048 个,DeepSeek 团队选择的超参数)供 MLA 运行。
注意:索引器和选择器都是后天习得的。它们结合起来,形成了一个注意力面罩,过滤掉不那么相关的标记。
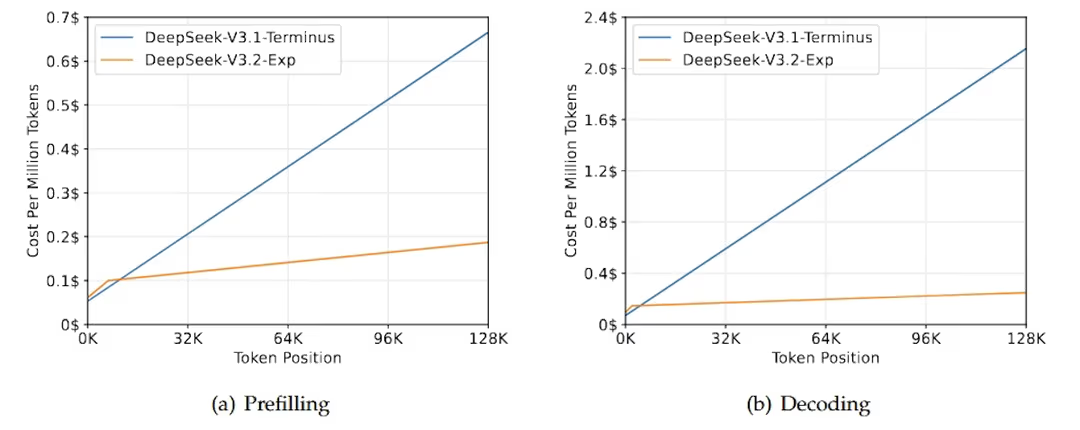
运行大型语言模型的最大瓶颈之一是多头注意力是一个二次的 O(N²) 运算。然而,由于闪电索引器处于 FP8,只有少数几个正面,其名义二次成本远远不及对整个上下文做完整 MLA 的节省。在预填充期间,每个代币的端到端成本几乎达到 128k,解码时仅以 k 为单位线性增长,约为 O(N\*k),其中 k<<N。

真正的含义是,DSA 存在是为了让我们能够负担大量推理代币。如果我们看 Speciale 变体,在推理基准测试(AIME、HMMT、IMOAnswerBench、LiveCodeBench)上,Speciale 经常能匹敌甚至击败 Gemini-3.0-Pro。但没有免费的午餐;Speciale 在相同问题下消耗的输出标记数量比 Gemini 和 GPT-5 多约 1.5--2 倍。例如,在 Codeforces 上,平均每个解输出 token 数为 270,1000 个,而 GPT-5 和 Gemini-3.0-Pro 则为 22,000 至 29k。
DSA 实际上是在用参数上的 FLOP 兑换在推理时间内用于代币的 FLOP。这和我们历史上遇到的"旋钮"不同。教训是:
如果你还负担不起更大或高强度预训练的基础模型,就多用测试时计算,并用更好的关注让它变得便宜。
这种框架在强化逻辑(RL)和显形技术(SFT)中很重要:
-
先行分析主要提升了 1 倍测试时间计算时的能力;
-
强化分析 + 数据结构分析(DSA)则可以通过增加测试时间计算来购买能力,同时保持在线性成本范围内。
3.扩展强化学习:可靠地提升性能
DeepSeek 明确表示他们的 RL 预算是预训练计算的 >10% ,这与历史上 RL 的支出相比,显得不成比例地高。有趣的是,Grok 最近也承认自己处于同样的运作模式,其他实验室很可能也是如此。这与 Meta ScaleRL 论文所称的高回报区划差不多:一旦 RL 达到训练前 FLOP 的两位数比例,你就会开始看到质的新行为,而非边缘的打磨。
DeepSeek 使用 GRPO,但实现了近期理论论文中讨论的修复。他们从 GxPO 变体群中选取了一些子集来诱导训练稳定性:
| 技术特性 | 说明 |
|---|---|
| 修正后的 KL 估计器 | 使用修正后的 K3 估计器进行无偏 KL 估计已讨论一段时间 |
| 非策略序列掩蔽 | 以减少非策略推广带来的学习 |
| 保持路由 | 通过对齐训练与推断之间的差异来提升模型的训练稳定性 |
| 保持采样掩码 | 通过对齐训练与推断之间的差异来提升模型的训练稳定性 |
| 综合来看,这是新强化学习文献趋同的清晰体现。强化学习不再是发明新目标,而是让旧目标真正匹配基础(训练与推理)的效果。这是更广泛强化与实质化理论叙事的一个有力数据: | |
| > 一旦你修正了不匹配并支付了浮币,强化学习总能为你带来单靠前置理论无法实现的巨大推理飞跃。 |
3.1在代理端
DeepSeek 的主要贡献是他们如何打包强化学习环境。他们综合了:
-
1,827 个通用代理环境
-
4,417 个任务
每个任务都暴露了一个工具集和一个自动验证器;此外还有用于代码修复(GitHub issue/PR 配对)和搜索(商业 Web API)和基于 Jupyter 的代码解释器配置。每个环境本质上都是一个元组:<env state, tools, task, verifier>。一旦有了这个,强化学习"就是"带有可验证奖励的 GRPO。
这可能为希望区分所服务模型的公司提供了一种新的护城河。与任何人都能抓取的由网页文本组成的预训练数据相比,代理化强化学习数据类似于配备定制工具和验证器的策划微型模拟器,这种体验更难以随意复制。来自应用或高质量合成数据生成器的专有使用数据可能成为越来越有价值的资产。
4. 工具使用的修正思维:更智能的情境管理
DeepSeek V3.2 还悄悄修补了智能体思维模型的一个大痛点:如何通过频繁的工具调用来管理上下文。
在最初的 DeepSeek-R1 配方中,每次消息后都会丢弃 CoT(思维链),因此模型必须从头重新推理。对于复杂的工具流(如多跳搜索或多轮代码调试),该策略迫使模型每回合烧毁相同的部分计划标记。结果是代币效率低,产生不必要的成本并增加延迟。
在该模型中,**只有当出现新用户消息时,累积的推理痕迹才会被丢弃。**工具输出和后续工具调用不会清除之前的思维;推理状态贯穿多步轨迹。当你最终放弃推理时,工具调用的历史和结果依然会留在上下文中。
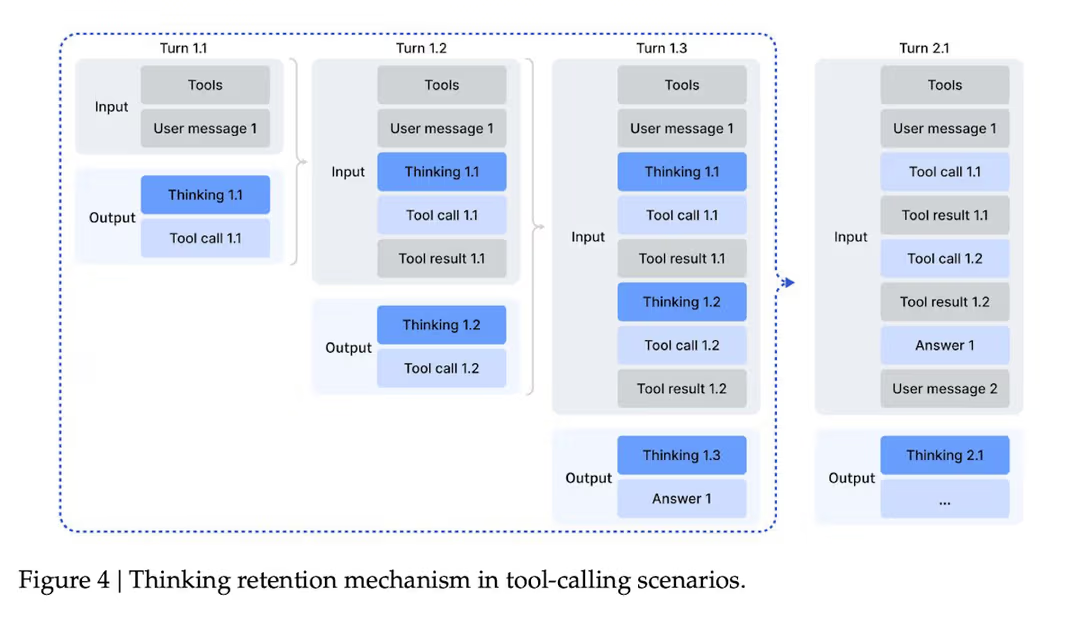
在评估方面,DeepSeek 表明显式上下文管理策略实际上是另一个轴,用来榨取测试时计算的效能。在 BrowseComp 上,像"达到 80% 上下文时总结"或"丢弃所有工具历史并重启"这样的简单策略,可以将通过率从 ~53% 提升到 ~68%。
因此,除了扩展强化学习和降低成本增加思维代币外,实际上,在运行时积极回收上下文是模型执行复杂任务时不超过上下文窗口的巧妙第三杠杆。
5.智能与效率的权衡
总之,开源正在追赶闭源的黄金标准,但它们需要的代币数量大约是它们的两倍。
| 模型 | 推理与编程基准表现 | 代币效率 | 成本效率 |
|---|---|---|---|
| DeepSeek-V3.2-Thinking | 在许多推理和编程基准测试中大致达到 GPT-5 高水平,但整体略逊于 Gemini-3.0-Pro | 每个代币的智能效率较低 | 按每美元计算的效率是数倍的(例如 GPT5 输出 10 美元,DeepSeek-V3.2 基于 Baseten 仅 0.45 美元) |
| DeepSeek-V3.2-Speciale | 高计算量的 Speciale 变体常常能匹敌甚至击败 Gemini-3.0-Pro | 消耗的输出 token 数量比 Gemini 和 GPT-5 多约 1.5--2 倍 | 更经济实惠 |
| 其他模型 | - | - | - |
| 在 IMO、CMO、IOI 和 ICPC WF 中获得金牌表现,无需针对比赛进行特定调校。 | |||
| 虽然 DeepSeek-V3.2 在每个代币的智能效率较低,但当与其闭源对应产品相比,按每美元计算的效率是数倍的(例如 GPT5 输出 10 美元,DeepSeek-V3.2 基于 Baseten 仅 0.45 美元)。 |